一种基于改进粒子群算法的微网惯性常数估计方法
1.本发明涉及一种微电网的电力系统惯性常数估计方法,尤其是涉及一种基于改进粒子群算法的微网惯性常数估计方法。
背景技术:
2.惯性是电力系统的固有属性,具体表现为电力系统对扰动引起频率波动的阻抗作用,是系统稳定运行的基本条件。惯量是用来衡量电力系统惯性大小的物理量,表现为系统受到扰动所吸收或注入有功功率能力的参数。电力系统稳定运行时需要将系统频率维持在一定的范围。当系统受到扰动后,系统频率变化率受系统惯性时间常数的影响,惯性时间常数越大,系统频率变化率越小,系统频率下降得越慢,系统抗扰动能力越强。因此,惯性常数是表征系统惯量大小,体现系统稳定性的重要参数。
3.传统的惯性常数估计方法一般采用发电机摇摆方程来计算惯性常数。虽然传统的惯量估计方法准确性较高,但需要电网中大扰动的激励,例如线路短路,发电机组退出运行等,不利于电网的稳定运行,不能实现惯量的实时评估,而且适用性较低。
4.基于改进粒子群算法的微网惯性常数估计方法利用微网正常运行时的有功功率与频率变化,使用armax系统辨识,建立由发电机有功功率变化到频率变化的模型,将模型的离散函数转换为连续函数,利用改进粒子群算法降阶,由降阶结果和摆动方程的传递函数形式对比获取惯性常数。和传统惯量评估方法相比较,该方法只需利用微网正常运行时的数据就可以进行惯量评估,不需要大扰动。传统评估方法需要确定大扰动发生时刻,并且在调频过程中无法区分惯量响应与一次调频响应,而该方法在电力系统正常运行时进行惯量评估,一次调频不参与调频过程,由此可以避免一次调频对惯量评估的影响,从而提高惯量评估准确性。
技术实现要素:
5.为解决电网运行过程中新能源渗透率提高导致的电网频率安全问题,本发明可以准确反映微电网运行下惯量的动态变化,为微电网的稳定运行提供参考,可以通过实时数据更新评估结果,有利于帮助微电网预防不稳定因素以及故障发生时快速解决。其次,采用的粒子群算法拥有强大的全局搜索和局部搜索能力、良好的寻优精度和收敛速度能使测得的惯性常数更加精准,最后将其运用到微网上,这对微网的稳定运行具有重大意义。
6.本发明具体采用以下技术方案:
7.1、一种基于改进粒子群算法的微网惯性常数估计方法:包括以下步骤:
8.step1:获取微网正常运行时发电机出口侧的有功功率与频率波动。
9.step2:对有功功率和频率波动数据进行预处理,预处理包括以下步骤:
10.(1)标幺化,除以各自的基准值,将信号从有名值转化为标幺值;
11.(2)去均值,对于仿真系统数据,通过去均值的方法去除信号的直流分量;
12.(3)预滤波,对信号进行预滤波,从而滤除影响惯性常数辨识的高频分量;
13.(4)重复采样,为了防止执行辨识程序时数值不稳定,将信号的采样率降低再重新采样。
14.step3:构建armax辨识模型,并求得辨识模型的离散采样函数;
15.armax辨识模型其结构如下:
16.y(k)+a1y(k-1)+a2y(k-2)+
…
+a
na
y(k-na)
17.=b1u(k-1)+b2u(k-2)+
…
+b
nb
u(k-nb)
18.+e(k)+c1e(k-1)+c2e(k-2)+
…
+c
nc
e(k-nc)
19.其中k=n+1,n+2,
…
,t,n=max{na,nb,nc},y(k)表示系统k时刻的输出,u(k)表示系统k时刻的输入,e(k)表示噪声项。
20.armax辨识模型由参数向量θ确定:
21.θ=[a1,a2,
…
,a
na
,b1,b2,
…
,b
nb
,c1,c2,
…
,c
nc
]
[0022]
其中na是自回归模型的阶数,nb是输入模型的阶数,nc是移动平均模型的阶数,a1…ana
