一种基于多核融合的大数据滤波方法与流程
本发明涉及核自适应滤波领域,具体涉及一种基于多核融合的大数据滤波方法。
背景技术:
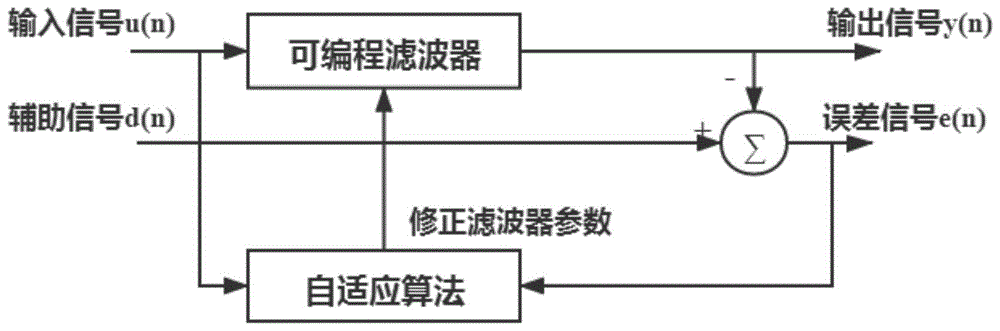
自适应滤波器可以根据所处环境中的统计变异自动地调整自由参数。其动作原理是通过估计输入信号的统计特性,调整其本身的响应,使得某一代价函数达到最小值,通常可用图1所示的辅助信号源来确定。辅助信号输入d(n)可以定义为滤波器的期望输出,在这种情形下,自适应算法的任务是调整滤波器的权值系数,使得滤波器的输出y(n)与期望输出d(n)之间的差值e(n)达到最小。由于线性系统计算能力的局限性,现实世界复杂的应用中通常采用非线性关系进行描述。核方法是将线性系统扩展到非线性应用领域的有力工具,由于其具备优良的性能而被越来越多地应用于非线性自适应滤波器的设计上。
互相关熵的理论可以推导一个崭新的度量函数(cim),近几年其在核自适应滤波领域获得越来越多的关注。传统的自适应滤波算法在高斯环境中能够获取非常有效的性能效果,但是在非高斯环境中算法性能会严重衰减。因为mse是度量变量全局相似度的方法,当输入数据混入非高斯噪声如脉冲噪声时,基于mse的学习方法的误差会变得非常大,此时滤波器权值会往性能劣化的方向大幅调整,性能严重衰减。引入最大互相关熵能够从代价函数上调整最优化的目标,由最小化均方误差改变为最大化互相关熵,使得系统具备抑制非高斯噪声的能力,表现出更强的鲁棒性。而且最大互相关熵与自适应滤波结合的数学推导清晰简单,模型结构易于理解,计算复杂度适中。
然而现有的基于最大互相关熵准则的核自适应滤波算法大多立足于单一模型进行参数估计,倘若面对更加复杂的数据集时,单一模型则很难达到最优的学习效果。除此之外,虽然大量文献资料已经基于不同的角度对核自适应滤波算法进行了改良,但基于信息论的多核自适应滤波算法的研究仍然较少,此类算法具有优良的鲁棒性,在噪声复杂的现实环境中拥有诸多应用场景。
singh.a.等人在文献《aclosedformrecursivesolutionformaximumcorrentropytraining》中提出以递归的方式求解以最大互相关熵为代价函数的自适应滤波,得出类似于rls算法的鲁棒算法,并通过系统辨识仿真实验验证了该算法相对于rls的抗脉冲噪声能力。该算法为后续基于互相关熵的核自适应滤波算法的研究提供了基础,但其基于单核模型,收敛精度仍有待提高。
陈霸东等人在文献《mixturecorrentropyforrobustlearning》中提出了基于最大混合熵准则的自适应滤波(krmmcc)算法,其目标函数中包含两个核函数,可以通过调整两个核函数的参数提高滤波器的学习性能。这种方法增加了模型中核参数的数量,提高了模型的可调性,但该文中使用的核自适应滤波模型仍为单一模型,在噪声更加多样化的复杂非高斯环境中效果不佳。
钱国兵等人提出了《mixturecomplexcorrentropyforadaptivefilter》,文章在krmmcc算法的结果上进行扩展,将混合复数熵应用于复数域的自适应滤波研究中,通过添加两个自由参数获得了优良的学习性能。然而该算法仍然是在单一模型中使用混合核函数,而非采用多个模型进行融合。当环境噪声的复杂程度提高时,该算法的性能表现出局限性。
师黎明和林云提出了《convexcombinationofadaptivefiltersunderthemaximumcorrentropycriterioninimpulsiveinterference》,文中引入最大互相关熵,通过构建两个自适应滤波器的凸组合而提出新的鲁棒算法。该算法不仅仅解决了学习非高斯噪声混杂的模型问题,同时利用凸组合克服普通单个自适应滤波器收敛速度与稳态精度之间的权衡取舍问题,并在植物识别场景仿真中验证了该算法的优越性能。该算法的提出证实了组合模型的优势,能够在复杂的噪声环境中表现更加优异的性能。
技术实现要素:
针对现有技术中的上述不足,本发明提供一种多模型自适应融合方法,采用基于互相关熵的核自适应滤波算法作为基本的滤波算法。根据指定的融合策略将训练好的单核模型进行融合,再将独立的单核模型通过学习的系数进行融合。该方法提升了模型的准确性,当面对噪声复杂的非高斯环境,多核模型通过学习融合系数进行融合,共同完成估计任务,具备较强的鲁棒性。
