不完全信息下的基于自注意力强化学习方法及决策智能体
本发明属于智能体领域,尤其是涉及一种不完全信息下的基于自注意力强化学习方法及决策智能体 。
背景技术:
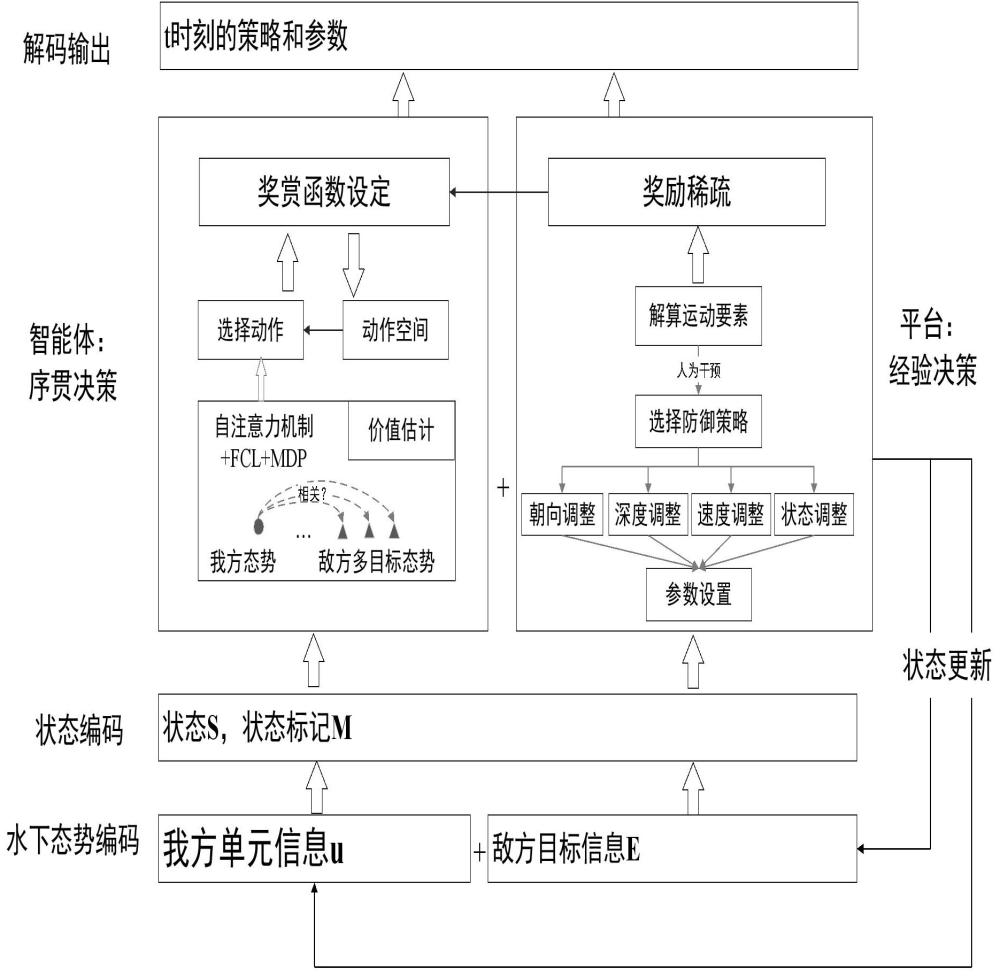
1、水下防御战术决策任务主要是水下平台根据对抗态势信息选择防御来袭目标的策略,并依据当前策略进一步规划机动参数,不断重复这一过程,直到来袭目标航程耗尽或任务结束。传统决策方法在发现目标后,依据解算目标运动要素、威胁判断等情报信息,选择防御策略、设置机动参数。在目标解算不收敛、情报信息缺失条件下,传统战术决策方法难以求解,最主要依赖指挥员依据对抗经验推理缺失信息,导致在模型计算过程中不可避免引入噪声和偏差,影响战术防御效果。如何在水声对抗环境下,基于不完全信息通过高效挖掘敌我对抗态势的全局信息和关联信息,实现从源数据到态势感知及水下平台防御来袭目标的实时序贯决策,其任务建模至关重要。如图1所示的关于水下防御战术决策的具体任务建模过程。
2、从图1可以看出,本文建模的水下防御战术决策任务主要包含四个内容:(1)水下态势信息编码:在当前时刻t分别整合编码我方水下平台的完全信息和探测得到的不完全敌方多目标信息,其中, d和 n分别指的是特征维度和探测到的目标个数; (2)状态编码:在复杂水下环境的影响下,水下平台探测信息包含海洋环境的传播损失、海洋混响、平台自噪声、辐射噪声等,且听测效果与被动声呐目标反射强度、主动声呐目标反射强度等因素有关,因此,听测到的目标信息有很多缺失信息,需要对其进行补全,本文进行补0处理得到对抗态势的状态编码,同时引入一个状态标记,本文中,黑体符号表示矩阵,非黑体符号表示矩阵中的元素。记录敌我总共 n+1个单元态势信息第 d维特征的的补码信息,其中,由于我方单元的信息完全已知,所以是一个 d维的全1矩阵,除此之外:
3、
4、其中,指的是敌方第 i个单元在 t时刻第 d维特征的缺失情况,指的是敌方第 i个单元在 t时刻第 d维的特征信息; (3)智能体的序贯决策和平台的经验决策:战场态势是一个动态持续演变的过程, 是敌我双方动态博弈的结果,而水下对抗态势错综复杂,且由于水声环境的复杂性,水下对抗情报信息经常不完全,造成敌我对抗兵力的感知和行动充满不确定性,这给依赖信息解算和领域知识的传统平台经验决策方法带来了很大困难。
技术实现思路
1、本发明所要解决的技术问题是怎样在对抗情报信息不完全的情况下实现精确度和时效性更佳的智能决策,提出了一种不完全信息下的基于自注意力强化学习方法及决策智能体。
2、为解决上述技术问题,本发明所采用的技术方案是:
3、一种不完全信息下的基于自注意力强化学习方法,包括以下步骤:
4、步骤1:获取水下平台敌我双方态势信息;
5、步骤2:对敌我双方态势信息进行整合编码和状态编码;
6、步骤3:将状态编码后的敌我双方态势信息输入智能体决策模型;
7、步骤4:对智能体的序贯决策结果进行解码并输出给水下平台进行相应的防御动作。
8、进一步地,所述智能体决策模型由离线-在线混合驱动型强化学习框架训练得到;
9、所述离线-在线混合驱动型强化学习框架包括智能体决策模型和经验决策平台,所述经验决策平台存储历史经验数据以及智能体实时决策数据形成的历史决策数据库,并根据历史决策数据库中的数据对智能体决策模型进行边训练边学习。
10、进一步地,所述智能体决策模型包括时序编码模块、第一自注意力机制模块、残差连接和归一化层、敌我双方态势分块交互模块、第二自注意力机制模块、全连接网络层。
11、进一步地,智能体决策模型的奖赏函数为:
12、
13、其中,是水下平台t时刻的位置坐标,代表被观测目标在时刻的探测半径,分别指的是水下平台和被观测目标t时刻的航向,和是被观测目标与水下平台最小安全距离和相对舷角度量的权重,t表示当前时间窗口的终点时刻,是时间窗口长度,表示归一化函数;
