用于解码非二进制码的方法和对应的解码装置与流程
本发明涉及电信和数据存储领域中的纠错码的解码。更具体地,本发明涉及一种用于非二进制低密度奇偶校验(LDPC)码的解码方法和对应的解码器。
背景技术:
使用中等硅面积的用于GF(q)中的非二进制低密度奇偶校验(NB-LDPC)码的高吞吐量解码器的设计是具有挑战性的问题,其既需要低复杂度算法又需要高效的体系结构。
从q元和积(QSPA)[1]、[2]、[3]、[4](例如扩展的最小和(EMS)[5]以及最小最大(Min-Max)[7])导出的算法涉及在它们实施了奇偶校验节点更新等式的校验节点单元(CNU)中的高复杂度。特别地,由于大的固有延迟,所以EMS或Min-Max的不同版本的CNU需要很多比较,这降低了最大可达到的吞吐量。这种高延迟是瓶颈,尤其针对高速NB-LDPC码(R>0.8)的解码,其中奇偶校验节点度dc采用大的值。使用足够的硬件并行性,CNU[8]、[10]的类似向前向后实施的技术或气泡检查算法[9]可以减少dc个时钟周期的最小值的延迟,但这仍不足以达到非常高的吞吐量。因此,基于EMS或Min-Max算法[13]、[14]、[15]的体系结构可以实现的编码增益接近于QSPA,但是以低解码吞吐量为代价。
除了类似EMS或Min-Max的算法,其他解决方案已在文献中被提出,相比QSPA而言具有以较大的性能损失为代价而大大降低解码复杂度的目的。可以实现高吞吐量并且同时使用小的芯片面积的体系结构在奇偶校验节点更新期间仅计算非常小的一组奇偶校验等式。多数逻辑可解码(MD)算法[11]和广义位翻转解码算法(GBFDA)[12]已经遵循了这种方法。相比QSPA而言这些简单算法以及相关联的体系结构[21]、[17]、[18]遭受了不可忽略的性能损失,取决于算法和LDPC码在0.7dB至几dB之间。这种性能损失是由于在GBFDA和MD的CNU中使用的软信息的缺乏而造成,并且无法使用大量的解码迭代[18]来恢复。此外,GBFDA和MD倾向于针对具有中等变量节点度(在GBFDA的情况中dv>3)的码更有效,并且针对超稀疏dv=2的NB-LDPC码没有很好地执行,其已被识别为重要的一类非二进制码[6]。
技术实现要素:
本发明允许提高非二进制低密度奇偶校验(NB-LDPC)的解码的性能。
为此,本发明涉及一种用于解码在大小q的有限域中定义的非二进制低密度奇偶校验码的方法,所述码可以被显示在二分图中,包括至少一个变量节点Vn,n=0,…,N–1以及至少一个校验节点Cm,m=0,…,M–1,所述方法包括:针对It次解码迭代的每次迭代j,以下步骤,包括:
连接至校验节点Cm的每个变量节点Vn被配置为用于确定最可靠符号以及为至少第p个最可靠符号的至少一个符号,其中p≥2以获得dc个最可靠符号的向量;
每个校验节点Cm被配置为用于:
基于由在所述二分图中连接至其的所述变量节点传递的dc个最可靠符号的向量而确定要被投票的第一符号
基于被定义为具有一个限制的dc个符号的组合的L+1个测试向量的列表而确定要被投票的i=1,…,L第二符号的列表,根据所述限制这些dc个符号的至多η个是具有p≥2的第p个最可靠符号并且这些dc个符号的至少dc–η个是最可靠符号
根据本发明的方法可以具有以下特征之一:
每个变量节点被配置为用于确定最可靠符号和第二最可靠符号及其对应的外在可靠性以使得在校验节点处L+1个测试向量的列表在和之间的差值是最小的至多η≤L个位置中通过由第二最可靠符号替代符号而建立。
针对η≤L,其包括以下步骤,所述步骤包括排序器单元被配置为将外在可靠性的差值从最高值到最低值进行排序以获得L个排序索引n的序列所述序列包括η个位置,其中在所述L+1个测试向量中由替代。
每个变量节点还被配置为用于使用相应的幅度投票v0、v2对的投票和的投票进行计数来计算来自校验节点的内在信息
其包括在It次解码迭代之前初始化步骤包括以下子步骤:
确定在N个非二进制噪声符号的序列中的第n符号的LLR向量Ln=(Ln[0],Ln[1],…,Ln[q-1]);
将APP向量的向量初始化为所述LLR向量Ln并且将矩阵初始化为全零矩阵,所述矩阵为来自校验节点m的内在信息。
视为输入所述LLR向量和向量的每个变量节点通过函数F1来结合先前向量投票符号和以及投票幅度v0、v1以获得定义为内在信息的向量。
所述函数F1是由投票符号和指示出的索引处的所述先前向量的值与所述投票幅度v0、v1的简单求和。
所述LLR向量和向量通过函数F2来结合(A5.1,A5.2)先前的向量所述投票符号和以及所述投票幅度v0、v1以获得向量
所述函数F2是由所述投票符号和指示出的索引处的先前的向量的值与所述投票幅度v0、v1的简单求和。
本发明还涉及一种解码装置,包括至少一个变量节点Vn以及至少一个校验节点Cm,根据本发明,所述解码器被配置为实施用于解码在大小q的有限域中定义的非二进制低密度奇偶校验码的方法。
本发明的解码装置可以具有以下特征之一:
其被配置为用于借由L个处理单元来实施校验节点操作,所述L个处理单元被动态地配置来计算其中i=1,…,L,所述L个处理单元的每一个处理单元共享对应于符号并且对应于所述码的系数的3xdc个输入,所述每个处理单元的输入借由2xdc个GF乘法器和2xdc个GF加法器而结合,所述处理单元包括必要于计算L个不同校验子作为中间步骤的所有逻辑以及取决于所述处理单元的速度的从0变化至log2(dc)+2的管道阶段的变量数。
