演唱者声音的处理方法及装置与流程
本发明涉及互联网技术,尤其涉及一种演唱者声音的处理方法及装置。
背景技术:
合声,是指至少两个演唱者共同演唱同一首歌曲的演唱方式。在实现本发明的过程中,发明人发现:由于不止是一个演唱者在演唱,因此,无法分辨出每个演唱者在合声演唱时的演唱情况。
因此,亟需提供一种方法,用以将每个演唱者的演唱声音从合声演唱声音中分离出来。
技术实现要素:
本发明的多个方面提供一种演唱者声音的处理方法及装置,用以将每个演唱者的演唱声音从合声演唱声音中分离出来。
本发明的一方面,提供一种演唱者声音的处理方法,包括:
获取至少两个演唱者演唱歌曲的合声音频数据;
根据所述至少两个演唱者中任一演唱者的音频特征参数和所述合声音频数据,获得所述任一演唱者演唱所述歌曲的独唱音频数据;
根据所述独唱音频数据,获得所述任一演唱者演唱所述歌曲的声音信号。
如上所述的方面和任一可能的实现方式,进一步提供一种实现方式,所述根据所述至少两个演唱者中任一演唱者的音频特征参数和所述合声音频数据,获得所述任一演唱者演唱所述歌曲的独唱音频数据之前,还包括:
获取所述任一演唱者朗读指定内容的标准音频数据;
根据所述标准音频数据,获得所述任一演唱者的音频特征参数。
如上所述的方面和任一可能的实现方式,进一步提供一种实现方式,所述音频特征参数,包括下列参数中的至少一项:
频率特征参数;
梅尔频率倒谱系数特征参数;以及
基音特征参数。
如上所述的方面和任一可能的实现方式,进一步提供一种实现方式,所述根据所述至少两个演唱者中任一演唱者的音频特征参数和所述合声音频数据,获得所述任一演唱者演唱所述歌曲的独唱音频数据,包括:
对所述合声音频数据进行频域变换处理,以获得所述合声音频数据所对应的合声频域数据;
根据所述任一演唱者的音频特征参数,在所述合声频域数据中,提取所述音频特征参数所对应的独唱频域数据;
对所述独唱频域数据进行频域逆变换处理,以获得所述任一演唱者的演唱所述歌曲的独唱音频数据。
如上所述的方面和任一可能的实现方式,进一步提供一种实现方式,所述频域变换处理包括傅里叶变换处理。
本发明的另一方面,提供一种演唱者声音的处理装置,包括:
获取单元,用于获取至少两个演唱者演唱歌曲的合声音频数据;
提取单元,用于根据所述至少两个演唱者中任一演唱者的音频特征参数和所述合声音频数据,获得所述任一演唱者演唱所述歌曲的独唱音频数据;
还原单元,用于根据所述独唱音频数据,获得所述任一演唱者演唱所述歌曲的声音信号。
如上所述的方面和任一可能的实现方式,进一步提供一种实现方式,所述提取单元,还用于
根据所述至少两个演唱者中任一演唱者的音频特征参数和所述合声音频数据,获得所述任一演唱者演唱所述歌曲的独唱音频数据之前,获取所述任一演唱者朗读指定内容的标准音频数据;以及
根据所述标准音频数据,获得所述任一演唱者的音频特征参数。
如上所述的方面和任一可能的实现方式,进一步提供一种实现方式,所述音频特征参数,包括下列参数中的至少一项:
频率特征参数;
梅尔频率倒谱系数特征参数;以及
基音特征参数。
如上所述的方面和任一可能的实现方式,进一步提供一种实现方式,所述提取单元,具体用于
对所述合声音频数据进行频域变换处理,以获得所述合声音频数据所对应的合声频域数据;
根据所述任一演唱者的音频特征参数,在所述合声频域数据中,提取所述音频特征参数所对应的独唱频域数据;以及
对所述独唱频域数据进行频域逆变换处理,以获得所述任一演唱者的演唱所述歌曲的独唱音频数据。
如上所述的方面和任一可能的实现方式,进一步提供一种实现方式,所述频域变换处理包括傅里叶变换处理。
由所述技术方案可知,本发明实施例通过获取至少两个演唱者演唱歌曲的合声音频数据,进而根据所述至少两个演唱者中任一演唱者的音频特征参数和所述合声音频数据,获得所述任一演唱者演唱所述歌曲的独唱音频数据,使得能够根据所述独唱音频数据,获得所述任一演唱者演唱所述歌曲的声音信号,这样,就将能够每个演唱者的演唱声音从合声演唱声音中分离出来了。
