使用SIMD引擎的通用数据压缩的制作方法
本发明在其一些实施例中涉及数据压缩,更具体地但非唯一地,涉及使用单指令流多数据流(single instruction multiple data,SIMD)引擎的数据压缩。
数据压缩广泛用于多种应用以减少用于存储和/或传递的数据量,以便减少用于存储数据的存储空间和/或用于传递数据的网络带宽。
数据压缩涉及使用比数据的原始表示少的比特来对数据进行编码。虽然数据压缩可显著减少存储和/或网络资源,但是其可能需要额外的处理和/计算资源,例如处理引擎、存储器资源和/或处理时间。当前有许多种数据压缩方法、技术和/或算法可用,每种方法、技术和/或算法都采用压缩比与所需处理资源之间的权衡。
技术实现要素:
根据本发明第一方面,提供了一种对输入数据流进行压缩的系统,用以对输入数据流进行处理,获得压缩输出数据流,包括:用于存储哈希表的存储器,所述哈希表包括多个子集中的一个相关子集的哈希值以及指向所述相关子集的存储器位置的指针,所述多个子集由多个数据项组成,所述多个数据项由所述输入数据流的多个数据项组成;以及包括:耦合到所述存储器的处理器,用于
执行以下操作,在执行以下操作中的至少一个操作时,指示单指令流多数据流(single instruction multiple data,SIMD)引擎对所述若干子集中一组连续子集中的每个被处理子集并发执行所述至少一个操作:
计算每一个所述被处理子集的哈希值,
搜索所述哈希表,以查找每个计算出的哈希值的匹配项,以及
根据匹配结果更新所述哈希表;
根据所述匹配结果和基于所述匹配结果进行比较的比较结果,更新所述压缩输出数据流;以及
针对多个所述相关子集重复所述计算、搜索和更新以创建所述压缩输出数据流。
在如上所述本发明第一方面的第一可能实施形式中,所述多个相关子集中的每个子集包括根据所述SIMD引擎的架构定义的预定数量的数据项。
根据如上所述第一方面或根据所述第一方面的所述第一实施形式,在第二可能实施形式中,所述组中的被处理子集的数量根据所述SIMD引擎架构来设置。
根据如上所述第一方面或根据所述第一方面的任一前述实施形式,在第三可能实施形式中,所述匹配结果指示所述哈希表中的现有哈希值中是否有所述每个计算出的哈希值的匹配项。
根据如上所述第一方面或根据所述第一方面的任一前述实施形式,在第四可能实施形式中,如果所述匹配结果指示所述计算出的哈希值与所述哈希表中的匹配哈希值相匹配,则执行所述比较以产生所述比较结果,以及
其中,所述比较包括:对被处理子集所包括的数据项和哈希表项中指针指向的与所述被处理子集的所述计算出的哈希值相匹配的哈希值关联的子集所包含的数据项进行比较。
根据如上所述第一方面或根据所述第一方面的任一前述实施形式,在第五可能实施形式中,如果所述比较结果指示所述被处理子集和所述相关子集的所述数据项相同,则使用指向所述压缩输出数据流中的所述相关子集的指针来替代所述被处理子集,以及
如果所述比较结果指示所述被处理子集和所述相关子集的所述数据项不同,则在所述压缩输出数据流中更新所述被处理子集,并使用用于所述被处理子集的新哈希表项来更新所述哈希表。
根据如上所述第一方面或根据所述第一方面的任一前述实施形式,在第六可能实施形式中,所述并发计算包括:所述处理器将所述组中的被处理子集加载到所述SIMD引擎的至少一个SIMD寄存器,以及所述SIMD引擎并发处理所述组中的子集,所述并发处理包括:
将所述组中的所述被处理子集相互间隔,
针对每个被处理子集使用不同的位移值,通过位移值来移动所述被处理子集,并对所述被处理子集进行处理以便为每个所述被处理子集创建一个哈希值。
根据如上所述第一方面或根据所述第一方面的任一前述实施形式,在第七可能实施形式中,为查找所述哈希表中的现有哈希值是否有每个所述被处理的子集的所述计算出的哈希值的所述匹配项而在所述哈希表中进行的所述并发搜索包括:所述处理器指示所述SIMD引擎进行并发搜索,以查找所述哈希表中的现有哈希值中是否有每个所述计算出的哈希值的匹配项。
根据如上所述第一方面或根据所述第一方面的任一前述实施形式,在第八可能实施形式中,通过至少一个被处理子集对所述哈希表进行的所述并发更新包括:所述处理器指示所述SIMD引擎使用与所述至少一个被处理子集相关的表项,来并发更新所述哈希表。
根据如上所述第一方面或根据所述第一方面的任一前述实施形式,在第九可能实施形式中,所述压缩输出数据流兼容使用传统压缩方法压缩的标准压缩输出数据流,所述压缩输出数据流使用传统解压方法进行解压。
根据本发明第二方面,提供了一种对输入数据流进行压缩的方法,用以对输入数据流进行处理,获得压缩输出数据流,包括:
存储包括多个哈希表项的哈希表,每个哈希表项包括多个子集中的一个相关子集的哈希值以及指向所述相关子集的存储器位置的指针,所述多个子集由多个数据项组成,所述多个数据项由所述输入数据流的多个数据项组成;;
执行以下操作,在执行以下操作中的至少一个操作时,指示处理器的单指令流多数据流(single instruction multiple data,SIMD)引擎对所述若干相关子集中一组连续子集中的每个被处理子集并发执行所述至少一个操作:
计算每一个所述被处理子集的哈希值,
搜索所述哈希表以查找每个计算出的哈希值的匹配项,以及
根据匹配结果更新所述哈希表;
根据所述匹配结果和基于所述匹配结果进行比较的比较结果,更新所述压缩输出数据流;以及
