一种用于VLSI设计的Huffman编码系统及其实现方法与流程
本发明涉及编码系统领域,特别是涉及一种用于vlsi设计的huffman编码实现系统及其实现方法。
背景技术:
目前,在对芯片面积、编码速率和压缩效率要求较高的数据无损压缩系统如视频和图像编码系统等一些领域,基于动态huffman编码或者传统静态huffman编码芯片已经很难满足要求。huffman编码属于最佳熵编码法的同时也是一种前缀码,其数据压缩效率最高。为了提高编码压缩效率的需要通常可采用动态huffman编码或者静态huffman编码二种方案。
动态huffman编码对输入字符的统计是动态进行的,随着待压缩数据的输入,逐步构造huffman树,因此随着编码的进行,同一个字符的编码可能发生改变(变得更长或更短)。动态huffman编码算法中每输入一个字符就要更新一次huffman树,这也导致动态huffman编码算法非常复杂,需要更多的寄存器和逻辑运算电路。在待压缩数据量不大时,由于不用预先统计待压缩数据中每种字符的频数,相对静态huffman编码可以节约时钟周期,但随着待压缩数据量的增加,消耗在更新huffman树上的时钟周期数急剧增加,降低了系统编码速率,不适合对编码速率要求较高且数据量巨大的编码系统。
此外,编码系统通常应该具有与之对应的同样优秀的解码系统才更具有实用价值,然而动态huffman编码系统每编码完一个字符,解码系统都必须使用和编码系统相同的算法更新huffman树后才能解压缩一个字符,解压缩效率的低下也导致动态huffman编码实际应用并不广泛。
静态huffman编码系统通过对待压缩数据的一次扫描,统计每种字符的出现频数后构造huffman树并得到每个字符对应的的编码,再对一次扫描中存储的待压缩数据进行遍历得到输出码流。在具备高速率编码功能的同时无需额外的存储器或复杂逻辑运算电路结构,节约芯片面积的同时也保证了整体编码系统的稳定性,这些特点使得其在对编码速率要求较高且数据量巨大的编码系统应用中成为一个很好的选择方案。
然而传统静态huffman编码系统一般是利用高级编程语言如c/c++语言中丰富的数据结构(如结构体变量和枚举变量)来描述构造huffman树过程中每一个节点的数据特性(如频数、节点位置关系、在huffman树中所处层数)并在软件开发平台上完成。在vhdl/veriloghdl硬件描述语言中并没有高级编程语言中类似结构体或枚举的数据结构,无法将传统静态huffman编码直接移植到vlsi设计中。
因此,若想要实现适用于vlsi设计的huffman编码系统,首先必须要在兼顾编码速率、芯片面积和系统功能稳定性的前提下,结合静态huffman树的构造过程提出了一种新的适合huffman编码器电路实现的数据格式
另一个问题是传统静态huffman编码系统中采用先构造huffman树后编码的算法不适合硬件电路实现且效率很低,因此必须改进静态huffman编码系统中构造huffman树的算法。新算法必须要在构造huffman树的过程中完成每次从队列里递归找到最小的两个节点,并且前一次的递归运算结果作为后一次的输入的同时完成对节点的编码,即在构造huffman树的过程中完成所有节点的编码。最后根据新的数据格式特点,在huffman树所有节点中快速匹配找到叶子节点及其对应的编码。
技术实现要素:
有鉴于此,本发明的目的是提供一种用于vlsi设计的huffman编码系统及其实现方法,可用于vlsi设计的对编码速率要求较高且待压缩数据量巨大的无损压缩编码系统。
本发明采用以下方案实现:一种用于vlsi设计的huffman编码系统,包括:
一复位信号检测单元,用以在系统运行时检测到复位信号使能后,使系统异步复位,并重新初始化编码系统;
一开始信号检测单元,用以当复位信号未使能且开始信号有效时启动编码系统,编码系统开始运行;
一输入数据扫描单元,用以对输入的待压缩数据进行扫描;
一输入数据缓存单元,用于保存扫描后的待压缩数据;
一码字频数缓存单元,用以保存待压缩数据中每种字符和它出现的频数;
一数据拼接单元,用以将频数、识别、字符、编码这四种寄存器变量按顺序拼接成与输入字符种类数目相同的寄存器变量;