上述说明仅是本发明技术方案的概述,为了能够更清楚了解本发明的技术手段,而可依照说明书的内容予以实施,并且为了让本发明的上述和其它目的、特征和优点能够更明显易懂,以下特举本发明的具体实施方式。
附图说明
通过阅读下文优选实施方式的详细描述,各种其他的优点和益处对于本领域普通技术人员将变得清楚明了。附图仅用于示出优选实施方式的目的,而并不认为是对本发明的限制。而且在整个附图中,用相同的参考符号表示相同的部件。在附图中:
图1为本发明一实施例提供的演唱者声音的处理方法的流程示意图;
图2为本发明另一实施例提供的演唱者声音的处理装置的结构示意图。
具体实施方式
下面将参照附图更详细地描述本公开的示例性实施例。虽然附图中显示了本公开的示例性实施例,然而应当理解,可以以各种形式实现本公开而不应被这里阐述的实施例所限制。相反,提供这些实施例是为了能够更透彻地理解本公开,并且能够将本公开的范围完整的传达给本领域的技术人员。
需要说明的是,本发明实施例中所涉及的用户终端设备可以包括但不限于手机、个人数字助理(Personal Digital Assistant,PDA)、无线手持设备、平板电脑(Tablet Computer)、个人电脑(Personal Computer,PC)、MP3播放器、MP4播放器、可穿戴设备(例如,智能眼镜、智能手表、智能手环等)等。
另外,本文中术语“和/或”,仅仅是一种描述关联对象的关联关系,表示可以存在三种关系,例如,A和/或B,可以表示:单独存在A,同时存在A和B,单独存在B这三种情况。另外,本文中字符“/”,一般表示前后关联对象是一种“或”的关系。
实施例一
图1为本发明一实施例提供的演唱者声音的处理方法的流程示意图,如图1所示。
101、获取至少两个演唱者演唱歌曲的合声音频数据。
102、根据所述至少两个演唱者中任一演唱者的音频特征参数和所述合声音频数据,获得所述任一演唱者演唱所述歌曲的独唱音频数据。
103、根据所述独唱音频数据,获得所述任一演唱者演唱所述歌曲的声音信号。
声音其实是一种波形,每个人的声音都可以用软件记录下来,并变成波的形式。声音的频率周期越短,则频率越高;声音的频率振幅越大,则响度越大;而声音所所对应的波形不同,则音色就不同。例如,有些人的声音是锯齿波,有些人的声音是正弦波等。不同人的声音的不同主要就是取决于音色的不同。音色,则可以用音频特征参数来描述,因此,基于演唱者的音频特征参数,就可以区分开不同演唱者的不同波形,从而将每个演唱者的演唱声音从合声演唱声音中分离出来了。
需要说明的是,101~103的执行主体的部分或全部可以为位于本地终端的应用,或者还可以为设置在位于本地终端的应用中的插件或软件开发工具包(Software Development Kit,SDK)等功能单元,或者还可以为位于网络侧服务器中的处理引擎,或者还可以为位于网络侧的分布式系统,本实施例对此不进行特别限定。
可以理解的是,所述应用可以是安装在终端上的本地程序(nativeApp),或者还可以是终端上的浏览器的一个网页程序(webApp),本实施例对此不进行特别限定。
这样,通过获取至少两个演唱者演唱歌曲的合声音频数据,进而根据所述至少两个演唱者中任一演唱者的音频特征参数和所述合声音频数据,获得所述任一演唱者演唱所述歌曲的独唱音频数据,使得能够根据所述独唱音频数据,获得所述任一演唱者演唱所述歌曲的声音信号,这样,就将能够每个演唱者的演唱声音从合声演唱声音中分离出来了。
可选地,在本实施例的一个可能的实现方式中,在101中,具体可以实时采集所述合声音频数据。
具体地,可以采集至少两个演唱者演唱歌曲的声音信号,然后,将所述声音信号转换为合声音频数据。例如,对所述声音信号进行抽样、量化和编码处理,以获得脉冲编码调制(Pulse Code Modulation,PCM)数据。
