融合的存储器和算术电路的制作方法
融合的存储器和算术电路
1.优先权申请
2.本技术是2019年5月20日提交的美国专利申请第16/417,152号的延续,并且要求该美国专利申请的优先权,该美国专利申请的内容通过引用整体并入本文。
背景技术:
3.现场可编程门阵列(fpga)包括与可重配置布线网络互连的可编程逻辑块的阵列。逻辑块在类型上不同,并且通常包括可重配置逻辑、存储器以及算术逻辑。可重配置逻辑通常使用查找表来实现。
4.可重配置布线网络可以被编程为以许多可能的配置之一将逻辑块连接在一起。这种可编程性是有代价的。针对给定区域,与算术逻辑块相比,布线网络通常密度较小并且支持较少的数据。因此,算术逻辑块的实际大小/宽度被布线网络所提供的可用输入和输出的数量限制。尽管可以通过级联较小的算术逻辑块来实现较大的算术运算,但是这种方法引入了不必要的延迟,并且显著降低了应用的总逻辑密度。
附图说明
5.在附图的图中通过示例而非限制的方式示出了所公开的技术的一些实施方式。
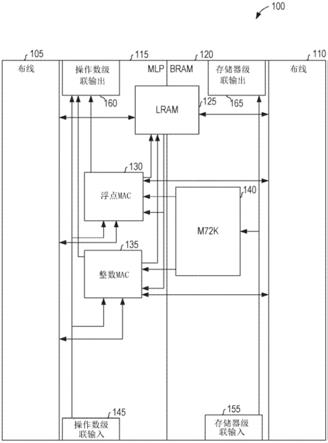
6.图1是根据一些示例实施方式的融合了存储器和算术电路的fpga的重复单元(tile)的高级别示意图。
7.图2是根据一些示例实施方式的融合了存储器和算术电路的fpga重复单元的算术电路部分的高级别示意图。
8.图3是根据一些示例实施方式的融合了存储器和算术电路的fpga重复单元的存储器电路部分的高级别示意图。
9.图4是根据一些示例实施方式的在fpga重复单元中用于与存储器融合的算术电路的部分的示意图。
10.图5是根据一些示例实施方式的在fpga重复单元中用于与存储器融合的算术电路的部分的示意图。
11.图6是根据一些示例实施方式的在fpga重复单元中用于与存储器融合的算术电路的部分的示意图。
12.图7是根据一些示例实施方式的在fpga重复单元中用于与存储器融合的算术电路的部分的示意图。
13.图8是根据一些示例实施方式的在fpga重复单元中用于与存储器融合的算术电路的部分的示意图。
14.图9是根据一些示例实施方式的在fpga重复单元中用于与算术电路融合的存储器电路的示意图。
15.图10是根据本发明的各种实施方式的、示出了融合的存储器和算术电路所执行的方法的操作的流程图。
16.图11是根据一些示例实施方式的示出了系统的部件的框图,该系统用于控制本文所描述的电路的制造。
具体实施方式
17.现在将描述用于融合的存储器和算术电路的示例方法、系统和电路。在以下描述中,阐述了具有示例特定细节的多个示例以提供对示例实施方式的理解。然而,对于本领域的普通技术人员来说明显的是,可以在没有这些示例特定细节的情况下和/或在具有与此处给出的细节不同的组合的情况下实践这些示例。因此,给出具体实施方式是出于简化说明的目的而非限制。
18.fpga的重复单元融合了存储器和算术电路。重复单元的多个实例之间的直接连接也是可用的,从而允许将多个重复单元视为更大的存储器或算术电路。通过使用被称为级联输入和输出(cascade inputs and outputs)的这些连接,算术电路的输入和输出带宽进一步增加。
19.重复单元与交换结构(switch fabric)之间的连接总数是不变的,并且在存储器电路与算术电路之间进行分配。算术单元访问来自以下组合的输入:交换结构、存储器电路、重复单元的第二存储器电路以及级联输入。在一些示例实施方式中,重复单元上的连接的布线(routing)是基于制造后(post-fabrication)配置。在一个配置中,所有连接都由存储器电路使用,从而在写入或读取存储器时允许更高的带宽。在另一配置中,所有连接都由算术电路使用。
20.通过在fpga的单个重复单元上融合存储器和算术电路,与数据经由fpga的交换结构从存储器电路传输至算术电路的现有技术实现方式相比,从存储器到算术电路的数据传输的带宽增加了。
21.图1是fpga的重复单元100连同所连接的布线105和布线110的高级别示意图。重复单元100融合了存储器和算术电路,并且包括机器学习处理器(mlp)115、块随机存取存储器(bram)120以及逻辑随机存取存储器(lram)125。mlp 115包括浮点乘法累加(mac)130和整数mac 135。bram 120包括存储器140。重复单元100经由布线105和布线110连接至其他重复单元。另外地,重复单元100经由操作数级联输入(operand cascade input)145和存储器级联输入155直接连接至第一fpga重复单元,而不使用fpga的布线连接。重复单元100还经由操作数级联输出160和存储器级联输出165直接连接至第二fpga重复单元,而不使用fpga的布线。级联连接可以是单向的或双向的。
