对话控制装置、对话系统、对话控制方法以及存储介质与流程
本发明涉及对话控制装置、对话系统、对话控制方法以及存储介质。
背景技术:
与人进行交流的机器人等设备的开发正在发展,为了使这种机器人等设备得到普及,亲近容易度是较重要的方面。例如,日本特开2006-071936号公报公开了以下技术:通过与使用者的对话来学习使用者的喜好,并进行与使用者的喜好相符合的对话。
在日本特开2006-071936号公报公开的技术中,难以高精度地掌握使用者的喜好。
技术实现要素:
本发明是鉴于上述那样的情况而进行的,其目的在于提供能够高精度地掌握使用者的喜好、并进行与使用者的喜好相符合的对话的对话控制装置、对话系统、对话控制方法以及存储介质。
为了实现上述目的,本发明所涉及的对话控制装置的一个方式的特征在于,具备:反应取得单元,取得多个反应判定结果,该多个反应判定结果中包含对规定对象针对第1发言装置的发言的反应进行了判定的结果、以及对上述规定对象针对与上述第1发言装置相独立地设置的第2发言装置的发言的反应进行了判定的结果;以及发言控制单元,基于由上述反应取得单元取得的多个反应判定结果,对包含上述第1以及第2发言装置上述第1以及第2发言装置在内的多个发言装置中的至少任一个的上述发言进行控制。
另外,为了实现上述目的,本发明所涉及的对话系统的一个方式为,具备构成为能够发言的第1发言装置和第2发言装置、以及对话控制装置,该对话系统的特征在于,上述对话控制装置具备:反应取得单元,取得多个反应判定结果,该多个反应判定结果中包含对规定对象针对第1发言装置的发言的反应进行了判定的结果、以及对上述规定对象针对与上述第1发言装置相独立地设置的上述第2发言装置的发言的反应进行了判定的结果;以及发言控制单元,基于由上述反应取得单元取得的多个反应判定结果,对包含上述第1以及第2发言装置在内的多个发言装置中的至少任一个的上述发言进行控制。
另外,为了实现上述目的,本发明涉及的对话控制方法的一个方式的特征在于,包括:取得多个反应判定结果的处理,该多个反应判定结果中包含对规定对象针对第1发言装置的发言的反应进行了判定的结果、以及对上述规定对象针对与上述第1发言装置相独立地设置的第2发言装置的发言的反应进行了判定的结果;以及基于所取得的上述多个反应判定结果,对包含上述第1以及第2发言装置在内的多个发言装置中的至少任一个的上述发言进行控制的处理。
另外,为了实现上述目的,本发明所涉及的存储介质的一个方式的特征在于,存储使计算机作为如下单元发挥功能的程序:反应取得单元,取得多个反应判定结果,该多个反应判定结果中包含对规定对象针对第1发言装置的发言的反应进行了判定的结果、以及对上述规定对象针对与上述第1发言装置相独立地设置的第2发言装置的发言的反应进行了判定的结果;以及发言控制单元,基于由上述反应取得单元取得的多个反应判定结果,对包含上述第1以及第2发言装置在内的多个发言装置中的至少任一个的上述发言进行控制。
发明的效果
根据本发明,能够提供能够高精度地掌握使用者的喜好、并进行与使用者的喜好相符合的对话的对话控制装置、对话系统、对话控制方法以及存储介质。
附图说明
图1是表示本发明的第1实施方式所涉及的对话系统的构成的图。
图2是第1实施方式所涉及的机器人的主视图。
图3是表示第1实施方式所涉及的机器人的构成的框图。
图4是表示第1实施方式所涉及的声音反应极性判定表的一例的图。
图5是表示第1实施方式所涉及的对话控制处理的流程的流程图。
图6是表示第1实施方式所涉及的用户确定处理的流程的流程图。
图7是表示第1实施方式所涉及的声音判定处理的流程的流程图。
图8是表示第1实施方式所涉及的表情判定处理的流程的流程图。
图9是表示第1实施方式所涉及的行动判定处理的流程的流程图。
图10是表示第1实施方式所涉及的嗜好判定处理的流程的流程图。
图11是表示第2实施方式的对话系统的构成框图。
具体实施方式
以下,参照附图对本发明实施方式进行详细地说明。
(第1实施方式)
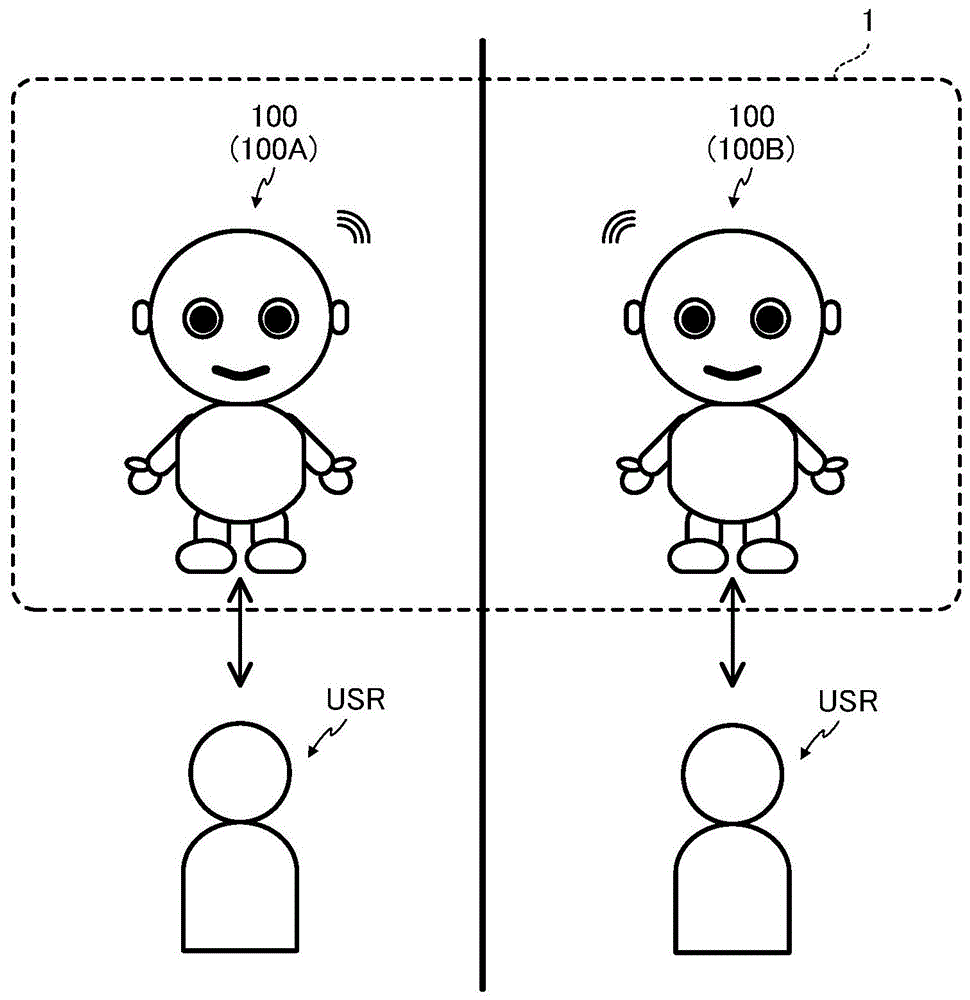
本发明的第1实施方式所涉及的对话系统1构成为包含多个机器人100。多个机器人100被配置于规定对象的办公室、住宅等居住空间内,多个机器人100与规定对象进行对话。在以下的说明中,对2台机器人100与规定对象进行对话的例子进行说明,但是对话系统1也可以构成为包含3台以上的机器人100。
此处,规定对象是指使用对话系统的用户(使用者),典型地说,是对话系统的所有者、该所有者的家庭成员或朋友等。另外,除了人以外,规定对象还包含例如作为宠物饲养的动物、与机器人100不同的其他机器人。
如图1所示,对话系统1具备能够相互通信的2台机器人100,与用户usr进行对话。此处,为了便于说明,朝向图1的纸面而将左侧的机器人100设为机器人100a,朝向图1的纸面而将右侧的机器人100设为机器人100b。此外,在不区分机器人100a和机器人100b地进行说明的情况下,有时将任一个机器人或者将这些机器人统称地记载为“机器人100”。机器人100a和机器人100b被配置于相互不同的场所,且分别设置于相同的规定对象无法识别机器人100a以及机器人100b的发言的双方那样的场所。例如,机器人100a被配置在规定对象的办公室,机器人100b被配置在远离该办公室的规定对象的住宅。或者,机器人100a配置在规定对象常去的设施,机器人100b配置在远离该设施的规定对象常去的其他设施。
如图2所示,机器人100是在外观上具有模仿了人的立体形状的机器人。另外,机器人100的外饰由以合成树脂为主的材料形成。机器人100具有躯体部101、与躯体部101的上部连接的头部102、与躯体部101的左右分别连接的手部103、以及从躯体部101向下部连接的两只脚部104。另外,头部102具有左右一对眼部105、嘴部106以及左右一对耳部107。此外,将图2的上侧、下侧、左侧、右侧分别设为机器人100的上侧、下侧、右侧、左侧。
接着,参照图3对机器人100的构成进行说明。图3示出对机器人100a和机器人100b的各构成进行表示的框图,机器人100a与机器人100b的构成相同。首先,以机器人100a为例对其构成进行说明。
如图3所示,机器人100a具有控制部110a、存储部120a、摄像部130a、声音输入部140a、声音输出部150a、移动部160a以及通信部170a。这些各部经由总线bl相互电连接。
控制部110a由具有cpu(centralprocessingunit:中央处理单元)、rom(readonlymemory:只读存储器)、ram(randomaccessmemory:随机存取存储器)的计算机构成,对机器人100a整体的动作进行控制。控制部110a通过由cpu读出rom所存储的控制程序并在ram上执行,由此对机器人100a的各部的动作进行控制。