一拼接数据缓存单元,用以保存拼接后的数据;
一huffman树节点生成单元,用以按静态huffman树生成节点的构造方法生成所有节点;
一huffman树节点缓存单元,用以存放生成的huffman树的所有节点数据;
一huffman树构造编码单元,用以将生成的所有节点从上到下逐层构造huffman树,并在构造huffman树的同时完成对所有节点的编码;
一叶子节点识别单元,用以从huffman树的所有节点中识别出叶子节点及其对应的编码;
一根节点编码位去除单元,用以去掉每个叶子节点所对应编码中的根节点编码位,去掉每个叶子节点所对应编码中的根节点编码位;
一huffman码表建立单元,用以建立huffman码表并得到每个叶子节点所对应编码的长度;
一编码输出单元,用以根据huffman码表按位输出编码结果;
一编码输出结束标志单元,用以表示编码输出是否结束;
一返回开始信号检测单元,用以重新检测开始信号,等待编码系统再次运行。
本发明还采用以下方案实现:一种用于vlsi设计的huffman编码系统的实现方法,包括下述步骤:
步骤s1:所述编码系统运行时对复位信号是否使能进行实时检测,若检测到复位信号使能,则使系统异步复位,并重新初始化编码系统;
步骤s2:当复位信号未使能且开始信号有效时,启动编码系统,开始扫描输入的待压缩数据;
步骤s3:对输入的待压缩数据进行一遍扫描,将输入的待压缩数据送入输入数据缓存单元,通过加法器实现每一种字符出现的频数进行统计,将频数统计结果送入码字频数缓存单元,将待压缩数据保存入寄存器中;
步骤s4:将字符、频数这两种寄存器变量与识别、编码这两种寄存器变量,依次按频数、识别、字符、编码的顺序分配一定位宽后拼接成与输入字符种类数目相同的寄存器变量,此时初始时识别、编码位均为零,并送入拼接数据缓存单元保存;
步骤s5:将按照新数据格式构造的数据,采用静态huffman树生成节点的算法递归生成所有节点;
步骤s6:对根节点编码1并初始化第一层的两个节点的编码,用第一层的节点匹配出下一层的节点,从上到下逐层构造出huffman树,并在构造huffman树的同时对所有节点进行编码;
步骤s7:对huffman树中所有的节点进行识别,找出所有叶子节点及其对应的编码;
步骤s8:去掉每个叶子节点所对应编码中的根节点编码位,得到每个叶子节点所对应编码的长度,根据最后得到的叶子节点的编码和编码长度,建立huffman码表;
步骤s9:按照huffman码表按位输出编码结果,编码结果全部输出后,编码输出结束标志单元置1,编码输出结束;
步骤s10:返回开始信号检测,为系统下一次开始编码进行初始化。
进一步地,所述步骤s4中,数据拼接单元对给定的总共m个n种字符(a0~an-1)和每种字符对应的频数、识别和编码进行拼接,其中拼接的数据格式总位宽,由低位至高位依次是编码n位,字符
进一步地,所述步骤s5包括以下步骤:
步骤s51:生成huffman树中所有节点,huffman树节点生成单元在集合f所有的节点中选取两个最小的节点相加,生成一个新节点,将新节点的识别位加1;
步骤s52:在f中删除已选取的两个最小节点,并将生成的新节点加入到集合f中;
步骤s53:返回步骤s51,重复步骤s51与步骤s52,直到集合f中只剩两个节点为止,最后两个节点相加及得到根节点后即生成了huffman树中所有节点;将所有生成的huffman树的节点数据存储于huffman树节点缓存单元,此时节点生成的先后顺序就是节点数据按升序排列的顺序。
进一步地,所述步骤s6中构造huffman树,首先huffman树构造编码单元对根节点编码1,然后根据所有节点生成的从后往前顺序,从最晚生成的节点开始,检测每一个节点是否是由在它生成之前的两个节点相加而成,如果是,将当前检测节点的识别位加1,如果不是,则当前检测节点是叶子节点,开始检测下一个节点;在构造huffman树的同时,huffman树构造编码单元根据每个节点在huffman树上的位置,得到所有节点的huffman编码。
进一步地,所述步骤s7中,遍历huffman树的所有节点,叶子节点识别单元将识别出所有的叶子节点,同时得到了叶子节点的编码,也就是输入数据的编码,此时的编码还不是真实的huffman编码,由于每个编码的最高位是根节点的编码位,在最后的编码结果中,这一位是冗余的。
