用于使用少量样本进行神经话音克隆的系统和方法与流程
本公开大体上涉及可以提供改善的计算机性能、特征和用途的用于计算机学习的系统和方法。更具体地,本公开涉及用于通过深度神经网络的文本转语音的系统和方法。
背景技术:
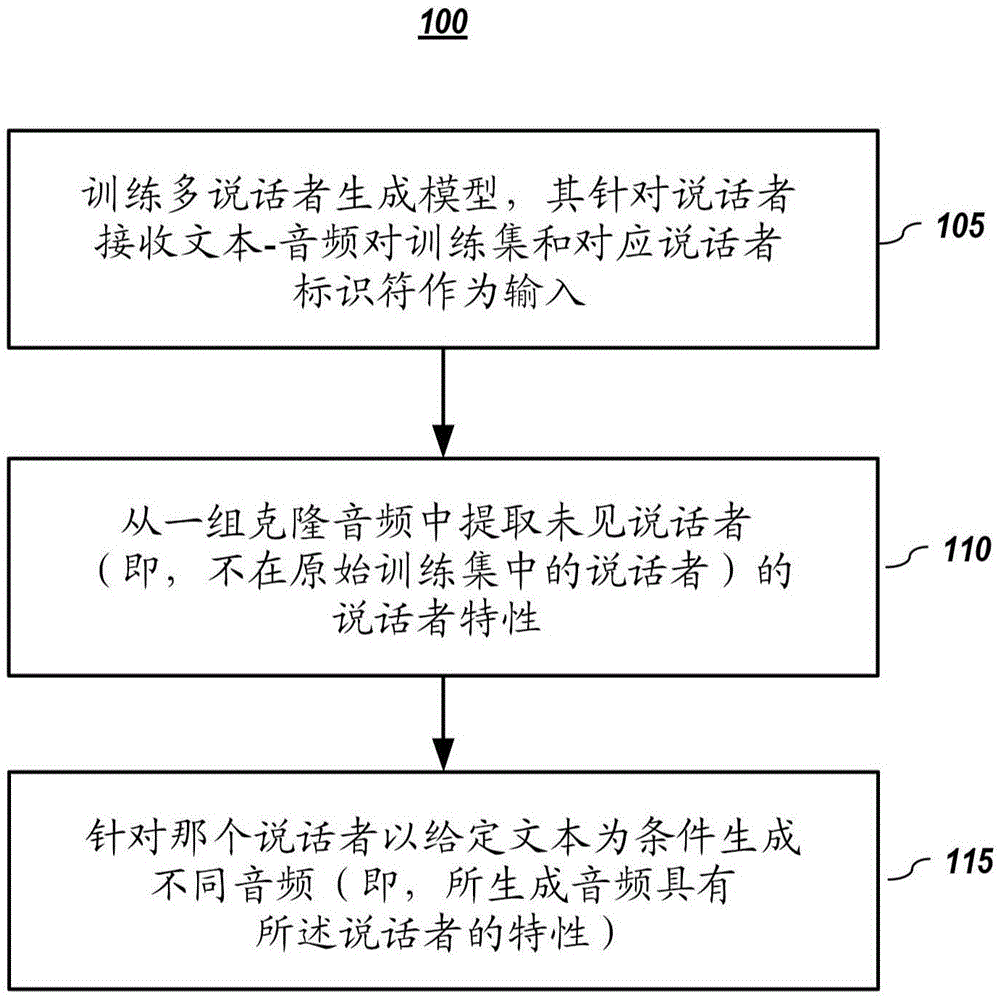
:通常被称为文本转语音(tts)系统的人工语音合成系统将书面语言转换为人类语音。tts系统用于各种应用中,诸如人机界面、视力损伤的可访问性、媒体和娱乐。根本上地,它允许无需视觉界面的人机交互。传统的tts系统基于复杂的多级人工工程管线。通常,这些系统首先将文本转换为紧凑的音频表示,然后使用称为声码器的音频波形合成方法将这种表示转换为音频。tts系统的一个目标是能够使文本输入生成听起来像具有特定音频/说话者特性的说话者的对应音频。例如,从对应于特定个体的少量数据制作听起来像那个个体的个性化语音接口(有时称为“话音克隆”)是高度所需能力。一些系统确实具有这种能力;但是,在尝试执行话音克隆的系统当中,它们通常需要大量样本来创建具有所需语音特性的自然发声语音。因此,需要可以使用非常有限数目的样本提供话音克隆的用于创建、开发且/或部署说话者文本转语音系统的系统和方法。技术实现要素:根据本申请的一方面,提供了一种用于从输入文本合成音频的计算机实施的方法,包括:给定不是用于训练多说话者生成模型的训练数据的一部分的新说话者的一组有限的一个或多个音频,使用包括第一组受训练模型参数的说话者编码器模型来在给定所述一组有限的一个或多个音频作为所述说话者编码器模型的输入的情况下针对所述新说话者获得说话者嵌入,所述说话者嵌入是说话者的语音特性的表示;以及使用包括第二组受训练模型参数的多说话者生成模型、所述输入文本和由包括所述第一组受训练模型参数的所述说话者编码器模型生成的用于所述新说话者的所述说话者嵌入来生成用于所述输入文本的合成音频表示,其中所述合成音频包括所述新说话者的语音特性,其中包括所述第二组受训练模型参数的所述多说话者生成模型是使用以下各项作为输入来针对说话者进行训练的:(1)文本-音频对训练集,其中文本-音频对包括文本和所述说话者对该文本的对应音频,以及(2)与用于该说话者的说话者标识符对应的说话者嵌入。根据本申请的另一方面,提供了一种用于从输入文本合成音频的计算机实施的方法,包括:接收不是作为用于训练多说话者生成模型的训练数据的一部分的一组有限的一个或多个文本和新说话者的对应groundtruth音频,所述训练得到用于一组说话者嵌入的说话者嵌入参数,其中说话者嵌入是说话者的说话者特性的低维表示;将所述一组有限的一个或多个文本和用于所述新说话者的对应groundtruth音频、以及包括说话者嵌入参数的所述说话者嵌入中的至少一者或多者,输入到包括受预训练模型参数或受训练模型参数的所述多说话者生成模型中;使用由所述多说话者生成模型生成的合成音频与其对应groundtruth音频的比较来调整所述说话者嵌入参数中的至少一些,以获得表示所述新说话者的说话者特性的说话者嵌入;以及使用包括受训练模型参数的所述多说话者生成模型、所述输入文本和用于所述新说话者的所述说话者嵌入来生成用于所述输入文本的合成音频表示,其中所述合成音频包括所述新说话者的说话者特性。附图说明将参考本公开的实施方式,其示例可以在附图中示出。这些图式希望为说明性的而非限制性的。虽然大体上在这些实施方式的上下文中描述本公开,但是应当理解,本公开的范围并不旨在限于这些特定实施方式。图式中的项目可能未按比例绘制。图1描绘根据本公开的实施方式的用于从一组有限的音频生成具有说话者特性的音频的示例性方法。图2描绘根据本公开的实施方式的用于从一组有限的音频样本生成具有说话者特性的音频的说话者自适应方法。图3以图形方式描绘根据本公开的实施方式的用于训练、克隆和音频生成的说话者自适应编码方法。图4描绘根据本公开的实施方式的用于从一组有限的音频样本生成具有说话者特性的音频的说话者嵌入方法的说话者自适应。图5以图形方式描绘根据本公开的实施方式的用于训练、克隆和音频生成的整模型方法的说话者自适应。图6描绘根据本公开的实施方式的用于联合训练多说话者生成模型和说话者编码模型并且接着从一组有限的音频样本针对说话者生成具有说话者特性的音频的说话者嵌入方法。图7以图形方式描绘根据本公开的实施方式的用于联合训练、克隆和音频生成的说话者嵌入方法。图8描绘根据本公开的实施方式的用于单独训练多说话者生成模型和说话者编码器模型并且接着使用受训练模型从一组有限的音频样本针对说话者生成具有说话者特性的音频的说话者嵌入方法。图9以图形方式描绘根据本公开的实施方式的用于训练、克隆和音频生成的对应说话者嵌入方法。图10描绘根据本公开的实施方式的用于单独训练多说话者生成模型和说话者编码器模型但是对所述模型进行联合微调并且接着使用受训练模型从一组有限的一个或多个音频样本针对说话者生成具有说话者特性的音频的说话者嵌入方法。图11a和图11b以图形方式描绘根据本公开的实施方式的用于训练、克隆和音频生成的说话者嵌入方法。图12以图形方式示出根据本公开的实施方式的说话者编码器架构。图13以图形方式示出根据本公开的实施方式的具有中间态维度的说话者编码器架构的更详细实施方式。图14以图形方式描绘根据本公开的实施方式的说话者验证模型架构。图15描绘根据本公开的实施方式的说话者验证等错误率(eer)(使用1个登记音频)对克隆音频样本数目。使用librispeech数据集训练多说话者生成模型和说话者验证模型。使用vctk数据集执行话音克隆。图16a描绘根据本公开的实施方式的使用1个登记音频的说话者验证等错误率(eer)对克隆音频样本数目。图16b描绘根据本公开的实施方式的使用5个登记音频的说话者验证等错误率(eer)对克隆音频样本数目。图17描绘根据本公开的实施方式的用于25个说话者的确认集的嵌入估计的平均绝对误差对克隆音频数目,其以具有注意力机制以及没有注意力机制(通过简单地求平均)示出。图18描绘根据本发明的实施方式的具有nsamples=5的说话者编码器模型的推断注意力系数对克隆音频样本的长度。图19示出根据本公开的实施方式的用于说话者自适应方法的说话者分类准确性对迭代次数。图20描绘根据本公开的实施方式的在具有不同数目的克隆样本的说话者分类准确性方面的说话者自适应方法与说话者编码方法的比较。图21描绘根据本公开的实施方式的针对不同数目的克隆样本的说话者验证(sv)等错误率(eer)(使用5个登记音频)。图22描绘根据本公开的实施方式的用于1和10样本计数的相似性得分的分布。图23描绘根据本公开的实施方式的由说话者编码器做出的估计说话者嵌入的视觉化。图24描绘根据本公开的实施方式的推断嵌入的前两个主分量,其具有用于vctk说话者的性别和口音地区的groundtruth(标注的真实数据)标签。图25描绘根据本文献的实施方式的计算装置/信息处置系统的简化框图。图26以图形方式描绘根据本公开的实施方式的示例性deepvoice3架构2600。图27描绘根据本公开的实施方式的用于使用文本转语音架构(诸如图26或图31中所描绘)的总体概述方法。图28以图形方式描绘根据本公开的实施方式的卷积块,其包括具有门控线性单元的一维(1d)卷积和残差连接。图29以图形方式描绘根据本公开的实施方式的注意力块的实施方式。图30以图形方式描绘根据本公开的实施方式的具有全连接(fc)层的示例性生成world声码器参数。图31以图形方式描绘根据本公开的实施方式的示例性详细deepvoice3模型架构。具体实施方式在以下描述中,出于解释目的,阐明具体细节以便提供对本公开的理解。然而,将对本领域的技术人员显而易见的是,可在没有这些细节的情况下实践本公开。此外,本领域的技术人员将认识到,下文描述的本公开的实施方式可以以各种方式(例如过程、装置、系统、设备或方法)在有形的计算机可读介质上实施。附图中示出的组件或模块是本公开示例性实施方式的说明,并且意图避免使本公开不清楚。还应理解,在本论述的全文中,组件可描述为单独的功能单元(可包括子单元),但是本领域的技术人员将认识到,各种组件或其部分可划分成单独组件,或者可整合在一起(包括整合在单个的系统或组件内)。应注意,本文论述的功能或操作可实施为组件。组件可以以软件、硬件、或它们的组合实施。此外,附图内的组件或系统之间的连接并不旨在限于直接连接。相反,在这些组件之间的数据可由中间组件修改、重格式化、或以其它方式改变。另外,可使用另外或更少的连接。还应注意,术语“联接”、“连接”、或“通信地联接”应理解为包括直接连接、通过一个或多个中间设备来进行的间接连接、和无线连接。在本说明书中对“一个实施方式”、“优选实施方式”、“实施方式”或“多个实施方式”的提及表示结合实施方式所描述的具体特征、结构、特性或功能包括在本公开的至少一个实施方式中,以及可包括在多于一个的实施方式中。另外,在本说明书的各个地方出现以上所提到的短语并不一定全都是指相同的实施方式或多个相同实施方式。在本说明书的各个地方使用某些术语目的在于说明,并且不应被理解为限制。服务、功能或资源并不限于单个服务、单个功能或单个资源;这些术语的使用可指代相关服务、功能或资源的可分布或聚合的分组。集合可以包括一个或多个元素。本文使用的“音频”可以以多种方式表示,包括但不限于文件(编码或原始音频文件)、信号(编码或原始音频)或听觉声波;因此,例如,生成音频或生成合成音频装置的提及意味着生成能够借助于一个或多个装置产生最终听觉声音或为最终听觉声音的内容,因此应理解为意味着上述中的任一个或多个。术语“包括”、“包括有”、“包含”和“包含有”应理解为开放性的术语,并且其后任何列出内容都是实例,而不旨在限于所列项目。本文所使用的任何标题仅是为了组织目的,并且不应被用于限制说明书或权利要求的范围。本专利文献中提到的每个参考文献以其全文通过引用并入本文。