,b1…bnb
,c1…cnc
为所需求解的辨识模型的系数;
[0023]
所述armax辨识模型是一个为多项式模型,可以表示为传递函数的形式:
[0024][0025]
多项式a(q),b(q),c(q)分别为:
[0026]
a(q)=1+a1q-1
+
…
+a
na
q-na
[0027]
b(q)=b1q-1
+
…
+b
nb
q-nb
[0028]
c(q)=1+c1q-1
+
…
+c
nc
q-nc
[0029]
其中q-1
是一个后向移位算子;
[0030]
armax辨识模型由两部分组成,确定性部分由传递函数b(q)/a(q)描述,其表示系统对一个已知输入信号的响应;随机性部分由传递函数c(q)/a(q)描述,其表示不可测的噪声对确定性部分状态的影响。
[0031]
在辨识armax模型时,首先需要确定模型的阶数,模型的阶数足够大才能保证系统的动态特性,但也不能太大导致模型过拟合。在惯性常数辨识时,可以设置一个较小的搜索范围,辨识得到一个低阶模型。尽管辨识模型的阶数会比实际系统的阶数低,但足以保证系统惯量响应的动态特性。通常可以将模型的阶数设置在10以内,并采用aic准则确定模型的阶数,aic准则函数如下:
[0032][0033]
式中,表示残差方差,n表示信号长度,p(p=na+nb+nc)表示模型阶数。aic值取最小时对应的阶数即为armax模型的阶数。
[0034]
step4:对armax模型进行参数求解,模型阶数确定后,可采用最小二乘法求解armax模型的参数θ。为了确定预测误差,构建了如下的伪线性预测模型:
[0035]
[0036]
式中表示系统k时刻的预测输出;由于噪声项是无法直接测量的,故是一个伪测量向量,表示如下:
[0037][0038]
u(k-1),
…
,u(k-nb)
[0039]
e(k-1|θ),
…
,e(k-nc|θ)]
t
[0040]
k时刻的预测误差定义为:
[0041][0042]
则参数向量θ加权最小二乘估计的准则函数定义为:
[0043][0044]
其中
[0045][0046][0047][0048]
这里,e(k|θ)是损失函数,λ
t-k
是k时刻预测误差的权值。λ
t-k
决定了数据对当前参数估计值的影响程度。通常,旧数据无法反映当前系统的动态,因此λ
t-k
对旧数据赋予了更小的权重。λ叫做遗忘因子,它是一个小于1的正数。λ值越小,旧数据的权重越小,即旧数据被遗忘得越多。较小的λ使得算法能更快跟踪系统的变化,同时也增大了参数估计值的方差。
[0049]
为求解参数θ的估计值,只需极小化准则函数j(θ)。根据递推解法可以求得加权最小二乘递推算法:
[0050][0051]
递推计算需要事先选择初始参数和p(0),根据一批数据利用非递推算法,预先求得
[0052][0053][0054]
置p(0)=p(l0),式中l0为初始数据长度。
[0055]
step5:利用matlab里的d2c函数将离散函数转换成高阶传递函数形式,其代码具体命令如下:
[0056]
构建离散系统模型的命令函数如下:
[0057]
gz=tf(num,deb,ts),其中ts指采样时间,num,den为离散系统模型的分子和分母系数向量;或者gz=zpk(z,p,k,ts),其中ts指采样时间,z、p、k分别为离散模型的零、极点及增益;
[0058]
将离散函数转换为连续函数的命令函数如下:
[0059]
g=d2c(gz,method),将采样系统gz转换为连续系统g,method=’zod’、’tusin’、’prewarp’、’matched’中的一种。
[0060]