针对所述多个子集重复所述计算、搜索和更新以创建所述压缩输出数据流。
在如上所述本发明第二方面的第一可能实施形式中,所述并发计算包括:所述处理器将所述组中的被处理子集加载到所述SIMD引擎的至少一个SIMD寄存器,以及所述SIMD引擎并发处理所述组中的被处理子集,所述并发处理包括:
将所述组中的所述被处理子集相互间隔,以及
针对每个被处理子集使用不同的位移值,通过位移值来移动所述被处理子集,并对所述被处理子集进行处理以便为每个所述被处理子集创建一个哈希值。
根据如上所述第二方面,在第二可能实施形式中,为查找所述哈希表中的现有哈希值是否有每个所述被处理子集的所述计算出的哈希值的所述匹配项而在所述哈希表中进行的所述并发搜索包括:所述处理器指示所述SIMD引擎进行并发搜索,以查找所述哈希表中的现有哈希值是否有每个所述计算出的哈希值的匹配项。
根据如上所述第二方面,在第三可能实施形式中,通过至少一个被处理子集对所述哈希表进行的所述并发更新包括:所述处理器指示所述SIMD引擎使用与所述至少一个被处理子集相关的表项,来并发更新所述哈希表。
根据如上所述第二方面或根据所述第二方面的任一前述实施形式,在第四可能实施形式中,所述压缩输出数据流兼容使用传统压缩方法压缩的标准压缩输出数据流,所述压缩输出数据流使用传统解压方法进行解压。
除非另有定义,否则本文所用的所有技术和科学术语都具有与本发明普通技术人员公知的含义相同的含义。虽然类似于或等同于本文所描述的那些方法和材料可以使用在本发明实施例的实践中或测试中,但是以下描述了示例性方法和/或材料。在有冲突的情况下,以包括定义的专利说明书为准。此外,材料、方法和示例仅仅是示例性的,并非旨在必然限制。
附图说明
此处仅作为示例,结合附图描述了本发明的一些实施例。现在具体结合附图,需要强调的是所示的项目作为示例,为了说明性地讨论本发明的实施例。这样,根据附图说明,如何实践本发明实施例对本领域技术人员而言是显而易见的。
在附图中:
图1是根据本发明一些实施例的使用SIMD引擎来压缩输入数据流的示例性系统的示意图;
图2是根据本发明一些实施例的使用SIMD引擎来压缩输入数据流的示例性过程的流程图;
图3A是根据本发明一些实施例的用于将输入数据流的多个连续字节同时加载到SIMD引擎的寄存器中的示例性序列的示意图;
图3B是根据本发明一些实施例的使用SIMD引擎针对多个子集同时计算哈希值的示例性序列的示意图,其中每个子集包括输入数据流的连续字节;
图4是根据本发明一些实施例的使用SIMD引擎对哈希表进行同时搜索以查找多个哈希值的匹配项的示例性序列的示意图;
图5是根据本发明一些实施例的使用SIMD引擎来同时更新多个哈希表项的示例性序列的示意图。
具体实施方式
本发明在其一些实施例中涉及数据压缩,更具体地但非唯一地,涉及使用SIMD引擎的数据压缩。
本发明提出了使用一个或多个处理器的SIMD引擎为多个应用进行通用数据压缩的系统和方法,这些应用需要进行数据压缩以便减少数据总量(数据量),例如数据存储和/或数据传递的量。包括字节、字、双字和/或像素等多个数据项的输入数据流通过以下方式压缩:用指向重复数据序列的先前实例的指针来替代这些重复数据序列。本文提出的压缩系统和方法利用本领域已知的无损压缩方法和/或算法,例如Lempel-Ziv(LZ77和LZ78)、Lempel-Ziv-Welch(LZW)、Lempel-Ziv-Oberhumer(LZO)和/或LZ4。本发明中阐述的压缩方法仅展示由处理器的SIMD引擎执行的压缩操作以促进压缩过程,例如减少压缩资源和/或压缩时间。但是预期本领域技术人员熟悉压缩方法的所有方面。压缩方案利用SIMD引擎在压缩过程中并发执行一个或多个操作、处理连续数据项的子集以计算相应的哈希值、搜索哈希表以查找哈希值的匹配项和/或使用哈希值和指向相关子集的指针来更新哈希表。SIMD引擎支持对多个数据项并发执行单个指令(处理器指令)。可略微操作压缩方法和/或算法以支持SIMD引擎进行的并发执行。
与现有的按序压缩方法(传统和/或标准压缩方法)相比,将SIMD引擎技术应用到数据压缩过程可呈现出明显的优势。一般而言,向量处理技术,尤其是SIMD技术,在许多方面迅速发展,例如,许多数据项可并行处理和/或处理器的处理能力。现有压缩方法采用的按序数据压缩可能是一种主要的耗时和/或处理器密集型操作。由于输入数据流的数据项相对于压缩过程的基本操作可视为相互独立,所以输入数据流的同步处理可充分利用SIMD引擎和/或技术。使用SIMD引擎可明显减少压缩时间和/或计算资源。即使并发执行压缩操作中的一个,也可使压缩性能明显提高,因此,应用SIMD引擎来执行两个或所有压缩操作,例如处理子集以计算哈希值、搜索哈希表以查找哈希值的匹配项和/或更新哈希表,可以呈现甚至更明显的压缩性能改进。
使用SIMD引擎压缩的压缩数据(流)的格式可完全兼容使用一些传统压缩方法的压缩数据。使用SIMD引擎的压缩数据的这种完全兼容支持使用如本领域已知的用于对压缩数据进行解压的标准解压方法、技术和/或工具来对压缩数据进行解压。当然,这些解压方法、技术和/或工具可能需要根据所用的压缩格式来适当地选择。例如,可采用LZ4解压对使用SIMD引擎根据LZ4压缩数据格式压缩的压缩数据进行解压。
