一种基于图的泛基因组数据组织方法及其系统
1.本发明属于医疗技术领域,具体涉及为一种基于图的泛基因组数据组织方法及其系统。
背景技术:
2.生命科学、医药等领域的发展与测序技术的应用息息相关,但是由于测序技术、测序成本甚至计算成本等原因,很多基因组的研究存在很多问题,例如过于依赖参考基因组。目前,参考基因组在很多领域都占据着十分重要的地位,几乎在所有涉及基因组的研究中,人们首先要做的就是为研究物种构造参考基因组,然后基于参考基因组开展不同的后续研究,例如将该物种其他新被测序的个体数据与参考基因组比较发现差异,这种方法在人类基因组学中是寻求疾病基因起源的基础。但是基于参考基因组的方法最大的缺点就是遗漏问题,因为仅仅一条基因组显然不能包含基因组的所有信息,在如今大量物种和个体可以被广泛测序的背景下,以人类为例,如果仍采用传统参考基因组的研究方法,至少有10%的人类基因组序列信息会在参考基因组中被遗漏。
3.近年来,随着测序技术的发展使得个体基因组的组装质量不断提高,测序成本的降低也使得测序的数量在不断增多,仍以人类为例,测序样本基因组的组装质量已经可以比肩于grch38,目前已有许多可用的基因组组装结果,相信在未来这个数量还会不断增加,不只是人类,其他物种也一样,我们正在从基因组时代逐步进入种群基因组时代。种群基因组时代的到来带来了大量的基因组数据和前所未有研究机遇的同时,也为生物信息学分析方法提出了新的要求和挑战,比如,如何有效地组织大规模种群基因组数据并进行后续分析(如系统发育分析)是研究者亟待解决的问题。
4.面对大量基因组数据,基因组图作为一种有效的数据组织方式被广泛应用,但是为了后续研究,需要尽量在序列信息完整性的同时保证数据结构的有效性和简洁性,目前相关研究有很多,但是大部分数据组织比较混乱,可读性、信息完整性都比较差。
5.为了解决目前在针对大量基因组数据时,数据组织方式混乱,对序列的可读性、有效性和完整性都较差的问题,提供一种基于图的泛基因组数据组织方法及其系统。
技术实现要素:
6.为了克服背景技术中提出的问题,本发明提供一种基于图的泛基因组数据组织方法及其系统。
7.一种基于图的泛基因组数据组织方法,包括:
8.获取一组泛基因组序列数据;
9.对所述泛基因组序列数据进行构图,得到泛基因组的着色图;
10.标记并获取所述着色图单个结点的访问状态的特征,遍历所述着色图得到将所述着色图分解后的csupb数据模型、以及csupb数据模型的数据信息;
11.基于所述csupb数据模型的数据信息确定所述csupb数据模型之间的包含关系,根
据所述包含关系构建csupb结构树模型。
12.所述着色图单个结点访问状态的特征包括未访问状态,半访问状态,可访问状态和已访问状态;
13.可选的,所述未访问状态为无任何一个入点被访问;半访问状态为至少有一个入点已访问且至少有一个入点未被访问;可访问状态为所有入点已被访问,其自身处于随身可以被访问的状态;已访问状态为该节点所有入点已被访问且自身也已被访问;
14.可选的,所述遍历着色图采用类后序遍历方法;
15.可选的,所述csupb数据模型为:在着色图g=(v,e,c)中,v(g),v(e)和v(c)分别是图g的点集、边集和颜色集。对任意一个颜色集g1=(v1,e1,c1)是图g的一个子图,满足对任意一个结点ui∈v1,对两个不同的点s和t,称为《s,t,c1》一个colored superbubble;s称为的源结点,t为汇结点;
16.可选的,所述csupb数据模型的数据信息包括但不限于以下信息:源点、汇点、csupb数据模型的颜色和csupb数据模型的次序。
17.所述包含关系是基于所述csupb数据模型的颜色和csupb数据模型的次序确定;
18.可选的,csupb1,csupb2和csupb3是任意的csupb数据模型,令g1=(v1,e1,c1),g2=(v2,e2,c2)和g1=(v3,e3,c3),分别是csupb1,csupb2和csupb3包含结点所诱导的子图,如同时满足衡量标准,csupb1为csupb2的子csupb,且csupb2是csupb1的父csupb;