其被配置为用于实施本发明的方法,并且包括:i)一堆存储器,其存储了具有i=0,…,L个符号,ii)q个处理器,其具有将所述符号(其中i=0,…,L)与Galois域的q个元素进行比较并且确定对应于那个符号的投票的幅度所需的逻辑;以及iii)实施了函数F1和F2的q个单元格,其中一堆存储器被实施为L个RAM存储器或一堆L个寄存器,处理器被实施为log2(q)位的L-XNOR门以及1位的L-OR门以将输入符号(符号具有i=0,…,L)与q个Galois域元素进行比较并且确定所述投票的幅度,所述单元格包括必要于实施F1和F2以及用于和的存储资源的逻辑。
其包括排序器单元,其被配置为用于根据本发明的方法来获得L个排序索引n的序列所述排序器单元包括基数L的至少一个子处理器,其中每个子处理器包括:i)比较器的一个阶段,其被配置为用于执行所述输入的所有可能的组合;ii)多个加法器和多个NOT门,其被配置为计算与相同输入相关联的不同比较器的输出信号的总和,所述加法器被配置为用于检查针对所述输入的每一个输入的大于或小于的条件被满足了多少次;iv)多个逻辑门,其被配置为用于实施L个不同掩饰,其允许根据由所述加法器的输出提供的信息对所述输入进行排序,逻辑门为XNOR门、OR门和AND门。
本发明通过如在EMS和Min-Max中完成的利用GBFDA操作的低复杂度并且在CNU中引入了软信息来允许实现高吞吐量和编码增益这二者尽可能地接近QSPA以提高编码增益。
ES-GBFDA CNU的核心思想是使用对从最可靠的Galois域值获得的符号的硬判决来计算校验子,并且声明满足了奇偶校验的硬判决符号的投票。该投票然后被传播到符号节点并且在存储器中沿着解码迭代被累积。
与ES-GBFDA相反,本发明不仅考虑了校验子计算中的最可靠的符号,还考虑了至少第二最可靠的符号(在每个传入消息中)。通过这样做,扩展的信息集可用于奇偶校验节点更新,并且这允许引入由CNU执行的弱和强投票的概念,并且被传播到符号节点存储器。通过这个特征,每个变量节点可以接收两种投票,其幅度可以被调整为产生所述投票的校验子的可靠性。
出于这个理由,本发明的解码方法可以被称为多投票符号翻转解码器(MV-SF)。
在MV-SF CNU处,我们称测试向量为从每个传入消息的最可靠符号和第二最可靠符号获取的符号集合。
本发明引入了一些额外的软信息并且扩大了考虑过的测试向量的列表,因此,提高了解码性能。同时,每个额外的测试向量的CNU的复杂度与GBFDA相同,其给了本发明的方法控制性能/复杂度权衡的好的特性:考虑更多的测试向量,则性能更好,并且考虑较少的测试向量,则吞吐量更好。
作为示例,在GF(32)上的(N=837,K=723)NB-LDPC码上与ES-GBFDA相比具有四倍更多测试向量的解码器示出了与GBFDA相比的0.44dB的编码增益,并且与Min-Max相比仅仅具有0.21dB的性能损失。此外,相关联的体系结构可以以小于两倍的面积增加而达到近似于ES-GBFDA[18]的吞吐量,而不是如从直接体系结构映射所预期那样的四倍的面积增加。
本发明通过创建增加了在校验节点更新中的软信息量的测试向量的列表而提高了ES-GBFDA的编码增益。变量节点还被修改以在涉及计算中的投票中引入不同的幅度,其中目的在于区分投票是由最可靠的信息产生还是由最可靠符号和第二最可靠符号这二者产生。使用本发明,减少了ES-GBFDA与Min-Max或EMS之间的性能的差距。
源于本发明的方法,提出了一种解码器的高吞吐量体系结构。所需的面积比ES-GBFDA的面积少L/2倍,其中L为测试向量的列表大小。这一事实表明了体系结构的优化,其没有增加其面积L倍,这是由于那将是直接映射解决方案的情况。相比最好的Min-Sum与Min-Max体系结构而言,即使高估面积,本发明也达到至少27%的更多效率(吞吐量/面积),仅具有0.21dB性能损失的成本。基于GBFDA的本发明可以达到近似EMS和Min-Max的性能,但具有更高吞吐量的优势。
附图说明
本发明的其他特征和优点将参考附图出现在下面的描述中,其中:
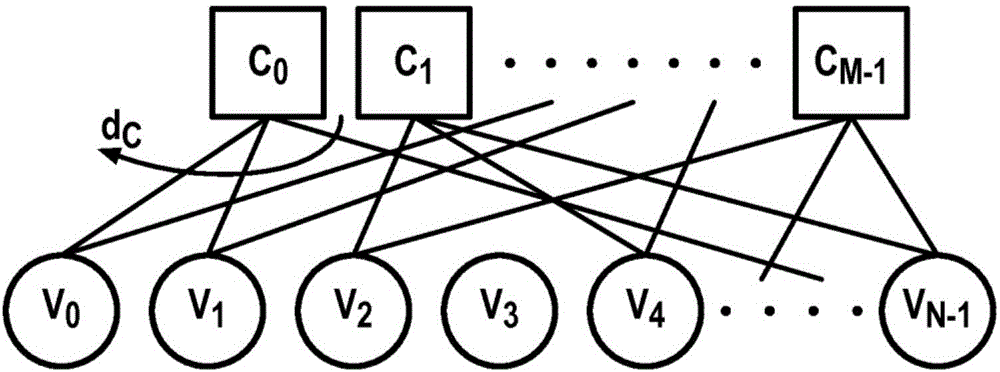
图1a示出了本发明的方法的二分图;
图1b示出了本发明的方法的单个变量节点;
图1c和图1d示出了本发明的单个校验节点;
图2示出了在本发明的方法中生成L个排序索引的结构;
图3示出了根据本发明的从校验节点接收信息的变量节点;
图4示出了本发明的解码器的体系结构;
图5a和图5b示出了本发明的解码器的校验节点单元的体系结构;
图6示出了本发明的解码器的变量节点单元的体系结构;
图7示出了本发明的解码器的变量节点单元的CELL;
图8示出了针对27个元素列表中的4-最小值查找器的本发明的排序器单元的总体体系结构;
图9a和9b示出了图8的排序器单元的针对第一阶段(l=0)的体系结构;
图10示出了针对不同于图8的排序器单元的第一阶段的阶段(l>0)的体系结构;
图11示出了基于消息传递体系结构的针对本发明的解码器的面积复杂度的理论估计;
图12示出了针对dc列表中的R最小值查找器的面积复杂度的理论估计。
具体实施方式
一种用于解码在大小q的有限域中定义的非二进制低密度奇偶校验(NB-LDPC)码的方法是基于包括至少一个变量节点Vn,n=0,…,N–1以及至少一个校验节点Cm,m=0,…,M–1的二分图。
