数据压缩方法及装置与流程
本发明涉及数据压缩领域,具体地,涉及一种数据压缩方法及装置。
背景技术:
实体企业的工作空间使用或产生了海量的实时数据,这些实时数据的读写和特征分析效率关系着生产运维决策的制定和执行的效率,尤其在即将到来的“工业4.0”或《中国制造2025》时代,海量数据的处理将越发重要。
在目前的存储、读写、搜索架构中,实时数据并需要全部保存,因此,可以通过有损数据压缩算法来对实时数据进行处理,现有技术中使用的有损数据压缩算法例如可以是死区压缩算法、pi的旋转门压缩算法及其扩展等算法,这些数据压缩算法兼顾了特征数据覆盖率、计算和存储性能,在工业界具有广泛的应用。
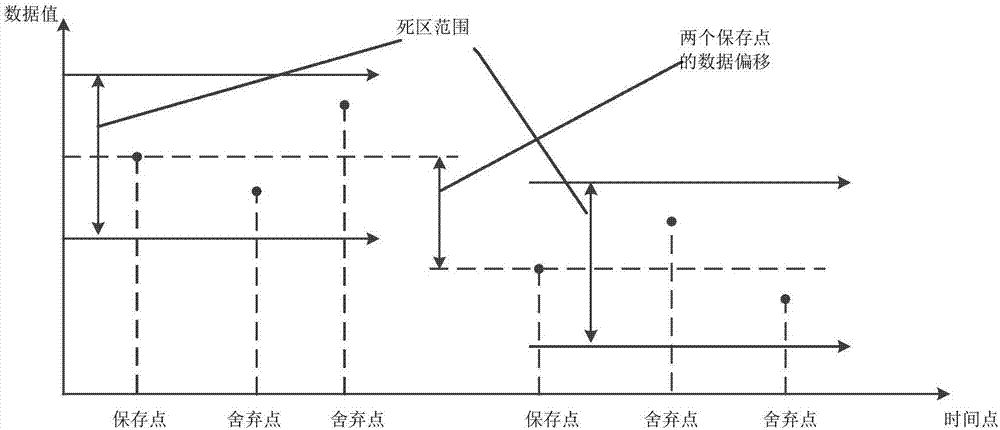
图1示出了死区压缩算法的原理示意图。死区压缩算法工作在一维线型空间中,如图1所示,在时间点-数据值的坐标中,比对当前数据和上一个保存的数据的偏差是否位于预先设定好的变化区间内,即死区范围内,若是则将当前数据确定为舍弃点并将其过滤掉,否则将当前数据确定为保存点并将其保存,新的保存点与先前保存点之间的数据偏移超过预先设定好的变化区间。在确定出新的保存点之后,根据该新的保存点来确定位于该新的保存点之后的数据点是保存还是舍弃。死区压缩算法适用于波动稳定的数据压缩,不适用于总是沿一个方向波动的数据压缩。
图2示出了pi的旋转门压缩算法的原理示意图。pi的旋转门压缩算法工作在二维线型空间中,如图2所示,在时间点-数据值的坐标中,使用上一个保存点a和当前的数据点b画一条线段ab,并按照设定的偏差将此线段在垂直方向上向上向下移动,进而扩展出一个二维数据空间1。选择上一个保存点a和当前的数据点b的下一个数据点c继续上述过程,扩展出一个二维数据空间2。如果后一个二维数据空间2能包含位于上一个保存点a和下一个数据点c之间的所有数据点,则判断数据点c之前的数据点b为舍弃点,否则判断据点c之前的数据点b为保存点。继续上述的判断过程,可以判断出图2中,二维数据空间3能够包含保存点a与数据点d之间的所有数据点(数据点b和数据点c),则数据点d的前一数据点c为舍弃点。二维数据空间4并不能够包含保存点a与数据点e之间的所有数据点(数据点b、数据点c和数据点d),则数据点e的前一数据点d为保存点。然后根据保存点d来对保存点d之后的数据点继续上述的判断过程。pi的旋转门压缩算法适用于慢变化的数据。
从上述对死区压缩算法、pi的旋转门压缩算法的描述中可知,现有技术进行数据压缩时,均采取一刀切的方式,即根据数据点在一条边界线的内侧还是外侧、数据点在一个边界四边形的内侧还是外侧,来决定舍弃或保存数据,本质上都是检查数据点的数据值是否在纯人为设定的上限或下限之间来决定舍弃或保存。
技术实现要素:
本发明实施例的目的是提供一种数据压缩方法及装置,以解决或至少部分解决上述技术问题。
为了实现上述目的,本发明实施例提供一种数据压缩方法,该方法包括:将采集的数据的采集时间和数据值映射为时间-数据值的坐标系中的数据点;根据指定为起始点的已保存的数据点确定在采集时间上位于该已保存的数据点之后的下一个要被保存的数据点;将确定的要被保存的数据点重新指定为起始点并根据该重新指定的起始点确定在采集时间上位于该重新指定的起始点之后的下一个要被保存的数据点,直到确定出所述数据点中所有要被保存的数据点;以及保存被确定要被保存的数据点;其中,确定下一个要被保存的数据点包括:按照采集时间的顺序依次判断所述起始点之后的数据点是否满足当前被考虑的数据点与所述起始点之间存在至少一个数据点到当前被考虑的数据点与所述起始点之间的线段的距离超过预定义值;如果所述当前被考虑的数据点与所述起始点之间存在至少一个数据点到当前被考虑的数据点与所述起始点之间的线段的距离超过预定义值,则将当前被考虑的数据点之前的一个相邻的数据点确定为下一个要被保存的数据点。
