基于端到端实测数据统计的路径特征刻画模拟方法及装置与流程
本发明涉及网络路径特征刻画技术领域,确切地说涉及一种基于端到端实测数据统计的路径特征刻画模拟方法及装置。
背景技术:
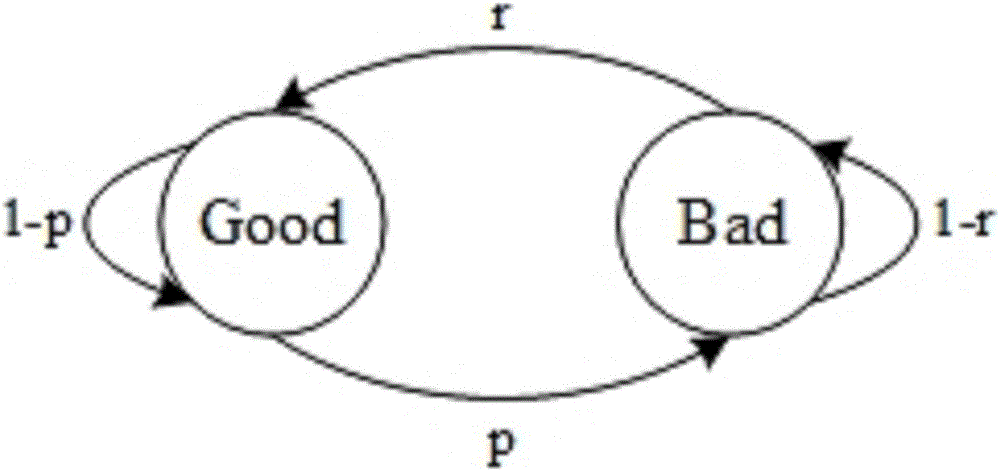
随着Internet的不断发展,网络流媒体应用日益普遍,典型应用主要包括:1)交互式网络流媒体点播;2)IPTV、网络电台等流媒体广播;3)IP电话、网络会议等即时流媒体通信应用。由于现有Internet采用“尽力分发”(BestEffortDelivery)机制,且网络结构复杂,端到端路径状态多变,会给流媒体报文的传输造成时延、丢包、抖动等影响,从而对流媒体应用的服务质量产生干扰。为帮助检验和改善流媒体应用服务对于网络的适应能力,须搭建可模拟真实网络特征的仿真模拟测试环境。发明人在实现本发明的过程中发现,现有端到端路径特征刻画与模拟方法对复杂真实网络的仿真模拟度有限。对网络流媒体应用服务而言,最严重的影响来自于报文的丢失。而报文丢失可分为两类,一类是在网络传输过程中由于多种原因造成的丢包,即流媒体报文没有传送到端到端路径的目的端;另一类则是由于时延,特别是端到端排队时延所造成的抖动、乱序等因素,使得目的端的应用程序未能在可容忍的时延范围内接收到报文,即,尽管报文最终成功传送到了目的端,但因为延迟过大等因素,已无法再使用,故而形同于丢包。故而,刻画端到端网络路径特征主要集中在丢包与时延两个方面。丢包模型方面,现有丢包模型包括Bernoulli模型、简单Gilbert模型、Gilbert模型、Gilbert-Elliott模型、4-stateMarkov模型。上述5种模型中,Bernoulli模型最基础,Gilbert-Elliott模型与4-stateMarkov模型相对复杂度较高,应用最为广泛。4-stateMarkov模型可以看作Gilbert-Elliott模型的扩展,其余三种模型均可看作Gilbert-Elliott模型的简化版本。Bernoulli模型拥有2个状态(Good和Bad)和1个参数p(参见图1-A)。Good状态表示一个报文传输成功后的状态,Bad状态表示一个报文传输失败后的状态(丢包),参数p则代表一个丢包事件发生的概率。在Bernoulli模型的基础上,简单Gilbert模型将参数扩展为二元组(p、r)(参见图1-B),p代表成功传输一个报文后下一个报文丢失的概率,r代表丢失一个报文后下一个报文继续丢失的概率。Gilbert模型在简单Gilbert模型的基础上,进一步将参数扩展为三元组(p,r,h)(参见图1-C)。Gilbert模型的Good状态依然表示一个报文传输成功后的状态,而Bad状态则描述了爆发式(burst)丢包,即连续丢包事件中存在部分报文成功传输事件的状态。参数p代表在处于Good状态的情况下下一个报文丢失的概率,r代表Bad状态中下一个报文丢失的概率,h则代表Bad状态中报文传输成功的概率。Bad状态中,丢包事件占Bad状态全部事件的比重称为丢包密度(LossDensity),当丢包密度为100%,即h=0,Bad状态全部由丢包事件构成时,Gilbert模型等同于简单Gilbert模型。基于Gilbert模型,Gilbert-Elliott模型进一步将参数扩展为四元组(p,r,h,k)(参见图1-D)。Gilbert-Elliott模型的Good状态描述了在连续成功传输报文事件中存在部分丢包事件的状态,而Bad状态则描述了爆发式(burst)丢包,即连续丢包事件中存在少部分报文成功传输事件的状态。参数p代表Good状态中下一个报文丢失的概率,k代表Good状态中报文传输成功的概率,r代表Bad状态中下一个报文丢失的概率,h代表Bad状态中报文传输成功的概率。换言之,在Good状态中,发生丢包事件的概率为(1-k),而在Bad状态中,发生丢包事件的概率为(1-h)。