此外,本领域的技术人员应认识到:(1)某些步骤可以可选地执行;(2)步骤可不限于本文中所阐述的特定次序;(3)某些步骤可以以不同次序执行;以及(4)某些步骤可同时地进行。a.介绍1.少次性(few-shot)生成模型人类可以仅从少量例子中学习大多数新生成任务,并且其激励了对少次性生成模型进行研究。对少次性生成建模的早期研究主要集中于贝叶斯模型。已经使用分层贝叶斯模型来挖掘用于少次性字符生成的组合性和因果性。类似的想法已被修改为声学建模任务,其目标是用不同语言生成新单词。最近,深度学习方法已经适于少次性生成建模,特别是对于图像生成应用。对于条件图像生成,已经考虑使用注意力机制和元学习过程进行少次性分布估计。通过从少量观察到的字母建模字形样式并且以所估计的样式为条件合成整个字母表,少次性学习已经应用于字体样式转移。所述技术是基于多内容生成对抗网络,与groundtruth相比处罚不切实际的合成字母。顺序生成建模已经应用于使用空间注意力机制的图像生成的一次性泛化。2.语音处理中的说话者嵌入说话者嵌入是一种用于对说话者中的判别信息进行编码的方法。其已经在许多语音处理任务(诸如说话者识别/验证、说话者聚类、自动语音识别和语音合成)中使用。在其中一些任务中,模型显式地学习输出具有判别任务(诸如说话者分类)的嵌入。在其它任务中,嵌入被随机初始化并且从与说话者判别没有直接关系的目标函数隐式地学习。例如,在2018年5月8日提交的标题为“systemsandmethodsformulti-speakerneuraltext-to-speech”的共同转让的第15/974,397号美国专利申请(案卷号28888-2144)以及2017年5月19日提交的标题为“systemsandmethodsformulti-speakerneuraltext-to-speech”的共同转让的第62/508,579号美国临时专利申请(案卷号28888-2144p)(前述专利文献中的每一者完整地并且出于所有目的以引用的方式并入本文中)中,训练多说话者生成模型的实施方式以从文本生成音频,其中从生成损失函数隐式地学习说话者嵌入。3.话音转换话音转换的目标是修改来自源说话者的话语以使其听起来像目标说话者,同时保持语言内容不变。一种常见方法是动态频率翘曲,以便对齐不同说话者的频谱。一些人已经提出了动态编程算法,其使用匹配最小化算法在匹配源说话者和目标说话者时据称同时估计最佳频率翘曲和加权变换。其他人使用与局部线性嵌入集成的频谱转换方法进行流形学习。还存在用于使用神经网络建模频谱转换的方法。通常使用目标说话者和源说话者的大量音频对来训练那些模型。4.具有有限样本的话音克隆的总体介绍基于深度学习的生成模型已经被成功地应用于许多领域,诸如图像合成、音频合成和语言建模。深度神经网络能够对复杂数据分布进行建模,并且其随大训练数据很好地缩放(scale)。其可以进一步以外部输入为条件来控制高级行为,诸如规定所生成样本的内容和样式。对于语音合成,生成模型可以以文本和说话者身份为条件。文本携带语言信息并且控制所生成语音的内容,而说话者表示捕获说话者特性,诸如音高范围、语速和口音。一种用于多说话者语音合成的方法是以(文本、音频、说话者身份)三元组联合训练生成模型和说话者嵌入。用于所有说话者的嵌入可以被随机初始化并且使用生成损失来训练。在一个或多个实施方式中,一个想法是使用低维嵌入对与说话者相关的信息进行编码,同时针对所有说话者共享大部分模型参数。此类模型的一个限制是其只能为在训练期间观察到的说话者生成语音。一个更令人关注的任务是从少量语音样本学习未见说话者的话音或话音克隆。话音克隆可以在许多支持语音的应用程序中使用,以便提供个性化用户体验。在本专利文献中,实施方式解决使用来自未见说话者(即,新说话者/在训练期间未出现的说话者)的有限语音样本的话音克隆,其也可以在语音的一次性或少次性生成建模的上下文中考虑。使用大量样本,可以从头开始针对任何目标说话者训练生成模型。然而,除了具有吸引力之外,少次性生成建模还具有挑战性。生成模型应当从由一组一个或多个音频样本所提供的有限信息中学习说话者特性,并且推广到未见文本。本文提出了使用端到端神经语音合成方法的不同话音克隆实施方式,其应用具有注意力机制的序列到序列建模。在神经语音合成中,编码器将文本转换为隐藏表示,并且解码器以自回归方式估计语音的时频表示。与传统的单位选择语音合成和统计参数语音合成相比,神经语音合成倾向于具有更简单的管线并且产生更自然的语音。端到端多说话者语音合成模型可以通过生成模型的权重和说话者嵌入查找表来参数化,其中说话者嵌入查找表携带说话者特性。在本专利文献中,解决两个问题:(1)说话者嵌入能够在多大程度上捕获说话者之间的差异?;(2)能够仅使用少量样本在多大程度上针对未见说话者学习说话者嵌入?在语音自然性、说话者相似性、克隆/推断时间和模型占用空间方面公开了两种一般话音克隆方法的实施方式:(i)说话者自适应以及(ii)说话者编码。b.话音克隆图1描绘根据本公开的实施方式的用于从一组有限的音频生成具有说话者特性的音频的示例性方法。在一个或多个实施方式中,训练(105)多说话者生成模型,其针对说话者接收文本-音频对训练集和对应说话者标识符作为输入。作为说明,考虑以下多说话者生成模型:其采用文本ti,j和说话者身份si。模型中的可训练参数由w参数化,并且表示对应于si的可训练说话者嵌入。w和两者可以通过最小化损失函数l来优化,所述损失函数l处罚所生成音频与groundtruth音频之间的差异(例如,声谱图的回归损失):其中是一组说话者,是用于说话者si的文本-音频对训练集,并且ai,j是用于说话者si.的ti,j的groundtruth音频。对所有训练说话者的文本-音频对估计期望值。在一个或多个实施方式中,用于损失函数的算子通过小批量来近似。在一个或多个实施方式中,和分别用于表示经过训练的参数和嵌入。说话者嵌入已经被证明能够有效地捕获用于多说话者语音合成的说话者差异。其是说话者特性的低维连续表示。例如,2018年5月8日提交的标题为“systemsandmethodsformulti-speakerneuraltext-to-speech”的共同转让的第15/974,397号美国专利申请(案卷号28888-2144)、2017年5月19日提交的标题为“systemsandmethodsformulti-speakerneuraltext-to-speech”的共同转让的第62/508,579号美国临时专利申请(案卷号28888-2144p)、2018年8月8日提交的标题为“systemsandmethodsforneuraltext-to-speechusingconvolutionalsequencelearning”的共同转让的第16/058,265号美国专利申请(案卷号28888-2175)以及2017年10月19日提交的标题为“systemsandmethodsforneuraltext-to-speechusingconvolutionalsequencelearning”的共同转让的第62/574,382号美国临时专利申请(案卷号28888-2175p)(上述专利文献中的每一者完整地并且出于所有目的以引用的方式并入本文中)公开了多说话者生成模型的实施方式,所述实施方式可以作为说明在本文中使用,但是可以使用其它多说话者生成模型。尽管使用纯生成损失来训练,但是确实可以在嵌入空间中观察到判别性质(例如,性别或口音)。参见下面部分f,例如,多说话者生成模型的实施方式,但是可以使用其它多说话者生成模型。话音克隆旨在从一组克隆音频中提取(110)未见说话者sk(不在s中)的说话者特性以便以用于那个说话者的给定文本为条件生成(115)不同音频。可以考虑的用于所生成音频的两个性能度量是:(i)其有多么自然,以及(ii)其是否听起来像是由同一个说话者发音。在以下部分中解释用于神经话音克隆的两种一般方法(即,说话者自适应和说话者编码)的各种实施方式。1.说话者自适应在一个或多个实施方式中,说话者自适应涉及通过应用梯度下降来使用一组一个或多个音频样本和对应文本对用于未见说话者的受训练多说话者模型进行微调。微调可以应用于说话者嵌入或整个模型。a)仅说话者嵌入微调图2描绘根据本公开的实施方式的用于从一组有限的音频样本生成具有说话者特性的音频的说话者自适应方法。图3以图形方式描绘根据本公开的实施方式的用于训练、克隆和音频生成的说话者自适应编码方法。在一个或多个实施方式中,训练(205/305)多说话者生成模型335,其针对说话者接收文本-音频对训练集340和345以及对应说话者标识符325作为输入。在一个或多个实施方式中,所述多说话者生成模型可以是如上面部分b中所论述的模型。在一个或多个实施方式中,说话者嵌入是用于说话者特性的低维表示,其可以被训练。在一个或多个实施方式中,说话者身份325到说话者嵌入330的转换可以由查找表完成。在一个或多个实施方式中,受训练多说话者模型参数是固定的,但是可以针对先前未见(即,新的)说话者使用一组文本-音频对350和355来对说话者编码部分进行微调(210/310)。通过对说话者嵌入进行微调,可以生成用于这个新说话者的改善说话者嵌入。在一个或多个实施方式中,对于仅嵌入自适应,可以使用以下目标:其中是用于目标说话者sk的一组文本-音频对。在已经对说话者嵌入参数进行微调以产生用于新说话者的说话者嵌入330之后,可以针对输入文本360生成(215/315)新音频365,其中所生成音频基于说话者嵌入具有先前未见说话者的说话者特性。b)整模型微调图4描绘根据本公开的实施方式的用于从一组有限的音频样本生成具有说话者特性的音频的说话者自适应方法。图5以图形方式描绘根据本公开的实施方式的用于训练、克隆和音频生成的对应说话者自适应编码方法。在一个或多个实施方式中,训练(405/505)多说话者生成模型535,其针对说话者接收文本-音频对训练集540和545以及对应说话者标识符525作为输入。