一种针对基因数据的取样字典树索引的压缩方法和系统与流程
本发明涉及dna数据压缩领域,尤其是fastq格式的文件压缩,特别涉及一种针对基因数据的取样字典树索引的压缩方法和系统。
背景技术:
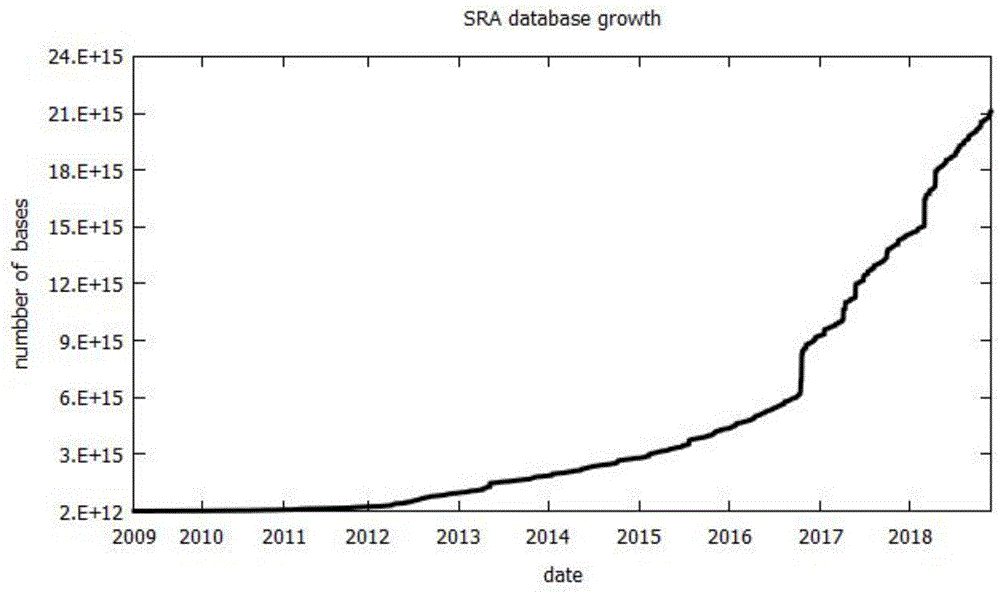
近年来dna数据的研究有着广泛的应用领域,包括遗传工程、医学诊断、法医生物学和遗传系谱学等重要领域和学科,而为这些研究领域提供基础数据的dna测序工程,也逐渐成为了各国的重点研究项目。同时随着测序成本的不断降低,利用现代测序技术得到的数据已达到了pb级。根据美国国家生物技术信息中心(ncbi)的官方统计,截止到2018年11月21日,sra(sequencereadarchive)存储的通过ngs测序技术得到的序列碱基数量已经超过21127万亿,并仍然以指数形式增长(图1)。dna数据量的高速增长增加了数据存储、传输和分析成本。
事实上,在dna序列总数据量高速增长的同时,数据的冗余度也越来越高。以人类的dna数据为例,研究表明,人类的dna相互之间有99%以上是相同的;对于单个人体的dna,在高通量测序时为了提高测序结果的准确率,平均每个人的dna都要重复测序30次左右并保存所有的测序结果,这就更大程度地增加了基因数据的冗余性。能有效地利用这种高重复率来进行压缩,可以极大程度地缓解大量数据的存储。因此,对dna数据的存储,压缩是一个行之有效的方法。数据压缩能够减少数据存储和管理成本,减少能耗,减少网络传输成本,减少数据备份时间。
主流的高通量测序平台包括illuminaga和abi公司自主研发的solid测序仪。其产生的数据都是以fastq格式存储的,fastq格式也因此成了高通量测序数据存储数据上的标准格式。该格式文件是由一条条记录(read)组成的,每条记录由4行组成,分别为标识、序列、“+”和质量分值。如图2所示为某fastq文件中的一条记录。其中序列部分存储的是测序得到的碱基序列,除去a、c、g、t以外,测序时不能判断是何种碱基时用字符“n”代替,这一行一般为40~120个字符。质量分值部分与序列部分是一一对应的,反映的是对应碱基测序结果的准确程度。
由于fastq文件的独有的特性,对fastq文件的压缩要将标识、序列和质量分值三部分单独进行,以此来提高压缩率。因为质量分值部分与序列部分是一一对应的,并且标识部分序列比较短,因此序列部分占据整个文件的三分之一甚至更多。
此外理论上来说,序列部分仅由四个actg字符组成,也就是说230g的数据中有三分之一的数据仅仅由四个字符组成,可以预料到肯定有相当大数量的子串是重复的。此外,dna在测试过程中,为了测量准确,测试深度都大于30x,即每个片段将会被复制30次以上。基于以上两点,我们可以推断出序列部分的子串具有冗余性。
由于dna数据只包含四种碱基符号{a,c,g,t},若将其看成随机的字符串,则每个碱基符号需要2bits(log24),故对dna数据进行压缩,其每个碱基需少于2bits存储才能达到有效的压缩结果。传统的压缩算法工具如compress、gzip、7-zip,一般是用来压缩文本、图像、视频等其他各种数据格式。这些传统的压缩算法工具可以用来压缩测序项目的数据,并且如gzip和bzip2经常用于个人储存。然而,若用这些传统的压缩算法工具则会使其存储空间大于2比特/符号。因此从1993年起出现了专门针对dna数据的压缩算法。
