虚拟对象显示方法、装置、电子设备及存储介质与流程
本发明涉及计算机技术领域,特别涉及一种虚拟对象显示方法、装置、电子设备及存储介质。
背景技术:
随着计算机技术的发展和终端功能的多样化,在终端上能够进行的游戏种类越来越多,在一些电子游戏中,需要在图形用户界面中显示多个虚拟对象,在对虚拟对象进行显示时,可以对虚拟对象的由动画驱动的骨骼模型进行显示。对于任一帧,通常需要确定该虚拟对象的骨骼模型中每个骨骼的位姿数据,来确定该虚拟对象在该任一帧中的姿态。
目前,虚拟对象显示方法通常是:对于多个虚拟对象中任一个虚拟对象,通过中央处理器,获取该虚拟对象对应的多个动画帧,再通过中央处理器,对该虚拟对象对应的多个动画帧进行融合,得到当前帧中该虚拟对象的骨骼模型中每个骨骼的位姿数据,通过图像处理器,对该虚拟对象进行显示。每处理结束一个虚拟对象,即可继续处理下一个虚拟对象,直至对该多个虚拟对象均处理结束。
上述虚拟对象显示方法采用了由中央处理器逐个确定多个虚拟对象的骨骼模型中每个骨骼的位姿数据的串行处理方式,对多个动画帧进行融合的步骤耗时较长,随着虚拟对象的数量的增加,中央处理器对多个虚拟对象的处理时间则大幅度增加,从而可能出现中央处理器过载的问题,上述虚拟对象显示方法的显示效率低,显示效果差。
技术实现要素:
本发明实施例提供了一种虚拟对象显示方法、装置、电子设备及存储介质,可以解决相关技术中中央处理器过载、显示效率低和显示效果差的问题。所述技术方案如下:
一方面,提供了一种虚拟对象显示方法,所述方法包括:
获取多个虚拟对象中每个虚拟对象对应的多个动画帧和每个动画帧的权重,所述每个动画帧包括虚拟对象的骨骼模型中每个骨骼的位姿数据;
通过图像处理器,按照所述每个动画帧的权重,并行对所述多个虚拟对象对应的多个动画帧进行融合,得到所述多个虚拟对象的骨骼模型中每个骨骼的目标位姿数据;
根据所述多个虚拟对象的骨骼模型中每个骨骼的目标位姿数据,在图形用户界面中显示所述多个虚拟对象。
一方面,提供了一种虚拟对象显示装置,所述装置包括:
获取模块,用于获取多个虚拟对象中每个虚拟对象对应的多个动画帧和每个动画帧的权重,所述每个动画帧包括虚拟对象的骨骼模型中每个骨骼的位姿数据;
融合模块,用于通过图像处理器,按照所述每个动画帧的权重,并行对所述多个虚拟对象对应的多个动画帧进行融合,得到所述多个虚拟对象的骨骼模型中每个骨骼的目标位姿数据;
显示模块,用于根据所述多个虚拟对象的骨骼模型中每个骨骼的目标位姿数据,在图形用户界面中显示所述多个虚拟对象。
一方面,提供了一种电子设备,所述电子设备包括一个或多个处理器和一个或多个存储器,所述一个或多个存储器中存储有至少一条指令,所述指令由所述一个或多个处理器加载并执行以实现所述虚拟对象显示方法所执行的操作。
一方面,提供了一种计算机可读存储介质,所述计算机可读存储介质中存储有至少一条指令,所述指令由处理器加载并执行以实现所述虚拟对象显示方法所执行的操作。
本发明实施例通过获取多个虚拟对象对应的多个动画帧和权重,通过图像处理器并行对该多个虚拟对象进行动画帧融合,得到每个虚拟对象的骨骼模型中每个骨骼的目标位姿数据,从而将其作为显示多个虚拟对象的依据,对多个虚拟对象进行显示,该过程中通过图像处理器并行对多个虚拟对象进行动画帧融合,而无需由中央处理器逐个获取动画帧和权重、动画帧融合和显示,可以有效减少中央处理器的处理负担,避免出现中央处理器过载的问题,可以大幅度提高处理效率,进而提高该虚拟对象显示过程的显示效率,也提高了该虚拟对象的显示效果。
附图说明
为了更清楚地说明本发明实施例中的技术方案,下面将对实施例描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图。
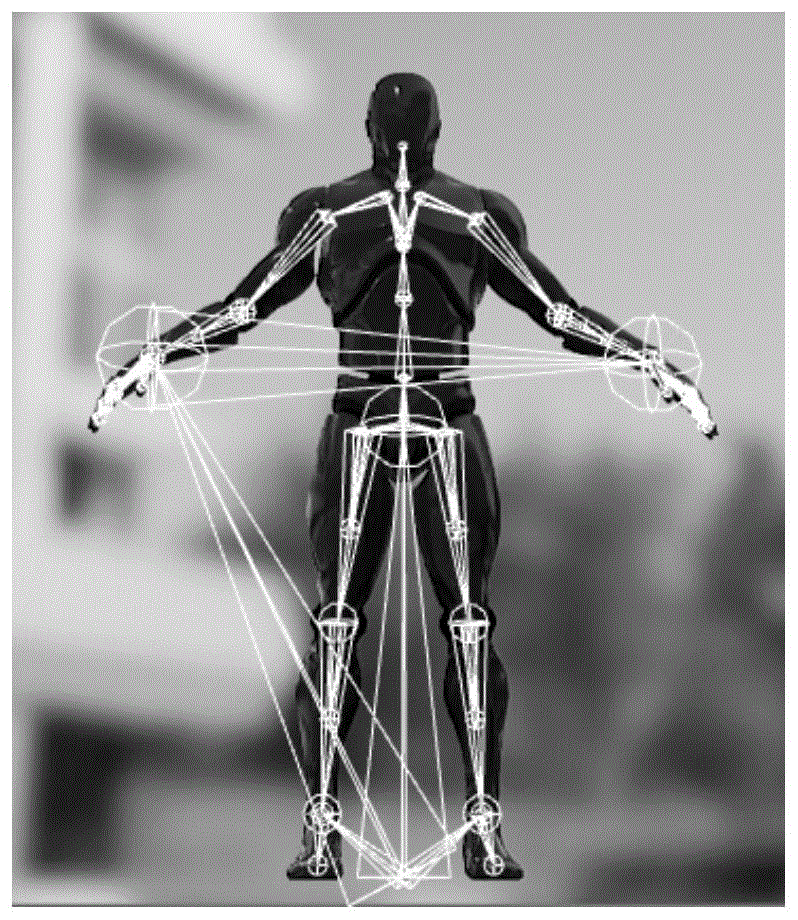
图1是本发明实施例提供的一种虚拟对象显示的示意图;
图2是本发明实施例提供的一种虚拟对象显示方法的流程图;
图3是本发明实施例提供的一种动画树的示意图;
图4是本发明实施例提供的一种动画树的示意图;
图5是本发明实施例提供的一种第二贴图的获取过程的示意图;
图6是本发明实施例提供的一种从第二贴图中获取多个动画帧的过程的示意图;
图7是本发明实施例提供的一种多个骨骼的示意图;
图8是本发明实施例提供的一种动画帧融合过程的示意图;
图9是本发明实施例提供的一种动画帧和权重写入缓冲区的过程的示意图;
图10是本发明实施例提供的一种多个虚拟对象的显示过程的示意图;
图11是本发明实施例提供的一种虚拟对象显示方法的流程图;
图12是本发明实施例提供的一种多个虚拟对象的显示示意图;
图13是本发明实施例提供的一种虚拟对象显示装置的结构示意图;
图14是本发明实施例提供的一种电子设备的结构示意图。
具体实施方式
为使本发明的目的、技术方案和优点更加清楚,下面将结合附图对本发明实施方式作进一步地详细描述。
本发明实施例主要涉及电子游戏或者模拟训练场景,以电子游戏场景为例,用户可以提前在该终端上进行操作,该终端检测到用户的操作后,可以下载电子游戏的游戏配置文件,该游戏配置文件可以包括该电子游戏的应用程序、界面显示数据或虚拟场景数据等,以使得该用户在该终端上登录电子游戏时可以调用该游戏配置文件,对电子游戏界面进行渲染显示。用户可以在终端上进行触控操作,该终端检测到触控操作后,可以确定该触控操作所对应的游戏数据,并对该游戏数据进行渲染显示,该游戏数据可以包括虚拟场景数据、该虚拟场景中虚拟对象的行为数据等。
