耳机的制作方法
本申请涉及耳机领域,特别是涉及一种具有运动传感器的耳机。
背景技术:
随着科技进步,市面上出现了许多搭配有运动传感器的智能型行动配件,诸如智能型手环、智能型手表等。这些类型的配件通过无线传输技术将运动传感器所感测到的数据发送至智能型手机,再利用智能型手机的应用程序对所述数据进行解析,从而产生分析结果。使用者可通过分析结果取得个人心律、运动步数等与生理状态和运动状态关联的信息。然而,进行无线传输将大量地消耗智能型行动配件以及智能型手机的电量,并且不良的联机质量也会使数据的分析延迟。
另一方面,对与运动姿势关联的感测数据进行分析时所使用的识别模型,其训练过程往往需使用到大量的卷标数据。一般来说,卷标数据都是由人员根据自身对姿势的判断来对感测数据进行贴标而产生。以人工方式对数据进行贴目标效率不高。此外,不同的人员对相同姿势的判断标准并不相同,且长期的贴标过程容易使人员疲累而导致判断错误。基此,训练模型时所使用的卷标数据中经常参杂了许多错误的卷标数据,进而导致模型的效能不彰。
技术实现要素:
基于此,有必要针对上述问题,提供一种具有运动传感器的耳机。
一种耳机,包括:
扬声器,用于播放音频数据;
运动传感器,用于感测使用者的姿势以产生第一感测数据;
收发器,用于与外部装置进行数据传输;以及
处理器,耦接所述运动传感器以及所述收发器,所述处理器根据所述第一感测数据判断所述姿势是否正确以产生输出结果,并且透过所述收发器发送所述输出结果。
在其中一个实施例中,所述输出结果指示所述姿势是否正确,并且所述耳机的模式包括:
一般模式,所述收发器只发送所述输出结果;以及
训练模式,所述收发器发送所述第一感测数据至所述外部装置。
在其中一个实施例中,所述处理器储存多个识别模型,并且根据所述第一感测数据以及所述识别模型判断所述姿势是否正确以产生所述输出结果。
在其中一个实施例中,所述耳机还包括:
生理传感器,耦接所述处理器,所述生理传感器感测所述用户的生理信息以产生第二感测数据,其中所述处理器根据所述第一感测数据和所述第二感测数据产生所述输出结果。
在其中一个实施例中,所述耳机还包括:
第一壳体,对应于所述使用者的第一耳,其中所述运动传感器设置于所述第一壳体;以及
第二壳体,对应于所述使用者的第二耳,其中所述生理传感器设置于所述第二壳体。
在其中一个实施例中,所述第一感测数据为动作姿态参数,并且所述第二感测数据为生理参数。
在其中一个实施例中,在产生所述输出结果后,所述处理器降低当前播放的所述音频数据的声量,并且发送与所述输出结果关联的提示音至所述扬声器。
在其中一个实施例中,所述处理器透过所述收发器接收由应用所设定的锻练菜单,并且根据所述第一感测数据以及所述锻练菜单判断所述姿势是否正确以产生所述输出结果,其中所述锻练菜单包括锻练种类、组数以及次数中的一种或多种的组合。
在其中一个实施例中,所述处理器根据所述收发器接收到的更新信息而更新固件,以取得更新后的所述识别模型。
一种耳机,包括:
扬声器,用于播放音频数据;
运动传感器,用于感测使用者的姿势以产生第一感测数据;以及
处理器,包括数据处理单元及音频处理单元,所述数据处理单元耦接于所述运动传感器与所述音频处理单元之间,根据所述第一感测数据判断所述姿势是否正确以产生输出结果,并且透过所述音频处理单元发送所述输出结果至所述扬声器播放。
在其中一个实施例中,所述数据处理单元储存多个识别模型,并且根据所述第一感测数据以及所述识别模型判断所述姿势是否正确以产生所述输出结果。
在其中一个实施例中,所述耳机还包括收发器,所述收发器耦接所述数据处理单元并与外部装置进行数据传输,所述数据处理单元根据所述收发器接收到的更新信息而更新固件,以取得更新后的所述识别模型。
在其中一个实施例中,所述输出结果指示所述姿势是否正确,并且所述耳机的模式包括:
一般模式,在所述数据处理单元产生所述输出结果后,所述音频处理单元发送与所述输出结果关联的提示音至所述扬声器;以及
训练模式,所述数据处理单元发送所述第一感测数据至外部装置。
在其中一个实施例中,所述数据处理单元在所述一般模式下产生所述输出结果后,所述音频处理单元将降低当前播放的所述音频数据的声量,并且发送与所述输出结果关联的所述提示音至所述扬声器。
上述耳机,不需要透过无线传输技术来将传感器所产生的原始数据发送至诸如智能型手机等外部装置。因此,可显著地降低耳机和/或外部装置所耗用的电量。
为了增加卷标数据的产生效率,并且改善识别所训练模型的准确率(accuracy),本申请提出一种产生卷标数据的系统和方法。
本申请提供一种产生卷标数据的系统,包括第一影像捕获设备、第二影像捕获设备、运动感测装置以及第一处理器。第一影像捕获设备感测用户的姿势以产生平面影像。第二影像捕获设备感测用户的姿势以产生深度影像。运动感测装置感测用户的姿势以产生运动数据。第一处理器耦接第一影像捕获设备、第二影像捕获设备以及运动感测装置。第一处理器根据平面影像以及深度影像产生姿势的识别结果,并且根据识别结果对运动数据进行贴标以产生卷标数据。
本申请提供一种产生卷标数据的方法,包括:感测用户的姿势以产生平面影像;感测用户的姿势以产生深度影像;感测用户的姿势以产生运动数据;以及根据平面影像以及深度影像产生姿势的识别结果,并且根据识别结果对运动数据进行贴标以产生卷标数据。
基于上述,本申请的产生卷标数据的系统可自动化地对数据进行贴标,帮助用户更快速地产生卷标数据,并且使用卷标数据所训练出来的识别模型的识别准确率也会获得提升。
附图说明
图1为本申请一个实施例中耳机的结构示意图;
图2为本申请一个实施例中耳机的电路框图;
图3为本申请一个实施例中产生卷标数据的系统的连接关系图;
图4为本申请一个实施例中产生卷标数据的方法流程图;
图5为本申请一个实施例中产生卷标数据的方法的步骤流程图。
具体实施例
为了便于理解本申请,下面将参照相关附图对本申请进行更全面的描述。附图中给出了本申请的较佳的实施例。但是,本申请可以以许多不同的形式来实现,并不限于本文所描述的实施例。相反地,提供这些实施例的目的是使对本申请的公开内容的理解更加透彻全面。本文中在本申请的说明书中所使用的术语只是为了描述具体地实施例的目的,不是旨在于限制本申请。
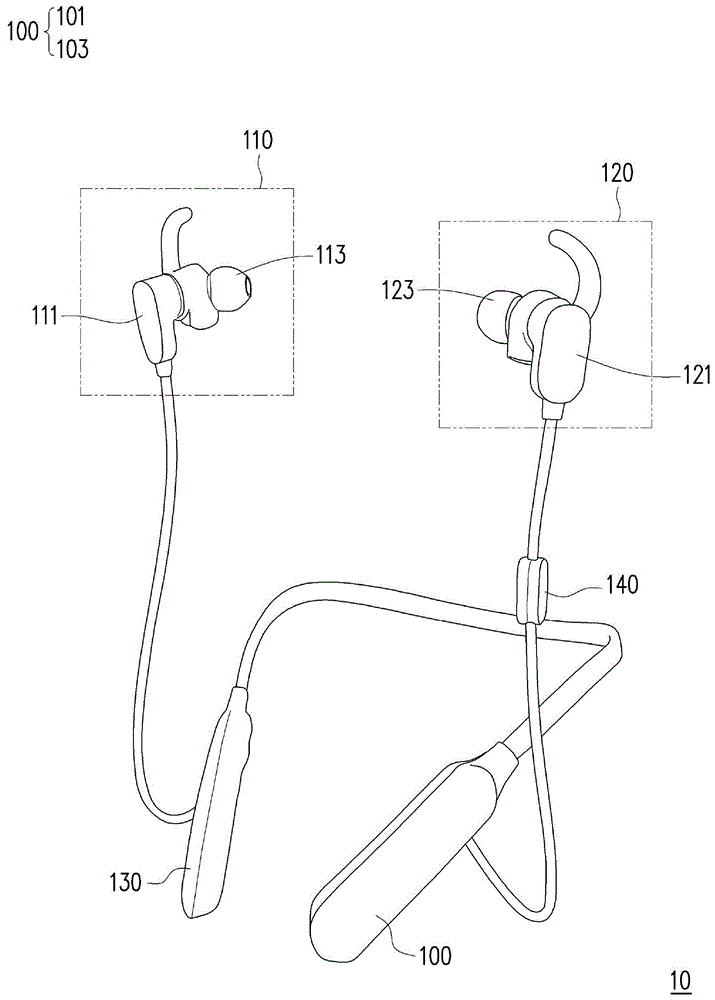
图1为本申请一个实施例中耳机10的结构示意图,图2为本申请一个实施例中耳机10的电路框图,请同时参照图1及图2。
耳机10可包括主板100、第一壳体110、第二壳体120、电源模块130以及麦克风与控制按键模块140。电源模块130用以提供耳机10运行所需耗用的电量。麦克风与控制按键模块140可用以作为耳机10的输入设备,用户可透过麦克风与控制按键模块140将声音或控制指令发送至耳机10的处理器101。
主板100可以是陶瓷基板、印刷电路板(printedcircuitboard,pcb)、有机基板或中介基板,本申请不限于此。在本实施例中,主板100可包括处理器101以及收发器103。
处理器101可以是中央处理单元(centralprocessingunit,cpu),或是其他可程序化一般用途或特殊用途的微处理器(microprocessor)、数字信号处理器(digitalsignalprocessor,dsp)、可程序化控制器、特殊应用集成电路(applicationspecificintegratedcircuit,asic)或其他类似组件或上述组件的组合,本申请不限于此。