可选地,所述按照采集时间的顺序依次判断所述起始点之后的数据点是否满足当前被考虑的数据点与所述起始点之间存在至少一个数据点到当前被考虑的数据点与所述起始点之间的线段的距离超过预定义值包括:针对所述当前被考虑的数据点与所述起始点之间的所有数据点中的每一个数据点,以该每一个数据点的坐标为圆心、以所述预定义值为半径建立针对所述每一个数据点的圆;判断所述当前被考虑的数据点与所述起始点之间的线段是否与针对所述每一个数据点的圆中的至少一个圆相离;在所述当前被考虑的数据点与所述起始点之间的线段与针对所述每一个数据点的圆中的至少一个圆相离的情况下,确定所述当前被考虑的数据点与所述起始点之间存在至少一个数据点到当前被考虑的数据点与所述起始点之间的线段的距离超过预定义值;以及在所述当前被考虑的数据点与所述起始点之间的线段与针对所述每一个数据点的圆中的每一个圆均不相离的情况下,确定所述当前被考虑的数据点与所述起始点之间不存在数据点到当前被考虑的数据点与所述起始点之间的线段的距离超过预定义值。
可选地,所述判断所述当前被考虑的数据点与所述起始点之间的线段是否与针对所述每一个数据点的圆中的至少一个圆相离包括:根据所述当前被考虑的数据点与所述起始点之间的线段方程和针对所述每一个数据点的圆中的每一个圆的方程来判断所述当前被考虑的数据点与所述起始点之间的线段是否与针对所述每一个数据点的圆中的至少一个圆相离。
可选地,所述确定下一个要被保存的数据点还包括:如果所述当前被考虑的数据点与所述起始点之间不存在数据点到当前被考虑的数据点与所述起始点之间的线段的距离超过预定义值,则将当前被考虑的数据点之前的一个相邻的数据点确定舍弃点。
可选地,所述预定义值为2。
相应地,本发明实施例还提供一种数据压缩装置,所述装置包括:映射模块,用于将采集的数据的采集时间和数据值映射为时间-数据值的坐标系中的数据点;第一确定模块,用于根据指定为起始点的已保存的数据点确定在采集时间上位于该已保存的数据点之后的下一个要被保存的数据点;第二确定模块,用于将确定的要被保存的数据点重新指定为起始点并根据该重新指定的起始点确定在采集时间上位于该重新指定的起始点之后的下一个要被保存的数据点,直到确定出所述数据点中所有要被保存的数据点;以及保存模块,用于保存被确定要被保存的数据点;其中,所述第一确定模块包括:判断单元,用于按照采集时间的顺序依次判断所述起始点之后的数据点是否满足当前被考虑的数据点与所述起始点之间存在至少一个数据点到当前被考虑的数据点与所述起始点之间的线段的距离超过预定义值;确定单元,用于如果所述当前被考虑的数据点与所述起始点之间存在至少一个数据点到当前被考虑的数据点与所述起始点之间的线段的距离超过预定义值,则将当前被考虑的数据点之前的一个相邻的数据点确定为下一个要被保存的数据点。
