利用非均匀窗口大小的并行TURBO解码的制作方法
本公开涉及用于执行turbo检测处理以从接收到的信号中恢复数据符号的帧的检测电路,该数据符号的帧包括该帧的每个数据符号的一个或多个奇偶校验和/或系统软判决值。该帧的数据符号已经用turbo编码器进行编码,该turbo编码器包括上部卷积编码器和下部卷积编码器,每个卷积编码器可以由具有多个网格状态的网格表示。
因此,本公开的实施例可以提供被配置为使用turbo解码器来恢复数据符号的帧的接收器和用于解码被turbo编码的数据的方法。在一个示例中,数据符号是比特。
本申请要求对英国专利申请1702341.7的巴黎公约优先权,其内容通过引用结合于此。
背景技术:
在过去的二十年里,无线通信已经被受益于迭代解码算法的信道码而彻底改变了。例如,长期演进(longtermevolution,lte)[1]和wimax[2]蜂窝电话标准采用turbo码[3],该turbo码包括两个卷积码的级联。传统上,对数巴赫-科克-耶利内克-拉维夫(logarithmicbahl-cocke-jelinek-raviv,对数-bcjr)算法[4]被用于马尔可夫链的迭代解码,该马尔可夫链由这些卷积码施加在编码比特上。同时,无线局域网(wirelesslocalareanetworks,wlan)的wi-fi标准[5]已经采用低密度奇偶校验(lowdensityparitycheck,ldpc)码[6],其可以基于最小和算法[7]操作。由于它们强大的纠错能力,这些复杂的信道编码已经促进了以紧密接近无线信道的容量的传输吞吐量的可靠通信。然而,如果要求实时操作,可实现的传输吞吐量受到迭代解码算法的处理吞吐量的限制。此外,迭代解码算法的处理延迟对端到端延迟施加了限制。这尤其重要,因为多千兆比特传输吞吐量和超低端到端延迟可能预期是下一代无线通信标准[8]的目标。因此,需要具有改进的处理吞吐量和更低处理延迟的迭代解码算法。由于最小和算法的固有并行性,它可以以完全并行的方式操作,促进ldpc解码器具有高达16.2gbit/s的处理吞吐量[9]。相比之下,最先进的turbo解码器的处理吞吐量[10]被限制在2.15gbit/s。这可能归因于对数-bcjr算法的固有串行性质,这是由其前向递归和后向递归的数据依赖性所施加的[4]。更具体地,由典型的两个卷积编码器中的每一个生成的被turbo编码的比特必须跨越多个连续的时间段被串行处理,该多个连续的时间段是实际集成的电路实施方式中的时钟循环(clockcycle)。此外,对数-bcjr算法通常交替地应用于两个卷积码,直到已经执行了足够数量的解码迭代。结果,要求数千个时间段来完成最先进的turbo解码器的迭代解码处理。
因此,提供具有较少的数据依赖性并且使能够高度并行处理的、对数-bcjr解码器的替代方案呈现技术问题。
技术实现要素:
根据本技术的第一示例实施例,提供了一种turbo解码器电路,用于执行turbo解码处理以从接收到的信号中恢复数据符号的帧,该数据符号的帧包括该帧的每个数据符号的奇偶校验或奇偶校验以及系统软判决值(llr值)。该帧的数据符号可以已经用turbo编码器使用系统码或非系统码来编码,使得接收到的该帧的软判决值可以包括系统码示例的系统和奇偶校验符号或非系统码的奇偶校验符号的软判决值。turbo解码器电路恢复已经用turbo编码器编码的帧的数据符号,该turbo编码器包括每个能够由网格表示的上部卷积编码器和下部卷积编码器、以及在上部卷积编码器和下部卷积编码器之间交织编码数据的交织器。turbo解码器电路包括时钟、用于交织软判决值的可配置网络电路、上部解码器和下部解码器。上部和下部解码器中的每一个包括处理元件,该处理元件被配置为在一系列连续时钟循环期间,从可配置网络电路迭代地接收与数据符号有关的先验软判决值(先验llr),该数据符号与表示上部或下部卷积编码器的状态之间的可能路径的整数个连续网格级(stage)的窗口相关联。处理元件使用先验软判决值执行与该窗口相关联的并行计算,以生成与数据符号有关的对应非本征软判决值。可配置网络电路包括网络控制器电路,该网络控制器电路在连续时钟循环期间迭代地控制可配置网络电路的配置,以通过交织由下部解码器提供的非本征软判决值来为上部解码器提供先验软判决值,并且通过交织由上部解码器提供的非本征软判决值来为下部解码器提供先验软判决值。由网络控制器控制的可配置网络电路执行的交织是根据预定调度的,这在一个或多个连续时钟循环的不同循环提供先验软判决值,以避免在相同时钟循环期间向上部或下部解码器的相同处理元件提供不同先验软判决值之间的竞争。
因此,根据本技术的示例实施例,上部解码器和下部解码器的每个处理元件执行与其网格的窗口相关联的计算。这意味着每个处理元件正在对与帧的数据符号的一部分(section)相关联且相对应的网格的一部分(section)执行与turbo解码的前向递归和后向递归相关联的计算。作为turbo解码器的任意并行处理的结果,处理元件可以划分上部解码器的网格,而不限制窗口大小到处理元件的映射,尽管可以通过在可用的处理元件之间尽可能多地共享网格级(trellisstage)的窗口大小实现更大的解码率。这也意味着帧的大小可以独立于可用于执行turbo解码的处理元件的数量而变化,从而可以动态配置通过划分网格形成的窗口大小。turbo解码电路的这种任意并行性质至少部分地是由于预定调度而实现的,该预定调度配置可配置网络,不仅根据在编码器处执行的交织来交织软判决值,而且还管理软判决值的传送,以避免在相同时钟循环中向相同处理元件传送不同软判决值而引起的竞争。
本公开的各种其他方面和特征在所附权利要求中限定,并且包括turbo解码的方法、通信设备和无线通信网络的基础设施装备。
附图说明
现在将仅参考附图通过示例的方式描述本公开的实施例,在附图中相同的部分被提供有对应的参考编号,并且其中:
图1是根据lte标准操作的移动通信系统的示意图;
图2是图1中所示的lte系统的示例发射器的示意框图;
图3是图1中所示的lte系统的示例接收器的示意框图;
图4是简化的turbo编码器的示意框图;
图5是示出lteturbo编码器的更详细示例的示意框图;
图6是表示使用形成图5的turbo编码器的一部分的卷积编码器编码的状态和状态转换的图示;
图7是根据对数-bcjr算法的示例turbo解码器的示意框图;
图8a是图形地示出对于对数-bcjrturbo解码器的上部和下部解码器每个中的单个处理元件的后向和前向递归的调度的示意表示,并且图8b是对数似然比的生成的对应的图;
图9是完全并行turbo解码器的示意框图;
图10是根据本技术的示例实施例的任意并行turbo解码器的示意框图;
图11是根据本技术实施例的上部或下部解码器的处理元件中的一个的示例的示意框图;
图12a、12b、12c、12d是图形地示出在处理元件(称为子处理元件)内执行的后向和前向递归的调度以生成对于在包括第二前向子处理元件的任意并行turbo解码器的上部和下部解码器每个中的单个处理元件的对数似然比的示意表示,该第二前向子处理元件操作相对于第一前向子处理元件延迟的一个时钟循环;
图13a是被配置为计算后向子处理元件中的后向状态度量向量的、图11中所示的处理元件的一部分的示意电路图,并且图13b是被配置为计算第一前向子处理元件中的前向状态度量向量的、图11中所示的处理元件的一部分的示意框图;
图14a是被配置为计算第一前向子处理元件中的比特度量向量的、图11中所示的处理元件的一部分的示意电路图,并且图13b是被配置为计算第二前向子处理元件中的非本征(extrinsic)和后验(posteriori)对数似然比的、图11中所示的处理元件的一部分的示意框图;
图15是误码率相对于信噪比的曲线图,其示出了根据本技术实施例使用128个处理元件和512个符号的帧长度对于不同数量的时钟循环的任意并行turbo解码器的性能;以及
图16是误码率相对于信噪比的曲线图,其示出了根据本技术实施例使用128个处理元件和6144个符号的帧长度、对于不同数量的时钟循环的任意并行turbo解码器的性能。
具体实施方式
示例通信系统
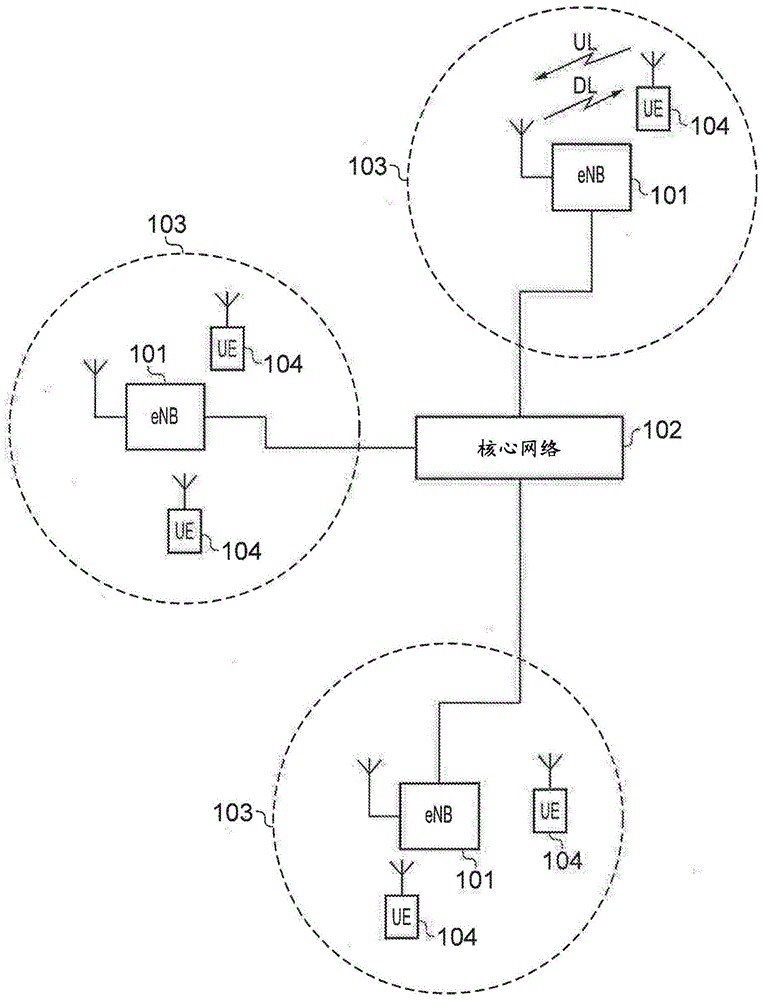
图1提供了传统移动电信系统的示意图,其中该系统包括移动通信设备104、基础设施装备101和核心网络102。基础设施装备也可以被称为例如基站、网络元件、增强型节点b(enhancednodeb,enodeb)或协调实体,并且向覆盖区域或小区内的一个或多个通信设备提供无线接入接口。一个或多个移动通信设备可以经由使用无线接入接口发送和接收表示数据的信号来传输数据。网络实体101可通信地链接到核心网络102,其中核心网络可以连接到具有与由通信设备104和基础设施装备102形成的结构类似的结构的一个或多个其他通信系统或网络。核心网络还可以为由网络实体所服务的通信设备提供包括认证、移动性管理、计费等的功能。图1的移动通信设备也可以被称为通信终端、用户设备(userequipment,ue)、终端设备等,并且被配置为经由网络实体与由相同或不同覆盖区域服务的一个或多个其他通信设备通信。通信系统可以根据任何已知的协议来操作,例如,在一些示例中,系统可以根据3gpp长期演进(lte)标准来操作,其中网络实体和通信设备一般地分别被称为enodeb和ue。
如将从上面解释的操作中理解,ue和enodeb的物理层被配置为发送和接收表示数据的信号。因此,典型的发射器/接收器链如图2和3所示。