控制部110a通过执行控制程序,由此作为用户检测部111a、用户确定部112a、用户信息取得部113a、声音识别部114a、发言控制部115a、声音合成部116a、反应判定部117a以及嗜好判定部118a发挥功能。
用户检测部111a检测在机器人100a周围(例如,离机器人100a为半径2m的范围内)存在的用户usr。用户检测部111a例如对后述的摄像部130a进行控制而对机器人100a周围进行摄像,通过对物体的活动、头、面部等进行检测,由此对在机器人100a周围存在的用户usr进行检测。
用户确定部112a确定用户检测部111a检测到的用户usr。用户确定部112a例如从摄像部130a的摄像图像中提取与用户usr的面部部分相当的面部图像。然后,用户确定部112a从该面部图像中检测出特征量,与后述的存储部120a的用户信息数据库中所登记的、表示面部的特征量的面部信息进行对照,基于对照的结果来计算相似度,并根据计算出的相似度是否满足规定的基准来确定用户usr。在存储部120a的用户信息数据库中存储有规定的多个用户usr的表示各自的面部的特征量的面部信息。通过用户确定部112a来确定用户检测部111a检测到的用户usr是这些用户usr中的哪个用户usr。特征量是能够识别用户usr的信息即可,例如是将眼、鼻、嘴等面部所包含的各部分的形状、大小、配置等外观特征用数值进行了表示的信息。在以下的说明中,将由用户检测部111a检测到、且由用户确定部112a确定出的用户usr称为对象用户。如此,用户确定部112a作为本发明的对象确定单元发挥功能。
用户信息取得部113a取得表示对象用户的发言、外观、行动等的用户信息。在本实施方式中,用户信息取得部113a例如对摄像部130a、声音输入部140a进行控制,而取得包含拍摄到对象用户的摄像图像的图像数据的图像信息、以及包含对象用户发出的声音的声音数据的声音信息中的至少任一个,作为用户信息。如此,用户信息取得部113a与摄像部130a、声音输入部140a协作而作为本发明的取得单元发挥功能。
声音识别部114a对用户信息取得部113a取得的声音信息中所包含的声音数据实施声音识别处理,并转换为表示对象用户的发言内容的文本数据。声音识别处理例如使用存储部120a的声音信息db(database:数据库)122a所存储的音响模型、语言模型、单词词典。声音识别部114a例如从所取得的声音数据中消除背景噪声,对被消除了背景噪声之后的声音数据中所包含的音位进行识别,参照单词词典生成将识别出的音位列转换为单词的多个转换候选。然后,声音识别部114a参照语言模型从所生成的多个转换候选中选择妥当性最高的候选,作为与声音数据对应的文本数据进行输出。
发言控制部115a对机器人100a的发言进行控制。发言控制部115a例如参照存储部120a的发言信息db123a所存储的发言信息,从发言信息db123a所存储的发言信息中提取与状况相应的多个发言候选。然后,发言控制部115a参照用户信息db121a所存储的用户信息中所包含的嗜好信息,从所提取的多个发言候选中选择与对象用户的嗜好相适合的发言候选,并决定为机器人100a的发言内容。如此,发言控制部115a作为本发明的发言控制单元发挥功能。
另外,发言控制部115a经由通信部170a与机器人100b进行通信,并与机器人100b的发言控制部115b协作而如以下那样调整并决定机器人100a的发言内容。
即,发言控制部115a与机器人100b的发言控制部115b协作,例如取得机器人100b发言后的经过时间,当在所取得的经过时间为规定经过时间(例如72小时)以内时机器人100a发言的情况下,调整并决定机器人100a的发言的话题,以使机器人100a发言的话题成为与在机器人100a的发言开始前的规定经过时间以内机器人100b发言了的话题不同的话题。这样的话题的决定,在机器人100b的发言控制部115b中也同样地进行。通过以上,机器人100a以及机器人100b发言的话题被决定为相互不同的话题,并按照所决定的话题来控制两个机器人100a、100b的发言。
如后述那样,机器人100a以及机器人100b分别判定对象用户针对自身的发言的反应,并基于其判定结果来收集(存储)对象用户的嗜好信息,但是在该情况下,当机器人100a与机器人100b发言的话题重复、或者总是关联时,无法收集对象用户的新的嗜好信息、更广领域的嗜好信息。另外,对象用户也会由于听到重复的话题的发言而感到厌烦。通过将机器人100a与机器人100b的发言的话题决定为相互不同的话题,由此能够收集更多的各种各样的嗜好信息。
与此相对,当在机器人100b发言后经过了规定经过时间以上的情况下,发言控制部115a独自地决定发言内容,而不被机器人100b的发言内容限制。即,机器人100a以及100b发言的话题(发言内容)相互不协作、且相互无关(相互独立)地决定。
发言控制部115a生成并输出表示与机器人100b协作决定的自身的发言内容的文本数据。
声音合成部116a生成与从发言控制部115a输入的表示机器人100a的发言内容的文本数据对应的声音数据。声音合成部116a例如使用存储部120a的声音信息db122a中保存的音响模型等,生成将文本数据所示的文字串读出的声音数据。另外,声音合成部116a控制声音输出部150a,以便将所生成的声音数据进行声音输出。
反应判定部117a判定对象用户针对机器人100a的发言的反应。由此,对于上述规定的多个用户usr中的由用户确定部112a确定出的每个对象用户,判定针对机器人100a的发言的反应。反应判定部117a具有声音判定部117aa、表情判定部117ba以及行动判定部117ca。声音判定部117aa、表情判定部117ba以及行动判定部117ca分别基于对象用户的声音、表情以及行动,将针对对象机器人100a的发言的反应分类为三个极性,由此进行判定。三个极性为肯定的反应即“积极(positive)”、否定的反应即“消极(negative)”以及既不肯定也不否定的中立的反应即“中性(neutral)”。
声音判定部117aa基于在机器人100a发言后对象用户所发出的声音,判定对象用户针对机器人100a的发言的反应。声音判定部117aa基于文本数据将对象用户的发言内容分类为声音反应极性的“积极”、“消极”以及“中性”这三个极性,由此判定对象用户针对机器人100a的发言的反应,上述文本数据是声音识别部114a对于在机器人100a的发言后用户信息取得部113a取得的声音实施声音识别处理而生成的。如此,声音判定部117aa作为本发明的声音判定单元发挥功能。
