一种大数据环境下的DDoS攻击检测方法与流程
本发明涉及网络技术领域,具体涉及一种大数据环境下的DDoS攻击检测方法。
背景技术:
随着互联网的高速发展,普通用户带宽的普遍升级,家庭用户的带宽已经达到或超过20M。此外,随着3G网络的普及,以及4G网络的逐步推广,移动互联网也进入了一个的蓬勃发展的时期。个人网络带宽的快速增长和不断增加的网络用户,使网络数据呈现爆炸式的趋势增长,人类已进入大数据时代。在大数据环境下,越来越多的公司和企业通过迁移其信息技术基础设施到云服务供应商来降低成本,例如分布式存储的数据中心和各种类型的云计算系统等。但是,这些高带宽的网络用户一旦被黑客控制并参与到数据中心或云计算系统的DDoS攻击(分布式拒绝服务攻击)时,其影响将无法估量。
DDoS攻击发动时,成百上千的傀儡机向攻击目标发出流量巨大的数据包,攻击者为了隐蔽自己的位置,会为攻击数据包随机生成伪造的源IP地址,或者采用更高级的反射DDoS攻击。此时,服务器端监测到的请求源IP地址数量剧增,分布越发分散;而服务器端提供服务的某些端口则涌入数量庞大的请求流量,此时,服务器端监测到的请求目的IP地址、目的端口分布越发集中。信息熵能反映出系统的不确定性程度,还能有效刻画通信中消息的总信息量,通过某种方式计算网络请求的信息熵,可用于对大规模网络流量DDoS攻击进行预警。
根据Spark实时流处理技术原理对DDoS攻击检测算法进行并行化,再融合Spark实时流处理技术,对到达数据中心或云计算等大数据系统的数据流进行并行的实时分析和处理,可大大提高DDoS攻击检测的速度和检测精度。
目前,已有的DDoS攻击检测算法和系统,采用单机处理方法,耗时巨大,不能满足高带宽、海量用户群的大数据环境的实际需求。在大数据环境下,对超大流量DDoS攻击的高效、及时检测并报警研究未见文献报导,其研究成果有重要的理论意义和重大的经济价值。
技术实现要素:
本发明的目的是提供一种大数据环境下的DDoS攻击检测方法,保障了大数据环境的DDoS攻击检测实时性和可靠性。
为了实现以上目的,本发明是通过以下技术方案实现的:
一种大数据环境下的DDoS攻击检测方法,其特点是,该方法包含如下步骤:
S1,大数据环境下采集各种流数据;
S2,从采集的各种流数据提取源IP地址;
S3,计算源IP地址的信息熵;
S4,判定源IP地址的信息熵是否大于预设的门限值V,如果是,则转步骤S8;若否,则判定该IP地址对应的数据流是正常的数据流,转步骤S5;
S5,用正常的数据流进行K-Means聚类;
S6,动态采样的K-Means模型训练和算法设计;
S7,动态采样的K-Means算法并行化处理;
S8,用并行化处理的动态采样的K-Means算法进行DDoS攻击检测;
S9,计算准则函数E小于等于预设门限值d,如果是,则判定该数据流为正常数据流,转向步骤S1;否则,判定该数据流为异常数据流,转向步骤S10;
S10,DDoS攻击处理。
所述的步骤S3中,信息熵的定义:
X表示信息源符号,它有n种取值:X1…Xi…Xn,分别对应的概率为:P1…Pi…Pn,因为每一种信源符号的出现相互独立,所以,有:
所述的步骤S3具体包括:
S3.1统计△t时间内所有请求中,有n种不同的源IP,每种源IP数记为Xi(i=1,2…n),每一Xi出现的次数为Ni(i=1,2…n);