22.在第一操作模式下,mac 130和135从布线105、lram 125、存储器140和操作数级联输入145中的一个或更多个接收输入。由mac 130和135将输出提供给布线105、操作数级联输出160、lram 125或其任何合适的组合。存储器140从布线110、存储器级联输入155或两者接收输入。由存储器140将输出提供给布线110、存储器级联输出165或两者。在第一操作模式下,mac 130和135不从布线110接收输入,并且存储器140不从布线105接收输入。因此,来自fpga的布线结构的输入在mlp 115与bram 120之间进行分配,并且mlp 115在重复单元100内访问来自bram 120的数据,而不经过交换结构。
23.典型的mac将两个乘积相乘并且将结果添加至累加器。在一些示例实施方式中,mac 130和135通过允许将部分乘积相加并且在添加至累加器之前将其作为输出提供,来提
供附加功能。因此,单独部分乘积、针对当前乘法的部分乘积之和、以及跨多个乘法循环的累加结果都可以通过使用mac 130和135来访问。
24.在第二操作模式下,mac 130和135从布线105、布线110、lram 125和操作数级联输入145中的一个或更多个接收输入。由mac 130和135将输出提供给布线105、布线110、操作数级联输出160、lram 125或其任何合适的组合。在第二操作模式下,存储器140不从布线105或布线110接收输入。因此,在第二操作模式下,重复单元100作为专用mlp操作,其中mlp 115具有对fpga的布线结构的完全访问,存储器140被有效地禁用。尽管如此,lram 125可以在第二操作模式下使用一些布线连接。
25.在第三操作模式下,存储器140从布线105、布线110、存储器级联输入155或其任何合适的组合接收输入。由存储器140将输出提供给布线105、布线110、存储器级联输出165或其任何合适的组合。在第三操作模式下,mlp 115不从布线105或布线110接收输入。因此,在第三操作模式下,重复单元100作为专用bram操作,其中bram 120具有对fpga的布线结构的完全访问,mlp 115被有效地禁用。
26.如图1所示,lram 125连接至布线105和布线110。在一些示例实施方式中,在所有操作模式下都保持针对lram 125的布线连接。为了将存储在lram 125中的数据用于mlp 115所进行的计算,控制信号识别要读取的地址并且使用在lram 125中该地址处的数据。经由重复单元内连接将数据从lram 125提供给mlp 115,而不使用布线105或布线110。
27.在lram 125和存储器140与浮点mac 130和整数mac 135之间示出的重复单元内连接操作在比布线105和110更高的带宽。在各种示例实施方式中,重复单元内数据访问速度是比布线连接访问速度快至少10倍、50倍、100倍或500倍的因素。
28.lram 125与bram 120之间的差异通常是实现细节,使得bram 120类似于高速缓存式存储器(通常使用sram单元),并且lram 125类似于寄存器文件(通常使用触发器)。然而,这些并不是具体的规则,并且其他类型的存储器可以用于lram 125和bram 120。在一些示例实施方式中,bram 120具有比lram 125更大的存储容量并且针对面积进行了优化,lram 125针对延迟进行了优化。在另外的示例实施方式中,lram 125存储用于矩阵乘法的部分乘积之和的工作集(working set)。
29.图2是根据一些示例实施方式的融合了存储器和算术电路的fpga重复单元的算术电路部分200的高级别示意图。在一些示例实施方式中,算术电路200是mlp 115。算术电路200从fpga重复单元的存储器部分接收重复单元内输入,从fpga的布线结构接收布线结构输入,从fpga的布线结构接收控制信号,以及从另一fpga重复单元接收操作数级联输入而不使用布线结构。在各种示例实施方式中,存在更多或更少的输入。
30.算术电路200将重复单元内输出提供给fpga重复单元的存储器部分,将布线结构输出提供给fpga的布线结构,以及将操作数级联输出提供给另一fpga重复单元而不使用布线结构。在各种示例实施方式中,存在更多或更少的输出。通常,从第一fpga重复单元接收操作数级联输入,算术电路200是第二fpga重复单元的一部分,并且操作数级联输出被提供给第三fpga重复单元。
31.图3是根据一些示例实施方式的融合了存储器和算术电路的fpga重复单元的存储器电路部分300的高级别示意图。在一些示例实施方式中,存储器电路300是bram 120。存储器电路300从fpga重复单元的算术部分接收重复单元内输入,从fpga的布线结构接收布线
结构输入,从fpga的布线结构接收控制信号,从第一fpga重复单元接收存储器级联输入,以及从第二fpga重复单元接收反向(reverse)存储器级联输入。级联输入不使用布线结构。存储器级联输入可以包括控制信号以及数据信号。在各种示例实施方式中,存在更多或更少的输入。