可选地,所述判断单元包括:圆建立子单元,用于对所述当前被考虑的数据点与所述起始点之间的所有数据点中的每一个数据点,以该每一个数据点的坐标为圆心、以所述预定义值为半径建立针对所述每一个数据点的圆;判断子单元,用于判断所述当前被考虑的数据点与所述起始点之间的线段是否与针对所述每一个数据点的圆中的至少一个圆相离;确定子单元,用于:在所述当前被考虑的数据点与所述起始点之间的线段与针对所述每一个数据点的圆中的至少一个圆相离的情况下,确定所述当前被考虑的数据点与所述起始点之间存在至少一个数据点到当前被考虑的数据点与所述起始点之间的线段的距离超过预定义值;以及在所述当前被考虑的数据点与所述起始点之间的线段与针对所述每一个数据点的圆中的每一个圆均不相离的情况下,确定所述当前被考虑的数据点与所述起始点之间不存在数据点到当前被考虑的数据点与所述起始点之间的线段的距离超过预定义值。
可选地,所述判断子单元用于根据所述当前被考虑的数据点与所述起始点之间的线段方程和针对所述每一个数据点的圆中的每一个圆的方程来判断所述当前被考虑的数据点与所述起始点之间的线段是否与针对所述每一个数据点的圆中的至少一个圆相离。
可选地,所述确定单元还用于如果所述当前被考虑的数据点与所述起始点之间不存在数据点到当前被考虑的数据点与所述起始点之间的线段的距离超过预定义值,则将当前被考虑的数据点之前的一个相邻的数据点确定舍弃点。
可选地,所述预定义值为2。
相应地,本发明实施例还提供一种机器可读存储介质,该机器可读存储介质上存储有指令,该指令用于使得机器执行上述的数据压缩方法。
通过上述技术方案,能够实现压缩后的相邻数据点的数据特征尽量不重复,从而可以在数据压缩率和数据特征覆盖率之间取得很好的平衡。
本发明实施例的其它特征和优点将在随后的具体实施方式部分予以详细说明。
附图说明
附图是用来提供对本发明实施例的进一步理解,并且构成说明书的一部分,与下面的具体实施方式一起用于解释本发明实施例,但并不构成对本发明实施例的限制。在附图中:
图1示出了死区压缩算法的原理示意图;
图2示出了pi的旋转门压缩算法的原理示意图;
图3示出了根据本发明一实施例的数据压缩方法的流程示意图;
图4示出了根据本发明又一实施例的数据压缩方法的流程示意图;
图5示出了根据本发明一实施例的数据压缩方法的原理示意图;
图6示出了根据本发明一实施例的数据压缩方法的计算示意图;
图7示出了本发明实施例提供的数据压缩算法的应用示意图;以及
图8示出了根据本发明一实施例的数据压缩装置的结构框图。
具体实施方式
以下结合附图对本发明实施例的具体实施方式进行详细说明。应当理解的是,此处所描述的具体实施方式仅用于说明和解释本发明实施例,并不用于限制本发明实施例。
图3示出了根据本发明一实施例的数据压缩方法的流程示意图。如图3所示,本发明实施例提供一种数据压缩方法,该方法可以包括以下步骤:
步骤s31,将采集的数据的采集时间和数据值映射为时间-数据值的坐标系中的数据点。
具体地,可以首先定义横轴代表时间、纵轴代表数据值的坐标系。该坐标系例如可以以(0,0)为原点,或者可以根据需要以任意一点作为坐标原点。然后再将采集的数据的采集时间和数据值映射为所述坐标系中的数据点。这样,所采集的每一个数据在所述坐标系中均唯一的对应一个数据点。
步骤s32,根据指定为起始点的已保存的数据点确定在采集时间上位于该已保存的数据点之后的下一个要被保存的数据点。