更具体来说,处理器101的内部可包括一或多个具有不同功能的处理单元。如图2所示,处理器101可包括数据处理单元p1以及音频处理单元p2,其中数据处理单元p1耦接于运动传感器111与音频处理单元p2之间。数据处理单元p1可用以识别使用耳机10的用户的姿势,且音频处理单元p2可用以执行音频处理以及发送音频数据至扬声器113和/或扬声器123。
收发器103耦接于处理器101的数据处理单元p1,并可以透过无线或有线的方式与处理器101或外部装置进行数据传输。收发器103还可以执行例如低噪声放大(lownoiseamplifying,lna)、阻抗匹配、混频、上下变频转换、滤波、放大以及类似的操作。
第一壳体110对应于耳机10使用者的第一耳,并可设置运动传感器111以及扬声器113。第二壳体120对应于耳机10使用者的第二耳,并可设置生理传感器121以及扬声器123。扬声器112与扬声器123分别耦接至处理器101的音频处理单元p2。音频处理单元p2可发送信号b至扬声器112和/或扬声器123,借以透过扬声器112和/或扬声器123播放音频数据。在一些实施例中,第一壳体110可设置运动传感器111和/或生理传感器121,并且第二壳体120可设置运动传感器111和/或生理传感器121,本申请不限于此。
运动传感器111耦接处理器101的数据处理单元p1,并可用以感测耳机10使用者的姿势以产生感测数据d1。运动传感器111可以是电子罗盘、地磁传感器、陀螺仪、角速度传感器、加速度传感器、六轴传感器或九轴传感器,本申请不限于此。感测数据d1可以是位移、加速度、角速度或磁力变化等与人体姿势关联的动作姿态参数。
生理传感器121耦接处理器101的数据处理单元p1,并可用以感测耳机10使用者的生理信息以产生感测数据d2。生理传感器121可以是心电传感器、声音传感器、温湿度传感器、汗液酸碱度传感器或肌电传感器,本申请不限于此。感测数据d2可以是心率值、呼吸率或过敏反应等与人体生理状态关联的生理参数。
耳机10可具备一般模式及训练模式。在一般模式中,耳机10可用以对使用者的姿势进行辨识并产生用以判断使用者的姿势是否正确的输出结果op,其中耳机10的收发器103不发送除了输出结果op以外的任何数据。换言之,耳机10在一般模式中仅会耗费极小的电量。
另一方面,在训练模式中,耳机10可利用使用者在运动时所产生的感测数据来训练识别模型im。更具体来说,在训练模式中,耳机10的数据处理单元p1可透过收发器103将感测数据d1和/或感测数据d2发送至外部装置(例如:智能型手机)。外部装置可根据感测数据d1和/或感测数据d2来进行识别模型im的训练。换言之,耳机10的训练模式可产生与用户的姿势或生理信息关联的训练数据。
在一般模式中,处理器101的数据处理单元p1可接收来自运动传感器111的感测数据d1,并且根据感测数据d1判断耳机10使用者的姿势是否正确,借以产生输出结果op。输出结果op可用以提示使用者其进行运动时的姿势正确或不正确。
更具体来说,处理器101的数据处理单元p1可储存(或预存)一或多个识别模型im。数据处理单元p1可根据识别模型im以及感测数据d1来判断用户的姿势是否正确并产生输出结果op。在一些实施例中,数据处理单元p1更可以根据识别模型im、感测数据d1以及感测数据d2来判断用户的姿势是否正确并产生输出结果op。
在产生输出结果op后,数据处理单元p1可透过收发器103将输出结果op输出至外部装置(例如:智能型手机)。另一方面,数据处理单元p1也可将输出结果op发送至音频处理单元p2。音频处理单元p2可对输出结果op进行音讯处理(audioprocessing)以产生对应的信号b,并将信号b发送至扬声器113以及扬声器123以进行播放。信号b可以提示音的形式来提示耳机10使用者其姿势是否正确。在播放与输出结果op关联的信号b时,若用户正使用耳机10收听音乐或广播等其他音频数据,则音频处理单元p2可降低当前音频数据的声量。据此,用户可将对应于信号b的提示音听得更加清楚。