32.存储器电路300将重复单元内输出提供给fpga重复单元的算术部分,将布线结构输出提供给fpga的布线结构,将存储器级联输出提供给第二fpga重复单元,以及将反向存储器级联输出提供给第一fpga重复单元。在各种示例实施方式中,存在更多或更少的输出。
33.图4是根据一些示例实施方式的在fpga重复单元中用于与存储器融合的算术电路的部分400的示意图。部分400包括:复用器410a、410b、410c和410d;寄存器420a、420b、420c和420d(统称为0级延迟寄存器420);比特重映射逻辑430a、430b、430c和430d;以及1级延迟寄存器440(在图5中更详细地示出为单独的寄存器510a、510b、510c、510d、510e、510f、510g、510h、510i、510j、510k、510l、510m、510n、510o和510p)。部分400接受针对两个乘法操作数a和b的输入,将操作数重映射为由算术电路的下一部分使用的格式,并且将经重映射的操作数提供给由下一部分使用的延迟寄存器。
34.复用器410a从下述四个选项中选择用于b操作数的低位(low bits):mlp_din[71:0],经由布线结构105接收到的72位数据;regfile_dout[71:0],从重复单元100内的lram 125接收到的72位数据;bram_dout[71:0],从重复单元100内的bram 120接收到的72位数据;以及fwdi_multb_l[71:0],从操作数级联输入145接收到的72位数据。复用器410b从下述八个选项中选择用于b操作数的高位(high bits):bram_din[71:0],经由布线结构110接收到的72位数据;regfile_dout[143:72],从重复单元100内的lram 125接收到的72位数据;bram_dout[143:72],从重复单元100内的bram 120接收到的72位数据;mlp_din[71:0];regfile_dout[71:0];bram_dout[71:0];以及fwdi_multb_l[71:0]。因此,b操作数是根据来自布线结构105、布线结构110、lram 125、bram 120和操作数级联输入145中的一个或更多个的输入的组合来生成的。
[0035]
由复用器410c从下述四个选项中选择用于a操作数的低位:mlp_din[71:0];regfile_dout[71:0];bram_dout[71:0];以及fwdi_multa_l[71:0],从操作数级联输入145接收到的72位数据。由复用器410d从下述八个选项中选择用于a操作数的高位:bram_din[71:0];mlp_din[71:0];regfile_dout[143:72];regfile_dout[71:0];fwdi_multa_l[71:0];bram_dout[143:72];bram_dout[71:0];以及fwdi_multa_h[71:0],从操作数级联输入145接收到的72位数据。因此,a操作数也是根据来自布线结构105、布线结构110、lram 125、bram 120和操作数级联输入145中的一个或更多个的输入的组合来生成的。
[0036]
由复用器410a至410d选择的输入可选地存储在寄存器420a至420d中的对应寄存器中,该寄存器以下述形式将数据提供给操作数级联输出160:fwdo_multb_l[71:0],b操作数的低位;fwdo_multb_h[71:0],b操作数的高位;fwdo_multa_l[71:0],a操作数的低位;以及fwdo_multa_h[71:0],a操作数的高位。另外地,寄存器420a至420d中的每个寄存器被比特重映射逻辑430a至430d中的对应比特重映射逻辑所访问。比特重映射逻辑430a至430d中的每个比特重映射逻辑基于乘法模式和字节选择模式输入来重映射输入。指数和符号位(sign bits)作为信号《expa》、《sgna》、《expb》、《sgnb》、《expc》、《sgnc》、《expd》和《sgnd》被从比特重映射逻辑430a至430d输出。经重映射的输入被提供给1级延迟寄存器440,以由算
术电路的下一部分进行访问。
[0037]