g-sqz算法对于序列、质量分值部分,则构造<碱基,质量分值>单元组,然后使用huffman编码。该方法比较简单,压缩效果也有限,仅略优于gzip,没有充分利用到fastq文件的特点。
dsrc算法对于序列部分,会首先先将字符“n”放到质量分值部分中,再进行lz匹配,剩余部分则使用2比特编码。该算法整体效果较好,但由于判断机制过多导致速度会降低。
kungfq算法对于序列部分,使用三碱基组与rle结合的方式,用1b进行区分,如果字符连续重复率较高,则使用rle编码,用4b表示长度,3b表示五种碱基,否则使用7b来表示连续三个碱基。总体而言,该方法压缩率较高,但是压缩速度比较慢,同时考虑了出现次数较少的“n”,造成了一定的资源浪费。
lfqc算法对于序列部分,将每k个分值分为一组,判断是否存在一个字符q出现的次数lq≥k/2,如存在则将该组放入编号为q的bucket中,否则放入全局bucket中,同时将映射信息记录到索引bucket中,最后对所有bucket都使用huffman编码。该方法有较高的压缩率,但分组判断再进行huffman编码使得压缩速度变得很缓慢。
lw-fqzip算法是yongpengzhang、linsenli等学者在2015年提出的一种轻量级的面向fastq文件的有参照压缩方法。对于序列部分,据统计,以“cg”开头的字符串出现的频率较高,所以在构建索引时,只取“cg”开头并出现一定次数的字符串,这样会减少索引表的大小。在进行匹配时也只匹配“cg”开头的串。整体来说,该方法取得了较高的压缩率,但在执行压缩前需要先读取参考文件构造索引表,这个过程比较耗时,影响了压缩速度。
以上各种压缩算法各有优劣,压缩率大体都在3~6之间。以gzip为基准(压缩率和压缩速度均设为1),各种压缩算法的压缩率和压缩速度如图3所示。从图中可以看出,压缩速度和压缩率基本上呈反比。而压缩率的进一步提升往往需要指数级增长的cpu时间和内存空间,因此在压缩过程中,会保持其压缩率和压缩速度方面的均衡性。
技术实现要素:
本发明的目的是解决上述现有技术在压缩数据时,没有真正的挖掘出字符串的冗余信息,要么就是方法太过复杂,增加了很多判断检测,导致压缩速度很慢。
具体地说,本发明公开了一种针对基因数据的取样字典树索引的压缩方法,其中包括:
步骤1、用户上传待压缩的基因数据,该基因数据包括:标识、序列和质量分值;
步骤2、提取该序列中预设长度的子串到字典树索引结构中进行查找,若该字典树索引结构中具有该子串,则将该子串压缩为该子串在该字典树索引结构中的位置、长度,作为该子串的索引值,否则将该子串加入该字典树索引结构,记录该子串在该字典树索引结构中的位置、长度作为该子串的索引值。
所述的针对基因数据的取样字典树索引的压缩方法,其中步骤2中将该子串加入该字典树索引结构具体为:
步骤21、判断该质量分值是否大于预设值,若大于,则执行步骤22,否则,记录完整的该子串而不将其加入该字典树索引结构;
步骤22、通过对该子串进行取样筛选,选择该子串的一部分加入到整棵字典树中。
所述的针对基因数据的取样字典树索引的压缩方法,其中还包括:
步骤3、根据该标识的分隔符,将该标识分为多个区域,判断各区域之间是否完全相同,若是,则将该标识压缩为单个该区域和该区域的个数,否则继续判断各区域之间是否存在数字递增的关系,若是,则使用游程编码将该标识压缩,只记录该多个区域的起始值和长度,否则继续判断该多个区域的数字是否在预设范围内,若是,则使用最小比特法将该标识进行编码压缩,否则直接单独存储各个该区域。
所述的针对基因数据的取样字典树索引的压缩方法,其中还包括:
步骤4、获取指定碱基的符号n,将序列部分对应碱基符号为“n”的质量分值加128,并判断质量分值串中是否存在连续相同字符,若存在,则使用rle编码对该质量分值串进行压缩,否则使用哈夫曼编码对该质量分值串进行压缩。
所述的针对基因数据的取样字典树索引的压缩方法,其中该基因数据的格式为fastq文件格式。
本发明还提供了一种针对基因数据的取样字典树索引的压缩系统,其中包括:
接收模块,用于接收用户上的传待压缩的基因数据,该基因数据包括:标识、序列和质量分值;
索引压缩模块,用于提取该序列中预设长度的子串到字典树索引结构中进行查找,若该字典树索引结构中具有该子串,则将该子串压缩为该子串在该字典树索引结构中的位置、长度,作为该子串的索引值,否则将该子串加入该字典树索引结构,记录该子串在该字典树索引结构中的位置、长度作为该子串的索引值。
所述的针对基因数据的取样字典树索引的压缩系统,其中索引压缩模块中将该子串加入该字典树索引结构具体为:
判断模块,用于判断该质量分值是否大于预设值,若大于,则调用筛选模块,否则,记录完整的该子串而不将其加入该字典树索引结构;
筛选模块,用于通过对该子串进行取样筛选,选择该子串的一部分加入到整棵字典树中。
所述的针对基因数据的取样字典树索引的压缩系统,其中还包括:
标识压缩模块,根据该标识的分隔符,将该标识分为多个区域,判断各区域之间是否完全相同,若是,则将该标识压缩为单个该区域和该区域的个数,否则继续判断各区域之间是否存在数字递增的关系,若是,则使用游程编码将该标识压缩,只记录该多个区域的起始值和长度,否则继续判断该多个区域的数字是否在预设范围内,若是,则使用最小比特法将该标识进行编码压缩,否则直接单独存储各个该区域。
所述的针对基因数据的取样字典树索引的压缩系统,其中还包括:
序列压缩模块,用于获取指定碱基的符号n,将序列部分对应碱基符号为“n”的质量分值加128,并判断质量分值串中是否存在连续相同字符,若存在,则使用rle编码对该质量分值串进行压缩,否则使用哈夫曼编码对该质量分值串进行压缩。
所述的针对基因数据的取样字典树索引的压缩系统,其中该基因数据的格式为fastq文件格式。
本发明的技术效果包括:
1、fastq文件序列部分字符串所独有的冗余性,使得数据压缩中,挖掘重复字符串,以此为基础进行压缩是非常有潜力的一种方法。关于如何利用此特性,在国内外针对fastq文件的压缩研究中多次有所体现,但是在利用重复性时,均使用了以hash表为基础构造索引。比如对于同样一条字符串,在使用哈希表时,查找前需要对字符串进行哈希处理,就要遍历所有的字符;而使用字典树时,如果查找不成功,则在字符串遍历完之前就能得到结果。减少了匹配时间,能够提高速度。
2、但是为了能够充分挖掘冗余性,利用字典树,字典树越大越好。但是在满足此要求的同时,需要消耗极大的内存,这给算法带来了困难。因此需要提高内存的利用效率,控制字典树的大小,让字典树中尽量保留最有效的信息。