表情判定部117ba基于机器人100a发言后的对象用户的表情,判定对象用户针对机器人100a的发言的反应。表情判定部117ba计算表示笑脸的程度的笑脸度,作为用于评价对象用户的表情的指标。表情判定部117ba从在机器人100a的发言后用户信息取得部113a取得的摄像图像中提取对象用户的面部图像,并检测对象用户的面部的特征量。表情判定部117ba参照存储部120a的反应判定信息db124a中存储的笑脸度信息,并基于所检测出的特征量来计算对象用户的笑脸度。表情判定部117ba根据计算出的笑脸度,将对象用户的表情分类为表情反应极性的“积极”、“消极”以及“中性”这三个极性,由此判定对象用户针对机器人100a的发言的反应。如此,表情判定部117ba作为本发明的表情判定单元发挥功能。
行动判定部117ca基于机器人100a发言后的对象用户的行动,判定对象用户针对机器人100a的发言的反应。行动判定部117ca从在机器人100a的发言后用户信息取得部113a取得的摄像图像中检测对象用户的行动,并将对象用户的行动分类为行动反应极性的“积极”、“消极”以及“中性”这三个极性,由此判定对象用户针对机器人100a的发言的反应。如此,行动判定部117ca作为本发明的行动判定单元发挥功能。
嗜好判定部118a确定对象用户与机器人100a之间的对话的话题,并基于反应判定部117a的各判定结果来判定嗜好度,该嗜好度表示对象用户针对所确定的话题的嗜好的高度。由此,对于上述规定的多个用户usr中的由用户确定部112a确定出的每个对象用户,判定其嗜好度。此处,所谓嗜好是指无论有形还是无形而与各种事物有关的兴趣、喜好,例如除了包含与食品、体育、天气等有关的兴趣、喜好以外,还包含对于机器人100的对应(发言内容)的喜好。嗜好判定部118a按照对象用户对于话题的嗜好从高到低的顺序,将嗜好度分类为“嗜好度a”、“嗜好度b”、“嗜好度c”以及“嗜好度d”这四个等级。如此,嗜好判定部118a作为本发明的确定单元以及嗜好判定单元发挥功能。
此外,用户检测部111a、用户确定部112a、用户信息取得部113a、声音识别部114a、发言控制部115a、声音合成部116a、反应判定部117a以及嗜好判定部118a,可以通过单个计算机来实现各功能,也可以分别通过独立的计算机来实现各功能。
存储部120a具备能够改写存储内容的非易失性的半导体存储器、硬盘驱动器等,并存储控制部110a对机器人100a的各部进行控制所需要的各种数据。
存储部120a具有分别保存各种数据的多个数据库。存储部120a例如具有用户信息db121a、声音信息db122a、发言信息db123a以及反应判定信息db124a。另外,在存储部120a中,按照每个用户usr存储包含机器人100a发言的发言日期时间以及发言的话题等的发言履历信息。
用户信息db121a将与所登记的多个用户usr的各个有关的各种信息作为用户信息进行积累并存储。用户信息例如包含为了识别多个用户usr的各个而预先分配的用户识别信息(例如,用户usr的id)、表示用户usr的面部的特征量的面部信息、以及表示用户usr对于各话题的嗜好度的嗜好信息。如此,多个用户usr各自的嗜好信息被存储为,使用用户识别信息能够识别出是哪个用户usr的嗜好信息。
声音信息db122a为,作为用于声音识别处理或者声音合成处理的数据,例如保存有音响模型、单词词典以及语言模型,上述音响模型表示将含义与其他词语进行区别的声音的最小单位即音位的各自的特征(频率特性),上述单词词典将音位的特征与单词建立对应,上述语言模型表示单词的排列及其连接概率。
发言信息db123a存储表示机器人100a的发言候选的发言信息。发言信息例如包含开始与对象用户交谈的情况下的发言候选、对于对象用户的发言的应答的情况下的发言候选、以及与机器人100b会话的情况下的发言候选等、对应于与对象用户的对话状况的各种发言候选。
反应判定信息db124a存储反应判定信息,在反应判定部117a判定对象用户针对机器人100a的发言的反应时使用该反应判定信息。反应判定信息db124a为,作为反应判定信息,例如存储在反应判定部117a的声音判定部117aa判定对象用户针对机器人100a的发言的反应时使用的声音判定信息。声音判定信息例如以图4所示的声音反应极性判定表的形式存储。在声音反应极性判定表中,后述的声音反应极性与特征关键字建立对应。另外,反应判定信息db124a为,作为反应判定信息,例如存储在反应判定部117a的表情判定部117ba计算对象用户的笑脸度时使用的笑脸度信息。笑脸度信息例如是根据眼角、嘴角的位置、眼、嘴的大小等的变化程度,将笑脸度在0~100%的范围内进行数值化而得到的信息。
摄像部130a由摄像机构成,该摄像机具备镜头、以及ccd(chargecoupleddevice:图像耦合器件)图像传感器、cmos(complementarymetaloxidesemiconductor:互补金属氧化物半导体)图像传感器等摄像元件,摄像部130a对机器人100a的周围进行摄像。摄像部130a例如设置于头部102的正面上部,对头部102的前方进行摄像,生成并输出数字图像数据。摄像机安装于以能够改变镜头所朝向的方向的方式动作的马达驱动的架台(万向架等),并构成为能够对用户usr的面部等进行追踪。
声音输入部140a由麦克风、a/d(analogtodigital:模拟数字)转换器等构成,例如将由设置在耳部107的麦克风拾音到的声音进行放大,并将实施了a/d转换、编码等信号处理的数字声音数据(声音信息)输出到控制部110a。
声音输出部150a由扬声器、d/a(digitaltoanalog:数字模拟)转换器等构成,对从控制部110a的声音合成部116a供给的声音数据实施译码、d/a转换、放大等信号处理,并将模拟声音信号从例如设置在嘴部106的扬声器输出。
机器人100a通过声音输入部140a的麦克风对对象用户的声音进行拾音,并在控制部110a的控制下,将与对象用户的发言内容对应的声音从声音输出部150a的扬声器输出,由此能够与对象用户进行对话而产生交流。如此,机器人100a作为本发明的第1发言装置发挥功能。
移动部160a是用于使机器人100a移动的部位。移动部160a具有分别设置于机器人100a的左右的脚部104的底部的车轮、旋转驱动左右的车轮的马达、以及对马达进行驱动控制的驱动电路。根据从控制部110a接收到的控制信号,驱动电路向马达供给驱动用的脉冲信号。马达根据驱动用的脉冲信号使左右的车轮旋转驱动,而使机器人100a移动。如此,移动部160a作为本发明的移动单元发挥功能。此外,构成为左右的车轮分别独立地旋转驱动,但机器人100a只要能够进行前进、后退、转弯、加减速等行驶,则马达的数量是任意的。例如,可以设置连结机构、转向机构等而通过一个马达来驱动左右的车轮。另外,也能够与马达的数量相匹配地适当变更驱动电路的数量。