由复用器410a至410d选择的输入被配置信号sel_multb_l、sel_multb_h、sel_multa_l和sel_multa_h控制。因此,算术电路被一个或更多个配置信号配置,以从第一连接结构、第二连接结构、第一融合存储器、第二融合存储器、操作数级联输入或其任何合适的组合接收输入。作为示例,响应于第一配置信号,算术电路被配置成对经由布线结构接收到的数据(例如mlp_din[71:0],复用器410a至410d中的每个复用器的可能选择)以及在fpga的重复单元内从第一存储器接收到的数据(例如bram_dout[143:72](复用器410b和410d的可能选择)或bram_dout[71:0](复用器410a和410c的可能选择))执行操作。作为另一示例,响应于第二配置信号,算术电路被配置成对经由布线结构接收到的数据以及在fpga的重复单元内从第二存储器接收到的数据(例如regfile_dout[143:72](复用器410b和410d的可能选择)或regfile_dout[71:0](复用器410a和410c的可能选择))执行操作。
[0038]
图5是根据一些示例实施方式的在fpga重复单元中用于与存储器融合的算术电路的部分500的示意图。部分500包括:寄存器510a、510b、510c、510d、510e、510f、510g、510h、510i、510j、510k、510l、510m、510n、510o和510p;乘法器520a、520b、520c、520d、520e、520f、520g和520h;加法器530a、530b、530c、530d、550a、550b和560;复用器540a、540b、540c、540d和570;以及2级延迟寄存器580。
[0039]
寄存器510a至510p中的每个寄存器存储针对乘法器520a至520h之一的操作数的八位数据。乘法器520a至520h中的每个乘法器接受a操作数的八位和b操作数的八位。因此,部分500总共处理a操作数的64位和b操作数的64位。为了处理由部分400接收到的完整输入,部分500被复制,其中部分500的每个实例处理一半的输入。
[0040]
在第一操作模式下,部分500被配置成确定八个8位乘法运算之和。通过根据情况用前导零(leading zeros)进行符号扩展或填充,可以在第一操作模式下确定较少的乘法运算之和或八个较小的(例如6位或4位)运算之和。在第二操作模式下,部分500被配置成确定两个16位乘法运算之和。通过根据情况用前导零进行符号扩展或填充,可以在第二操作模式下确定单个乘法运算或两个较小的(例如12位或10位)运算之和。在第三操作模式下,使用附加的移位器和更宽的加法器,部分500与部分500的第二实例相结合地被配置成确定单个32位乘法运算。通过根据情况用前导零进行符号扩展或填充,可以在第三操作模式下确定较小的(例如18位或24位)乘法运算。在另外的操作模式下,除了乘法运算之和之外或代替于乘法运算之和,可以在输出端处提供一个或更多个单独的乘法结果。
[0041]
关于第一操作模式,八个乘法器520a至520h中的每个乘法器使用操作数a和b的不同部分作为输入来执行八位乘法。八个乘法的结果由加法器530a至530d成对地进行求和。四个加法结果由加法器550a至550b成对地进行求和,使用复用器540a至540d(由modelsel信号控制)来确定是直接取加法结果还是如所示出地进行移位。移位后的结果用于支持16位乘法。加法器550a至550b的两个结果由加法器560进行求和。加法器560的结果是八个八位乘法之和,并且经由复用器(mux)570被提供给2级延迟寄存器580。
[0042]
对于第二操作模式,乘法器520a至520d与加法器530a、530b、550a相结合地确定第一个16位乘法结果。乘法器520e至520h与加法器530c、530d和550b相结合地确定第二个16位乘法结果。可以使用第一操作数大小的四个乘法器来生成第二操作数大小的乘法结果,该第二操作数大小是第一操作数大小的两倍。较大的操作数被划分成高和低两部分,并且
被组织如下:其中,ah表示a操作数的高部分;al表示a操作数的低部分;bh表示b操作数的高部分;bl表示b操作数的低部分。ah al
×
bh bl=al
×
bl+ah
×
bl《《size+bh
×
al《《size+ah
×
bh《《2
×
size。
[0043]
因此,在第二操作模式下,乘法器520d将bl与ah相乘,并且乘法器520c将bh与al相乘。该结果由加法器530b相加,并且来自加法器530b的结果被左移八位。乘法器520b将bh与ah相乘,并且结果被左移十六位。乘法器520a将bl与al相乘。在通过加法器530a和550a的结果之后,加法器550a的输出是16位乘法运算的结果。乘法器520e至520h以及加法器530c、530d、550b被类似地配置成处理第二个16位乘法运算。两个运算的结果由加法器560进行求和,并且经由复用器570被提供给2级延迟寄存器580。加法器560的输出的大小比加法器550a和550b的输出的大小大一位。因此,在运算的八位模式下,加法器560提供19位输出,并且在运算的十六位模式下,加法器560提供34位输出。
[0044]
