基于稀疏双目融合卷积神经网络的立体图像质量评价方法与流程
本发明属于图像处理领域,涉及到立体图像质量评价方法的改进优化,以及立体图像质量评价卷积神经网络的计算速度的优化,尤其涉及一种基于稀疏双目融合卷积神经网络的立体图像质量评价方法。
背景技术:
由于观看降质的立体图像会造成视觉疲劳和晕眩,立体图像质量评价成为了亟待解决的事情[1]。立体图像质量评价要考虑深度信息、视差信息和双目竞争等因素,相比平面图像质量评价,立体图像质量评价更具有挑战性。通常立体图像质量评价可分为主观和客观评价两种方法。然而主观评价方法费事费力,因此立体图像客观质量评价成为一个研究的热点问题[2]。
一般来说,立体图像质量客观评价可以分为传统的基于特征提取的方法[3-4]、基于稀疏表示的方法[5-9]和基于深度学习的方法[10-13]。稀疏表示模拟了人类视觉系统的感知机制,它可以将图像中大部分像素表示为零,去除冗余信息。因此,一些人使用基于稀疏表示的方法来评价立体图像的质量。例如,文献[5]对立体图像的左视图和右视图的结构和纹理特征进行了稀疏表示,分别计算了左视图和右视图的稀疏特征相似性指标,并将它们结合起来得到最终的质量分数。文献[6]联合稀疏表示dog、hog和lbp特征,并使用支持向量回归得到立体图像的质量分数。在[7]中,lin等人将融合图像幅度图和融合图像相位图进行稀疏表示,并采用支持向量机回归。m等人稀疏表示了融合图像对比度图和融合图像相位图,并采用支持向量机回归得到立体图像质量分数[8]。在文献[9]中,yang等人提出了一种基于学习梯度字典的彩色视觉特征的无参考立体图像质量评价方法。并将特征输入到训练后的支持向量机模型中,进行质量分数的预测。由于深度学习网络模拟了大脑分层处理图像的过程,近年来,许多人使用深度学习模型来评价立体图像的质量。例如,文献[10]提取了立体图像的自然场景统计特征,并采用得到的特征对dbn进行训练,得到立体图像质量分数。在文献[11]中,ding等人提出了一种基于卷积神经网络(cnn)的无参考立体图像质量评价方法。将cnn网络提取的特征和视差特征通过支持向量机回归,得到立体图像的客观质量分数。在文献[12]中,lv等人提出了一种基于双目自相似度和深度神经网络(dnn)的立体图像质量评价方法。在文献[13]中,sang等人通过主成分分析(pca)融合了立体图像的左右视图。然后采用融合图像训练cnn网络,得到立体图像质量分数。
上述文献中,基于稀疏表示方法可以找到图像的关键信息,但需要通过手工提取特征。如在文献[5]中,提取了结构和纹理特征。文献[6]中,手动提取了dog、hog和lbp特征。在文献[7-8]中提取了融合图像幅度和融合图像相位特征。文献[9]提取了梯度特征。基于深度学习的方法可以通过网络自身学习到综合特征,这使得提取的特征更加全面、合适。但深度学习网络通常计算复杂度高,同时网络对存储空间的要求大。由于神经网络具有高度的非凸性,在网络训练中,过度参数化和随机初始化是克服局部最小值的负面影响的必要手段[14]。也就是说,深度学习网络具有很高的冗余潜力。因此,一些人利用稀疏正则化来压缩dnn。例如,在文献[14]中,liu等人提出了一种采用稀疏分解的稀疏卷积神经网络。这种稀疏卷积神经网络可以使90%以上的参数归零,并且在ilsvrc2012数据集的准确率下降小于1%。在文献[15]中,wen等人提出了一种结构化稀疏的学习(structuredsparsitylearningssl)的方法来正则化dnn。并且ssl可以获得一个硬件友好的结构化稀疏的dnn,从而有效地加速dnn的运算速度。但几乎没有人将ssl应用在立体图像质量评价的深度学习网络中。在文献[15]的启发下,我们提出了一种稀疏的双目融合卷积神经网络来评价立体图像的质量,cnn网络的利用避免了稀疏表示法中的手工特征提取,将ssl应用于卷积神经网络,减少了网络的计算量,加快了网络的运算速度。