图2提供了示出了组成发射器的组件的示意框图,该发射器可以经由如图1中所示的lte系统的无线接入接口形成物理层传输的e-nodeb101或通信设备104的一部分。在图2中,数据经由数据格式化器204处的输入接收,并形成用于传输的帧或子帧。然后,数据帧被纠错编码器206利用纠错码来进行编码,并被馈送到符号形成器208,该符号形成器208将纠错编码的比特形成为比特组,以用于映射到用于调制的符号上。然后,数据符号被符号交织器210交织,并被馈送到ofdm调制器212,该ofdm调制器212用已经从交织器210接收的数据符号来调制ofdm符号的子载波。然后,ofdm符号被转换成rf频率,并由发射器214经由天线216发送。
相对应地,操作以经由lte无线接入接口接收经由物理层为通信设备104或enodeb101发送的数据的接收器包括接收器天线301,该接收器天线301检测经由无线接入接口发送到射频接收器302的射频信号。图3表示接收器的简化版本,并且几个块将组成ofdm解调器/均衡器304,该ofdm解调器/均衡器304将时域ofdm符号转换到频域,并解调ofdm符号的子载波以恢复数据符号并执行解交织(deinterleave)等。然而,ofdm解调器/均衡器304的输出是将表示数据比特的编码的软判决值馈送到turbo解码器306。turbo解码器执行turbo解码算法,以检测和恢复发送的数据比特的估计,该发送的数据比特被输出为与发射器的输入相对应的输出308上的数据比特流。
对于如上所述的lte的示例,图4示出了图2中所示的纠错编码器206的示例实施例。图4提供了示出简化的turbo编码器的示例表示,该简化的turbo编码器对包括kl个比特的消息帧
如以上参考图2所解释的,在turbo编码之后,编码帧可以被调制到无线信道上并被发送到接收器,例如图3中提供的示例。
lteturbo编码器
图5中提供了lteturbo编码器[1]的更具体的图示,其还示出了终止机制。对于图5中所示的示例,turbo编码器是1/3速率编码,其中从如图2中所示的数据格式化器204接收的数据比特被馈送到上部卷积编码处理器401。从图5中可以看出,所接收的kl比特的消息帧
在下部卷积编码器403中,开关420在从内部交织器404接收的比特之间切换,并且对应于上部卷积编码器的开关410。以类似于上部卷积编码器的方式,下部卷积编码器的输出信道422、424分别提供奇偶校验帧
总之,图5的lteturbo编码器[1]采用12个附加终止比特来迫使每个卷积编码器进入最终状态
图5中呈现的turbo编码器的示例提供了上部卷积编码器401和下部卷积编码器403,其每个具有三个存储器元件406。如熟悉卷积编码器的人已知的,存储器元件406的二进制内容可以被解释为状态,使得卷积编码处理可以被合成为通过包括卷积编码器的可能状态的网格的转换。这样,卷积编码器或turbo编码器可以被描述为马尔可夫处理,并且因此被表示为网格图。用于卷积编码器的状态转换图的示例如图6中所示。图6的状态转换图表示具有m=8个状态和每状态的k=2个转换的网格的一级(onestage),并且因此可以提供与以相同方式操作的上部卷积编码器401和下部卷积编码器403相对应的示例。对于上部卷积编码器401,通过考虑对应的消息比特b1,k,从初始状态s0=1开始,并相继转换到每个后续状态sk∈{1,2,...,m}。因为对于消息比特b1,k∈{0,1}有两个可能的值,所以对于可以通过从先前状态sk-1转换来达到的状态sk有k=2个可能的值。例如,在图6中,sk-1=1的先前状态意味着后续状态选自sk∈{1,5}。这个示例也可以用符号c(1,1)=1和c(1,5)=1来表示,其中c(sk-1,sk)=1指示卷积编码器可以从sk-1转换到sk,而c(sk-1,sk)=0指示这种转换是不可能的。在k=2选项中,选择状态sk的值使得b1(sk-1,sk)=b1,k。例如,在图6中,sk-1=1和b1,k=0给出sk=1,而sk-1=1和b1,k=1给出sk=5。接着,根据b2,k=b2(sk-1,sk)和b3,k=b3(sk-1,sk),为奇偶校验帧b2和系统帧b3中的对应的比特选择二进制值。在图6的示例中,sk-1=1和sk=1给出b2,k=0和b3,k=0,而sk-1=1和sk=5给出b2,k=1和b3,k=1。
__________________________________________________________________
lteturbo解码器的示例
在它们通过无线信道传输之后,如图4所示由turbo编码器生成的三个编码帧
其中上标“a”、“e”或“p”可以被附加以分别指示先验、非本征或后验llr。
对数-bcjr算法通常形成通过表示马尔可夫处理的每个状态的连接的网格(诸如卷积编码器)、来执行前向递归处理和后向递归处理的解码或检测处理。对于被turbo编码的数据,执行对数-bcjr解码处理的解码器包括上部解码器和下部解码器。上部解码器和下部解码器中的每一个都各自执行前向递归处理和后向递归处理,并且为每次迭代生成馈送到上部解码器和下部解码器中的另一个的非本征llr。
图7提供了示出对应于图4的简化turbo编码器的、用于对数-bcjr算法的简化turbo解码器的示例实施方式的示意框图。对数-bcjrturbo解码器迭代地操作,其中i次迭代中的每一次迭代包括所示的所有处理元件或算法块的操作。
本技术的实施例可以提供与传统算法相比具有改进的解码率的任意并行turbo解码器。此外,与诸如在我们共同未决的国际专利申请pct/ep2015/067527[26]中公开的完全并行turbo解码器相比,应用turbo解码的并行处理的程度可以根据可用的一个或多个处理元件的数量而不是描述编码器的网格中的级的数量来设置。
根据用于解码由图5的编码器编码的数据帧的一个示例实施方式的lteturbo解码器包括上部解码器和下部解码器、以及上部终止元件(te)和下部终止元件、以及crc单元。上部解码器使用交织器连接到下部解码器,而下部解码器使用解交织器连接到上部解码器。lteturbo解码器通常一次解码一帧比特,并且通常支持所有l=188帧长度{k1,k2,k3,...,k188}={40,48,56,...,6144}和lte标准[1]的对应的交织器设计。为了发起长度为长度kl的帧的解码,其中l∈[1,l],上部解码器被提供有kl个奇偶校验llr
如图7所示,第一组2kl个算法块601专用于对由上部卷积编码器401产生的被turbo编码的数据执行turbo解码算法的第一部分。上部解码器601的第一行kl个算法块610专用于通过可能状态的网格执行前向递归处理,而第二行kl个算法块612专用于根据对数-bcjr算法通过网格级执行后向递归。每个算法块与网格中的kl个级中的一个级相对应,其包括一组先前状态和一组下一状态之间的一组转换。第二组2kl个算法块602专用于对由下部卷积编码器403产生的被turbo编码的数据执行turbo解码算法的第二部分。至于上部解码器601,下部解码器包括下部解码器602的第一行kl个算法块620,该下部解码器602的第一行kl个算法块620专用于通过可能状态的网格执行前向递归处理,而第二行kl个算法块622专用于根据对数-bcjr算法通过网格状态执行后向递归。
专用于执行对数-bcjr算法610的前向递归部分的、上部解码器601的kl个算法块610中的第k个算法块610被布置成从解调器接收第k个llr值
每个依次被布置成在上部解码器601和下部解码器602中一个接一个地执行前向递归的第k个算法块610、620组合l=3先验llr
在上部解码器601和下部解码器602中执行后向递归的第k个算法块612、622组合对于每个转换的先验度量
上部解码器601和下部解码器602为帧的每个数据比特交换非本征llr,该非本征llr成为编码数据帧的系统比特的估计。更具体地,交织器604根据由turbo编码器的上部卷积编码器401和下部卷积编码器402所使用的数据比特的交织,对在上部解码器601和下部解码器602之间传递的数据比特的llr值进行交织。此外,交织器604对在下部解码器602和上部解码器601之间传递的数据比特的llr值执行解交织,以反转由turbo编码器的上部卷积编码器401和下部卷积编码器402所使用的数据比特的交织。
如将从以上描述中理解,对于被turbo编码的数据的turbo解码通常包括贯穿解码处理操作的上部解码器和下部解码器。更具体地,上部解码器的操作更新kl个后验llr
使用网格级的窗口的turbo解码的适应
在操作以执行对数-bcjr算法的turbo解码器的一些实施方式中,奇偶校验、系统、先验、非本征和后验llr可以在解码期间被组合成连续窗口的链,每个窗口包括相等数量wl的每种类型的llr。此外,turbo解码处理通常根据具有cl个时钟循环的周期的周期性调度来完成。通常,wl和cl的值取决于当前帧长度kl。然而,不同的turbo解码器采用不同的开窗(windowing)和不同的调度技术,这将在下面的部分中讨论。
第一示例开窗
在第一示例[21]中,llr被分组为p=8个连续窗口的链,因为这是lte帧长度kl的所有l=188个支持值的最大公约数。这确保了所有窗口包括相同数量wl=kl/p的每种类型的llr,而不管当前帧的长度kl。因此,[21]的设计采用p=8个处理元件的链,其中每个处理元件对上部解码器的窗口中的不同的一个窗口以及对下部解码器的对应窗口执行处理。因此,每个窗口执行对数-bcjr算法的计算610、612、620、622的处理。这样,具有索引k∈[1,kl]的llr由具有索引