在一些示例实施方式中,部分500在第二操作模式下仅执行单个16位乘法。在这些实施方式中,忽略由乘法器520e至520h以及加法器530c、530d、550b、560生成的结果。相反,复用器570被配置成将包含单个16位乘法结果的来自加法器550a的输出提供给2级延迟寄存器580。
[0045]
在第三操作模式下,使用附加的移位器和更宽的加法器,以类似于关于第二操作模式描述的方式对由部分500的两个实例提供的四个16位乘法运算进行组合,产生以下电路:该电路使用下面关于图6讨论的加法器630确定单个32位乘法。
[0046]
尽管部分500被描述为对所选的输入执行乘法运算,然后对乘法运算的结果求和,但是也考虑了算术电路的其他配置。例如,来自寄存器510a至510p的输入可以被提供给所示出的乘法器520a至520h,并且也可以被提供给一组加法器。针对每个乘法器/加法器对使用复用器,对加法器530a至530d的输入被选择作为乘法结果或加法结果。因此,基于控制复用器的配置信号,算术电路确定输入操作数之和或输入操作数的乘积之和(如图5所示)。
[0047]
图6是根据一些示例实施方式的在fpga重复单元中用于与存储器融合的算术电路的部分600的示意图。部分600包括:图5的复用器570;以及来自部分500的副本的对应复用器610,所述部分500的副本处理输入a和b的高半部分。复用器570和610的输出被提供给2级延迟寄存器620a和620b,每个为34位宽。对部分600的输入也是从1级延迟寄存器630a、630b、630c、630d、630e、630f、630g和630h接收的,存储由图4的比特重映射逻辑430a至430d生成的《sgna》、《sgnb》、《sgnc》、《sgnd》、《expa》、《expb》、《expc》和《expd》值。部分600还包括:加法器650;复用器640a、640b、640c、640d、640e、640f、640g、640h、660、680a和680b;乘法器670a和670b;以及3级延迟寄存器690。
[0048]
来自部分500及其副本的结果由加法器650相加。复用器660基于add0_15_bypass信号的值选择来自部分500的结果或来自两个部分的求和结果,并且将所选择的结果提供给乘法器670a和复用器680a。基于经由复用器640a至640d接收到的《expa》、《expb》、《sgna》和《sgnb》值以及从复用器660接收到的值,乘法器670a生成24位浮点乘法结果。类似地,基于经由复用器640e至640h接收到的《expc》、《expd》、《sgnc》和《sgnd》值以及从寄存器620b接收到的结果,乘法器670b生成第二个24位浮点乘法结果。基于fpmult_ab信号,复用器680a至680b输出由乘法器670a至670b生成的24位浮点结果或者传递由寄存器620b和复用器660提供的结果。复用器680a至680b的输出被提供给3级延迟寄存器690。
[0049]
因此,在一种操作模式下,部分600的复用器680a至680b的输出是部分500及其副本部分的输出,绕过了加法器650和乘法器670a至670b。在第二操作模式下,复用器680a的输出是由部分500及其副本执行的所有乘法之和,并且复用器680b的输出是由部分500的副本执行的乘法之和。在第三操作模式下,复用器680a至680b的输出是部分500及其副本部分的输出的24位浮点版本。在第四操作模式下,复用器680a的输出是由部分500及其副本执行的所有乘法之和的24位浮点表示,并且复用器680b的输出是由部分500的副本执行的乘法之和的24位浮点表示。
[0050]
图7是根据一些示例实施方式的在fpga重复单元中用于与存储器融合的算术电路的部分700的示意图。部分700包括:图6的复用器680a;1级延迟寄存器710a、710b、710c和710d;复用器720a、720b、720c、720d、740a、740b、750a、750b、770和780;3级延迟寄存器730a和730b;加法器760a和760b;4级延迟寄存器790。部分700与上块795之间的连接也在图7中示出。上块795是指图8所示的算术电路的部分。
[0051]
复用器680a的输出存储在3级延迟寄存器730a中。3级延迟寄存器730b存储图6的复用器660b的输出或者下面关于图8所描述的通过将复用器660b的输出与fwdi_dout[47:0]相加而生成的相加结果。
[0052]