step6:aibpso算法原理如下:
[0061]
(1)自适应粒子群算法机理
[0062]
①
采用非线性的动态惯性权重系数,如下定义为:
[0063][0064]
在公式中,w
min
、w
max
最小和最大值是权重的最大值和最小值。f是粒子的当前目标函数值,f
avg
和f
min
是所有粒子的平均目标值和最小目标值。随粒子的目标函数值而自动改变的权重称为自适应权重。
[0065]
②
当粒子位置超过边界时,重新进行初始化即重新更新粒子的位置和速度。
[0066][0067]
其中,x
minn
为粒子位置下界,x
maxn
为粒子位置上界,v
maxn
为速度最大更新步长。
[0068]
(2)双态粒子群算法原理
[0069]
为了解决粒子群算法中的停滞现象,根据种群进化因子可以将群体规模为m的粒子群分为两个不同模态行为的特征子群,探索群体与捕食群体。这样整个粒子群不会因为遇到局部极值点而停止搜索,群体在整个搜索过程中按照探索群体与捕食群体的比例r2:
r1有充足的能量在解空间中进行搜索。
[0070]
①
捕食状态,当捕食状态下粒子群行为与传统的粒子群算法一致时,为了减少进化迭代过程中粒子离开搜索空间,通常作相应限定更新粒子的位置与速度。
[0071]
②
探索状态,在优化的过程中,如果没有更好的解,这说明整个群体已经陷入局部极值点,部分粒子会分散,进而探索新的解空间。然后根据进化的因子将一部分的分散粒子转为探索状态。当粒子从“捕食”状态转变为“探索状态”时,粒子在搜索空间中被随机初始化:
[0072][0073]
其速度更新公式如下:
[0074]
vk(t+1)=w
·
sign(r)
·
vk+c1·
r()(pi(t)-xk(t))+c2·
r()(pg(t)-xk(t))+c3·
u(0,1)(xk(t)-hpg)
[0075]
xi(t+1)=xi(t)+vi(t+1)
[0076][0077]
式中:r(),c3为(0,1)之间的随机数,r为随机数,sign(r)为符号函数,u(0,1)为高斯分布函数。hpg为当前探索种群汇中最优粒子所在位置。具有双态动态行为的粒子群的优点就是在整个搜索的过程中不会因为遇到局部极值点而停止搜索,而是会有足够动量在搜索空间中进行搜索,所以能提高找到全局最优解的概率。种群进化加速因子定义如下:
[0078][0079]
gbesti为第i代种群最优适应度值,α∈(0,1)为平滑系数,防止分母为0,f为进化因子。当f=0时进化停止;当f》0时,群体为进化状态;当f》1时群体进化加速;当f《1时群体进化减速,处于减速状态的群体如果还没找到全局最优解,那么微粒群体会按比例分出一部分粒子群转为探索状态来寻求更大解空间。
[0080]
(3)粒子免疫优化
[0081]
多数粒子在进化后期易集中收敛于局部极值点,且粒子本身没有适应性变异能力,群体后半部分寻优能力下降,容易收敛于局部极值点,很难找到全局最优极值。引入人工免疫系统中的选择替换机制,如果群体粒子连续迭代特定代数后,群体中的最优值没有明显变优,则群体就自行进行免疫操作。
[0082]
①
在粒子进行免疫的过程中,计算每个个体与个体i的距离,同时计算出个体最优的和:
[0083][0084]
其中:d(j)为个体间的距离,p
sum
为个体最优的和,p(i)为粒子适应度值。
[0085]
②
若计算出的粒子个体间的距离小于某一精度时,则进行计算替换:
[0086][0087]
其中,a为(0,1)之间的随机数,m为群体个体数目,num为与第i个个体距离小于某一精度的个数。pr(i)为替换概率,pf(i)为适应度概率,pd(i)为粒子个体浓度。
[0088]
③