通信部170a由用于使用无线通信方式来进行通信的无线通信模块以及天线构成,与机器人100b进行无线数据通信。作为无线通信方式,例如能够适当地采用bluetooth(注册商标)、ble(bluetoothlowenergy:低功耗蓝牙)、zigbee(注册商标)、红外线通信等近距离无线通信方式、wifi(wirelessfidelity)等无线lan通信方式。在本实施方式中,机器人100a经由通信部170a与机器人100b进行无线数据通信,由此机器人100a以及机器人100b与对象用户进行对话。
机器人100b与机器人100a相同,因此对其构成进行简单说明。与机器人100a同样,机器人100b具备控制部110b、存储部120b、摄像部130b、声音输入部140b、声音输出部150b、移动部160b以及通信部170b。控制部110b对机器人100b整体的动作进行控制,通过执行控制程序而作为用户检测部111b、用户确定部112b、用户信息取得部113b、声音识别部114b、发言控制部115b、声音合成部116b、反应判定部117b以及嗜好判定部118b发挥功能。发言控制部115b参照用户信息db121b所存储的用户信息中包含的嗜好信息,从所提取的多个发言候选中选择与对象用户的嗜好相适合的发言候选,并决定为机器人100b的发言内容。经由通信部170b与机器人100a进行通信,并与机器人100a的发言控制部115a协作,例如取得机器人100a发言后的经过时间。在所取得的经过时间为上述规定经过时间以内时,发言控制部115b调整并决定机器人100b的发言内容,以使得机器人100b发言的话题与在机器人100b的发言开始前的规定经过时间以内机器人100a发言了的话题不同。反应判定部117b判定对象用户针对机器人100b的发言的反应。反应判定部117b具有声音判定部117ab、表情判定部117bb以及行动判定部117cb。声音判定部117ab通过基于对象用户的声音将针对对象机器人100b的发言的反应分类为“积极”、“消极”、“中性”这三个极性来进行判定。表情判定部117bb通过基于对象用户的表情将针对对象机器人100b的发言的反应分类为“积极”、“消极”、“中性”这三个极性来进行判定。行动判定部117cb通过基于对象用户的行动将针对对象机器人100b的发言的反应分类为“积极”、“消极”、“中性”这三个极性来进行判定。存储部120b具有分别保存各种数据的多个数据库。存储部120b例如具有用户信息db121b、声音信息db122b、发言信息db123b以及反应判定信息db124b。另外,在存储部120b中,按照每个用户usr来存储包含机器人100b发言的发言日期时间以及发言的话题等的发言履历信息。机器人100b通过声音输入部140b的麦克风对对象用户的声音进行拾音,并在控制部110b的控制下,从声音输出部150b的扬声器输出与对象用户的发言内容对应的声音,由此能够与对象用户进行对话而产生交流。如此,机器人100b作为本发明的第2发言装置发挥功能。
接着,参照图5所示的流程图对机器人100执行的对话控制处理进行说明。对话控制处理是根据对象用户的嗜好来控制对话的处理。此处,以机器人100a的控制部110a执行的情况为例来说明对话控制处理。控制部110a以用户检测部111a在机器人100a的周围检测到用户usr的情况为契机,开始对话控制处理。
控制部110a为,当开始对话控制处理时,首先执行用户确定处理(步骤s101)。此处,参照图6所示的流程图,对用户确定处理进行说明。用户确定处理是确定用户检测部111a检测出的存在于机器人100a周围的用户的处理。
控制部110a为,当开始用户确定处理时,首先从由摄像部130a取得的摄像图像中提取对象用户的面部图像(步骤s201)。控制部110a(用户确定部112a)例如对摄像图像中的肤色区域进行检测,并判定在肤色区域内是否存在与眼、鼻、嘴等面部部分相当的部分,当判断为存在与面部部分相当的部分时,将肤色区域视为面部图像而进行提取。
接着,控制部110a对与所提取的面部图像对应的登记用户进行检索(步骤s202)。控制部110a(用户确定部112a)例如从所提取的面部图像中检测特征量,并与存储部120a的用户信息db121a中存储的面部信息进行对照,对相似度为规定的基准以上的登记用户进行检索。
控制部110a根据步骤s202中的检索结果来确定存在于机器人100周围的用户usr(步骤s203)。控制部110a(用户确定部112a)例如将与如下的特征量对应的用户usr,确定为存在于机器人100a周围的对象用户,上述特征量是用户信息db121a中所存储的上述多个用户usr各自的面部的特征量中、与从面部图像中检测出的特征量之间的相似度最高的特征量。
控制部110a在执行了步骤s203的处理之后,结束用户确定处理,使处理返回到对话控制处理。
返回到图5,在执行了用户确定处理(步骤s101)之后,控制部110a建立与机器人100b(其他机器人)之间的通信连接(步骤s102)。此处,所谓通信连接的建立是指,指定通信对象而进行规定的过程、并建立相互能够收发数据的状态。控制部110a控制通信部170a而进行基于通信方式的规定的过程,由此建立与机器人100b之间的通信连接。此外,在机器人100a与机器人100b使用红外线通信方式来进行数据通信的情况下,不需要事先建立通信连接。
接着,控制部110a判定在比上述规定经过时间短的规定时间内(例如,20秒以内)、在步骤s101中确定出的对象用户是否发言(步骤s103)。控制部110a例如使用附设于cpu的rtc(realtimeclock:实时时钟)计测的当前时刻信息来计测从本处理的执行开始时起的经过时间,并基于用户信息取得部113a取得的声音信息来判定在规定时间内对象用户有无发言。
当判定为在规定时间内对象用户发言了的情况下(步骤s103:是),控制部110a(发言控制部115a)判断为正在执行与对象用户之间的对话,并与机器人100b协作地决定作为针对对象用户的发言的应答的发言内容(步骤s104)。控制部110a(发言控制部115a)参照存储部120a的发言信息db123a以及用户信息db121a,决定与对象用户的发言内容相对应、且与用户信息db121a中存储的对象用户的嗜好相适合的话题的候选。在该情况下,作为与对象用户的嗜好相适合的话题的候选,决定与后述的嗜好度a以及b对应的话题。