本发明涉及到的虚拟场景可以用于模拟一个三维虚拟空间,也可以用于模拟一个二维虚拟空间,该三维虚拟空间或二维虚拟空间可以是一个开放空间。该虚拟场景可以用于模拟现实中的真实环境,例如,该虚拟场景中可以包括天空、陆地、海洋等,该陆地可以包括沙漠、城市等环境元素,用户可以控制虚拟对象在该虚拟场景中进行移动,该虚拟对象可以是该虚拟场景中的一个虚拟的用于代表用户的虚拟形象,也可以是该虚拟场景中的一个虚拟的用于代表与用户交互的角色的虚拟形象。该虚拟形象可以是任一种形态,例如,人、动物等,本发明对此不限定。该虚拟场景中可以包括多个虚拟对象,每个虚拟对象在虚拟场景中具有自身的形状和体积,占据虚拟场景中的一部分空间。
以射击类游戏为例,用户可以控制虚拟对象在该虚拟场景的天空中自由下落、滑翔或者打开降落伞进行下落等,在陆地上中跑动、跳动、爬行、弯腰前行等,也可以控制虚拟对象在海洋中游泳、漂浮或者下潜等,当然,用户也可以控制虚拟对象乘坐载具在该虚拟场景中进行移动,在此仅以上述场景进行举例说明,本发明实施例对此不作具体限定。用户也可以控制虚拟对象通过兵器与其他虚拟对象进行战斗,该兵器可以是冷兵器,也可以是热兵器,本发明对此不作具体限定。当然,还可以为其他种类的电子游戏中的场景,例如,角色扮演类游戏等,或可以为其他模拟场景,本发明实施例提供的方法的应用场景并不限定。例如,如图1所示,终端可以在虚拟场景中显示多个虚拟对象。
骨骼动画:模型动画的一种,指一系列类似生物骨骼层级关系的矩阵列,骨骼动画中每一个动画帧存储有每一个骨骼的位置和旋转等信息,即这一个骨骼在这一个动画帧中的位姿,连续一段时间内的多个动画帧则形成了每一个骨骼在这段时间内的运动数据,从而使用骨骼动画可以实时驱动骨骼模型。
骨骼模型:一般指由骨骼动画驱动的角色模型,和一般的静态物件不同,骨骼模型每帧对应有骨骼动画,该骨骼动画显示的效果可以为虚拟对象做出相应动作的效果,具体绘制时可以通过采样动画数据做顶点的蒙皮,也即是采样骨骼模型中每个骨骼的位姿数据做顶点的蒙皮。
蒙皮(skinning):指在角色渲染时将角色模型每一个顶点按照它对应的所有骨骼按权重进行加权变形顶点,从而达到骨骼的姿势驱动最后渲染的角色模型。在当代游戏引擎中,蒙皮可以每帧在cpu执行,也可以每帧在gpu的顶点着色器执行,后者效率更高。
例如,虚拟对象的骨骼模型的骨架可以如图1所示,终端在对虚拟对象进行显示时可以先确定该虚拟对象的骨骼模型中每个骨骼的位姿数据,再基于该位姿数据,对该虚拟对象进行显示。
绘制命令(drawcall):在图形显示中由cpu发送至gpu,通过该绘制命令,cpu可以通知gpu在哪些位置以什么参数绘制哪个模型。可以理解地,每帧从cpu发送到gpu的drawcall个数越少,处理效率越高。
实例化(instancing):在图形显示中指一种调用drawcall的方式。如果拓扑相同的骨骼模型在一帧中需要显示多个,可以通过一次instancing的方式调用drawcall,以通知gpu这个骨骼模型本次绘制多少个,并且每个骨骼模型绘制在什么位置。
图2是本发明实施例提供的虚拟对象显示方法的流程图,该虚拟对象显示方法应用于电子设备中,该电子设备可以被提供为终端,也可以被提供为服务器,本发明实施例对此不作限定,下述仅以该电子设备被提供为终端为例进行说明。参见图2,该方法可以包括以下步骤:
201、终端获取多个虚拟对象的位姿指示数据。
在本发明实施例中,终端可以在图形用户界面中显示多个虚拟对象,该多个虚拟对象的骨骼模型的拓扑可以相同或类似。终端在对每个虚拟对象进行显示时可以先确定该虚拟对象的目标姿态,也即是显示形态,该目标姿态可以通过该虚拟对象的骨骼模型中每个骨骼的目标位姿数据来确定,再执行显示步骤。其中,位姿数据可以包括位置数据和姿态数据。也即是,终端可以先确定该虚拟对象的目标显示情况,再根据该目标显示情况对其进行显示。例如,该每个骨骼的目标位姿数据可以为每个骨骼的位置数据和旋转数据等。
具体地,该终端可以获取多个虚拟对象的位姿指示数据,基于该位姿指示数据来确定该多个虚拟对象的目标位姿数据。其中,位姿指示数据用于确定虚拟对象的骨骼模型中每个骨骼的目标位姿数据。该位姿指示数据是指会对虚拟对象的骨骼模型中每个骨骼的目标位姿数据产生影响的数据。
例如,在一个具体示例中,以电子游戏场景为例,虚拟对象的运动速度不同时,该虚拟对象需要显示的运动姿态则可以不同,则该虚拟对象的运动速度即可作为一项位姿指示数据。又例如,在一个具体示例中,以电子游戏场景为例,用户对虚拟对象进行的控制操作不同时,该虚拟对象需要作出的动作可能不同,则可以将检测到的控制操作作为一项位姿指示数据。在该示例中,该位姿指示数据可以理解为角色行为逻辑数据,该角色是指虚拟对象,行为逻辑数据即是指用来确定该角色的行为的数据。
上述仅为两种具体示例来对该位姿指示数据进行示例性说明,该位姿指示数据具体包括哪些类型的数据可以由相关技术人员根据需求进行设置,本发明实施例对该位姿指示数据的数据类型不作限定。