可选地,在本实施例的一个可能的实现方式中,在101中,具体可以预先从存储设备中获取预先录制的至少两个演唱者演唱歌曲的音频文件,进而,对所述音频文件进行解码,以获得所述合声音频数据。
其中,所述音频文件可以包括现有技术中各种编码格式的音频文件,例如,动态图像专家组(Moving Picture Experts Group,MPEG)层3(MPEGLayer-3,MP3)格式音频文件、WMA(Windows Media Audio)格式音频文件、高级音频编码(Advanced Audio Coding,AAC)格式音频文件或APE格式音频文件等,本实施例对此不进行特别限定。
可以理解的是,所述存储设备可以为电脑的硬盘,或者还可以为手机的非运行内存即物理内存,例如,只读存储器(Read-Only Memory,ROM)和内存卡等,本实施例对此不进行特别限定。
可选地,在本实施例的一个可能的实现方式中,在102之前,还可以进一步获取所述任一演唱者朗读指定内容的标准音频数据,进而,则可以根据所述标准音频数据,获得所述任一演唱者的音频特征参数。
所述指定内容的选择,可以是随机选择的任意一段文字内容,或者还可以是预先指定的一段文字内容,本实施例对此不进行特别限定。
具体来说,所述音频特征参数,可以包括但不限于下列参数中的至少一项:
频率特征参数;
梅尔频率倒谱系数特征(Mel Frequency Cepstrum Coefficient,MFCC)参数;以及
基音(pitch)特征参数。
在该实现方式中,可以采用现有技术中的任何方法,根据所述标准音频数据,获得所述任一演唱者的音频特征参数,详细描述可以参见现有技术中的相关内容,此处不再赘述。
可选地,在本实施例的一个可能的实现方式中,在102中,具体可以对所述合声音频数据进行频域变换处理,以获得所述合声音频数据所对应的合声频域数据。接着,则可以根据所述任一演唱者的音频特征参数,在所述合声频域数据中,提取所述音频特征参数所对应的独唱频域数据。然后,则可以对所述独唱频域数据进行频域逆变换处理,以获得所述任一演唱者的演唱所述歌曲的独唱音频数据。
其中,所述频域变换处理可以包括但不限于傅里叶变换处理,例如,快速傅里叶变换(Fast Fourier Transform,FFT)处理。
具体来说,具体可以对所述合声音频数据进行分帧处理,以获得至少一帧音频数据。然后,则可以对所述至少一帧音频数据,进行频域变换处理,以获得每帧音频数据所对应的频域数据。例如,可以对合声音频数据按照20ms的间隔,进行分帧处理,且相邻帧之间有50%的数据重叠,以获得至少一帧音频数据。然后,则可以对所述至少一帧音频数据,进行FFT处理,以获得每帧音频数据所对应的频域数据。
接着,可以根据所述任一演唱者的音频特征参数,在每帧音频数据所对应的频域数据中,提取所述音频特征参数所对应的频域数据。假设以基音特征参数作为音频特征参数,那么,则可以在每帧音频数据所对应的频域数据中,提取基音的频率(即基频)成分,以及基频的倍频成分,将其他频率成分去除。
最后,则可以对所提取的音频特征参数所对应的频域数据进行逆FFT处理,以获得所述任一演唱者的演唱所述歌曲的独唱音频数据。
本实施例中,通过获取至少两个演唱者演唱歌曲的合声音频数据,进而根据所述至少两个演唱者中任一演唱者的音频特征参数和所述合声音频数据,获得所述任一演唱者演唱所述歌曲的独唱音频数据,使得能够根据所述独唱音频数据,获得所述任一演唱者演唱所述歌曲的声音信号,这样,就将能够每个演唱者的演唱声音从合声演唱声音中分离出来了。
需要说明的是,对于前述的各方法实施例,为了简单描述,故将其都表述为一系列的动作组合,但是本领域技术人员应该知悉,本发明并不受所描述的动作顺序的限制,因为依据本发明,某些步骤可以采用其他顺序或者同时进行。其次,本领域技术人员也应该知悉,说明书中所描述的实施例均属于优选实施例,所涉及的动作和模块并不一定是本发明所必须的。
在所述实施例中,对各个实施例的描述都各有侧重,某个实施例中没有详述的部分,可以参见其他实施例的相关描述。
