一种基于车载诊断系统数据的路况分析预警方法与流程
本发明属于车联网安全技术领域,涉及一种基于车载诊断系统数据的路况分析预警方法。
背景技术
随着经济社会的快速发展,人、车、路等交通元素急剧增加,全国各地交通问题成为焦点。现有驾驶行为预测技术都只是简单地对驾驶时间和驾驶里程进行分析,仅仅是收集了行驶速度、行驶时间、行驶里程、急刹车次数等数据,然后参考固定标准进行判断,智能程度非常低。并不能根据用户的不同和路段的不同进行智能提醒。只是依托于空调及车窗开关系统的附属功能,所以不能广泛应用于各式各样的车型,无法满足用户的需求。且市面上的原有技术,大多是机械式的安全提醒,并没有处理突发情况等等的智能化功能。智能化程度低,只能根据固定标准判断路况和评价行驶状态,适用范围狭隘,无法响应时代对于车联网的需求。路况分析预警系统能使车辆提醒功能摆脱传统的机械式提醒,响应时代对于车联网的需求,发展开展智能化提醒系统。
技术实现要素:
本发明的目的就是提供一种基于车载诊断系统数据的路况分析预警方法。
本发明包括如下步骤:
步骤一、将用户个人信息与车辆信息录入云端数据分析中心,每个用户建立一个数据库,并设置密码;通过车辆上强制安装的汽车诊断第二代系统接口,按照汽车诊断第二代系统协议读取车辆数据后,将车辆数据上传至云端数据分析中心中对应该车辆用户的数据库。
步骤二、云端数据分析中心利用深度学习算法分析步骤一中得到的车辆数据并建立分类模型:
1、对不平衡数据集进行处理,使用欠采样使数据集达到平衡。避免出现正常数据比例过大,异常数据比例过小的现象。
2、对车载数据集建立分类模型,辅助路况分析与行为分析。将数据贴上正常与异常两个标签,然后按相同比例分为两部分:去除标签的数据集和保留标签数据集。
采用基于k-means算法与高斯混合模型相结合的异常检测机制对无标签数据集进行聚类分析,采用基于k-means算法的异常检测机制对有标签数据集进行同样聚类分析。从汽车诊断第二代系统接口上收集到的数据视为一系列的向量,代表高维空间的一系列特征点。k-means算法对特征点进行分簇,分为异常和正常两簇。对于单个数据点的车辆行驶状态,观察它相对于哪个簇中心的欧几里得距离更近,然后比较其他数据点到簇中心的距离方差,即可判断该点是异常状态还是正常状态。无标签的数据集还需要在后期加入高斯混合模型来计算计算数据被分在不同类中的概率,进而实现数据点的细分类,获得更为精确的结果,避免过拟合的产生。
3、对实时数据集建立路况预测模型,为预警提供技术支持。使用车辆行驶中出现的异常数据点来刻画道路的整体状态,利用自编码器进行异常信息的检测,并且用bp算法进行模型训练。对驾驶数据进行分析,得到路况模型,避开了实地收集路况的环节。自编码器中的模型有压缩数据和恢复数据的作用,压缩和恢复主要针对隐藏层中的特征数据。被提取出的特征数据将经过sigmoid函数,以实现车辆数据的离散化,进而满足了k-means算法的使用条件。通过bp神经网络赋予每个属性权值,以克服传统k-means算法各属性等权的缺点。自编码器对驾驶员驾驶习惯的再次建模可以给所有用户匹配个性化路况预警,有针对性地改良不良驾驶习惯,大幅度提高个性智能化预警的水平。
步骤三、云端数据分析中心将步骤二中分析完成的数据存储至对应车辆用户的数据库中,并将分析结果发送至用户移动端,查看时需输入步骤一中设置的密码,确保数据安全性。移动端根据数据,告知用户当前路况,提示危险路段和拥塞路段,同时纠正用户不良驾驶行为,实现实时预测。
步骤四、建立度量指标。量化模型的性能,检验模型的正确性、稳定性和可依赖性,进而辅助后续的改进。
采用无监督学习路况分析模型,通过无标签数据验证模型的准确性。