图1a示出了具有M个校验节点Cm,m=0,…,M–1以及N个变量节点Vn,n=0,…,N–1的二分图。如此图所示,每个校验节点Cm被连接到dc个变量节点Vn。
NB-LDPC记号
让我们定义具有码长N和信息长度K的在GF(q)(q=2p)上的(N,K)NB-LDPC码。其奇偶校验矩阵HM,N具有N列和M行。HM,N的非零系数为hm,n,其中m为行索引并且n为列索引。校验节点度被表示为dc并且变量节点度被表示为dv。定义了连接到第m个校验节点的变量节点集合,并且定义了连接到第n个变量节点的校验节点集合。在嘈杂的加性高斯白噪声(AWGN)信道上传输之后,接收到的符号序列被定义为Y=(y0,y1,…,yN–1)。考虑到码字符号cn的传输,针对每个x∈GF(q),对数似然比(LLR)被计算为Ln[x]=log[P(cn=0)|yn)/P(cn=x|yn)]。第n个符号的LLR向量为Ln=(Ln[0],Ln[1],...,Ln[q-1])。基于Ln中最可靠元素的硬判决被称为zn∈GF(q)。
增强型串行GBFDA(ES-GBFDA)
根据本发明的用于解码NB-LDPC码的方法是ES-GBFDA的改进。在解释本发明的方法之前我们简要地描述这个已知的改进算法,特别是以上被称为“算法1”的来自[18]的ES-GBFDA。
在这个算法1中,在迭代过程中可以区分两个主要步骤:校验节点单元(CNU),步骤A2和A3;以及变量节点单元(VNU),步骤A1、A4和A5。
在初始化期间,等于信道LLR,Ln,并且为全零矩阵。在初始化之后,在第j次迭代处,步骤A1将外在信息进行排序以查找具有最大可靠性(GFmax)的符号其将被视为新的硬判决。
外在信息被计算为是其中所有投票被累积的向量并且是来自校验节点Cm的内在信息。步骤A2计算校验子s,需要在A3中计算其是要被投票(被选择)的符号。在步骤A4中,对上的投票进行计数,其中v是投票的幅度。在步骤A5中,累积初始LLR加上连接到变量节点Vm的所有校验节点的投票。投票修改和的值,改变了Al中排序过程的结果,并且因此翻转了中的符号。步骤A6通过查找与的最大值相关联的符号来执行试验性的解码,并且步骤A7基于所有校验子的信息而实施停止标准。解码的码字然后为
称为多投票符号翻转解码算法(MV-SF)的本发明的方法的总体介绍
我们现在通过增加由每个校验节点计算出的候选者的列表并且因此还增加传播到变量节点的投票的数量来以总体的方式描述基于ES-GBFDA的本发明的方法。我们仅介绍涉及在第j次解码迭代处的步骤。
假设为从最可靠符号获得的硬判决,并且为在校验节点Cm的输入消息内的第p个最可靠符号的硬判决。我们只考虑最可靠符号和第二最可靠符号符号(相应地)与可靠性(相应地)相关联。
我们将校验节点Cm的测试向量定义为dc个符号的组合,其具有限制:这些dc个符号的至少一个并且至多η个无法基于最可靠信息。为了减少测试向量候选者的数量,我们只考虑和之间的组合。为了建立校验节点Cm的测试向量的列表,首先计算与的可靠性之间的差值并且针对以上升的顺序对该差值进行排序。排序的差值的第一个元素是其中的可靠性更接近于的可靠性的符号。为了保持测试向量的数量低,我们在至多η位置中仅用替代其中与之间的差值更小(排序的列表中的第一η个元素)。参数η调整算法的性能/复杂度权衡,这是由于其直接涉及到使用要由每个校验节点处理的测试向量的数量。η被选为η<<dc以保持复杂度低。具有η位置的集合被表示为
让我们定义为校验节点m的列表2η-1个可能的测试向量的第i个测试向量,不同于仅基于符号的那一个。每个都是使用替代而建立。
在等式(1)中指示出测试向量的定义,其中是在集合中的第t个元素,it是i的二进制表示的位t并且是补偿值。操作符和分别为’AND’和’OR’操作符。
以同样的方式,我们可以借由等式(2)定义每个的可靠性。
本发明的方法的优选实施例的描述
我们现在考虑其中每个校验节点由L=η个测试向量组成的情况。每个测试向量具有dc–1个符号,以及一个符号。在测试向量i、中的符号的位置由N′i给出如下:
测试向量的可靠性等式由下面给出:
可以从等式(4)推导出,在N′i中由改变没有在校验节点的总体可靠性中引入强变化,在和中变化的元素仅仅是其被选择是因为差值是η个最小的之一(所以和这二者在选出的位置N′i中具有近似的可靠性)。
换句话说,由于具有高可靠性,近似于处理其候选者增加了在解码器中的有用软信息的量,并且因此提高了性能。
为了保持复杂度低并且避免针对每个测试向量计算并存储(4),函数务必要非常简单。
在本发明的优选实施例中,仅考虑投票的两个幅度:针对从最可靠的测试向量得出的符号候选者的v0,以及针对其他测试向量的v1,v0>v1。然而,针对幅度v0和v1的这个后面的条件是必要的但不足以获得最佳的效率和性能。如已经提到的,使用η,幅度之间的距离是要被优化的最重要的参数。如果v0和v1太接近,则投票的幅度将被容易地混合并且符号的翻转将在几乎没有任何标准的情况下完成,这是因为具有非常不同的可靠性值的候选者将具有几乎相同的投票幅度。如果v0和v1之间的差值太大,则较小可靠的测试向量的投票将不被考虑并且该效果将近似于不具有候选者的扩展列表。另一方面,值v0和v1也务必要根据信道信息被依比例决定。不同于例如EMS或Min-max的其他算法其中所有信息与传入的LLR密切相关,基于投票过程的算法混合了两个不同域,一个具有信道信息并且一个基于投票。容易推导出,投票幅度或信道信息需要某种标准化以将它们正确地结合。因此,我们需要通过函数来优化投票v0和v1的幅度以及它们与LLR信息的组合。
