基于统计规律的资讯内容异常检测方法与流程
本发明涉及数据检索领域,具体涉及一种基于统计规律的资讯内容异常检测方法。
背景技术:
随着互联网资讯的快速传播,基于人工识别的资讯内容检测方式已经不能满足各大媒体的业务发展要求,人工的检测方式准确度和工作效率难以保证。
技术实现要素:
本发明的目的是针对现有的技术存在的不足,提出了一种工作效率高的基于统计规律的资讯内容异常检测方法。
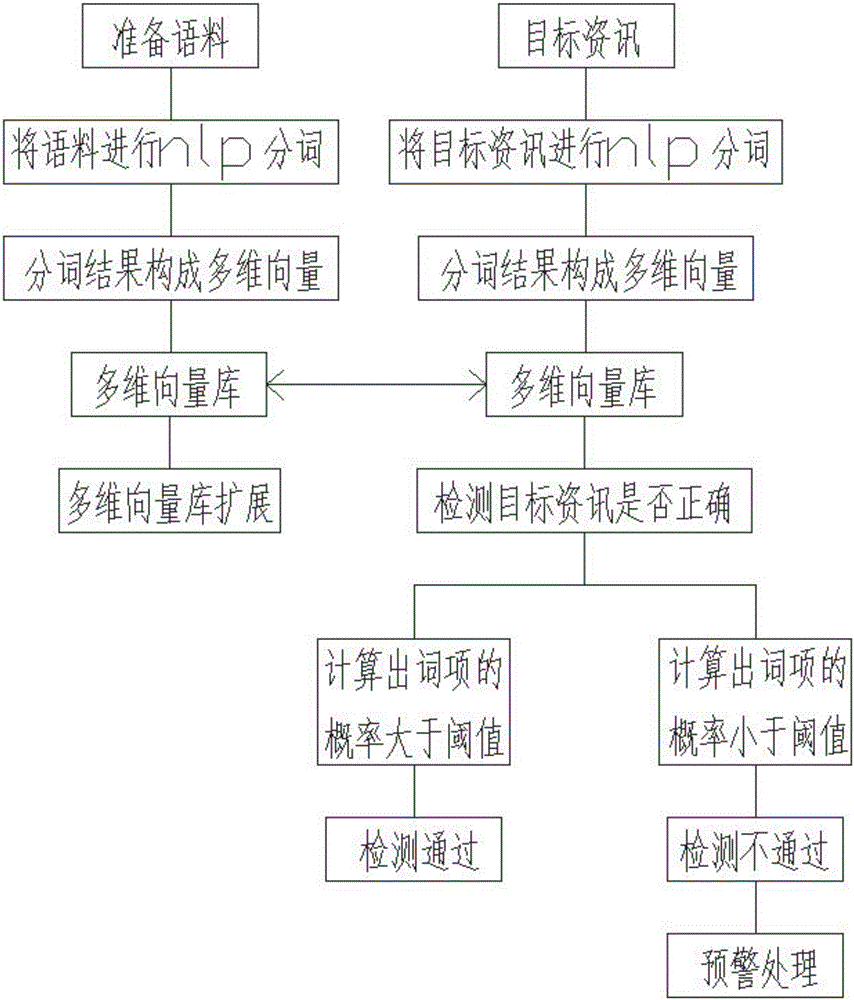
本发明所解决的技术问题采用以下技术方案来实现一种基于统计规律的资讯内容异常检测方法,包括如下步骤:步骤一、准备语料;步骤二、将语料进行nlp分词;步骤三、分词结果构成多维向量;步骤四、多维向量积攒成多维向量库;步骤五、形成多维向量库扩展;步骤六、需要检测时准备目标资讯;步骤七、将目标资讯进行nlp分词;步骤八、分词结果构成多维向量;步骤九、在多维向量库内检测目标资讯是否正确;步骤十、计算出词项的概率大于阈值;步骤十一、检测通过;步骤十二、计算出词项的概率小于阈值;步骤十三、检测不通过;步骤十四、预警处理。
本发明的有益效果为:提出了一种基于统计规律的资讯内容异常检测方法,通过基于统计规律的资讯内容错误检测方法,可以给媒体机构提供智能的资讯内容错误提醒机制,减少人为的错误发生,保障互联网的媒体事业健康稳定的发展。
相比采用黑白名单,简单的过滤敏感词,本发明更能高效准确的检测资讯内容的错误。
附图说明
图1是本发明的基于统计规律的资讯内容异常检测方法的流程图。
具体实施方式
参照附图,一种基于统计规律的资讯内容异常检测方法,包括如下步骤:步骤一、准备语料;步骤二、将语料进行nlp分词;步骤三、分词结果构成多维向量;步骤四、多维向量积攒成多维向量库;步骤五、形成多维向量库扩展;步骤六、需要检测时准备目标资讯;步骤七、将目标资讯进行nlp分词;步骤八、分词结果构成多维向量;步骤九、在多维向量库内检测目标资讯是否正确;步骤十、计算出词项的概率大于阈值;步骤十一、检测通过;步骤十二、计算出词项的概率小于阈值;步骤十三、检测不通过;步骤十四、预警处理。
本发明提出了一种基于统计规律的资讯内容异常检测方法,通过基于统计规律的资讯内容错误检测方法,可以给媒体机构提供智能的资讯内容错误提醒机制,减少人为的错误发生,保障互联网的媒体事业健康稳定的发展。
相比采用黑白名单,简单的过滤敏感词,本发明更能高效准确的检测资讯内容的错误。
- 还没有人留言评论。精彩留言会获得点赞!