复用器750a从以下中选择值:fwdi_dout[47:0];regfile_dout[47:0],来自lram 125的48位;regfile_dout[95:48],来自lram 125的不同的48位;延迟寄存器730b;以及{24’h0,fwdi_dout[47:24]},在操作数级联输入的24位之前的24个0比特。复用器750b从3级延迟寄存器730a和730b中选择值。复用器750a和750b的输出被提供给加法器760a和760b。基于从复用器740a和740b接收到的sub_ab_del和load_ab_del信号以及从复用器750a和750b接收到的所选择的值,加法器760a生成加法结果。基于从复用器740a和740b接收到的sub_ab_del和load_ab_del信号以及从复用器750a和750b接收到的所选择的值,加法器760b生成加法结果或减法结果。sub信号控制加法器760a和760b是生成加法结果还是减法结果。load信号控制加法器760a和760b是将输入值与累加值相加还是忽略累加值且仅加载输入值,提供输入值作为输出并且将累加器值设置为输入值。del信号具有0至4个周期的延迟。
[0053]
旁路复用器770选择由加法器760b生成的结果或复用器750b的结果。因此,旁路复用器770提供来自部分700的加法结果或来自图6的结果。复用器780选择复用器770的输出或加法器760a的输出,并且将结果提供给4级延迟寄存器790。
[0054]
图8是根据一些示例实施方式的在fpga重复单元中用于与存储器融合的算术电路的部分800的示意图。部分800对应于图7所示的上块795。部分800包括:图6的复用器660b;图7的复用器720c和720d;加法器840a和840b;4级延迟寄存器790;复用器830a、830b、860a、860b、860c、860d和880;逻辑块850a和850b;以及输出寄存器870。图7的部分700在图8中表示为下块890。
[0055]
复用器830a从以下中选择值:fwdi_dout[47:0];regfile_dout[71:0];regfile_dout[47:24],来自lram 125的24位,并且复用器830a选择来自输出寄存器870的经由反馈路径接收到的值。复用器830b选择来自复用器660b的值或来自4级延迟寄存器790的值。
[0056]
加法器840a对来自复用器830a和830b的输出求和,如由sub_reg和load_reg信号所修改的。sub信号控制加法器840a是生成加法结果还是减法结果。load信号控制加法器
840a是将输入值与累加值相加还是忽略累加值且仅加载输入值,提供输入值作为输出并且将累加器值设置为输入值。由于sub_reg和load_reg不是del信号,因此在处理输入时没有延迟。加法器840b根据sub_reg信号将来自复用器830a至830b的输出相加或取差。复用器860b和860c选择加法器840a至840b的输出,或者基于fpadd_cd_bypass信号提供来自复用器830b的输出。复用器860d选择来自复用器860b、860c的输出、mult8byp输入和mult16byp输入。如果使用旁路信号,则在电路被配置成8位运算时选择mult8byp信号,并且在电路被配置成16位运算时选择mult16byp信号。
[0057]
复用器860d的输出存储在输出寄存器870中。如果电路被配置成执行浮点格式转换(例如从内部24位浮点格式转换成16位输出浮点格式),则输出寄存器870中的值被逻辑块850b处理,然后被作为输入提供给复用器860a。同样地,如果电路被配置成执行浮点格式转换,则4级延迟寄存器790中的值被逻辑块850a处理。复用器860a从寄存器790和870的已处理的值和未处理的值中选择输入。复用器860a的输出被提供作为fwdo_dout[47:0],48位操作数级联输出。
[0058]
复用器880基于output_sel信号从以下中选择电路的输出值:复用器860a的输出;lram_dout[71:0],从lram 125读取的72位值;以及bram_dout[143:72]。所选择的输出值被提供作为dout[71:0],提供给布线结构105的72位输出。
[0059]
图9是根据一些示例实施方式的在fpga重复单元中用于与算术电路融合的存储器电路900的示意图。存储器电路900包括bram输入块910、bram写复用器(wmux)920、bram存储器930以及bram读复用器(rmux)940。图9提供了图3的高级别示意图的附加细节。
[0060]
bram输入块910从算术电路接收重复单元内输入,从布线结构接收布线结构输入和控制信号,从第一fpga重复单元接收存储器级联输入,以及从第二fpga重复单元接收反向存储器级联输入。基于输入和控制信号,bram输入块910将输入提供给bram wmux 920、bram存储器930以及bram rmux 940。同样基于输入和控制信号,bram输入块910将存储器级联输出提供给第一fpga重复单元而不使用布线结构,并且将反向存储器级联输出提供给第二fpga重复单元而不使用布线结构。
[0061]