通过详细说明本发明的至少一项实施例,将会理解,本发明的应用不一定限于下文描述中陈述的和/或附图和/或示例中说明的部件和/或方法的构造和布置细节。本发明能够用于其它实施例或者能够以各种方式实践或执行。
本发明可以是一种系统、一种方法和/或一种计算机程序产品。计算机程序产品可包括一种计算机可读存储介质(或媒体),其上存储有计算机可读程序指令,用于使处理器执行本发明的各方面。
计算机可读存储介质可以是有形设备,该有形设备可保留和存储指令以供指令执行设备使用。计算机可读存储介质可以是,例如但不限于,电子存储设备、磁性存储设备、光存储设备、电磁存储设备、半导体存储设备或前述存储设备的任意合适组合。
本文描述的计算机可读程序指令可以从计算机可读存储介质下载到相应的计算/处理设备,或者通过网络,例如互联网、局域网、广域网和/或无线网络,下载到外部计算机或外部存储设备。
计算机可读程序指令可作为独立软件包全部在用户的计算机上执行、部分在用户的计算机上执行、部分在用户的计算机上且部分在远程计算机上执行,或全部在远程计算机或服务器上执行。在最后一种场景中,远程计算机可通过任意类型的网络连接到用户的计算机,这些类型的网络包括局域网(local area network,LAN)或广域网(wide area network,WAN),或者可以(例如使用互联网服务提供商通过互联网)连接到外部计算机。在一些实施例中,包括可编程逻辑电路、现场可编程门阵列(field-programmable gate array,FPGA)或可编程逻辑阵列(programmable logic array,PLA)等的电子电路可使用计算机可读程序指令的状态信息来对电子电路进行个性化,从而执行计算机可读程序指令,以便执行本发明的各方面。
本发明的各方面在本文中参考根据本发明实施例的方法、装置(系统)和计算机程序产品的流程图图示和/或方框图进行描述。将理解,流程图图示和/或方框图中的每个方框以及流程图图示和/或方框图中的方框的组合可以通过计算机可读程序指令来实施。
图中的流程图和方框图图示了根据本发明各实施例的系统、方法和计算机程序产品的可能实施方式的架构、功能和操作。就此而言,流程图或方框图中的每个方框可表示一个模块、一个片段或一部分指令,指令包括用于实现指定逻辑功能的一个或多个可执行指令。在一些替代性实施方式中,方框中提到的功能可不按图中提到的顺序发生。例如,相继示出的两个方框事实上可以基本上并发执行,或者这些方框有时可以按相反的顺序执行,这取决于所涉及的功能。还将注意到,方框图和/或流程图图示的每个方框以及方框图和/或流程图图示中的方框的组合可以通过执行指定功能或动作或执行专用硬件和计算机指令组合的基于硬件的专用系统来实施。
现参考图1,图1是根据本发明一些实施例的使用SIMD引擎来压缩输入数据流的示例性系统的示意图。系统100包括:输入/输出(input/output,I/O)接口102,用于接收和/或指定输入数据流120并输出压缩输出数据流130;处理器104,包括用于对输入数据流120进行压缩以创建压缩数据流130的SIMD引擎106;存储器108;以及程序存储器110。输入数据流120可通过一种或多种格式接收,例如数据文件、媒体文件、流数据,等等。输入数据流120包括多个数据项,例如可按顺序排列为流的字节、字、双字和/或像素。I/O接口102可包括一个或多个接口,例如网络接口、存储器接口和/或存储接口。处理器104可使用I/O接口102通过网络和/或一个或多个本地外设接口,例如通用串行总线(universal serial bus,USB)、安全数字(secure digital,SD)卡接口等,来接收和/或发送数据流120和/或130。处理器104还可使用I/O接口102将数据流120和/或130提取和/或存储到存储器108等存储器中和/或程序存储器110等存储设备中。同构或异构的处理器104可排列为集群和/或排列为一个或多个多核处理器以进行并行处理,其中每个多核处理器具有一个或多个SIMD引擎106。SIMD引擎106包括多个处理管道,用于向量处理,例如,并发处理多个数据项。程序存储器110可包括一个或多个非瞬时性永久存储设备,例如硬盘、闪存阵列等。程序存储器110还可包括一个或多个网络存储设备,例如存储服务器、网络可接入存储器(network accessible storage,NAS)、网盘等。
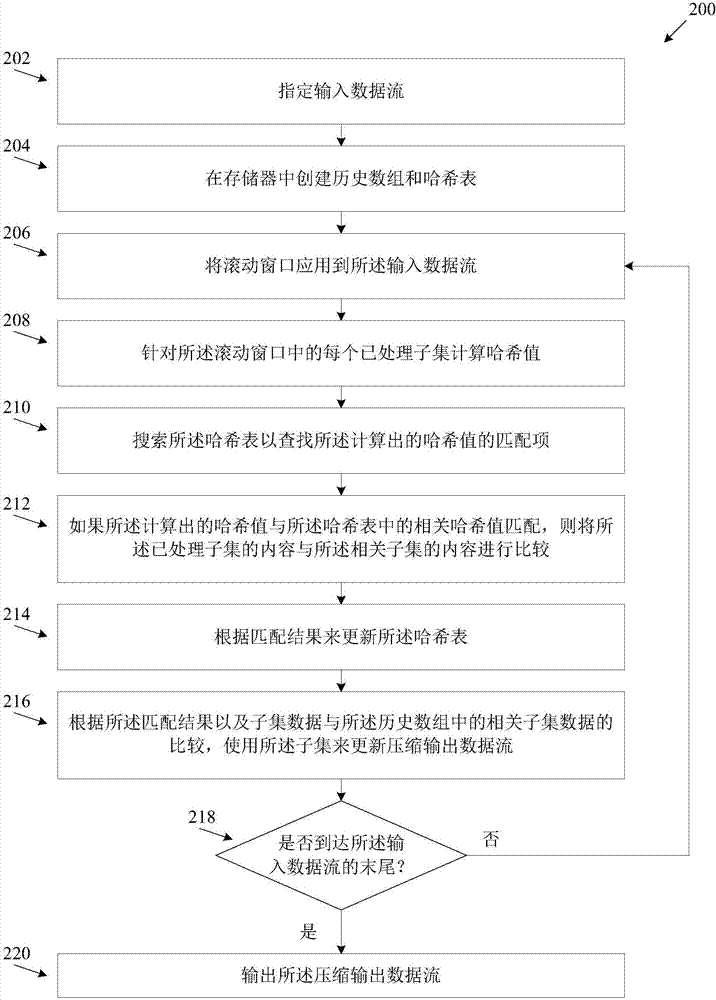
还参考图2,图2是根据本发明一些实施例的使用SIMD引擎来压缩输入数据流的示例性过程的流程图。用于对输入数据流进行压缩的压缩过程200可由系统100等系统执行。压缩过程200采用SIMD引擎106来并发处理输入数据流120的多个数据项以产生压缩输出数据流130。
压缩过程200可由一个或多个软件模块完成,例如包括由处理器104执行的多个程序指令的压缩器112和/或来自程序存储器110的SIMD引擎106。处理器104的处理单元可执行压缩器112以管理和/或协调压缩过程,例如,将数据加载到SIMD引擎106、从SIMD引擎106收集数据、同步数据、同步任务、更新压缩输出数据流130,等等。执行压缩器112的处理器104可指示SIMD引擎106在压缩过程200中并发处理输入数据流120的多个数据项和/或中间产品,以便加快压缩过程200,从而减少处理资源和/或处理时间。处理器104通过向SIMD引擎发起单个指令来应用并发处理,SIMD引擎使用多个处理管道对多个数据项和/或中间产品并发执行该操作(指令)。压缩器112可在存储器108中创建一个或多个数据结构以控制压缩序列200,例如历史数组114、哈希表116,等等。