为了实现上述目的,本发明采用了如下的技术方案:
一种基于多核融合的大数据滤波方法,步骤如下:
第一步:对于各滤波器初始化,单独设置各个核自适应滤波器的参数,包括核宽度σ、正则化因子γ、初始融合系数α。
第二步:对各滤波器按照单核自适应滤波算法进行参数的数据更新,计算出第i时刻的权重系数ai。
第三步:训练滤波器权重系数的同时更新融合系数,第m个滤波器的融合系数即当权重系数计算为有效情况下的核宽度的后验概率,融合系数必须符合阈值的限定。
第四步:按照学习所得的融合系数进行多个独立核自适应滤波的加权融合,得到最终的多核模型。当待预测的输入数据到来时,通过已融合的多核模型进行预测。
其中,第二步的单核自适应算法的权值更新过程如下:
步骤1:第i时刻输入训练数据对{ui,di},设定变量hm,i用于滤波器预测值的计算,hm,i计算公式为
步骤2:根据第m个滤波器在上一时刻的权重系数am,i-1,计算估计输出值
步骤3:计算第m个滤波器中在第i时刻估计值与期望值的误差em,i=di-ym,i,其中di是第i个输出信号的期望值;ym,i是第m个滤波器在第i时刻输出估计值。
步骤4:计算中间值:
其中rm,i,θm,i,zm,i均是第m个滤波器在第i时刻产生的中间变量;qm,i-1是第m个滤波器在第i-1时刻的中间变量,用于计算滤波器系数;hm,i是第m个滤波器在第i时刻的中间变量,用于计算滤波器输出值的;
步骤5:中间值迭代更新:
其中rm,i,zm,i均是第m个滤波器在第i时刻产生的中间变量;qm,i-1是第m个滤波器在第i-1时刻产生的中间变量;(·)-1表示逆运算;(·)t表示矩阵的转置运算。
步骤6:滤波器系数迭代更新:
其中zm,i,rm,i均是第m个滤波器在第i时刻产生的中间变量;em,i是第m个滤波器在第i时刻输出期望值与输出估计值的误差;am,i-1是第m个滤波器在第i-1时刻的滤波器系数;(·)-1表示逆运算。
其中,第三步的根据指定融合策略更新融合系数过程如下:
步骤1:计算第i时刻各个独立滤波器的估计值:
其中
步骤2:更新多个独立滤波器的融合系数:
其中αm,i为第m个滤波器在第i时刻的权重系数;p(·)为后验概率;di+1是i+1时刻输出信号的期望值;
步骤3:判断独立单核滤波器的融合系数是否符合阈值范围,当大于阈值则取预先设定的上限,若小于阈值则取预先设定的下限。
其中,第四步的将多个独立滤波器进行融合过程如下:
步骤1:最后,当给定未知输出的输入信号ut,可通过多核自适应滤波器进行估计。
本发明的有益效果为:本发明在非高斯噪声环境中,单一核自适应滤波模型无法保证估计精度的情况下,通过采用多模型自适应融合的办法,使得多个模型通过自适应学习确定融合系数,得到较为准确的结果。
本发明在噪声复杂的非高斯环境中,表现出优异的估计性能,能够根据输入信号准确估计输出信号,且算法具有较好的收敛速度。
第二步采用krmc算法对多个独立的核自适应滤波器进行训练,保证了预测模型的多样性。
第三步根据指定的融合策略完成系数的迭代更新,使用似然函数进行递归计算。该融合策略合理应用了训练阶段滤波器的估计结果,完成了融合参数的自主学习更新。
第四步利用学习到的融合系数将多个模型进行融合,并利用最终的多核模型进行参数估计,保证了滤波器良好的鲁棒性,得到更加可靠精确的结果。
附图说明
图1为自适应滤波器示意图。
图2为多个滤波器模型融合示意图。
图3为基于多核融合的大数据滤波方法的流程图。
图4为高斯混合噪声下四种算法的学习曲线对比图。
图5为二项分布噪声下四种算法的学习曲线对比图。
图6为拉普拉斯噪声下四种算法的学习曲线对比图。
具体实施方式
下面通过实施例,并配合附图,对本发明的技术方案作进一步的说明。
参见图2和图3,一种基于多核融合的大数据滤波方法,步骤如下:
第一步:对于各滤波器初始化,单独设置各个核自适应滤波器的参数,包括核宽度σ、正则化因子γ、初始融合系数α。
第二步:对各滤波器按照单核自适应滤波算法进行参数的数据更新,计算出第i时刻的权重系数ai。
第三步:训练滤波器权重系数的同时更新融合系数,第m个滤波器的融合系数即当权重系数计算为有效情况下的核宽度的后验概率,融合系数必须符合阈值的限定。