在Gilbert-Elliott模型的基础上,4-stateMarkov模型分别将Good和Bad状态拆分为2个独立状态,故4-stateMarkov模型拥有4个状态,同时具有参数五元组(P13、P14、P23、P31、P32.)(参见图2)。4-stateMarkov模型的4种状态定义如下:1)状态1:报文传输成功(等价于进入Good状态);2)状态2:Bad状态中报文传输成功;3)状态3:Bad状态中报文传输失败(丢包,可连续);4)状态4:Good状态中报文传输失败(丢包,非连续)。根据状态定义,Good状态中的丢包属于独立非连续丢包,故状态4到状态1的转移概率为P41=1,状态1、3、2各自到自身的转移概率则分别为P11=1-P13-P14,P22=1-P23,P33=1-P31-P32。时延模型方面,现有时延模型主要采用的方法,是在端到端单向时延参考基准上增加指定范围内的上下抖动,如LinuxTC-NetEM工具采用的时延模型,使用以下指令:#tcqdiscchangedeveth0rootnetemdelay100ms75msdelay表示端到端单向时延参考基准值(均值),jitter表示在单向时延参考基准上增加的抖动(标准偏差)。在上述指令中,100ms(microsecond,毫秒)为时延均值,75ms为标准偏差。满足该时延均值及标准偏差的随机数可设定为服从uniform分布(平均分布)、normal分布(正态分布)、pareto分布(帕雷托分布)和pareto-normal(帕雷托-正态分布)分布,通常未指定分布的情况下默认服从uniform分布。另外,针对时延模型,由于真实网络中通常采用的互联网授时协议(NTP,NetworkTimeProtocol)精度有限,特别是在复杂网络环境中,由于端到端的双向不对称路由或者网络拥塞等原因,使得路径两端节点间可能产生100ms(毫秒)及以上的误差,从而导致端到端单向时延难以准确测量,也为端到端路径时延刻画模拟带来极大挑战。事实上,端到端路径时延主要由4类时延构成,分别是传输时延(TransmissionDelay)、传播时延(Propagation)、节点处理时延(NodalProcessingDelay)和排队时延(QueuingDelay)。传输时延仅与报文大小及传输速率有关;传播时延仅与链路类型及链路长度有关;节点处理时延是指路由器等网络节点判断执行报文转发所需时间;排队时延则是指当转发节点或链路繁忙时,报文必须排队等待处理或发送的过程所消耗的时间。显然,对指定端到端路径而言,传送某一报文的传输时延、传播时延都是定值,而节点处理时延相对于排队时延较为稳定,通常也视为定值,或纳入排队时延。故,端到端路径时延可视为由端到端基本实验与端到端排队时延构成。端到端排队时延则更直接的反应了网络对于流媒体应用的时延影响,且能在节点时钟不同步的情况下进行测量(如授权公告号为CN100499526C,授权公告日为2009年6月10日的中国专利文献公开了一种端到端排队时延测量方法,由探测发送端发送一串探测分组对,并在探测接收端测量探测每个分组对内两个探测分组之间的时间间隔,得到这些时间间隔的分布,然后通过排队时延概率密度函数重构算法,得到端到端排队时延的概率密度函数),可以避免端到端时延模拟无可靠实测数据参考的问题。采用上述LinuxTC-NetEM时延模型亦可模拟排队时延,即假设端到端基本时延为0,于是设置delay为排队时延均值,jitter为排队时延标准差。但是该模拟具有一明显缺陷,即可能产生无实际意义的负值,而排队时延不会为负,因此负值需要剔除。对于上述现有技术,通过基于端到端实测数据进行参数训练及模拟比较可以发现,采用上述现有技术生成的仿真模拟数据与真实网络实测数据之间的统计特性存在明显差异,模拟准确度有限(参见图9-图11)。对丢包模型而言,上述现有技术由于有限状态机的状态数量有限,难以准确模拟丢包模式复杂多变的真实网络。而对时延模型而言,上述现有技术所能应用的随机数分布有限,且每次只能应用单一分布,同样难以准确模拟流量拥塞复杂多变的真实网络。