如202处所示,过程200开始于压缩器112使用I/O接口102接收输入数据流120,例如,通过网络从远端设备接收输入数据流120,从本地外设接口、从存储器108和/或程序存储器110提取输入数据流120。
执行压缩过程200的系统100使用一种或多种无损压缩方法,例如本领域已知的Lempel-Ziv(LZ77和LZ78)、Lempel-Ziv-Welch(LZW)、Lempel-Ziv-Oberhumer(LZO)和/或LZ4,来压缩输入数据流120。如上文所提及的,本发明所阐述的压缩方法仅展示由SIMD引擎106执行的压缩操作以促进压缩过程200。
在进一步提供使用SIMD引擎106来压缩输入数据流120的实施例之前,首先要描述压缩方法的一些基本方面。压缩方法的基本概念是确定输入数据流120中的数据的重复序列并使用指向同一序列的一个先前实例的指针来替代该重复序列,而不是将该重复序列自身放置到压缩输出数据流130中。将滑动窗口应用到输入数据流120以指定包括输入数据流120的连续数据项的滚动序列。滚动序列的数据项存储在历史数组中,例如存储在历史表114中。针对每个滚动序列计算哈希值,并将计算出的哈希值存储在哈希表例如哈希表116的哈希表项中。每个哈希表项包括几对计算出的哈希值以及一个指向历史数组114中的相关滚动序列的指针。对于每个新滚动序列,计算哈希值并在哈希表116中搜索匹配项,从而检查哈希表116中是否存在相同的哈希值。如果发现匹配,则该新滚动序列可能和与该匹配哈希值相关的先前滚动序列相同。
可使用多个哈希函数来计算哈希值。哈希函数的选择可呈现计算复杂度和/或处理时间与两个子集的相似性的确定性之间的权衡。有可能计算出复杂的哈希值,该值会很明确,使得每个滚动序列与一个唯一的哈希值相关。但是复杂的哈希值的计算可能对计算要求很高。复杂度较低的哈希函数可为滚动序列产生不太复杂的哈希值,然而,可能存在一定程度的不确定性,例如,对于两个或更多不相似的滚动序列,计算出的哈希值可能相同。在哈希值的复杂度较低的这种情况下,需对具有同一哈希值的新滚动序列和先前滚动序列的实际数据项进行比较以确定匹配项。如果检测到匹配,则表明新滚动序列与匹配的先前滚动序列相同,新滚动序列可以不包含在压缩输出数据流130中,而是被指向匹配的先前滚动序列的位置的指针所替代。该指针可置于压缩输出数据流130中的被替代的滚动序列需要被插入的合适位置处。如果没有检测到匹配,则滚动序列包含在压缩输出数据流130中。在对哈希表进行搜索后,可相应地更新哈希表。如果没有匹配,则可更新哈希表以包含针对新滚动序列计算的新哈希值。如果所有哈希表项都被占用,则可从哈希表中省略与先前的滚动序列相关的一个或多个哈希值,例如匹配频率最低的哈希表项等。
历史数组114的大小,例如可用于比较的先前滚动序列的数量,是可变的。在一个大型历史数组114例如包括更多可用于比较的先前滚动序列的情况下,匹配概率增加,从而使得压缩得到改进。然而,历史数组114越大,就需要越多的搜索操作和/或存储器资源,因此增加了用于压缩的处理资源和/或处理时间。对于大多数压缩方法,历史数组116的大小通常是2KB、4KB、8KB、16KB和/或32KB,以实现压缩效率与所耗处理和/或存储器资源之间的最佳权衡。
通常,压缩方法采用串行序列来为每个滚动序列计算哈希值,搜索哈希表并相应地更新哈希表。另一方面,压缩过程200可使用SIMD引擎106来并发执行计算、搜索和/或更新操作中的一个或多个以加快压缩过程200。
如204处所示,压缩器112在存储器108中创建历史数组114以存储最新子集。历史数组114的典型大小是2KB、4KB、8KB、16KB和/或32KB。可根据处理资源的可用性和/或存储器108的大小为历史数组114分配其它大小。压缩器112还在存储器108中创建哈希表116以存储哈希表项,哈希表项包括指向存储在历史数组114中的子集之一的指针和针对相关子集计算的哈希值。理所当然,最初,在压缩过程200的开始处,历史数组114和哈希表116为空,并且随着滑动窗口应用到输入数据流120而逐渐被子集(滚动序列)填满。
如206处所示,压缩器112将滚动窗口应用到输入数据流120。该窗口的大小决定每个子集的大小,可根据处理器104的架构和/或SIMD引擎106的架构进行调整。压缩器112在输入数据流120上滑动该滑动窗口,使得在窗口的每次滑动(移位)期间,省略前一滚动序列的最早(第一个)数据项并增加一个新的数据项以创建一个新滚动序列。
如208处所示,压缩器112使用SIMD引擎106为每个新滚动序列计算哈希值。为了支持滚动序列的并发处理,将滚动序列分解为多个被处理子集,每个子集包括该滚动序列的连续数据项。使用SIMD引擎106对被处理子集的组(滚动序列)进行并发处理。该组中被处理子集的数量可根据处理器104的架构和/或SIMD引擎106的架构进行调整。压缩器112将被处理子集加载到SIMD引擎106的一个或多个寄存器以计算每个子集的哈希值。压缩器112发布给SIMD引擎的加载指令的类型、概要、特性和/或用法可根据处理器104和/或SIMD引擎106的架构进行调整。