在一个具体示例中,终端可以实时获取多个虚拟对象的位姿指示数据,以确定该多个虚拟对象的目标位姿数据,进而对该多个虚拟对象进行显示。例如,终端可以获取当前多个虚拟对象的位姿指示数据,确定下一帧该多个虚拟对象的骨骼模型中每个骨骼的目标位姿数据,从而按照该多个虚拟对象的骨骼模型中每个骨骼的目标位姿数据,来显示该下一帧,每一帧均遵循上述确定目标位姿数据和显示的逻辑,从而实现对该多个虚拟对象的动画显示效果。
202、终端基于每个虚拟对象的位姿指示数据,对动画树进行遍历,得到该每个虚拟对象的遍历结果,该动画树的叶结点关联有动画帧。
终端获取到该多个虚拟对象的位姿指示数据后,可以根据每个虚拟对象的位姿指示数据,进一步确定该每个虚拟对象的骨骼模型中每个骨骼的目标位姿数据。位姿指示数据可以包括多种类型的数据,该数据的类型不同时,该虚拟对象可能会做出不同的动作,也即是,根据该位姿指示数据,可能会确定出该虚拟对象的多个动画帧。
例如,对于一个虚拟对象,该虚拟对象的位姿指示数据中的某一项位姿指示数据可能指示虚拟对象做出奔跑的姿势,另一项位姿指示数据可能指示虚拟对象转身,还可能有一项位姿指示数据指示虚拟对象举起虚拟道具。此外,该虚拟对象的位姿指示数据中的多项位姿指示数据还可能会分别指示虚拟对象的手腕和手肘呈现30度和60度。在确定该虚拟对象的目标位姿数据时则需要综合考虑该这些情况。
终端可以根据每个虚拟对象的位姿指示数据,获取虚拟对象对应的多个动画帧,该获取过程可以基于动画树来实现。其中,该动画树的叶结点关联有动画帧。终端可以根据该每个虚拟对象的位姿指示数据,来对该动画树进行遍历,从而基于该动画树的判定逻辑,得到该每个虚拟对象的遍历结果,该遍历结果即为该每个虚拟对象的位姿指示数据符合该动画树的哪几个的叶结点,从而确定该位姿指示数据对应哪几个动画帧。
该动画树的所有叶结点可以关联有虚拟对象对应的所有动画帧,每次确定虚拟对象的骨骼模型中每个骨骼的目标位姿数据时,即可来判断该虚拟对象的位姿指示数据落在哪几个叶结点上。在一种可能实现方式中,该动画树可以包括根(root)结点和资源播放(assetplayer)结点,也可以包括root结点、融合(blend)结点和assetplayer结点。root结点为一个动画树的起始结点,在此还可以将其称为animnode_root,其中,anim为生动的意思,blend结点一般为动画树中间的融合结点,具体如何融合可以根据配置,在对结点进行更新时根据位姿指示数据进行判断,assetplayer结点为资源播放结点,它是指动画树的叶结点,且与动画帧相关联。该动画帧是指动画资源。在一个具体的可能实施例中,该动画树可以为虚拟引擎(unrealengine,ue)4中的蓝图编辑器,ue4引擎为一种游戏引擎。在该图3中,anim是指生动的,root是指根,初始,asset是指资源,player是指播放,blend是指融合,sequence是指序列,finalanimationpose是指最终的动画姿态,result是指结果。
在对虚拟对象进行显示时每帧均可以输入位姿指示数据,对该动画帧进行遍历,选出该帧需要进行融合的动画帧。例如,如图3所示,动画树包括root结点和assetplayer结点,动画树的root结点下直接挂上一个assetplayer结点,也即是,该虚拟对象只对应有一个动画帧,每一帧虚拟对象的显示均按照该动画帧进行动画播放,以呈现出虚拟对象做出固定动作的现象。又例如,如图4所示,动画树包括root结点、blend结点和assetplayer结点。终端可以根据位姿指示数据,从多个叶节点中进行选择,例如,可以根据该虚拟对象的速度数据在静止(idle),走(walk),跑(run)和冲刺(sprint)几个动画帧中进行选择。再多一些层次,则可以从多个叶节点中确定出多个动画帧以及每个动画帧的权重,也即是下述步骤203所示的内容。
203、终端根据该多个虚拟对象对应的多个遍历结果,获取多个虚拟对象中每个虚拟对象对应的多个动画帧和每个动画帧的权重。
其中,该每个动画帧包括虚拟对象的骨骼模型中每个骨骼的位姿数据。
通过上述步骤202,终端可以得到每个虚拟对象的遍历结果,该遍历结果即为该每个虚拟对象的位姿指示数据符合该动画树的哪几个的叶结点,也即是指该虚拟对象对应的多个叶节点,进而终端可以根据该每个虚拟对象的遍历结果,获取该每个虚拟对象对应的多个动画帧和每个动画帧的权重。
这样通过该步骤203,对于每个虚拟对象,终端确定该每个虚拟对象对应的需要融合的多个动画帧以及权重,以便于后续对每个虚拟对象对应的多个动画帧进行融合,以确定每个虚拟对象的骨骼模型中每个骨骼的目标位姿数据,这样最终显示时每个虚拟对象的姿态或显示形态也即满足该目标位姿数据。
在一种可能实现方式中,在启动虚拟对象显示功能时,可以先进行初始化,再执行本发明实施例提供的虚拟对象显示方法的步骤。例如,在电子游戏场景中,在电子游戏运行时,终端可以进行初始化,写入待获取的数据,从而后续可以基于判断步骤,从待获取的数据中选择一些数据进行获取。在本发明实施例中,该待获取的数据可以为贴图的形式,后续终端还可以基于对多个动画帧进行融合得到多个虚拟对象的骨骼模型中各个骨骼的目标位姿数据后,将其存储于一个贴图中,在此称之后存储多个虚拟对象的骨骼模型中各个骨骼的目标位姿数据的贴图为第一贴图,称存储所有待获取的动画帧的贴图为第二贴图。