3、在控制字典树大小方面,应该充分利用已有信息,采样是最好的方式。与此同时质量分值充分反应了字符串的有效性,因此利用质量分值来评估取样的字符串,让字典树种保留最有效的信息,控制大小的同时,又能保证压缩率。
4、dna文件的压缩对于资源的消耗是非常大的,单机压缩容易遭遇cpu、内存及存储瓶颈。使用分布式系统不仅可以将这些瓶颈分摊,还可以更有效地利用基因相似度高的特点。
附图说明
图1为sra数据增长示意图;
图2为fastq文件格式示意图;
图3为fastq文件压缩算法对比示意图;
图4为分布式压缩系统结构图;
图5为序列字符串“gggttttcctgaaa”构造的trie树示意图;
图6为取样率为1/3时构造的trie树示意图;
图7为根据质量分值决定碱基序列是否加入索引示意图。
具体实施方式
为让本发明的上述特征和效果能阐述的更明确易懂,下文特举实施例,并配合说明书附图作详细说明如下。
系统架构:
分布式dna文件压缩系统主要实现了基因文件的压缩存储功能。系统由客户端(client)、服务器端(server)和压缩节点(compressor)三部分组成。这三部分的相互联系如图4所示。
在分布式压缩系统中,client端是直接面向用户的,用户可以发起写(压缩)、读(解压缩)、查、删的请求,进行数据分块,所有的请求和数据都会发送到server端。
server起到一个桥梁作用,连接client端和compressor节点。server维护了一个请求队列,用于接收数据和请求。当接收到请求之后,server从队列中取出请求和数据,根据请求类型的不同选择相应的处理,除查询请求外,其他的请求和数据都会转发给压缩节点。server维护了一个文件-块映射索引表,用于存储文件-块的映射信息,包括块偏移、目标压缩节点等。
compressor节点主要执行压缩存储和解压缩,并保存块文件-存储位置的映射信息。每个压缩节点使用单独的块-位置映射信息,具有较好的独立性,使得分布式系统能够更好地扩展。
在compressor节点进行数据压缩:
压缩一共分为两部分,首先是将fastq中四种不同的数据分开,然后对其中除“+”以外的三部分分别压缩,其中符号“+”为固定格式,不需要进行压缩。fastq格式文件是由一条条记录(read)组成的,每条记录由4行组成,分别为标识、序列、“+”和质量分值。因此首先是将四部分分离,分别进行压缩。针对序列部分,直接根据换行来判断即可。
1、针对序列部分的压缩
序列部分是本发明算法的核心,也是整个算法的压缩速度和压缩率中的核心部分。主要规则如下:构建字典树trie。首先取一定长度的子串到trie索引结构中进行查找,如果匹配成功,则只需记录匹配成功的字典树trie中位置和长度,作为索引信息,以通过位置和长度在字典树中找到这个字符串;如果没有匹配成功,则按照下面所示的两种方法将其加入到trie结构中。如果序列是字符串“gggttttcctgaaa”,则构造的字典树如图5所示。