现参考图3A,图3A是根据本发明一些实施例的用于将输入数据流的多个连续字节同时加载到SIMD引擎的寄存器中的示例性序列的示意图。还参考图3B,图3B是根据本发明一些实施例的使用SIMD引擎针对一组子集同时计算哈希值的示例性序列的示意图,其中每个子集包括输入数据流的连续字节。在示例性加载序列300期间,压缩器,例如压缩器112,将连续数据项310加载到SIMD引擎106的四个寄存器302A至302D,这样每个连续寄存器将包含按一个项目滑动的数据的窗口。加载到寄存器302的连续数据项的数目决定了每个被处理子集的大小和/或子集组的大小。图3A中显示的示例性序列描述了使用16字节架构的SIMD引擎,例如,每个寄存器是16字节宽,从而支持一组8个子集的并发处理,例如计算8个哈希值320,其中每个哈希值是针对一个包括4个连续数据项310的子集计算的。如稍后将描述的,需要将这些数据项310分隔以支持SIMD引擎106并发计算8个哈希值320。分隔数据项310使得每个字节(8位)占用一个字(16位)的空间,这样32个数据项310占用四个16字节的寄存器,以符合示例性SIMD引擎106的寄存器宽度。SIMD引擎106的其它架构,例如32、64、128、256字节等,可支持将不同数量的连续数据项310加载到SIMD引擎106的寄存器302。由于哈希值320是针对每4个连续数据项310而计算的,所以加载到SIMD引擎106的32个字节由11个连续数据项SK 310A至SK+10 310K组成。
假设处理器104是例如采用单一指令多数据流扩展(Streaming SIMD Extensions,SSE)指令集对16字节的SIMD引擎106进行操作的INTEL架构(Intel Architecture,IA)处理器,则加载32个字节的操作可能需要8个指令。
在加载操作中,压缩器112将数据项字节(8位)转换为字(16位),使得每个数据项占用一个字的空间,如图3B所示。
压缩器112指示SIMD引擎106对加载到寄存器302中的数据项310进行移位。对寄存器部分302A至302D中的每一个应用不同的移位,使得:
-存储在寄存器部分302A中的数据项SK 310A至SK+7 310H向左移动6位。
-存储在寄存器部分302B中的数据项SK+1 310B至SK+8 310I向左移动4位。
-存储在寄存器部分302C中的数据项SK+2 310C至SK+9 310J向左移动2位。
-存储在寄存器部分302D中的数据项SK+3 310D至SK+10 310K保持不动。
应用到寄存器302的移位程度取决于加载到寄存器302中的连续数据项310的数量,因此移位程度取决于SIMD引擎106的架构。
在加载序列300之后的示例性处理序列301期间,压缩器112可指示SIMD引擎106针对每个被处理子集并发计算330哈希值320。压缩器112发布给SIMD引擎的计算指令的类型、概要、特性和/或用法可根据处理器104和/或SIMD引擎106的架构进行调整。哈希值320的计算330可以是对连续数据项310的子集执行的简单XOR运算。连续数据项310的子集称为被处理子集。每个被处理子集包括4个连续数据项310,例如,第一被处理子集包括数据项SK310A至SK+3 310D,第二被处理子集包括数据项SK+1 310B至SK+4 310E,等等,直到最后一个被处理子集包括数据项SK+7 310I至SK+10 310K。
SIMD引擎106通过对包含在每个被处理子集中的相应4个数据项310应用计算330来针对所有被处理子集并发计算哈希值320,计算330可以是一个简单的XOR运算。针对提供的示例性序列和SIMD引擎106的架构,SIMD引擎106产生8个哈希值320,哈希值320A对应数据项SK 310A至SK+3 310D,哈希值320B对应数据项SK+1 310B至SK+4 310E,哈希值320C对应数据项SK+2 310C至SK+5 310F,哈希值320D对应数据项SK+3 310D至SK+6 310G,哈希值320E对应数据项SK+4 310E至SK+7 310H,哈希值320F对应数据项SK+5 310F至SK+8 310I,哈希值320G对应数据项SK+6 310G至SK+9 310J,哈希值320H对应数据项SK+7 310H至SK+10 310K。计算出的哈希值320存储在SIMD引擎106的寄存器304中。
假设处理器104是例如采用SSE指令集对16字节的SIMD引擎106进行操作的IA处理器,则计算32个哈希值320可能需要6个指令。
再次参考图2。如210处所示,压缩器112通过将每个计算出的哈希值320与哈希表116的哈希表项中的多个可用哈希值中的每一个进行比较,来搜索每个计算出的哈希值320的匹配项。如果在哈希表116的一个哈希表项中找到相同的哈希值,则找到了针对一个计算出的哈希值320的匹配。压缩器112可发布指令以指示SIMD引擎106并发搜索哈希表116以查找每个计算出的哈希值320的匹配项。压缩器112发布给SIMD引擎的搜索指令的类型、概要、特性和/或用法可根据处理器104和/或SIMD引擎106的架构进行调整。例如,对于IA处理器104,压缩器112可使用来自SSE指令集的如以下函数1中出现的“聚集(gather)”指令来指示SIMD引擎106执行搜索操作。