在这个预训练之后,在一个或多个实施方式中,可以针对先前未见说话者使用一组文本-音频对550和555对包括说话者嵌入参数在内的受预训练多说话者模型参数进行微调(410/510)。对整个多说话者生成模型(包括说话者嵌入参数)进行微调允许为说话者自适应提供较多自由度。对于整模型自适应,可以使用以下目标:在一个或多个实施方式中,虽然整个模型为说话者自适应提供较多自由度,但是其优化可能是具有挑战性的,尤其是对于少量克隆样本。在运行优化时,迭代次数可以对于避免欠拟合或过度拟合是重要的。在已经对多说话者生成模型535进行微调并且基于所述一组一个或多个样本来为新说话者产生说话者嵌入530之后,可以针对输入文本560生成(415/515)新音频565,其中所生成音频基于说话者嵌入具有先前未见说话者的说话者特性。2.说话者编码本文呈现的是用于直接从未见说话者的音频样本估计说话者嵌入的说话者编码实施方式方法。如上所述,在一个或多个实施方式中,说话者嵌入可以是说话者特性的低维表示,并且可以与说话者身份表示对应或相关。多说话者生成模型和说话者编码器模型的训练可以以多种方式完成,包括联合地、单独地或使用联合微调单独地训练。下文更详细地描述这些训练方法的示例性实施方式。在实施方式中,此类模型在话音克隆期间不需要任何微调。因此,相同模型可以用于所有未见说话者。a)联合训练在一个或多个实施方式中,说话者编码函数采用一组克隆音频样本并且估计所述函数可以由θ参数化。在一个或多个实施方式中,说话者编码器可以从头开始与多说话者生成模型一起联合地进行训练,其中针对所生成音频质量定义损失函数:在一个或多个实施方式中,使用用于多说话者生成模型的说话者训练说话者编码器。在训练期间,随机取样一组克隆音频样本用于训练说话者si。在推断期间,(即,来自目标说话者sk的音频样本)用于计算图6描绘根据本公开的实施方式的用于联合训练多说话者生成模型和说话者编码模型并且接着从一组有限的音频样本为说话者生成具有说话者特性的音频的说话者嵌入方法。图7以图形方式描绘根据本公开的实施方式的用于联合训练、克隆和音频生成的对应说话者嵌入方法。如图6和图7所示的实施方式中所描绘,联合训练(605/705)说话者编码器模型728(其针对说话者接收来自文本-音频对训练集740和745的一组训练音频745)以及多说话者生成模型735(其针对说话者接收文本-音频对训练集740和745以及来自说话者编码器模型728的用于所述说话者的说话者嵌入730作为输入)。对于新说话者,受训练说话者编码器模型728和一组克隆音频752被用来生成(610/710)用于新说话者的说话者嵌入755。最后,如图所示,受训练多说话者生成模型735可以用于以给定文本760和由受训练说话者编码器模型728生成的说话者嵌入755为条件生成(615/715)新音频765,使得所生成音频765具有新说话者的说话者特性。应当注意,在一个或多个实施方式中,当从头开始等式4中的训练时观察到优化挑战。主要问题是拟合平均话音以最小化整体生成损失,其通常在生成建模文献中称为模式崩溃。解决模式崩溃的一个想法是针对中间嵌入(例如,通过经由softmax层将嵌入映射到说话者类标签来使用分类损失)或者所生成音频(例如,集成受预训练说话者分类器以促进所生成音频的说话者差异)引入判别损失函数。然而,在一个或多个实施方式中,此类方法仅稍微改善了说话者差异。另一种方法是使用单独训练程序,其示例在以下部分中公开。b)多说话者模型和说话者编码模型的单独训练在一个或多个实施方式中,可以采用用于说话者编码器的单独训练程序。在一个或多个实施方式中,从受训练多说话者生成模型中提取说话者嵌入接着,可以训练说话者编码器模型以从所取样克隆音频预测嵌入。可以针对对应回归问题存在若干目标函数。在实施方式中,通过简单地使用估计嵌入与目标嵌入之间的l1损失来获得良好结果:图8描绘根据本公开的实施方式的用于单独训练多说话者生成模型和说话者编码器模型并且接着使用受训练模型从一组有限的音频样本针对说话者生成具有说话者特性的音频的说话者嵌入方法。图9以图形方式描绘根据本公开的实施方式的用于训练、克隆和音频生成的对应说话者嵌入方法。如图8和图9所示的实施方式中所描绘,训练(805a/905)多说话者生成模型935,其针对说话者接收文本-音频对训练集940和945以及对应说话者标识符925作为输入。可以作为模型935的训练的一部分训练说话者嵌入930。一组说话者克隆音频950和从受训练多说话者生成模型935获得的对应说话者嵌入可以用于训练(805b/905)说话者编码器模型928。例如,返回到图8,针对说话者,可以在训练(805b/905)说话者编码器模型928中使用一组一个或多个克隆音频952(其可以从文本-音频对训练集940和945中选择)以及对应说话者嵌入930(其可以从受训练多说话者生成模型935获得)。在已经训练说话者编码器模型928之后,针对新说话者,受训练说话者编码器模型928以及一组一个或多个克隆音频可以用于为在训练阶段(810/910)期间未见的新说话者生成说话者嵌入955。在一个或多个实施方式中,受训练多说话者生成模型935使用由受训练说话者编码器模型928生成的说话者嵌入955来以给定输入文本960为条件生成音频965,使得所生成音频具有新说话者的说话者特性(815/915)。c)使用联合微调的多说话者模型和说话者编码模型的单独训练在一个或多个实施方式中,可以组合现有方法的训练概念。例如,图10描绘根据本公开的实施方式说话者嵌入方法,其用于单独训练多说话者生成模型和说话者编码器模型,但是对所述模型进行联合微调并且接着使用受训练模型从一组有限的一个或多个音频样本为说话者生成具有说话者特性的音频。图11a和图11b以图形方式描绘根据本公开的实施方式的用于训练、克隆和音频生成的对应说话者嵌入方法。如图10、图11a和图11b所示的实施方式中所描绘,训练(1005a/1105)多说话者生成模型1135,其针对说话者接收文本-音频对训练集1140和1145以及对应说话者标识符1125作为输入。在一个或多个实施方式中,可以作为模型1135的训练的一部分训练说话者嵌入1130。一组说话者克隆音频1150和从受训练多说话者生成模型1135获得的对应说话者嵌入可以用于训练(1005b/1105)说话者编码器模型1128。例如,返回到图10,针对说话者,可以在训练(1005b/1105)说话者编码器模型1128中使用一组一个或多个克隆音频1150(其可以从文本-音频对训练集1140和1145中选择)以及对应说话者嵌入1130(其可以从受训练多说话者生成模型1135获得)。接着,在一个或多个实施方式中,可以使用其受预训练参数作为初始条件来对说话者编码器模型1128和多说话者生成模型1135进行联合微调(1005c/1105)。在一个或多个实施方式中,可以基于目标函数等式4使用受预训练和受预训练作为初始点来对整个模型(即,说话者编码器模型1128和多说话者生成模型1135)进行联合微调。微调使得生成模型能够学习如何补偿嵌入估计的误差并且产生较少注意力问题。然而,生成损失仍可能主导学习,并且所生成音频中的说话者差异可能会略微减少(详见部分c.3)。在一个或多个实施方式中,在已经训练并且微调多说话者生成模型1135和说话者编码器模型1128之后,受训练说话者编码器模型1128和用于新说话者的一组一个或多个克隆音频1152可以用于针对在训练阶段(1010/1110)期间未见的新说话者生成说话者嵌入1155。在一个或多个实施方式中,受训练多说话者生成模型1135使用由受训练说话者编码器模型1128生成的说话者嵌入1155来以给定输入文本1160为条件生成合成音频1165,使得所生成音频1165具有新说话者的说话者特性(1015/1115)。d)说话者编码器实施方式在一个或多个实施方式中,针对说话者编码器神经网络架构包括三个部分(例如,图12中示出了一个实施方式):(i)频谱处理:在一个或多个实施方式中,计算用于克隆音频样本的梅尔声谱图1205并将其传递到prenet(前网络)1210,所述prenet1210包含具有用于特征变换的指数线性单元(elu)的全连接(fc)层。(ii)时间处理:在一个或多个实施方式中,使用具有门控线性单元和残差连接的若干卷积层1220来并入时间上下文。接着,可以应用平均池化1225来概括整个话语。(iii)克隆样本注意力:考虑到不同克隆音频包含不同量的说话者信息,在一个或多个实施方式中,可以使用多头自注意力机制1230来计算不同音频的权重并且得到聚合嵌入1235。图13描绘根据本公开的实施方式的具有中间态维度的说话者编码器架构的较详细视图(batch:批次大小,nsamples:克隆音频样本的数目,t:梅尔声谱图时间帧的数目,fmel:梅尔频率信道的数目,fmapped:在prenet之后的频率信道的数目,dembedding:说话者嵌入维度)。在所描绘的实施方式中,最后一层处的乘法运算代表沿着克隆样本的维度的内积。3.用于评估的判别模型实施方式话音克隆性能度量可以基于通过众包平台的人类评估,但是其在模型开发期间往往是缓慢且昂贵的。相反,使用本文呈现的使用判别模型的两种评估方法。a)说话者分类说话者分类器确定音频样本属于哪个说话者。针对话音克隆评估,可以在用于克隆的目标说话者集合上训练说话者分类器。高质量话音克隆将导致高说话者分类准确性。可以使用具有图13所示的类似频谱处理层和时间处理层以及在softmax函数之前的额外嵌入层的说话者分类器。b)说话者验证说话者验证是基于来自说话者的测试音频和登记音频来鉴定说话者的声称身份的任务。明确地说,其执行二元分类以识别测试音频和登记音频是否来自同一说话者。在一个或多个实施方式中,可以使用端到端文本无关说话者验证模型。可以在多说话者数据集上训练说话者验证模型,接着可以直接测试克隆音频和groundtruth音频是否来自同一说话者。