具体地,确定下一个要保存的数据点可以包括:按照采集时间的顺序依次判断所述起始点之后的数据点是否满足当前被考虑的数据点与所述起始点之间存在至少一个数据点到当前被考虑的数据点与所述起始点之间的线段的距离超过预定义值;如果所述当前被考虑的数据点与所述起始点之间存在至少一个数据点到当前被考虑的数据点与所述起始点之间的线段的距离超过预定义值,则将当前被考虑的数据点之前的一个相邻的数据点确定为下一个要被保存的数据点。
在所述当前被考虑的数据点与所述起始点之间存在至少一个数据点到当前被考虑的数据点与所述起始点之间的线段的距离超过预定义值的情况下,说明当前被考虑的数据点之前的一个相邻的数据点与相邻数据点的数据特征不同,需要保存,因此可以将该当前被考虑的数据点之前的一个相邻的数据点确定为保存点。
如果所述当前被考虑的数据点与所述起始点之间不存在数据点到当前被考虑的数据点与所述起始点之间的线段的距离超过预定义值,说明当前被考虑的数据点之前的一个相邻的数据点与相邻数据点的数据特征相似,可以不保存,因此可以将当前被考虑的数据点之前的一个相邻的数据点确定舍弃点。
其中,可以在所述坐标系中确定所述当前被考虑的数据点与所述起始点之间的线段的方程,然后根据点到直线之间的距离公式来计算数据点到线段之间的距离。
可选地,所述预定义值可以根据实际需要进行设置,例如所述预定义值可以设置为2。
可选地,可以将所采集的数据中的第一个数据确定为要保存的数据,则该要保存的数据所映射的数据点就是已保存的数据点。
步骤s33,将确定的要被保存的数据点重新指定为起始点并根据该重新指定的起始点确定在采集时间上位于该重新指定的起始点之后的下一个要被保存的数据点,直到确定出所述数据点中所有要被保存的数据点。
采用步骤s32中的具体执行方式继续确定下一个要保存的数据点,直到确定出所述数据点中所有要被保存的数据点。
步骤s34,保存被确定要被保存的数据点。
在确定出所有要保存的数据点后,可以将确定为要保存的数据点保存,将确定为舍弃点的数据点舍弃。可选地,可以将要保存的数据点逆映射为所采集的数据,然后再进行保存。
本发明实施例提供的数据压缩方法可以实现压缩后的相邻数据点的数据特征尽量不重复,从而可以在数据压缩率和数据特征覆盖率之间取得很好的平衡。
基于图3所示的实施例,上述步骤s32可以进一步包括以下步骤:
步骤s321,针对所述当前被考虑的数据点与所述起始点之间的所有数据点中的每一个数据点,以该每一个数据点的坐标为圆心、以所述预定义值为半径建立针对所述每一个数据点的圆。
可选地,在执行上述步骤s32时,可以针对每一个数据点以该每一个数据点的坐标为圆心、预定义值为半径计算建立针对每一数据点的圆,例如,可以在所述坐标系中,通过计算圆的直角坐标方程来实现建立针对每一数据点的圆。
步骤s322,判断所述当前被考虑的数据点与所述起始点之间的线段是否与针对所述每一个数据点的圆中的至少一个圆相离。
在平面中,线段与圆的位置关系可以是相离、相切或相交。
可选地,在步骤s322中可以根据所述当前被考虑的数据点与所述起始点之间的线段方程和针对所述每一个数据点的圆中的每一个圆的方程来判断所述当前被考虑的数据点与所述起始点之间的线段是否与针对所述每一个数据点的圆中的至少一个圆相离。具体地,可以在坐标系中根据当前被考虑的数据点的坐标和起始点的坐标计算当前被考虑的数据点与所述起始点之间的线段的方程,然后将该线段的方程分别带入上述的每一数据点的圆的方程中从而得到一个一元二次方程,通过解该一元二次方程来判断所述位置关系,在该一元二次方程无实数解的情况下,确定参考线段与圆相离,说明圆对应的数据点到所述线段的距离大于预定义值,否则,确定线段与圆不相离,也就是说数据点到所述线段的距离不大于所述预定义值。