具体地,终端可以遍历该动画树,得到该动画树的所有叶结点所关联的动画帧,将该所有叶结点所关联的动画帧存储于第二贴图中。在该终端中可以存储有该动画树,例如,该动画树可以为ue4引擎的蓝图编辑器,终端可以先启动该蓝图编辑器,获取该所有叶结点所关联的动画帧,将其存入第二贴图中,从而将该第二贴图作为数据基础,每次对动画树遍历得到每个虚拟对象的遍历结果后,可以从该第二贴图中获取需要融合的多个动画帧。例如,如图5所示,终端可以遍历左图所示的动画树,可以得到右图所示的第二贴图。该动画树仅为一种示例,对其实际结构不构成限定。
相应地,该步骤203中,终端可以根据该多个虚拟对象对应的多个遍历结果,从该第二贴图中获取该多个虚拟对象对应的多个动画帧和每个动画帧的权重。具体地,对于每个虚拟对象的遍历结果,终端可以根据该遍历结果中的多个叶结点的标识信息,获取该多个叶结点的标识信息所关联的多个动画帧的标识信息,从而根据该多个动画帧的标识信息,从第二贴图中获取该多个动画帧,再基于该遍历结果,获取该多个动画帧中每个动画帧的权重。
在一种可能实现方式中,每个动画帧均可以以矩阵的方式存在,也即是,每个动画帧均可以为第一骨骼动画矩阵,该第二贴图同理,第二贴图可以为包括有所有动画帧的第二骨骼动画矩阵。该第二骨骼动画矩阵可以基于该第一骨骼动画矩阵得到,例如,该第二骨骼动画矩阵的每一列可以为一个动画帧的数据。每一列可以对应一个动画帧的标识信息,终端可以根据多个动画帧的标识信息,从第二贴图中多个标识信息对应的列中提取该多个动画帧。例如,如图6所示,终端可以从第二贴图的骨骼动画矩阵中提取多个列的动画帧,以进行后续的动画帧融合步骤。
需要说明的是,该步骤201至步骤203为获取多个虚拟对象中每个虚拟对象对应的多个动画帧和每个动画帧的权重的过程,在该过程中,对于每个虚拟对象,每次确定虚拟对象的骨骼模型中每个骨骼的目标位姿数据时,即可来判断该虚拟对象的位姿指示数据落在哪几个叶结点上,进而将这几个叶结点所关联的多个动画帧确定为该位姿指示数据符合的多个动画帧,从而在后续可以对这些动画帧进行融合,以得到该虚拟对象的骨骼模型中每个骨骼的目标位姿数据。
在一种可能实现方式中,终端可以通过中央处理器(centralprocessingunit,cpu)中的多个任务线程,执行该获取多个虚拟对象中每个虚拟对象对应的多个动画帧和每个动画帧的权重的步骤。这样通过多线程的方式可以节省cpu获取多个虚拟对象对应的多个动画帧以及权重所需花费的时间和开销,提高了该多个虚拟对象对应的多个动画帧以及权重的获取效率,且可以不占用主线程,使得主线程的开销为零,从而有效提高该获取过程的效率。
204、终端通过图像处理器,按照该每个动画帧的权重,并行对该多个虚拟对象对应的多个动画帧进行融合,得到该多个虚拟对象的骨骼模型中每个骨骼的目标位姿数据。
终端确定了多个虚拟对象中每个虚拟对象对应的多个动画帧以及权重后,可以对每个虚拟对象对应的多个动画帧进行融合,以确定每个虚拟对象的骨骼模型中每个骨骼的目标位姿数据。
相关技术中,该过程通常是由cpu的一个线程来获取一个虚拟对象对应的多个动画帧,并基于该线程继续对该多个动画帧进行融合。对该虚拟对象的处理过程结束后,才会对下一个虚拟对象进行同理的处理,而本发明实施例中,可以通过图像处理器来完成动画帧融合的步骤,且由于该图像处理器的核心数目多,可以支持高并发性的处理任务,在对该多个虚拟对象对应的多个动画帧进行融合时可以并行实现,这样无需串行确定该多个虚拟对象的骨骼模型中每个骨骼的目标位姿数据,可以大幅度提高对该多个虚拟对象的处理效率,进而提高该虚拟对象显示过程的显示效率。
具体地,终端进行动画帧融合的过程可以为:对于该多个虚拟对象中每个虚拟对象,终端按照该每个虚拟对象对应的多个动画帧的权重,对该每个虚拟对象对应的多个动画帧中骨骼模型中各个骨骼的位姿数据进行加权,得到该每个虚拟对象的骨骼模型中每个骨骼的目标位姿数据。
例如,该各个骨骼的位姿数据可以包括该各个骨骼的位置数据和旋转数据,对于每个虚拟对象的骨骼模型中每一个骨骼,终端可以将该每个虚拟对象对应的多个动画帧中该骨骼的位置数据和旋转数据进行加权,得到该每个虚拟对象的骨骼模型中该骨骼的位置数据和旋转。
在一个具体示例中,对于每个虚拟对象的骨骼模型中每一个骨骼,终端可以按照该每个虚拟对象对应的多个动画帧的权重,对该每个虚拟对象对应的多个动画帧中该骨骼在骨骼坐标下的坐标进行加权,得到该每个虚拟对象的骨骼模型中该骨骼在骨骼坐标系下的坐标,将该每个虚拟对象的骨骼模型中该骨骼在骨骼坐标系下的坐标转换为骨骼模型坐标系下的坐标,以便于后续蒙皮并显示。终端还可以再基于该虚拟对象在虚拟场景中的位置信息,将骨骼模型坐标系下的坐标转换为世界坐标系下的坐标,从而将该世界坐标系下的坐标作为该骨骼的目标位姿数据,从而可以对各个虚拟对象进行显示时可以体现出其在虚拟场景中的位置以及姿态。在一种可能实现方式中,终端可以通过一个计算机着色器(computershader)进行动画帧融合,通过另一个computershader进行坐标转换。
