一种基于深度投影的机械手爪抓取规划方法及控制装置与流程
本发明属于机器人装配领域,尤其涉及一种基于深度投影的机械手抓取规划方法及控制装置。
背景技术:
现有的抓取规划方法,基本可以分为基于解析的抓取规划方法和基于学习的抓取规划方法。
基于解析的抓取规划方法在抓取合成阶段,首先定义一些如立方体、球、圆柱、圆锥等这样的基础形状,同时定义他们相对应的可能抓取位姿,然后利用形状单元(shape primitives)、分解树(decomposition trees)或者最小体积包围盒(minimum volume bounding box)等不同的方法对物体进行分解,分解成上述的基础形状。最后按照预定义的候选抓取位姿,将每一个分解出的基础形状对应的候选抓取位姿全部取出,组合成整个物体的候选抓取位姿。而在抓取选择阶段,通过在GraspIt!或OpenRAVE等仿真环境进行抓取仿真,获取每一个手爪与物体的接触点处的六维力旋量信息,进而求取ε度量或者凸包体积度量,从而选出具有最大度量值的抓取位姿,作为最优抓取位姿。
基于学习的抓取规划方法通常利用已有的抓取场景信息及对应的成功与不成功抓取位姿等作为样本,离线训练用于抓取规划的神经网络。而在线部分,用工作场景的RGB或者RGB-D的数据作为输入,经过已训练好的模型,直接输出最优抓取位姿。
基于解析的方法在计算速度上优于基于学习的方法,然而对于基于解析的方法,需要对机械手爪以及被抓取物体进行精确三维建模,而这对于具有庞大数量的待抓取物体进行建模几乎是不现实的。特别是对于可变形物体,如毛绒玩具等,根本无法构建出可用的静态模型。而基于学习的方法虽然不需要对待抓取物体和机械手爪进行精确建模,但是由于滑动窗口方法的采用,导致规划速度上远不如基于解析的方法,同时该类方法由于直接采用RGB数据作为网络模型的输入,对光照稳定性有较高的要求。
技术实现要素:
针对现有技术的问题,本发明提供了一种无需对待抓取物体建模、能够适应不同物体和手爪尺寸、不受光照变化影响的快速抓取规划方法及控制装置。
本发明是通过以下技术方案来实现的:
本发明公开了一种基于深度投影的机械手爪抓取规划方法,所述的方法主要包括如下步骤:1)、利用场景深度信息,生成抓取位姿正负样本,进行抓取选择神经网络的训练;2)、根据当前场景深度信息,生成候选抓取位姿样本,并用训练好的网络获得最优抓取位姿。
作为进一步地改进,本发明所述的步骤1)的步骤如下:
a、获取合成的场景深度信息,所述场景深度信息由待抓取物体与待抓取物体的承载物合成;
b、将合成的场景深度信息投影到抓取位姿投影平面上,生成抓取位姿正负样本;
c、利用训练样本信息训练抓取选择神经网络,所述训练样本信息包括抓取位姿正负样本以及对应抓取位姿是正样本或负样本的标签。
作为进一步地改进,本发明所述的步骤2)的步骤如下:
a、获取当前场景深度信息,利用当前场景深度信息生成候选抓取位姿的坐标系,获得在候选抓取位姿的坐标系下合成的当前场景深度信息,所述当前场景深度信息由当前的待抓取物体与待抓取物体的承载物合成;
b、将合成的当前场景深度信息投影到候选抓取位姿投影平面,生成候选抓取位姿样本;