具有索引p∈[1,p]的处理元件基于包括wl个奇偶校验、系统、先验、非本征和后验llr的窗口来操作。这里,符号k′∈[1,wl]用于索引第p个窗口内的llr,该符号可以根据k=k′+(p-1)wl被转换为帧内的索引k∈[1,kl]。在解码处理开始时,具有索引p的处理元件被提供有wl个上部奇偶校验llr
每个处理元件根据下面的等式(1)至(4)对每个窗口执行计算。注意,与上部解码器不同,下部解码器不受益于系统llr,这相当于使得
此外,贯穿解码处理,每个解码器中的第(p-1)个处理元件周期性地向第p个处理元件提供对用于k′=0的情况的上部前向状态度量向量
处理元件根据图8中所示的调度进行操作。图8提供了图形表示,示出了处理元件如何调度(a)(1)和(2)的后向和前向递归、以及(b)对于第一开窗示例的turbo解码器中的单个处理元件的(3)和(4)的llr的生成。处理元件对上部解码器的窗口执行(1)到(4),接着对下部解码器的相对应的窗口执行(1)到(3)。这里,执行后向递归,其中递减的llr索引k′在连续的时钟循环中被处理。同时,执行前向递归,其中递增的llr索引k′在连续的时钟循环中被处理。在cl个时钟循环的每个周期中的前cl/2个时钟循环期间,处理元件执行上部解码器的前向递归和后向递归。此后,在cl个时钟循环的每个周期中的后cl/2个时钟循环期间,执行下部解码器的前向递归和后向递归,如图8所示。注意,以下讨论同样适用于上部和下部解码器,因此上标“u”和“l”从符号中移除。
后向递归基于(1)操作,以便生成后向状态度量向量βk′-1。这被存储在内部存储器中,以便促进其在递归的下一步中用作βk′,以及用于非本征llr
如图8中所示,在递归的后半部分的每个时钟循环中,由每个处理元件输出两个后验llr和两个非本征llr。更具体地,在为上部解码器执行的每个递归的后半部分的每个时钟循环期间,(4)用于生成后验llr
第二示例开窗
从[22]提供的第二示例以与第一示例的方式类似的方式操作,但是利用了所支持的lte帧长度的不同连续子集具有不同的最大公约数8、16、32和64的观察。更具体地,取决于帧长度kl,该设计采用8、16、32或64个窗口,每个窗口包括相同数量wl的每种类型的llr,根据
这种设计采用了p=64个处理元件的链,尽管这些处理元件中的一些在解码较短的帧长度时被去激活。更具体地,被激活的处理元件的数量等于所使用的窗口的数量,使得每个处理元件可以对上部解码器的窗口中的不同的一个窗口以及对于下部解码器的对应窗口执行处理。
处理元件对每个窗口的处理根据(6)-(9)完成。注意,与上部解码器不同,下部解码器不受益于系统llr,这相当于使得
对第一示例的turbo解码器设计的另一差异在于,分别计算(6)和(7)的后向状态度量向量βk′-1和前向状态度量向量αk′。在后向和前向递归的连续时钟循环中,这些状态度量可以无限制地增长,这可能导致固定点实施方式中的溢出。[23]的模归一化(modulenormalisation)方案利用了这样的观察,即每个向量中的状态度量的绝对值并不重要,相反,重要的是这些状态度量之间的差异。这激发了每个向量在其生成期间内归一化状态度量。为了最小化溢出的发生,归一化是通过减去每个向量中状态度量的最大值来实现的,如(6)和(7)中所示。
第三示例开窗
第三示例是所谓的“混洗(shuffled)”turbo解码器[24],其以类似于示例1和2的turbo解码器的方式操作,但是采用专用于执行上部解码器的解码的p个处理元件的一个链、以及专用于执行下部解码器的解码的p个处理元件的第二链,其中p是kl的整数除数。每个处理元件对于对应解码器中的窗口中的不同的一个窗口执行处理,其中每个窗口具有长度wl=kl/p。与第一和第二示例的turbo解码器相比,解码处理根据周期性调度完成,其中周期由cl=wl而不是由cl=2wl给出。更具体地,上部解码器的后向和前向递归与下部解码器的后向和前向递归同时执行。在调度的特定时钟循环中由一个解码器生成的非本征llr立即通过交织器或解交织器被传递到另一个解码器,在另一个解码器中它们可以在调度的下一个时钟循环中用作先验llr。
第四示例完全并行turbo解码器
完全并行turbo解码器(fullyparallelturbodecoder,fptd),诸如在我们共同未决的国际专利申请pct/ep2015/067527中公开的,以类似于第一示例的turbo解码器的方式操作,但是使用kl个窗口,每个窗口的长度为wl=1。因此,fptd采用p=kl个处理元件的链,其中每个处理元件对上部解码器的窗口中的不同的一个窗口以及对下部解码器的对应窗口执行处理。fptd解码处理根据周期性调度完成,其中周期由cl=2给出。每个窗口的处理根据下面的(10)-(15)完成。注意,在下部解码器的情况下,可以完全省略(15),因为它不生成后验llr。这里,(10)和(13)中的上标“c”表示时钟循环索引,而(11)、(12)、(14)和(15)中的上标“c-1”表示先前时钟循环的索引。包括该符号以便强调(10)的转换度量向量和(13)的比特度量向量是流水线式的。
不是在每个周期的第一时钟循环中对上部解码器执行所有处理,而是在第二时钟循环中对下部解码器执行处理之前,fptd采用由lte交织器的奇偶性质激发的奇偶调度。此外,fptd采用流水线技术,以便最大化可实现的时钟频率。更具体地,在每个周期的第一时钟循环期间,具有奇数索引的处理元件对上部解码器的对应窗口执行(10)、(14)和(15)的处理,以及对下部解码器的对应窗口执行(11)、(12)和(13)的处理。同时,具有偶数索引的处理元件对下部解码器的对应窗口执行(10)和(14)的处理,以及对上部解码器的对应窗口执行(11)、(12)和(13)的处理。在每个周期的第二时钟循环中,具有偶数索引的处理元件对上部解码器的对应窗口执行(10)、(14)和(15)的处理,以及对下部解码器的对应窗口执行(11)、(12)和(13)的处理。同时,具有奇数索引的处理元件对下部解码器的对应窗口执行(10)和(14)的处理,以及对上部解码器的对应窗口执行(11)、(12)和(13)的处理。注意,在用于(11)和(12)的fptd中使用的归一化技术不同于第二示例的归一化技术。更具体地,为了移除确定每个向量中最大状态度量的要求,(11)和(12)的方案总是减去第一状态度量。还要注意,fptd受益于向下部解码器提供系统llr
图9提供了如在pct/ep2015/067527中公开的fptd的图示。在图9中,相应的上部turbo解码部分701和下部turbo解码部分702对应于对数-bcjr算法601、602的上部turbo解码部分和下部turbo解码部分,但是被kl个并行算法块706、708代替。因此,上部解码器701由kl个算法块706组成,而下部解码器702由kl个算法块708组成。如图9所示,并且对应于对数-bcjr算法的操作,图3的接收器中的解调器向如图9所示被布置成两行的、turbo解码器的2kl个算法块708、706提供先验llr。更具体地,在它们通过无线信道的传输之后,三个编码帧被解调并被提供给图9的turbo解码器。解调器提供三个帧,每个帧包括kl个软值先验对数似然比(llr)
任意并行turbo解码器的示例实施例
如以上所解释的,在pct/ep2015/067527中公开的fptd提供了一种用于执行turbo解码的并行处理的布置,该布置移除了处理元件之间的依赖性,这允许每个处理元件并行地执行与每个网格级相对应的计算,并具有增加的吞吐量。因此,实际上,窗口大小如以上所解释。然而,fptd存在明显的缺点在于,使用fptd执行turbo解码的算法和计算要求在解码器处提供llr值的帧中的每一个符号由处理元件表示。对于lte帧的示例,所需求的处理器的数量将是k188=6144,因为这是所支持的最长帧长度。这可以被认为是一个缺点,因为只有这些处理器的有限子集可以用于较短的帧长度,导致降低的硬件效用。因此,将期望找到一种布置,其中可以利用任意数量的处理元件来实现turbo解码,允许在吞吐量和要对撞的(tobestruck)硬件效用之间达成期望的权衡。这种布置在以下段落中被称为任意并行turbo解码器。因此,根据本技术的实施例,任意并行turbo解码器(arbitraryparallelturbodecoder,aptd)被布置成使用任意数量的处理元件、使用并行处理来执行进一步的解码。为此,每个处理元件表示与在发送的帧中的多个符号相对应的多个llr值的处理算法中使用的变量的计算,使得可以减少处理元件的数量。然而,为了提供任意并行turbo解码器,有必要调整上部和下部解码器之间的符号的交织,因为每个处理元件正在对多个帧长度执行计算。结果,提供了被称为benes网络的可配置网络,该网络被调度以在上部解码器和下部解码器之间提供符号的最优切换,这尽可能地防止其中一个或多个处理元件空闲的冲突或等待循环。将在以下段落中将更好地理解本技术的实施例。本技术的实施例可以提供一种turbo解码器电路,用于执行turbo解码处理以从接收到的信号中恢复数据符号的帧,该数据符号的帧包括该帧的每个数据符号的奇偶校验和系统软判决值(llr值),例如其中该帧的数据符号已经用turbo编码器使用帧的每个数据符号的系统码或奇偶校验软判决值来编码,例如其中该帧的数据符号已经用turbo编码器使用非系统码来编码。因此,由接收到的信号表示的帧可以已经用系统或非系统码进行了编码。turbo解码器电路恢复已经用turbo编码器编码的帧的数据符号,该turbo编码器包括每个能够由网格表示的上部卷积编码器和下部卷积编码器、以及在上部卷积编码器和下部卷积编码器之间交织编码数据的交织器。turbo解码器电路包括时钟、被配置为交织软判决值的可配置网络电路、上部解码器和下部解码器。