第四步:按照学习所得的融合系数进行多个独立核自适应滤波的加权融合,得到最终的多核模型。当待预测的输入数据到来时,通过已融合的多核模型进行预测。
其中,第二步的单核自适应算法的权值更新过程如下:
步骤1:第i时刻输入训练数据对{ui,di},设定变量hm,i用于滤波器预测值的计算,hm,i计算公式为
步骤2:根据第m个滤波器在上一时刻的权重系数am,i-1,计算估计输出值
步骤3:计算第m个滤波器中在第i时刻估计值与期望值的误差em,i=di-ym,i,其中di是第i个输出信号的期望值;ym,i是第m个滤波器在第i时刻输出估计值。
步骤4:计算中间值:
其中qm,i-1是第m个滤波器在第i-1时刻的中间变量,用于计算滤波器系数;hm,i是第m个滤波器在第i时刻的中间变量,用于计算滤波器输出值的;
步骤5:中间值迭代更新:
其中rm,i,θm,i,zm,i均是第m个滤波器在第i时刻产生的中间变量;qm,i-1是第m个滤波器在第i-1时刻产生的中间变量;σm是第m个滤波器的高斯核带宽;(·)-1表示逆运算;(·)t表示矩阵的转置运算。
步骤6:滤波器系数迭代更新:
其中zm,i,rm,i均是第m个滤波器在第i时刻产生的中间变量;em,i是第m个滤波器在第i时刻输出期望值与输出估计值的误差;am,i-1是第m个滤波器在第i-1时刻的滤波器系数;(·)-1表示逆运算。
其中,第三步的根据指定融合策略更新融合系数过程如下:
步骤1:计算第i时刻各个独立滤波器的估计值:
其中
步骤2:更新多个独立滤波器的融合系数:
其中αm,i为第m个滤波器在第i时刻的权重系数;p(·)为后验概率;di+1是i+1时刻输出信号的期望值;
步骤3:判断独立单核滤波器的融合系数是否符合阈值范围,当大于阈值则取预先设定的上限,若小于阈值则取预先设定的下限。
其中,第四步的将多个独立滤波器进行融合过程如下:
步骤1:最后,当给定未知输出的输入信号ut,可通过多核自适应滤波器进行估计。
结合具体的实验,对本发明提供的基于多核融合的大数据滤波方法的效果进行说明:在三种不同的噪声分布下,将本发明的算法与其它多种算法的仿真结果展开比较,通过下述非线性问题对本次发明的性能进行验证。非线性方程描述如下:
di=10·sinc(ui)+ωi
其中,ui是取值于区间[-5,5]的均匀分布的随机序列,ωi是加性噪声,其分布包括如下四种形式:(1)高斯混合噪声,噪声值以0.8的概率取方差为0.09的零均值高斯分布,以0.2的概率取方差为0.36的零均值高斯分布;(2)分布服从x~b(500,0.8)的二项分布噪声;(3)分布服从x~l(0,0.09)的拉普拉斯噪声。四种噪声的输入-输出数据对为
在本发明的模拟中分别使用3个独立的核自适应滤波器模型,再将3个独立的学习滤波器进行融合。在仿真中,当某一融合系数过小时,会导致迭代更新的提前终止,为了防止这种情况的发生,本次模拟设置了融合系数的上下限阈值,分别为0.1和0.9。这一设置不仅确保迭代更新的持续进行,而且不影响所提出算法的性能。
本次模拟中,选择500个有噪声的样本作为训练数据,并选择100个无噪声的样本作为测试数据。其余参数设置为γ=0.008,α1,1=0.2,α2,1=0.3,α3,1=0.5,2个独立的基于krmc内核模型的核宽度分别设置为
本发明仿真的目的是通过不同的算法训练核自适应滤波器,从而测试对比不同算法的性能。为了更真实地反映算法的泛化能力,仿真选择了测试结果作为实验结果,评价指标为100轮次蒙特卡洛实验运行所得的均方误差(mse)结果。四种不同分布噪声下的蒙特卡洛实验所得的mse结果如图4-6所示。
本发明的实验结果表明,具有不同核宽度的单核自适应滤波器的性能是不同的,通常而言,很难为核自适应滤波器选择合适的核宽度。而多核自适应滤波器模型的性能优于单核自适应滤波器,其原因在于单核自适应滤波器并不能学习到所有输入输出数据对的特征。而基于模型融合的多核模型性能优于单一的多核模型,其原因在于本发明所提出的基于模型融合的多核自适应滤波算法使用三个独立的学习滤波器,并且对多个不同的非线性函数估计进行融合。
以上所述仅为本发明的优选实施例而已,并不用于限制本发明,对于本领域的技术人员来说,本发明可以有各种更改和变化。凡在本发明的精神和原则之内,所作的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!