实施例二
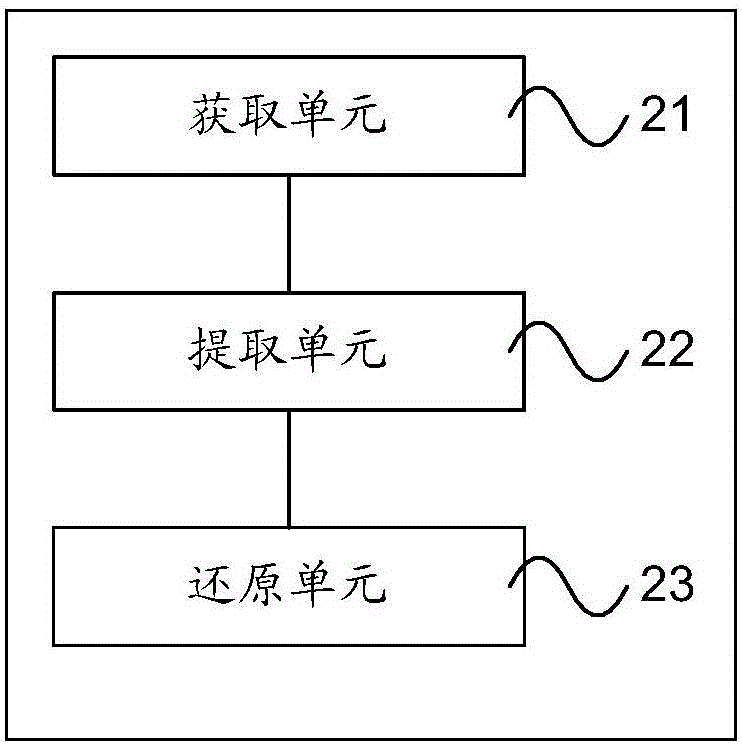
图2为本发明另一实施例提供的演唱者声音的处理装置的结构示意图,如图2所示。本实施例的演唱者声音的处理装置可以包括获取单元21、提取单元22和还原单元23。其中,获取单元21,用于获取至少两个演唱者演唱歌曲的合声音频数据;提取单元22,用于根据所述至少两个演唱者中任一演唱者的音频特征参数和所述合声音频数据,获得所述任一演唱者演唱所述歌曲的独唱音频数据;还原单元23,用于根据所述独唱音频数据,获得所述任一演唱者演唱所述歌曲的声音信号。
需要说明的是,本实施例所提供的演唱者声音的处理装置的部分或全部可以为位于本地终端的应用,或者还可以为设置在位于本地终端的应用中的插件或软件开发工具包(Software Development Kit,SDK)等功能单元,或者还可以为位于网络侧服务器中的处理引擎,或者还可以为位于网络侧的分布式系统,本实施例对此不进行特别限定。
可以理解的是,所述应用可以是安装在终端上的本地程序(nativeApp),或者还可以是终端上的浏览器的一个网页程序(webApp),本实施例对此不进行特别限定。
可选地,在本实施例的一个可能的实现方式中,所述提取单元22,还可以进一步用于根据所述至少两个演唱者中任一演唱者的音频特征参数和所述合声音频数据,获得所述任一演唱者演唱所述歌曲的独唱音频数据之前,获取所述任一演唱者朗读指定内容的标准音频数据;以及根据所述标准音频数据,获得所述任一演唱者的音频特征参数。
可选地,在本实施例的一个可能的实现方式中,所述提取单元22,所采用的所述音频特征参数,可以包括但不限于下列参数中的至少一项:
频率特征参数;
梅尔频率倒谱系数特征参数;以及
基音特征参数。
可选地,在本实施例的一个可能的实现方式中,所述提取单元22,具体可以用于对所述合声音频数据进行频域变换处理,以获得所述合声音频数据所对应的合声频域数据;根据所述任一演唱者的音频特征参数,在所述合声频域数据中,提取所述音频特征参数所对应的独唱频域数据;以及对所述独唱频域数据进行频域逆变换处理,以获得所述任一演唱者的演唱所述歌曲的独唱音频数据。
其中,所述频域变换处理可以包括但不限于傅里叶变换处理,例如,快速傅里叶变换(Fast Fourier Transform,FFT)处理。
需要说明的是,图1对应的实施例中方法,可以由本实施例提供的演唱者声音的处理装置实现。详细描述可以参见图1对应的实施例中的相关内容,此处不再赘述。
本实施例中,通过获取单元用于获取至少两个演唱者演唱歌曲的合声音频数据,进而由提取单元根据所述至少两个演唱者中任一演唱者的音频特征参数和所述合声音频数据,获得所述任一演唱者演唱所述歌曲的独唱音频数据,使得还原单元能够根据所述独唱音频数据,获得所述任一演唱者演唱所述歌曲的声音信号,这样,就将能够每个演唱者的演唱声音从合声演唱声音中分离出来了。
本领域技术人员可以理解实现上述实施例方法中的全部或部分步骤是可以通过程序来指令相关的硬件来完成,该程序存储在一个存储介质中,包括若干指令用以使得一个设备(可以是单片机,芯片等)或处理器(processor)执行本申请各个实施例所述方法的全部或部分步骤。而前述的存储介质包括:U盘、移动硬盘、只读存储器(ROM,Read-Only Memory)、随机存取存储器(RAM,Random Access Memory)、磁碟或者光盘等各种可以存储程序代码的介质。
上述说明示出并描述了本申请的若干优选实施例,但如前所述,应当理解本申请并非局限于本文所披露的形式,不应看作是对其他实施例的排除,而可用于各种其他组合、修改和环境,并能够在本文所述发明构想范围内,通过上述教导或相关领域的技术或知识进行改动。而本领域人员所进行的改动和变化不脱离本申请的精神和范围,则都应在本申请所附权利要求的保护范围内。
- 还没有人留言评论。精彩留言会获得点赞!