上部解码器包括与上部卷积编码器相关联的多个上部处理元件,上部解码器的处理元件中的每一个处理元件被配置为,在一系列连续时钟循环期间,从可配置网络电路迭代地接收与数据符号有关的先验软判决值(先验llr),其中该先验软判决值与表示上部卷积编码器的状态之间的可能路径的整数个连续网格级的窗口相关联,以使用该先验软判决值执行与该窗口相关联的并行计算,以便生成与该数据符号有关的对应非本征软判决值,。该系列连续时钟循环是执行整个解码处理以便在turbo解码处理的多次迭代中恢复帧的数据符号所需求的多个时钟循环。然后,上部解码器的处理元件向可配置网络电路提供非本征软判决值。上部解码器的至少一个处理元件被配置为相对上部解码器的至少一个其他处理元件执行与不同数量的网格级相关联的窗口的计算。这是因为,例如,与上部卷积编码器的状态之间的可能路径相对应的网格级的数量可以不是处理元件数量的整数倍。
下部解码器包括与下部卷积编码器相关联的多个下部处理元件,下部解码器的处理元件中的每一个处理元件被配置为在一系列连续时钟循环期间,从可配置网络电路迭代地接收与数据符号有关的先验软判决值,其中该先验软判决值与表示下部卷积编码器的状态之间的可能路径的整数个连续网格级的窗口相关联,以使用该先验软判决值执行与该窗口相关联的并行计算,以便生成与该数据符号有关的对应非本征软判决值。然后,每个处理元件向可配置网络电路提供非本征软判决值。下部解码器的至少一个处理元件被配置为相对下部解码器的至少一个其他处理元件执行与不同数量的网格级相关联的窗口的计算。
可配置网络电路包括网络控制器电路,该网络控制器电路在连续时钟循环期间,迭代地控制可配置网络电路的配置,以通过交织由下部解码器提供的非本征软判决值来为上部解码器提供先验软判决值,并且通过交织由上部解码器提供的非本征软判决值来为下部解码器提供先验软判决值。由网络控制器控制的由可配置网络电路执行的交织是根据预定调度的,这在一个或多个连续时钟循环的不同循环提供先验软判决值,以避免在相同时钟循环期间向上部或下部解码器的相同处理元件提供不同先验软判决值之间的竞争。
因此,根据本技术的示例实施例,上部解码器和下部解码器的每个处理元件执行与其网格的窗口相关联的计算。这意味着每个处理元件正在对与帧的数据符号的一部分相关联且相对应的网格的一部分执行与turbo解码的前向递归和后向递归相关联的计算。作为turbo解码器的任意并行处理的结果,处理元件可以划分上部解码器的网格,而不限制窗口大小到处理元件的映射,尽管可以通过在可用的处理元件之间尽可能多地共享网格级的窗口大小实现更大的解码率。这也意味着帧的大小可以独立于可用于执行turbo解码的处理元件的数量而变化,从而可以动态配置通过划分网格形成的窗口大小。
本技术的实施例可以通过以一种方式将可配置网络布置为将先验软判决值从上部解码器提供给下部解码器并且从下部解码器提供给上部解码器,来实现这种任意并行解码,其中在该方式中两者都匹配编码器处执行的交织,而且还避免了在相同时钟循环期间向上部或下部解码器的相同处理元件提供不同先验软判决值之间的竞争,因为处理元件正在为包括多于一个的网格级的窗口执行计算。这是通过预定调度来实现的,该预定调度在至少一个时钟循环中布置来自上部解码器或下部解码器的一个或多个先验软判决值,以例如被延迟一个或多个时钟循环、或因为先验软判决值没有被传送而被跳过。已经接收没有延迟或跳过的先验软判决值的处理元件继续由该处理元件使用在先前迭代中接收的该先验软判决值的先前版本执行的计算的前向递归和后向递归。
在一些示例性实施例中,为了将来自上部解码器的非本征软判决值传输为用于下部解码器的先验软判决值,并将来自下部解码器的非本征软判决值传输为用于上部解码器的先验软判决值,可配置网络电路可以包括一个或多个存储器,其用于在经由可配置网络电路进行通信之前存储非本征软判决值,或者在通信之后存储先验软判决值。因此,存储器还可以根据预定调度与可配置网络电路的配置相组合,以保持如果其被跳过以避免竞争则不会被更新(重写)的先验软判决值。因此,在一个或多个时钟循环上存储用于turbo解码处理的迭代的先验软判决值,以执行对网格窗口的计算,这可以重用在特定存储器位置处保持的相同的先验软判决值,为此该处理元件被重用,以避免竞争。至于fptd[26]的示例,这种妥协可能导致精度降低,但是总体而言,turbo解码器的处理可以产生对数据符号的帧的估计的更快结果。
每个处理元件可以正根据用于整数个网格级的前向和后向调度来执行计算,这些计算输出成为用于下部解码器或上部解码器中的另一个解码器的先验软判决值的非本征软判决值。因此,交织器的调度相对于这些计算来确定,并且非本征软判决值被生成并传送到上部和下部解码器中的另一个解码器,该非本征软判决值被调度以避免任何竞争,代价是在通过交织器的传送中引入延迟或删除一些软判决值,并且调度被设计成减少这些竞争。预定调度的设计是为了减少延迟和删除。延迟的影响可能是针对处理元件在没有最先进/最新的非本征/先验软判决值(extrinsic/apriorisoftdecisionvalues)的情况下继续前向递归和后向递归的计算,因为作为竞争的结果,最新版本不能被传送。在一些示例中,软判决值可以比要求的更早传送,但是目的是减少针对由于非本征软判决值而错过的机会的数量。处理元件使用它在先前次迭代中所具有的先验软判决值,或者如果它是第一次迭代,它将其设置为零。
在一些示例实施例中,由一个或多个处理元件根据网格的窗口执行的计算可以由其中根据子窗口执行计算和处理、包括一个或多个时钟循环的不同子周期、例如包括窗口的网格状态的两个子窗口形成。在一些示例中,每个窗口的处理被限制到包括网格级的前半向上舍入(firsthalfroundingup)或网格级的后半向上舍入(lasthalfroundingup)的子窗口。在这些子周期和子窗口内,完成前向递归和后向递归,并且然后,如果子周期中的时钟循环数大于子窗口中的网格级的数量,则执行前向递归和后向递归的开始。
在一些示例中,作为由处理元件执行以执行turbo解码处理的计算的一部分,根据前向或后向状态度量中的一个生成非本征软判决值,另一个从存储器加载。
图10提供了任意并行turbo解码器(aptd)的示意框图。如图10中所示,并且对应于图7和9所示的参考编号,aptd采用上部解码器1001和下部解码器1002,每个解码器包括p个处理元件的链,其中数字p可以任意选择,诸如p=64。上部和下部解码器每个包括上部处理元件(pe)1006和下部处理元件1008,它们分别执行与上部卷积编码器和下部卷积解码器相对应的前向递归和后向递归的计算。上部解码器1001和下部解码器1002的每个处理集中的最后一个元件是终止元件1010、1012。
如将在以下段落中解释的,上部处理元件1006和下部处理元件1008每个执行计算以实施aptd。然而,为了容纳其中上部处理元件1006和下部处理元件1008每个对多个帧长度执行计算的布置,aptd包括可配置交织器1020,用于将上部解码器1001中的处理元件1006连接到下部解码器1002中的处理元件1008,以及解交织器,用于将下部解码器1002中的每一个处理元件1008连接到上部解码器1001中的每一个处理元件1006。交织器和解交织器各自由包括
可配置交织器由两个
aptd可用于一次解码一帧比特,支持所有l=188帧长度{k1,k2,k3,...,k188}={40,48,...,5661,4和lteturbo码[1]的对应交织器设计。为了发起帧的解码,使用
终止元件在解码处理开始时仅操作一次。相比之下,上部解码器和下部解码器的处理元件贯穿解码处理连续地操作。更具体地,上部解码器连续地更新kl个后验llr
在解码处理中,奇偶校验、系统、先验、非本征和后验llr被分组到连续窗口的链中,其中每个窗口由对应的上部或下部解码器中的连续处理元件处理。更具体地,对于长度为kl≤2p的短帧,每个解码器中的前(p-kl/2)个处理元件被去激活,同时剩余的kl/2个连续处理元件处理连续窗口,每个窗口包括两个每种类型的llr。因此,由具有索引p∈[1,p]的处理元件处理的每种类型的llr的数量由以下给出
等效地,具有索引k∈[1,kl]的llr由具有索引
因此,具有索引k∈[1,kl]的llr由具有以下索引的对应解码器中的处理元件来处理
其中
aptd解码处理根据周期性调度完成,其中根据下式,周期cl取决于当前帧长度kl,
其中dl为非负整数,可以针对每个帧长度kl单独选择dl,以便控制纠错能力和aptd的吞吐量之间的权衡。例如,可以针对kl=2016选择dl=2,其中kl=2016是当p=64时不满足mod(kl,p)=0的最长lte帧长度。在连续的时钟循环中,图10的计数器1026重复计数到cl,其中使用
贯穿aptd解码处理,当前帧长度kl的索引l和计数器c的值被提供给每个处理元件,以及图10的交织器rom控制器1026。交织器rom控制器将l和c转换成地址,该地址可用于读取
图10的每个终止元件被提供有六个输入llr
该等式是使用使用
图11提供了示意框图,其示出了形成上部解码器1001和下部解码器1002的图10所示的处理元件的一个示例实施方式的部分。如上所述,处理元件可以被赋予索引p∈[1,p],使得每个解码器在包括wl,p个奇偶校验、系统、先验、非本征和后验llr的窗口的基础上操作。在本部分中,符号k′∈[1,wl,p]用于第p个窗口内的llr的索引,它可以根据