14、指的是水下平台防御规避过程中在给定时间窗口内相距目标自导开机扇面的最短距离,该最小安全距离越大,则奖赏值越大,如果平台进入被观测目标探测扇面,则取值为负;
15、经验决策函数根据被观测目标与水下平台在时刻的相对舷角进行[-1,1]范围内的奖赏取值,如果相对舷角为±90°,则取值为-1,代表目标朝水下平台正衡方向而来,如果保持该态势则发现水下平台概率更大、命中毁伤更大;如果相对舷角为0°或±180°,则取值为1,代表此种态势下被观测目标与水下平台保持水平,如果保持该态势,目标发现水下平台的概率会降低,且难以命中。
16、进一步地,在步骤3将编码后的敌我双方态势信息输入智能体决策模型时,还引入一个状态标记,记录敌我总共n+1个单元态势信息各维特征的的补码信息,n表示敌方被观测目标的单元数量,d表示态势信息的维度,表示我方单元的状态标记信息,分别表示第1到n个敌方被观测目标单元在t时刻的状态标记信息, 同时,由于我方单元的信息完全已知,所以是一个d维的全1矩阵,敌方n个目标t时刻的状态补码信息为:
17、
18、其中,指的是敌方第i个被观测目标在t时刻第d维特征的缺失情况,指的是敌方第i个被观测目标单元在t时刻第d维的特征信息。
19、进一步地,所述时序编码模块具体的时序编码为:
20、在己方信息和敌方信息分别拼接一个表示绝对时间步信息的特征。
21、进一步地,所述敌我双方态势分块交互模块是指,编码后的敌我双方态势信息在经过时序编码模块、第一自注意力机制层模块以及残差连接和归一化层后,
22、首先,依据原态势表征信息,将表征信息分裂为我方完全信息的态势表征和敌方不完全信息的情报表征;
23、其次,对于完全表征,连接一个全连接前向网络进行维度映射,其操作包括一个线性变换和一个relu激活输出:
24、
25、其中,分别是全连接前向网络的权重和偏差;
26、随后,将敌方不完全信息的情报表征以及输入第二自注意力表征机制进行敌我之间的交互表征;
27、最后,将交互表征信息通过全连接网络层进行维度映射。
28、进一步地,所述离线-在线混合驱动型强化学习框架的训练方法是:
29、首先,构建离线策略回放池,在训练未开始之前,采集各种态势下不同领域专家干预下的经验策片段,用于模型前期的专家经验指导;
30、其次,在模型开始训练后,一边采集智能体决策模型的序贯决策片段在增式因子的线性递增模式下将智能体决策模型的序贯决策片段按照先进先出的方式逐步代替经验决策平台中的专家经验增加至离线策略回放池中。
31、进一步地,所述经验决策平台是指根据来袭目标的态势信息进行目标解算后,与经验库进行匹配,得到经验库中的决策方案;
32、如果目标解算不收敛,引入人工干预进行信息推理,直到解算出可收敛的包括机动、速度调整、深度调整等防御策略及其对应的机动参数,转向角、定速、定深。
33、本发明还提供了一种决策智能体,其特征在于,使用一种不完全信息下的基于自注意力强化学习方法学习训练得到,将学习训练后的决策智能体使用在水下平台中进行方案决策。
34、采用上述技术方案,本发明具有如下有益效果:
35、本发明提供的一种不完全信息下的基于自注意力强化学习方法及决策智能体,在面对水下对抗态势错综复杂,对抗情报信息不完全的情况时,通过离线-在线混合驱动的强化学习框架,通过历史数据库引入游戏平台的对抗专家经验来指导模型的前期决策,再基于在线交互的学习模式驱动防御目标的后期智能决策,从而加快智能体的收敛速度,提高其类人的智能决策水平。同时针对多目标攻击问题,提出敌我态势分块交互的自注意力机制,捕捉我方完全信息下的态势表征与不完全信息下的敌方情报的对抗关联信息,实现对抗双方的态势信息融合表征及关联信息挖掘,提高智能体的态势感知能力,实现水下平台防御来袭目标的实时高效决策。
- 还没有人留言评论。精彩留言会获得点赞!