当计算出的替换概率大于某一替换概率精度值时,粒子位置将得到更新:
[0089]
x(t+1)=x(t)
new
+rand()
[0090]
改进的粒子群aibpso算法过程如下:
[0091]
(1)随机初始化粒子的位置和速度;
[0092]
(2)根据每个粒子的初始适应值,保留初始最佳位置和最佳适应度值;
[0093]
(3)更新粒子的位置和速度,并评价各粒子适应度和群体进化加速因子,同时更新惯性权重;
[0094]
(4)将粒子群的适应度值排序,一方面让性能较好的部分按捕食状态行动,另一方面将其余粒子按探索状态行动,并更新粒子的位置与速度,各粒子当前适应度值和粒子历史最优适应度值对比,更新粒子最优适应度值;
[0095]
(5)粒子进行免疫过程时,计算每个个体与个体i的距离,并计算个体最优的和,若计算出的个体之间的距离小于某一精度时再计算替换概率。随后若计算出的替换概率大于某一替换概率精度值时,粒子的位置更新并输出结果。
[0096]
step7:利用改进的粒子群算法将高阶传递函数降为一阶传递函数,其模型降阶的过程描述为用一个低阶的gr(s)模型去类似逼近高阶模型g(s),当匹配误差足够小,那么低阶系统被看作是高阶系统的降阶模型;
[0097]
将模型降阶问题转化为以下的优化问题:
[0098][0099]
aibpso的优化变量x由4个参数基因构成,采用实数编码,x=[a0,a1,a2,a3,τ],评价函数用j,如下所示:
[0100][0101]
其中c(t)和cr(t)为g(s)和gr(s)的laplace变换函数,ts为过渡时间。
[0102]
step8:关于同步发电机的摇摆方程表示如下:
[0103][0104]
式中,h
in
、δf、pm、pe、d
in
和f分别为惯性常数、电网频率变化、机械功率、电磁功率、阻尼系数和电频率。上式也可转换为增量形式:
[0105][0106]
式中h
in
、δf、δpm、δpe和d
in
分别为惯性时间常数、电网频率变化、机械功率变化、电磁功率变化和阻尼系数。对上式做拉普拉斯变换可以将转子运动方程转化为一个一阶传
递函数:
[0107][0108]
将高阶传递函数由粒子群算法降为一阶的传递函数与上式进行系数对比可以获得阻尼系数d
in
和惯性常数h
in
。
[0109]
本发明的有益效果:
[0110]
通过本发明引进一种基于改进粒子群算法的微网惯性常数估计方法,涉及微电网领域,可以准确反映微电网运行下惯量的动态变化,为微电网的稳定运行提供参考,可以通过实时数据更新评估结果,有利于帮助微电网预防不稳定因素以及故障发生时快速解决。其次,aibpso算法加强了平衡全局探索能力和局部开发能力,丰富了粒子群体的多样性,其大范围变异能力可改善收敛速度,避免陷入局部极值点,从而能较好的找到全局极值点,使测得的惯性常数更加精准,最后将其运用到微网上,这对微网的稳定运行具有重大意义。
附图说明
[0111]
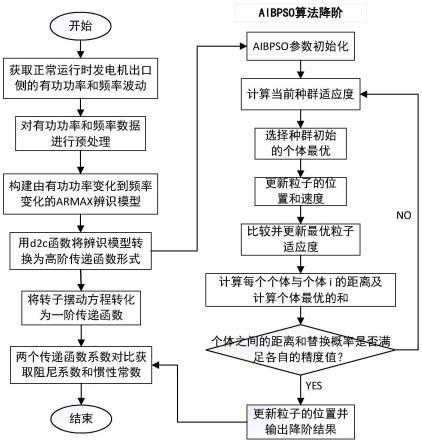
图1为基于改进粒子群算法的微网惯性常数估计方法流程框图。
具体实施方式
[0112]
下面结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述。
[0113]
如图1所示,本发明的一个实施算例,公开了一种基于改进粒子群算法的微网惯性常数估计方法,包括以下步骤:
[0114]
step1:获取微网正常运行时发电机出口侧的有功功率与频率波动。
[0115]
step2:对有功功率和频率波动数据进行预处理,预处理包括以下步骤:
[0116]
(1)标幺化,除以各自的基准值,将信号从有名值转化为标幺值;