如图11中所示,处理元件包括执行计算以实施aptd所需求的组件。如图11中所示,处理元件在上侧接收导体(conductor)1101、1102上的当前llr值,这些值被存储在ram1104、1105中。相对应地,在处理元件的下侧,先验llr值在导体1104上从
如将从图11中所示的电路图中理解,与上部解码器不同,下部解码器不受益于系统llr,这相当于使得
在解码处理开始时,每个解码器中具有索引p的处理元件被提供有wl,p个奇偶校验llr
此外,如图10中所示,贯穿解码处理,每个解码器中的第(p-1)个处理元件周期性地向第p个处理元件提供对用于k′=0的情况的前向状态度量向量
在解码处理的每个时钟循环期间,如图11中所示,每个处理元件接受上述输入,从ram读取,在后向、第一前向和第二前向子处理元件内执行处理,写入到ram以及生成上述输出。每个上部处理元件使用五个ram,以用于存储f比特奇偶校验llr
存储先验llr
后向和前向ram控制器由l和c驱动,它们分别使用该l和c来产生地址ab∈[1,wl,p]和af∈[1,wl,p]。这里,生成地址ab和af,使得后向子处理元件和第一前向子处理元件根据图12中所示的调度来操作。这里,后向子处理元件执行后向递归,其中递减的llr索引k′在连续的时钟循环中被处理。同时,第一前向子处理元件执行前向递归,其中递增的llr索引k′在连续的时钟循环中被处理。在cl个时钟循环的每个周期的前
图12提供了示出由第一和第二前向子处理元件以及与图11中所示的那些相对应的上部解码器的处理元件的后向子处理元件执行一系列处理序列的图形表示。图12示出了用于操作第一和第二前向子处理元件、以及上部解码器的处理元件内和下部解码器的处理元件内的后向子处理元件的调度。注意,如下所述,第二前向子处理元件的操作相对于第一前向子处理元件的操作延迟一个时钟循环,因为它们被图11中的流水线寄存器分隔开。
注意,用于子处理元件的操作的调度可以用矩阵来描述。在上部解码器和下部解码器中的每一个采用p=9个处理元件来对kl=40比特的最短lte帧长度执行处理的情况下,我们根据(17)获得窗口长度。假设选择dl=2以便在纠错能力和吞吐量之间进行权衡,我们根据(19)获得
该矩阵包括针对p=9个处理元件中的每一个处理元件的一列和针对每个调度周期中的cl=6个时钟循环中的每一个时钟循环的一行。这里,如图12中所示,第p列和第c行中的元件标识了在每个调度周期内的第c个时钟循环中由第p个处理元件处理的llr的索引k∈[1,kl]。同样,用于上部解码器的后向子处理元件、下部解码器的第一前向子处理元件和下部解码器的后向子处理元件的调度可以分别由以下三个矩阵描述。
如图11中所示,除了llr
注意,与上部解码器不同,下部解码器不受益于系统llr,这相当于使得
图13(a)示出了在后向子处理元件中执行(20)的后向状态度量向量
如图11中所示,在后向子处理元件的计算后,后向状态度量向量
类似地,如上所述,图11的第一前向子处理元件被提供有llr
注意,与上部解码器不同,下部解码器不受益于系统llr,这相当于使得
图13(b)示出了在第一前向子处理元件中执行(26)的前向状态度量向量
如图11中所示,在第一前向子处理元件的计算之后,前向状态度量向量
同时,第一前向子处理元件使用图14a的示意图执行(27)的计算,以便生成比特度量向量
这里,(27)中的上标“c”表示时钟循环索引,其被包括以强调(28)和(29)中流水线的动作,如将在下面讨论的。
图14(a)提供了示意电路图,该示意电路图提供了用于计算第一前向子处理元件中(27)的比特度量向量
如图11中所示,流水线寄存器用于向第二前向子处理元件供应比特度量向量
注意,与上部解码器不同,下部解码器不受益于系统llr,这相当于使得
图14b提供了示意电路图,该示意电路图提供了用于计算第二前向子处理元件中(28)和(29)的非本征llr
注意,对于第二前向子处理元件的调度可以由以上在(21)和(23)中对于第一前向子处理元件例示的相同矩阵来描述,但是由于流水线延迟而向下旋转(rotate)一行。在该示例中,对于上部和下部解码器中的第二前向子处理元件的调度可以分别由以下两个矩阵来描述。
在通过交织器和解交织器的llr交换与前向递归一起被调度的方案中,存储非本征llr
如上所述,kl=40比特lte交织器和解交织器可以分别由向量π=[1,38,15,12,29,26,3,40,17,14,31,28,5,2,19,16,33,30,7,4,21,18,35,32,9,6,23,20,37,34,11,8,25,22,39,36,13,10,27,24]和π-1=[1,14,7,20,13,26,19,32,25,38,31,4,37,10,3,16,9,22,15,28,21,34,27,40,33,6,39,12,5,18,11,24,17,30,23,36,29,2,35,8]来描述。因此,在我们的示例中,由交织器向下部解码器和由解交织器向上部解码器提供先验llr的调度可以分别由以下两个矩阵描述。
先验llr被传送到的下部解码器和上部解码器内的特定处理元件可以由矩阵
然而,这些矩阵揭示了通过交织器和解交织器的llr交换与前向递归一起被调度的方案导致了竞争问题。更具体地,在上面提供的示例矩阵
为了解决这种竞争问题,我们独立于前向递归和后向递归来调度交织和解交织。更具体地,如上所述,图11的前向递归和后向递归是通过使用前向和后向ram控制器调度大多数ram的读取和写入操作来实施的。相反,对于存储先验llr
下面提供了用于设计交织或解交织调度的特定算法。
为了最大化aptd的吞吐量,以上算法可以相继使用更高的dl值,直到对于交织器和解交织器两者都成功。在我们的示例中,得到的交织和解交织调度
如图10中所示,交织器和解交织器调度被存储在rom中。这些rom由将l和c转换成地址ar的输出和输入rom控制器来控制,该地址ar可用于从对应rom的读取端口dr读取ram地址。每个rom包括可以使用
优点概述
如以上所解释的本技术的实施例可以提供具有以下优点的aptd:
传统turbo解码器被限制为采用数量为p的处理元件,该数量p是帧长度kl的整数倍。这确保了所有窗口具有相同的长度wl=kl/p,并且交织可以在没有竞争的情况下完成。相比之下,aptd支持任意数量p的处理元件,并采用不同长度的窗口。aptd通过独立于非本征llr的生成来调度该非本征llr的交织和解交织以避免竞争。更具体地,一些非本征llr的交织或解交织相对于它们的生成被延迟,或者被完全禁用。
当帧长度kl短于2048比特时,示例2的turbo解码器禁用其p=64个处理元件中的一些。相比之下,当帧长度kl短于2p时,aptd仅禁用每个解码器中其p个处理元件中的一些。在这种情况下,每个解码器中的kl/2个处理元件处理长度为wl,p=2的窗口,而剩余的处理元件被禁用。当kl大于2p时,窗口中的一些窗口长度为
像示例3的混洗(shuffled)turbo解码器一样,aptd对于上部解码器的每个窗口采用一个处理元件,以及对于下部解码器的每个窗口采用单独的处理元件,其中贯穿解码处理来同时处理所有窗口。然而,当混洗turbo解码器在每个窗口内执行单个前向递归和单个后向递归时,aptd将每个窗口划分为两个子窗口。aptd在对另一子窗口执行前向递归和后向递归之前,对一个子窗口执行前向递归和后向递归。这根据奇偶布置来执行,使得上部解码器的每个窗口中的第一子窗口与下部解码器的每个窗口中的第二子窗口同时处理,反之亦然。注意,在所有窗口都具有偶数长度wl,p的情况下,这种布置相当于使得两倍的窗口,并且使用每个处理元件在相同解码器内的两个相邻窗口的处理之间交替。这与使用每个处理元件在上部解码器中的特定窗口的处理和下部解码器中的对应窗口之间交替的示例1、2和4的turbo解码器形成对比。注意,aptd采用的方案的优点在于消除了对处理元件能够将非本征llr交织或解交织回自身的要求,允许采用更简单的交织器和解交织器。
在aptd的窗口具有最小长度wl,p=2的特殊情况下,上述奇偶布置变得相当于fptd的奇偶布置,并且以相同的方式受益于lte交织器的奇偶性质。在窗口长度wl,p为奇数的情况下,在前
示例1至3的已知turbo解码器在前向递归和后向递归两者的后半部分期间生成非本征llr。这种方案在递归的前半部分期间不生成非本征llr,在后半部分的每个步骤产生两个llr。因此,这种方案在后半部分要求两个交织器和两个解交织器,并且在递归的前半部分该硬件未使用。相比之下,aptd仅在前向递归期间基于已经最近生成的后向状态度量来生成非本征llr,该后向状态度量是在先前解码迭代期间执行的递归的结束期间、或者在当前递归的开始期间生成的。如图15和16所表征的,这仅允许使用单个交织器和单个解交织器,尽管这实现的代价是要求更多解码迭代以便实现相同比特错误率(ber)。
与示例1至3的turbo解码器相反,aptd可以在递归的完成后重复该递归的开始。这提供了第二次机会来生成相关联的非本征llr,允许禁用这些重新生成的llr中的一个或其他的交织或解交织,而不完全消除这些llr的交织或解交织。当窗口长度wl,p短时,这也允许生成更近的后向状态度量向量,准备用于在下一次迭代中生成非本征llr。
像示例4的fptd一样,aptd采用流水线来增加最大时钟频率,但代价是要求更多的解码迭代来实现相同ber。虽然通过fptd的上部解码器和下部解码器中的一个的流水线有三个级,但aptd将其减少到两个级,从而提高ber。这是通过对每个子处理元件在输入处执行状态度量的归一化和限幅来实现的,而不是像在fptd那样在输出处执行状态度量的归一化和限幅。
