一种社交网络文本情感分析方法
本发明属于自然语言处理,具体涉及一种社交网络文本情感分析方法。
背景技术:
1、社交网络的兴起带来了大量用户生成的文本数据,包括情感、意见和评论。这些文本数据对于了解用户的情感倾向以及在社交媒体营销、舆情监测等方面具有重要价值。然而,随着数据规模的迅速增加,有效地分析这些文本中的情感变得愈发具有挑战性。
2、在自然语言处理领域,为了提高对文本数据的处理性能,研究者们提出了各种模型和方法。ernie模型作为一种强大的自然语言处理模型,能够融合大量的知识以提高文本表示的性能。然而,单一模型可能无法充分捕获文本的复杂情感信息。
技术实现思路
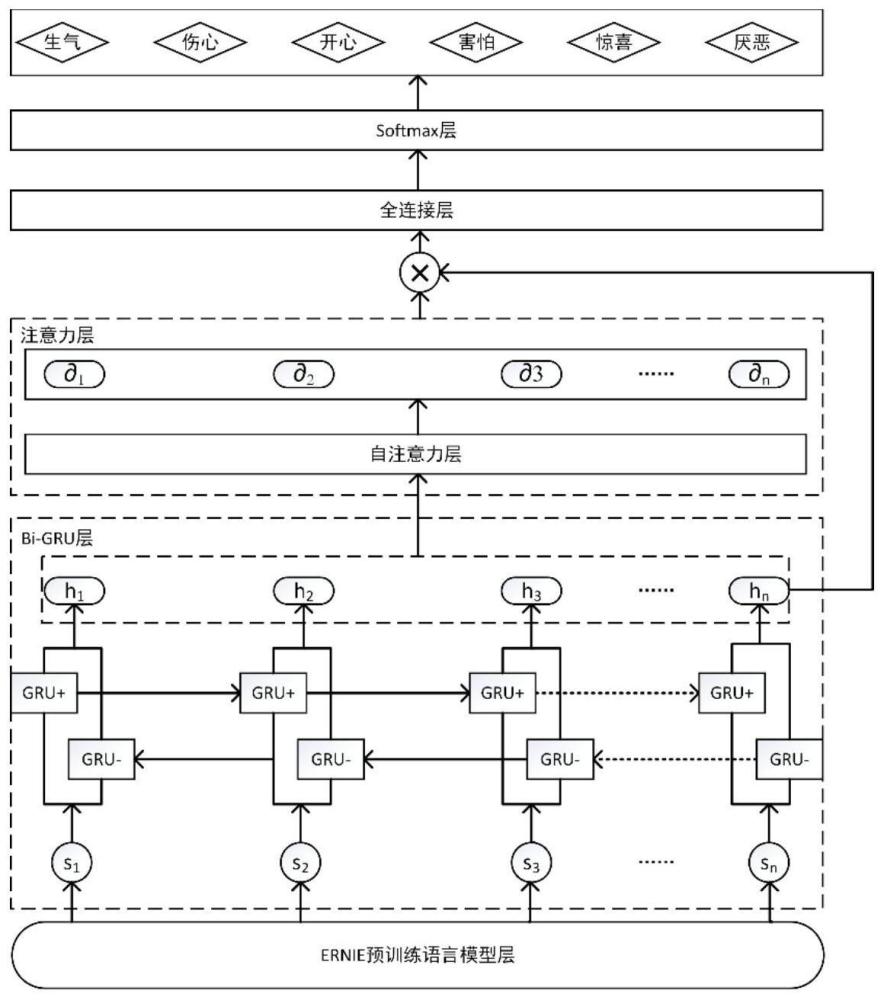
1、为解决以上现有技术存在的问题,本发明引入了bi-gru模型,一种双向循环神经网络,用于有效地捕获文本的上下文信息。通过结合ernie的知识融合能力和bi-gru的上下文建模能力,提出了一种新的情感分析方法。这种方法旨在更准确地分析社交网络文本中的情感信息,为更广泛的应用场景提供更有力的支持。
2、为实现以上现有目的,本发明的一种社交网络文本情感分析方法,该方法包括:
3、s1、获取网络文本信息,对文本信息进行预处理;
4、s2、采用预训练后的语言模型ernie对预处理后的文本数据进行词向量化,得到字向量序列;
5、s3、采用bi-gru网络层对字向量序列进行前向和后向信息汇总合并,得到最终的bi-gru模型隐含向量;
6、s4、将每个单词的隐含向量与通过自注意力层计算出的单词权重相乘,得到加权后的最终向量;
7、s5、将加权后的最终向量输入到训练后的文本情感分析模型中,得到文本的情感分类结果。
8、优选的,对文本信息进行预处理包括:对文本数据进行清洗,包括去停用词和去除换行符,统一英文数据集中英文字母的大小写,并将数据序列化。
9、优选的,采用预训练后的语言模型ernie对预处理后的文本数据进行词向量化包括:
10、s21、使用ernie模型对文本数据集t进行向量化,将情感分类的文本内容tb统一为固定长度的lmax,并将t中的每个文本tb转换为字符形式,获得字符序列t';
11、s22、将每个字符t'c分别输入到ernie的词嵌入层、位置嵌人层和对话嵌人层,得到三个向量v2、v2和v3;
12、s23、将三个向量的和输入到ernie的双向transformer层,得到一个字向量序列si;
13、s24、将所有的的字向量进行组合,得到长度为len(t)的字向量序列s。
14、优选的,采用bi-gru网络层对字向量序列进行前向和后向信息汇总合并包括:
15、s31、将字向量序列输入到网络中;
16、s32、建立两个独立的门控循环单元,通过两个独立的门控循环单元对字向量序列进行句子级的前向和后向信息建模,即前向gru利用前向隐含向量与嵌入输入词计算得到的信息,生成一个前向隐含向量;后向gru使用后向隐含向量与相应的嵌入输入词计算生成一个后向隐含向量;
17、s33、将前向和后向隐含向量融合至双向门控循环单元模型的最终隐含表示中,实现对输入序列全面而动态的上下文建模。
18、优选的,将每个单词的隐含向量与通过自注意力层计算出的单词权重相乘包括:
19、s41、构建多层感知器;
20、s42、将隐含向量和随机初始向量输入到构建的多层感知器共同学习得到新的隐藏表示ut和上下文向量uw;
21、s43、计算每个词的注意力权重;
22、s44、将每个单词的隐含向量与其通过自注意力层计算得到的权重相乘,从而得到一个经过加权的最终向量。
23、进一步的,计算每个词的注意力权重的公式为:
24、
25、其中,为隐藏表示,t为转置,uw为上下文向量。