由bram输入块910提供给bram wmux 920的信号包括写地址、写使能信号、数据、读地址以及读使能信号。基于wrmem_input_sel信号,bram输入块910中的一组复用器从bram输入块910的输入中选择要提供给bram wmux 920的信号。作为示例,从布线结构提供至bram输入块910的控制信号或者从级联存储器输入中选择写地址。作为另一示例,从重复单元内输入所提供的数据或者从级联存储器输入所提供的数据中选择数据。作为又一示例,从布线结构提供至bram输入块910的控制信号或者从级联存储器输入中选择写使能信号。
[0062]
由bram输入块910提供给bram存储器930的信号包括提供给bram wmux 920的写地址和读使能信号。bram输入块910将读地址提供给bram rmux 940。
[0063]
bram wmux 920将数据提供给bram存储器930。基于从bram输入块910接收到的读使能信号,bram存储器930确定是否要存储数据。如果存储了数据,则bram存储器930使用由bram输入块910提供的写地址来确定存储数据的位置。
[0064]
bram存储器930将数据提供给bram rmux 940。所提供的数据是由bram wmux 920提供的数据或者从写地址读取的数据,这取决于读使能信号的值。bram rmux 940从重复单元内输入数据和bram存储器930所提供的数据中进行选择,以生成对布线结构的输出和重
复单元内输出。
[0065]
在一些示例实施方式中,配置信号被提供给存储器电路900,其控制由存储器电路900对fpga的布线结构的访问。在上述模式下,存储器电路900能够访问融合的存储器和算术重复单元的布线连接的一部分(例如图1的布线110),但不是所有的布线连接。在第二模式下,存储器电路900能够访问融合的存储器和算术重复单元的所有布线连接(例如图1的布线105和布线110)。在第二模式下,融合的存储器和算术重复单元可以用作标准的仅存储器(memory-only)重复单元。另外地,融合的存储器和算术重复单元可以首先用作仅存储器重复单元,以快速地加载存储器,然后切换至第一模式以便与以下电路一起操作:能够访问一半布线连接的算术电路,以及具有一半布线连接的存储器电路。
[0066]
使用重复单元内通信,fpga重复单元的算术电路部分可以向/从bram存储器930读取和写入数据,同时以重复单元内通信速度操作而非以较慢的布线结构速度操作。因此,与不使用重复单元内通信的情况下的数据相比,算术电路部分处理更多的数据。在要对相同的数字执行许多计算并且中间结果并不重要时,这种将处理与参数提供进行分离特别有用。例如,在矩阵乘法中,第一操作数的一行中的每个数字乘以第二操作数的一列中的每个数字,并且将结果之和存储为结果矩阵中的元素。对第一操作数的每一行和第二操作数的每一列重复此过程,但丢弃单独的乘法结果。因此,通过使用fpga的布线结构将矩阵加载到bram存储器930中,然后在使用重复单元内通信从bram存储器930加载单独的乘法操作数的同时使用算术部分执行计算,融合的算术和存储器重复单元的吞吐量与使用单独的算术和存储器重复单元的现有技术解决方案相比显著增加。
[0067]
图10是根据本发明的各种实施方式的示出了由融合的存储器和算术电路执行的方法1000的操作的流程图。通过示例而非限制的方式,方法1000被描述为由图1至图9的电路执行。
[0068]
在操作1010中,存储器电路从fpga的第一连接结构接收第一组输入。作为示例,bram 120从fpga的布线结构110接收第一组输入。在该示例中,第一组输入包括读使能信号和地址。
[0069]
在操作1020中,存储器电路在fpga的重复单元内提供第一组输出。在该示例中,bram 120的bram rmux 940将根据在操作1010中接收到的地址从bram存储器930读取的数据提供给图9的重复单元内输出。
[0070]
在操作1030中,算术电路接收fpga重复单元内的第一组输出。在该示例中,mlp 115接收作为图4所示的bram_dout信号的数据。
[0071]
在操作1040中,算术电路从fpga的第二连接结构接收第二组输入。在该示例中,mlp 115从fpga的布线结构105接收第二组输入。这也被示出为图4的mlp_din输入信号。
[0072]
在操作1050中,算术电路基于第一组输出的第一子集和第二组输入的第二子集生成结果。如在本文中所使用的,子集可以包括集合的整体。因此,如果由存储器提供64位数据并且由布线结构提供64位数据,则算术结果可以基于输入的任何部分,只要其取决于两个输入即可。作为示例,每一个64位输入可以被视为八个8位操作数,并且所生成的结果可以是对成对的8位操作数执行的八个乘法运算之和,每对中的一个操作数经由重复单元内通信从存储器接收,并且每对中的一个操作数经由fpga的布线结构接收。
[0073]
图11是根据一些示例实施方式的示出对fpga进行编程的计算机1100的部件的框
