基于混合交通网络路权定价的平行控制方法、装置及介质与流程
本发明涉及混合交通网络控制领域,尤其是涉及一种基于混合交通网络路权定价的平行控制方法、装置及介质。
背景技术:
1、随着自动驾驶和车联网通信技术的不断发展,包括自动驾驶车辆(cav)和人类驾驶车辆(hdv)的混合交通网络在不久的将来将变得普遍。在这种情况下,需要一种有效的控制方法来确保hdv和cav的整个驾驶过程都能被控制。
2、在混合交通网络中,部署cav需要深入了解人类驾驶员的意图并能够适应他们的驾驶风格。然而,hdv的行为是异质的,并且受到认知限制和反应能力等主观因素的影响。研究表明,混合交通网络的完全可控性存在显著差异,主要是由于人类遵从程度的参差不齐。因此,混合交通网络的控制策略存在以下缺陷:
3、1)现有关于混合交通网络控制问题大都聚焦cav的控制策略,而缺少对hdv的控制策略,并且hdv对于控制指令的服从意识参差不齐,现有控制方案未能考虑提升hdv的服从意识。2)现有研究证明交通控制可以建模成路权交易的过程,但是他们都是在v2x环境下,通过价格或虚拟奖励控制换道cav过程,未能给出混合交通网络下精细的定价策略以实现控制。3)现有控制策略采用中心式的方法存在可扩展性差和鲁棒性差的问题,同类方案中缺乏针对混合交通场景的去中心式的控制策略。
技术实现思路
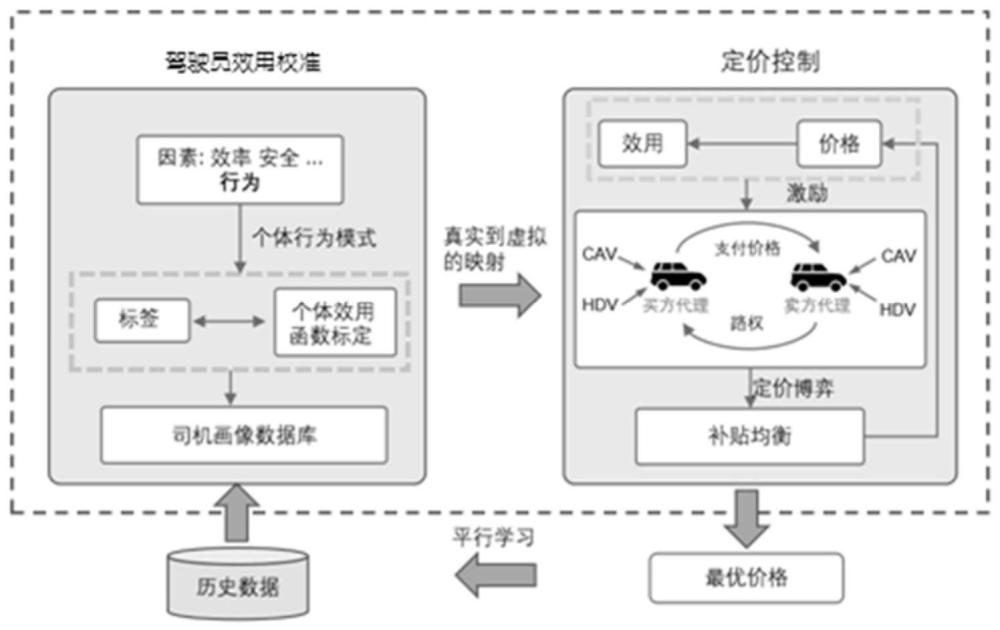
1、本发明的目的是解决混合交通场景下的交通控制问题,提供一种基于混合交通网络路权定价的平行控制方法、装置及介质,使用平行学习理论使智能代理能够接管人工驾驶车辆(hdv)和自动驾驶车辆(cav),并参与混合交通网络中的路权协商。
2、本发明的目的可以通过以下技术方案来实现:
3、一种基于混合交通网络路权定价的平行控制方法,包括以下步骤:
4、获取历史驾驶数据;
5、驾驶员效用校准:考虑驾驶员效用影响因素,对异质的驾驶员行为模式进行学习,并基于平行学习理论采用智能代理接管车辆,利用历史驾驶数据标定驾驶员效用函数;
6、定价控制:基于校准后的驾驶员效用函数对博弈论模型进行参数化,建模驾驶员的交互行为,采用动态定价机制通过效用补偿激励卖方,生成能够增加路权交易概率的最优价格,根据最优价格对应的决策策略实现混合交通网络的车辆控制;同时,将最优价格对应的驾驶员决策数据反馈至历史驾驶数据。
7、所述建模驾驶员的交互行为时,以表示主动购买路权的参与者的集合,以表示被动参与路权交易的参与者的集合,和进行谈判交互,最终可能达成路权交易,在这个过程中,用表示的行动空间,其中,c表示主动购买路权,w表示消极态度;用表示的行动空间,其中,y表示让行,r表示拒绝让行。
8、所述定价控制过程中的定价博弈包括四种情况:
9、情况一:主动购买路权的参与者选择消极态度且被动参与路权交易的参与者选择让行;
10、情况二:主动购买路权的参与者选择消极态度且被动参与路权交易的参与者选择拒绝让行;
11、情况三:主动购买路权的参与者选择主动购买路权且被动参与路权交易的参与者选择让行;
12、情况四:主动购买路权的参与者选择主动购买路权且被动参与路权交易的参与者选择拒绝让行。
13、当定价博弈处于情况一、情况二和情况四时,交易双方的驾驶员效用函数值分别为ui(ai,aj),uj(ai,aj);当定价博弈处于情况三时,交易双方的驾驶员效用函数值分别为ui(ai,aj)-γpi,uj(ai,aj)+γpj;其中,ai和aj分别表示参与者i和j所采取的行动,u为各种情况下参与者的效用函数值,pi表示参与者i需要支付的金额,即道路使用价格,pj表示当参与者j让出路权时能获得的支付金额,γ代表效用与价格之间的兑换汇率。