或使用聚类结果的簇划分。令簇划分为:
c={c1,c2,...,ck},
dbi指数越小,聚类结果越好。设现有数据集d={x1,x2,......xm},簇划分c={c1,c2,........ck},参考模型簇划分c*={c*1,c*2,......c*s},令λ与λ*分别表示c和c*对应的簇标记向量。考虑所有样本对在两个组划分中的归属情况分为类别a、b、c、d见式⑵:
a=|ss|,ss={(xi,xj)|λi=λj,λi*=λj*,i<j}
b=|sd|,sd={(xi,xj)|λi=λj,λi*≠λj*,i<j}
c=|ds|,ds={(xi,xj)|λi≠λj,λi*=λj*,i<j}
d=|dd|,dd={(xi,xj)|λi≠λj,λi*≠λj*,i<j}⑵;
然后采用rand指数
所述的准确性评估指标采用f2系数评估方法,引入精确率和召回率两个指标。
精确率p
召回率
本发明数据获取方便,针对obd硬件(车载诊断系统)进行开发,拥有提供数据的设备。该设备在市场上的绝大部分车辆都有安装,不用担心数据收集的问题。采用多种神经网络和无监督深度学习算法,如对不平衡数据集进行欠采样,基于k-means算法的异常检测机制,自编码器,前馈神经网络等,减小测量误差。使用无监督的学习方法来训练深度神经网络,在这种学习方法中,性质类似的数据点会自动聚焦到一起。所有数据只有特征向量没有标签,但是可以发现这些数据呈现出聚群的结构,进而获得更准确的簇划分。实地路况分析通常需要耗费大量的人力物力,而我们的核心算法跳过了最繁琐的实地路况分析,极大地减少了部署开支。我们采用基于k-means算法的异常检测机制,对驾驶数据进行分析,得到路况模型,十分巧妙地避开了实地收集路况的环节。推测路况而不是耗费大量资金去收集路况信息,这既降低了项目的部署难度,也节约了资金消耗。具有智能分析和提醒功能,有限避免不良驾驶行为,躲避拥塞道路,预警事故多发地段。
附图说明
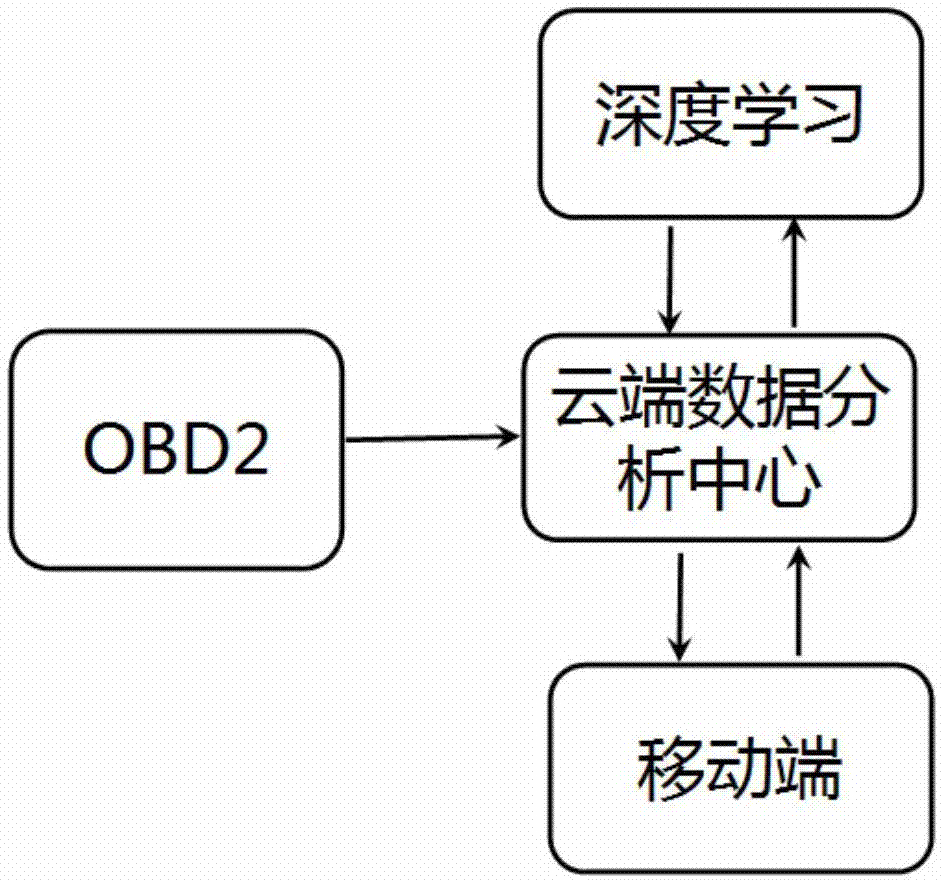
图1为本发明的设计框图;
图2为本发明实施例中步骤二与步骤四的流程图。
具体实施方式
一种基于车载诊断系统数据的路况分析预警方法,首先通过读取车辆上安装的obd样本数据来获取车辆行驶的数据(速率、行驶方向、加速度、位置等),监听异常行为(急刹车、急速行驶等),然后上传到云端数据分析中心利用多种深度学习算法分析并学习用户的驾驶行为,对样本数据进行多次建模和评估,以判断当前道路的拥塞状况、是否容易产生急刹车等危险行为。在获取并分析了足够多的数据之后,系统会根据用户的驾驶行为二次建模,告知用户当前路况,在易堵车的路段和事故高发路段提前警示用户,从而大幅度降低堵车概率和事故发生概率。
如图1所示,一种基于车载诊断系统数据的路况分析预警方法,具体包括如下步骤:
步骤一、将用户个人信息与车辆信息录入云端数据分析中心,每个用户建立一个数据库,并设置密码;通过车辆上强制安装的汽车诊断第二代系统(obd2,thesecondon—boarddiagnostics)接口,按照汽车诊断第二代系统协议读取车辆数据后,将车辆数据上传至云端数据分析中心中对应该车辆用户的数据库。
步骤二、云端数据分析中心利用深度学习算法分析步骤一中得到的车辆数据并建立分类模型,如图2所示:
1、对不平衡数据集进行处理,使用欠采样使数据集达到平衡。避免出现正常数据比例过大,异常数据比例过小的现象。
2、对车载数据集建立分类模型,辅助路况分析与行为分析。将数据贴上正常与异常两个标签,然后按相同比例分为两部分:去除标签的数据集和保留标签数据集。