说明性结果
图15提供了当采用总共2p=128个处理元件以及最大值8、16、24、32、40、48、56和64个时钟循环来解码具有长度kl=512的帧时、所提出的aptd“提出的”的误码率(ber)性能的曲线图。注意,流水线在这些结果中被禁用,并且当它被启用时,可以预期有轻微的ber下降。这些结果与示例1的turbo解码器的对应版本“基准(仅前向)”进行比较,其仅在前向递归上计算非本征llr,如在所提出的方案中那样。它采用硬件复杂度与提出的处理元件中的每一个类似的8个并行处理器,以及最大值246、466、686、909、1126、1346、1566和1786个时钟循环来解码具有相同长度kl=512的帧。还提供了示例1的turbo解码器的第二版本“基准(前向和后向)”的结果,其在前向递归和后向递归两者上计算非本征llr,代价是硬件复杂度比提出的处理元件中的每一个高42%。该方案采用8个并行处理器以及最大值246、466、686、909、1126、1346、1566和1786个时钟循环来解码具有相同长度kl=512的帧。
图16提供了当采用总共2p=128个处理元件以及最大值96、192、288、384、480、576、672和768个时钟循环来解码具有长度kl=6144的帧时,所提出的aptd“提出的”的误码率(ber)性能的曲线图。注意,流水线在这些结果中被禁用,并且当它被启用时,可以预期有轻微的ber下降。这些结果与示例1的turbo解码器的相应版本“基准(仅前向)”进行比较,其仅在前向递归上计算非本征llr,如在所提出的方案中那样。它采用硬件复杂度与提出的处理元件中的每一个类似的8个并行处理器,以及最大值1654、3282、4910、6538、8166、9794、11422、13050个时钟循环来解码具有相同长度kl=6144的帧。还提供了示例1的turbo解码器的第二版本“基准(前向和后向)”的结果,其在前向递归和后向递归上计算非本征llr,代价是硬件复杂度比提出的处理元件中的每一个高42%。该方案使用8个并行处理器以及最大值1654、3282、4910、6538、8166、9794、11422、13050个时钟循环来解码具有相同长度kl=6144的帧。
以下段落提供了本技术的进一步的方面和特征:
一种turbo解码器电路,用于执行turbo解码处理以从接收到的信号中恢复数据符号的帧,该数据符号的帧包括该帧的每个数据符号的一个或多个奇偶校验和/或系统软判决值。该帧的数据符号已经用turbo编码器编码,该turbo编码器包括每个能够由网格表示的上部卷积编码器和下部卷积编码器、以及在上部卷积编码器和下部卷积编码器之间交织数据符号的交织器。turbo解码器电路包括时钟、被配置为交织软判决值的可配置网络电路、以及上部解码器和下部解码器。上部解码器包括与上部卷积编码器相关联的多个上部处理元件,上部解码器的处理元件中的每一个处理元件被配置为,在一系列连续时钟循环期间,从可配置网络电路迭代地接收与数据符号有关的先验软判决值,其中该先验软判决值与表示上部卷积编码器的状态之间的可能路径的整数个连续网格级的窗口相关联,以使用该先验软判决值执行与该窗口相关联的并行计算,以便通过执行turbo解码的前向递归和后向递归生成与数据符号有关的对应非本征软判决值,以及被配置为向可配置网络电路提供非本征软判决值,上部解码器的至少一个处理元件被配置为相对上部解码器的至少一个其他处理元件执行与不同数量的网格级相关联的窗口的计算。下部解码器包括与下部卷积编码器相关联的多个下部处理元件,下部解码器的处理元件中的每一个处理元件被配置为,在一系列连续时钟循环期间,从可配置网络电路迭代地接收与数据符号有关的先验软判决值,其中该先验软判决值与表示下部卷积编码器的状态之间的可能路径的整数个连续网格级的窗口相关联,以使用该先验软判决值执行与该窗口相关联的并行计算,以便通过执行turbo解码的前向递归和后向递归生成与数据符号有关的对应非本征软判决值,以及被配置为向可配置网络电路提供非本征软判决值,下部解码器的至少一个处理元件被配置为相对下部解码器的至少一个其他处理元件执行与不同数量的网格级相关联的窗口的计算。可配置网络电路包括网络控制器电路,该网络控制器电路在连续时钟循环期间迭代地控制可配置网络电路的配置,以通过交织由下部解码器提供的非本征软判决值来为上部解码器提供先验软判决值,并且通过交织由上部解码器提供的非本征软判决值来为下部解码器提供先验软判决值,由网络控制器控制的可配置网络电路执行的交织是根据预定调度的,这在一个或多个连续时钟循环的不同循环提供先验软判决值,以避免在相同时钟循环期间向上部或下部解码器的相同处理元件提供不同先验软判决值之间的竞争。
一种turbo解码器电路,用于执行turbo解码处理以从接收到的信号中恢复数据符号的帧,该数据符号的帧包括该帧的每个数据符号的软判决值。该帧的数据符号已经用turbo编码器编码,该turbo编码器包括每个能够由网格表示的上部卷积编码器和下部卷积编码器、以及在上部卷积编码器和下部卷积编码器之间交织数据符号的交织器。turbo解码器电路包括时钟、被配置为交织软判决值的可配置网络电路、以及上部解码器和下部解码器。上部解码器包括与上部卷积编码器相关联的多个上部处理元件,上部解码器的处理元件中的每一个处理元件被配置为在一系列连续时钟循环期间,从可配置网络电路迭代地接收与数据符号有关的先验软判决值,以执行并行计算来生成与数据符号有关的对应非本征软判决值,并向可配置网络电路提供非本征软判决值,其中该先验软判决值与表示上部卷积编码器的状态之间的可能路径的整数个连续网格级的窗口相关联。下部解码器包括与下部卷积编码器相关联的多个下部处理元件,下部解码器的处理元件中的每一个处理元件被配置为在一系列连续时钟循环期间,从可配置网络电路迭代地接收与数据符号有关的先验软判决值,以执行并行计算来生成与数据符号有关的对应非本征软判决值,并向可配置网络电路提供非本征软判决值,其中该先验软判决值与表示下部卷积编码器的状态之间的可能路径的整数个连续网格级的窗口相关联。可配置网络电路根据预定调度进行配置,以在上部和下部解码器之间提供一个或多个连续时钟循环的不同循环的先验软判决值,以避免不同先验软判决值之间的竞争。
根据以上段落中所述的实施例,由处理元件根据前向递归和后向递归而执行的计算包括:接收与相邻网格级有关的前向或后向状态度量,将前向或后向状态度量与数据符号的先验、奇偶校验和系统软判决值进行组合,并生成与另一相邻网格级有关的前向或后向状态度量,其中所接收的前向或后向状态度量在与先验、奇偶校验和系统软判决值组合之前被归一化。
以下编号的段落提供了示例实施例的进一步示例方面和特征:
第1段、一种turbo解码器电路,用于执行turbo解码处理以从接收到的信号中恢复数据符号的帧,该数据符号的帧包括该帧的每个数据符号的一个或多个奇偶校验和/或系统软判决值,该帧的数据符号已经用turbo编码器编码,该turbo编码器包括每个能够由网格表示的上部卷积编码器和下部卷积编码器、以及在上部卷积编码器和下部卷积编码器之间交织该数据符号的交织器,该turbo解码器电路包括:
时钟,
可配置网络电路,被配置为交织软判决值,
上部解码器,包括与上部卷积编码器相关联的多个上部处理元件,上部解码器的处理元件中的每一个处理元件被配置为,在一系列连续时钟循环期间,从可配置网络电路迭代地接收与数据符号有关的先验软判决值,其中该先验软判决值与表示上部卷积编码器的状态之间的可能路径的整数个连续网格级的窗口相关联,以使用先验软判决值执行与该窗口相关联的并行计算以便生成与数据符号有关的对应非本征软判决值,以及被配置为向可配置网络电路提供非本征软判决值,上部解码器的至少一个处理元件被配置为相对上部解码器的至少一个其他处理元件执行与不同数量的网格级相关联的窗口的计算,以及
下部解码器,包括与下部卷积编码器相关联的多个下部处理元件,下部解码器的处理元件中的每一个处理元件被配置为,在该系列连续时钟循环期间,从可配置网络电路迭代地接收与数据符号有关的先验软判决值,其中该先验软判决值与表示下部卷积编码器的状态之间的可能路径的整数个连续网格级的窗口相关联,以使用先验软判决值执行与该窗口相关联的并行计算以便生成与数据符号有关的对应非本征软判决值,以及被配置为向可配置网络电路提供非本征软判决值,下部解码器的至少一个处理元件被配置为相对下部解码器的至少一个其他处理元件执行与不同数量的网格级相关联的窗口的计算,
其中可配置网络电路包括网络控制器电路,网络控制器电路在该连续时钟循环期间迭代地控制可配置网络电路的配置,以通过交织由下部解码器提供的非本征软判决值来为上部解码器提供先验软判决值,以及通过交织由上部解码器提供的非本征软判决值来为下部解码器提供先验软判决值,由网络控制器控制的可配置网络电路执行的交织是根据预定调度的,这在一个或多个连续时钟循环的不同循环提供先验软判决值,以避免在相同时钟循环期间向上部或下部解码器的相同处理元件提供不同先验软判决值之间的竞争。
第2段、根据段落1所述的turbo解码器电路,其中上部解码器和下部解码器中的每一个的处理元件被配置为从存储器读取先验软判决值,并且在执行计算之后将非本征软判决值写入存储器,并且可配置网络电路被配置为从存储器读取非本征软判决值,并且将先验软判决值写入存储器,并且可配置网络根据预定调度对一个或多个非本征软判决值的读取相对于处理元件对一个或多个非本征软判决值的写入延迟了一个或多个时钟循环。