c、将候选抓取位姿样本放入训练好的抓取选择神经网络,获得最优抓取位姿。
作为进一步地改进,本发明所述的步骤1)a步骤的具体步骤为:获取场景点云信息;从场景点云信息中分割出待抓取物体的点云信息以及承载体的位姿信息;将分割出的待抓取物体点云信息及承载体的位姿信息构建合成的场景深度信息;
作为进一步地改进,本发明所述的步骤2)中的a步骤的具体步骤为:获取当前场景点云信息;从当前场景点云信息中分割出待抓取物体的点云信息以及承载体的位姿信息;对待抓取物体的点云信息利用PCA主成分分析算法获取点云主轴方向;生成待抓取物体的点云信息的凸包,对于凸包的每一个三角面,根据三角面的法向量以及待抓取物体点云的主轴生成候选抓取位姿坐标系。
作为进一步地改进,本发明将合成的场景深度信息投影到抓取位姿投影平面上之前,根据不同手爪的尺寸信息,选取不同的深度投影尺寸,和/或将合成的当前场景深度信息投影到候选抓取位姿投影平面之前,根据不同手爪的尺寸信息,选取不同的深度投影尺寸。
作为进一步地改进,本发明利用3D图像渲染的方法将合成的场景深度信息投影到抓取位姿投影平面上,和/或利用3D图像渲染的方法将合成的当前场景深度信息投影到候选抓取位姿投影平面。
本发明还公开了一种用于机械手爪抓取规划的控制装置,包括
第一运算模块,根据当前场景深度信息,生成候选抓取位姿样本,并用训练好的抓取选择神经网络获得最优抓取位姿;
控制模块,将机械手爪调整至最优抓取位姿进行抓取。
作为进一步地改进,本发明所述第一运算模块包括
第一获取单元,获取当前场景深度信息,利用当前场景深度信息生成候选抓取位姿的坐标系;获得在候选抓取位姿的坐标系下合成的当前场景深度信息;
第一位姿样本生成单元,将合成的当前场景深度信息投影到候选抓取位姿投影平面,生成候选抓取位姿样本;
抓取选择单元,将候选抓取位姿样本放入训练好的抓取选择神经网络,获得最优抓取位姿。
作为进一步地改进,本发明所述第一获取单元具体地获取当前场景点云信息;从当前场景点云信息中分割出待抓取物体的点云信息以及承载体的位姿信息;对待抓取物体的点云信息利用PCA主成分分析算法获取点云主轴方向;生成待抓取物体的点云信息的凸包,对于凸包的每一个三角面,根据三角面的法向量以及待抓取物体点云的主轴生成候选抓取位姿坐标系,将分割出的待抓取物体点云信息及承载体的位姿信息构建合成的当前场景深度信息。
作为进一步地改进,本发明所述控制装置还包括第二运算模块,第二运算模块利用场景深度信息,生成抓取位姿正负样本,进行抓取选择神经网络的训练。
作为进一步地改进,本发明所述第二运算模块包括
第二获取单元,获取合成的场景深度信息;
第二位姿样本生成单元,将合成的场景深度信息投影到抓取位姿投影平面上,生成抓取位姿正负样本;
训练单元,利用训练样本信息训练抓取选择神经网络;所述训练样本信息包括抓取位姿正负样本以及对应抓取位姿是正样本或负样本的标签。
作为进一步地改进,本发明所述第二获取单元具体的获取场景点云信息;从场景点云信息中分割出待抓取物体的点云信息以及承载体的位姿信息;将分割出的待抓取物体点云信息及承载体的位姿信息构建合成的场景深度信息。