进一步地,所述步骤s8中,根节点编码位去除单元将所有叶子节点对应编码的最高位去除,也就是将根节点的编码位去除,得到了每个叶子节点真实的huffman编码;则此时huffman码表建立单元根据每个叶子节点所表示的字符和它对应的编码建立huffman码表,并且记录下每个叶子节点对应huffman编码的编码长度,也就是最后每个编码输出结果的编码长度。
进一步地,所述步骤s9中,编码输出单元遍历输入数据缓存单元中保存的待压缩数据,根据huffman码表建立单元创建的huffman码表对输入的待压缩码流数据进行编码,得到编码后的码流;然后编码输出单元从高位到地位,依次按位串行输出码流的编码结果。
相较于现有技术,本发明具有以下有益效果:本发明通过veriloghdl硬件描述语言完成了用于vlsi设计的huffman编码实现系统,并在huffman编码实现过程中,提出了一种新的数据格式用于构造huffman树并对所有节点编码,采用了新的快速算法实现了构造huffman树和得到节点编码可以同时进行等创新技术,大量逻辑和算术运算使用veriloghdl硬件描述语言实现的递归电路中,使得该发明可用于vlsi设计的对编码速率要求较高且待压缩数据量巨大的无损压缩编码系统。另外,本发明通过对原有静态huffman编码过程的优化,简化了编码的步骤,提高了编码的可读性和可维护性,节约了电路面积。其次,采用了更加快速的统计字符方法以及同时完成建树和编码的技术,使得数据的吞吐率有了较大提升,提高了编码的效率,减小了电路的面积。除此之外,采用了提前清空单元缓存的技术,有利于降低电路的噪声和干扰。最后,本发明在编码过程中使用了新的huffman编码的方法,使编码过程更加灵活、快速、高效。该编码设计兼顾了功耗、速度等方面的性能,适合超大规模集成电路实现、数字信号处理、数字图像处理以及数据传输等领域。
附图说明
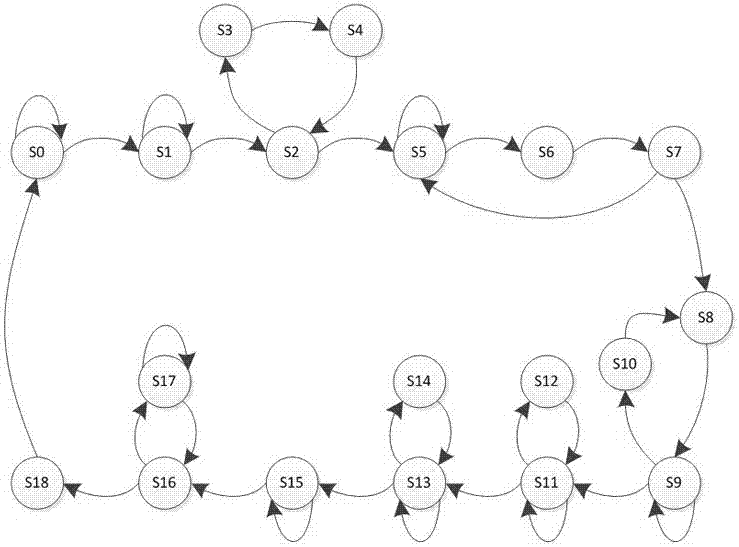
图1是本发明的一种用于vlsi设计的huffman编码系统的状态转换图。
图2是本发明的一种用于vlsi设计的huffman编码系统的数据格式图。
图3是本发明的一种用于vlsi设计的huffman编码系统的设计流程图。
图4是本发明的huffman编码的仿真电路时序说明图。
图5是本发明的huffman编码时钟周期的modelsim仿真结果图。
图6是本发明的huffman编码结果输出的modelsim仿真结果图。
具体实施方式
下面结合附图及实施例对本发明做进一步说明。
本实施例提供一种用于vlsi设计的huffman编码系统,包括:
一复位信号检测单元,用以在系统运行时检测到复位信号使能后,使系统异步复位,并重新初始化编码系统;
一开始信号检测单元,用以当复位信号未使能且开始信号有效时启动编码系统,编码系统开始运行;
一输入数据扫描单元,用以对输入的待压缩数据进行扫描;
一输入数据缓存单元,用于保存扫描后的待压缩数据;
一码字频数缓存单元,用以保存待压缩数据中每种字符和它出现的频数;
一数据拼接单元,用以将频数、识别、字符、编码这四种寄存器变量按顺序拼接成与输入字符种类数目相同的寄存器变量;
一拼接数据缓存单元,用以保存拼接后的数据;
一huffman树节点生成单元,用以按静态huffman树生成节点的构造方法生成所有节点;
一huffman树节点缓存单元,用以存放生成的huffman树的所有节点数据;
一huffman树构造编码单元,用以将生成的所有节点从上到下逐层构造huffman树,并在构造huffman树的同时完成对所有节点的编码;
一叶子节点识别单元,用以从huffman树的所有节点中识别出叶子节点及其对应的编码;
一根节点编码位去除单元,用以去掉每个叶子节点所对应编码中的根节点编码位,去掉每个叶子节点所对应编码中的根节点编码位;
一huffman码表建立单元,用以建立huffman码表并得到每个叶子节点所对应编码的长度;
一编码输出单元,用以根据huffman码表按位输出编码结果;
一编码输出结束标志单元,用以表示编码输出是否结束;
