一种实体关系提取的方法和装置与流程
本发明涉及自然语言处理,尤其涉及一种实体关系提取的方法和装置。
背景技术:
1、自然语言处理是指用计算机处理自然语言。它是研究人与计算机进行通信的各种方法。在信息时代,从文本中提取关键信息,将会有利于文本的整理、分类和利用。自然语言处理又分为命名实体识别、关系识别等基础任务。
2、随着深度学习的发展,基于深度学习的自然语言处理在充分的数据训练下,可以达到很高的精度。但是,数据集内容的充分性和域内知识的相关性对模型的效果有很大影响。提高数据质量、数据数量可以提升模型的性能、泛化能力和鲁棒性。
3、然而,现实中用于自然语言处理的数据集往往存在数据量不足,数据类别分布不均匀的现象。例如,在实体关系提取任务中,只有少部分的关系拥有足够的三元组,针对这样的少样本情况,会导致学习模型的效果较差。
技术实现思路
1、有鉴于此,本发明实施例提供一种实体关系提取的方法和装置,能够批量生成数据较少的关系类别对应的扩充数据集,从而实现对各种数据类型的扩充,平衡了数据类别;同时,通过对合并数据集进行数据增强处理,生成一个更大的数据集,用于模型训练,提高了模型的泛化能力和鲁棒性,提高了实体关系提取效率和准确性。
2、为实现上述目的,根据本发明实施例的一个方面,提供了一种实体关系提取的方法,包括:
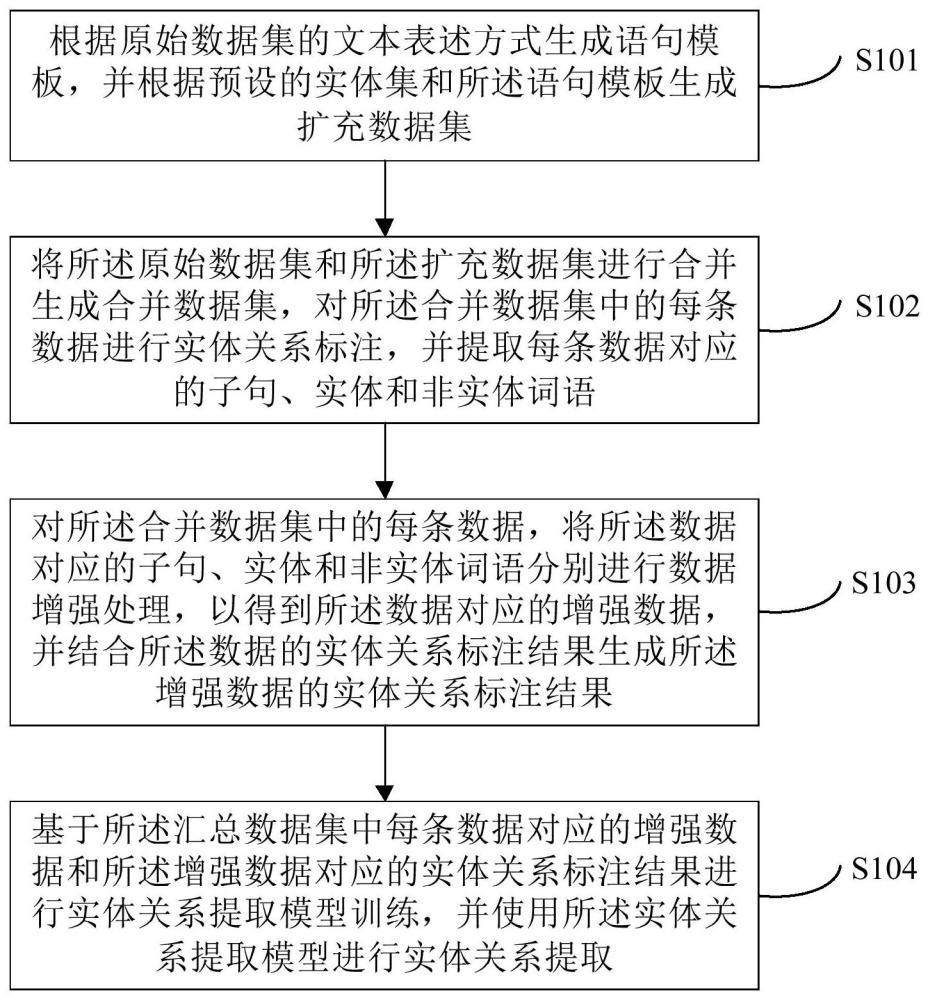
3、根据原始数据集的文本表述方式生成语句模板,并根据预设的实体集和所述语句模板生成扩充数据集;
4、将所述原始数据集和所述扩充数据集进行合并生成合并数据集,对所述合并数据集中的每条数据进行实体关系标注,并提取每条数据对应的子句、实体和非实体词语;
5、对所述合并数据集中的每条数据,将所述数据对应的子句、实体和非实体词语分别进行数据增强处理,以得到所述数据对应的增强数据,并结合所述数据的实体关系标注结果生成所述增强数据的实体关系标注结果;
6、基于所述汇总数据集中每条数据对应的增强数据和所述增强数据对应的实体关系标注结果进行实体关系提取模型训练,并使用所述实体关系提取模型进行实体关系提取。
7、可选地,根据预设的实体集和所述语句模板生成扩充数据集,包括:使用所述预设的实体集中的实体替换所述语句模板中的对应字段,以生成扩充数据集。
8、可选地,对所述合并数据集中的每条数据进行实体关系标注,包括:结合实体在数据中的位置对所述合并数据集中的每条数据的实体关系进行标注。
9、可选地,结合实体在数据中的位置对所述合并数据集中的每条数据的实体关系进行标注,包括:对所述合并数据集中的每条数据,结合实体在所述数据中的位置,对所述数据中在不同位置出现的同名实体后追加位置编码信息,以对所述数据中的实体关系进行标注;其中,所述位置编码信息为所述同名实体在所述数据中出现的次数序号。
10、可选地,结合所述数据的实体关系标注结果生成所述增强数据的实体关系标注结果,包括:结合所述数据的实体关系标注结果中各个实体的位置编码信息,生成所述增强数据的实体关系标注结果。
11、可选地,提取每条数据对应的子句、实体和非实体词语,包括:对每条数据,将所述数据按照标点符号划分成多个子句;遍历所述多个子句,根据所述预设的实体集,从每个子句中提取实体,并对不是实体的部分进行分词处理得到非实体词语。
12、可选地,对所述合并数据集中的每条数据,将所述数据对应的子句、实体和非实体词语分别进行数据增强处理,包括:对所述合并数据集中的每条数据,对所述数据对应的子句,以一定的概率进行随机删除或者位置交换以进行数据增强处理;对所述数据对应的实体,以一定的概率,使用从所述预设的实体集中选取的与所述实体的类别相同的实体对所述实体进行替换,以进行数据增强处理;对所述数据对应的非实体词语,以一定的概率,使用所述非实体词语的近义词对所述非实体词语进行替换,以进行数据增强处理;其中,若所述非实体词语为数字,则使用随机产生的数字对所述非实体词语进行替换。
