基于LDPC码节点剩余度置信传播译码的改进方法与流程
本发明属于电子、通讯、与信息工程类领域,特别涉及无线通信和信息存储中ldpc纠错码的译码方法的设计。
背景技术:
低密度奇偶校验(ldpc,low-densityparity-check)码是一种线性码。ldpc码因其接近香浓极限的特性,目前已经被广泛应用到深空通信、光纤通信、卫星数字视频、音频广播、数据存储等领域。
传统ldpc码的迭代译码方法flooding,在每次迭代过程中,先同时更新所有的从变量节点到校验节点的边信息,然后再同时更新所有的从校验节点到变量节点的边信息。flooding译码的收敛速度较慢,为了提高译码收敛速度,casado等人将剩余度概念运用到了置信传播,并提出了两种译码时序:基于剩余度置信(rbp,residualbeliefpropagation)传播译码、基于校验节点的剩余度置信传播(nwrbp,node-wiserbp)译码。两者的区别是,rbp动态选择最大剩余度所在的边进行更新,而nwrbp动态选择最大剩余度所在的校验节点进行更新。这两个译码方法的收敛速度都优于flooding。尽管rbp和nwrbp的误码率低于flooding,然而这两种动态译码过程容易出现边或节点更新次数不均匀的现象,且性能受限于陷井集(trappingsets)的影响,导致一些错误的变量节点(即误码)在多次迭代译码后仍然不能被纠正。
技术实现要素:
经研究发现,nwrbp在译码过程中,变量节点更新的次数并不均衡,存在某些节点更新次数极少的现象。而相对于更新次数较多的变量节点,更新次数较少的变量节点不能为相邻节点提供足够的有用信息,亦或该节点无法从相邻节点获得有用信息,导致相邻节点或其本身发生错误的概率更大。本发明正是利用这一现象,在nwrbp译码的基础上提出一种改进方法enhancednwrbp(enwrbp),该方法能有效均衡各变量节点的更新次数,从而进一步降低了ldpc码的译码误码率。
技术方案如下:
为方便理解译码流程,定义符号如下:
n(cm)={vn:hmn=1}表示与校验节点cm相连的所有变量节点的集合;
n(cm)\vn表示除了变量节点vn,所有与校验节点cm相连的变量节点的集合;
n(vn)={cm:hnm=1}表示与变量节点vn相连的所有校验节点的集合;
n(vn)\cm表示除了校验节点cm,所有与变量节点vn相连的所有校验节点的集合;
lvj→ci表示变量节点vj到校验节点ci所在边的置信度值;
mci→vj表示校验节点ci到变量节点vj所在边的置信度值。
本发明提出的enwrbp译码器的译码流程描述如下:
1)参数设置:变量节点vj更新次数uvj=0,j=1,2,...,n;设置初始化值被强制置零的变量节点总数为t,变量t=0,变量
2)初始化:所有从校验节点到变量节点的边信息mc→v设置为0;所有从变量节点到校验节点的边信息lv→c设置为相应的信道接收信息ri;
3)计算所有边信息mci→vj的剩余度值r(mci→vj)=abs(m'ci→vj-mci→vj),其中abs表示求绝对值,mci→vj和m'ci→vj分别表示从校验节点ci到变量节点vj的边信息在更新前后的置信度值;
4)在所有剩余度值中,找出最大剩余度值r(mcmax→vmax),并用cmax和vmax分别表示最大剩余度值所在边的两个端节点,即校验节点和变量节点;
5)对每一个vj∈n(cmax),更新从校验节点cmax到所有临边变量节点的信息mcmax→vj,记录vj更新的次数,即uvj=uvj+1;并将剩余度r(mcmax→vj)的值设置为0;
6)对每一个ca∈n(vj)\cmax,更新边信息lvj→ca;再对每一个vi∈n(ca)\vj,计算新的剩余度值r(mca→vi);
7)若未达到最大迭代次数或译码序列不符合奇偶校验检测,则返回步骤4);
8)当译码失败且t<t,在{uvj}中查找最小值所对应的变量节点,即查找译码过程中变量节点更新次数最小的变量节点,记为vmin;否则跳转至步骤10);
9)
10)译码结束,输出译码序列。
有益效果
本发明是基于ldpc码节点剩余度置信传播译码的改进方法。经研究发现,nwrbp在译码过程中,节点更新的次数并不均衡,存在某些节点更新次数少的现象,而相对于更新次数较多的变量节点,更新次数较少的变量节点不能为相邻节点提供足够的有用信息,亦或该节点无法从相邻节点获得有用信息,导致相邻节点或其本身发生错误的概率更大。本发明正是利用此现象,对这部分节点的信道接收值强制置零,并重新译码,从而有效降低误码率,达到提高译码性能的效果。