在该步骤s104中,在决定出的话题的候选为一个时,将其决定为最终的话题。另一方面,在决定出多个话题的候选的情况下,当在机器人100b的存储部120b中存储有发言履历信息时,控制部110a(发言控制部115a)经由通信部170a读出存储部120b中所存储的发言履历信息,并判定在所读出的发言履历信息中是否存在与多个话题的候选中的某一个相同或者相关联的话题、且是从其发言日期时间起到当前(即,机器人100a的发言开始时)为止的经过时间为规定经过时间以内的话题(以下称为“第1比较对象话题”)。
然后,控制部110a(发言控制部115a)为,当判定为在发言履历信息中存在上述第1比较对象话题时,从多个话题的候选中除去与上述第1比较对象话题一致或者相关联的话题,并最终地决定话题。在通过该除去而剩余的话题的候选存在多个的情况下,将从其中随机地选择出的一个话题决定为最终的话题。
另一方面,在决定出多个话题的候选的情况下,当在机器人100b的存储部120b中未存储任何发言履历信息时、或者当判定为在发言履历信息中不存在第1比较对象话题时,将从决定出的多个话题的候选中随机地选择出的一个话题决定为最终的话题。发言控制部115a输出表示按照如以上那样决定出的话题的发言内容的文本数据。
另一方面,当判定为在规定时间内对象用户未发言的情况下(步骤s103:否),控制部110a(发言控制部115a)决定与对象用户交谈的发言的话题(步骤s105)。此时,控制部110a(发言控制部115a)参照存储部120a的发言信息db123a以及用户信息db121a,决定与用户信息db121a中所存储的对象用户的嗜好相适合的多个话题的候选。在该情况下,作为与对象用户的嗜好相适合的话题的候选,决定与后述的嗜好度a以及b对应的话题。
在该步骤s105中,在决定出的话题的候选为一个时,将其决定为最终的话题。另一方面,在决定出多个话题的候选时,与步骤s104的情况相同,从这多个话题的候选中选择最终的话题。具体地说,控制部110a(发言控制部115a)为,在决定出多个话题的候选的情况下,当在机器人100b的存储部120b中存储有发言履历信息时,控制部110a(发言控制部115a)经由通信部170a读出存储部120b中所存储的发言履历信息,并判定在所读出的发言履历信息中是否存在上述第1比较对象话题。
然后,控制部110a(发言控制部115a)为,当判定为在发言履历信息中存在第1比较对象话题时,从多个话题的候选中除去与第1比较对象话题一致或者相关联的话题,并最终地决定话题。在通过该除去而剩余的话题的候选存在多个的情况下,将从其中随机地选择出的一个话题决定为最终的话题。
另一方面,在决定出多个话题的候选的情况下,当在机器人100b的存储部120b中未存储任何发言履历信息时、或者当判定为在发言履历信息中不存在第1比较对象话题时,将从决定出的多个话题的候选中随机地选择出的一个话题决定为最终的话题。
在对象用户在规定时间内未发言的情况下与对象用户交谈的动作,成为对象用户与机器人100a以及机器人100b之间的对话的触发,为了促使对象用户使用对话系统1而实施。
在执行了步骤s104或者步骤s105之后,控制部110a基于按照决定出的话题的发言内容来进行发言(步骤s106)。控制部110a(声音合成部116a)生成与从发言控制部115a输入的表示机器人100a的发言内容的文本数据对应的声音数据,并控制声音输出部150a而输出基于声音数据的声音。
步骤s107~步骤s109是用于判定对象用户针对步骤s106中的机器人100a的发言的反应的处理。
控制部110a(反应判定部117a的声音判定部117aa)首先执行声音判定处理(步骤s107)。此处,参照图7所示的流程图对声音判定处理进行说明。声音判定处理是基于在机器人100a的发言后从对象用户发出的声音来判定对象用户针对机器人100a的发言的反应的处理。
声音判定部117aa为,当开始声音判定处理时,首先判定在步骤s106中的机器人100a的发言后是否存在对象用户的发言(步骤s301)。控制部110a基于用户信息取得部113a在机器人100a的发言后取得的声音信息,判定有无针对机器人100a的发言的对象用户的发言。
在判定为在机器人100a的发言后存在对象用户的发言的情况下(步骤s301:是),声音判定部117aa从针对机器人100a的发言的对象用户的发言中提取特征关键字(步骤s302)。声音判定部117aa基于由声音识别部114生成的表示对象用户的发言内容的文本数据,例如提取与感情相关的关键字,作为对对象用户的发言内容赋予特征的特征关键字。
接着,声音判定部117aa基于特征关键字来判定声音反应极性(步骤s303)。声音判定部117aa例如参照在存储部120a的反应判定信息db124a中作为反应判定信息而存储的图4所示的声音反应极性判定表,根据与所提取的特征关键字建立了对应的声音反应极性来进行判定。声音判定部117aa例如在特征关键字为“喜欢”、“快乐”等的情况下,将声音反应极性判定为“积极”。
另一方面,当判定为在机器人100a的发言后没有对象用户的发言的情况下(步骤s301:否),由于对象用户针对机器人100a的发言的反应不明确,因此声音判定部117aa将声音反应极性判定为“中性”(步骤s304)。
控制部110在执行了步骤s303或者s304之后,结束声音判定处理,使处理返回到对话控制处理。
返回到图5,在执行了声音判定处理(步骤s107)之后,控制部110a(反应判定部117的表情判定部117ba)执行表情判定处理(步骤s108)。此处,参照图8所示的流程图对表情判定处理进行说明。表情判定处理是基于对象用户的表情来判定对象用户针对机器人100a的发言的反应的处理。
控制部110a(反应判定部117a的表情判定部117ba)为,当开始表情判定处理时,首先,从在步骤s106中的机器人100a的发言后由用户信息取得部113a取得的摄像图像中提取对象用户的面部图像(步骤s401)。
接着,表情判定部117ba基于在步骤s401中提取的面部图像,计算对象用户的笑脸度(步骤s402)。控制部110例如参照反应判定信息db124a中所存储的笑脸度信息,基于面部图像中的眼角位置的变化、嘴大小的变化等,在0~100%的范围内计算出对象用户的笑脸度。
接着,表情判定部117ba判定在步骤s402中计算出的对象用户的笑脸度是否为70%以上(步骤s403)。在对象用户的笑脸度为70%以上的情况下(步骤s403:是),控制部110将表情反应极性判定为“积极”(步骤s405)。
在对象用户的笑脸度不为70%以上的情况下(步骤s403:否),控制部110a判定对象用户的笑脸度是否为40%以上且小于70%(步骤s404)。在对象用户的笑脸度为40%以上且小于70%的情况下(步骤s404:是),控制部110将表情反应极性判定为“中性”(步骤s406)。