26、优选的,文本情感分析模型进行训练包括:获取训练数据集,其中训练数据集中的数据为经过加权后的最终向量;将上一层的输出v进行融合降维处理,采用softmax函数对降维融合后的向量进行归一化处理,得到每个情感标签的近似概率值y,根据近似概率值计算模型的损失函数,并采用反向传播算法,反向计算每个神经元的误差项值,并采用adam梯度下降的优化方案对损失函数进行优化;当损失函数收敛时,完成模型的训练。
27、本发明的有益效果:
28、本发明采用了结合ernie和bi-gru神经网络的创新方法,以提高社交网络文本情感分析的效果。ernie模型的知识融合能力使其能够更好地理解文本背后的语义信息,而引入的bi-gru模型则有效地捕获文本的上下文信息。通过将这两种模型有机地结合,本发明不仅能够更全面地考虑文本信息,还能够更准确地分析用户在社交网络上表达的情感。这一综合性的方法有助于克服传统情感分析方法的局限性,提高了在社交媒体营销、舆情监测等领域的应用性能,为更智能、更精准的情感分析提供了一种创新性的解决方案;本发明采用改进的adam梯度下降的优化方案对参数进行更新,其中基于梯度范数的自适应训练历史,修正每次迭代中的梯度范数,能够在整个训练过程中保持高梯度和代表性梯度,并解决低梯度和非典型梯度问题。
技术特征:
1.一种社交网络文本情感分析方法,其特征在于,包括:
2.根据权利要求1所述的一种社交网络文本情感分析方法,其特征在于,对文本信息进行预处理包括:对文本数据进行清洗,包括去停用词和去除换行符,统一英文数据集中英文字母的大小写,并将数据序列化。
3.根据权利要求1所述的一种社交网络文本情感分析方法,其特征在于,采用预训练后的语言模型ernie对预处理后的文本数据进行词向量化包括:
4.根据权利要求1所述的一种社交网络文本情感分析方法,其特征在于,采用bi-gru网络层对字向量序列进行前向和后向信息汇总合并包括:
5.根据权利要求1所述的一种社交网络文本情感分析方法,其特征在于,将每个单词的隐含向量与通过自注意力层计算出的单词权重相乘包括:
6.根据权利要求5所述的一种社交网络文本情感分析方法,其特征在于,计算每个词的注意力权重的公式为:
7.根据权利要求1所述的一种社交网络文本情感分析方法,其特征在于,文本情感分析模型进行训练包括:获取训练数据集,其中训练数据集中的数据为经过加权后的最终向量;将上一层的输出v进行融合降维处理,采用softmax函数对降维融合后的向量进行归一化处理,得到每个情感标签的近似概率值y,根据近似概率值计算模型的损失函数,并采用反向传播算法,反向计算每个神经元的误差项值,并采用adam梯度下降的优化方案对损失函数的参数进行优化;当损失函数收敛时,完成模型的训练。
8.根据权利要求7所述的一种社交网络文本情感分析方法,其特征在于,计算每个情感标签的近似概率值的公式为:
9.根据权利要求7所述的一种社交网络文本情感分析方法,其特征在于,采用改进的adam梯度下降的优化方案对参数进行更新包括:
10.根据权利要求7所述的一种社交网络文本情感分析方法,其特征在于,模型的损失函数表达式为:
技术总结
本发明属于自然语言处理技术领域,具体涉及一种社交网络文本情感分析方法,包括:获取网络文本信息,对文本信息进行预处理;采用预训练后的语言模型ERNIE对预处理后的文本数据进行词向量化,得到字向量序列;采用Bi‑GRU网络层对字向量序列进行前向和后向信息汇总合并,得到最终的Bi‑GRU模型隐含向量;将每个单词的隐含向量与通过自注意力层计算出的单词权重相乘,得到加权后的最终向量;将加权后的最终向量输入到训练后的文本情感分析模型中,得到文本的情感分类结果;本发明采用了结合ERNIE和Bi‑GRU神经网络的创新方法,以提高社交网络文本情感分析的效果。
技术研发人员:付蔚,张明灵
受保护的技术使用者:重庆邮电大学
技术研发日:
技术公布日:2024/4/17
- 还没有人留言评论。精彩留言会获得点赞!