如何处理立体图像左右视点之间的关系是立体图像质量评价的关键,针对左右视点的处理方式,上述文献大致可分为两类。文献[5-6][10-12]首先对左右视点分别进行了处理,然后考虑双目融合和双目竞争机制将两个视点的特征进行融合。文献[7-9][13]首先将左右两个视点融合成融合图像,然后对融合图像进行处理。事实上,在人类视觉皮层中,左视图和右视图的融合是一个长期的过程,融合和处理同时发生,左右两个视图被分层的处理和融合[16]。因此,我们采用双目融合卷积神经网络,将两个视图通过四次concat进行四次融合,模拟视觉皮层的长期融合与信息的处理。
技术实现要素:
为了解决现有技术问题,本发明提出一种稀疏的双目融合卷积神经网络进行立体图像质量评价;采用卷积神经网络进行立体图像质量评价,避免了手动的特征提取。采用结构化稀疏正则化约束卷积神经网络,降低网络的计算复杂度,加快了网络计算速度,提高了网络性能;考虑到人眼的双目融合和双目竞争机制,模拟视觉皮层的长期融合过程,立体图像的左右两个视点通过四次concat进行四次融合,同时进行信息的处理;本专利的立体图像质量评价方法更加准确高效,更贴合人眼感知质量,运算速度更快,在一定程度上推动立体成像技术的发展。
解决现有技术存在的问题,本发明采用如下技术方案予以实施:
1、一种基于稀疏双目融合卷积神经网络的立体图像质量评价方法,其特征在于,包括如下步骤:
s1、构建基于双目融合卷积神经网络的立体图像质量评价网络,网络包含左右分支和融合分支;
s2、在双目融合卷积神经网络的每一层施加结构化稀疏约束,网络优化的目标函数如公式(1)所示:
其中,w代表网络中所有的权重;ed(w)为网络的损失函数;r(w)为应用在所有权重上的非结构化正则约束;rg(w(l))为应用在每一层上的结构化稀疏正则化约束。
2、根据权利要求1所述的一种基于稀疏双目融合卷积神经网络的立体图像质量评价方法,其特征在于,所述s1中通过神经网络中左右视图构建左右分支步骤;
2.1、分别将左右分支进行划分第一卷积层和第一池化层、第二卷积层和第二池化层、第三卷积层、第四卷积层;
2.2、左右分支中第一卷积层进行结构稀疏约束后输入第一池化层;
2.3、第一池化层输出端与第二卷积层连接,将第二卷积层进行结构稀疏约束后输入第二池化层;
2.4、第二池化层输出端与第三卷积层连接,将第三卷积层进行结构稀疏约束后输入第四卷积层;所述第四卷积层输出端连接融合分支进行融合处理。
3、根据权利要求1所述的一种基于稀疏双目融合卷积神经网络的立体图像质量评价方法,其特征在于,所述s1中通过神经网络中左右视图构建融合分支步骤;
3.1、融合分支划分为第一池化层和第一卷积层、第二池化层和第二卷积层、第三卷积层、第四卷积层和第三池化层、三层全连接层,共进行四次融合操作;
3.2、来自左右分支结构稀疏约束后的第一卷积层的特征图通过‘concat’操作进行第一次融合操作,将融合后的特征图输入到融合分支第一池化层,然后送入融合分支第一卷积层进行信息处理,同时对融合分支第一卷积层进行结构化稀疏约束;
3.3、来自左右分支结构稀疏约束后的第二卷积层的特征图与融合分支经第一次融合后的第一卷积层的特征图通过‘concat’操作进行第二次融合操作,将融合后的特征图输入到融合分支第二池化层,然后送入融合分支第二卷积层进行信息处理,同时对融合分支第二卷积层进行结构化稀疏约束;
3.4、来自左右分支结构稀疏约束后的第三卷积层的特征图与融合分支经第二次融合后的第二卷积层的特征图通过‘concat’操作进行第三次融合操作,将融合后的特征图输入到融合分支第三卷积层进行信息处理,同时对融合分支第三卷积层进行结构化稀疏约束;
3.5、来自左右分支结构稀疏约束后的第四卷积层的特征图与融合分支经第三次融合后的第三卷积层的特征图通过‘concat’操作进行第四次融合操作,将融合后的特征图输入到融合分支第四卷积层进行信息处理,同时对融合分支第四卷积层进行结构化稀疏约束;将融合后的第四卷积层送入第三池化层,然后将输出特征图送入三层全连接层进行立体图像质量的判断。