技术实现要素:
本发明旨在针对上述现有技术所存在的缺陷和不足,提供一种基于端到端实测数据统计的路径特征刻画模拟方法,用以刻画端到端路径丢包及时延这两类与流媒体应用密切相关的基本路径特征,可以解决现有技术方案在进行端到端路径特征模拟应用时,缺乏实测数据支撑且模拟实测数据准确度不足的技术难题。同时,本发明还提供了实现上述方法的装置。本发明是通过采用下述技术方案实现的:一种基于端到端实测数据统计的路径特征刻画与模拟方法,其特征在于包括以下步骤:1)采集真实网络端到端路径实测基础数据;2)根据所获得的实测基础数据,执行预处理,获取端到端路径实测特征数据;3)根据所获得的实测特征数据,计算特征数据累积百分比,实施累积百分比曲线分段拟合建模,在每个分段区间根据不同目标函数进行拟合,所生成的累积分布函数(CumulativeDistributionFunction,CDF)所组成的集合即构成实测特征数据在该分段区间的刻画模型集;4)根据步骤3)所获得的实测特征数据在各分段拟合区间的刻画模型集,实施分段仿真模拟与选优,最终形成端到端路径特征最优刻画模型并验证。所述步骤2)进一步包括:2-1)处理基础数据,获取“连续丢包”和“连续丢包间隔”(均以报文数量为单位计量)作为端到端路径丢包特征数据;2-2)处理基础数据,获取“排队时延”作为端到端路径时延特征数据。所述步骤3)进一步包括:3-1)基于步骤2),分别计算“连续丢包”、“连续丢包间隔”及“排队时延”三类特征数据的累积百分比,形成特征数据累积百分比曲线;3-2)分别配置所述三类特征数据在执行累积百分比曲线拟合时所需的分段拟合策略;3-3)根据步骤3-2)配置的分段拟合策略,分别将上述三类特征数据的累积百分比曲线划分为多个拟合区间,在每个区间根据预设目标函数集中的每个目标函数逐一进行拟合建模,所得累积分布函数所组成的集合即构成特征数据在各分段拟合区间的刻画模型集。所述步骤4)进一步包括:4-1)根据步骤3)所构建的分段拟合区间刻画模型集,分别对上述三类特征数据累积百分比曲线的任一分段进行仿真模拟并记录;4-2)根据步骤4-1)获得的模拟数据,针对分段拟合区间刻画模型集中的每个累积分布函数,逐一比较对应模拟数据与实测特征数据的累积百分比曲线匹配程度,选择与实测特征数据最为相符的累积分布函数作为刻画该分段拟合区间的最优模型;在各分段区间选择最优模型即可构成端到端路径特征的最优刻画模型;4-3)根据步骤4-2)获得的上述三类特征数据最优刻画模型,执行仿真模拟并比较模拟数据与实测特征数据的累积百分比曲线匹配程度,验证模型的有效性。所述步骤1)中,所述实测基础数据是指基于真实网络环境测试而获取的原始数据,包括报文收发时间和报文序列编号。所述步骤2-1)中,所述“连续丢包”是指测试报文在传输过程中发生1个及以上的持续丢包;所述“连续丢包间隔”是指在任意两个相邻的“连续丢包”过程之间,报文持续成功发送而未有任何丢失。所述步骤2-2)中,所述排队时延是指端到端路径时延中,报文在路径上因排队处理因素所造成动态变化的时延部分。所述步骤3-2)中,所述分段拟合策略是指,根据特征数据累积百分比曲线特点而预设的拟合区间的具体划分,以及为每个拟合区间预设的拟合目标函数集。所述步骤4-1)中,所述仿真模拟是指,利用刻画模型集中的累积分布函数,通过反变换法求得符合累积分布函数的随机数。一种基于端到端实测数据统计的路径特征刻画模拟装置,其特征在于包括:A)基础数据获取模块,用于采集真实网络端到端路径实测基础数据;B)特征数据获取模块,用于对基础数据进行预处理,分析提取不同类型的特征数据;C)路径特征刻画模块,用于计算特征数据的累积百分比,并根据累积百分比曲线具体特点实施分段拟合,在各分段拟合区间建立由拟合所得累积分布函数构成的刻画模型集;D)模拟选优验证模块,用于根据分段拟合区间刻画模型集,实施路径特征模拟选优与验证。