步骤s323,在所述当前被考虑的数据点与所述起始点之间的线段与针对所述每一个数据点的圆中的至少一个圆相离的情况下,确定所述当前被考虑的数据点与所述起始点之间存在至少一个数据点到当前被考虑的数据点与所述起始点之间的线段的距离超过预定义值。
另一方面,在所述当前被考虑的数据点与所述起始点之间的线段与针对所述每一个数据点的圆中的至少一个圆相离的情况下,说明当前被考虑的数据点之前的一个相邻的数据点与相邻数据点的数据特征不同,需要保存,因此可以将该当前被考虑的数据点之前的一个相邻的数据点确定为保存点。
步骤s324,在所述当前被考虑的数据点与所述起始点之间的线段与针对所述每一个数据点的圆中的每一个圆均不相离的情况下,确定所述当前被考虑的数据点与所述起始点之间不存在数据点到当前被考虑的数据点与所述起始点之间的线段的距离超过预定义值。
另一方面,在所述当前被考虑的数据点与所述起始点之间的线段与针对所述每一个数据点的圆中的每一个圆均不相离的情况下,说明当前被考虑的数据点之前的一个相邻的数据点与相邻数据点的数据特征相似,可以不保存,因此可以将当前被考虑的数据点之前的一个相邻的数据点确定舍弃点。
本发明实施例中,根据映射到坐标系中的两个数据点之间的线段与所述起始点之间的线段与针对所述每一个数据点的圆中的每一个圆(以这个数据点作为圆心,通过扩大样本容量而扩展出的一个圆)之间的位置关系(相离、相切或相交)来判断当前被考虑的数据点之前的一个相邻的数据点是否符合其相邻数据点的特征,实现压缩后的相邻数据点的数据特征尽量不重复,从而能够在数据压损率和数据特征覆盖率上取得了一个很好的平衡。
图5示出了根据本发明一实施例的数据压缩方法的原理示意图。在图5所示的直角坐标中,原点为0,横轴代表数据点的采集时间,纵轴代表数据点的数值,实时数据值随着横轴上的采集时间而在纵轴上波动。图5中以6个数据采集点在坐标系中映射的数据点a至数据点f这6个数据点为例来对本发明实施例提供的数据压缩算法的原理进行进一步说明,其中所述6个数据点中a点是已知保存点。
参考图5,可以通过以下步骤来对本发明实施例提供的数据压缩算法的原理进行说明:
步骤s51,以每个数据点为圆心,以预定义值为半径分别建立圆针对数据点a至数据点f的圆。
步骤s52,从已知保存点a出发,向下一个数据点b连线,形成线段ab。
步骤s53,从已知保存点a出发,继续向数据点b的下一个数据点c连线,形成线段ac。
步骤s54,判断线段ac与已知保存点a和数据点c之间的数据点b的圆的位置关系,如果线段ac与数据点b的圆相离,则数据点b是保存点,否则,数据点b是舍弃点,从图5中可以看出,线段ac与数据点b的圆不相离,因此,可以确定数据点b是舍弃点。
已知保存点a和数据点c之间的所有圆(数据点b的圆)相离,则当前点(数据点c)的前一个点(数据点b)需要被保存,否则从已知保存点a继续向下一个点(数据点d)连线重复此过程(从数据点a出发继续向数据点d连线,即线段ad。如果线段ad和数据点b的圆、数据点c的圆其中的任一相离,则数据点d的前一个数据点点即数据点c需要被保存,否则继续从已知保存点a向下一个数据点e连线段来重复这一过程)。