在上面被称为“算法2”的本发明的优选实施例中,L=η。可以看出,算法2的一些步骤近似于算法1的一些步骤(即,ES-GBFDA)。
以上本发明的方法包括It次解码迭代。以下,在每次迭代j处描述本方法。
在It次解码迭代之前初始化步骤(Initialization)包括以下子步骤:
确定N个非二进制噪声符号的序列中的第n符号的LLR向量Ln=(Ln[0],Ln[1],…Ln[q-1]);
将APP向量的向量初始化为LLR向量Ln并且将矩阵初始化为全零矩阵,所述矩阵为来自校验节点m的内在信息。
在步骤A1.1和步骤A1.2中连接至校验节点Cm的每个变量节点Vn被配置为用于确定最可靠符号以及为至少第p个最可靠符号的至少一个符号,其中p≥2以获得dc个最可靠符号的向量。图1b示出了这些步骤A1.1和A1.2的原理。
特别地,步骤A1.1和步骤A1.2搜索最可靠符号(max1)的外在信息,及其相关联的硬判决符号和
此外,每个变量节点n=0,...,dc–1被配置为用于确定最可靠符号和第二最可靠符号及其对应的外在可靠性以使得在校验节点m处L+1个测试向量的列表通过在其中与之间的差值是最小的至多η≤L位置中由第二最可靠符号替代符号而建立,其中
基于dc个最可靠符号,每个校验节点Cm被配置为用于:
在步骤A3.1中,基于由在所述二分图中连接至其的所述变量节点传递的所述dc个最可靠符号的向量而确定要被投票(被选择)的第一符号
在步骤A3.2中,基于被定义为具有限制的dc个符号的组合的L+1个测试向量的列表而确定要被投票(被选择)的i=1,…,L第二符号的列表,根据所述限制这些dc个符号的至多η个是具有的第p个最可靠符号(其中p≥2)并且这些dc个符号的至少dc–η个是最可靠符号
图1c和图1d示出了步骤A3.1和步骤A3.2的原理。在这些图上,校验节点被连接到三个变量节点x;y,z。校验节点接收来自dc个不同变量节点的p个元素的dc个向量并且计算p个符号的dc个向量。由校验节点计算出的信息被发送到dc个不同变量节点。
可以看出,相比算法1而言,每个校验节点比算法1的校验节点执行更多操作。进一步地,步骤A3.1与算法1中的A3相同。
此外,每个变量节点被配置为用于在步骤A1.1和步骤A1.2中确定最可靠符号和第二最可靠符号及其对应的外在可靠性以使得在校验节点处在步骤A2.1和步骤A2.2中L+1个测试向量的列表通过其中和之间的差值是最小的至多η≤L个位置中用第二最可靠符号替代符号而建立,其中
本发明的方法还包括步骤:所述步骤包括排序器单元被配置为在步骤A1.3中将外在可靠性的差值从最高值到最低值进行排序以获得L个排序索引n的序列所述序列包括η个位置,其中在L+1个测试向量中由替代
特别地,步骤A1.3以增加的顺序对进行排序,其中因此,排序后的第一个值是在和符号的可靠性之间具有最小差值的那一个。最后,步骤A1.3存储在中的排序的n个索引。
图2示出了用于生成L个排序索引的步骤A1.3原理。在这个图上,校验节点连接到三个变量节点x、y和z。
此外,每个变量节点还被配置为用于在步骤A4.1和步骤A4.2中使用相应的幅度投票v0、v1对的投票和的投票进行计数来计算来自校验节点的内在信息
图3示出了步骤A4.1和步骤A4.2的原理,在其上变量节点根据从校验节点Cm接收到的信息对Wnm中的投票进行计数。在这个示例中,针对符号的计数相应地增加v0和v1。
此外,视为输入LLR向量和向量的每个变量节点通过函数F1来结合(A4.1,A4.2)先前向量投票符号和以及投票幅度v0、v1以获得被定义为内在信息的向量。
函数F1可以是由投票符号和指示出的索引处的先前向量的值与投票幅度v0、v1的简单求和。
此外,视为输入LLR向量和向量的每个变量节点在步骤A5.1、步骤A5.2中通过函数F2来结合先前向量投票符号和以及投票幅度v0、v1以获得向量
函数F2可以是由投票符号和指示出的索引处的先前向量的值与投票幅度v0、v1的简单求和。
来自算法2的步骤A2.1、A3.1、A4.1和A5.1与算法1中的A2、A3、A4和A5是相同的。这些步骤基于最可靠符号而执行。步骤A2.2、A3.2、A4.2和A5.2使用来自考虑过的和符号的集合的L个测试向量来执行。步骤A2.2针对由一个符号和dc–1个符号形成的L+1个测试向量(s′i)执行校验子计算。步骤A3.2根据L+1个测试向量中的每一个测试向量来计算投票过程的候选者步骤和A4.2和A5.2近似于算法的步骤A4和步骤A5。主要的区别是,在第一个中的投票候选者不是而是可以注意到,针对投票v0、v1存在两个幅度。如之前可以被解释的,必须满足限制v0>v1,这是因为使用符号而计算,所以它比使用符号和符号这二者计算的更可靠。
用于实施本发明的方法的解码器的体系结构
现在描述与图4有关的用于实施本发明的方法的解码器。