如图7所示,以第一骨骼(b1)和第二骨骼(b2),该虚拟对象对应的多个动画帧的数量为2(第一动画帧a1和第二动画帧a2)为例进行说明,第一动画帧中第一骨骼的位姿数据可以为a1b1,第二动画帧中第一骨骼的位姿数据可以为a2b1,第一动画帧中第二骨骼的位姿数据可以为a1b2,第二动画帧中第二骨骼的位姿数据可以为a2b2。假设两个动画帧的权重均为0.5,则如图8所示,对该两个动画帧进行融合后的结果,也即是第一骨骼和第二骨骼的目标位姿数据(rb1和rb2)可以分别为rb1=0.5*a1b1+0.5*a2b1和rb2=0.5*a1b2+0.5*a2b2。需要说明的是,该rb1和rb2为骨骼坐标系下的坐标,终端还可以进行坐标转换,将其转换为骨骼模型坐标系下的坐标(sb1和sb2),sb1=rb1=0.5*a1b1+0.5*a2b1,sb2=rb1*rbn=(0.5*a1b2+0.5*a2b2)*(0.5*a1b1+0.5*a2b1),上述仅以两个骨骼为例,将其推广至n个骨骼时,sbn=(w1*a1bn+w2*a2bn+…wm*ambn)*…*(w1*a1b2+w2*a2b2+…wm*amb2)*(w1*a1b1+w2*a2b1+…wm*amb1)。其中,b1-b2-…bn为n个骨骼,a1,a2,…,am为m个动画帧,w1,w2,…,wm为m个动画帧各自的权重,n和m均为正整数。*用于表示旋转数据进行四元数相乘,位置数据进行矩阵相乘。在将该骨骼模型坐标系下的坐标转换为世界坐标系下的坐标时需要考虑到该骨骼模型在世界坐标下的坐标,在此不对其做过多赘述。
在一种可能实现方式中,该终端对该多个虚拟对象进行动画帧融合时可以通过多个并行通道进行,具体地,终端可以根据该多个虚拟对象的数量,通过该图像处理器的多个并行通道,按照该每个动画帧的权重,并行对该多个虚拟对象对应的多个动画帧进行融合,得到该多个虚拟对象的骨骼模型中每个骨骼的目标位姿数据,每个并行通道用于对一个虚拟对象对应的多个动画帧进行融合。正是由于gpu的核心数目较多,支持高并发性的处理任务,可以有效提高处理效率。
在该实现方式中,在该步骤204之前,终端可以获取该多个虚拟对象的数量,根据该多个虚拟对象的数量,获取图像处理器的目标数量的并行通道。该图像处理器的并行通道的数量可以根据多个虚拟对象的数量确定,在此将并行通道的数量命名为目标数量。可以理解地,如果需要进行判断的虚拟对象的数量较多,需要的并行通道的数量则比较多。具体地,该终端获取该图像处理器的目标数量的并行通道的过程可以通过下述两种方式中任一种方式实现:
方式一、终端将该多个虚拟对象的数量作为目标数量,获取图像处理器的该目标数量的并行通道。
在该方式一中,由于图像处理器的核心数目多,可以支持高并发性的处理任务,终端可以根据多个虚拟对象的数量,获取相同数量的并行通道,通过每个并行通道,对该多个虚拟对象中的一个虚拟对象进行判断。例如,该多个虚拟对象的数量为1000,终端可以获取图像处理器的1000个并行通道,一个并行通道对应一个虚拟对象。
方式二、当该多个虚拟对象的数量大于数量阈值时,终端将该数量阈值作为目标数量,获取图像处理器的该目标数量的并行通道;当该多个虚拟对象的数量小于或等于数量阈值时,该终端的图像处理器的处理能力不同时,该目标数量还可能不同。将该多个虚拟对象的数量作为目标数量,获取图像处理器的该目标数量的并行通道。
在该方式二中,考虑到图像处理器的并行处理能力,可以在该终端中设置数量阈值,也即是,终端可以通过该图像处理器,并行对该数量阈值的虚拟对象进行处理,如果虚拟对象的数量大于数量阈值时,则可以分批处理。该数量阈值其实质为该图像处理器对多个虚拟对象进行并行判断的最大数量。该数量阈值可以由相关技术人员根据图像处理器的处理能力和需求进行设置,本发明实施例对此不作限定。例如,该数量阈值可以为100,如果虚拟对象的数量为1000,则该终端可以获取100个并行通道,分为十批来进行判断。而如果虚拟对象的数量为50,则该终端可以获取50个并行通道。
终端可以采用上述两种方式中任一种来获取多个并行通道,具体采用哪种实现方式可以由相关技术人员根据终端的图像处理器的处理能力进行设置,本发明实施例对此不作限定。
在一种可能实现方式中,对于上述步骤203中获取到的每个虚拟对象对应的多个动画帧,还可以进行筛选,对筛选后的多个动画帧进行融合。具体地,终端可以根据该每个动画帧的权重,将权重最大的目标数量的动画帧作为该每个虚拟对象对应的目标动画帧,终端按照该目标动画帧的权重,对该每个虚拟对象对应的目标动画帧进行融合,得到该每个虚拟对象的骨骼模型中每个骨骼的目标位姿数据。
其中,该目标数量可以由相关技术人员根据需求进行设置,例如,该目标数量可以为8,本发明实施例对该目标数量不作限定。这样将对融合结果影响较大的动画帧进行融合,可以不将对融合结果影响较小的动画帧考虑在内,从而可以有效减少计算量,减少动画帧融合过程所需花费的时间,以提高动画帧融合的效率,进而提高虚拟对象的显示效率。
当然,在该实现方式中,当该每个虚拟对象对应的多个动画帧的数量小于或等于该目标数量时,终端将该每个虚拟对象对应的多个动画帧作为该每个虚拟对象对应的目标动画帧。例如,如果某个虚拟对象对应的动画帧的数量为5,则终端可以对这5个动画帧进行融合。
