一种集成麦克风接收阵列的超声定向发射参量阵的制作方法
本实用新型涉及电子技术领域,尤其涉及一种集成麦克风接收阵列的超声定向发射参量阵。
背景技术:
参量阵是一种非线性声源,它可以采用小孔径发射阵列生成具有尖锐指向性的低频声波。Westervelt在1963年首次提出了参量阵的理论模型。Berktay发展了Westervelt的研究,并在1965年提出了宽带参量阵的理论模型。
波束合成是参量阵研究的重要部分。在早期参量阵声呐中,探测信号波束一般被设计为指向固定方向,然后由机械方式完成波束偏转。随后电控波束偏转被应用于参量阵声呐设计,其有效的降低了目标的搜索与跟踪时间。类似的研究也开展在空气介质中,Tan等提出采用声相控阵技术实现电控波束偏转,并通过仿真验证了其可行性。随后,Shi与Gan完成了参量阵波束的电控偏转实验。
说话人识别技术,是一项根据语音中反映说话人生理和行为特征的语音参数,自动识别说话人身份的技术。说话人识别基于语音,既包含了人的生理特征即解剖学上存在的差异,又包含了人的行为特征即后天的发音习惯上的不同。
技术实现要素:
本实用新型旨在提供一种集成麦克风接收阵列的超声定向发射参量阵,适用于手机等便携式设备,通过定向发声以便保护用户在设备使用过程中的个人信息,并且不影响他人。
为达到上述目的,本实用新型是采用以下技术方案实现的:
本实用新型公开的集成麦克风接收阵列的超声定向发射参量阵,包括收发一体的麦克风换能器阵列、信号处理单元,所述麦克风换能器阵列与信号处理单元电连接,麦克风换能器阵列包括若干个换能器和麦克风,所述信号处理单元用于发射信号的预处理以及接收信号的分析。
优选的,所述信号处理单元包括:
声频定向发射模块,用于对信号进行调制和放大,输出到后级换能器上通过电声转换发射定向超声波;
相控驱动模块,用于控制换能器阵列的各个单元信号相位,使得换能器阵列在本身无机械偏转的情况下产生声束的偏转。
优选的,所述信号处理单元还包括:
说话人定位模块,通过麦克风换能器阵列中的麦克风阵列接收来自说话人的语音,通过对各阵元接收到的信号进行相位分析和处理,对说话人进行定位。
进一步的,所述信号处理单元还包括:
说话人识别模块,从语音信号中提取说话人语音特征的模型并与事先训练好的模型库进行匹配以确认说话人身份。
优选的,所述麦克风换能器阵列为直线形、矩形、圆形、环形或椭圆形。
优选的,所述信号处理单元包括DSP或FPGA。
优选的,所述说话人识别模块包括说话人模型库、特征提取模块、模型训练模块、模型识别模块和逻辑决策模块,所述说话人模型库包括多个说话人模型。
说话人鉴别时,取其与测试语音匹配距离最小的模型所对应的说话人,作为说话人鉴别的结果。在说话人确认时,用测试音的模型与所声称的说话人的模型进行比较,若匹配距离小于一个规定的阀值,则该说话人得到确认,否则,该说话人不是他所声称的那个身份。