在对象用户的笑脸度不为40%以上且小于70%的情况下(步骤s404:否),即,在对象用户的笑脸度小于40%的情况下,控制部110将表情反应极性判定为“消极”(步骤s407)。
控制部110a在步骤s405~s407的任一个中判定了对象用户的表情反应极性之后,结束表情判定处理,使处理返回到对话控制处理。
返回到图5,在执行了表情判定处理(步骤s108)之后,控制部110a执行行动判定处理(步骤s109)。此处,参照图9所示的流程图对行动判定处理进行说明。行动判定处理是基于对象用户的行动来判定对象用户针对机器人100a的发言的反应的处理。
控制部110a(反应判定部117a的行动判定部117ca)为,当开始行动判定处理时,首先判定对象用户是否活泼地运动(步骤s501)。行动判定部117ca基于在步骤s106中的机器人100a的发言后由用户信息取得部113a取得的摄像图像中的对象用户的运动来进行判定。在判定为对象用户活泼地运动的情况下(步骤s501:是),行动判定部117ca判定对象用户的视线是否朝向机器人100a(步骤s502)。行动判定部117ca例如根据用户信息取得部113a取得的摄像图像中的眼睛区域内的瞳孔位置和面部的朝向等来确定对象用户的视线的朝向,由此进行判定。
在判定为对象用户的视线朝向机器人100a的情况下(步骤s502:是),行动判定部117ca将行动反应极性判定为“积极”(步骤s508)。另一方面,在判定为对象用户的视线未朝向机器人100a的情况下(步骤s502:否),行动判定部117ca将行动反应极性判定为“消极”(步骤s509)。
在步骤s501中,在判定为对象用户未活泼地运动的情况下(步骤s501:否),行动判定部117ca判定对象用户是否接近了机器人100a(步骤s503)。行动判定部117ca例如根据用户信息取得部113a取得的摄像图像中的面部图像的大小变化来进行判定。
在判定为对象用户接近了机器人100a的情况下(步骤s503:是),行动判定部117ca判定对象用户的视线是否朝向机器人100a(步骤s504)。在判定为对象用户的视线朝向机器人100a的情况下(步骤s504:是),行动判定部117ca将行动反应极性判定为“积极”(步骤s508)。另一方面,在判定为对象用户的视线未朝向机器人100a的情况下(步骤s504:否),行动判定部117ca将行动反应极性判定为“消极”(步骤s509)。
在步骤s503中,在判定为对象用户未接近机器人100a的情况下(步骤s503:否),行动判定部117ca判定对象用户是否从机器人100a远离了(步骤s505)。在判定为对象用户从机器人100a远离了的情况下(步骤s505:是),行动判定部117ca将行动反应极性判定为“消极”(步骤s509)。
另一方面,在判定为对象用户未从机器人100a远离的情况下(步骤s505:否),行动判定部117c判定是否观察不到对象用户的面部(步骤s506)。在对象用户使面部的朝向反转等而变得无法从摄像图像中提取对象用户的面部图像的情况下,行动判定部117ca判定为观察不到对象用户的面部部分。在判定为观察不到对象用户的面部部分的情况下(步骤s506:是),行动判定部117ca将行动反应极性判定为“中性”(步骤s510)。
在判定为不是观察不到对象用户的面部部分的情况下(步骤s506:否),行动判定部117ca判定对象用户的视线是否朝向机器人100a(步骤s507)。在判定为对象用户的视线朝向机器人100a的情况下(步骤s507:是),行动判定部117ca将行动反应极性判定为“积极”(步骤s508)。另一方面,在判定为对象用户的视线未朝向机器人100a的情况下(步骤s507:否),行动判定部117ca将行动反应极性判定为“消极”(步骤s509)。
控制部110为,当在步骤s508~步骤s510的任一个中判定了对象用户的行动反应极性之后,结束行动判定处理,使处理返回到对话控制处理。
返回到图5,在执行了行动判定处理(步骤s109)之后,控制部110a(嗜好判定部118a)执行嗜好判定处理(步骤s110)。此处,参照图10所示的流程图对嗜好判定处理进行说明。嗜好判定处理是如下的处理:使用声音判定处理、表情判定处理、行动判定处理的各判定结果,综合地判定对象用户针对对象用户与机器人100a之间的对话的话题的嗜好度。
嗜好判定部118a为,当开始嗜好判定处理时,首先,确定对象用户与机器人100a之间的对话的话题(步骤s601)。嗜好判定部118a为,在对话控制处理的步骤s105中,当在对象用户在规定时间未发言的情况下与对象用户交谈时,在预先设定有话题的情况下,参照ram等中所存储的话题关键字,确定对象用户与机器人100a之间的对话的话题。另一方面,在未预先设定话题的情况下,基于由声音识别部114a产生的表示对象用户的发言内容的文本数据,从对象用户的发言中提取题关键字,由此确定对象用户与机器人100a之间的对话的话题。例如,根据“喜欢棒球”这样的对象用户的发言来确定“棒球”这样的话题。
接着,嗜好判定部118a判定通过图7的声音判定处理判定出的声音反应极性是否为“积极”(步骤s602),在声音反应极性为“积极”的情况下(步骤s602:是),将嗜好度判定为“嗜好度a”(步骤s609)。
在声音反应极性不为“积极”的情况下(步骤s602:否),嗜好判定部118a判定声音反应极性是否为“消极”(步骤s603)。在声音反应极性为“消极”的情况下(步骤s603:是),嗜好判定部118a判定通过图8的表情判定处理判定出的表情反应极性是否为“积极”(步骤s604)。在表情反应极性为“积极”的情况下(步骤s604:是),嗜好判定部118a将嗜好度判定为“嗜好度b”(步骤s610)。另一方面,在表情反应极性不为“积极”的情况下(步骤s604:否),嗜好判定部118a将嗜好度判定为“嗜好度d”(步骤s612)。
在步骤s603中,在声音反应极性不为“消极”的情况下(步骤s603:否),嗜好判定部118a判定通过图9的行动判定处理判定出的行动反应极性是否为“积极”(步骤s605)。在行动反应极性为“积极”的情况下(步骤s605:是),嗜好判定部118a判定表情反应极性是否为“积极”或者“中性”中的某一个(步骤s606)。在表情反应极性为“积极”或者“中性”中的某一个的情况下(步骤s606:是),嗜好判定部118a将嗜好度判定为“嗜好度a”(步骤s609)。另一方面,在表情反应极性不是“积极”和“中性”的任一个的情况下(步骤s606:否),即,在表情反应极性为“消极”的情况下,嗜好判定部118a将嗜好度判定为“嗜好度c”(步骤s611)。