在一种可能实现方式中,上述步骤203之后,终端可以将该多个虚拟对象中每个虚拟对象对应的多个动画帧和每个动画帧的权重写入缓存,从而该步骤204可以为:通过图像处理器,从该缓存中提取该多个虚拟对象中每个虚拟对象对应的多个动画帧和每个动画帧的权重,执行该按照该每个动画帧的权重,并行对该多个虚拟对象对应的多个动画帧进行融合,得到该多个虚拟对象的骨骼模型中每个骨骼的目标位姿数据的步骤。
在一个具体的可能实施例中,终端可以将该多个动画帧和每个动画帧的权重写入缓冲区,终端可以在初始化时在图像处理器中分配较大的缓冲区,后续获取到每帧需要融合的动画帧后,可以将其写入该缓冲区中,从而可以通过图像处理器,从该缓冲区中读取相应的数据继续进行处理。
具体地,终端可以将该多个虚拟对象中每个虚拟对象对应的多个动画帧和每个动画帧的权重写入缓冲区,该步骤204中,终端可以通过图像处理器,从该缓冲区中读取该多个虚拟对象中每个虚拟对象对应的多个动画帧和每个动画帧的权重,执行该按照该每个动画帧的权重,并行对该多个虚拟对象对应的多个动画帧进行融合,得到该多个虚拟对象的骨骼模型中每个骨骼的目标位姿数据的步骤。
上述写入缓存或写入缓冲区的过程中,终端还可以对应存储每个虚拟对象的标识信息和该每个虚拟对象对应的多个动画帧以及权重在缓存或缓冲区中的位置。进而,终端可以根据每个虚拟对象的标识信息,获知该每个虚拟对象对应的多个动画帧以及权重在缓存或缓冲区中的位置,并通过图像处理器,从该位置中,读取相应的数据。
例如,如图9所示,在此称n个虚拟对象为n个角色,终端可以通过中央处理器(cpu)对动画树0至动画树n进行遍历,得到所需融合的动画帧和权重0至n,n和m均为正整数,也即是,每个虚拟对象对应的多个动画帧和权重,并将结果写入图像处理器(gpu)的缓冲区(buffer)里。如图6示,终端通过图像处理器,可以从缓冲区中读取每个虚拟对象所需融合的动画帧和权重,再从第二贴图中提取多个动画帧进行融合,得到每个虚拟对象的骨骼模型中每个骨骼的目标位姿数据。
在一种可能实现方式中,终端可以将该多个虚拟对象的骨骼模型中每个骨骼的目标位姿数据存储于第一贴图中。例如,如图6所示,终端将融合结果均存储于第一贴图中,可以理解地,该第一贴图也可以采用骨骼动画矩阵的形式。比如,该第一贴图的宽为所有动画帧数之和,高为骨骼个数,每一列为一个虚拟对象的骨骼模型中每个骨骼的目标位姿数据。
205、终端根据该多个虚拟对象的骨骼模型中每个骨骼的目标位姿数据,在图形用户界面中显示该多个虚拟对象。
终端在获取到该多个虚拟对象的骨骼模型中每个骨骼的目标位姿数据后,则可以确定每个虚拟对象的显示形态,进而在图形用户界面中显示相应的显示形态,显示的每个虚拟对象的姿态则与该每个虚拟对象的骨骼模型中每个骨骼的目标位姿数据相符。
具体地,终端可以根据该每个虚拟对象的骨骼模型中每个骨骼的目标位姿数据,对该每个虚拟对象进行蒙皮,得到该每个虚拟对象的显示形态,在图形用户界面中,显示该每个虚拟对象的显示形态。
其中,该蒙皮过程中,终端可以根据每个顶点所对应的至少一个骨骼的目标位姿数据,获取每个顶点的位置,所有顶点的位置均确定后,虚拟对象的显示形态也即确定了,从而终端可以按照该顶点的位置在图形用户界面中进行显示。
在上述将该多个虚拟对象的骨骼模型中每个骨骼的目标位姿数据存储于第一贴图中的实现方式中,该步骤205中,终端可以对该第一贴图进行采样,以在图形用户界面中显示该多个虚拟对象。
在一种可能实现方式中,终端可以将该多个虚拟对象的骨骼模型中每个骨骼的目标位姿数据与该多个虚拟对象的标识信息对应存储于第一贴图中。相应地,该采样过程可以为:终端根据该多个虚拟对象的标识信息,对该第一贴图进行采样,以在图形用户界面中显示该多个虚拟对象。
在一个具体的可能实施例中,该骨骼模型中每个骨骼的目标位姿数据也可以与该每个骨骼的标识信息对应存储,例如,虚拟对象的标识信息可以用角色id表示,该每个骨骼的标识信息可以用骨骼id表示。终端可以根据角色id和骨骼id,对第一贴图进行采样,实现对角色的显示。
在一种可能实现方式中,终端可以对多个虚拟对象进行批量显示,进而减少绘制命令的发起次数,提高处理效率。具体地,终端可以对绘制命令进行实例化,得到对象,该绘制命令包括该多个虚拟对象的标识信息,终端可以通过该对象,执行该根据该多个虚拟对象的标识信息,对该第一贴图进行采样,以在图形用户界面中显示该多个虚拟对象的步骤。
该批量显示的过程是指通过实例化(instancing)的方式调用绘制命令(drawcall),进而批量对该多个虚拟对象进行渲染显示。这样通过一次调用、发起一个drawcall即可对多个虚拟对象进行显示,可以大幅度减少drawcall的发起次数,提高处理效率。
在一种可能实现方式中,绘制命令可以包括该多个虚拟对象对应的多个动画帧和每个动画帧的权重在缓存中的位置。具体地,绘制命令可以包括该多个虚拟对象对应的多个动画帧和每个动画帧的权重在缓冲区的位置。进而,终端通过图像处理器,可以根据该位置,从缓存或缓冲区读取数据进行动画帧融合,并根据融合后的数据对虚拟对象进行显示。