在这个图上,描述了完整体系结构的示意图。可以区分出三个主要部分:i)VNU单位、ii)CNU单元和iii)排序器单元。解码器具有dc个VNU单元。每个VNU单元通过使用和传入符号(具有i从0至L)来计算和符号,其是CNU单元的输入。此外,VNU单元计算和并且执行减法其被用作排序器单元的输入。因此,VNU单元实施来自算法2的步骤A1.1、A1.2、A4.1、A4.2、A5.1和A5.2。排序器单元接收dc个值并且寻找L个最小值(被添加到扩展列表的元素是在和的可靠性之间具有较小差值的那些)。排序器输出是在dc个输入内具有最小的值的L个元素的索引。体系结构的这部分实施了步骤A1.3并且由于其复杂性和相对新颖性,所以其在本部分的最后进行解释,与其他分开。最后,发现了两种不同的CNU单元:一些仅计算符号(CNU单元HD)并且一些计算具有和这二者的测试向量(CNU单元测试向量(TV))。解码器仅具有一个CNU单元HD和L个CNU单元TV。用于计算hmn系数的硬件资源在HD和TV单元这二者之间共享。CNU单元HD实施步骤A2.1和A3.1步骤,而L个CNU单元TV实施来自算法2的步骤A2.2和步骤A.3。
CNU单元
图5a和图5b示出了CNU单元的实施例。被包括在这些单元中的所有算术资源被定义在GF(q)上。图6a包括CNU单元HD,其与针对ES-GBFDA体系结构在[18]中应用的那一个相同。coeff Hmn和coeff H′mn块在每个时钟周期中生成由步骤A2.1、A2.2、A3.1和A3.2所需的系数hmn和h′mn。这些块由两个ROM和一个计数器来实施,为了简单起见其不被包括在图中。hmn系数乘以输入。乘法器的输出使用树型结构来增加,生成硬判决校验子s(步骤A2.1)。如步骤A3.1指示出的,该校验子s乘以系数并且结果被增加到符号以计算Rn。
图6b表示针对测试向量i的CNU单元。此块执行与图6a中的那一个相同的算术运算,主要的区别是,不是所有符号输入都是最可靠的那些为了知道其中哪个dc个可能的位置务必要由来改变,必须完成与来自排序器单元的传入n′(i)索引进行的比较。该比较借由XOR门来完成。如果一个位置的索引等于n′(i),则XOR门的输出是零并且是使用多路复用器;在其他情况中,被选择。注意到作为在图6b中的一个的L个CNU单元对实施步骤A2.2和步骤A3.2(来计算s′i和R′n-i)是必需的。此外,重要的是注意到针对生成hmn和系数的硬件资源在所有CNU单元之间共享。换句话说,在整个解码器中仅需要dc个coeff Hmn块和dc个coeff块,并且如图5所示其输出被连接到所有CNU单元。
VNU单元
图6示出了VNU单元的实施例。VNU单元包括四个不同部分:i)乒乓存储器,ii)用于选择活动单元格(cell)的逻辑,iii)VNU单元格,以及iv)第一和第二最大查找器逻辑。
每个VNU单元具有存储了和R′n-i符号的2×(L+1)个RAM。单个RAM存储了对应于一个子矩阵的信息的(q-1)个(或R′n-i)符号。和R′n-i符号使用p位来表示,因为连接到相同输入的q=2p.个存储器以乒乓的方式工作,所以在q-1个时钟周期期间一个RAM进行读并且另一个进行写并且在下一个q-1个周期内存储器以相反的方式工作。这降低了解码器的空闲周期并且提高了其效率。
用于选择活动单元格的逻辑生成了指示出VNU单元格是否接收投票的sym_sel x。为了计算单元格x的sym_sel x,所有和R′n-i符号(由多路复用器选择的乒乓RAM的输出)和与单元格相关联的符号x进行比较,其中x∈GF(q)。这些比较使用XNOR门来实施,因此如果符号(或R′n-i)之一等于x,则XNOR门之一的输出将是指示出符号x被投票的那一个。sym_sel x通过将OR操作施加到与符号x相比较的所有XNOR输出来计算。连接到R′n-i的XNOR门(A位)的所有输出也被添加(为了简化在图7上被省略)以知道从扩展列表接收到的投票(#v)的数量。此外,连接到最可靠候选者输入的XNOR门的输出被用作vote_sel x。为了总结单元格工作的逻辑如下:i)如果vote_sel x等于一并且sym_sel x也是活动的,则投票由生成,因此幅度v0在单元格中被选择;ii)vote_sel x等于零但sym_sel x是活动的,投票由R′n-i生成,因此与v1(v1x#v)成比例的幅度在单元格中被选择;iii)否则,没有投票被执行。
每个VNU单元具有计算Wn(O)-Wmn(O)、Wn(α0)-Wmn(α0)、|Wn(α1)-Wmn(α1)...,Wmn(αq-1)-Wmn(αq-2)|的q个单元格。
在图7中,包括了针对VNU单元的一个单元格的体系结构。Ln和Wn的量化的位数量是Q′b。针对n的一个值以及连接到这个变量节点Vn的校验节点Cm的dv·值元素αx的单元格在RAMWn(αx)和Wmn(αx)的每个字中存储,因此字的长度为Qb+Q′b×dv。存储器具有q-1个字是因为存储了针对n的q-1个不同值的信息。在初始化期间,RAM充满与dv×Q′b个零级联的Ln个值。在那之后,RAM存储针对Wn(αx)(步骤A5.1和步骤A5.2)和Wmn(αx)的dv个不同值的更新的信息(步骤A4.1和步骤A4.2)。Wn(αx)的更新取决于:i)sym_sel的值,ii)在相同VNU单元的其他单元格中修剪(clipping)的检测,iii)在自己的单元格中修剪的检测以及iv)vote_sel的值。如果单元格检测到投票(sym_sel是活动的)并且没有检测到修剪,则在自己的单元格中,Wn(αx)=Wn(αx)+υv。如果单元格没有检测到投票并且在其他单元格中检测到修剪,则Wn(αx)=Wn(αx)-υy。在其他情况中,Wn(αx)仍然相同。vy可以采取两个值:v0(步骤A4.1和步骤A5.1)或v1×#v(步骤A4.2和步骤A5.2)。具有深度L的ROM存储不同的v1×#v个可能值,以避开乘数。ROM没有被包括在图8中。另一方面,信号dv_sel从dv个可能值中选择对应的Wmn(αx)。Wmn(αx)是Wn(αx)-Wmn(αx)的计算所需要的。此外,如果sym_sel=1,则Wmn(αx)增加了vy以考虑到在当前迭代中做出的投票的幅度(步骤A4.1和步骤A4.2)。注意到在图8中由vote_sel控制的加法器的符号仅是示意图的方式表示由选择了v0或v1×#v的vote_sel控制的加法器和多路复用器。Wn(αx)和dvWmn(αx)这二者更新的值被连接并再次被存储在RAM中。