在一些实施例中,处理器101的数据处理单元p1可透过收发器103接收由使用者设定的锻炼菜单。例如,使用者可透过智能型手机的应用设定锻炼菜单,并发送锻炼菜单至耳机10。处理器101的数据处理单元p1可根据感测数据d1、识别模型im以及锻炼菜单来判断使用者的姿势是否正确,借以产生输出结果op。锻炼菜单可包括锻炼种类、组数(set)或次数(rep),但本申请不限于此。
在一些实施例中,除了使用默认于数据处理单元p1的识别模型im进行姿势的识别外,耳机10还可以自外部装置接收新的识别模型im。具体来说,处理器101的数据处理单元p1可透过收发器103接收更新信息,其中更新信息用以提示耳机10进行固件的更新,且更新信息可包括识别模型im的相关信息。数据处理单元p1根据接收到的更新信息而更新耳机10的固件,借以取得更新的或新增的识别模型im。
图3为本申请一个实施例中产生卷标数据的系统30的连接关系图。系统30可包括第一处理器310、第一影像捕获设备320、第二影像捕获设备330、运动感测装置340以及云端处理单元350。系统30可用以根据一使用者的姿势自动地产生对应所述姿势的卷标数据。云端处理单元350可使用卷标数据训练出对应于所述使用者姿势的客制化识别模型,以更准确地识别出所述使用者运动时的姿势是否正确。
第一处理器310耦接第一影像捕获设备320、第二影像捕获设备330、运动感测装置340以及云端处理单元350。第一处理器310可以是中央处理单元,或是其他可程序化一般用途或特殊用途的微处理器、数字信号处理器、可程序化控制器、特殊应用集成电路或其他类似组件或上述组件的组合,本申请不限于此。
第一影像捕获设备320可感测使用者的姿势以产生对应所述姿势的平面影像i1。第二影像捕获设备330可感测使用者的姿势以产生对应所述姿势的深度影像i2。第一影像捕获设备320及第二影像捕获设备330可以是相机、摄影机等,本申请不限于此。在一些实施例中,第一影像捕获设备320可以是红绿蓝摄影机,且第二影像捕获设备330可以是深度摄影机,本申请不限于此。
运动感测装置340可感测用户的姿势以产生对应所述姿势的运动数据d3。运动感测装置340可以是六轴传感器或九轴传感器。在一些实施例中,运动感测装置340可以是如图2所示的耳机10,并且所述运动数据d3可以是如图2所示的感测数据d1,本申请不限于此。
云端处理单元350耦接第一处理器310。云端处理单元350可以是中央处理单元,或是其他可程序化一般用途或特殊用途的微处理器、数字信号处理器、可程序化控制器、特殊应用集成电路或其他类似组件或上述组件的组合,本申请不限于此。
在本实施例中,当使用者进行运动时,第一处理器310可分别自第一影像捕获设备320和第二影像捕获设备330接收对应于所述用户姿势的平面影像i1和深度影像i2,并且自运动感测装置340接收对应于所述用户姿势的运动数据d3。接着,第一处理器310可基于平面影像i1和深度影像i2而对用户的姿势进行识别(例如:透过默认的或所接收到的识别模型对用户的姿势进行识别),从而产生对应于使用者姿势的识别结果。在取得识别结果后,第一处理器310可根据识别结果对运动资料d3进行贴标以产生对应的卷标数据td,其中所述卷标数据td为具有时间卷标的运动数据d3。