优选的,本实用新型还包括智能手机,所述说话人定位模块和/或说话人识别模块包含在智能手机中。
本实用新型的有益效果在于:换能器阵列和麦克风阵列集成到一起,减小了空间占用。另外,利用信号处理技术对麦克风阵列信号进行处理,识别并定位用户,使换能器能够自适应地根据用户位置发出定向声束。本实用新型不仅能保护用户隐私使其他人免于干扰,还能够根据用户位置实时调整声束,使得设备使用更加便捷。
附图说明
图1示出了应用于手机的集成麦克风阵列的超声定向换能器系统。
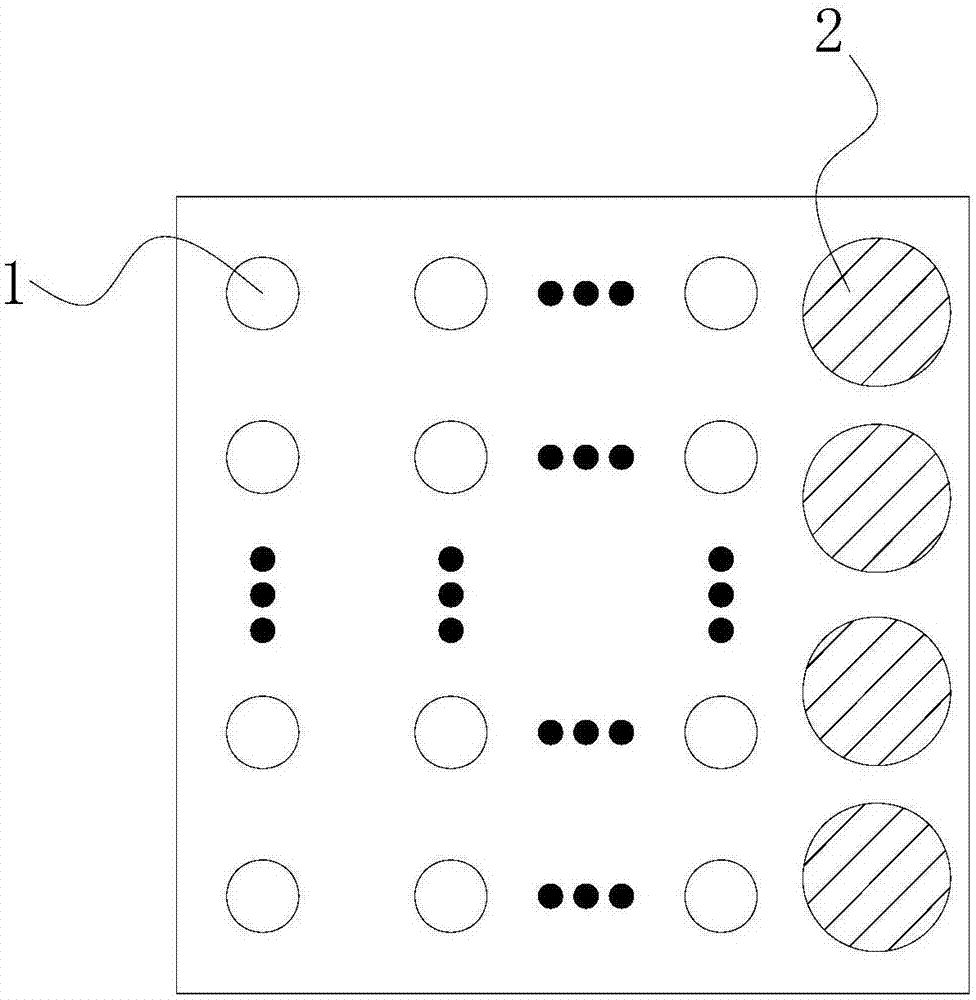
图2示出了集成麦克风阵列的换能器结构示意图;
图3示出了消除声反馈的原理;
图4示出了人声识别体系;
图5示出了声阵列信号处理的基本模型;
图6示出了声学数字相控阵技术的原理
图7示出了N阵元均匀线性阵列实现波束电控偏转的结构。
具体实施方式
为了使本实用新型的目的、技术方案及优点更加清楚明白,以下结合附图,对本实用新型进行进一步详细说明。
图1所示为集成麦克风接收阵列的超声定向换能器系统,换能器阵列位于手机屏幕所在平面并与之平行。信号处理模块利用手机中的信号处理硬件平台向超声定向换能器输出激励信号并处理麦克风阵列的接收信号以识别和定位说话人。
图2示出了集成麦克风和超声定向参量阵的换能器阵列结构。换能器分时接收或者发射。单一阵元的发射具有一定的指向性,当组成正方形阵列后,指向性得到增强,功率也随之增大。而四个小型麦克风置于超声换能器旁以均匀线阵排列,大大减小系统整体所占空间,同时减小定位难度,提高精度。由于阵元跟阵元之间的作用,会产生旁瓣。因此,在每个阵元发声外部,用一层多孔疏松的材料进行对活塞换能器的进一步传播整形。
图3示出了PEM-AFROW(Prediction Error Method based Adaptive Filtering with Row Operations)算法消除声反馈的原理。由于麦克风阵列距离超声定向换能器较近,难免会接收到来自换能器的发声,影响麦克风对人声的识别定位。其中K为扩声增益;q-1是延时因子;q-d表示d个样本的延迟;为反馈补偿信号;是抵消滤波器;F是信号从传声器到扬声器(即换能器阵)传递的声反馈路径。
关于手机内部冲激响应F的滤波器系数向量f(n)可以用nF+1阶的有限脉冲响应FIR滤波器表示:
F(q,n)=fT(n)q=[f0(n)f1(n)…fnF(n)][q0q1…qnF]T
将估计得到的冲激响应系数值在满足一定条件下有规律地复制到抵消滤波器中。这样传声信号x(n)减去经过抵消滤波器滤波后的扬声器信号,得到的反馈补偿信号d(n)就应该等于声源信号s(n)。这里声源信号s(n)为nA阶的时变自回归模型。如下表示:
这里e(n)为理想白噪声激励序列,b(n)=1。
传递函数H(q,n)可以用无限脉冲响应IIR滤波器形式写出如下:
图4出了人声识别体系。说话人识别系统的逻辑框图如图,包括特征提取、模型训练、模式匹配、以及逻辑决策四个主要模块。特征提取模块处理单通道麦克风信号,从语音信号中提取说话人语音特征以便建立说话人语音特征模型。模型训练模块是指建立说话人模型的过程。说话人模型可以是单一的模板模型、矢量量化模型、高斯混合模型、隐马尔可夫模型、人工神经网络模型、支持向量机、动态贝叶斯网络以及它们的混合模型。不论什么模型,模型的参数估计和优化都在这一步骤完成。模式匹配模块将事先采集的测试音特征与说话人模型进行匹配,计算匹配距离。说话人确认时,只与所声称的说话人模型进行匹配;说话人鉴别时,与所有人的模型进行匹配。逻辑决策模块根据匹配距离的计算结果,判决说话人是否是所声称的说话人或说话人到底是谁。
图5示出了声阵列信号处理的基本模型。由于识别人声后后利用分频2D-MUSIC算法进行人声定位,分频2D-MUSIC算法是一种基于子空间分解的定位算法,在建立麦克风阵列理论模型时,与普通MUSIC算法不同,引入时间因子,在时域上进行分时,进而达到频域分频,以此推导出频谱及相应的位置信息受目标声源的相干性、平稳性及信号带宽影响更小。
图6示出了声学数字相控阵技术的原理示意图。以线性阵列发射单频原波为例,若各阵元所发射的原波传播至与实际发射阵列成θ0角度的虚拟平面位置时具有相同相位,整个阵列合成波束即可获得θ0角度的波束偏转。声学数字相控阵技术中通过对各阵元发射信号加载不同初相φi来满足上述要求,而初相φi则采用信号延时方法获得。
图7示出了N阵元均匀线性阵列实现波束电控偏转的结构示意图。该阵列形状条件下波束偏转时相邻阵元所发信号的初相间具有等值相差φ0。φ0由相邻阵元到虚拟平面的垂直距离差决定,有φ0=d·sin(θ0)/λ(d为相邻阵元间距,λ为发射信号波长)。当需要完成θo角度波束偏转时,第i个阵元的发射信号初相为(i-1)·φ0,而阵元i所需信号延时τi的计算公式如下:
对于一原波组而言,波束偏转时,其所属的原波具有相同的延时。如此对原波组施加时延τi后,同组各原波将同步完成θo角度的波束偏转。而基于图2所示的方形换能器阵列,根据期望发射方位,利用此法算出各阵元所需延时,即可实现波束偏转,达到调节发射声波方向的目的。
当然,本实用新型还可有其它多种实施例,在不背离本实用新型精神及其实质的情况下,熟悉本领域的技术人员可根据本实用新型作出各种相应的改变和变形,但这些相应的改变和变形都应属于本实用新型所附的权利要求的保护范围。
- 还没有人留言评论。精彩留言会获得点赞!