例如,如图10所示,终端在对多个虚拟对象(在此称虚拟对象为实例)进行显示时,可以通过上述instancing的方式批量对多个实例进行实例化绘制(drawinstanced),每个实例的骨骼模型中每个骨骼的目标位姿数据可以从第一贴图中采样得到。举一个示例,在显示过程中可以通过顶点着色器(vertexshader)对虚拟对象的骨骼模型的顶点进行蒙皮(skinning),蒙皮数据可以为浮点数float,大小为4*4,蒙皮过程也即是根据实例的索引(标识信息)载入动画的过程,实例的索引可以用instanceindex表示,载入动画可以用loadanimation表示,输出姿态(outposition)为实例的位置以及根据实例的骨骼动画矩阵(instancewvp)进行蒙皮的结合结果,mul为旋转数据进行四元数相乘,位置数据进行矩阵相乘。对在此仅以一种示例进行说明,对具体绘制过程不造成限定。
该过程中将多个虚拟对象作为一个群体,批量地对群体直接进行显示,可以大幅度减少发起drawcall的数量,减少cpu的负荷,可以有效提高显示效率。这样本发明实施例提供的方法支持显示的虚拟对象的数量显著提升,可以突破相关技术中虚拟对象的数量瓶颈。
例如,如图11所示,在一个具体示例中,以电子游戏场景为例,在游戏开始运行时,终端可以进行初始化,写入待获取的数据,从而后续可以基于判断步骤,从待获取的数据中选择一些数据进行获取。在本发明实施例中,该待获取的数据可以为贴图的形式,后续终端还可以基于对多个动画帧进行融合得到多个虚拟对象的骨骼模型中各个骨骼的目标位姿数据后,将其存储于一个贴图中,在此称之后存储多个虚拟对象的骨骼模型中各个骨骼的目标位姿数据的贴图为第一贴图,称存储所有待获取的动画帧的贴图为第二贴图。
在本发明实施例中,以虚拟对象称为角色为例,初始化后游戏运行时,终端可以通过cpu,根据游戏数据,进行动画树遍历,得到每个角色当前帧需要的动画帧和权重(动画帧数据),发送角色位置和所需的动画帧数据到缓冲区(buffer)。终端还可以通过cpu发送动画帧融合指令和绘制指令至缓冲区。终端可以通过gpu读取缓冲区的所有指令,当指令包含动画帧融合指令时,可以通过gpu并行对每个角色进行动画帧融合,得到骨骼动画矩阵,以供蒙皮使用。当指令包含绘制指令时,可以对角色进行实时蒙皮,一次性并行绘制所有角色,从而将多个角色绘制到屏幕(图形用户界面)中。如图12所示,在屏幕中同时绘制有大量的角色。以上流程可以在屏幕显示每帧画面时执行,直至游戏结束。
需要说明的是,通过测试,本发明实施例提供的虚拟对象显示效率极高,同样1000个角色模型在ue4游戏引擎中,如果使用相关技术中由cpu串行处理的方式开销为30毫秒,而采用本发明实施例提供的方法仅需要2毫秒。且通过cpu的多个任务线程实现动画帧获取步骤,可以使得主线程开销为0,显著提升处理效率。通过gpu并行对多个虚拟对象进行动画帧融合,开销也不过0.75毫秒。并且在gpu显示的任何阶段都可以获得每一个虚拟对象每一个骨骼的目标位姿数据,因而可以直接将多个虚拟对象看做一个群体,通过instancing的方式发起一个drawcall,大大减少了显示负担和时间,显示时间从25毫秒减少到了2毫秒,效率提升了十倍之多。
本发明实施例通过获取多个虚拟对象对应的多个动画帧和权重,通过图像处理器并行对该多个虚拟对象进行动画帧融合,得到每个虚拟对象的骨骼模型中每个骨骼的目标位姿数据,从而将其作为显示多个虚拟对象的依据,对多个虚拟对象进行显示,该过程中通过图像处理器并行对多个虚拟对象进行动画帧融合,而无需由中央处理器逐个获取动画帧和权重、动画帧融合和显示,可以有效减少中央处理器的处理负担,避免出现中央处理器过载的问题,可以大幅度提高处理效率,进而提高该虚拟对象显示过程的显示效率,也提高了该虚拟对象的显示效果。
上述所有可选技术方案,可以采用任意结合形成本发明的可选实施例,在此不再一一赘述。
图13是本发明实施例提供的一种虚拟对象显示装置的结构示意图,参见图13,该装置包括:
获取模块1301,用于获取多个虚拟对象中每个虚拟对象对应的多个动画帧和每个动画帧的权重,该每个动画帧包括虚拟对象的骨骼模型中每个骨骼的位姿数据;
融合模块1302,用于通过图像处理器,按照该每个动画帧的权重,并行对该多个虚拟对象对应的多个动画帧进行融合,得到该多个虚拟对象的骨骼模型中每个骨骼的目标位姿数据;
显示模块1303,用于根据该多个虚拟对象的骨骼模型中每个骨骼的目标位姿数据,在图形用户界面中显示该多个虚拟对象。
在一种可能实现方式中,该融合模块1302用于根据该多个虚拟对象的数量,通过该图像处理器的多个并行通道,按照该每个动画帧的权重,并行对该多个虚拟对象对应的多个动画帧进行融合,得到该多个虚拟对象的骨骼模型中每个骨骼的目标位姿数据,每个并行通道用于对一个虚拟对象对应的多个动画帧进行融合。
在一种可能实现方式中,该融合模块1302用于对于该多个虚拟对象中每个虚拟对象,按照该每个虚拟对象对应的多个动画帧的权重,对该每个虚拟对象对应的多个动画帧中骨骼模型中各个骨骼的位姿数据进行加权,得到该每个虚拟对象的骨骼模型中每个骨骼的目标位姿数据。
在一种可能实现方式中,该融合模块1302用于:
根据该每个动画帧的权重,将权重最大的目标数量的动画帧作为该每个虚拟对象对应的目标动画帧;