第3段、根据段落1或2所述的turbo解码器电路,其中,上部解码器和下部解码器中的每一个的处理元件被配置为从存储器读取先验软判决值,以及在执行计算之后将非本征软判决值写入存储器,并且可配置网络电路被配置为从存储器读取非本征软判决值,以及将先验软判决值写入存储器,以及由可配置网络根据预定调度对非本征软判决值中的一个或多个非本征软判决值的读取或者由处理元件对一个或多个非本征软判决值的写入中的至少一个被跳过。
第4段、根据段落1、2或3中任一段所述的turbo解码器电路,其中,上部解码器或下部解码器中的处理元件的数量不是网格级的数量的整数倍。
第5段、根据段落1至4中任一段所述的turbo解码器,其中,由处理元件处理的每个窗口内网格级的最小和最大数量之间的差在上部和下部解码器中的任一个中是一。
第6段、根据段落1至5中任一段所述的turbo解码器电路,其中,窗口中的每个窗口包括由彼此相邻的处理元件处理的相同数量的网格级。
第7段、根据段落1至6中任一项所述的turbo解码器电路,其中,上部和下部解码器包括相同数量的处理元件,并且上部解码器的每个处理元件如下部解码器的对应处理元件一样对包括对应网格级的窗口执行计算。
第8段、根据段落1至7中任一段所述的turbo解码器,其中,处理元件和交织的处理调度根据相同数量的时钟循环是周期性的,每次迭代表示相同调度的周期。
第9段、根据段落8所述的turbo解码器,其中,周期由上部或下部解码器中的任一个窗口中的最大网格级加上减少用于根据预定调度跳过以避免竞争的需求而所需的非负整数来给出。
第10段、根据段落1至9中任一段所述的turbo解码器电路,其中,处理元件中的每一个处理元件被配置为根据周期性调度执行并行计算,并且每个周期包括第一子周期和第二子周期,第一子周期包括周期中的一个或多个第一时钟循环,第二子周期包括周期中的剩余循环,其中,在第一子周期期间,每个窗口的处理包括在包括窗口中的前一个或多个网格级的第一子窗口、或者包括窗口中的后一个或多个网格级的第二子窗口内的前向递归和后向递归后向递归,且在第二子周期期间,处理元件中的每一个处理元件被配置为在包括窗口中的剩余网格级的第一和第二子窗口中的另一个内执行前向递归和后向递归。
第11段、根据段落10所述的turbo解码器电路,其中,第一和第二子周期中的一个包括在周期中的时钟循环的半向下舍入(halfroundingdown),第一和第二子周期中的另一个包括在周期中的时钟循环的剩余半向上舍入,并且在包括时钟循环的半向下舍入的第一子周期和第二子周期中的一个子周期期间,每个处理元件对包括窗口中的网格级的半向下舍入的第一或第二子窗口执行并行计算,并且在包括时钟循环的半向上舍入的第一子周期和第二子周期的另一个子周期期间,处理元件对包括窗口中的网格级的半向上舍入的第一或第二子窗口执行计算。
第12段、根据段落11所述的turbo解码器电路,其中,处理元件被配置为在与子窗口内的完全前向递归和子窗口内的完全后向递归相关联的子周期内对子窗口执行计算,并且在执行完全前向递归和完全后向递归之后,任何剩余的时钟循环被处理元件用来执行与后续前向递归和后续后向递归的至少一部分相关联的计算。
第13段、根据段落12所述的turbo解码器电路,其中,在第一子周期期间,上部解码器的处理元件被配置为执行与第一或第二子窗口中的相同的一个相关联的计算,并且下部解码器的处理元件被配置为执行与第一或第二子窗口中的另一个相关联的计算,并且
在第二子周期期间,上部解码器的处理元件被配置为执行与在第一子周期期间未被处理元件处理的第一或第二子窗口相关联的计算,并且下部解码器的处理元件被配置为执行与在第一子周期期间未被处理元件处理的第一或第二子窗口中的另一个相关联的计算。
第14段、根据段落10至13中任一段所述的turbo解码器电路,其中,前向递归根据执行与前向方向上的每个连续网格级相关联的计算的调度来生成与多个网格状态相对应的多个前向状态度量,并且后向递归根据执行与后向方向上的每个连续网格级相关联的计算的调度来生成与多个网格状态相对应的多个后向状态度量,并且前向递归根据用于前向递归的调度将前向状态度量存储在存储器中,或者后向递归根据用于后向递归的调度将后向状态度量存储在存储器中,并且前向递归或后向递归中的另一个从存储器加载存储的前向或后向状态度量,并组合前向和后向状态度量以根据用于前向或后向递归的调度来计算非本征软判决值。
第15段、根据段落10至14中任一段所述的turbo解码器电路,其中,由处理元件根据前向递归和后向递归而执行的计算包括:接收与相邻网格级有关的前向或后向状态度量,将前向或后向状态度量与数据符号的先验、奇偶校验和系统软判决值进行组合,以及生成与另一相邻网格级有关的前向或后向状态度量,其中所接收的前向或后向状态度量在与先验、奇偶校验和系统软判决值组合之前被归一化。
第16段、根据段落15所述的turbo解码器电路,其中,处理元件被配置为根据两步流水线来生成非本征软判决值,该两步流水线包括第一步,该第一步将前向和后向状态度量彼此组合并与奇偶校验软判决值组合以形成中间变量,以及第二步,该第二步将中间变量彼此组合、缩放中间变量的组合并将缩放的中间变量的组合与系统软判决值组合,并且流水线的两步在两个连续的时钟循环期间被执行,并且由流水线的步骤施加的延迟被包容在由可配置网络的预定调度施加的延迟中以避免竞争。
第17段、根据段落1至16中任一段所述的turbo解码器电路,其中,帧中的数据符号的数量是可变的,并且由上部和下部解码器执行的计算的每个窗口的网格级的数量是相对于帧长度和上部和下部解码器的处理元件的数量来确定的。
第18段、一种从接收到的信号中恢复数据符号的帧的turbo解码方法,该数据符号的帧包括该帧的每个数据符号的一个或多个奇偶校验和/或系统软判决值,该帧的数据符号已经用turbo编码器编码,该turbo编码器包括每个能够由网格表示的上部卷积编码器和下部卷积编码器、以及交织已经在上部卷积编码器和下部卷积编码器之间交织的编码数据的交织器,该方法包括:
使用包括与上部卷积编码器相关联的多个上部处理元件的上部解码器,通过如下步骤来执行前向和后向迭代递归处理:
在一系列连续时钟循环期间,在上部解码器的处理元件中的每一个处理元件处从可配置网络电路迭代地接收与数据符号有关的先验软判决值,其中该先验软判决值与表示上部卷积编码器的状态之间的可能路径的整数个连续网格级的窗口相关联,
由处理单元中的每一个处理元件使用先验软判决值执行与该窗口相关联的并行计算,以便生成与数据符号有关的对应非本征软判决值,上部解码器的至少一个处理元件相对上部解码器的至少一个其他处理元件执行与不同数量的网格级相关联的窗口的计算,
向可配置网络电路提供非本征软判决值,以及
使用包括与下部卷积编码器相关联的多个下部处理元件的下部解码器,通过如下步骤来执行前向和后向迭代递归处理:
在该系列连续时钟循环期间,在下部解码器的处理元件中的每一个处理元件处从可配置网络电路迭代地接收与数据符号有关的先验软判决值,其中该先验软判决值与表示下部卷积编码器的状态之间的可能路径的整数个连续网格级的窗口相关联,
由处理单元中的每一个处理元件使用先验软判决值执行与该窗口相关联的并行计算,以便生成与数据符号有关的对应非本征软判决值,下部解码器的至少一个处理元件相对下部解码器的至少一个其他处理元件执行与不同数量的网格级相关联的窗口的计算,
向可配置网络电路提供非本征软判决值,
在连续时钟循环期间,迭代地控制可配置网络电路的配置,以通过交织由下部解码器提供的非本征软判决值来为上部解码器提供先验软判决值,并且通过交织由上部解码器提供的非本征软判决值来为下部解码器提供先验软判决值,由网络控制器控制的可配置网络电路执行的交织是根据预定调度的,这在一个或多个连续时钟循环的不同循环提供先验软判决值,以避免在相同时钟循环期间向上部或下部解码器的相同处理元件提供不同先验软判决值之间的竞争。
第19段、一种接收器,用于检测和恢复已经用turbo码编码的数据符号的帧,该接收器包括:
检测电路,用于检测携带该数据符号的帧的接收到的信号,每个数据符号的帧包括帧的每个数据符号的一个或多个奇偶校验和/或系统软判决值,每个帧的数据符号已经用turbo编码器编码,该turbo编码器包括每个能够由网格表示的上部卷积编码器和下部卷积编码器,以及交织已经在上部卷积编码器和下部卷积编码器之间交织的编码数据的交织器,以及
turbo解码器电路,用于执行turbo解码处理以从接收到的信号中恢复数据符号的帧中的每一个,该turbo解码器电路包括:
时钟,
可配置网络电路,被配置为交织软判决值,
上部解码器,包括与上部卷积编码器相关联的多个上部处理元件,上部解码器的处理元件中的每一个处理元件被配置为,在一系列连续时钟循环期间,从可配置网络电路迭代地接收与数据符号有关的先验软判决值,其中该先验软判决值与表示上部卷积编码器的状态之间的可能路径的整数个连续网格级的窗口相关联,以使用先验软判决值执行与该窗口相关联的并行计算以便生成与数据符号有关的对应非本征软判决值,以及被配置为向可配置网络电路提供非本征软判决值,上部解码器的至少一个处理元件被配置为相对上部解码器的至少一个其他处理元件执行与不同数量的网格级相关联的窗口的计算,以及
下部解码器,包括与下部卷积编码器相关联的多个下部处理元件,下部解码器的处理元件中的每一个处理元件被配置为,在系列连续时钟循环期间,从可配置网络电路迭代地接收与数据符号有关的先验软判决值,其中该先验软判决值与表示下部卷积编码器的状态之间的可能路径的整数个连续网格级的窗口相关联,以使用先验软判决值执行与该窗口相关联的并行计算以便生成与数据符号有关的对应非本征软判决值,以及被配置为向可配置网络电路提供非本征软判决值,下部解码器的至少一个处理元件被配置为相对下部解码器的至少一个其他处理元件执行与不同数量的网格级相关联的窗口的计算,