采用基于k-means算法与高斯混合模型相结合的异常检测机制对无标签数据集进行聚类分析,采用基于k-means算法的异常检测机制对有标签数据集进行同样聚类分析。从汽车诊断第二代系统接口上收集到的数据视为一系列的向量,代表高维空间的一系列特征点。k-means算法对特征点进行分簇,分为异常和正常两簇。对于单个数据点的车辆行驶状态,观察它相对于哪个簇中心的欧几里得距离更近,然后比较其他数据点到簇中心的距离方差,即可判断该点是异常状态还是正常状态。无标签的数据集还需要在后期加入高斯混合模型来计算计算数据被分在不同类中的概率,进而实现数据点的细分类,获得更为精确的结果,避免过拟合的产生。
3、对实时数据集建立路况预测模型,为预警提供技术支持。使用车辆行驶中出现的异常数据点来刻画道路的整体状态,利用自编码器进行异常信息的检测,并且用bp算法进行模型训练。自编码器中的模型有压缩数据和恢复数据的作用,压缩和恢复主要针对隐藏层中的特征数据。被提取出的特征数据将经过sigmoid函数,以实现车辆数据的离散化,进而满足了k-means算法的使用条件。通过bp神经网络赋予每个属性权值,以克服传统k-means算法各属性等权的缺点。自编码器对驾驶员驾驶习惯的再次建模可以给所有用户匹配个性化路况预警,有针对性地改良不良驾驶习惯,大幅度提高个性智能化预警的水平。
步骤三、云端数据分析中心将步骤二中分析完成的数据存储至对应车辆用户的数据库中,并将分析结果发送至用户移动端,查看时需输入步骤一中设置的密码,确保数据安全性。移动端根据数据告知用户当前路况,提示危险路段和拥塞路段,同时纠正用户不良驾驶行为,实现实时预测。
步骤四、建立度量指标。量化模型的性能,检验模型的正确性、稳定性和可依赖性,进而辅助后续的改进。
采用将带标签的数据去除标签后重新投入路况分析模型,将结果与原标签数据对比,验证模型的准确性。
或是使用聚类结果的簇划分。令簇划分为:c={c1,c2,...,ck},定义
dbi指数越小,聚类结果越好。通过收集用户体反馈数据或者其他途径得到了比较权威的参考模型,就可以考虑性能度量的“外部指标”了:设现有数据集d={x1,x2,......xm},簇划分c={c1,c2,........ck},参考模型簇划分c*={c*1,c*2,......c*s},令λ与λ*分别表示c和c*对应的簇标记向量。考虑所有样本对在两个组划分中的归属情况分为类别a、b、c、d见式⑵:
a=|ss|,ss={(xi,xj)|λi=λj,λi*=λj*,i<j}
b=|sd|,sd={(xi,xj)|λi=λj,λi*≠λj*,i<j}
c=|ds|,ds={(xi,xj)|λi≠λj,λi*=λj*,i<j}
d=|dd|,dd={(xi,xj)|λi≠λj,λi*≠λj*,i<j}⑵;
然后采用rand指数
通常用于检测正常类的简单模型将会检测出超过99%的准确率,所以不能用简单的准确率作为评估指标,而是采用f2系数评估方法,引入精确率和召回率两个指标。在机器学习领域当中的python模块sklearn的资料中显示:理想的系统兼具高精确率与高召回率,在返回大量结果的同时,所有结果的标签也都是正确的。
精确率p被定义为:正类判定为正类的数量tp除以正类判定为正类的数量加上负类判定为正类的数量fp的总和
召回率r被定义为:正类判定为正类的数量tp除以正类判定为正类的数量加上正类判定为负类的数量fn的总和,
由于正类判定为负类的后果会比负类判定为正类的后果更加严重,因此高召回率,意味着误将负类判定为正类的概率会增加;同时,为避免负类判定为正类的概率太大,使用f2分数
- 还没有人留言评论。精彩留言会获得点赞!