按照该目标动画帧的权重,对该每个虚拟对象对应的目标动画帧进行融合,得到该每个虚拟对象的骨骼模型中每个骨骼的目标位姿数据。
在一种可能实现方式中,该装置还包括:
第一存储模块,用于将该多个虚拟对象的骨骼模型中每个骨骼的目标位姿数据存储于第一贴图中;
该显示模块1303用于对该第一贴图进行采样,以在图形用户界面中显示该多个虚拟对象。
在一种可能实现方式中,该第一存储模块用于将该多个虚拟对象的骨骼模型中每个骨骼的目标位姿数据与该多个虚拟对象的标识信息对应存储于第一贴图中;
该显示模块1303用于根据该多个虚拟对象的标识信息,对该第一贴图进行采样,以在图形用户界面中显示该多个虚拟对象。
在一种可能实现方式中,该显示模块1303用于:
对绘制命令进行实例化,得到对象,该绘制命令包括该多个虚拟对象的标识信息;
通过该对象,执行该根据该多个虚拟对象的标识信息,对该第一贴图进行采样,以在图形用户界面中显示该多个虚拟对象的步骤。
在一种可能实现方式中,该获取模块1301用于:
获取该多个虚拟对象的位姿指示数据;
基于每个虚拟对象的位姿指示数据,对动画树进行遍历,得到该每个虚拟对象的遍历结果,该动画树的叶结点关联有动画帧;
根据该多个虚拟对象对应的多个遍历结果,获取多个虚拟对象中每个虚拟对象对应的多个动画帧和每个动画帧的权重。
在一种可能实现方式中,该获取模块1301还用于遍历该动画树,得到该动画树的所有叶结点所关联的动画帧;
该装置还包括:
第二存储模块,用于将该所有叶结点所关联的动画帧存储于第二贴图中;
该获取模块1301用于根据该多个虚拟对象对应的多个遍历结果,从该第二贴图中获取该多个虚拟对象对应的多个动画帧和每个动画帧的权重。
在一种可能实现方式中,该获取模块1301用于通过中央处理器中的多个任务线程,执行该获取多个虚拟对象中每个虚拟对象对应的多个动画帧和每个动画帧的权重的步骤。
在一种可能实现方式中,该装置还包括:
写入模块,用于将该多个虚拟对象中每个虚拟对象对应的多个动画帧和每个动画帧的权重写入缓存;
该融合模块1302用于:
通过图像处理器,从该缓存中提取该多个虚拟对象中每个虚拟对象对应的多个动画帧和每个动画帧的权重;
执行该按照该每个动画帧的权重,并行对该多个虚拟对象对应的多个动画帧进行融合,得到该多个虚拟对象的骨骼模型中每个骨骼的目标位姿数据的步骤。
在一种可能实现方式中,该显示模块1303用于:
根据该每个虚拟对象的骨骼模型中每个骨骼的目标位姿数据,对该每个虚拟对象进行蒙皮,得到该每个虚拟对象的显示形态;
在图形用户界面中,显示该每个虚拟对象的显示形态。
本发明实施例提供的装置,通过获取多个虚拟对象对应的多个动画帧和权重,通过图像处理器并行对该多个虚拟对象进行动画帧融合,得到每个虚拟对象的骨骼模型中每个骨骼的目标位姿数据,从而将其作为显示多个虚拟对象的依据,对多个虚拟对象进行显示,该过程中通过图像处理器并行对多个虚拟对象进行动画帧融合,而无需由中央处理器逐个获取动画帧和权重、动画帧融合和显示,可以有效减少中央处理器的处理负担,避免出现中央处理器过载的问题,可以大幅度提高处理效率,进而提高该虚拟对象显示过程的显示效率,也提高了该虚拟对象的显示效果。
需要说明的是:上述实施例提供的触发智能网业务的装置在触发智能网业务时,仅以上述各功能模块的划分进行举例说明,实际应用中,可以根据需要而将上述功能分配由不同的功能模块完成,即将设备的内部结构划分成不同的功能模块,以完成以上描述的全部或者部分功能。另外,上述实施例提供的触发智能网业务的装置与触发智能网业务的方法实施例属于同一构思,其具体实现过程详见方法实施例,这里不再赘述。
图14是本发明实施例提供的一种电子设备的结构示意图,该电子设备1400可因配置或性能不同而产生比较大的差异,可以包括一个或多个处理器(centralprocessingunits,cpu)1401和一个或多个的存储器1402,其中,该一个或多个存储器1402中存储有至少一条指令,该至少一条指令由该一个或多个处理器1401加载并执行以实现上述各个方法实施例提供的虚拟对象显示方法。当然,该电子设备1400还可以具有有线或无线网络接口、键盘以及输入输出接口等部件,以便进行输入输出,该电子设备1400还可以包括其他用于实现设备功能的部件,在此不做赘述。
在示例性实施例中,还提供了一种计算机可读存储介质,例如包括指令的存储器,上述指令可由处理器执行以完成上述实施例中的虚拟对象显示方法。例如,该计算机可读存储介质可以是只读存储器(read-onlymemory,rom)、随机存取存储器(randomaccessmemory,ram)、只读光盘(compactdiscread-onlymemory,cd-rom)、磁带、软盘和光数据存储设备等。
本领域普通技术人员可以理解实现上述实施例的全部或部分步骤可以通过硬件来完成,也可以通过程序来指令相关的硬件完成,该程序可以存储于一种计算机可读存储介质中,上述提到的存储介质可以是只读存储器,磁盘或光盘等。
上述仅为本发明的较佳实施例,并不用以限制本发明,凡在本发明的精神和原则之内,所作的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!