函数1:
void__m512i_m512_132gather_epi32(__m512i vindex,void const*base_addr,int scale)
概要:
void__m512i_m512_132gather_epi32(__m512i vindex,void const*base_addr,int scale)
#include“immintrin.h”
指令:vpgatherdd zmm32z{k},vm32z
CPUID标志:对于AVX-512是AVX512F,对于KNC是KNCNI
描述:
使用32位的索引从存储器中聚集32位的整数。将32位的元素从始于base_addr的地址加载,并按vindex中的每个32位元素偏移(每个索引按scale中的因子进行缩放),scale应为1、2、4或8。
运算:
FOR j:=0to 15
i:=j*32
dst[i+31:i]:=MEM[base_addr+SignExtend(vindex[i+31:i])*scale]
ENDFOR
Dst[MAX:512]:=0
压缩器112可发布如下文的伪码片段1中所表达的“聚合”指令来指示SIMD引擎106执行搜索操作。
伪码片段1:
Result[i]=hashTable[hashes[i]]for i in 0…15
如212处所示,如果一个或多个计算出的哈希值320与哈希表116中存储的哈希值之一匹配,则压缩器112可开始进一步比较以确定被处理子集是否与包含该匹配的已存储哈希值的哈希表项所指向的相关子集相同。该进一步比较可能是需要的,因为压缩器112使用的哈希函数计算330可以是一种可能出现不明确结果的简单XOR运算,例如,可能为具有不同数据项310的不同子集计算出相同的哈希值320。进一步比较包括将被处理子集中包含的数据项310与相关子集中包含的数据项310进行比较,其中该相关子集与哈希表116中的匹配的已存储哈希值相关。如果被处理子集和相关子集的数据项310相似,则压缩器112发布被处理子集的匹配指示。
现参考图4,图4是根据本发明一些实施例的使用SIMD引擎对哈希表进行同时搜索以查找多个哈希值的匹配项的示例性序列的示意图。在示例性搜索序列400期间,压缩器112等压缩器指示SIMD引擎106等SIMD引擎对哈希表116等哈希表进行并发搜索以查找哈希值320等多个计算出的哈希值与哈希表项402中存储的哈希值的匹配项。示例性序列400遵循先前的示例性加载序列300和示例性并发计算序列301的示例。SIMD引擎106并发启动8个比较操作450以将存储在寄存器304中的每个计算出的哈希值320与在哈希值116的哈希表项402中可用的每个已存储哈希值进行比较。每个搜索操作与计算出的哈希值320之一相关,例如,搜索操作450A与计算出的哈希值320A相关,搜索操作450B与计算出的哈希值320B相关,等等,直到搜索操作450H与计算出的哈希值320H相关。如示例性搜索序列400中所见,在搜索操作450A中,在相应的计算出的哈希值320A之间未发现匹配。但是在哈希表116中检测到空哈希表项402G。在搜索操作450B中,在相应的计算出的哈希值320B与存储在哈希表项402C中的哈希值之间发现匹配。在搜索操作450H中,在相应的计算出的哈希值320H与存储在哈希表项402K中的哈希值之间检测到另一匹配。由于SIMD引擎106使用的哈希函数计算330可以是对数据项310执行的一个简单的XOR运算,所以哈希值320可能是不明确的。因此,需要将被处理子集的和与哈希表116中的匹配的已存储哈希值相关的子集的实际数据项310进行比较以确定确切的匹配。压缩器112可为历史数组114中的每个匹配的计算出的哈希值320启动比较操作460。例如,SIMD引擎106指示计算出的哈希值320B与哈希表项402C中存储的哈希值之间的匹配。因此,压缩器启动比较操作460A来比较与哈希表项402C相关的数据集的数据项310。例如,假设哈希表项402C与开始于数据项SK-5 310P的子集相关,则压缩器112将(产生哈希值320B的)数据项SK+1 310B至SK+4 310E与相应的数据项SK-5 310P至SK-2 310M进行比较以确定匹配。如果数据项SK+1 310B至SK+4 310E类似于数据项SK-5 310P至SK-2 310M,则压缩器112可指示匹配。类似地,压缩器112启动比较操作460B来比较与哈希表项402K相关的数据集的数据项310。例如,假设哈希表项402K与开始于数据项SK-3 310N的子集相关,则压缩器112将(产生哈希值320H的)数据项SK+7 310H至SK+10 310K与相应的数据项SK-3 310N至SK 310A进行比较以确定匹配。如果数据项SK+7 310H至SK+10 310K类似于数据项SK-3 310N至SK 310A,则压缩器112可指示匹配。