S3.2分别计算Xi出现的概率Pi
S3.3计算△t内信息熵H(X)
S3.4计算前n-1个△t的信息熵的均值A
S3.5求出阈值V,k为放大系数
V=(Max[H(X)]-A)×k (5)
S3.6计算△t的信息熵值和均值的差值S
S=H(X)-A (6)
S3.7如果(S>V)表示熵值变化巨大,发攻击预警;如果(S≤V)表示熵值在正常变化范围内,数据流正常。
所述的步骤S5具体包含:
S5.1,数据集D为初始样本,其中每个点为n维:dj=(x1,x2,x3…xn),从数据集合D中随机选择k个对象作为初始簇中心,聚类中心集合记为K;
S5.2,计算数据集D中每个点到k个聚类中心的距离,根据最小值,将点分配给对应的类别,聚类中心对应的数据集合记为Ck,采用公式(7)欧氏距离来进行计算;
S5.3,更新簇的聚类中心
S5.4,计算准则函数
S5.5,满足准则函数阈值则退出,否则返回步骤S5.2。
所述的步骤S6中,对动态采样的K-Means算法的定义如下:
定义1:规模函数W(X)定义如式(10)所示,其中D2(X,C)表示X中的点到所处聚类中心的距离平方和;
定义2:动态采样概率函数P(X)定义如式(11)所示;
定义3:初始规模为W,初始采样个数m(m<K)。
所述的动态采样的K-Means算法实现如下:
A)从集合X中随机取1个点加入集合C;
B)根据式(10)计算集合C的初始限定规模函数值,记为W;
C)循环logW=N次开始,按式(11)计算动态采样概率P(X),记为P,从集合X中按概率P取出m个点加入集合C′,求C∪C′,记为C,循环结束;
D)采用K-Means算法求出集合C的聚类中心。
所述的步骤S7为:
根据大数据处理平台Spark运行的原理对设计动态采样的K-Means算法进行并行化,使改进的K-Means算法能在多个虚拟机中同时进行DDoS攻击检测。
所述的DDoS攻击检测为用动态采样的K-Means算法并行化检测已预警的数据流。
所述的已预警的数据流的DDoS攻击检测就是按(9)式计算已预警的数据流的准则函数值E,即通过聚类看已预警的数据流是否被包含在正常数据集中,如果是,则判定该数据流是正常数据流;否则,可判定该数据流是DDoS攻击流,要进行DDoS攻击流处理。
对DDoS攻击流处理方法:将DDoS攻击流对应的源IP地址加入到系统的黑名单中,DDoS攻击检测系统接收黑名单并更新之前的黑名单,过滤所有加入黑名单的源IP地址发送的数据流。
本发明与现有技术相比,具有以下优点:
1、保障了DDoS攻击检测的可靠性。通过计算数据流的源IP的熵值,对可疑的数据进行预警,再通过采用并行化的动态采样的K-Means算法对可疑的数据流进行二次DDoS攻击检测,充分保证了DDoS攻击检测的精度和可靠性。
2、解决了大数据环境下的并行DDoS攻击检测问题。目前的DDoS攻击检测模型和算法一般适用于单机环境,不适合并行计算环境,通过对普通K-Means算法的并行化,实现了利用云计算系统或数据中心的多个虚拟机对海量的数据流并行的DDoS攻击检测。并且,检测的虚拟数可随数据流量的增加而线性增长。
3、充分保证了DDoS检测的实时性。由于采用Spark实时数据流处理技术,所有DDoS攻击检测都并行在多个虚拟机环境的内存中完成,大大加速DDoS攻击的检测速度,解决了大数据环境下高带宽、海量用户的数据流实时检测问题。