作为进一步地改进,本发明所述第二位姿样本生成单元将合成的场景深度信息投影到抓取位姿投影平面上之前,根据不同手爪的尺寸信息,选取不同的深度投影尺寸,和/或第一位姿样本生成单元将合成的当前场景深度信息投影到候选抓取位姿投影平面之前,根据不同手爪的尺寸信息,选取不同的深度投影尺寸。
作为进一步地改进,本发明所述第二位姿样本生成单元利用3D图像渲染的方法将合成的场景深度信息投影到抓取位姿投影平面上,和/或第一位姿样本生成单元利用3D图像渲染的方法将合成的当前场景深度信息投影到候选抓取位姿投影平面。
本发明的有益效果是:
(1)综合了机械手爪的尺寸信息等,该抓取规划方法能够适应于不同种类的机械手爪,无需对待抓取物体建模、能够适应不同物体和手爪尺寸、不受光照变化影响的快速抓取规划方法。
(2)利用对待抓取物体点云进行PCA,获取点云主轴方向,在生成候选抓取位姿坐标系的步骤中,剔除了与待抓取位姿点云主轴冲突的抓取位姿,减少了无效候选抓取位姿的数量,提高了候选抓取位姿成为最优抓取位姿的整体效率。
(3)利用3D图像渲染的方法做深度投影的生成,避免了逐个点云做投影的低效,大大减少了在线抓取规划时间。
附图说明
图1为机械手爪位姿坐标系定义示意图;
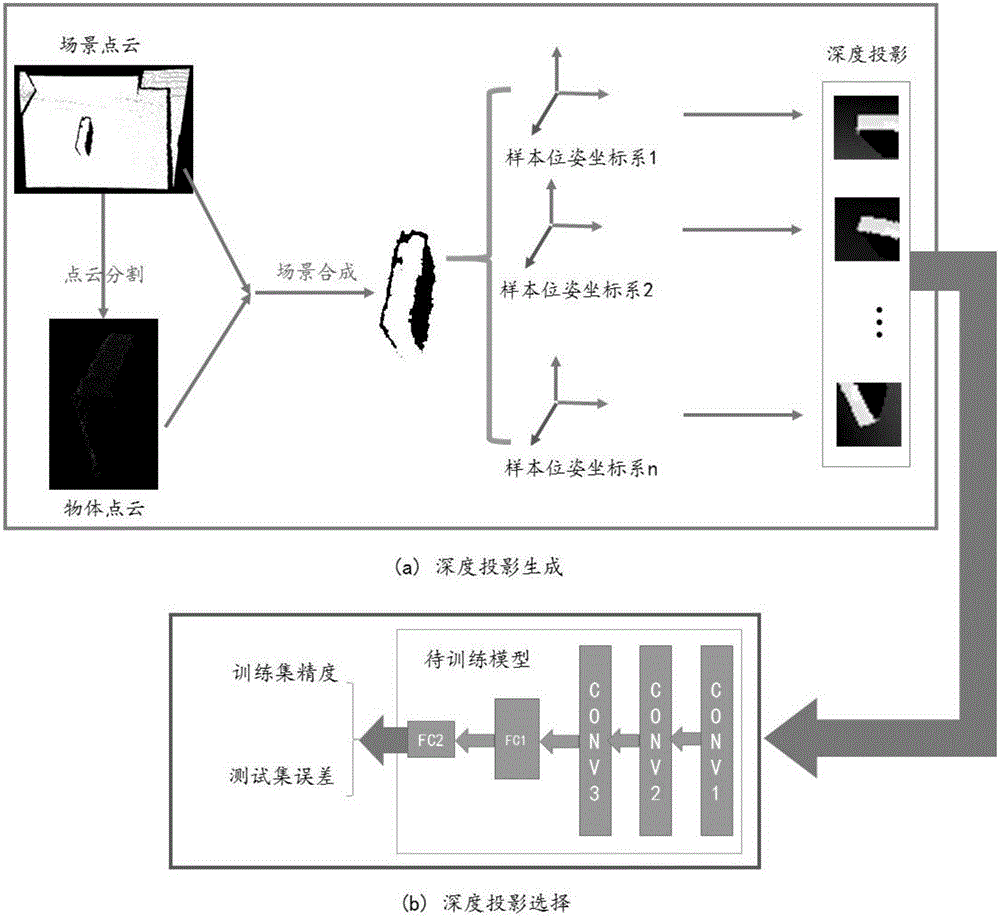
图2为离线部分的深度投影生成过程,以及网络训练过程的示意图;
图3为根据分割出的待抓取物体点云信息及桌面位姿信息构建的合成场景示意图;
图4为在线部分的深度投影生成过程,以及利用训练好的网络做抓取选择的过程示意图。
具体实施方式
下面结合说明书附图,通过具体实施例子对本发明的技术方案作进一步地说明。
本发明公开的一种基于深度投影的机械手抓取规划方法通过抓取规划控制装置以及机械手爪来实现,机械手爪用于抓取三维空间中的任意物体,抓取规划控制装置通过本发明公开的抓取规划方法完成抓取规划,即利用包含待抓取物体的场景点云信息作为输入,根据机械手爪信息进行抓取规划,最终输出最优抓取位姿,将最优抓取位姿坐标系作为机械手爪位姿坐标系,根据抓取规划结果控制机械手爪完成抓取。
图1为机械手爪位姿坐标系定义示意图;本发明中提出的方法,用欧式空间的一个六自由度的位姿直接表示机械手爪的位姿,其中六个自由度分别是平移部分的x、y、z,旋转部分的滚动角(roll)、俯仰角(pitch)、偏航角(yaw)。图1中Z轴是手爪接近向量的反方向;X轴是大拇指合起的方向。
本发明的机械手爪抓取规划方法是经由控制器接收一组输入,包括待抓取物体的场景点云信息;由控制器分割场景点云,获取待抓取物体点云以及承载物位姿;在物体点云周围生成候选抓取位姿;利用场景点云及候选抓取位姿生成深度投影;生成的深度投影作为训练好的控制器中的深度神经网络的输入部分,利用该网络选择出最优深度投影,对应的抓取位姿即为最优抓取位姿。细分为:
步骤201:利用场景深度信息,生成抓取位姿样本,进行抓取选择神经网络的训练。
其中,所述抓取位姿样本包括抓取位姿正样本和抓取位姿负样本,所述抓取位姿正样本对应能够成功抓取的抓取位姿的样本,所述负样本对应抓取失败的抓取位姿的样本。