再次参考图2。如214处所示,压缩器112根据匹配结果更新哈希表116。压缩器112可发布指令以指示SIMD引擎106使用与一个或多个被处理子集相关的新哈希表项402来并发更新哈希表项402中的相应的一个或多个。即,每个新哈希表项402包括针对相应子集计算出的哈希表项320和指向历史数组114中的相应子集的指针。在一个或多个场景中,可使用一种或多种更新方案来更新哈希表116。在一种方案中,所有被处理子集都与哈希表116中的表项相关。然而,如果例如哈希表116包含的哈希表项402比并发处理的子集的数量多,则压缩器112可应用一种或多种方案来更新哈希表116。例如,如果在SIMD引擎106的匹配搜索操作中检测到一个或多个空哈希表项,例如哈希表项402,则可更新一个或多个哈希表项402中的每个空哈希表项以便与被处理子集之一相关。这意味着创建相应的哈希表项402以包含计算出的哈希值,例如相应被处理子集的计算出的哈希值320,以及指向第一数据项的指针,例如指向被处理子集的数据项310的指针。
在另一种场景中,在SIMD引擎106的匹配搜索操作中,一个或多个计算出的哈希值320与存储在哈希表116中的一个或多个哈希值匹配。然而,在比较操作之后,压缩器112指示被处理子集的内容(数据项)与(匹配的哈希表项所指向的)相关子集的内容(数据项)不同。在这种情况下,压缩器112可通过指向被处理子集的第一个数据项310的指针来更新哈希表116中的相应哈希表项402。哈希值自然是相同的,因此压缩器112不改变哈希值。
压缩器112还可应用一种或多种方法和/或技术来丢弃一个或多个哈希表项402以支持新创建的哈希表项402,该新创建的哈希表项包括与最近的子集相关的新计算出的哈希值320。
压缩器112发布给SIMD引擎的更新指令的类型、概要、特性和/或用法可根据处理器104和/或SIMD引擎106的架构进行调整。例如,对于IA处理器104,压缩器112可使用来自SSE指令集的如以下函数2中出现的“分散(scatter)”指令来指示SIMD引擎106在哈希表116中执行更新操作。
函数2:
void__m512i_m512_132scatter_epi32(void*base_addr,__m512i vindex,__512i a,int scale)
概要:
void__m512i_m512_132scatter_epi32(void*base_addr,__m512i vindex,__512i a,int scale)
#include“immintrin.h”
指令:vpscatterdd vm32{k},zmm
CPUID标志:对于AVX-512是AVX512F,对于KNC是KNCNI
描述:
使用32位索引将32位的整数从a分散到存储器中。将32位元素存储于始于base_addr的地址处,并按vindex中的每个32位元素偏移(每个索引按scale中的因子进行缩放),scale应为1、2、4或8。
运算:
FOR j:=0to 15
i:=j*32
MEM[base_addr+SignExtend(vindex[i+31:i])*scale]:=a[i+31:i]
ENDFOR
压缩器112可发布如下文的伪码片段2中所表达的分散指令来指示SIMD引擎106执行更新操作。
伪码片段2:
hashTable[hashes[i]]=position[i]for i in 0…15
现参考图5,图5是根据本发明一些实施例的使用SIMD引擎来同时更新多个哈希表项的示例性序列的示意图。在针对哈希表116等哈希表的示例性更新序列500期间,压缩器112等压缩器指示SIMD引擎106等SIMD引擎通过哈希表项402等一个或多个新哈希表项来并发更新哈希表116。示例性序列500遵循先前的示例性加载序列300、示例性并发计算序列301和示例性并发搜索序列400的示例。SIMD引擎106并发启动8个更新操作510以通过更新后的哈希值和指向被处理子集的更新后的指针来更新哈希表项402。SIMD引擎106通过计算出的哈希值320中的相应一个和指向与该计算出的哈希值320相关的相应子集的第一个数据项310的指针来更新每个更新后的哈希表项402。如示例性更新序列500中所示,SIMD引擎106并发启动8个更新操作510以更新哈希表116中的8个哈希表项402。例如,更新操作510A用于通过针对包括数据项SK 310A至SK+3 310D的被处理子集而计算的计算出的哈希值320A并通过指向数据项SK 310A的更新后的指针来更新哈希表项402G,其中数据项SK 310A是该被处理子集的第一个数据项310。在更新操作510A之后,包括数据项SK 310A至SK+3 310D的被处理子集被视为相关子集。类似地,更新操作510B用于通过针对包括数据项SK+1 310B至SK+4 310E的被处理子集而计算的计算出的哈希值320B并通过指向数据项SK+1 310B的更新后的指针来更新哈希表项402C,其中数据项SK+1 310B是该被处理子集的第一个数据项310。在更新操作510B之后,包括数据项SK+1 310B至SK+4 310E的被处理子集被视为相关子集。并发更新操作510对所有被处理子集都相似,一直到用于更新哈希表项402K的更新操作510H。在更新操作510H中,通过针对包括数据项SK+7 310H至SK+10 310K的被处理子集而计算的计算出的哈希值320H并通过指向数据项SK+7 310H的更新后的指针来更新哈希表项402K,其中数据项SK+7 310H是该被处理子集的第一个数据项310。在更新操作510H之后,包括数据项SK+7 310H至SK+10 310K的被处理子集被视为相关子集。