与现有技术相比,本发明所达到的有益效果如下:一、本发明中,采用步骤1)至步骤4)形成的基于端到端实测数据统计的路径特征刻画与模拟方法,其用以刻画端到端路径丢包及时延这两类与流媒体应用密切相关的基本路径特征,可以解决现有技术方案在进行端到端路径特征模拟应用时,缺乏实测数据支撑且模拟实测数据准确度不足的技术难题。二、与现有技术相比,本发明选用的端到端路径特征数据方便根据实测数据统计计算,并且采用本发明技术方案刻画模拟得到的模拟数据与实测数据的统计特性更为匹配,具有很高的一致性。通过端到端实测数据进行验证的实验结果表明,相比现有技术,本发明所提出的技术方案可更加准确地模拟真实网络端到端路径的丢包与时延特征。实测实验数据通过在PlanetLab平台进行收集。端到端测试节点分别为pl2.6test.edu.cn和planetlab3.cs.uoregon.edu。通过持续传输测试,记录成功传输报文的相关信息为1个样本,共收集样本42,648,616个,构成实测基础数据样本集。丢包特征方面,采用Gilbert-Elliott模型以及4-stateMarkov模型与本发明技术方案进行比较。时延特征方面,以LinuxTC-NetEm时延模型(随机数分布采用与实策数据统计特性最为接近的paredo-normal分布模型)与本发明技术方案进行比较。基于实测数据样本集,分别按上述现有技术方案及本发明技术方案进行刻画模拟,通过模拟数据与实测数据的累积分布统计特性(累计百分比曲线)比较,本发明所述方法明显具有更好的模拟准确度,与实测数据具有很高的一致性(参见图9-图11)。附图说明下面将结合说明书附图和具体实施方式对本发明作进一步的详细说明,其中:图1-A为Bernoulli模型示意图;图1-B为简单Gilbert模型示意图;图1-C为Gilbert模型示意图;图1-D为Gilbert-Elliott模型示意图;图2为4-stateMarkov模型示意图;图3为实施例1所述路径特征刻画模拟方法示意图;图4为实施例2所述路径特征刻画模拟装置示意图;图5为特征数据“连续丢包”累积百分比示意图;图6为特征数据“连续丢包”各区间刻画模型集示意图;图7为特征数据“连续丢包”各区间刻画模型选优对比示意图;图8为端到端路径特征“连续丢包”刻画模型示意图;图9为端到端路径丢包特征“连续丢包”刻画模拟比较示意图;图10为端到端路径丢包特征“连续丢包间隔”刻画模拟比较示意图;图11为端到端路径时延特征“排队时延”刻画模拟比较示意图。具体实施方式实施例1图3为本发明一种基于端到端实测数据统计的路径特征刻画模拟方法的实施例,包括:101.采集存储真实网络端到端路径实测基础数据,包括报文收发时间和报文序列编号等。102.对采集的实测基础数据进行预处理,获取实测特征数据。即,根据报文序列号统计丢包特征“连续丢包”“连续丢包间隔”;根据报文收发时间计算时延特征“排队时延”。103.分别计算特征数据“连续丢包”“连续丢包间隔”及“排队时延”的累积百分比及其曲线点集。104.分别配置以上3类特征数据累积百分比曲线的分段拟合策略。即,将指定特征数据的累积百分比曲线在(0,1)范围划分为n个区间,分别指定每个区间的拟合目标函数集,记为Fi(i=0,1,...,n)。105.针对以上3类特征数据,分别执行累积百分比曲线分段拟合建模。即,在累积百分比曲线的划分区间i,根据配置策略指定的拟合目标函数集Fi,逐一进行拟合建模,拟合所得累积分布函数组成特征数据在区间i的刻画模型集Ci。106.针对以上3类特征数据,分别执行累积百分比曲线分段模拟选优。即,在累积百分比曲线的划分区间i,根据刻画模型集Ci中的每个累积分布函数,通过反变化法逐一执行仿真模拟,比较模拟数据与实测特征数据的累积百分比曲线的匹配程度,选择最优累积分布函数作为特征数据在区间i的最优刻画模型。107.针对以上3类特征数据,分别选择各分段拟合区间最优刻画模型,组成端到端路径特征最优模型并执行仿真模拟,通过比较模拟数据与实测特征数据的累积百分比曲线的匹配程度,验证模型的有效性。