在步骤s605中,在行动反应极性不为“积极”的情况下(步骤s605:否),嗜好判定部118a判定行动反应极性是否为“中性”(步骤s607),在行动反应极性不为“中性”的情况下(步骤s607:否),嗜好判定部118a将嗜好度判定为“嗜好度c”(步骤s611)。
另一方面,在行动反应极性为“中性”的情况(步骤s607:是),嗜好判定部118a判定表情反应极性是否为“积极”(步骤s608)。嗜好判定部118a为,在表情反应极性为“积极”的情况下(步骤s608:是),将嗜好度判定为“嗜好度b”(步骤s610),在表情反应极性不为“积极”的情况下(步骤s608:否),将嗜好度判定为“嗜好度d”(步骤s612)。
在步骤s609~步骤s612的任一个中,在判定了对象用户的嗜好度之后,嗜好判定部118a结束嗜好判定处理,使处理返回到对话控制处理。
返回到图5,在执行了嗜好判定处理(步骤s110)之后,控制部110a将嗜好判定结果反映到嗜好度信息中(步骤s111)。控制部110a为,作为嗜好判定处理的嗜好判定结果,将使对象用户与机器人100a之间的对话的话题和嗜好度建立了对应的信息,追加到用户信息db121a中所存储的用户信息的嗜好度信息中,而对嗜好度信息进行更新。由此,嗜好度信息按照每个用户usr被更新。对象用户与机器人100a之间的对话的话题是ram等中所存储的话题关键字所表示的话题。另外,控制部110a对通信部170a进行控制,将使对象用户与机器人100a之间的对话的话题和嗜好度建立了对应的信息,发送给机器人100b。接受到该信息的机器人100b同样地将其追加到用户信息db121b中所存储的用户信息的嗜好度信息中,而对嗜好度信息进行更新。由此,机器人100a与机器人100b能够共享各自的嗜好判定结果。此外,与多个话题的各个建立对应地存储的嗜好度信息所包含的嗜好度的初始值被设定为嗜好度a。如此,包含反应判定部117a(117b)、嗜好判定部118a(118b)的控制部110a(110b)以及通信部170a(170b)作为本发明的反应取得单元发挥功能。
在执行了步骤s111的处理之后,控制部110a判定在机器人100a周围是否存在对象用户(步骤s112)。在判定为在机器人100a周围存在对象用户的情况下(步骤s112:是),控制部110a判断为能够继续与对象用户进行对话,并使处理返回到步骤s103。在该步骤s112为是的情况下的步骤s103中,判定从步骤s106的发言完成起的经过时间是否为规定时间以内。
另一方面,在判定为在机器人100a周围不存在对象用户的情况下(步骤s112:否),控制部110a判断为不能够继续与对象用户进行对话,并解除与机器人100b(其他机器人)的通信连接(步骤s113)。控制部110a对通信部170a进行控制而进行基于通信方式的规定的过程,由此解除与机器人100b的通信连接。之后,控制部110a结束对话控制处理。
以上是机器人100a的控制部110a执行的对话控制处理,机器人100b的控制部110b执行的对话控制处理也相同。如图5所示,控制部110b开始对话控制处理。如图6所示那样执行用户确定处理。
在图5的步骤s103中,在判定为在规定时间内对象用户发言了的情况下(步骤s103:是),控制部110b(发言控制部115b)判断为正在执行与对象用户的对话,并决定作为针对对象用户的发言的应答的发言内容(步骤s104)。控制部110b(发言控制部115b)参照存储部120b的发言信息db123b以及用户信息db121b,决定与对象用户的发言内容对应、且与对象用户的嗜好相适合的话题的候选。
在该步骤s104中,当决定出的话题的候选为一个时,将其决定为最终的话题。另一方面,在决定出多个话题的候选的情况下,当在机器人100a的存储部120a中存储有发言履历信息时,控制部110b(发言控制部115b)经由通信部170b读出存储部120a中所存储的发言履历信息。然后,控制部110b(发言控制部115b)判定在所读出的发言履历信息中,是否存在与多个话题的候选的某一个相同或者相关联的话题、且是从其发言日期时间起到当前(即机器人100b的发言开始时)为止的经过时间为规定经过时间以内的话题(以下称为“第2比较对象话题”)。
控制部110b(发言控制部115b)为,当判定为存在第2比较对象话题时,从多个话题的候选中除去与上述第2比较对象话题一致或者相关联的话题,并最终地决定话题。
另一方面,在决定出多个话题的候选的情况下,当在机器人100a的存储部120a中未存储任何发言履历信息时、或者当判定为在发言履历信息中不存在第2比较对象话题时,将从决定出的多个话题的候选中随机地选择的一个话题决定为最终的话题。发言控制部115b输出表示按照如以上那样决定出的话题的发言内容的文本数据。
另一方面,在判定为在规定时间内对象用户未发言的情况下(步骤s103:否),控制部110b(发言控制部115b)决定与对象用户交谈的发言内容(步骤s105)。此时,控制部110b(发言控制部115b)参照存储部120b的发言信息db123b以及用户信息db121b,决定与用户信息db121b中所存储的对象用户的嗜好相适合的多个话题的候选。在该情况下,作为与对象用户的嗜好相适合的话题,将与嗜好度a以及b对应的话题决定为话题的候选。
在该步骤s105中,在决定出的话题的候选为一个时,将其决定为最终的话题。另一方面,在决定出多个话题的候选时,与步骤s104的情况同样,从这多个话题的候选中选择最终的话题。具体地,控制部110b(发言控制部115b)为,在决定出多个话题的候选的情况下,当在机器人100a的存储部120a中存储有发言履历信息时,控制部110b(发言控制部115b)经由通信部170b读出存储部120a中所存储的发言履历信息。然后,控制部110b(发言控制部115b)判定在所读出的发言履历信息中是否存在上述第2比较对象话题。
控制部110b(发言控制部115b)为,在判定为存在第2比较对象话题时,从多个话题的候选中除去与第2比较对象话题一致或者相关联的话题,并最终地决定话题。
另一方面,在决定出多个话题的候选的情况下,但在机器人100a的存储部120a中未存储任何发言履历信息时、或者当判定为在发言履历信息中不存在第2比较对象话题时,将从决定出的多个话题的候选中随机地选择出的一个话题决定为最终的话题。