更具体来说,第一处理器310可先根据平面影像i1和深度影像i2侦测出运动中使用者的一特定姿势以及所述特定姿势的开始时间,并对运动数据d3进行贴标以将对应于开始时间的开始时间卷标与运动数据d3相关联。接着,第一处理器310可根据平面影像i1和深度影像i2侦测出所述特定姿势的结束时间,并对运动数据d3进行贴标以将对应于结束时间的结束时间卷标与运动数据d3相关联。在产生开始时间卷标和结束时间卷标后,第一处理器310可根据开始时间卷标和结束时间卷标而对开始时间至结束时间之间的时段中的运动数据d3进行贴标,使所述时段中的运动数据d3对应于所述特定姿势,亦即,将对应于所述特定姿势的姿势标签与所述时段中的运动数据d3相关联。在上述的步骤完成后,第一处理器310可产生卷标数据td,其中卷标数据td即为已完成贴目标运动数据d3。
在产生卷标数据td后,第一处理器310可将卷标数据td发送至云端处理单元350。举例来说,第一处理器310可透过一发送器将对应于一用户的卷标数据td发送至云端处理单元350。云端处理单元350可基于卷标数据td训练对应的识别模型im,其中所述识别模型im用以辨识所述用户的姿势是否正确。云端处理单元350可将其所产生的新的或更新后的识别模型im发送至第一处理器310,使得第一处理器310可根据新的识别模型im来产生新的卷标数据。
另一方面,云端处理单元350也可将所产生的识别模型im发送至运动感测装置340。运动感测装置340可根据所接收到的识别模型im来判断用户进行运动时的姿势正确或不正确。具体来说,云端处理单元350可根据所产生的识别模型im发送包括了识别模型im信息的更新信息至运动感测装置340,其中更新信息用以提示运动感测装置340进行固件的更新。运动感测装置340可自云端处理单元350接收更新信息,并且根据更新信息来更新运动感测装置340的固件,借以取得更新或新的识别模型im。
图4为本申请一个实施例中产生卷标数据的方法40流程图,其中方法40可由如图3所示的系统30实施。在步骤s410,感测使用者的姿势以产生平面影像。在步骤s420,感测使用者的姿势以产生深度影像。在步骤s430,感测使用者的姿势以产生运动数据。在步骤s440,根据平面影像以及深度影像产生姿势的识别结果,并且根据识别结果对运动数据进行贴标以产生卷标数据。在步骤s450,根据卷标数据产生识别模型。在步骤s460,根据产生的识别模型而发送更新信息,以提示运动感测装置更新固件。
图5为本申请一个实施例中产生卷标数据的方法40的步骤流程图。在步骤s441,根据平面影像以及深度影像侦测姿势的开始时间。在步骤s442,根据平面影像以及深度影像侦测姿势的结束时间。在步骤s443,对开始时间至结束时间之间的时段中的运动数据进行贴标,借以使时段中的运动数据对应于姿势。
综上所述,本申请的耳机可在本地端进行姿势的识别并产生判断结果。耳机将不需要透过无线传输技术来将传感器所产生的原始数据发送至诸如智能型手机等外部装置。如此,可显著地降低耳机和/或外部装置所耗用的电量。此外,耳机可配置不同类型的传感器以分别产生不同种类的感测数据,进而使感测数据具有更多元的应用方式。另一方面,本申请的产生卷标数据的系统使用图像处理技术对用户的运动姿势进行识别,并且根据识别结果自动地对数据进行贴标。产生卷标数据的系统不需人力介入卷标数据的产生过程。如此,所述系统可以帮助用户更快速地产生卷标数据,并且使用卷标数据所训练出来的识别模型的识别准确率也会获得提升。
以上所述实施例的各技术特征可以进行任意的组合,为使描述简洁,未对上述实施例中的各个技术特征所有可能的组合都进行描述,然而,只要这些技术特征的组合不存在矛盾,都应当认为是本说明书记载的范围。
以上所述实施例仅表达了本申请的几种实施例,所述描述较为具体和详细,但并不能因此而理解为对发明专利范围的限制。应当指出的是,对于本领域的普通技术人员来说,在不脱离本申请构思的前提下,还可以做出若干变形和改进,这些都属于本申请的保护范围。因此,本申请专利的保护范围应以所附权利要求为准。
- 还没有人留言评论。精彩留言会获得点赞!