如图7中所示出的,q个单元格的输出(Wn-Wmn)是最大值查找器单元的输入。此块寻找:第一最大值(在步骤A1.1中),第二最大值(在步骤A1.2中)及其在q个输入之间的相关联的GF符号(和)。应用于此块的体系结构可以在[20]中找到。最后,减去和输出以计算最高可靠性值和第二高可靠性值之间的差值。排序器单元(见图5)生成针对VNU单元的dc个输出之间的L个最小值的L个n′(i)索引。这个排序器将在下面进行解释。
整个解码器的延迟等式与[18]中的那一个是相同的;然而,如果想要达到相同频率,则管道阶段的数量必须增加。解码器的延迟为(q-1+pipeline)×dv×(#iterations+1)+(q-1+pipeline)个时钟周期。计算每个子矩阵花费(2q-l)但是管道延迟务必增加,所以每个子矩阵需要(q-1+pipeline)个时钟周期。由于存在dv个子矩阵,所以每次迭代需要(q-1+pipeline)×dv个时钟周期。我们务必将一次额外迭代添加到初始化的迭代的总数并且需要(q-1+pipeline)个时钟周期以在迭代过程之后得到解码的码字的值。
排序器单元:在dc个元素列表中的L-最小值查找器
提出的上升的排序器单元可以被看作L-最小值查找器。该体系结构是基于来自[20]的那一个,但不是寻找两个最小值,而是寻找L个最小值。在这项提议和在[20]中的那一个之间的主要区别是我们没有应用掩饰来计算不同于绝对的那一个的最小值。避免掩饰的事实以增加一些硬件资源的代价而减少了关键路径。我们描述排序器单元的体系结构为L=4和dc=27,但是它可以容易地被推广。此外,由于目的仅是示出存在可能的解决方案来以适中面积和连续处理实现上升的排序器单元,所以针对每一个阶段的基数的选择没有被优化(在由具有第一输入的管道生成的延迟后,每个时钟周期可以对一组新的元素进行排序)。
图8示出了针对具有L=4和dc=27的查找器的根据本发明的实施例的排序器的体系结构。如发生在针对两个最小查找器在[20]中的体系结构,我们区分两种不同的阶段:l=0和l>0。阶段l=0单元只涉及L个输入,而l>0计算2×L个输入。
图9a和图9b上示出了针对阶段l=0的一个单元的体系结构。首先,执行L传入值(xn)之间的比较(图10a)。必须计算的比较的总数是(L-1)×L,然而,仅仅需要(L-1)×L/2来计算比较,这是因为其他(L-1)×L/2个值可以通过施加补集至减法器的输出(由NOT门执行)来获得。在比较之后,其中输入xn是最小值的情况的数量被计数,cn。为了计算每个cn,需要log2(L)个加法器(针对L=4的情况,两个两位的加法器)。计数cn的结果借由XNOR门与所有可能的解法进行比较(图10b)。作为示例,如果c0是相比于在四个元素的列表中的两个元素的最小值:则其输入被连接至零(不是最小值)一(相比一个元素而言是最小值)三(是绝对最小值)的XNOR门的输出为零;并且其输入为二(与两个元素相比的最小值)的XNOR门的输出等于一。因此,具有输入cn的XNOR门的输出将仅仅设置一个AND门输出为xn。跟随前面的示例,连接至具有输出等于一(与二相比较的那一个)的XNOR的AND门将具有如结果x0;其余的AND门(与零、一和三相比较而言)将具有零输出。最后,OR操作被施加到连接至具有相同恒定输入值的XNOR门的AND门的输出。在图10b中,连接至其恒定输入等于三的XNOR门的AND门的输出被连接至相同的OR门,其是计算第一最小值的那一个(这是因为如果该值是与在四个元素的列表中的三个元素相比的最小值,则选出的元素将是第一最小值)。其余的最小值可以遵循相同的原因。注意到AND门和OR门被复制(在图10b中的x2),这是因为我们需要不仅输出排序的幅度,而且输出对应的索引。
在图10上示出了阶段l>0的单元的体系结构。在这种情况中,存在2×L个输入,其可以被视为两个L个排序的序列。具有两组已经排序的L个元素的事实减少了所需的比较的次数(从(2×L)×(2×L-1)至2×L2),这是因为在相同组的元素之间的比较是可以避免的。总计需要L2个减法器,这是因为如发生在阶段l=0的单元其他L2个值是由减法器计算出的那一个的补集。为了对其中xn小于x′n元素(并且反之亦然)的比较的次数进行计数,需要log2(L+1)个加法器(针对L=4的情况,需要两个二位的加法器和一个三位的加法器)。由于对两组输入的每一个组内的元素进行排序,所以一些先验信息是已知的。例如,为了计算第一最小值,务必仅仅考虑到每组的第一最小值并且其cn或c′n等于L的那一个将为绝对最小值。相反,针对第L最小值应该考虑所有传入的输入。图10包括了如何计算针对L=4的第L最小值。第4最小值输出可以为:i)具有c0或c′0等于4的输入组(x0和x′0)的第4最小值(其是与其他全组相比的最小值);ii)输入组(x1和x′1)的第3最小值,其是与其他组(c1=3或c′1=3)的元素中的三个元素相比的最小值;iii)输入组(x2和x′2)的第2最小值,其是与其他组(c2=2或c′2=2)的元素中的两个元素相比的最小值;或iv)第1最小值(x3和x′3),其是与其他列表(c3=1或c′3=1)的第4最小值相比的最小值。针对其余的最小值在第1个和第L个之间的计算和硬件资源可以归纳示例而容易地得出。AND门和OR门被复制以对幅度和索引这二者进行排序。