一返回开始信号检测单元,用以重新检测开始信号,等待编码系统再次运行。
在本实施例中,一种用于vlsi设计的huffman编码系统的实现方法,包括下述步骤:
步骤s1:所述编码系统运行时对复位信号是否使能进行实时检测,若检测到复位信号使能,则使系统异步复位,并重新初始化编码系统;
步骤s2:当复位信号未使能且开始信号有效时,启动编码系统,开始扫描输入的待压缩数据;
步骤s3:对输入的待压缩数据进行一遍扫描,将输入的待压缩数据送入输入数据缓存单元,通过加法器实现每一种字符出现的频数进行统计,将频数统计结果送入码字频数缓存单元,将待压缩数据保存入寄存器中;
步骤s4:将字符、频数这两种寄存器变量与识别、编码这两种寄存器变量,依次按频数、识别、字符、编码的顺序分配一定位宽后拼接成与输入字符种类数目相同的寄存器变量,此时初始时识别、编码位均为零,并送入拼接数据缓存单元保存;
步骤s5:将按照新数据格式构造的数据,采用静态huffman树生成节点的算法递归生成所有节点;
步骤s6:对根节点编码1并初始化第一层的两个节点的编码,用第一层的节点匹配出下一层的节点,从上到下逐层构造出huffman树,并在构造huffman树的同时对所有节点进行编码;
步骤s7:对huffman树中所有的节点进行识别,找出所有叶子节点及其对应的编码;
步骤s8:去掉每个叶子节点所对应编码中的根节点编码位,得到每个叶子节点所对应编码的长度,根据最后得到的叶子节点的编码和编码长度,建立huffman码表;
步骤s9:按照huffman码表按位输出编码结果,编码结果全部输出后,编码输出结束标志单元置1,编码输出结束;
步骤s10:返回开始信号检测,为系统下一次开始编码进行初始化。
在本实施例中,所述步骤s4中,数据拼接单元对给定的总共m个n种字符(a0~an-1)和每种字符对应的频数、识别和编码进行拼接,其中拼接的数据格式总位宽,由低位至高位依次是编码n位,
字符
在本实施例中,所述步骤s5包括以下步骤:
步骤s51:生成huffman树中所有节点,huffman树节点生成单元在集合f所有的节点中选取两个最小的节点相加,生成一个新节点,将新节点的识别位加1;
步骤s52:在f中删除已选取的两个最小节点,并将生成的新节点加入到集合f中;
步骤s53:返回步骤s51,重复步骤s51与步骤s52,直到集合f中只剩两个节点为止,最后两个节点相加及得到根节点后即生成了huffman树中所有节点;将所有生成的huffman树的节点数据存储于huffman树节点缓存单元,此时节点生成的先后顺序就是节点数据按升序排列的顺序。
在本实施例中,所述步骤s6中构造huffman树,首先huffman树构造编码单元对根节点编码1,然后根据所有节点生成的从后往前顺序,从最晚生成的节点开始,检测每一个节点是否是由在它生成之前的两个节点相加而成,如果是,将当前检测节点的识别位加1,如果不是,则当前检测节点是叶子节点,开始检测下一个节点;在构造huffman树的同时,huffman树构造编码单元根据每个节点在huffman树上的位置,得到所有节点的huffman编码。
在本实施例中,所述步骤s7中,遍历huffman树的所有节点,叶子节点识别单元将识别出所有的叶子节点,同时得到了叶子节点的编码,也就是输入数据的编码,此时的编码还不是真实的huffman编码,由于每个编码的最高位是根节点的编码位,在最后的编码结果中,这一位是冗余的。
在本实施例中,所述步骤s8中,根节点编码位去除单元将所有叶子节点对应编码的最高位去除,也就是将根节点的编码位去除,得到了每个叶子节点真实的huffman编码;则此时huffman码表建立单元根据每个叶子节点所表示的字符和它对应的编码建立huffman码表,并且记录下每个叶子节点对应huffman编码的编码长度,也就是最后每个编码输出结果的编码长度。
在本实施例中,所述步骤s9中,编码输出单元遍历输入数据缓存单元中保存的待压缩数据,根据huffman码表建立单元创建的huffman码表对输入的待压缩码流数据进行编码,得到编码后的码流;然后编码输出单元从高位到地位,依次按位串行输出码流的编码结果。