步骤202:根据当前场景深度信息,生成候选抓取位姿样本,并用训练好的抓取选择神经网络获得最优抓取位姿。
其中,抓取位姿正负样本离线生成,候选抓取位姿样本在线生成,所述离线生成为不在抓取的过程中生成,所述在线生成为在抓取的过程中生成。
步骤201的具体过程为:
步骤301:获取合成的场景深度信息,所述场景深度信息由待抓取物体与待抓取物体的承载物合成。
具体地(1)获取场景点云信息;(2)从场景点云信息中分割出待抓取物体的点云信息以及承载体的位姿信息。其中,所述承载体用于承载待抓取物体,例如所述承载体可以是桌子、椅子等,所述待抓取物体可以是摆放在桌子、椅子上的订书机、黑板擦等;图2中的原始点云中只有一个物体,但是实际场景中可能包括多个物体等,而本发明的方法只需要将待抓取物体的点云信息以及桌子的位姿信息分割出来即可。(3)将分割出的待抓取物体点云信息及承载体的位姿信息构建合成场景深度信息。在一具体实施方式中,对场景点云信息进行点云分割后,在原桌子位姿处新建模拟桌子模型,与待抓取物体的点云信息构成只含有待抓取位姿和桌子的场景深度信息;
步骤302:将合成的场景深度信息投影到抓取位姿投影平面上,生成深度投影样本;所述深度投影样本即为抓取位姿正负样本。
在一具体实施方式中,所述抓取位姿投影平面为样本抓取位姿坐标系的x-y平面,利用3D图像渲染方法,将合成的场景深度信息渲染到样本抓取位姿坐标系的x-y平面上,生成深度投影样本。
其中,根据机械手爪的不同抓取范围,选取不同的深度投影尺寸,所述深度投影尺寸确定深度投影样本尺寸大小。在一具体实施方式中,具有较大开合范围即较大抓取范围的机械手爪,一般抓取范围较大,选用较大的投影尺寸;具有开合范围小即抓取范围较小的机械手爪可选用较小的投影尺寸。
步骤303:利用训练样本信息训练深度神经网络,所述深度神经网络即为抓取选择神经网络。
其中,所述训练样本信息包括深度投影样本以及对应抓取位姿是正样本或负样本的标签。
其中,可以利用如Caffe、Tensorflow等搭建合适的网络模型并进行深度神经网络的训练。
其中,利用训练样本信息训练抓取选择神经网络,获得训练集上的分类精度以及测试集上的分类误差。当训练集上具有较高的分类精度,同时测试集上的分类误差足够小时,网络模型训练完毕。图2所示的网络模型是一个示例模型,具有三层卷积网络(conv1、conv2、conv3)和两层全连接网络(fc1、fc2)共5层组成,而在具体的训练过程,可以通过调整网络结构、层数、每层内部的参数等来训练出最优的网络。
图2为离线部分的深度投影生成过程,以及网络训练过程的示意图;
步骤一:从场景点云分割出待抓取物体;
步骤二:根据分割出的待抓取物体点云信息及桌面位姿信息构建的合成场景,如图3所示。
步骤三:根据不同手爪的尺寸信息,选取不同的深度投影尺寸。利用3D图像渲染方法,将合成场景信息渲染到样本抓取位姿坐标系的x-y平面上,生成深度投影样本。
步骤四:将上述生成的深度投影样本训练深度神经网络,网络的输入是训练样本,训练样本包括深度投影以及对应抓取位姿是正样本或负样本的标签。
步骤202的具体过程为:
步骤401:获取当前场景深度信息,利用当前场景深度信息生成候选抓取位姿的坐标系,获得在候选抓取位姿的坐标系下合成的当前场景深度信息,所述当前场景深度信息由当前的待抓取物体与待抓取物体的承载物合成;。
具体地(1)获取当前场景点云信息;(2)从当前场景点云信息中分割出待抓取物体的点云信息以及承载体的位姿信息;(3)对待抓取物体的点云信息利用PCA主成分分析算法获取点云主轴方向;(4)生成待抓取物体的点云信息的凸包,对于凸包的每一个三角面,根据三角面的法向量以及待抓取物体点云的主轴生成候选抓取位姿坐标系;其中,候选抓取位姿坐标系的x-y平面也即凸包三角面所在的平面,凸包三角面的法向量即为坐标系的z轴,点云主轴用于确定坐标系的x轴。(5)将分割出的待抓取物体点云信息及承载体的位姿信息构建合成的当前场景深度信息。在一具体实施方式中,对当前场景点云信息进行点云分割后,在原桌子位姿处新建桌子模拟模型,与待抓取物体的点云信息构成只含有待抓取位姿和桌子的当前场景深度信息;
步骤402:将合成的当前场景深度信息投影到候选抓取位姿投影平面,生成候选深度投影样本,即为候选抓取位姿样本。也就是所述候选抓取位姿样本为候选抓取位姿对应的深度投影。
在一具体实施方式中,所述候选抓取位姿投影平面为候选抓取位姿坐标系的x-y平面,利用3D图像渲染方法,将合成的当前场景深度信息渲染到候选抓取位姿坐标系的x-y平面上,生成候选深度投影样本。
其中,根据机械手爪的不同抓取范围,选取不同的深度投影尺寸,所述深度投影尺寸确定候选深度投影样本尺寸大小。在一具体实施方式中,具有较大开合范围即较大抓取范围的机械手爪,一般抓取范围较大,选用较大的投影尺寸;具有开合范围小即抓取范围较小的机械手爪可选用较小的投影尺寸。
步骤403:将候选抓取位姿样本放入抓取选择神经网络,获得最优抓取位姿完成抓取规划。
将候选深度投影样本放入离线部分训练好的抓取选择神经网络,从而获得候选抓取位姿的正/负标签以及候选抓取位姿样本是最优抓取位姿的概率。其中,候选深度投影样本中为正标签且概率最大的为最优抓取位姿,所述最优抓取位姿为机械手爪最终用于抓取待抓取物体时所处的位姿。
图4为在线部分的深度投影生成过程,以及利用训练好的网络做抓取选择的过程示意图;
步骤一:对场景点云信息进行点云分割,分割出待抓取物体的点云,以及承载待抓取物体的桌子等的位姿信息;
步骤二:对待抓取物体的点云进行PCA主成分分析,获取点云主轴方向;
步骤三:生成待抓取物体点云的凸包,对于凸包的每一个三角面,根据三角面的法向量以及待抓取物体点云的主轴生成候选抓取位姿坐标系;
步骤四:根据桌子位姿和待抓取物体的点云生成只含有待抓取位姿和桌子的场景;
步骤五:根据不同手爪的尺寸信息,选取不同的深度投影尺寸。利用3D图像渲染方法,将合成场景信息渲染到候选抓取位姿坐标系的x-y平面上,生成候选深度投影。
步骤六:将候选深度投影放入离线部分训练好的神经网络,输出最优抓取位姿。
