高性能极化码译码算法的制作方法
本发明属于无线通信技术,特别是一种针对极化码的基于比特翻转机制的高性能译码算法。
背景技术:
极化(polar)码由arikanerdal在2008年提出。在无限码长时,极化码采用串行抵消(successivecancellation,sc)译码算法可以达到二进制离散无记忆信道(b-dmc)容量。但是,在有限码长下sc译码算法并不能为极化码提供令人满意的译码性能。为了弥补这一缺陷,现阶段主要有两种可以提高sc译码性能的方法。一种是由i.tal和a.vardy于2015年5月在ieeeinformationtheory第61卷第5期2213-2226页的“listdecodingofpolarcodes”中提出的连续消除列表(successivecancellationlist,scl)算法,另一种是o.afisiadis等于2014年在第48届ieeeasilomarconferenceonsignals会议上提出的基于比特翻转(bit-flip)的sc译码算法(scflip)。与sc译码算法不同,scl算法保留多条译码结果(又称译码路径),在译每一个信息比特时,可以同时考虑所有译码路径等于0和1的可能性,为了限制译码复杂度,在每个信息比特位置仅最多总共保留l条最可靠的路径。路径的可靠度,采用文中给出的路径可靠度量值近似估计。由于路径可靠度量值并不总是准确,i.tal和a.vardy发现,如果用一个循环冗余校验(crc)与极化码级联,则可以加强最终译码路径选择的准确性,从而大幅提高了极化码性能。正是这一译码方式,使得极化码入选了5gembb场景下,控制信道的编码方式。但是,该译码算法同样存在缺陷,主要是译码复杂度较高、时延大、存储空间开销大等等。
scflip则是一种既可以提升sc译码性能,又能不像scl需要很大存储空间和译码复杂度的译码算法。他的核心思想为当一次标准的sc译码算法失败后,则利用译码结果寻找到该错误帧中的第一个出错比特,并在新的一次译码尝试中,翻转寻找到的这个比特的硬判决值。根据统计结果显示,如果能准确寻找到该错误帧中的第一个出错比特,则90%的错误帧可以通过此算法得以纠正,从而大幅提高译码性能。
实际上,比特翻转算法为标准译码器在出错条件下提供了一种译码性能和复杂度可调节的折衷。通过t次译码尝试,去寻找第一个出错的位置,以提高性能。t越大,则重新译码正确的可能性就越大,但是复杂度也随之上升。在sc译码中,比特翻转机制已经得以很好地利用。但是,尚未应用于scl译码算法中,这是因为,sc的翻转准则(即利用最终译码结果寻找第一个出错比特)无法直接运用到scl中以提供良好的译码性能。
技术实现要素:
本发明的目的在于提供一种高性能极化码译码方法。该方法具有计算复杂度低和检测误码率低的优点。可以作为极化码译码技术迈向商业化应用的重要参考资料。实现本发明目的的技术方案为:
一种高性能极化码译码方法,步骤如下:
第一步,对k个信息比特进行crc编码,而后对所得到的码字进行极化码编码。极化码码字序列
其中,g为极化码的生成矩阵,
第二步,在接收端,接收信道数据序列为
接收端采用现有的标准串行抵消列表(scl)译码器进行译码试图恢复发送序列。将y作为译码的输入,译码列表空间大小为l;当每一个信息比特译码完成后,立即计算当前位置的翻转度量值,直至最后译码结束;