在本发明中,图5的解码器,需要n′(i)索引的输出来阐述测试向量。使用提出的体系结构,n′(i)索引的计算并行地完成,避免了将大大增加每解码器的迭代的时钟周期数量的递归解决方案。
实施结果和比较
下面我们在此给出上述解码器体系结构的面积和吞吐量的估计结果。
为了执行估计,如[21]中的那些的分析方法被应用。为了确保完成与其他工程结构的公平的比较,我们高估了一些硬件资源以提供在面积和关键路径这二者中的上限。例如,图7中的第一和第二最大值查找器的面积被视为与针对具有L=4的L-最小值查找器相同。为了比较提议,在具有q=32、dc=27和dv=4的域GF(q)上的具有准循环矩阵HK=124,N=837)的(837,726)码被考虑。应用于算法2的量子化方案为Qb=7并且Q′b=5。注意到由于针对这个码的投票的优化的幅度为v0=0.5并且v1=0.25,所以相比ES-GBFDA而言需要两个额外的位,其仅使用整数投票幅度工作并且不能区分投票中的软判决(所有投票都具有相同幅度)。
另一方面,该MV-SF体系结构增加了硬件来计算测试向量,相比[18]中的ES-GBFDA而言增加了关键路径的长度。在针对测试向量的选择的校验节点处(图4b)与排序器单元处(图9)增加了关键路径的门的数量。因此,为了实现与ES-GBFDA体系结构[18]近似的频率,有必要加倍管道阶段的数量(管道=10)。在排序器节点处的四个额外的管道阶段以及在校验节点处的一个额外管道阶段对保持关键路径等于22个门是必要的。
虽然此关键路径比[18]中的那一个长两个门,但是路由的效果比来自逻辑深度的那一个更大,所以我们可以在没有在估计中引入大的误差的情况下,假设频率~238mhz。针对具有以前的参数的MV-SF解码器的硬件资源可以在图11的表中找到。
在图12的表中,总结了包括在本文中的那一个的基于不同算法的NB-LDPC体系结构的结果。注意到图13的表中的所有码具有相同大小,即相同数量的编码符号N=837,以及相同数量的非二进制奇偶校验等式M=124。用于ES-GBFDA[18]的码比其他码具有3个更多的冗余行。重要的是注意到由于在每个参考中执行不同的算法,所以不同的编码增益由每个解码器获得。由于这个原因,我们还包括每个解码器的性能损失,视为参考EMS的性能。在编码增益中的性能退化在效率参数中难以考虑到,所以它不被包括。效率参数被计算为throughput(Mbps)=area(MXORS),遵循来自[13]和[14]、[15]的效率的描述。
将ES-GBFDA解码器与用于实施本发明的方法的那一个进行比较,我们使用稍低的吞吐量(不是615mbps而是540Mbps)来增加面积1.5M/847k=1.77倍。
算法2的解码器比基于[18]中的ES-GBFDA的那一个的效率少726/360=2倍,但是其达到不可忽略的0.44dB的编码增益。算法2的直接映射体系结构需要L+1倍ES-GBFDA的面积(L针对不可靠的测试向量并且一针对最可靠的那一个),其为4.23MXOR。因此,我们的建议是比具有12%的较少吞吐量的直接映射体系结构面积消耗少4.23M/1.5M=2.82倍。在效率方面,使用相同的编码增益,直接映射体系结构(615Mbps=4.23MXORs=145)比这项工作的建议超过两倍的较少效率。
尽作者最好的知识,在[15]中的体系结构是基于Min-Sum算法的最有效的一个。
相比这个体系结构而言,本发明的解码器需要1.5M/806K=1.86倍更多的面积,但是达到540/149=3.62倍更高的吞吐量。相比基于简化的Min-Sum的在[15]中的那一个而言,算法2的解码器为360=185=1.9倍的更高效率,但是应该考虑在编码增益中的0.26dB的差值。关于Min-Max体系结构,我们与最有效的那一个进行比较,[22](其他高效的体系结构被包括在图14的表中)。在[22]中提出的基于Min-Max的体系结构比在本文中引入的那一个小2.75倍。然而,我们的建议达到比[22]中的Min-Max解码器的吞吐量高的540/154=3.5倍。在效率方面,相比基于最小最大的那一个而言,基于算法2的体系结构示出了27%的效率增益,以0.21dB的性能损失的代价。
为了总结,相比基于EMS或Min-Max的那一个而言,基于本发明的方法的体系结构具有1.86和2.75倍的更多的面积,但是达到3.5倍的更高的吞吐量。相比EMS而言MV-SF引入0.26dB的性能损失,相比Min-Max而言0.21dB。
参考文献
[1]M.Davey and D.J.MacKay,"Low density parity check codes over GF(q)",IEEE Commun.Letter,vol.2,pp.165-167,Jun.1998.