有益效果
本专利采用结构化稀疏学习ssl来优化所采用的卷积神经网络,使网络的权重结构化的稀疏,降低网络的计算复杂度,加快网络的运算速度,提升网络的评价性能,为实时的立体图像质量评价提供可能性。实验结果表明网络能够在性能有所提升的情况下达到超过2×的计算速度提升。采用卷积神经网络中的四次融合模拟人脑中的长期的双目融合过程,理论上和实验上都表明本发明所提出的模型适用于对称和非对称失真立体图像。
附图说明
图1是本发明基于稀疏双目融合卷积神经网络结构图。
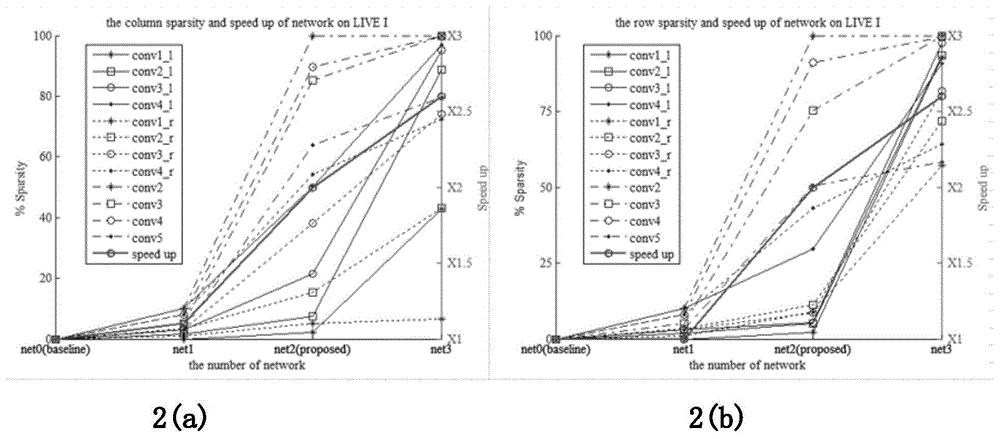
图2(a)在livei上每层卷积层的列稀疏度(columnsparsity)和网络整体加速的关系(b)
在livei上每层卷积层的行稀疏度(rowparsity)和网络整体加速的关系
具体实施方式
本发明采用公开的立体图像库live3dphasei和live3dphaseii进行实验。live3dphasei图像库包含20张原始立体图像对和365张对称失真立体图像对,失真类型包含jpeg压缩、jpeg2000压缩、高斯模糊gblur、高斯白噪声wn和快衰退ff,dmos值分布在-10到60。live3dphaseii图像库包含8张原始立体图像对和360张对称失真和非对称失真的立体图像对,其中120对为对称失真立体图像,240对为非对称失真立体图像,失真类型包含jpeg压缩、jpeg2000压缩、高斯模糊gblur、高斯白噪声wn和快衰退ff,dmos值分布在0到100。
下面结合技术方案详细说明本方法:
本发明质量评价方法模拟人脑处理立体图像的流程,采用卷积神经网络的四次concat模拟左右视点的长期融合与处理,使网络适用于对称和非对称失真立体图像。将ssl应用在网络每一卷积层,结构化稀疏约束网络滤波器个数和滤波器形状,降低网络计算复杂度,加快网络运算速度,提升网络评价性能。
具体步骤如下:
1结构化稀疏学习ssl实施方式
采用
其中,w代表网络中所有的权重。ed(w)为网络的损失函数。r(w)为应用在所有权重上的非结构化正则约束,本申请中使用l2范数。rg(w(l))为应用在每一层上的结构化稀疏正则化约束。ssl中采用grouplasso来实现结构化稀疏,grouplasso正则化能使某些分组为零。应用在权重w上的grouplasso可以表示为
在ssl方法中w(g)的分组方式可以分为按滤波器分组,按通道分组,按滤波器的形状分组和按网络的层数分组即filter-wise,channel-wise,filtershape-wise和depth-wise,表示为
2双目融合卷积神经网络的构建
本申请采用的双目融合卷积神经网络如图1所示。双目融合网络模仿人脑立体视觉处理机制,将左右视点进行长期的融合。融合网络分为三部分:左分支、右分支和融合分支。左分支和右分支中都有四个卷积层和两个池层。融合分支包含四个卷积层、三个池化层和三个全连接层。网络滤波器尺寸和滤波器个数如图1所示。为了模拟视觉皮层中左右视图的长期融合和处理,两个视点通过网络中的四次concat(如图1中的①②③④)融合四次,同时通过卷积操作实现信息的处理。实现了图像的边融合边处理,模拟了人眼的视觉机制。考虑到双目组合和双目竞争机制,需要给左右视图分配不同的权重,得到最终的融合图像[17]。本申请中通过融合网络自主学习得到左右视图的权重。同时在每个卷积层上使用ssl对滤波器和滤波器形状进行结构化稀疏约束。
双目融合网络中的卷积操作被定义为公式(3)。
fl=relu(wl*flth_input+bl)(3)
其中,wl与bl分别代表第l层卷积层的权重与偏执。fl代表第l层卷积层输出的特征图,flth_input代表第l层卷积层的输入。relu为激活函数,*代表卷积操作。