[0117]
(2)去均值,对于仿真系统数据,通过去均值的方法去除信号的直流分量;
[0118]
(3)预滤波,对信号进行预滤波,从而滤除影响惯性常数辨识的高频分量;
[0119]
(4)重复采样,为了防止执行辨识程序时数值不稳定,将信号的采样率降低再重新采样。
[0120]
step3:构建armax辨识模型,并求得辨识模型的离散采样函数;
[0121]
armax辨识模型其结构如下:
[0122]
y(k)+a1y(k-1)+a2y(k-2)+
…
+a
na
y(k-na)
[0123]
=b1u(k-1)+b2u(k-2)+
…
+b
nb
u(k-nb)+e(k)+c1e(k-1)+c2e(k-2)+
…
+c
nc
e(k-nc)
[0124]
其中k=n+1,n+2,
…
,t,n=max{na,nb,nc},y(k)表示系统k时刻的输出,u(k)表示系统k时刻的输入,e(k)表示噪声项。
[0125]
armax辨识模型由参数向量θ确定:
[0126]
θ=[a1,a2,
…
,a
na
,b1,b2,
…
,b
nb
,c1,c2,
…
,c
nc
]
[0127]
其中na是自回归模型的阶数,nb是输入模型的阶数,nc是移动平均模型的阶数,a1…ana
,b1…bnb
,c1…cnc
为所需求解的辨识模型的系数;
[0128]
所述armax辨识模型是一个为多项式模型,可以表示为传递函数的形式:
[0129][0130]
多项式a(q),b(q),c(q)分别为:
[0131]
a(q)=1+a1q-1
+
…
+a
na
q-na
[0132]
b(q)=b1q-1
+
…
+b
nb
q-nb
[0133]
c(q)=1+c1q-1
+
…
+c
nc
q-nc
[0134]
其中q-1
是一个后向移位算子;
[0135]
armax辨识模型由两部分组成,确定性部分由传递函数b(q)/a(q)描述,其表示系统对一个已知输入信号的响应;随机性部分由传递函数c(q)/a(q)描述,其表示不可测的噪声对确定性部分状态的影响。
[0136]
在辨识armax模型时,首先需要确定模型的阶数,模型的阶数足够大才能保证系统的动态特性,但也不能太大导致模型过拟合。在惯性常数辨识时,可以设置一个较小的搜索范围,辨识得到一个低阶模型。尽管辨识模型的阶数会比实际系统的阶数低,但足以保证系统惯量响应的动态特性。通常可以将模型的阶数设置在10以内,并采用aic准则确定模型的阶数,aic准则函数如下:
[0137][0138]
式中,表示残差方差,n表示信号长度,p(p=na+nb+nc)表示模型阶数。aic值取最小时对应的阶数即为armax模型的阶数。
[0139]
step4:对armax模型进行参数求解,模型阶数确定后,可采用最小二乘法求解armax模型的参数θ。为了确定预测误差,构建了如下的伪线性预测模型:
[0140][0141]
式中表示系统k时刻的预测输出;由于噪声项是无法直接测量的,故是一个伪测量向量,表示如下:
[0142][0143]
u(k-1),
…
,u(k-nb)
[0144]
e(k-1|θ),
…
,e(k-nc|θ)]
t
[0145]
k时刻的预测误差定义为:
[0146][0147]
则参数向量θ加权最小二乘估计的准则函数定义为:
[0148]
[0149]
其中
[0150][0151][0152][0153]
这里,e(k|θ)是损失函数,λ
t-k
是k时刻预测误差的权值。λ
t-k
决定了数据对当前参数估计值的影响程度。通常,旧数据无法反映当前系统的动态,因此λ
t-k