下面再以丢包特征数据“连续丢包”为例,基于“有益效果部分第二点”中采用的实测数据,进一步具体说明端到端路径特征刻画模拟过程。根据上述实测数据,根据测试报文序列号统计端到端路径丢包特征数据“连续丢包”,所得累积百分比曲线示意图参见图5。综合考虑计算效率和刻画准确度,将“连续丢包”累积百分比曲线在(0,1)区间按照步长5个0.2划分为(0,0.2]、(0.2,0.4]、(0.4,0.6]、(0.6,0.8]、(0.8,1)分段拟合区间。根据“连续丢包”累积百分比曲线特点,在前4个区间,即(0,0.2]、(0.2,0.4]、(0.4,0.6]、(0.6,0.8]、(0.8,1.0),优选幂律函数f(x)=a*x^b和指数函数f(x)=a*exp(b*x)作为各区间的拟合目标函数,构成每个区间的目标函数集。而在最后一段(0.8,1.0)则优选指数函数f(x)=1-a*exp(b*x)作为目标函数。根据上述配置执行分段拟合后,各区间所得CDF集即特征数据在该区间的刻画模型集,参见图6。基于所得刻画模型集,通过反变换进行仿真模拟。随后根据误差平方和(SumofSquaresDuetoError,SSE)指标,比较每个区间内采用不同CDF生成的模拟数据与实测特征数据的累积百分比曲线的匹配程度(参见图7)。根据SSE指标定义,SSE值越趋于0,匹配程度越高。显然,根据表2,在前4个区间,即(0,0.2]、(0.2,0.4]、(0.4,0.6]、(0.6,0.8],均应选择幂律函数作为“连续丢包”在上述区间的最优刻画模型。各区间最优模型则组合构成端到端路径“连续丢包”的刻画模型,参见图8。根据最终获取的端到端路径“连续丢包”刻画模型,通过反变换进行仿真模拟,模拟数据与实测特征数据的比较参见图9。实施例2图4为本发明一种基于端到端实测数据统计的路径特征刻画模拟装置的结构示意图,包括以下模块:201.基础数据获取模块,用于采集真实网络端到端路径实测基础数据,包括报文收发时间、报文序列编号等。202.特征数据获取模块,用于对所获基础数据进行预处理,分析提取不同的特征数据。203.路径特征刻画模块,用于根据所获特征数据计算特征数据累积百分比,并根据累积百分比曲线的具体特点实施分段拟合,建立各分段拟合区间的刻画模型集。204.模拟选优验证模块,用于根据所获特征数据累积百分比曲线分段拟合区间的刻画模型集,实施路径特征模拟选优与验证。优选的,202模块包含单元212、222:212.丢包特征数据获取单元,用于获取端到端路径丢包特征数据,即“连续丢包”及“连续丢包间隔”。222.时延特征数据获取单元,用于获取端到端路径时延特征数据,即“排队时延”。优选的,203模块包含单元213、223、233:213.累积百分比统计单元,用于计算指定特征数据的累积百分比,创建对应的累积百分比曲线点集。223.拟合策略配置单元,用于配置特征数据累积百分比曲线的分段拟合策略,包括拟合区间的具体划分以及为每个拟合区间的可选拟合目标函数等。233.拟合建模执行单元,用于根据拟合策略配置要求,执行特征函数累积百分比曲线的分段拟合建模。优选的,204模块包含单元214、224、234、244:214.模拟单元,根据已建立的分段拟合区间刻画模型集中的每个CDF,采用反变化法进行仿真模拟,生成特征模拟数据并记录。224.选优单元,根据“模拟单元”生成的模拟数据,比较同一区间根据不同CDF生成的模拟数据与实测特征数据的累积百分比曲线的匹配程度,选择最相符的CDF作为当前区间的最优刻画模型,并最终由各分段拟合区间的最优模型组合构成当前路径特征的最优刻画模型。234.验证单元,用于根据径特征最优刻画模型,采用反变化法执行仿真模拟,并计算模拟数据与实测特征数据的累积分布函数曲线的匹配程度,验证路径特征刻画模型的有效性。244.存储单元,用于保存通过有效性验证的路径特征刻画模型以及路径描述等相关信息,建立路径特征刻画模拟数据库,以供后续模拟应用使用。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1