其中可配置网络电路包括网络控制器电路,网络控制器电路在连续时钟循环期间迭代地控制可配置网络电路的配置,以通过交织由下部解码器提供的非本征软判决值来为上部解码器提供先验软判决值,以及通过交织由上部解码器提供的非本征软判决值来为下部解码器提供先验软判决值,由网络控制器控制的可配置网络电路执行的交织是根据预定调度的,这在一个或多个连续时钟循环的不同循环提供先验软判决值,以避免在相同时钟循环期间向上部或下部解码器的相同处理元件提供不同先验软判决值之间的竞争。
第20段、根据段落19所述的接收器,其中,每个帧中的数据符号的数量从一个到另一个动态地变化。
第21段、一种形成无线通信网络的无线电接入网络的一部分的基础设施装备,该基础设施装备包括根据段落19所述的接收器。
第22段、一种用于利用无线通信网络发送或接收数据的通信设备,该通信设备包括根据段落19所述的接收器。
引用文献
[1]etsits36.212v10.8.0(2013-06)lte;evolveduniversalterrestrialradioaccess(e-utra);multiplexingandchannelcoding,v10.2.0ed.,2011.
[2]ieee802.16-2012standardforlocalandmetropolitanareanetworks-part16:airinterfaceforbroadbandwirelessaccesssystems,2012.
[3]c.berrou,a.glavieux,andp.thitimajshima,“nearshannonlimiterror-correctingcodinganddecoding:turbo-codes(1),”inproc.ieeeint.conf.oncommunications,vol.2,geneva,switzerland,may1993,pp.1064–1070.
[4]p.robertson,e.villebrun,andp.hoeher,“acomparisonofoptimalandsub-optimalmapdecodingalgorithmsoperatinginthelogdomain,”inproc.ieeeint.conf.oncommunications,vol.2,seattle,wa,usa,june1995,pp.1009–1013.
[5]ieee802.11n-2009standardforinformationtechnology-telecom-municationsandinformationexchangebetweensystems-localandmetropolitanareanetworks-specificrequirements-part11:wirelesslanmediumaccesscontrol(mac)andphysicallayer(phy),2009.
[6]d.j.c.mackayandr.m.neal,“nearshannonlimitperformanceoflowdensityparitycheckcodes,”electron.lett.,vol.32,no.18,pp.457–458,aug.1996.
[7]m.fossorier,“reducedcomplexitydecodingoflow-densityparitycheckcodesbasedonbeliefpropagation,”ieeetrans.commun.,vol.47,no.5,pp.673–680,may1999.
[8]5gradioaccess.ericssonwhitepaper,june2013.
[9]v.a.chandrasettyands.m.aziz,“fpgaimplementationofaldpcdecoderusingareducedcomplexitymessagepassingalgorithm,”journalofnetworks,vol.6,no.1,pp.36–45,jan.2011.
[10]t.ilnseher,f.kienle,c.weis,andn.wehn,“a2.15gbit/sturbocodedecoderforlteadvancedbasestationapplications,”inproc.int.symp.onturbocodesanditerativeinformationprocessing,gothenburg,sweden,aug.2012,pp.21–25.
[11]l.fanucci,p.ciao,andg.colavolpe,“vlsidesignofafully-parallelhigh-throughputdecoderforturbogallagercodes,”ieicetrans.fundamentals,vol.e89-a,no.7,pp.1976–1986,july2006.
[12]d.vogrig,a.gerosa,a.neviani,a.graelliamat,g.montorsi,ands.benedetto,“a0.35-μmcmosanalogturbodecoderforthe40-bitrate1/3umtschannelcode,”ieeej.solid-statecircuits,vol.40,no.3,pp.753–762,2005.
[13]q.t.dong,m.arzel,c.j.jego,andw.j.gross,“stochasticdecodingofturbocodes.”ieeetrans.signalprocessing,vol.58,no.12,pp.6421–6425,dec.2010.
[14]a.nimbalker,y.blankenship,b.classon,andt.k.blankenship,“arpandqppinterleaversforlteturbocoding,”inproc.ieeewirelesscommun.networkingconf.,lasvegas,nv,usa,mar.2008,pp.1032–1037.
[15]l.li,r.g.maunder,b.m.al-hashimi,andl.hanzo,“alow-complexityturbodecoderarchitectureforenergy-efficientwirelesssensornetworks,”ieeetrans.vlsisyst.,vol.21,no.1,pp.14–22,jan.2013.[online].available:http://eprints.soton.ac.uk/271820/
[16]p.radosavljevic,a.debaynast,andj.r.cavallaro,“optimizedmessagepassingschedulesforldpcdecoding,”inasilomarconf.signalssystemsandcomputers,no.1,pacificgrove,ca,usa,oct.2005,pp.591–595.
[17]cn102611464
[18]cn102723958
[19]wo2011/082509
[20]“a122mb/sturbodecoderusingamid-rangegpu”byxianjunj.,etal,publishedatwirelesscommunicationsandmobilecomputingconference(iwcmc),20139thinternational,pages1090-1094,1-5july2013.
[21]“turboipcoreuserguide”,ug-turbo,2015.11.11altera.
[22]l.f.gonzalez-perez,l.c.yllescas-calderon,andr.parra-michel,“parallelandconfigurableturbodecoderimplementationfor3gpp-lte,”in2013int.conf.reconfigurablecomput.fpgas,pp.1–6,ieee,dec2013.
[23]yufeiwu,b.d.woernerandt.k.blankenship,"datawidthrequirementsinsisodecodingwithmodulenormalization,"inieeetransactionsoncommunications,vol.49,no.11,pp.1861-1868,nov2001.
[24]j.zhangandm.p.c.fossorier,“shufflediterativedecoding,”ieeetrans.commun.,vol.53,no.2,pp.209–213,feb.2005.
[25]c.chang,“arbitrarysizebenesnetworks”,parallelprocessingletters,vol.7,no.3,sept1997.
[26]pct/ep2015/067527
- 还没有人留言评论。精彩留言会获得点赞!