在本实施例中,结合状态转换图进行进一步描述。
如图1所示,一种用于vlsi设计的huffman编码系统的实现方法的状态转换图,主要状态包括:状态s0~状态s18。
采用一段式mealy型状态机结构,编码过程在状态跳转中完成,编码过程中的大量运算都采用递归结构,为数据实现高速实时处理做了充分准备,复用寄存器资源减少寄存器和存储器使用个数。
状态s0,初始化编码系统,清零频数统计,当复位信号未使能且开始信号有效时启动编码系统,跳转到s1状态。
状态s1,编码系统开始运行并对输入的待压缩数据进行一遍扫描,将输入的待压缩数据送入输入数据缓存单元;通过加法器对每一种字符出现的频数进行统计,并将频数统计结果送入码字频数缓存单元,将待压缩数据保存入寄存器中。完成后跳转到s2状态。
状态s2~s4,在设计编码系统时根据编码系统具体应用的特点,将频数、识别、字符、编码这四个变量转换成二进制表示,且新拼接的数据总位宽及其中各个变量的位宽可以视其具体编码的数据特点和待压缩数据量确定。按如图2所示数据格式拼接生成变量(初始时识别位、编码位均为零),若待压缩数据中字符种类用n表示,则按新数据格式拼接成n个变量并存储备份后跳转到s5状态,其中备份的数据将用于状态s11~s12中识别出叶子节点及其对应的编码。
状态s5~s7,按“每次从数据队列中取出值最小的两个作为节点求和后再入队并删除找到的两个值最小的,直到队列里只剩两个元素作为huffman树中第一层的两个节点”算法,递归生成2n-2个节点后跳转到s8。
状态s8~s10,对根节点编码1(根节点编码位用于状态s13~s14中得到编码长度)并初始化第一层的两个节点的编码(本系统实现方法中规定huffman树中第0层是根节点)后无条件跳转到s9。在状态s9中用第一层的节点匹配出下一层的节点,从上到下逐层构造huffman树,并在构造huffman树的同时完成对所有节点的编码,在逐层构造huffman树时通过s10状态判断下一次需要匹配建树是左或右节点。构造huffman树完成后跳转到s11。
状态s11~s12,用状态s2~s4状态中备份的数据,从huffman树的所有节点中识别出n个叶子节点及其对应的编码后跳转到状态s13。
状态s13~s14,去掉每个叶子节点所对应编码中的根节点编码位并得到每个叶子节点的编码长度后跳转到状态s15。
状态s15~s17,输出编码后的结果,先按位输出每个元素的编码,然后按位输出数据序列对应的huffman编码序列,全部输出结束后跳转到状态s18.
状态s18,输出编码结束标志位后跳转到状态s0,等待下一次编码任务。
在本实施例中,huffman编码系统如图3所示;结合图4~5,描述huffman编码实现系统对一段串行数据序列进行编码。本实施例采用的方案是对对一段串行数据序列进行huffman编码器的仿真验证,通过观察输出各元素编码和编码后的数据序列检验huffman编码器设计的正确性。通过统计total_cycles的时钟周期个数检验编码性能,即时钟周期数越少,性能越高。
本实施例设计如下:
(1)组成输入串行数据序列的元素是[0~9]这10个阿拉伯数字,每个数字用其对应的4位二进制数表示,例如5对应0101,9对应1001。输入数据序列长度为256。
(2)复位之后,当start信号高有效后开始连续串行输入256个元素,data_in数据宽度为4,输入需要256个时钟周期。
(3)code_start信号高有效后进行huffman编码,经过编码运算后,code_done信号高有效表明整个编码过程结束。
(4)输出编码后的结果,先输出每个元素的编码,然后输出数据序列对应的huffman编码序列,电路时序图4所示。
在本实施例中,在modelsim软件上进行仿真验证,仿真结果如图5所示。code_start信号高有效后到code_done的total_cycles数为584个,编码结果开始按位串行输出。
在本实施例中,编码结果如图6所示,按huffman编码表检验output_data串行输出的数据即可验证。
以上所述仅为本发明的较佳实施例,凡依本发明申请专利范围所做的均等变化与修饰,皆应属本发明的涵盖范围。
- 还没有人留言评论。精彩留言会获得点赞!