对旧数据赋予了更小的权重。λ叫做遗忘因子,它是一个小于1的正数。λ值越小,旧数据的权重越小,即旧数据被遗忘得越多。较小的λ使得算法能更快跟踪系统的变化,同时也增大了参数估计值的方差。
[0154]
为求解参数θ的估计值,只需极小化准则函数j(θ),根据递推解法可以求得加权最小二乘递推算法:
[0155][0156]
递推计算需要事先选择初始参数和p(0),根据一批数据利用非递推算法,预先求得
[0157][0158][0159]
置p(0)=p(l0),式中l0为初始数据长度。
[0160]
step5:利用matlab里的d2c函数将离散函数转换成高阶传递函数形式,其代码具体命令如下:
[0161]
构建离散系统模型的命令函数如下:
[0162]
gz=tf(num,deb,ts),其中ts指采样时间,num,den为离散系统模型的分子和分母系数向量;或者gz=zpk(z,p,k,ts),其中ts指采样时间,z、p、k分别为离散模型的零、极点
及增益;
[0163]
将离散函数转换为连续函数的命令函数如下:
[0164]
g=d2c(gz,method),将采样系统gz转换为连续系统g,method=’zod’、’tusin’、’prewarp’、’matched’中的一种。
[0165]
step6:aibpso算法原理如下:
[0166]
(1)自适应粒子群算法机理
[0167]
①
采用非线性的动态惯性权重系数,如下定义为:
[0168][0169]
在公式中,w
min
、w
max
最小和最大值是权重的最大值和最小值。f是粒子的当前目标函数值,f
avg
和f
min
是所有粒子的平均目标值和最小目标值。随粒子的目标函数值而自动改变的权重称为自适应权重。
[0170]
②
当粒子位置超过边界时,重新进行初始化即重新更新粒子的位置和速度。
[0171][0172]
其中,x
minn
为粒子位置下界,x
maxn
为粒子位置上界,v
maxn
为速度最大更新步长。
[0173]
(2)双态粒子群算法原理
[0174]
为了解决粒子群算法中的停滞现象,根据种群进化因子可以将群体规模为m的粒子群分为两个不同模态行为的特征子群,探索群体与捕食群体。这样整个粒子群不会因为遇到局部极值点而停止搜索,群体在整个搜索过程中按照探索群体与捕食群体的比例r2:r1有充足的能量在解空间中进行搜索。
[0175]
①
捕食状态,当捕食状态下粒子群行为与传统的粒子群算法一致时,为了减少进化迭代过程中粒子离开搜索空间,通常作相应限定更新粒子的位置与速度。
[0176]
②
探索状态,在优化的过程中,如果没有更好的解,这说明整个群体已经陷入局部极值点,部分粒子会分散,进而探索新的解空间。然后根据进化的因子将一部分的分散粒子转为探索状态。当粒子从“捕食”状态转变为“探索状态”时,粒子在搜索空间中被随机初始化:
[0177][0178]
其速度更新公式如下:
[0179]
vk(t+1)=w
·
sign(r)
·
vk+c1·
r()(pi(t)-xk(t))+c2·
r()(pg(t)-xk(t))+c3·
u(0,1)(xk(t)-hpg)
[0180]
xi(t+1)=xi(t)+vi(t+1)
[0181][0182]
式中:r(),c3为(0,1)之间的随机数,r为随机数,sign(r)为符号函数,u(0,1)为高
斯分布函数。hpg为当前探索种群汇中最优粒子所在位置。具有双态动态行为的粒子群的优点就是在整个搜索的过程中不会因为遇到局部极值点而停止搜索,而是会有足够动量在搜索空间中进行搜索,所以能提高找到全局最优解的概率。种群进化加速因子定义如下:
[0183][0184]