19.所述数据组织方法还包括:基于所述csupb结构树模型构建泛基因组坐标系;
20.可选的,所述泛基因组坐标系采用三元组的方式表示所述着色图上单个位点的位置特征;
21.可选的,所述三元组的子特征包括:数值信息,拓扑信息和颜色信息。
22.所述泛基因组坐标系采用六元组的方式表示所述着色图上单条序列的位置特征;
23.可选的,所述六元组的子特征包括:路径起始点的偏移值,路径起始结点所在的最小的csupb,路径终止点的偏移值,路径终止结点所在的最小的csupb,同时包含路径起始结点和终止结点的最小csupb,路径的颜色;所述六元组的子特征记作:startpos,startbub,endpos,endbub,pathbub,pathcolor。
24.基于所述着色图上单条序列的位置特征确定至少两个单条序列之间的相互关系;所述两个单条序列的位置特征分别为:path1:(startpos1,startbub1,endpos1,endbub1,pathbub1,pathcolor1)和path2:(startpos2,startbub2,endpos2,endbub2,pathbub2,pathcolor2),(startpos1,endpos1)和(startpos2,endpos2)无交,输出path1和path2相离;(startpos1,endpos1)和(startpos2,endpos2)相互包含,且pathcolor1和pathcolor2存在包含关系,但颜色包含关系和区间包含关系相反,输出path1和path2包含;非上述情况,输出path1和path2相交。
25.获取所述泛基因组序列数据后,进行预处理,所述预处理采用包括碱基替换、添加序列片段的方法;
26.可选的,所述碱基替换的方法是为应对所述泛基因组序列数据存在简并碱基序列时,将该碱基替换成该位点其他系列出现频率最高的碱基;
27.可选的,所述添加序列片段是在所述泛基因组序列数据的头部和尾部分别添加相
同序列片段;
28.可选的,基于所述预处理后,所述泛基因组的着色图为有向、无环、无简并碱基,且有唯一的起点和终点的图。
29.一种基于图的泛基因组数据组织方法的分析设备,所述设备包括:存储器和处理器;
30.所述存储器用于存储程序指令;
31.所述处理器用于调用程序指令,当程序指令被执行时,用于执行上述的基于图的泛基因组数据组织方法。
32.一种基于图的泛基因组数据组织方法的分析系统,包括:
33.第一处理单元,用于获取一组泛基因组序列数据,对所述泛基因组序列数据进行构图,得到泛基因组的着色图;
34.第二处理单元,用于标记并获取所述着色图单个结点的访问状态的特征,遍历所述着色图得到将所述着色图分解后的csupb数据模型、以及csupb数据模型的数据信息;
35.第三处理单元,基于所述csupb数据模型的数据信息确定所述csupb数据模型之间的包含关系,根据所述包含关系构建csupb结构树模型;
36.第四处理单元,基于所述csupb结构树模型构建泛基因组坐标系。。
37.一种计算机可读存储介质,其上存储有计算机程序,所述计算机程序被处理器执行时实现上述的基于图的泛基因组数据组织方法。
38.本技术具有以下有益效果:
39.1、本发明提出了一种新的数据组织方式,基于泛基因组的研究思路,通过构建着色图刻画大量的复杂数据,数据结构清晰明了,再通过对着色图进行分解和重组、有效解析着色图的结构信息;可以将一组泛基因组序列数据构建成一个具有唯一起始和终止结点的有向无环图。基于该图,一方面,提出了一个csupb的数据结构,它在继承superbubble特征的同时,也结合了结点来源和连锁性等样本信息。通过提出的类后序遍历策略对图进行一次遍历,就可以将整个着色图分解成一个一个有大有小的csupb。之后,再利用遍历时获得的信息,得到csupb之间的包含关系,并快速得到csupb结构树。另一方面,为了描述结点的位置信息,引入偏移值。