图。在各种实施方式中不需要使用所有部件。例如,客户端、服务器、自主系统以及基于云的网络资源可以各自使用不同组的部件,或者例如在服务器的情况下,可以使用较大的存储设备。
[0074]
计算机1100(也称为计算设备1100和计算机系统1100)形式的一个示例计算设备可以包括全部通过总线1140连接的处理器1105、存储器存储设备1110、可移除存储设备1115和不可移除存储设备1120。尽管示例计算设备被示出和描述为计算机1100,但是在不同的实施方式中,计算设备可以具有不同的形式。例如,计算设备可以替代地是智能电话、平板电脑、智能手表、或者包括与关于图11示出和描述的那些元件相同或相似的元件的其它计算设备。诸如智能手机、平板电脑和智能手表的设备被统称为“移动设备”。此外,尽管各种数据存储元件被示出为计算机1100的一部分,但是存储设备还可以包括或替选地包括经由网络(例如因特网)可访问的基于云的存储设备,或基于服务器的存储设备。
[0075]
存储器存储设备1110可以包括易失性存储器1145和非易失性存储器1150并且可以存储程序1155。计算机1100可以包括或者能够访问计算环境,该计算环境包括各种计算机可读介质,例如易失性存储器1145、非易失性存储器1150、可移除存储设备1115和不可移除存储设备1120。计算机存储设备包括随机存取存储器(ram)、只读存储器(rom)、可擦除可编程只读存储器(eprom)和电可擦除可编程只读存储器(eeprom)、闪存或其他存储技术、致密盘只读存储器(cd rom)、数字多功能盘(dvd)或其他光盘存储设备、磁带盒、磁带、磁盘存储设备或其他磁存储设备、或能够存储计算机可读指令的任何其他介质。
[0076]
计算机1100可以包括或者能够访问计算环境,该计算环境包括输入接口1125、输出接口1130和通信接口1135。输出接口1130可以对接或者包括显示设备例如触摸屏,该显示设备也可以用作输入设备。输入接口1125可以对接或者包括以下中的一个或更多个:触摸屏、触摸板、鼠标、键盘、摄像装置、一个或更多个设备特定的按钮、集成在计算机1100内的或者经由有线或无线数据连接而耦接至计算机1100的一个或更多个传感器、以及其他输入设备。计算机1100可以使用通信接口1135在联网环境中操作,以连接至一个或更多个远程计算机例如数据库服务器。远程计算机可以包括个人计算机(pc)、服务器、路由器、网络pc、对等设备或其他公共网络节点等。通信接口1135可以连接至局域网(lan)、广域网(wan)、蜂窝网络、wifi网络、蓝牙网络或其他网络。
[0077]
存储在计算机可读介质上的计算机指令(例如存储在存储器存储设备1110中的程序1155)可以由计算机1100的处理器1105执行。硬盘驱动器、cd-rom和ram是包括非暂态计算机可读介质(例如存储设备)的物品的一些示例。在载波被认为过于短暂的程度上,术语“计算机可读介质”和“存储设备”不包括载波。“计算机可读非暂态介质”包括所有类型的计算机可读介质,包括磁存储介质、光存储介质、闪存介质和固态存储介质。应当理解,软件可以被安装在计算机中并且与计算机一起出售。替选地,可以获得软件并且将其加载到计算机中,包括通过物理介质或分发系统,包括例如从软件创建者所拥有的服务器或从软件创建者不拥有但使用的服务器来获得软件。例如,软件可以存储在服务器上以用于通过因特网分发。
[0078]
程序1155被示出为包括设计模块1160以及布局和布线模块1165。可以使用硬件(例如机器的处理器、asic、fpga或其任何合适的组合)来实现本文中描述的模块中的任何一个或更多个。此外,这些模块中的任何两个或更多个模块可以被组合成单个模块,并且本
文中针对单个模块描述的功能可以在多个模块之间细分。此外,根据各种示例实施方式,本文中描述为在单个机器、数据库或设备内实现的模块可以分布在多个机器、数据库或设备上。
[0079]
设计模块1160限定电路(例如处理器、信号处理器、计算引擎、状态机或控制器电路)的设计。例如,设计模块1160可以提供用户界面以允许用户设计电路。
[0080]
布局和布线模块1165基于由设计模块1160限定的电路设计来确定所得到的集成电路的物理布局。例如,包括具有融合的存储器和算术电路的一个或更多个重复单元的设计可以由布局和布线模块1165布置,以便被编程至fpga配置中。
[0081]
提供本公开内容的摘要以符合37c.f.r.
§
1.72(b),其要求使得读者能够快速确定本技术公开内容的性质的摘要。要理解的是,摘要不用于解释或限制权利要求。另外,在前述具体实施方式中,可以看出,出于使本公开内容精简的目的,各种特征在单个实施方式中被组合在一起。本公开内容的方法不应被解释为限制权利要求。因此,所附权利要求由此并入具体实施方式中,每个权利要求自身独立作为单独的实施方式。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1