第三步,对scl译码结果进行crc检测,如果有译码路径可以通过crc,则选择能够通过crc中最可靠的路径作为译码输出。如果没有路径可以通过crc,则启动比特翻转机制,即进行t次重新译码尝试,每次译码尝试中,确定正确路径最有可能被删除出候选路径列表的位置i,翻转全部路径在位置i的由标准scl译码所得到的译码比特。其余比特仍采用标准scl译码方法。每次新的译码尝试完成后,将所得到的新的l条译码结果进行crc检测。重译过程直到有路径能通过crc检测或者达到最大重译次数t为止。如果有译码路径能通过crc检测,则挑选过检路径中最可靠的路径作为译码输出,如果没有,则选择原始scl译码中最可靠的路径作为译码输出。
本发明与现有的基于极化码的标准scl译码方法相比,其显著优点为:
(1)有效地提升了译码性能。当标准scl译码错误后,通过t次译码尝试,可以以较大概率将正确路径在候选路径中恢复。并且由于其余l-1条干扰路径也参与比特翻转,故均受到额外的路径可靠度量值惩罚,进一步保证了正确译码路径被保留至最后输出。
(2)几乎无复杂度增加。在高信噪比下,本方法下的平均译码复杂度相比标准scl译码器几乎没有提升。
附图说明
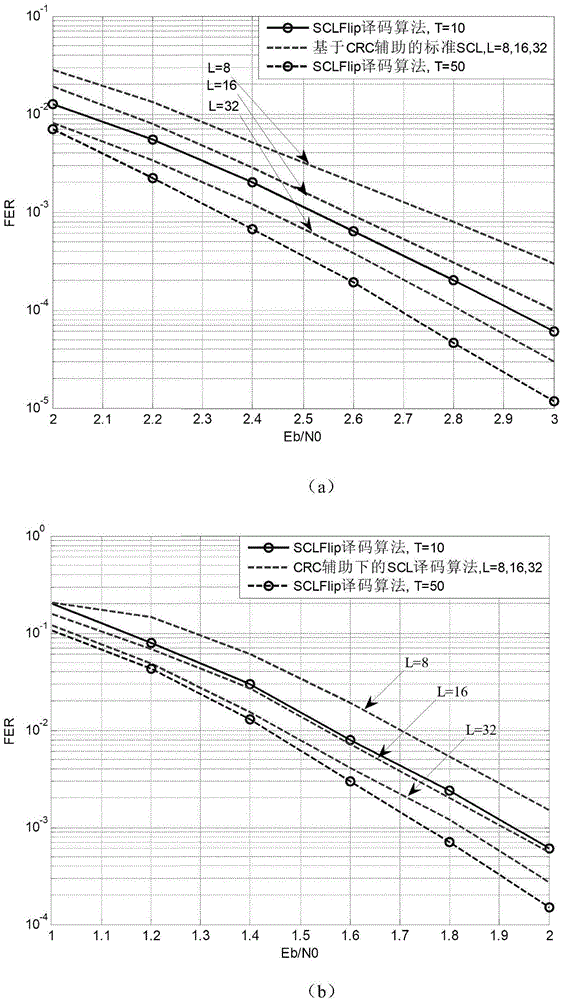
图1是采用本发明中公开的译码算法与标准scl译码算法性能在不同码长下的对比示意图。(a)是l=8下的sclflip译码算法同基于crc辅助下的标准scl译码算法性能比较,码长为256,码率为0.5;(b)是l=8下的sclflip译码算法同基于crc辅助下的标准scl译码算法性能比较,码长为1024,码率为0.5。
图2是采用本发明中公开的译码算法与标准scl译码算法的平均复杂度对比示意图。
具体实施方式
下面对本发明作进一步详细描述。
本发明为一种高性能极化码译码方法。首先对信息序列进行crc编码、极化编码和调制后得到发送信号。接收端采用基于比特翻转下的串行抵消译码算法(bit-flipbasedscl,sclflip)。该方法包含两个部分,首先由标准scl译码算法进行译码,译码结果由crc进行检测,如果有译码路径可以通过crc检测,则用可通过crc检测且最可靠的译码路径作为译码结果。如果无译码路径通过crc检测,则立即启动比特翻转机制:即寻找到正确路径掉出候选路径的位置,将此位置的所有路径的当前由标准scl译码得到的译码比特进行翻转,从而将正确路径在候选路径中恢复。其余信息比特仍采用标准scl算法译码。
本发明为基于极化码的比特翻转串行抵消译码算法,其具体实施步骤如下:
第一步,对k个信息比特进行crc编码,而后对所得到的码字进行极化码编码。极化码码字序列
其中,g为极化码的生成矩阵,
第二步,在接收端,接收信道数据序列为
接收端采用现有的标准串行抵消列表(scl)译码器进行译码试图恢复发送序列。将y作为译码的输入,译码列表空间大小为l。当每一个信息比特译码完成后,立即计算当前位置的翻转度量值,直至最后译码结束。