再次参考图2。如216处所示,压缩器112通过被处理子集来更新压缩输出流130。对于被指为与输入数据流120中的一个相关子集(先前子集)匹配(具有相同的数据项310)的每个被处理子集,压缩器112在压缩输出流130中使用指向相关子集的位置的指针来替代该被处理子集。对于被指为与输入数据流120中的任何相关子集(先前的子集)都不匹配的每个被处理子集,压缩器112将该被处理子集自身放置在压缩输出流130中。
如决策点218处所示,压缩器112检查输入数据流120中是否有可用的附加数据项。如果检测到附加数据项310,则过程200分岔到步骤206,并针对附加子集组重复步骤206至216。如果压缩器112确定已到达输入数据流120的末尾,则过程200分岔到220。
如220处所示,在压缩器112处理输入数据流120之后,压缩器112使用I/O接口102等输出压缩输出流130。
压缩输出数据流130的格式可兼容通过如本领域已知的传统(标准)压缩方法,特别是应用按序压缩的方法,为输入数据流120创建的压缩数据流。压缩输出数据流130的这种兼容支持使用如本领域已知的标准解压方法、技术和/或工具来对压缩输出数据流130进行解压。自然地,可选择压缩器112使用的压缩格式作为解压格式。例如,如果压缩输出数据流130符合LZ4压缩数据格式,则可能需要标准的LZ4解压方法、技术和/或工具来对压缩输出数据流130进行解压。
示例
现参考以下示例,这些示例和以上描述一起以一种非限制性方式阐明了本发明。
使用SIMD引擎,例如SIMD引擎106,进行多次实验来验证压缩过程所提供的性能改进。在实验期间,使用如本领域当前已知的(传统方法)LZO压缩算法来压缩一个典型的输入数据流,例如输入数据流120,LZO压缩算法被连续应用到该输入数据流。还使用SIMD引擎106,使用如过程200所应用的简单的压缩算法来压缩同一个典型的输入数据流120,以并发计算330哈希值320和搜索哈希表116。通过使用16字节的SIMD架构的Intel将两种压缩方法(传统和过程200)在3.0GHz操作频率的高级矢量扩展指令集(Advanced Vector Extensions,AVX)处理器上执行。上述实验针对如下各压缩比进行:1.0、2.3和3.8。实验结果在以下表1中显示。
表1:
表1表明,与传统(标准)压缩过程相比,使用SIMD引擎106的压缩过程200呈现出了约40%的明显性能改进。
对本发明各个实施例的描述只是为了说明的目的,而这些描述并不旨在穷举或限于所公开的实施例。在不脱离所描述的实施例的范围和精神的情况下,本领域技术人员可以清楚理解许多修改和变化。相比于市场上可找到的技术,选择此处使用的术语可最好地解释本实施例的原理、实际应用或技术进步,或使本领域其他技术人员理解此处公开的实施例。
预期在从本申请开始走向成熟的专利的生命周期中,将会开发出许多相关向量处理技术,例如SIMD,术语SIMD的范围旨在包括所有这类先验新技术。
本文使用的术语“约”是指±10%。
术语“包括”以及“有”表示“包括但不限于”。这个术语包括了术语“由……组成”以及“本质上由……组成”。
短语“本质上由……组成”是指构造或方法可包括额外的材料和/或步骤,但前提是这些额外的材料和/或步骤不会实质上改变所要求保护的构造或方法的基本和新颖特性。
除非上下文中另有明确说明,此处使用的单数形式“一个”和“所述”包括复数含义。例如,术语“一个复合物”或“至少一个复合物”可以包括多个复合物,包括其混合物。
此处使用的词“示例性”表示“作为一个例子、示例或说明”。任何“示例性的”实施例并不一定理解为优先于或优越于其它实施例,和/或并不排除其它实施例特点的结合。
此处使用的词语“可选地”表示“在一些实施例中提供且在其它实施例中没有提供”。本发明的任意特定的实施例可以包括多个“可选的”特征,除非这些特征相互矛盾。
在整个本申请案中,本发明的各种实施例可以范围格式呈现。应理解,范围格式的描述仅为了方便和简洁起见,并且不应该被解释为对本发明范围的固定限制。因此,对范围的描述应被认为是已经具体地公开所有可能的子范围以及所述范围内的个别数值。例如,对例如从1到6的范围的描述应被认为是已经具体地公开子范围,例如从1到3、从1到4、从1到5、从2到4、从2到6、从3到6等,以及所述范围内的个别数字,例如1、2、3、4、5和6。不管范围的宽度如何,这都适用。
当此处指出一个数字范围时,表示包括了在指出的这个范围内的任意所列举的数字(分数或整数)。短语“在第一个所指示的数和第二个所指示的数范围内”以及“从第一个所指示的数到第二个所指示的数范围内”和在这里互换使用,表示包括第一个和第二个所指示的数以及二者之间所有的分数和整数。
单个实施例也可以提供某些特征的组合,这些特征在各个实施例正文中有简短的描述。相反地,本发明的各个特征在单个实施例的正文中有简短的描述,也可以分别提供这些特征或任何适合的子组合或者作为本发明所述的任何合适的其它实施例。不可认为各个实施例的正文中描述的某些特征是这些实施例的必要特征,除非没有这些元素,该实施例无效。
此处,本说明书中提及的所有出版物、专利和专利说明书都通过引用本说明书结合在本说明书中,同样,每个单独的出版物、专利或专利说明书也具体且单独地结合在此。此外,对本申请的任何参考的引用或识别不可当做是允许这样的参考在现有技术中优先于本发明。就使用节标题而言,不应该将节标题理解成必要的限定。
- 还没有人留言评论。精彩留言会获得点赞!