40.2、本发明中,还提出一种三元坐标系统来全面完整地刻画该着色图的特征和信息;
41.本技术的技术方案有效解决了目前的数据组织方式混乱,对序列的可读性、有效性和完整性都较差的问题,简洁方便。
附图说明
42.为了更清楚地说明本发明实施例中的技术方案,下面将对实施例描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的一些实施例,对于本领域技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获取其他的附图。
43.图1为本发明实施例提供的基于图的泛基因组数据组织方法示意流程图;
44.图2为本发明实施例提供的基于图的泛基因组数据组织方法的分析设备示意图;
45.图3为本发明实施例提供的基于图的泛基因组数据组织方法的分析系统示意流程图;
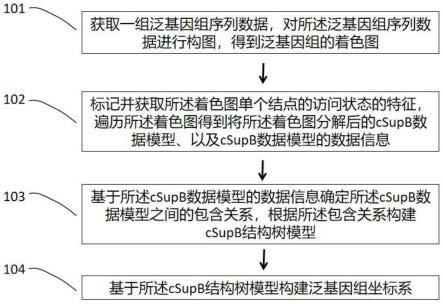
46.图4为本发明实施例提供的着色图的构建、分解和重组示意图;
具体实施方式
47.为了使本技术领域的人员更好地理解本发明方案,下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述。
48.在本发明的说明书和权利要求书及上述附图中的描述的一些流程中,包含了按照特定顺序出现的多个操作,但是应该清楚了解,这些操作可以不按照其在本文中出现的顺序来执行或并行执行,操作的序号如101、102等,仅仅是用于区分开各个不同的操作,序号本身不代表任何的执行顺序。另外,这些流程可以包括更多或更少的操作,并且这些操作可以按顺序执行或并行执行。需要说明的是,本文中的“第一”、“第二”等描述,是用于区分不同的消息、设备、模块等,不代表先后顺序,也不限定“第一”和“第二”是不同的类型。
49.下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域技术人员在没有做出创造性劳动前提下所获取的所有其他实施例,都属于本发明保护的范围。
50.图1为本发明实施例提供的一种血管内治疗的术中导航方法示意流程图,具体地,所述方法包括如下步骤:
51.101:获取一组泛基因组序列数据,对所述泛基因组序列数据进行构图,得到泛基因组的着色图;
52.在一个实施例中,获取所述泛基因组序列数据后,进行预处理,所述预处理采用包括碱基替换、添加序列片段的方法;
53.所述碱基替换的方法是为应对所述泛基因组序列数据存在简并碱基序列时,将该碱基替换成该位点其他系列出现频率最高的碱基;
54.所述添加序列片段是在所述泛基因组序列数据中每条序列的头部和尾部分别添加相同序列片段;该片段的作用将所有序列的头部和尾部分别锚到一起,而对图上其他位置的拓扑结构并不应该产生影响,即与基因组序列不会形成环结构,因此该片段在随机生成时需要判断是否适用于这组样本,并不是固定不变的,会随着样本的改变而做相应的调整。
55.基于所述预处理后,所述泛基因组的着色图为有向、无环、无简并碱基,且有唯一的起点和终点的图。每条序列都对应着色图上唯一一条从起点出发到终点结束的路径。
56.泛基因组,就是多个基因组的集合。泛基因组包括核心基因组(core genes)和非必需基因组(variable genes)。
57.路径(path):从v0到vk的一条路径是指一个序列v0,e1,v1,e2,
……
,ek,v
k,
其中ei是连接结点v
i-1
到vi的边,路径的长度是k。如果图中存在一条路径,它的起止点相同,则该路径是“闭”的,说明该图有环。
58.102:标记并获取所述着色图单个结点的访问状态的特征,遍历所述着色图得到将所述着色图分解后的csupb数据模型、以及csupb数据模型的数据信息;
59.在一个实施例中,所述着色图单个结点访问状态的特征包括未访问状态,半访问状态,可访问状态和已访问状态;
60.所述未访问状态为无任何一个入点被访问,记作-1;半访问状态为至少有一个入点已访问且至少有一个入点未被访问,记作0;可访问状态为所有入点已被访问,其自身处于随身可以被访问的状态,记作1;已访问状态为该节点所有入点已被访问且自身也已被访问,记作2;