标准scl译码算法表示为scl(0),在译码过程中译码器保留了l个最可靠的译码路径。在对信息比特进行译码时,需要为每条译码路径考虑当前比特译为0或1的概率,相当于将现有l条路径扩展为2l条,并基于可靠度量值选取最可靠的l条路径保留,作为下一个译码比特的输入信息,同时删除其余路径。
用
定义更为一般的译码向量:
其中,
第三步,对scl译码结果进行crc检测,如果有译码路径可以通过crc,则选择能够通过crc中最可靠的路径(路径可靠度量值最小)作为译码输出。如果没有路径可以通过crc,则启动比特翻转机制。该机制包含t个新的译码尝试,每次译码尝试需挑选一个子信道位置进行翻转操作。挑选依据为该位置的翻转度量值。对于任意位置
此处有:
由于标准scl译码器仅仅在译信息比特时会存在正确路径被删除的可能,故对于任意的冻结位,即
需要注意的是,该性质仅成立于sclflip译码器寻找需要翻转的位置时,在标准scl译码器中不成立。基于此性质可得
其中,
其中
故每个信息比特位置的翻转度量可以定义为:
需要注意的是,每个信息位置的翻转度量值需要在scl(0)译码中当前位置译码结束后就立即利用公式(5)和(6)计算,而不可等到全部比特译码完毕后再计算。发现scl(0)译码失败后,立即基于各信息位置的翻转度量值建立比特翻转列表,表示为
我们用scl(it)表示在第it个子信道位置做比特翻转操作的译码尝试,其中
由公式(7)和公式(8)可知,scl(it)译码特征在于,在第
每次译码尝试结束后进行crc校验,若有译码路径能够通过,则中止剩余的译码尝试,选择能通过crc的最可靠路径作为输出。如果没有译码路径能够通过,则从比特翻转列表中选取下一翻转位置it+1进行scl(it+1)译码。直至比特翻转列表中t个子信道位置都被尝试翻转或有译码路径通过crc为止。
整个sclflip译码算法流程可以用如下算法进行总结
图1给出了采用本发明中公开的sclflip译码算法与标准scl译码算法性能在不同码长下的对比示意图,其中纵坐标表示为误帧率(fer)。
图1(a)采用了极化码码长n=256,且α固定为0.35。可以发现,本发明sclflip译码器在t=10时,比基于crc辅助的标准scl译码算法在l=16时的性能更好。当t=50时,本发明sclflip译码算法性能要好于基于crc辅助的标准scl译码算法在l=32时的性能。在图1(b)中,极化码码长调整为n=1024,α固定为0.4。当t=10时,本发明公开的sclflip译码器与基于crc辅助的标准scl译码算法在l=16时性能基本接近。而t=50时,本发明的sclflip译码器性能比基于crc辅助的标准scl译码算法在l=32时性能要好。总的来说,在t给定的情况下,码长越小性能增益越明显。
图2给出了采用本发明中公开的sclflip译码算法与标准scl译码算法的平均归一化复杂度对比示意图。可以看到,极化码码长取到1024并且码率为0.5时,列表空间l=8的sclflip译码算法在低信噪比时复杂度非常高,但是随着信噪比的不断提升,其复杂度很快地收敛于scl译码算法(l=8)。特别地,在eb/no=1.5db时,t=50下的sclflip译码器的复杂度与l=16下的标准scl译码算法的复杂度相当,但是结合图1可见,其性能却优于l=32下的标准scl译码算法。
- 还没有人留言评论。精彩留言会获得点赞!