与说话者分类方法不同,说话者验证模型实施方式不需要使用来自用于克隆的目标说话者的音频进行训练,因此其可以用于具有少量样本的未见说话者。作为定量性能度量,可以使用等错误率(eer)来测量克隆音频与groundtruth音频的接近程度。应当注意,在一个或多个实施方式中,可以改变判定阈值以在错误接受率与错误拒绝率之间进行权衡。等错误率是指当所述两个比率相等时的点。说话者验证模型实施方式。给定一组(例如,1至5个)登记音频(登记音频来自同一说话者)和测试音频,说话者验证模型执行二元分类并且告知登记音频和测试音频是否来自同一说话者。虽然使用其它说话者验证模型就已足够,但是可以使用卷积-循环架构来创建说话者验证模型实施方式,诸如2015年11月25日提交的标题为“deepspeech2:end-to-endspeechrecognitioninenglishandmandarin”的共同转让的第62/260,206号美国临时专利申请(案卷号28888-1990p)、2016年11月21日提交的标题为“end-to-endspeechrecognition”的共同转让的第15/358,120号美国专利申请(案卷号28888-1990(bn151203usn1))以及2016年11月21日提交的标题为“deployedend-to-endspeechrecognition”的共同转让的第15/358,083号美国专利申请(案卷号28888-2078(bn151203usn1-1))中所描述的架构,前述专利文献中的每一者均完整地并且出于所有目的以引用的方式并入本文中。应当注意,未见说话者测试集上的等错误率结果与最先进的说话者验证模型同等水平。图14以图形方式描绘根据本公开的实施方式的模型架构。在一个或多个实施方式中,在将输入重新取样到恒定取样频率之后计算登记音频1405和测试音频1410的梅尔缩放声谱图1415、1420。接着,应用在时间和频带两者上卷积的二维卷积层1425,在每个卷积层之后具有批量归一化1430和修正线性单元(relu)非线性度1435。最后卷积块1438的输出被馈送到循环层(例如,门控循环单元(gru))1440中。随时间执行均值池化1445(并且如果有很多,则对登记音频执行),接着应用全连接层1450以获得用于登记音频和测试音频两者的说话者编码。概率线性判别分析(plda)1455可以用于对两种编码之间的相似性进行评分。plda得分可以被定义为:s(x,y)=w·xty–xtsx–ytsy+b(6)其中x和y是在全连接层之后的(分别)登记音频和测试音频的说话者编码,w和b是标量参数,并且s是对称矩阵。接着,可以将s(x,y)馈送到s形单元1460中以获得它们来自同一说话者的概率。可以使用交叉熵损失来训练模型。表1列出了根据本公开的实施方式的用于librispeech数据集的说话者验证模型的超参数。表1.用于librispeech数据集的说话者验证模型的超参数。参数音频重新取样频率16khz梅尔声谱图的频带80跳跃长度400卷积层、通道、滤波器、步幅1,64,20×5,8,×2循环层大小128全连接大小128丢弃概率0.9学习率10–3最大梯度范数100梯度裁剪最大值5除了此处所呈现的说话者验证测试结果(见图21)之外,还包括当在librispeech上训练多说话者生成模型时使用1个登记音频的结果。图15描绘根据本公开的实施方式的说话者验证等错误率(eer)(使用1个登记音频)对克隆音频样本数目。使用librispeech数据集训练多说话者生成模型和说话者验证模型。使用vctk数据集执行话音克隆。当在vctk上训练多说话者生成模型时,结果在图16a和图16b中。应当注意,克隆音频上的eer可以比在groundtruthvctk上可能更好,因为说话者验证模型是在librispeech数据集上训练的。图16a描绘根据本公开的实施方式的使用1个登记音频的说话者验证等错误率(eer)对克隆音频样本数目。图16b描绘根据本公开的实施方式的使用5个登记音频的说话者验证等错误率(eer)对克隆音频样本数目。在vctk数据集的包括84个说话者的子集上训练多说话者生成模型,并且在其他16个说话者上执行话音克隆。使用librispeech数据集训练说话者验证模型。c.实验应当注意,这些实验和结果是作为说明来提供的,并且是在特定条件下使用一个或多个特定实施方式执行的;因此,这些实验及其结果都不应该用于限制本专利文献的公开内容的范围。比较了用于话音克隆的两种方法的实施方式。对于说话者自适应方法,通过对嵌入或整个模型进行微调来训练多说话者生成模型并使其适于目标说话者。对于说话者编码方法,训练了说话者编码器,并且在具有和没有联合微调的情况下对其进行评估。1.数据集在第一组实验(部分c.3和c.4)中,使用librispeech数据集训练多说话者生成模型实施方式和说话者编码器模型实施方式,所述librispeech数据集包含以16khz取样的用于2484个说话者的音频,总计820小时。librispeech是用于自动语音识别的数据集,并且与语音合成数据集相比,其音频质量较低。在实施方式中,如共同转让的第62/574,382号美国临时专利申请(案卷号28888-2175p)和第16/058,265号美国专利申请(其均已经完整地并且出于所有目的以引用的方式并入本文中)中所描述,设计并采用分割和去噪管线以处理librispeech。使用vctk数据集执行话音克隆。vctk由以48khz取样的具有各种口音的108个英语母语说话者的音频构成。为了与librispeech数据集一致,将vctk音频样本下取样到16khz。对于选定说话者,针对每个实验随机取样少量克隆音频。下一段中所提出的测试句子用于生成用于评估的音频。测试句子(下面的句子用于针对话音克隆模型实施方式生成测试样本。空白字符、/和%指示说话者在单词之间插入的停顿的持续时间。使用四种不同单词分隔符,指示:(i)含糊不清连在一起的单词,(ii)标准发音和间隔字符,(iii)单词之间的短暂停顿,以及(iv)单词之间的长时间停顿。例如,在“way”之后具有长时间停顿并且在“shoot”之后具有短暂停顿的句子“eitherway,youshouldshootveryslowly”将被写为“eitherway%youshouldshoot/veryslowly%”,其中为了编码方便起见,%表示长时间停顿并且/表示短暂停顿。):prosecutorshaveopenedamassiveinvestigation/intoallegationsof/fixinggames/andillegalbetting%.differenttelescopedesigns/performdifferently%andhavedifferentstrengths/andweaknesses%.wecancontinuetostrengthentheeducationofgoodlawyers%.feedbackmustbetimely/andaccurate/throughouttheproject%.humansalsojudgedistance/byusingtherelativesizesofobjects%.churchesshouldnotencourageit%ormakeitlookharmless%.learnabout/settingup/wirelessnetworkconfiguration%.youcaneatthemfreshcooked%orfermented%.ifthisistrue%thenthose/whotendtothinkcreatively%reallyaresomehowdifferent%.shewilllikelyjumpforjoy%andwanttoskipstraighttothehoneymoon%.thesugarsyrup/shouldcreateveryfinestrandsofsugar%thatdrapeoverthehandles%.butreallyinthegrandschemeofthings%thisinformationisinsignificant%.iletthepositive/overrulethenegative%.hewipedhisbrow/withhisforearm%.insteadoffixingit%theygiveitanickname%.abouthalfthepeople%whoareinfected%alsoloseweight%.thesecondhalfofthebook%focusesonargument/andessaywriting%.wehavethemeans/tohelpourselves%.thelargeitems/areputintocontainers/fordisposal%.helovesto/watchme/drinkthisstuff%.still%itisanoddfashionchoice%.fundingisalwaysanissue/afterthefact%.letus/encourageeachother%.在第二组实验(部分c.5)中,研究了训练数据集的影响。使用vctk数据集-84个说话者用于训练多说话者生成模型,8个说话者用于确认,并且16个说话者用于克隆。2.模型实施方式详述a)多说话者生成模型实施方式受测试多说话者生成模型实施方式是基于共同转让的第62/574,382号美国临时专利申请(案卷号28888-2175p)和第6/058,265号美国专利申请(其均完整地并且出于所有目的以引用的方式并入本文中)中所公开的卷积序列到序列架构,其具有相同或相似的超参数和griffin-lim声码器。