61.所述遍历着色图采用类后序遍历方法;后序遍历的基本要求是在一个图中,访问完所有子结点后再访问父结点,类后序遍历的基本要求是,访问完所有父结点后再访问子结点,即对图中的每一个结点,只有当它所有的入点全部访问结束才可以对其自身及其出点进行访问。
62.所述csupb数据模型为:在着色图g=(v,e,c)中,v(g),v(e)和v(c)分别是图g的点集、边集和颜色集。对任意一个颜色集c1(c1c),g1=(v1,e1,c1)是图g的一个子图,满足对任意一个结点ui∈v1,对两个不同的点s和t,称为《s,t,c1》一个colored superbubble,又称csupb;如果它在g1上满足传统superbubble四个准则,可达性、匹配性、无环性和最小性,函数color来表示结点或边的颜色信息;s称为的源结点,t为汇结点;任意给定两个csupb,定义为csupb1和csupb2,令g1=(v1,e1,c1)和g2=(v2,e2,c2)分别是csupb1和csupb2包含结点所诱导的子图。那么设v0=v1∩v2,c0=c1∩c2,当或者且时,输出csupb1和csupb2分离;当且且v0≠v1(v2)时,输出csupb1和csupb2相交;当v0=v1且c0=c1,或者v0=v2且c0=c2时,输出csupb1和csupb2包含。如果两个csupb是包含关系,例如:v0=v2且c0=c2,称csupb1是csupb2的父bubble,csupb2是csupb1的子bubble。
63.supb的数据模型为:在组装图g=(v,e)中,v(g),v(e)分别是图g的点集和边集。对任意两个不同的点s和t,《s,t,》称为一个superbubble;如果上述superbubble满足以下四个准则:可达性、匹配性、无环性和最小性;可达性记作reachability:存在一条从点到达点的路径;匹配性记作matching:从点出发不经过点可以到达的点集,和不经过点的可以到达点的点集相同;无环性记作acyclicity:满足匹配性的点集所诱导的子图是无环的;最小性记作minimality:在点集u中,除了点t外没有其他点能与点s形成一个能够满足以上三条准则的对;s称为的源结点,t为汇结点;在此,只考虑至少包含两个supernode的superbubble。
64.如图4所示,图4ahaplotype为单模标本,为三条初始序列;基于supb的数据模型,在图4b中只有两个superbubble:《tat,acc》和《tca,gta》;图4b为着色图,k=3,每一个圆表示一个结点,黑色的箭头表示边。结点上方的字符依次表示结点的碱基、访问次序和颜色,最下方的数字表示每一个结点的理论偏移值;图4c为逆边方向访问图的结果;结点下方的数字分别表示最终和初始偏移值;图4d为csupb结构树。这里找到了5个csupb,依次是bub1.《tat,acc,111》;bub2.《ggg,gta,110》;bub3.《cac,gta,011》;bub4.《tca,ggg,110》;和bub5.《tca,gta,111》;图4e为着色图最终的分解和表示。
65.所述csupb数据模型的数据信息包括但不限于以下信息:源点、汇点、csupb数据模型的颜色和csupb数据模型的次序。
66.csupb数据模型的匹配原则:源(汇)结点的相邻出(入)边的颜色不相交;汇(源)结
点的相邻入(出)边颜色的并与每个相邻源(汇)结点的出(入)边颜色的交不为空;csupb颜色是源结点和汇结点颜色的交。
67.匹配流程:在类后序遍历中,如果遇到一个源结点s,就把它放到一个待访问的源结点队列q中;如果遇到一个汇结点t,就开始根据匹配原则从q中反向找到它匹配的源结点s。特别地,如果是则从q中删除s并继续;如果是则停止匹配。