步骤s55,从已知保存点a继续向数据点c的下一个数据点d连线形成线段ad,并重复步骤s54的过程,确定线段ad与已知保存点a和数据点d之间的所有圆(数据点b和数据点c的圆)之间的位置关系。从图5中可知,线段ad与数据点b的圆相交而非相离,并且于数据点c的圆也相交而非相离,从而可以确定出数据点d的前一数据点c是舍弃点。
步骤s56,重复步骤s54的过程,从图5中可以确定,线段ae与数据点b的圆和与数据点c的圆均不相离,但是线段ae与数据点d的圆相离,则说明数据点d的数据特征不同于相邻数据点的数据特征,因此,可以确定出数据点d为保存点。
步骤s57,从新保存的点(数据点d)出发,重复上面的步骤s51至步骤s56。
使用上述步骤一致迭代下去,就能根据数据点的采集顺序的先后确定出每一数据点是保存点还是舍弃点。
图6示出了根据本发明一实施例的数据压缩方法的计算示意图。在图6所示的直角坐标中,原点为0,横轴代表数据点的采集时间。在该实施例中预先设定的半径值为2,图6中数据点a为已知保存点,其是以确定下一个保存点为例说明数据压缩方法的计算过程,具体地,本发明实施例提供的数据压缩方法可以包括以下计算步骤:
步骤s61,确定数据点b的圆的方程:(x-10)2+(y-6)2=22,即x2+y2-20×x-12×y-4=0,其中x属于[8,12]。
步骤s62,确定线段ac的方程:
设线段ac的方程为y=kx+b,根据下面两个等式:
4=b,
11=k×20+b,
可知线段ac的方程为y=0.35×x+4,其中x属于[0,20]。
步骤s63,判断线段ac是否和圆b相交:
将线段ac的方程带入数据点b的圆的方程,整理可得以下一元二次方程:
1.1225x2-21.4x-36=0,
一元二次方程的判别式为:(-21.4)×(-21.4)-4×1.1225×(-36)=619.6,该判别式大于0,所以可知线段ac与数据点b的圆相交。
步骤s64,继续执行步骤s61至步骤s63可知,线段ad和数据点b的圆、数据点c的圆都相交,线段ae和数据点d的圆相离,可知数据点d的数据特征与数据点b、c、e不同,所以数据点d为保存点。
根据保存d继续上面的判断过程,从而确定数据点d之后的下一保存点。使用上述步骤一致迭代下去,就能根据数据点的采集顺序的先后确定出每一数据点是保存点还是舍弃点。
图7示出了本发明实施例提供的数据压缩算法的应用示意图。本本发明实施例提供的数据压缩方法已经在神华国神集团的数据采集项目中实施,在生产指挥中心部署的采集器中运行,用于安全监测实时数据和人员定位实时数据的数据压缩。目前,采集器运行稳定,数据压缩性能良好,根据各个测点的数据特征分别设置各个测点的数据变化量后,各个测点的数据特征能成功提取。
在实施过程中,合理划分各个模块,模块间应用生产者-消费者模式,实现了模块间低耦合,模块内高内聚,其中所划分的各模块分别是数据获取模块、数据映射模块、数据压缩模块、数据规约模块、数据发送模块以及数据缓存模块。图7中队列q1至队列q4均为时间优先的优先级队列。参考图7,各个模块具体实施方式如下:
数据获取模块,用于将从各种数据源获取到的实时数据分别放入到队列q1中。
数据映射模块,用于从队列q1中拉取数据,将原生实时数据映射成按测点分类的实时数据,并分别放入队列q2中。