为了获得较好性能,通过将跳跃长度和窗口大小参数减小到300和1200来增大时间分辨率,并且添加二次损失项以超线性地处罚较大幅度分量。对于说话者自适应实验,嵌入维数减少到128,因为其产生较少过度拟合问题。总体而言,基线多说话者生成模型实施方式在针对librispeech数据集进行训练时具有大约25m个可训练参数。对于第二组实验,共同转让的第62/574,382号美国临时专利申请(案卷号28888-2175p)和第16/058,265号美国专利申请(上文提到并且以引用的方式并入本文中)中的vctk模型的超参数用于训练用于vtck的84个说话者的多说话者模型,其具有griffin-lim声码器。b)说话者自适应对于说话者自适应方法,对整个多说话者生成模型参数或仅对其说话者嵌入进行微调。对于这两种情况,单独地针对每个说话者应用优化。c)说话者编码器模型在一个或多个实施方式中,单独地针对不同数目的克隆音频训练说话者编码器,以获得最小确认损失。最初,将克隆音频转换为具有80个频带的对数梅尔声谱图,其跳跃长度为400,窗口大小为1600。将对数梅尔声谱图馈送到频谱处理层,其包括大小为128的2层prenet。接着,使用两个1维卷积层施加时间处理,其滤波器宽度为12。最后,针对键、查询和值使用2个头和为128的单元大小施加多头注意力。最终嵌入大小为512。为了构造确认集,从训练集中提出25个说话者。在训练时使用为64的批量大小,其中初始学习率为0.0006,每8000次迭代应用为0.6的退火率。确认集的平均绝对误差在图17中示出。图17描绘根据本公开的实施方式的在具有注意力机制以及没有注意力机制(通过简单地求平均)的情况下示出的用于25个说话者的确认集的嵌入估计的平均绝对误差对克隆音频数目。较多克隆音频往往会导致较准确的说话者嵌入估计,尤其是具有注意力机制。注意力的一些含义。对于受训练说话者编码器模型,图18例示针对不同音频长度的注意力分布。图18描绘根据本发明的实施方式的用于具有nsamples=5的说话者编码器模型的推断注意力系数对克隆音频样本的长度。虚线对应于对所有克隆音频样本求平均值的情况。注意力机制可以产生高度非均匀分布的系数,同时组合不同克隆样本中的信息,并且尤其向较长音频指派较高系数,如由于其中可能存在较多信息内容而直观地预期。d)说话者分类模型在vctk数据集上训练说话者分类器实施方式以对音频样本属于108个说话者中的哪一者进行分类。说话者分类器实施方式具有大小为256的全连接层、具有256个宽度为4的滤波器的6个卷积层以及大小为32的最终嵌入层。所述模型针对大小为512的确认集实现100%准确性。e)说话者验证模型在librispeech数据集上训练说话者验证模型实施方式以测量与来自未见说话者的groundtruth音频相比的克隆音频的质量。从librispeech提出五十(50)个说话者作为用于未见说话者的确认集。通过在测试集中随机配对来自相同或不同说话者(每种情况为50%)的话语来估计等错误率(eer)。针对每个测试集执行40,960次试验。上文在部分b.3.b(说话者验证)中描述了说话者验证模型实施方式的细节。3.话音克隆性能对于说话者自适应方法实施方式,使用说话者分类准确性选择最佳迭代次数。对于整模型自适应实施方式,迭代次数针对1、2和3个克隆音频样本被选择为100,针对5和10个克隆音频样本被选择为1000。对于说话者嵌入自适应实施方式,迭代次数针对所有情况被固定为100k。对于说话者编码,在具有和没有说话者编码器和多说话者生成模型实施方式的联合微调的情况下考虑话音克隆。针对联合微调优化学习率和退火参数。表2总结所述方法并且列出用于训练、数据、克隆时间和占用空间大小的要求。表2.用于说话者自适应和说话者编码的要求的比较。克隆时间间隔采用1至10个克隆音频。推断时间是针对普通句子而言。全部假设在由位于加利福尼亚州圣克拉拉的nvidia公司出产的titanxgpu上实施。a)通过判别模型进行评估图19描绘根据本公开的实施方式的在用于108个vctk说话者的说话者分类准确性方面的用于话音克隆的整模型自适应和说话者嵌入自适应实施方式的性能。评估了不同数目的克隆样本和微调迭代。对于说话者自适应方法,图19示出说话者分类准确性对迭代次数。对于这两种自适应方法,分类准确性随着更多样本(多达十个样本)而显著增加。在低样本计数方案中,比起调整整个模型,调整说话者嵌入不太可能过度拟合样本。这两种方法还需要不同的迭代次数来收敛。与整模型自适应(其针对甚至100个克隆音频样本收敛大约1000次迭代)相比,嵌入自适应采用显著更多的迭代来收敛。图20和图21示出由说话者分类模型和说话者验证模型获得的分类准确性和eer。图20描绘根据本公开的实施方式的在具有不同数目的克隆样本的说话者分类准确性方面的说话者自适应方法与说话者编码方法的比较。图21描绘根据本公开的实施方式的针对不同数目的克隆样本的说话者验证(sv)eer(使用5个登记音频)。评估设置可以在部分c.2.e中找到。librispeech(未见说话者)和vctk分别代表从来自groundtruth数据集的话语的随机配对中估算出的eer。说话者自适应实施方式和说话者编码实施方式两者均受益于更多克隆音频。当克隆音频样本的数目超过五时,整模型适应性在两个度量中都胜过其它技术。与嵌入自适应相比,说话者编码方法产生较低分类准确性,但是它们实现类似的说话者验证性能。b)人类评估除了通过判别模型进行评估之外,还对amazonmechanicalturk框架进行主题测试。为了评估所生成音频的自然性,使用5级平均意见得分(mos)。为了评估所生成音频与来自目标说话者的groundtruth音频有多相似,使用mirjamwester等人的“analysisofthevoiceconversionchallenge2016evaluation”(在interspeech中,第1637至1641页,2016年9月)(下文中称为“wester等人(2016年)”)(其全部内容以引用的方式并入本文中)中的使用相同问题和类别的4级相似性评分。每个评估都是独立进行的,所以在评级期间不会直接比较两种不同模型的克隆音频。通过多数投票规则合计对同一样本的多次投票。表3和表4示出人类评估的结果。一般来说,较高数目的克隆音频改善了这两个度量。由于为未见说话者提供更多自由度,因此如预期那样改善对整模型自适应更为显著。在具有较多克隆音频的情况下对于说话者编码方法在自然性上存在非常微小的差异。最重要的是,说话者编码没有使基线多说话者生成模型的自然性降级。微调如预期那样改善了说话者编码的自然性,因为其允许生成模型学习如何在训练时补偿说话者编码器的错误。相似性得分在具有用于说话者编码的较高样本计数的情况下略有改善,并且与用于说话者嵌入自适应的得分相匹配。与groundtruth的相似性的差距也部分地归因于输出的有限自然性(因为它们是使用librispeech数据集来训练的)。表3.具有95%置信区间的自然性的平均意见得分(mos)评估(当使用librispeech数据集进行训练并且使用vctk数据集的108个说话者进行克隆时)。表4.具有95%置信区间的相似性得分评估(当使用librispeech数据集进行训练并且使用vctk数据集的108个说话者进行克隆时)。相似性得分。对于表4中的结果,图22示出如在wester等人(2016年)(上文引用)中由mturk用户给出的得分的分布。对于10样本计数,具有“同一说话者”等级的评估的比率对于所有模型均超过70%。4.说话者嵌入空间和操纵本公开的说话者嵌入能够进行说话者嵌入空间表示并且能够操纵以改变语音特性,所述操纵也可以称为话音变形。如图23以及本部分的其它地方所示,说话者编码器模型将说话者映射到有意义的潜在空间中。图23描绘根据本公开的实施方式的由说话者编码器做出的估计说话者嵌入的视觉化。描绘了具有5样本计数的用于说话者编码器的平均说话者嵌入的前两个主分量。仅示出英国和北美地区口音,因为它们构成了vctk数据集中的大多数标记说话者。受到单词嵌入操纵的启发(例如,为了将简单代数运算的存在演示为君王-女王=男-女),将代数运算应用于所推断的嵌入以变换其语音特性。为了变换性别,获得用于女性和男性的平均说话者嵌入并且将其差异添加到特定说话者。例如:英国男性+平均女性-平均男性可以产生英国女性说话者。同样,口音地区可以通过例如以下方式进行变换:英国男性+平均美国-平均英国以获得美国男性说话者。这些结果演示了以此方式获得的具有特定性别和口音特性的高质量音频。由编码器学习的说话者嵌入空间。为了分析由受训练说话者编码器学习的说话者嵌入空间,将主分量分析应用于推断嵌入的空间,并且从vctk数据集针对性别和口音地区考虑其groundtruth标签。图24示出根据本公开的实施方式的前两个主分量的视觉化。观察到,说话者编码器将克隆音频映射到具有高度有意义的判别模式的潜在空间。特别是对于性别,来自所学习的说话者嵌入的一维线性变换可以实现非常高的判别准确性-但是所述模型在训练时从未看到groundtruth性别标签。5.训练数据集的影响为了评估训练数据集的影响,当训练是基于vctk的包含84个说话者的子集时还考虑话音克隆设置,其中另外8个说话者用于确认且16个说话者用于测试。由于训练说话者有限,受测试说话者编码器模型实施方式对未见说话者的概括不佳。表5和表6呈现说话者自适应方法的人类评估结果。说话者验证结果在图16a和图16b中示出。仅嵌入自适应实施方式与整模型自适应实施方式之间的显著性能差异强调了训练说话者的多样性的重要性,同时将说话者判别信息并入到嵌入中。表5.具有95%置信区间的自然性的平均意见得分(mos)评估(当使用vctk数据集的84个说话者进行训练并且使用vctk数据集的16个说话者进行克隆时)。表6.具有95%置信区间的相似性得分评估(当使用vctk数据集的84个说话者进行训练并且使用vctk数据集的16个说话者进行克隆时)。