附图说明
图1为本发明一种大数据环境下的DDoS攻击检测方法
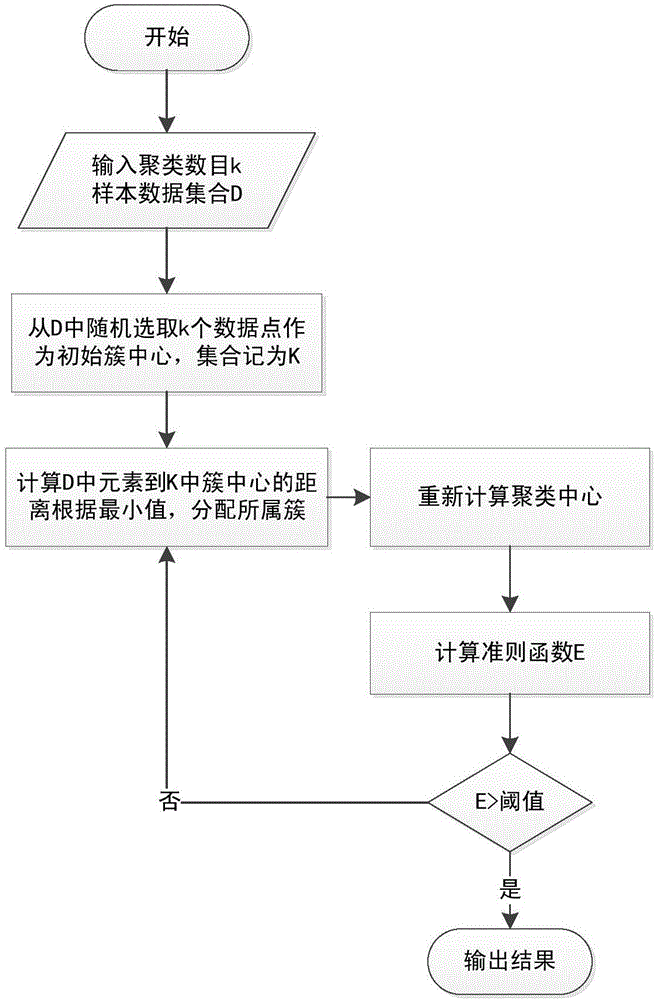
图2为K-Means算法流程图;
图3为动态采样的K-Means算法流程图;
图4为DDoS检测系统的框架图。
具体实施方式
以下结合附图,通过详细说明一个较佳的具体实施例,对本发明做进一步阐述。
如图1所示,一种大数据环境下的DDoS攻击检测方法,该方法包含如下步骤:
S1,大数据环境下采集各种流数据,即从大数据应用系统采集各种流数据;所述大数据应用系统,是指有数以万计以上的海量用户、数据量快速增长、数据量已达数PB的应用系统;所述的用户,包括已注册用户和非注册用户;
所述各种流数据,包括来自代理服务器的数据流、经过防火墙到达系统的数据流和各种POP数据流等;
S2,从采集的各种流数据提取源IP地址;
S3,计算源IP地址的信息熵;
S4,判定源IP地址的信息熵是否大于预设的门限值V,如果是,则判定该源IP地址对应的数据流可能是DDoS攻击流,转步骤S8;若否,则判定该IP地址对应的数据流是正常的数据流,转步骤S5;
所述的预设门限值V为源IP预警检测结果被接受的熵值最高标准
S5,用正常的数据流进行K-Means聚类;
S6,动态采样的K-Means模型训练和算法设计;
S7,动态采样的K-Means算法并行化处理;
S8,用并行化处理的动态采样的K-Means算法进行DDoS攻击检测;
S9,计算准则函数E小于等于预设门限值d,如果是,则判定该数据流为正常数据流,转向步骤S1;否则,判定该数据流为异常数据流,转向步骤S10;
所述的预设门限值d是正常数据流可接受的最小准则函数值;
S10,DDoS攻击处理。
上述的步骤S3中,信息熵的定义:
X表示信息源符号,它有n种取值:X1…Xi…Xn,分别对应的概率为:P1…Pi…Pn,因为每一种信源符号的出现相互独立,所以,有:
上述的步骤S3具体包括:
S3.1统计△t时间内所有请求中,有n种不同的源IP,每种源IP数记为Xi(i=1,2…n),每一Xi出现的次数为Ni(i=1,2…n);
S3.2分别计算Xi出现的概率Pi
S3.3计算△t内信息熵H(X)
S3.4计算前n-1个△t的信息熵的均值A
S3.5求出阈值V,k为放大系数
V=(Max[H(X)]-A)×k (5)
S3.6计算△t的信息熵值和均值的差值S
S=H(X)-A (6)
S3.7如果(S>V)表示熵值变化巨大,数据流可能是DDoS攻击流,发攻击预警;如果(S≤V)表示熵值在正常变化范围内,数据流正常。
如图2所述,所述的步骤S5具体包含:
输入:K,D(初始样本数据)
输出:K个聚类中心
S5.1,数据集D为初始样本,其中每个点为n维:dj=(x1,x2,x3…xn),从数据集合D中随机选择k个对象作为初始簇中心,聚类中心集合记为K;
S5.2,计算数据集D中每个点到k个聚类中心的距离,根据最小值,将点分配给对应的类别,聚类中心对应的数据集合记为Ck,采用公式(7)欧氏距离来进行计算;
S5.3,更新簇的聚类中心
S5.4,计算准则函数
S5.5,满足准则函数阈值则退出,否则返回步骤S5.2。
所述的步骤S6中,对动态采样的K-Means算法的定义如下:
定义1:规模函数W(X)定义如式(10)所示,其中D2(X,C)表示X中的点到所处聚类中心的距离平方和;
定义2:动态采样概率函数P(X)定义如式(11)所示;
定义3:初始规模为W,初始采样个数m(m<K)。
参见图3,上述的动态采样的K-Means算法实现如下:
输入:数据集,K
输出:K个聚类中心
A)从集合X中随机取1个点加入集合C;
B)根据式(10)计算集合C的初始限定规模函数值,记为W;
C)循环logW=N次开始,按式(11)计算动态采样概率P(X),记为P,从集合X中按概率P取出m个点加入集合C′,求C∪C′,记为C,循环结束;
D)采用普通K-Means算法求出集合C的聚类中心。
上述的步骤S7为:根据大数据处理平台Spark运行的原理对设计动态采样的K-Means算法进行并行化,使改进的K-Means算法能在多个虚拟机中同时进行DDoS攻击检测。
上述的DDoS攻击检测为用动态采样的K-Means算法并行化检测已预警的数据流。
上述的已预警的数据流的DDoS攻击检测就是按(9)式计算已预警的数据流的准则函数值E,即通过聚类看已预警的数据流是否被包含在正常数据集中,如果是,则判定该数据流是正常数据流;否则,可判定该数据流是DDoS攻击流,要进行DDoS攻击流处理。
对DDoS攻击流处理方法:将DDoS攻击流对应的源IP地址加入到系统的黑名单中,DDoS攻击检测系统接收黑名单并更新之前的黑名单,过滤所有加入黑名单的源IP地址发送的数据流。
图4是一个具体的DDoS攻击检测系统的框架图,系统由攻击预警模块、流量预处理模块、检测模块和攻击响应模块组成。攻击预警模块中嵌入了基于数据流源IP熵的预警算法,流量预处理模块主要对采集的数据进行处理,检测模块中嵌入了基于Spark的并行化DDoS攻击检测算法。
下面用一个实例来阐述本发明所述的方法。
为了阐述本发明所述的方法的检测速度和准确率,设计了如下实验:采用KDD99数据集的训练全集(500万条数据)作为实验样本,分别从中抽取5组作为实验数据。这五组的数据量分别为:1万条数据、50万条数据、100万条数据、200万条数据、500万条数据。实验设计了三个实验组:第一个实验组,采用单机算法串行处理数据样本;第二个实验组,采用在Spark集群上实现的普通K-Means算法的并行处理数据样本;第三个实验组,采用在Spark集群上实现的动态采样的改进K-Means算法的并行处理数据样本(本发明方法)。表1是三个实验组5次实验的耗时对比,表2是三个实验组5次实验的准确率对比。
表1三个实验组5次实验的耗时对比(秒)
表2三个实验组5次实验的准确率对比(百分比)
从表1看,本发明设计的方法比传统的单机方法节约近4倍的时间,比Spark普通并行方法相比节约近15~30%的时间;从表2看,本发明设计的方法比传统的单机方法和Spark普通并行方法相比,准确率都要高的多。
从上面实例看,本发明与传统方法相比,可充分保证大数据环境下DDoS攻击检测的实时性和可靠性。
尽管本发明的内容已经通过上述优选实施例作了详细介绍,但应当认识到上述的描述不应被认为是对本发明的限制。在本领域技术人员阅读了上述内容后,对于本发明的多种修改和替代都将是显而易见的。因此,本发明的保护范围应由所附的权利要求来限定。
- 还没有人留言评论。精彩留言会获得点赞!