68.入点(incoming node)/入边(incoming edge):任意给定两个结点u,v,称u是v的入点,当且仅当至少存在一条从u到v的路径,而且该路径上所有的边称为v的入边,v相邻入边的个数称为v的入度(indegree)。
69.出点(outgoing node)/出边(outgoing edge):同时,v也称为u的出点,路径上所有的边称为u的出边,u相邻出边的个数称为u的出度(outdegree)。
70.度(degree):结点入度和出度的和称为结点的度。
71.supernode:如果一个结点的出度或入度至少有一个大于1,那么该结点称为supernode。
72.branch:在本文中,一条路径v0,e1,v1,e2,
……
,ek,vk称为branch,如果该路径上所有结点的出度和入度都等于1且v0的前一个结点和vk的后一个结点都是supernode。
73.桥(bridge):在本文中,一条branch称为桥,如果该branch上任意一个点或边被删除,图的连通块数都会增加。
74.泡(bubble):由于序列差异导致路径图上先分岔后汇合,形成的类似于泡的结构称为bubble,详见supb的数据模型。
75.103:基于所述csupb数据模型的数据信息确定所述csupb数据模型之间的包含关系,根据所述包含关系构建csupb结构树模型。
76.在一个实施例中,类后序遍历得到所有的csupb数据模型,已知的信息有源/汇点、csupb颜色和csupb次序等信息,次序表示获得csupb的次序。为了更好地研究上述csupb数据模型,需要先确定csupb数据模型之间的包含关系,进而得到csupb层次结构树,显然结构树可能不止一棵。根据结构树的层次,为每一个csupb赋予一个level值。首先确定根csupb,将包含所有样本的csupb设为根csupb,其level为1。再根据嵌套层次给每一个csupb赋予一个level值。在本实施例中,csupb即为csupb数据模型。
77.基于所述csupb数据模型的颜色和csupb数据模型的次序确定包含关系;基本准则是,csupb1,csupb2和csupb3是任意的csupb数据模型,令g1=(v1,e1,c1),g2=(v2,e2,c2)和g3=(v3,e3,c3),分别是csupb1,csupb2和csupb3包含结点所诱导的子图,如同时满足以下三个条件,a.order(g1)<order(g2);b.且c1≠c0(c0是包括所有样本的颜色集);c.不存在csupb3,使得order(g1)<order(g3)<order(g2)且称csupb1为csupb2的子csupb,且csupb2是csupb1最近的父csupb。
78.104:基于所述csupb结构树模型构建泛基因组坐标系。
79.在线性参考基因组坐标系统中,仅用一个正整数a就可以唯一表示位点的位置信息,用一个二元组(a,b)就可以唯一表示序列的位置信息,而且还可以通过分析序列间的位置关系来讨论序列间的生物学关系。但显然,上述表示方法不适用于基因组图,这里,基于前面构建的csupb树模型,构建了一个单倍型泛基因组坐标系。
80.具体的,所述泛基因组坐标系采用三元组的方式表示所述着色图上单个位点的位置(base location;bl);
81.可选的,所述三元组的子特征包括:数值信息,拓扑信息和颜色信息;三元组的子特征英文记作:position,bubid,basecolor。由于在任意一个csupb中,其包含的每一个样本都有且只有一条路径,因此这种表示方法和图中每一个位点一一对应。其中,position表示位点对应结点的偏移值,bubid表示该位点所在的最小csupb,basecolor表示该位点的颜色,有两种表示方式,一种是和bubcolor一样用由0,1组成的字符串表示,另一种是随机选择一个该位点所在的样本id来表示,前者更全面,后者更简单,可以根据不同用途进行选择。在此三元组中,position,bubid和basecolor分别表示数值信息,拓扑信息和颜色信息。