本发明利用抓取合成和抓取选择两个过程完成抓取规划,所述抓取合成是将包含待抓取物体的场景信息作为输入,在机械手爪可抓取的大范围空间中,合成较可能成为最优抓取位姿的一些候选抓取位姿。本发明的方法利用场景点云的信息生成和候选抓取位姿一一对应的深度投影,从而完成抓取合成;所述抓取选择是指在抓取合成过程中生成的候选抓取位姿中利用一定的评价标准,选择评价最高也即最优的抓取位姿。通过训练一个深度网络(抓取选择神经网络)作为深度投影(候选抓取位姿样本)的评价标准来完成抓取选择。
本发明还公开了一种用于机械手爪抓取规划的控制装置。
实施例1:包括第一运算模块和控制模块。
第一运算模块,根据当前场景深度信息,生成候选抓取位姿样本,并用训练好的抓取选择神经网络获得最优抓取位姿;所述抓取选择神经网络用于作为从候选抓取位姿样本中获取最优抓取位姿的评价标准;第一运算模块包括第一获取单元、第一位姿样本生成单元、抓取选择单元;第一获取单元是获取当前场景深度信息,利用当前场景深度信息生成候选抓取位姿的坐标系,获得在候选抓取位姿的坐标系下合成的当前场景深度信息,第一获取单元具体地获取当前场景点云信息;从当前场景点云信息中分割出待抓取物体的点云信息以及承载体的位姿信息;对待抓取物体的点云信息利用PCA主成分分析算法获取点云主轴方向;生成待抓取物体的点云信息的凸包,对于凸包的每一个三角面,根据三角面的法向量以及待抓取物体点云的主轴生成候选抓取位姿坐标系,将分割出的待抓取物体点云信息及承载体的位姿信息构建合成的当前场景深度信息。第一位姿样本生成单元是将合成的当前场景深度信息投影到候选抓取位姿投影平面,生成候选抓取位姿样本;抓取选择单元是将候选抓取位姿样本放入训练好的抓取选择神经网络,获得最优抓取位姿。
第一位姿样本生成单元将合成的当前场景深度信息投影到候选抓取位姿投影平面之前,根据不同手爪的尺寸信息,选取不同的深度投影尺寸;第一位姿样本生成单元利用3D图像渲染的方法将合成的当前场景深度信息投影到候选抓取位姿投影平面上。
控制模块是将机械手爪调整至最优抓取位姿进行抓取。
实施例2:除了实施例1所包括的模块外,控制装置还包括第二运算模块,第二运算模块利用场景深度信息,离线生成抓取位姿正负样本,进行抓取选择神经网络的训练。第二运算模块包括第二获取单元、第二位姿样本生成单元和训练单元,
第二获取单元是获取合成的场景深度信息,第二获取单元具体的获取场景点云信息;从场景点云信息中分割出待抓取物体的点云信息以及承载体的位姿信息;将分割出的待抓取物体点云信息及承载体的位姿信息构建合成的场景深度信息。第二位姿样本生成单元是将合成的场景深度信息投影到抓取位姿投影平面上,生成抓取位姿正负样本。训练单元是利用训练样本信息训练抓取选择神经网络;训练样本信息包括抓取位姿正负样本以及对应抓取位姿是正样本或负样本的标签。
第二位姿样本生成单元将合成的场景深度信息投影到抓取位姿投影平面上之前,根据不同手爪的尺寸信息,选取不同的深度投影尺寸和/或,第二位姿样本生成单元利用3D图像渲染的方法将合成的场景深度信息投影到抓取位姿投影平面上。
以上所述的仅是本发明的优选实施方式,应当指出,对于本技术领域中的普通技术人员来说,在不脱离本发明核心技术特征的前提下,还可以做出若干改进和润饰,这些改进和润饰也应视为本发明的保护范围。
- 还没有人留言评论。精彩留言会获得点赞!