[2]L.Barnault and D.Declercq,"Fast decoding algorithm for LDPC over GF(2q)",Proc.Info.Theory Workshop,pp.70-73,Paris,France,Mar.2003.
[3]H.Wymeersch,H.Steendam and M.Moeneclaey,"Log-domain decoding of LDPC codes over GF(q),"Proc.IEEE Intl.Conf.on Commun.,pp.772-776,Paris,France,Jun.2004.
[4]C.Spagnol,E.Popovici and W.Marnane,"Hardware implementation of GF(2m)LDPC decoders",IEEE Trans,on Circuits and Syst.-I,vol.56,no.12,pp.2609-2620,Dec.2009.
[5]D.Declercq and M.Fossorier,"Decoding algorithms for nonbinary LDPC codes over GF(q),"IEEE Trans,on Commun.,vol.55,pp.633-643,Apr 2007.
[6]C.Poulliat,M.Fossorier and D.Declercq,"Design of regular(2,dc)-LDPC codes over GF(q)using their binary images",IEEE Trans.Commun.,vol.56(10),pp.1626-1635,October 2008.
[7]V.Savin,"Min-max decoding for non binary LDPC codes,"Proc.IEEE ISIT,pp.960-964,Toronto,Canada,July 2008.
[8]A.Voicila,D.Declercq,F.Verdier,M.Fossorier and P.Urard,"Low-Complexity Decoding for non-binary LDPC Codes in High Order Fields",IEEE Trans,on Commun.,vol.58(5),pp 1365-1375,May 2010.
[9]E.Boutillon and L.Conde-Canencia,"Bubble check:a simplified algo-rithm for elementary check node processing in extended min-sum non-binary LDPC decoders,"Electronics Letters,vol.46,pp.633-634,April 2010.
[10]X.Zhang and F.Cai,"Partial-parallel decoder architecture for quasi-cyclic non-binary LDPC codes,"Proc.of Acoustics Speech and Signal Processing(ICASSP),pp.1506-1509,Dallas,Texas,USA,March 2010.
[II]D.Zhao,X.Ma,C.Chen,and B.Bai,"A Low Complexity Decoding Algorithm for Majority-Logic Decodable Nonbinary LDPC Codes,"IEEE Commun.Letters,vol.14,no.11,pp.1062-1064,Nov.2010.
[12]C.Chen,B.Bai,X.Wang,and M.Xu,"Nonbinary LDPC Codes Con-structed Based on a Cyclic MDS Code and a Low-Complexity Nonbinary Message-Passing Decoding Algorithm,"IEEE Commun.Letters,vol.14,no.3,pp.239-241,March 2010.
[13]Y.-L.Ueng,C.-Y.Leong,C.-J.Yang,C.-C.Cheng,K.-H.Liao,and S.-W.Chen,"An efficient layered decoding architecture for nonbinary QC-LDPC codes,"IEEE Trans,on Circuits and Systems I:Regular Papers,vol.59,no.2,pp.385-398,Feb.2012.
[14]J.Lin and Z.Yan,"Efficient shuffled decoder architecture for nonbinary quasicyclic LDPC codes,"IEEE Trans,on Very Large Scale Integration(VLSI)Systems,vol.PP,no.99,p.1,2012.
[15]X.Chen and C.-L.Wang,"High-throughput efficient non-binary LDPC decoder based on the Simplified Min-Sum algorithm,"IEEE Trans.On Circuits and Systems I:Regular Papers,vol.59,no.11,pp.2784-2794,Nov.2012.
[16]X.Zhang,F.Cai and S.Lin,"Low-Complexity Reliability-Based Message-Passing Decoder Architectures for Non-Binary LDPC Codes,"IEEE Trans,on Very Large Scale Integration(VLSI)Systems,vol.20,no.11,pp.1938-1950,Sept.2011.
[17]F.Garcia-Herrero,M.J.Canet and J.Vails,"Architecture of generalized bit-flipping decoding for high-rate non-binary LDPC codes,"Springer Circuits,Systems,and Signal Processing,vol.32,no.2,pp.727-741,April 2013.
[18]F.Garcia-Herrero,MJ.Canet,J.Vails,"Decoder for an Enhanced Serial Generalized Bit Flipping Algorithm,"IEEE International Conference on Electronics,Circuits and Systems(ICECS),pp.412^115,Sevilla,Spain,Dec.2012.
[19]B.Zhou,J.Kang,S.Song,S.Lin,K.Abdel-Ghaffar,and M.Xu,"Construction of non-binary quasi-cyclic LDPC codes by arrays and array dispersions,"IEEE Trans,on Commun.,vol.57,no.6,pp.1652-1662,June 2009.
[20]L.Amaru,M.Martina,and G.Masera,"High speed architectures for finding the first two maximum/minimum values,"IEEE Trans,on Very Large Scale Integration(VLSI)Systems,vol.20,no.12,pp.2342-2346,Dec.2012.
[21]X.Zhang and F.Cai,"Reduced-complexity decoder architecture for nonbinary LDPC codes,"IEEE Trans,on Very Large Scale Integration(VLSI)Systems,vol.19,no.7,pp.1229-1238,July 2011.
[22]F.Cai;X.Zhang,"Relaxed Min-Max Decoder Architectures for Nonbinary Low-Density Parity-Check Codes,"IEEE Transactions on Very Large Scale Integration(VLSI)Systems,2013.
[23]F.Garcia-Herrero,D.Declercq,J.Vails,"Non-Binary LDPC Decoder based on Symbol Flipping with Multiple Votes,"submitted to IEEE Commun.Letters,2013.
- 还没有人留言评论。精彩留言会获得点赞!