d.一些结论本文提出了用于神经话音克隆的两种一般方法:说话者自适应和说话者编码。已经证明,即使仅使用少量克隆音频,这两种方法的实施方式也实现良好克隆质量。对于自然性,此处表明说话者自适应实施方式和说话者编码实施方式两者均实现与基线多说话者生成模型相似的自然性mos。因此,可以使用其它多说话者模型获得改善结果。对于相似性,证明这两种方法的实施方式均受益于较多数目的克隆音频。整模型自适应实施方式与仅嵌入自适应实施方式之间的性能差距指示除了说话者嵌入之外在生成模型中仍存在一些判别说话者信息。经由嵌入进行紧凑表示的一个好处是快速克隆并且每个用户的占用空间较小。特别是对于资源有限的应用,这些实际考虑应当明显倾向于使用说话者编码方法。观察到使用具有低质量音频的语音识别数据集以及说话者全集的表示的有限多样性训练多说话者生成模型实施方式的缺点。数据集质量的改善导致所生成样本具有更高自然性和相似性。而且,增加说话者的数量和多样性往往会使得能够实现更有意义的说话者嵌入空间,这可以改善由这两种方法的实施方式获得的相似性。这两种技术的实施方式可以受益于大规模且高质量的多说话者语音数据集。e.计算系统实施方式在实施方式中,本专利文献的方面可涉及、可包括一个或多个信息处理系统/计算系统或者可在一个或多个信息处理系统/计算系统上实施。计算系统可包括可操作来计算、运算、确定、分类、处理、传输、接收、检索、发起、路由、交换、存储、显示、通信、显现、检测、记录、再现、处理或利用任何形式信息、智能或数据的任何手段或手段的组合。例如,计算系统可为或可包括个人计算机(例如,膝上型计算机)、平板电脑、平板手机、个人数字助理(pda)、智能手机、智能手表、智能包装、服务器(例如,刀片式服务器或机架式服务器)、网络存储设备、摄像机或任何其他合适设备,并且可在大小、形状、性能、功能和价格方面改变。计算系统可包括随机存取存储器(ram)、一个或多个处理资源(例如中央处理单元(cpu)或硬件或软件控制逻辑)、rom和/或其他类型的存储器。计算系统的另外组件可包括一个或多个盘驱动器、用于与外部设备通信的一个或多个网络端口、以及各种输入和输出(i/o)设备(例如键盘、鼠标、触摸屏和/或视频显示器)。计算系统还可包括可操作为在各种硬件组件之间传输通信的一个或多个总线。图25描绘根据本公开的实施方式的计算设备/信息处理系统(或是计算系统)的简化框图。应理解,计算系统可不同地配置并且包括不同组件,包括如图25中所示的更少或更多的部件,但应理解,针对系统2500所示出的功能可操作为支持计算系统的各种实施方式。如图25所示,计算系统2500包括一个或多个中央处理单元(cpu)2501,cpu2501提供计算资源并控制计算机。cpu2501可实施有微处理器等,并且还可包括一个或多个图形处理单元(gpu)2519和/或用于数学计算的浮点协处理器。系统2500还可包括系统存储器2502,系统存储器2502可呈随机存取存储器(ram)、只读存储器(rom)、或两者的形式。如图25所示,还可提供多个控制器和外围设备。输入控制器2503表示至各种输入设备2504的接口,例如键盘、鼠标、触摸屏和/或触笔。计算系统2500还可包括存储控制器2507,该存储控制器2507用于与一个或多个存储设备2508对接,存储设备中的每个包括存储介质(诸如磁带或盘)或光学介质(其可用于记录用于操作系统、实用工具和应用程序的指令的程序,它们可包括实施本公开的各方面的程序的实施方式)。存储设备2508还可用于存储经处理的数据或是将要根据本公开处理的数据。系统2500还可包括显示控制器2509,该显示控制器2509用于为显示设备2511提供接口,显示设备2511可为阴极射线管(crt)、薄膜晶体管(tft)显示器、有机发光二极管、电致发光面板、等离子面板或其他类型的显示器。计算系统2500还可包括用于一个或多个外围设备2506的一个或多个外围控制器或接口2505。外围设备的示例可包括一个或多个打印机、扫描仪、输入设备、输出设备、传感器等。通信控制器2514可与一个或多个通信设备2515对接,这使系统2500能够通过各种网络(包括互联网、云资源(例如以太云、经以太网的光纤通道(fcoe)/数据中心桥接(dcb)云等)、局域网(lan)、广域网(wan)、存储区域网络(san))中的任一网络,或通过任何合适电磁载波信号(包括红外信号)来连接至远程设备。在示出的系统中,所有主要系统组件可连接至总线2516,总线2516可表示多于一个的物理总线。然而,各种系统组件可在物理上彼此接近或可不在物理上彼此接近。例如,输入数据和/或输出数据可远程地从一个物理位置传输到另一物理位置。另外,实现本公开的各方面的程序可经由网络从远程位置(例如,服务器)访问。此类数据和/或程序可通过各种机器可读介质中的任一机器可读介质来传送,机器可读介质包括但不限于:诸如硬盘、软盘和磁带的磁性介质;诸如cd-rom和全息设备的光学介质;磁光介质;以及硬件设备,该硬件设备专门被配置成存储或存储并执行程序代码,该硬件设备例如专用集成电路(asic)、可编程逻辑器件(pld)、闪存设备、以及rom和ram设备。f.多说话者生成模型实施方式此处提出用于语音合成的新颖全卷积架构实施方式。将实施方式缩放到非常大的音频数据集,并且解决了在尝试部署基于注意力的文本转语音(tts)系统时出现的若干现实问题。公开了全卷积字符到声谱图架构实施方式,其实现完全并行计算并且比使用循环单元的类似架构快一个数量级进行训练。为了方便起见,架构实施方式通常可以在本文中称为deepvoice3或dv3。1.模型架构实施方式在这个部分中,呈现用于tts的全卷积序列到序列架构的实施方式。架构实施方式能够将多种文本特征(例如,字符、音素、重音)转换为多种声码器参数,例如,梅尔频带声谱图、线性标度对数幅度声谱图、基本频率、频谱包络和非周期性参数。这些声码器参数可以用作用于音频波形合成模型的输入。在一个或多个实施方式中,deepvoice3架构包括三个部件:-编码器:一种全卷积编码器,其将文本特征转换为内部所学表示。-解码器:一种全卷积因果解码器,其以自回归方式使用多跳卷积注意力机制将所学表示解码为低维音频表示(梅尔频带声谱图)。-转换器:一种全卷积后处理网络,其从解码器隐藏状态预测最终声码器参数(取决于声码器选择)。与解码器不同,转换器是非因果的,并且因此可以依赖于未来上下文信息。图26以图形方式描绘根据本公开的实施方式的示例性deepvoice3架构2600。在实施方式中,deepvoice3架构2600使用编码器2605中的残差卷积层来将文本编码为用于基于注意力的解码器2630的每时间步键和值向量2620。在一个或多个实施方式中,解码器2630使用这些来预测对应于输出音频的梅尔标度对数幅度声谱图2642。在图26中,虚线箭头2646描绘在推断期间的自回归合成过程(在训练期间,使用来自对应于输入文本的groundtruth音频的梅尔声谱图帧)。在一个或多个实施方式中,接着将解码器2630的隐藏状态馈送到转换器网络2650以预测用于波形合成的声码器参数以便产生输出波2660。部分f.2.(其包括以图形方式描绘根据本公开的实施方式的示例性详细模型架构的图31)提供额外细节。在一个或多个实施方式中,待优化的总体目标函数可以是来自解码器(部分f.1.e)和转换器(部分f.1.f)的损失的线性组合。在一个或多个实施方式中,解码器2630和转换器2650是分开的并且应用多任务训练,因为其使得注意力学习在实践中更容易。具体地说,在一个或多个实施方式中,梅尔声谱图预测的损失引导注意力机制的训练,因为除了声码器参数预测之外还利用来自梅尔声谱图预测的梯度(例如,使用用于梅尔声谱图的l1损失)训练注意力。在多说话者场景中,跨编码器2605、解码器2630和转换器2650使用可训练说话者嵌入2670。图27描绘根据本公开的实施方式的用于使用文本转语音架构(诸如图26或图31中所描绘)的一般概述方法。在一个或多个实施方式中,使用诸如文本嵌入模型2610等嵌入模型将输入文本转换(2705)为可训练嵌入表示。使用编码器网络2605将嵌入表示转换(2710)为注意力键表示2620和注意力值表示2620,所述编码器网络2605包括一个或多个卷积块2616的系列2614。这些注意力键表示2620和注意力值表示2620由基于注意力的解码器网络使用,所述基于注意力的解码器网络包括一个或多个解码器块2634的系列2634,其中解码器块2634包括生成查询2638的卷积块2636和注意力块2640,以生成(2715)输入文本的低维音频表示(例如,2642)。在一个或多个实施方式中,输入文本的低维音频表示可以通过后处理网络(例如,2650a/2652a、2650b/2652b或2652c)经历额外处理,所述后处理网络预测(2720)输入文本的最终音频合成。如上文提到,可以在所述过程中使用说话者嵌入2670以致使合成音频2660展现与说话者标识符或说话者嵌入相关联的一个或多个音频特性(例如,男性话音、女性话音、特定口音等)。接下来,更详细地描述这些部件中的每一者和数据处理。示例性模型超参数可以在表7(下文)中获得。a)文本预处理文本预处理可以对良好性能为重要的。馈送原始文本(具有间隔和标点符号的字符)在许多话语上产生可接受的性能。然而,一些话语可能会对生僻单词错误发音,或者可能会产生跳过的单词和重复的单词。在一个或多个实施方式中,可以通过如下对输入文本进行归一化来减轻这些问题:1.用大写字母书写输入文本中的所有字符。2.移除所有中间标点符号。3.使用句号或问号结束每个话语。4.使用指示说话者在单词之间插入的停顿的持续时间的特殊分隔符字符替换单词之间的空格。在一个或多个实施方式中,可以使用四种不同单词分隔符,如上文论述。在一个或多个实施方式中,停顿持续时间可以通过手动标记来获得或由文本-音频对准器估计。