方法一:加入字典树时,首先根据固定长度(假设为5)将字符串进行子串划分,以步长为1获取子串,可以得到图5展示的字典树中所涉及到的子串,然后进行取样筛选。比如说设置的采样率为三分之一时,对子串进行筛选,只选择一部分加入到整棵树中,其中采用率可以换算成步长,例如本实施例中采样率为三分之一的时候,步长就为3,即实际应用中,步长的选择是根据内存大小和实际经验训练得到的,根据需求可以设置。取样率越高,就是舍去的字符串越少,则占用内存越大,压缩效果越好,反之取样率越低,则占用内存越少,压缩效果会受到影响。由于trie的查找过程是一个个字符匹配的过程,所以使用trie结构还可以实现部分匹配,如对于图6中的trie结构,如果匹配字符串“tccta”时,可以得到匹配长度为4(匹配到插入串3)的结果,匹配长度较为理想。这种匹配机制会尽可能地减少不必要的字符比较,在查询过程中会有更高的查询效率。如匹配字符串“ttacg”时,当匹配到字符“a”,发现匹配失败,后面的字符就不必要再进行比较了,这有助于查询效率的提升。
在使用取样索引后,会使得某些子串未能插入到trie结构中,在匹配过程中会遇到一些问题。仍以图6(a)的trie结构为例,当匹配字符串“gtttt”时,如果直接进行匹配,即便使用部分匹配,则会得到匹配的长度为1(匹配到插入串1),匹配长度较短。而在图5的trie结构中则可以完全匹配到。如果此时忽略字符串“gtttt”中的第一个字符“g”,从第二个字符“t”开始匹配,则可以得到匹配长度为4(匹配到插入串2)。在实际处理过程中,会先进行正常匹配,如果未完全匹配,则忽略第一个字符进行匹配,再综合这两种方式进行比较,选择匹配长度更长的方法进行处理。这一过程称为“懒惰匹配”。举例来说即,忽略第一个的意思是s或对第一个g字符不进行压缩,直接写入到压缩文件中,只对后面的字符串进行匹配。这样避免了下面这种情况:比如说要匹配字符串accdg,但是字典树中有ccdga,这个字符串在字典树中的位置为x,如果在匹配accdg的时候,舍弃第一个字符a,那么本发明可以对ccdg进行字典树匹配,获得(x,4)(其中4为匹配的长度)。这样得到的压缩数据为:a(x,4)。如果不使用懒惰匹配的方法,那么在匹配accdg的时候,发现字典树中没有,只能在压缩文件中写accdg,其与a(x,4)这一结果相比,占用的空间大,没有起到压缩的效果。
方法二:根据质量分值来决定是否加入字典树。质量分值反映了对应碱基测序结果的准确程度,质量分值越高表明对应碱基越准确,质量分值越低表明对应碱基越不准确,当质量分值为最小值时,表明当前碱基完全无法确定,此时对应的碱基用字符“n”表示,并且在一段序列的测序过程中,质量分值呈逐渐下降趋势。由此可以得知,如果某条碱基序列对应的质量分值较低,表明测序得到的此碱基序列的准确程度较低,这样在后续的匹配过程中被匹配到的概率也会较低。所以,在对字符串加入索引前,先判定其碱基序列对应的质量分值,如果质量分值较高,则加入trie索引;如果质量分值较低,则不将其加入到trie索引中,这样可以保证trie结构中的子串具有较高的质量分值和被匹配概率。该过程如图7所示。
2、针对标识部分的压缩
fastq文件的每个标识部分具有一定的相似性,都会被一些相同的分隔符(冒号、点号等)分成几个区域(field),各个field有一定的特点,根据不同情况处理如下:
·内容完全相同:这种情况可以只对该field存储一次即可;
·数字递增:使用游程编码,只记录起始值和长度即可;
·数字在一定范围内:将这部分内容当作纯数字处理,使用最小比特法进行编码;
·其他内容:直接单独存储。
其中对于“内容完全相同”和“数字递增”两种情况,对标识部分的整个处理过程中只需要保存一次即可;而对于“数字在一定范围内”和其他情况,则需要单独存储。
3、质量分值部分的压缩