附图说明
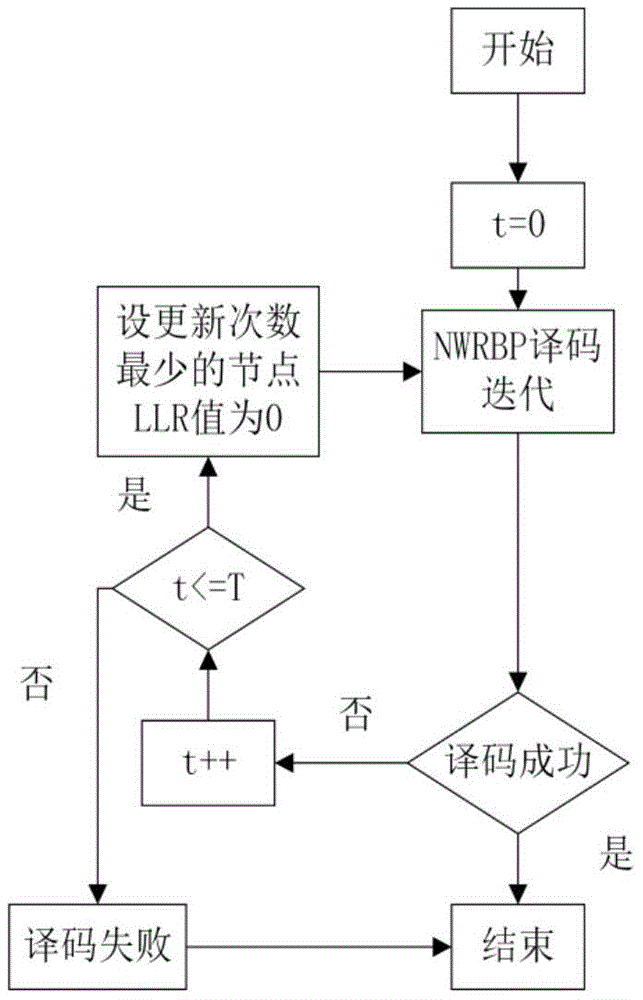
图1:本发明提出的nwrbp译码器技术方案。
图2:码a在加性高斯白噪声信道环境下,t=10时各译码方案误码率和误帧率与信噪比的关系。
图3:码b在高斯白噪声信道环境下,t=10时各译码方案误码率和误帧率与信噪比的关系。
图4:码a在高斯白噪声信道环境下,不同t值,enwrbp译码方案误码率和误帧率与信噪比的关系。
图5:码b在高斯白噪声信道环境下,不同t值,enwrbp译码方案误码率和误帧率与信噪比的关系。
用于仿真的码a:(155,3,5)ldpc码。
用于仿真的码b:(305,3,5)ldpc码。
具体实施方式
具体实施方案如图1所示。在nwrbp的一次译码过程中,如果达到最大的迭代次数仍然不满足译码成功条件,那么就寻找到在迭代过程中更新最少次数的变量节点vmin,并且将始于该节点的变量到校验节点的边信息初始化值设置为0。随后,重新用nwrbp进行译码,连续测试t个更新次数最少的变量节点。
步骤1:首先初始化,把所有从校验节点到变量节点的边信息mcj→vi设置为0;把所有从变量节点到校验节点的边信息lvi→cj设置为它们相应的信道接收信息ri;变量节点vj的更新次数uvj=0,j=1,2,...,n;设置最大迭代次数,设置最大尝试置零的变量节点数为t,变量t=0,变量
步骤2:计算校验节点到变量节点边信息的剩余度值r(mci→vj)。寻找剩余度值的最大值r(mcmax→vmax)所在的边,即在二分图中从校验节点cmax到变量节点vmax的置信度在更新前后残差最大。然后跟新边信息mcmax→vj,并且记录变量节点vj更新的次数,即uvj=uvj+1。随后,将剩余度rcmax→vj的值设置为0。接着,对于每一个ca∈n(vj)\cmax,更新变量节点到校验节点的信息lvj→ca,再对每一个vi∈n(ca)\vj,计算新的r(mca→vi)。接着,尝试译码判决,如果满足条件,译码结束,不满足则重复步骤2,直到达到最大迭代次数。
步骤3:如果不能译码成功,重新执行步骤1,接着找到更新次数最少的变量节点vmin,将其中所有从变量节点到校验节点的信息lvmin→cj设置为0,并返回步骤2重新译码。重复译码中断条件为:成功译码或者初始化置零的变量节点数达到t个。
下面结合实例及附图,对本发明作进一步地详细说明,但本发明的实施方式不限于此。
本发明实验所用计算机的配置为内存4gb,cpu是intelcorei5-24003.1ghz的台式计算机,所用代码是matlab2012b语言开发。用于测试发明方案的ldpc编码有a和b两种:码a是(155,3,5)ldpc码;码b是(305,3,5)ldpc码。本发明中所有的仿真都是在二进制输入加性高斯白噪声(bi-awgn)信道环境进行的。译码采用基于剩余度置信度传播(rbp)、基于校验节点的剩余度置信度传播(nwrbp),以及本发明提出的基于校验节点的改进剩余度置信度传播(enerbp),最大迭代次数为100,调制方式为bpsk。经分析各译码方案的性能,得出以下结论:
第一,enwrbp的译码性能要好于nwrbp和rbp。如图2和图3所示,在snr值较低时,图2中snr值为2.5~3db以及图3中2.5~2.7db,误码率ber和误帧率fer的曲线三者大致相同。随着snr值的增加,enwrbp和nwrbp的译码曲线逐渐优于rbp,图2中nwrbp和enwrbp依然大致相同,直到snr值为4.0db时,enwrbp开始优于nwrbp,图3中enwrbp在所示snr范围内始终优于rbp和nwrbp,并且这种优势随着snr值增大而在逐渐扩大。例如:如图3所示,在fer=2×10-4时,相比rbp和nwrbp,enwrbp的fer分别得到0.3db和0.18db的译码增益,类似的,在ber=2×10-5时,相比rbp和nwrbp,enwrbp的ber分别得到0.28db和0.16db的译码增益。
第二,随着t值的增大,enwrbp的译码效果更好。如图4和图5所示,t=10时的曲线要低于t=5时的曲线,这种趋势随着snr值的增大而增大。由此可见,通过增大对特定变量节点初始llr值置0尝试次数,可进一步提高enwrbp译码性能。例如:如图5所示,在fer=1×10-4时,相比t=5,t=10得到0.8db的译码增益,同样,在ber=1×10-5时,相比t=5,t=10得到1.2db的译码增益。
- 还没有人留言评论。精彩留言会获得点赞!