14、所述道路使用价格pi表示为:
15、
16、
17、其中,n(t)代表t时刻车道内的车辆数,vn(t)代表t时刻第n辆车的速度,σ(t)是根据交通状态计算的交易惩罚,α代表与交通状态惩罚相对应的系数。
18、所述定价控制过程中,交易过程中的决策制定被建模为量化响应均衡qre,qre旨在寻找参与者策略的概率分布,使得在博弈中其他参与者的行动给定的情况下,每个参与者的期望效用最大化,则最大化路权卖方j路权交易概率的最优价格为:
19、pj*=argmax(pr(ai=c,aj=y|pj)-pr(ai=c,aj=r))
20、
21、在混合策略选择中,参与者i采取行动ai的概率以及参与者j采取行动aj的概率分别由概率分布pri(ai)和prj(aj)决定,其中pri(ai)表示在可能的策略集上选择参与者i的混合策略,pri(aj)表示在可能的策略集上选择参与者j的混合策略,
22、
23、
24、每个参与者的期望效用由下式给出:
25、
26、
27、其中,pr-i(a-i)表示参与者i的对方参与者-i选择行动a-i的概率;a-i是-i的联合行动集合,pr-j(a-j)表示参与者j的对方参与者-j选择行动a-j的概率;a-j是-j的联合行动集合;λ是参与者选择中的理性程度。
28、所述路权交易过程中,驾驶员的总回报值是安全成本和效率收益的线性组合:
29、对于参与者i,其总回报表示为:
30、
31、其中,和分别是参与者i的效率收益和安全成本对应的系数,ai和aj分别表示参与者i和j所采取的行动,和分别是参与者i的效率收益和安全成本,∈i是一个符合正态分布的随机项;
32、对于参与者j,其总回报表示为:
33、
34、其中,和分别是参与者j的效率收益和安全成本对应的系数,和分别是参与者j的效率收益和安全成本,∈j是一个符合正态分布的随机项。
35、所述效率收益定义如下:
36、
37、
38、所述安全成本定义如下:
39、
40、
41、其中,c表示主动购买路权,w表示消极态度,y表示让行,r表示拒绝让行,vmax表示最大速度,vi、vj分别表示参与者i、j的当前速度,ttc表示碰撞时间。
42、一种基于混合交通网络路权定价的平行控制装置,包括存储器、处理器,以及存储于所述存储器中的程序,所述处理器执行所述程序时实现如上述所述的方法。
43、一种计算机可读存储介质,其上存储有程序,所述程序被执行时实现如上述所述的方法。
44、与现有技术相比,本发明具有以下有益效果:
45、(1)更高效:本发明将控制问题建模成基于定价机制的路权交易过程,实现更高效的控制算法;
46、(2)更真实的驾驶员行为建模:本发明采用博弈论建模车辆之间的社会交互,基于真实数据集验证了智能代理与驾驶员行为逻辑高度一致性;
47、(3)适用于混合交通网络:本发明基于对人类驾驶员的行为的深入理解,可以更好地刻画驾驶员的行为,并采用基于效用补偿的激励机制,能够有效提升驾驶员对于控制策略的服从意向,使得混合交通场景下能够解决人类驾驶车和自动驾驶车控制问题。
48、(4)可部署在去中心式的控制系统中:本发明将交通控制问题建模为路权交易问题,支持点对点之间的交易问题,可以并行处理控制问题,可以显著减少计算时间,同时避免中心式控制算法的鲁棒性差的问题。
49、(5)良好的可扩展性:本发明具有良好的可扩展性,随着交通场景的复杂性增加,本发明将可将场景都分解为路权交易问题,并进行分布式处理,能够在处理大批量路权交易时仍然保持高效。
- 还没有人留言评论。精彩留言会获得点赞!