82.可选的,所述泛基因组坐标系采用六元组的方式表示所述着色图上单条序列的位置(base location;bl);
83.可选的,所述六元组的子特征包括:路径起始点的偏移值,路径起始结点所在的最小的csupb,路径终止点的偏移值,路径终止结点所在的最小的csupb,同时包含路径起始结点和终止结点的最小csupb,路径的颜色;所述六元组的子特征格式为:(startpos,startbub,endpos,endbub,pathbub,pathcolor)。其中,startpos和endpos分别表示路径起始点和终止点的偏移值,startbub和endbub分别表示路径起始结点和终止结点所在的最小的csupb。pathbub表示同时包含路径起始结点和终止结点的最小csupb,显然startbub和endbub都是pathbub的子csupb,如果pathbub不存在,即路径跨越了根结点,如果设它跨越的根csupb数目是n,则pathbub记为-n,pathcolor表示这段路径的颜色,表示方式是由0,1组成的长度等于样本数的字符串。特别地,当path长度等于1时,此时路径就是一个位点,startpos=endpos,startbub=endbub=pathbub且pathcolor=basecolor,此时路径的六元组变成了位点的三元组。
84.基于所述着色图上单条序列的位置特征确定至少两个单条序列之间的相互关系。在线性坐标系中,如果给定两个区间,可以给出相离、相交和包含三种相互关系,类似地,在基因组图上,也可以给出两条路径的相互关系。所述两个单条序列的位置特征分别为:path1:(a1,bub1,b1,bub2,bub3,color1)和path2:(a2,bub4,b2,bub5,bub6,color2),分析[a1,b1]和[a2,b2]无交,输出path1和path2相离;[a1,b1]和[a2,b2]相互包含,且color1和color2存在包含关系,但颜色包含关系和区间包含关系相反,输出path1和path2包含;非上述情况,输出path1和path2相交。startpos用a表示,endpos用b表示。
[0085]
特别的,如果[a1,b1]和[a2,b2]存在交集,且color1和color2无交,基于上述关系得到path1和path2是相交关系,此时可以进行序列相似性分析。根据csupb结构树模型,寻找bub3和bub6共同的最近父csupb,bub7及其颜色color3。如果bub7不存在,说明路径跨越了根结点,此时同时包含path1和path2的区域是由一个或多个根csupb和一条或多条桥组成的,此时color3包含所有样本;如果bub7存在,则可以在该bub7内进行相似性分析,此时color1和color2的并集是color3的一个子集。如图4所示,随机选取部分结点指定碱基位置,例如:tca:(3,4,111),atg:(13,1,100),ccc:(17,-1,111)和ggg:(7,2,110)。随机选取三条路径:a.cagggtgta-》(5,4,11,2,5,100);b.gggagta-》(7,2,11,2,2,010);c.taaccc-》(13,1,17,-1,-1,011)。这里路径a和路径b相交,路径a(b)和路径c相离。
[0086]
基于基因组图坐标系,可以实现更多的功能。例如:如果给定一个基因组注释文件
access memory)、磁盘或光盘等。
[0101]
本领域普通技术人员可以理解实现上述实施例方法中的全部或部分步骤是可以通过程序来指令相关的硬件完成,所述的程序可以存储于一种计算机可读存储介质中,上述提到的存储介质可以是只读存储器,磁盘或光盘等。
[0102]
以上对本发明所提供的一种计算机设备进行了详细介绍,对于本领域的一般技术人员,依据本发明实施例的思想,在具体实施方式及应用范围上均会有改变之处,综上所述,本说明书内容不应理解为对本发明的限制。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1