b)字符与音素的联合表示在一个或多个实施方式中,部署的tts系统应当优选地包括用于修改发音以校正常见错误(其通常涉及例如专有名词、外来单词和特定领域的行话)的方式。这样做的常规方式是维护词典以将单词映射到其语音表示。在一个或多个实施方式中,模型可以直接将字符(包括标点符号和间隔)转换为声学特征,并且因此学习隐式字素到音素模型。当模型出错时,这种隐式转换会很难校正。因此,除了字符模型之外,在一个或多个实施方式中,可以通过显式地允许音素输入选项来训练仅音素模型和/或混合字符与音素模型。在一个或多个实施方式中,除了编码器的输入层有时接收音素和音素重音嵌入而不是字符嵌入之外,这些模型可以与仅字符模型相同。在一个或多个实施方式中,仅音素模型需要预处理步骤以将单词转换为其音素表示(例如,通过使用外部音素词典或单独训练的字素到音素模型)。对于实施方式,使用卡耐基梅隆大学发音词典cmudict0.6b。在一个或多个实施方式中,除了针对不在音素词典中的单词之外,混合字符与音素模型需要类似的预处理步骤。这些词表外/词典外单词可以作为字符输入,从而允许模型使用其隐式学习到的字素到音素模型。在训练混合字符与音素模型时,在每次训练迭代时以某固定概率将每个单词用其音素表示替换。结果发现,这改善发音准确性并且使注意力错误最小化,特别是当推广到比在训练期间见到的话语长的话语时。更重要的是,支持音素表示的模型允许使用音素词典校正错误发音,这是部署系统的所需特征。在一个或多个实施方式中,文本嵌入模型2610可以包括仅音素模型和/或混合字符与音素模型。c)用于顺序处理的卷积块通过提供足够大的感受野,堆叠卷积层可以利用序列中的长期上下文信息而不会在计算中引入任何顺序依赖性。在一个或多个实施方式中,卷积块用作主要顺序处理单元以对文本和音频的隐藏表示进行编码。图28以图形方式描绘根据本公开的实施方式的卷积块,其包括具有门控线性单元的一维(1d)卷积和残差连接。在一个或多个实施方式中,卷积块2800包括一维(1d)卷积滤波器2810、作为可学习非线性的门控线性单元2815、去往输入2805的残差连接2820以及缩放因子2825。在所描绘的实施方式中,缩放因子为但是可以使用不同值。缩放因子帮助确保在训练早期保留输入方差。在图28所描绘的实施方式中,c(2830)表示输入2805的维数,并且大小为2·c(2835)的卷积输出可以被分裂2840成相等大小的部分:门向量2845和输入向量2850。门控线性单元为梯度流提供线性路径,这减轻了堆叠卷积块的消失梯度问题,同时保持了非线性。在一个或多个实施方式中,为了引入与说话者相关的控制,在softsign函数之后,可以将与说话者相关的嵌入2855作为偏置添加到卷积滤波器输出。在一个或多个实施方式中,使用softsign非线性,因为其限制了输出的范围,同时还避免了基于指数的非线性有时展现出来的饱和问题。在一个或多个实施方式中,在整个网络中使用零均值和单位方差激活来初始化卷积滤波器权重。架构中的卷积可以是非因果的(例如,在编码器2605/3105和转换器2650/3150中)或因果的(例如,在解码器2630/3130中)。在一个或多个实施方式中,为了保持序列长度,针对因果卷积在左边用k-1个零时间步填补输入,并且针对非因果卷积在左边和右边用(k-1)/2个零时间步填补输入,其中k是奇数卷积滤波器宽度(在实施方式中,奇数卷积宽度用于简化卷积算术,但是可以使用偶数卷积宽度和偶数k值)。在一个或多个实施方式中,在卷积之前将丢弃2860应用于输入以进行规则化。d)编码器在一个或多个实施方式中,编码器网络(例如,编码器2605/3105)以嵌入层开始,所述嵌入层将字符或音素转换为可训练向量表示he。在一个或多个实施方式中,这些嵌入he首先经由全连接层从嵌入维度投影到目标维数。接着,在一个或多个实施方式中,通过一系列卷积块(诸如部分f.1.c中所描述的实施方式)对其进行处理以提取与时间相关的文本信息。最后,在一个或多个实施方式中,将其投影回到嵌入维度以创建注意力键向量hk。可以从注意力键向量和文本嵌入计算注意力值向量,以联合考虑he中的本地信息和hk中的长期上下文信息。每个注意力块使用键向量来计算注意力权重,而最终上下文向量被计算为值向量的加权平均值hv(参见部分f.1.f)。e)解码器在一个或多个实施方式中,解码器网络(例如,解码器2630/3130)通过以过去音频帧为条件预测一群组r个未来音频帧来以自回归方式生成音频。由于解码器是自回归的,所以在实施方式中,其使用因果卷积块。在一个或多个实施方式中,选择梅尔频带对数幅度声谱图作为紧凑的低维音频帧表示,但是可以使用其它表示。根据经验观察到,将多个帧一起解码(即,具有r>1)产生较好的音频质量。在一个或多个实施方式中,解码器网络以具有修正线性单元(relu)非线性的多个全连接层开始以预处理输入梅尔声谱图(在图26中表示为“prenet”2632)。接着,在一个或多个实施方式中,其后是一系列解码器块,其中解码器块包括因果卷积块和注意力块。这些卷积块生成用于注意力编码器的隐藏状态的查询(参见部分f.1.f)。最后,在一个或多个实施方式中,全连接层输出下一群组r个音频帧以及二元“最终帧”预测(指示是否已经合成话语的最后一个帧)。在一个或多个实施方式中,在注意力块之前的每个全连接层之前应用丢弃,除了第一个全连接层之外。可以使用输出的梅尔声谱图来计算l1损失,并且可以使用最终帧预测来计算二元交叉熵损失。选择l1损失,因为它凭经验产生最好结果。诸如l2等其它损失可能遭受异常频谱特征,其可以对应于非语音噪声。f)注意力块图29以图形方式描绘根据本公开的实施方式的注意力块的实施方式。如图29所示,在一个或多个实施方式中,可以分别以速率ωkey2905和ωquery2910将位置编码2905、2910添加到键2920和查询2938向量两者。可以通过将较大负值的掩模添加到logits来在推断中施加强制单调性。可以使用两种可能注意力方案之一:softmax或单调注意力(诸如来自raffel等人(2017年))。在一个或多个实施方式中,在训练期间,丢弃注意力权重。在一个或多个实施方式中,使用点积注意力机制(在图29中描绘)。在一个或多个实施方式中,注意力机制使用查询向量2938(解码器的隐藏状态)和来自编码器的每时间步键向量2920来计算注意力权重,并且接着输出被计算为值向量2921的加权平均值的上下文向量2915。从引入归纳偏置观察到经验益处,其中注意力在时间上遵循单调进展。因此,在一个或多个实施方式中,将位置编码添加到键向量和查询向量两者。这些位置编码hp可以被选择为hp(i)=sin(ωsi/10000k/d)(对于偶数i)或cos(ωsi/10000k/d)(对于奇数i),其中i是时间步索引,k是位置编码中的通道索引,d是位置编码中的通道总数,并且ωs是编码的位置率。在一个或多个实施方式中,位置率规定注意力分布中的线的平均斜率,大致对应于语速。对于单个说话者,可以针对查询将ωs设置为一并且可以针对键将其固定为输出时间步与输入时间步的比率(在整个数据集上计算)。对于多说话者数据集,可以从用于每个说话者的说话者嵌入针对键和查询两者计算ωs(例如,在图29中描绘)。由于正弦和余弦函数形成标准正交基,所以这个初始化产生呈对角线形式的注意力分布。在一个或多个实施方式中,针对查询投影和键投影将用于计算隐藏注意力向量的全连接层权重初始化为相同值。可以在所有注意力块中使用位置编码。在一个或多个实施方式中,使用上下文归一化(诸如在gehring等人(2017年)中)。在一个或多个实施方式中,将全连接层应用于上下文向量以生成注意力块的输出。总的来说,位置编码改善了卷积注意力机制。生产质量tts系统对注意力误差具有非常低的容忍度。因此,除了位置编码之外,还考虑额外策略来消除重复或跳过单词的情况。可以使用的一种方法是用在raffel等人(2017年)中介绍的单调注意力机制代替典型注意力机制,所述单调注意力机制预期通过训练来使硬单调随机解码与软单调注意力接近。raffel等人(2017年)还提出通过取样的硬单调注意力过程。其目的是通过仅仅注意力经由取样选择的状态来改善推断速度,并且因此避免对未来状态进行计算。本文的实施方式未受益于此类加速,并且在一些情况下观察到不良注意力行为,例如卡在第一个或最后一个字符上。尽管单调性有所改善,但这种策略可能会产生更加分散的注意力分布。在一些情况下,同时注意力若干字符,并且无法获得高质量语音。这可能归因于软对准的未归一化注意力系数,从而有可能导致来自编码器的弱信号。因此,在一个或多个实施方式中,使用仅在推断时将注意力权重约束为单调性从而保留没有任何约束的训练过程的替代策略。代替在整个输入上计算softmax,可以在固定窗口上计算softmax,所述固定窗口在最后一个注意力位置开始并且前进若干时间步。在本文的实验中,使用为三的窗口大小,但是可以使用其它窗口大小。在一个或多个实施方式中,初始位置被设置为零,并且稍后被计算为当前窗口内的最高注意力权重的索引。这个策略还在推断中强制单调注意力并且产生优异的语音质量。g)转换器在一个或多个实施方式中,转换器网络(例如,2650/3150)将来自解码器的最后一个隐藏层的激活作为输入,应用若干非因果卷积块,并且接着预测用于下游声码器的参数。在一个或多个实施方式中,与解码器不同,转换器是非因果的且非自回归的,所以其可以使用来自解码器的未来上下文来预测其输出。在实施方式中,转换器网络的损失函数取决于下游声码器的类型:1.gridin-lim声码器:在一个或多个实施方式中,griffin-lim算法通过迭代地估计未知相位来将声谱图转换为时域音频波形。已经发现,在波形合成之前将声谱图自乘由锐化因子参数化的次数有助于改善音频质量。l1损失用于线性标度对数幅度声谱图的预测。2.world声码器:在一个或多个实施方式中,world声码器是基于morise等人(2016年)。