双目融合网络中的所有池化层都为最大池化。在利用反向传播算法训练网络时,通过最小化损失函数来学习卷积层、池化层与全连接层的参数。损失函数使用欧几里得函数,如公式(4)所示。
其中,yi与yi分别代表样本i的期望输出与真实输出。n代表批处理的大小。
3立体图像质量评价结果与分析
本专利的实验在公开的live3dphasei和live3dphaseii上进行。live3dphasei和live3dphaseii均包含了5种失真类型,jpeg压缩、jpeg2000压缩、高斯模糊gblur、高斯白噪声wn和快衰退ff。live3dphasei图像库包含20张原始立体图像对和365张对称失真立体图像对。live3dphaseii图像库包含8张原始立体图像对和360张对称失真和非对称失真的立体图像对,其中120对为对称失真,240对为非对称失真。本专利采用pearson相关系数(plcc)和spearman等级相关系数(srocc)作为主客观评价结果一致性的度量方法。plcc和srocc越接近于1,评价效果越好。
在表1中,我们将所提出的方法与八种立体图像质量评价方法进行了比较。将最好的结果突出显示为粗体。其中,论文[6-9]是基于稀疏表示的方法,论文[10-13]是基于深度学习的方法,我们的方法结合了稀疏和cnn。针对立体图像左右视点之间的关系,文献[5-6][11-12]首先对两个视点进行处理,然后融合左右视图的特征;在文献[7-9][13]中,首先融合两个视点,然后将融合图像作为平面图像进行处理;我们的方法对两个视点采用长期的融合,边融合边处理。从表1可以看出,本专利的网络评价效果大大优于其他方法。只有plcc在liveii上略低于m[8]。然而,但srocc和rmse在liveii上均超过了m[8]。我们的plcc和srocc在livei上均超过了0.96,在liveiii上均超过了0.95。我们的方法比稀疏表示法和深度学习法都具有更好的性能。同时无论是先融合后处理的方法还是先处理后融合的方法,我们的稀疏融合网络都超越了它们。本专利的网络在对称和非对称失真立体图像上都有很好的处理效果。
为了证明ssl对所提出的网络的影响,我们对在不同结构化稀疏强度下的网络进行了比较。net0(baseline)是不使用结构化稀疏正则化的网络。图2显示了在livei上行稀疏度、列稀疏度和网络加速之间的关系,在liveii上稀疏度和网络加速的关系和livei具有相同的趋势。我们将基准网络net0的加速设置为1,net1、net2(proposedmethod)和net3上的稀疏度逐渐增大。我们可以看到,网络越稀疏,网络加速越大。在表2中,我们比较了在不同结构化稀疏强度的网络性能。当稀疏度较低时,如net1。由于
网络的稀疏性,速度略有加快,性能略有下降。在net3中,当稀疏度较高时,性能下降的幅度大于net1。但net3的加速比net1要大很多。当稀疏度合适时,性能反而有所改善,如net2(proposedmethod)。这可能是由于网络中不重要的冗余权重被约束为0,也就是说,结构稀疏正则化有助于提高网络性能。此外,我们提出的方法的速度也有很大的提升。在livei上加速为2.0倍,在liveii上加速为2.3倍。当行稀疏度和列稀疏度较高时(如net3),网络评价效果仅降低了0.01左右,但网络有3倍左右的加速,同时net3的评价效果仍然高于大多数方法。
应当指出的是,对于本领域的普通技术人员来说,在不脱离本发明构思的前提下,还可以做出若干变形和改进,这些都属于本发明的保护范围。因此,本发明专利的保护范围应以所附权利要求为准。
参考文献
[1]l.xing,j.you,t.ebrahimianda.perkis,"assessmentofstereoscopiccrosstalkperception,"inieeetransactionsonmultimedia,vol.14,no.2,pp.326-337,april2012.