13、可选地,在提取每条数据对应的子句、实体和非实体词语之后,还包括:将每条数据对应的子句、实体和非实体词语分别作为节点,生成所述数据对应的树状解析结果;对所述合并数据集中的每条数据,将所述数据对应的子句、实体和非实体词语分别进行数据增强处理,包括:对所述合并数据集中的每条数据,基于所述数据对应的树状解析结果,对所述数据对应的子句、实体和非实体词语分别进行数据增强处理。
14、可选地,在生成所述数据对应的树状解析结果之后,还包括:根据所述数据的实体关系标注结果得到各个节点对应的标注信息,并将所述标注信息添加到所述树状解析结果的对应节点中;结合所述数据的实体关系标注结果生成所述增强数据的实体关系标注结果,包括:根据所述树状解析结果的各个节点对应的标注信息,生成所述增强数据的实体关系标注结果。
15、根据本发明实施例的另一方面,提供了一种实体关系提取的装置,包括:
16、数据集扩充模块,用于根据原始数据集的文本表述方式生成语句模板,并根据预设的实体集和所述语句模板生成扩充数据集;
17、实体关系标注模块,用于将所述原始数据集和所述扩充数据集进行合并生成合并数据集,对所述合并数据集中的每条数据进行实体关系标注,并提取每条数据对应的子句、实体和非实体词语;
18、数据增强处理模块,用于对所述合并数据集中的每条数据,将所述数据对应的子句、实体和非实体词语分别进行数据增强处理,以得到所述数据对应的增强数据,并结合所述数据的实体关系标注结果生成所述增强数据的实体关系标注结果;
19、实体关系提取模块,用于基于所述汇总数据集中每条数据对应的增强数据和所述增强数据对应的实体关系标注结果进行实体关系提取模型训练,并使用所述实体关系提取模型进行实体关系提取。
20、根据本发明实施例的又一方面,提供了一种电子设备,包括:一个或多个处理器;存储装置,用于存储一个或多个程序,当所述一个或多个程序被所述一个或多个处理器执行,使得所述一个或多个处理器实现本发明实施例所提供的实体关系提取的方法。
21、根据本发明实施例的再一方面,提供了一种计算机可读介质,其上存储有计算机程序,所述程序被处理器执行时实现本发明实施例所提供的实体关系提取的方法。
22、上述发明中的一个实施例具有如下优点或有益效果:通过根据原始数据集的文本表述方式生成语句模板,并根据预设的实体集和语句模板生成扩充数据集;将原始数据集和扩充数据集进行合并生成合并数据集,对合并数据集中的每条数据进行实体关系标注,并提取每条数据对应的子句、实体和非实体词语;对合并数据集中的每条数据,将数据对应的子句、实体和非实体词语分别进行数据增强处理,以得到数据对应的增强数据,并结合数据的实体关系标注结果生成增强数据的实体关系标注结果;基于汇总数据集中每条数据对应的增强数据和增强数据对应的实体关系标注结果进行实体关系提取模型训练,并使用实体关系提取模型进行实体关系提取的技术方案,可以通过总结常用的文本表述方式生成多个语句模板,然后通过多个语句模板和实体集生成扩充数据集,可以批量生成数据较少的关系类别对应的扩充数据集,从而实现对各种数据类型的扩充,平衡了数据类别;同时,通过对合并数据集进行数据增强处理,生成一个更大的数据集,用于模型训练,提高了模型的泛化能力和鲁棒性,提高了实体关系提取效率和准确性。
23、上述的非惯用的可选方式所具有的进一步效果将在下文中结合具体实施方式加以说明。
- 还没有人留言评论。精彩留言会获得点赞!