图30以图形方式描绘根据本公开的实施方式的具有全连接(fc)层的示例性生成world声码器参数。在一个或多个实施方式中,作为声码器参数,预测布尔值3010(当前帧是浊音的还是清音的)、f0值3025(如果帧是浊音的)、频谱包络3015和非周期性参数3020。在一个或多个实施方式中,交叉熵损失用于浊音-清音预测,并且l1损失用于所有其它预测。在实施方式中,“σ”是s形函数,其用于获得用于二元交叉熵预测的有界变量。在一个或多个实施方式中,输入3005是转换器中的输出隐藏状态。3.wavenet声码器:在一个或多个实施方式中,wavenet被单独训练以用作将梅尔标度对数幅度声谱图作为声码器参数的声码器。这些声码器参数被作为外部调节器输入到网络。可以使用groundtruth梅尔声谱图和音频波形来训练wavenet。使用梅尔标度声谱图观察到良好性能,这对应于更紧凑的音频表示。除了在解码时在梅尔标度声谱图上的l1损失之外,在线性标度声谱图上的l1损失也可以用作griffin-lim声码器。应当注意,可以使用其它声码器和其它输出类型。2.deepvoice3的详细模型架构实施方式图31以图形方式描绘根据本公开的实施方式的示例性详细deepvoice3模型架构。在一个或多个实施方式中,模型3100使用深度残差卷积网络来将文本和/或音素编码成用于注意力解码器3130的每时间步键3120和值3122向量。在一个或多个实施方式中,解码器3130使用这些来预测对应于输出音频的梅尔频带对数幅度声谱图3142。虚线箭头3146描绘在推断期间的自回归合成过程。在一个或多个实施方式中,解码器的隐藏状态被馈送到转换器网络3150以输出用于griffin-lim3152a的线性声谱图或用于world3152b的参数,其可以用于合成最终波形。在一个或多个实施方式中,将权重归一化应用于模型中的所有卷积滤波器和全连接层权重矩阵。如图31所描绘的实施方式中所示出,wavenet3152不需要单独转换器,因为其采用梅尔频带对数幅度声谱图作为输入。a)优化deepvoice3实施方式用于部署使用tensorflow图运行推断证明是非常昂贵的,平均大约1qps。不良的tensorflow性能可能是由于在数百个节点和数百个时间步上运行图评估程序的开销。与tensorflow一起使用诸如xla等技术可以加速评估,但是不太可能与手写内核的性能相匹配。相反,针对deepvoice3实施方式推断实施定制gpu内核。归因于模型的复杂性和大量输出时间步,针对图中的不同操作(例如,卷积、矩阵乘法、一元和二元运算等)启动各个内核可能是不切实际的;启动cuda内核的开销为大约50μs,当在模型中的所有操作和所有输出时间步上进行合计时,其将吞吐量限制为大约10qps。因此,针对整个模型实施单个内核,这避免启动许多cuda内核的开销。最后,代替在内核中进行批量计算,本文的内核实施方式对单个话语进行操作,并且启动与gpu上的串流多处理器(sm)一样多的并发流。每个内核可以使用一个块来启动,所以预期gpu每个sm调度一个块,从而允许能够根据sm的数目线性地缩放推断速度。在具有56个sm的由位于加利福尼亚州圣克拉拉的nvidia公司出产的单个nvidiateslap100gpu上,实现了为115qps的推断速度,其对应于每天1000万次查询的目标。在实施方式中,在服务器上的所有20个cpu上并行化world合成,永久地将线程钉到cpu以便最大化高速缓存性能。在这个设置中,gpu推断是瓶颈,因为20个核心上的world合成比115qps更快。可以通过更优化的内核、更小的模型和固定精度的算术来更快地做出推断。b)模型超参数本专利文献中所使用的模型的所有超参数均在以下表7中提供。表7:用于所述专利文献中所使用的三个数据集的最佳模型的超参数。3.引用文献下文列出或在本文任何地方引用的每篇文献的全文均以引用的方式并入本文中。yannisagiomyrgiannakis。vocainethevocoderandapplicationsinspeechsynthesis。icassp,2015年。jonasgehring、michaelauli、davidgrangier、denisyarats和yanndauphin。convolutionalsequencetosequencelearning。icml,2017年。danielgriffin和jaelim。signalestimationfrommodifiedshort-timefouriertransform。ieeetransactionsonacoustics,speech,andsignalprocessing,1984年。soroushmehri、kundankumar、ishaangulrajani、ritheshkumar、shubhamjain、josesotelo、aaroncourville和yoshuabengio。samplernn:anunconditionalend-to-endneuralaudiogenerationmodel。iclr,2017年。masanorimorise、fumiyayokomori和kenjiozawa。world:avocoder-basedhigh-qualityspeechsynthesissystemforreal-timeapplications。ieicetransactionsoninformationandsystems,2016年。robertochshorn和maxhawkins。gentle。https://github.com/lowerquality/gentle,2017年。aaronvandenoord、sanderdieleman、heigazen、karensimonyan、oriolvinyals、alexgraves、nalkalchbrenner、andrewsenior和koraykavukcuoglu。wavenet:agenerativemodelforrawaudio。arxiv:1609.03499,2016年。vassilpanayotov、guoguochen、danielpovey和sanjeevkhudanpur。librispeech:anasrcorpusbasedonpublicdomainaudiobooks。acoustics,speechandsignalprocessing(icassp),2015ieeeinternationalconferenceon,第5206至5210页。ieee,2015年。librispeech数据集可以在http://www.openslr.org/12/处获得。colinraffel、thangluong、peterjliu、ronjweiss和douglaseck。onlineandlinear-timeattentionbyenforcingmonotonicalignments。icml,2017年。josesotelo、soroushmehri、kundankumar、joaofelipesantos、kylekastner、aaroncourville和yoshuabengio。char2wav:end-to-endspeechsynthesis。iclrworkshop,2017年。g3.附加实施方式的实现本公开的方面可利用用于一个或多个处理器或处理单元以使步骤执行的指令在一个或多个非暂态计算机可读介质上编码。应注意,一个或多个非暂态计算机可读介质应当包括易失性存储器和非易失性存储器。应注意,替代实现方式是可能的,其包括硬件实现方式或软件/硬件实现方式。硬件实施的功能可使用asic、可编程的阵列、数字信号处理电路等来实现。因此,任何权利要求中的术语“手段”旨在涵盖软件实现方式和硬件实现方式两者。类似地,如本文使用的术语“计算机可读媒介或介质”包括具有实施在其上的指令程序的软件和/或硬件或它们的组合。利用所构想的这些替代实现方式,应当理解,附图以及随附描述提供本领域的技术人员编写程序代码(即,软件)和/或制造电路(即,硬件)以执行所需处理所要求的功能信息。应当注意,本公开的实施方式还可涉及具有其上具有用于执行各种计算机实施的操作的计算机代码的非暂态有形计算机可读介质的计算机产品。介质和计算机代码可为出于本公开的目的而专门设计和构造的介质和计算机代码,或者它们可为相关领域中的技术人员已知或可用的。有形计算机可读介质的示例包括但不限于:诸如硬盘、软盘和磁带的磁性介质;诸如cd-rom和全息设备的光学介质;磁光介质;以及专门配置成存储或存储并执行程序代码的硬件设备,例如,专用集成电路(asic)、可编程逻辑器件(pld)、闪存设备、以及rom和ram设备。计算机代码的示例包括机器代码(例如,编译器产生的代码)以及包含可由计算机使用解释器来执行的更高级代码的文件。本公开的实施方式可整体地或部分地实施为可在由处理设备执行的程序模块中的机器可执行指令。程序模块的示例包括库、程序、例程、对象、组件和数据结构。在分布的计算环境中,程序模块可物理上定位在本地、远程或两者的设定中。本领域的技术人员将认识到,计算系统或编程语言对本公开的实践来说均不重要。本领域的技术人员将还将认识到,多个上述元件可物理地和/或在功能上划分成子模块或组合在一起。本领域技术人员将理解,前文的示例和实施方式是示例性的,并且不限制本公开的范围。旨在说明的是,在本领域的技术人员阅读本说明书并研究附图后将对本领域的技术人员显而易见的本公开的所有、置换、增强、等同、组合或改进包括在本公开的真实精神和范围内。还应注意,任何权利要求书的元素可不同地布置,包括具有多个从属、配置和组合。当前第1页12
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1