gbesti为第i代种群最优适应度值,α∈(0,1)为平滑系数,防止分母为0,f为进化因子。当f=0时进化停止;当f》0时,群体为进化状态;当f》1时群体进化加速;当f《1时群体进化减速,处于减速状态的群体如果还没找到全局最优解,那么微粒群体会按比例分出一部分粒子群转为探索状态来寻求更大解空间。
[0185]
(3)粒子免疫优化
[0186]
多数粒子在进化后期易集中收敛于局部极值点,且粒子本身没有适应性变异能力,群体后半部分寻优能力下降,容易收敛于局部极值点,很难找到全局最优极值。引入人工免疫系统中的选择替换机制,如果群体粒子连续迭代特定代数后,群体中的最优值没有明显变优,则群体就自行进行免疫操作。
[0187]
①
在粒子进行免疫的过程中,计算每个个体与个体i的距离,同时计算出个体最优的和:
[0188][0189]
其中:d(j)为个体间的距离,p
sum
为个体最优的和,p(i)为粒子适应度值。
[0190]
②
若计算出的粒子个体间的距离小于某一精度时,则进行计算替换:
[0191][0192]
其中,a为(0,1)之间的随机数,m为群体个体数目,num为与第i个个体距离小于某一精度的个数。pr(i)为替换概率,pf(i)为适应度概率,pd(i)为粒子个体浓度。
[0193]
③
当计算出的替换概率大于某一替换概率精度值时,粒子位置将得到更新:
[0194]
x(t+1)=x(t)
new
+rand()
[0195]
改进的粒子群aibpso算法过程如下:
[0196]
(1)随机初始化粒子的位置和速度;
[0197]
(2)根据每个粒子的初始适应值,保留初始最佳位置和最佳适应度值;
[0198]
(3)更新粒子的位置和速度,并评价各粒子适应度和群体进化加速因子,同时更新惯性权重;
[0199]
(4)将粒子群的适应度值排序,一方面让性能较好的部分按捕食状态行动,另一方面将其余粒子按探索状态行动,并更新粒子的位置与速度,各粒子当前适应度值和粒子历史最优适应度值对比,更新粒子最优适应度值;
[0200]
(5)粒子进行免疫过程时,计算每个个体与个体i的距离,并计算个体最优的和,若计算出的个体之间的距离小于某一精度时再计算替换概率。随后若计算出的替换概率大于
某一替换概率精度值时,粒子的位置更新并输出结果。
[0201]
step7:利用改进的粒子群算法将高阶传递函数降为一阶传递函数,其模型降阶的过程描述为用一个低阶的gr(s)模型去类似逼近高阶模型g(s),当匹配误差足够小,那么低阶系统被看作是高阶系统的降阶模型。
[0202]
将模型降阶问题转化为以下的优化问题:
[0203][0204]
aibpso的优化变量x由4个参数基因构成,采用实数编码,x=[a0,a1,a2,a3,τ],评价函数用j,如下所示:
[0205][0206]
其中c(t)和cr(t)为g(s)和gr(s)的laplace变换函数,ts为过渡时间。
[0207]
step8:关于同步发电机的摇摆方程表示如下:
[0208][0209]
式中,h
in
、δf、pm、pe、d
in
和f分别为惯性常数、电网频率变化、机械功率、电磁功率、阻尼系数和电频率。上式也可转换为增量形式:
[0210][0211]
式中h
in
、δf、δpm、δpe和d
in
分别为惯性时间常数、电网频率变化、机械功率变化、电磁功率变化和阻尼系数。对上式做拉普拉斯变换可以将转子运动方程转化为一个一阶传递函数:
[0212][0213]
将高阶传递函数由粒子群算法降为一阶的传递函数与上式进行系数对比可以获得阻尼系数d
in
和惯性常数h
in
。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1