[2]m.chen,l.k.cormackanda.c.bovik,"no-referencequalityassessmentofnaturalstereopairs,"inieeetransactionsonimageprocessing,vol.22,no.9,pp.3379-3391,sept.2013.
[3]xu,xiaogang,y.zhao,andy.ding,“no-referencestereoscopicimagequalityassessmentbasedonsaliency-guidedbinocularfeatureconsolidation,”electronicslettersvol.53,no.22,pp.1468-1470,2017.
[4]j.ma,p.an,l.shenandk.li,"reduced-referencestereoscopicimagequalityassessmentusingnaturalscenestatisticsandstructuraldegradation,"inieeeaccess,vol.6,pp.2768-2780,2018.
[5]k.li,f.shao,g.jiangandm.yu,"jointstructure–texturesparsecodingforqualitypredictionofstereoscopicimages,"inelectronicsletters,vol.51,no.24,pp.1994-1995,19112015.
[6]f.shao,k.li,w.lin,g.jiangandq.dai,"learningblindqualityevaluatorforstereoscopicimagesusingjointsparserepresentation,"inieeetransactionsonmultimedia,vol.18,no.10,pp.2104-2114,oct.2016.
[7]y.lin,j.yang,w.lu,q.meng,z.lvandh.song,"qualityindexforstereoscopicimagesbyjointlyevaluatingcyclopeanamplitudeandcyclopeanphase,"inieeejournalofselectedtopicsinsignalprocessing,vol.11,no.1,pp.89-101,feb.2017.
[8]m.karimi,m.nejati,s.m.r.soroushmehr,s.samavi,n.karimiandk.najarian,"blindstereoqualityassessmentbasedonlearnedfeaturesfrombinocularcombinedimages,"inieeetransactionsonmultimedia,vol.19,no.11,pp.2475-2489,nov.2017.
[9]j.yang,p.an,j.ma,k.liandl.shen,"no-referencestereoimagequalityassessmentbylearninggradientdictionary-basedcolorvisualcharacteristics,"2018ieeeinternationalsymposiumoncircuitsandsystems(iscas),florence,2018,pp.1-5.
[10]j.yang,b.jiang,h.song,x.yang,w.luandh.liu,"no-referencestereoimagequalityassessmentformultimediaanalysistowardsinternet-of-things,"inieeeaccess,vol.6,pp.7631-7640,2018.
[11]y.dingetal.,"no-referencestereoscopicimagequalityassessmentusingconvolutionalneuralnetworkforadaptivefeatureextraction,"inieeeaccess,vol.6,pp.37595-37603,2018.
[12]lvy,yum,jianggetal.,“no-referencestereoscopicimagequalityassessmentusingbinocularself-similarityanddeepneuralnetwork,”signalprocessing:imagecommunication,vol.47,pp.346-357,2016.
[13]q.sang,t.gu,c.liandx.wu,"stereoscopicimagequalityassessmentviaconvolutionalneuralnetworks,"2017internationalsmartcitiesconference(isc2),wuxi,2017,pp.1-2.
[14]baoyuanliu,minwang,h.foroosh,m.tappenandm.penksy,"sparseconvolutionalneuralnetworks,"2015ieeeconferenceoncomputervisionandpatternrecognition(cvpr),boston,ma,2015,pp.806-814.
[15]wen,wei&wu,chunpeng&wang,yandan&chen,yiran&li,hai.(2016).learningstructuredsparsityindeepneuralnetworks.
[16]hubeldh,wieseltn,“receptivefieldsofsingleneuronesinthecat\"sstriatecortex,”thejournalofphysiology,vol.148,no.3,pp.574-591,1959.
- 还没有人留言评论。精彩留言会获得点赞!