数据压缩模块,用于从队列q2中拉取数据,按照本发明实施例提供的数据压缩方法压缩实时数据,并将压缩后的实时数据分别放入队列q3中。
数据规约模块,用于从队列q3中拉取数据,执行数据映射的逆过程,即数据规约,获得按时间点分类的分批实时数据并将其放入队列q4中。
数据发送模块,用于从队列q4中拉取数据,异步发送至数据服务端。
数据缓存模块,用于在数据发送模块中注册回调函数,根据异步发送的响应和缓存策略,缓存相应的实时数据。
图8示出了根据本发明一实施例的数据压缩装置的结构框图。如图8所示,本发明实施例还提供一种数据压缩装置,该装置可以包括:映射模块81,用于将采集的数据的采集时间和数据值映射为时间-数据值的坐标系中的数据点;第一确定模块82,用于根据指定为起始点的已保存的数据点确定在采集时间上位于该已保存的数据点之后的下一个要被保存的数据点;第二确定模块83,用于将确定的要被保存的数据点重新指定为起始点并根据该重新指定的起始点确定在采集时间上位于该重新指定的起始点之后的下一个要被保存的数据点,直到确定出所述数据点中所有要被保存的数据点;以及保存模块84,用于保存被确定要被保存的数据点;其中,所述第一确定模块82包括:判断单元821,用于按照采集时间的顺序依次判断所述起始点之后的数据点是否满足当前被考虑的数据点与所述起始点之间存在至少一个数据点到当前被考虑的数据点与所述起始点之间的线段的距离超过预定义值;确定单元822,用于如果所述当前被考虑的数据点与所述起始点之间存在至少一个数据点到当前被考虑的数据点与所述起始点之间的线段的距离超过预定义值,则将当前被考虑的数据点之前的一个相邻的数据点确定为下一个要被保存的数据点。本发明实施例提供的数据压缩装置可以实现压缩后的相邻数据点的数据特征尽量不重复,从而可以在数据压缩率和数据特征覆盖率之间取得很好的平衡。
本发明实施例提供的数据压缩装置的具体工作原理及益处与上述本发明实施例提供的数据压缩方法的具体工作原理及益处相似,这里将不再赘述。
相应的,本发明提供一种机器可读存储介质,该机器可读存储介质上存储有指令,该指令用于使得机器执行本申请上述的数据压缩方法。
以上结合附图详细描述了本发明例的可选实施方式,但是,本发明实施例并不限于上述实施方式中的具体细节,在本发明实施例的技术构思范围内,可以对本发明实施例的技术方案进行多种简单变型,这些简单变型均属于本发明实施例的保护范围。
另外需要说明的是,在上述具体实施方式中所描述的各个具体技术特征,在不矛盾的情况下,可以通过任何合适的方式进行组合。为了避免不必要的重复,本发明实施例对各种可能的组合方式不再另行说明。
本领域技术人员可以理解实现上述实施例方法中的全部或部分步骤是可以通过程序来指令相关的硬件来完成,该程序存储在一个存储介质中,包括若干指令用以使得一个(可以是单片机,芯片等)或处理器(processor)执行本申请各个实施例所述方法的全部或部分步骤。而前述的存储介质包括:u盘、移动硬盘、只读存储器(rom,read-onlymemory)、随机存取存储器(ram,randomaccessmemory)、磁碟或者光盘等各种可以存储程序代码的介质。
此外,本发明实施例的各种不同的实施方式之间也可以进行任意组合,只要其不违背本发明实施例的思想,其同样应当视为本发明实施例所公开的内容。
- 还没有人留言评论。精彩留言会获得点赞!