对于质量部分,尽管其长度和序列部分相同,但由于质量分值的字符种类多,相对于序列部分具有一定的随机性,所以处理方式更为复杂。对质量分值部分的压缩规则设定如下:
·对于序列部分对应碱基为“n”的质量分值,其质量值加上128:序列部分的字符“n”会被忽略,序列部分的长度就会缩短,质量分值的范围在33~126,在解压过程中可以根据质量分值只要是一个大于128的数值,那么对应的位置就是一个n,来恢复字符“n”。需要知道的是在测序的时候,仪器会把测不准的碱基写成n,因此测序出来的结果中,不仅仅有4种碱基(acgt),还会多一个n;
·对于连续相同字符出现次数较多的情况,则使用rle编码:为了区分某一质量分值串是否使用了rle编码,设定一个标志位进行判定;
·其他情况则直接使用huffman编码。
以下为与上述方法实施例对应的系统实施例,本实施方式可与上述实施方式互相配合实施。上述实施方式中提到的相关技术细节在本实施方式中依然有效,为了减少重复,这里不再赘述。相应地,本实施方式中提到的相关技术细节也可应用在上述实施方式中。
本发明还提供了一种针对基因数据的取样字典树索引的压缩系统,其中包括:
接收模块,用于接收用户上的传待压缩的基因数据,该基因数据包括:标识、序列和质量分值;
索引压缩模块,用于提取该序列中预设长度的子串到字典树索引结构中进行查找,若该字典树索引结构中具有该子串,则将该子串压缩为该子串在该字典树索引结构中的位置、长度,作为该子串的索引值,否则将该子串加入该字典树索引结构,记录该子串在该字典树索引结构中的位置、长度作为该子串的索引值。
所述的针对基因数据的取样字典树索引的压缩系统,其中索引压缩模块中将该子串加入该字典树索引结构具体为:
判断模块,用于判断该质量分值是否大于预设值,若大于,则调用筛选模块,否则,记录完整的该子串而不将其加入该字典树索引结构;
筛选模块,用于通过对该子串进行取样筛选,选择该子串的一部分加入到整棵字典树中。
所述的针对基因数据的取样字典树索引的压缩系统,其中还包括:
标识压缩模块,根据该标识的分隔符,将该标识分为多个区域,判断各区域之间是否完全相同,若是,则将该标识压缩为单个该区域和该区域的个数,否则继续判断各区域之间是否存在数字递增的关系,若是,则使用游程编码将该标识压缩,只记录该多个区域的起始值和长度,否则继续判断该多个区域的数字是否在预设范围内,若是,则使用最小比特法将该标识进行编码压缩,否则直接单独存储各个该区域。
所述的针对基因数据的取样字典树索引的压缩系统,其中还包括:
序列压缩模块,用于获取指定碱基的符号n,将序列部分对应碱基符号为“n”的质量分值加128,并判断质量分值串中是否存在连续相同字符,若存在,则使用rle编码对该质量分值串进行压缩,否则使用哈夫曼编码对该质量分值串进行压缩。
所述的针对基因数据的取样字典树索引的压缩系统,其中该基因数据的格式为fastq文件格式。
本发明技术效果包括:
在fastq文件的压缩方面,压缩率比gzip提升了50%左右,和dsrc相当;压缩速度比gzip提升了3~6倍,比dsrc提升了55%左右。在保证较高的压缩速度的同时,有保证了压缩率,解决了现有方法的短板。提高了序列的压缩效果,并使用取样索引和根据质量分值高低决定是否加入到索引结构的策略来降低字典树的内存占用空间。
- 还没有人留言评论。精彩留言会获得点赞!