控制部110b为,当基于按照决定出的话题的发言内容进行发言(步骤s106)并输出声音时,执行判定对象用户的反应的图7所示的声音判定处理、图8所示的表情判定处理、以及图9所示的行动判定处理。当行动判定处理结束时,执行图10所示的嗜好判定处理。控制部110b将嗜好判定处理中的嗜好判定结果追加到用户信息db121b中所存储的用户信息的嗜好度信息中,而对嗜好度信息进行更新。另外,控制部110b对通信部170b进行控制,将使对象用户与机器人100b之间的对话的话题和嗜好度建立了对应的信息发送给机器人100a。接受到该信息的机器人100a同样地将其追加到用户信息db121a中所存储的用户信息的嗜好度信息中,而对嗜好度信息进行更新。由此,机器人100a与机器人100b共享各自的嗜好判定结果。
此外,在上述的第1实施方式中,当在机器人100a以及100b中的一个机器人发言后、在上述规定经过时间以内另一个机器人发言的情况下,将另一个机器人发言的话题决定为与在另一个机器人发言前的规定经过时间以内一个机器人发言了的话题不同的话题。在除此以外的情况下,相互不协作而相互无关(相互独立)地决定机器人100a以及100b发言的话题。也可以代替该决定方法,在用户信息db121a(db121b)中所存储的对象用户的嗜好信息的数量小于规定的阈值的情况下,将机器人100a以及100b发言的话题决定为相互不同的话题,在为规定的阈值以上的情况下,相互无关地决定机器人100a以及100b发言的话题。即,也可以为,在规定的条件成立时,将机器人100a以及100b发言的话题决定为相互不同的话题,在规定的条件不成立时,相互无关地决定机器人100a以及100b发言的话题。或者,也可以与规定的条件无关,总是相互不协作而相互无关地决定机器人100a以及100b发言的话题(发言内容)。
(第2实施方式)
在上述实施方式中,机器人100a和机器人100b分别具有反应判定、发言控制的功能,但是这些功能也可以与机器人100a和机器人100b相独立地存在。在本实施方式中,设置能够与机器人100a以及机器人100b进行通信的外部服务器,服务器进行机器人100a和机器人100b的反应判定、发言控制的处理。
如图11所示,本实施方式中的对话系统1包括机器人100a、机器人100b以及服务器200。
与第1实施方式同样,机器人100a具备控制部110a、存储部120a、摄像部130a、声音输入部140a、声音输出部150a、移动部160a以及通信部170a。但是,与第1实施方式的情况不同,控制部110a不具备发言控制部115a、反应判定部117a以及嗜好判定部118a。另外,与第1实施方式的情况不同,存储部120a不具备用户信息db121a、声音信息db122a、发言信息db123a以及反应判定信息db124a。机器人100b的构成也与机器人100a同样,具备控制部110b、存储部120b、摄像部130b、声音输入部140b、声音输出部150b、移动部160b以及通信部170b。控制部110b不具备发言控制部115b、反应判定部117b以及嗜好判定部118b。另外,存储部120b不具备用户信息db121b、声音信息db122b、发言信息db123b以及反应判定信息db124b。
服务器200具备控制部210、存储部220以及通信部270。控制部210具备发言控制部215、反应判定部217以及嗜好判定部218。即,代替机器人100a以及机器人100b,服务器200进行用于进行机器人100a以及机器人100b各自的发言的控制、用户的反应的判定、用户的嗜好的判定等各种处理。存储部220具备用户信息db221、声音信息db222、发言信息db223以及反应判定信息db224。即,将机器人100a和机器人100b所具备的上述数据库汇集到服务器200中。另外,存储部220按照每个用户usr来存储发言履历信息,该发言履历信息包含机器人100a和机器人100b进行了发言的发言日期时间以及所发言的话题等。服务器200经由通信部270、机器人100a的通信部170a以及机器人100b的通信部170b与机器人100a以及机器人100b进行无线数据通信。由此,服务器200控制机器人100a和机器人100b与对象用户进行对话的情况。如此,通信部170a、170b作为本发明的第1通信单元发挥功能。另外,通信部270作为本发明的第2通信单元发挥功能。
接着,对本实施方式中的对话控制处理进行说明。此处,以机器人100a的对话控制处理为例进行说明。机器人100a的控制部110a以用户检测部111a在机器人100a周围检测到用户usr的情况为契机,开始对话控制处理。
控制部110a为,当开始对话控制处理(参照图5)时,首先,执行用户确定处理。控制部110a检索与从摄像图像中提取出的面部图像对应的登记用户,该摄像图像是从摄像部130a取得的。控制部110a(用户确定部112a)访问服务器200的存储部220的用户信息db221,将从摄像图像中提取出的面部图像与用户信息db221中所存储的多个用户各自的面部图像进行对照,将用户usr确定为对象用户。此处,控制部110a作为本发明的对象确定单元发挥功能。
接受到用户usr的信息的服务器200的控制部210为,在判定为在规定时间内对象用户进行了发言的情况下,控制部210(发言控制部215)判断为正在执行与对象用户的对话,并决定作为针对对象用户的发言的应答的发言内容。控制部210(发言控制部215)参照存储部220的发言信息db223以及用户信息db221,决定与对象用户的发言内容对应、且与对象用户的嗜好相适合的话题的候选。
在决定出的话题的候选为一个时,将其决定为最终的话题。另一方面,在决定出多个话题的候选的情况下,当在存储部220中存储有机器人100b的发言履历信息时,控制部210(发言控制部215)读出存储部220中所存储的发言履历信息,并判定在所读出的发言履历信息中是否存在第1比较对象话题。
控制部210(发言控制部215)为,当判定为存在第1比较对象话题时,从多个话题的候选中除去与上述第1比较对象话题一致或者相关联的话题,并最终地决定话题。
另一方面,在决定出多个话题的候选的情况下,在未存储任何的机器人100b的发言履历信息时、或者在判定为在发言履历信息中不存在第1比较对象话题时,将从决定出的多个话题的候选中随机地选择出的一个话题决定为最终的话题。发言控制部215输出表示按照如以上那样决定的话题的发言内容的文本数据。
另一方面,在判定为在规定时间内对象用户未发言的情况下,控制部210(发言控制部215)决定与对象用户交谈的发言内容。此时,发言控制部215参照存储部220的发言信息db223以及用户信息db221,决定与用户信息db221中所存储的对象用户的嗜好相适合的多个话题的候选。
在决定出的话题的候选为一个时,将其决定为最终的话题。另一方面,在决定出多个话题的候选时,从这多个话题的候选中选择最终的话题。在决定出多个话题的候选的情况下,当存储有机器人100b的发言履历信息时,控制部210(发言控制部215)读出发言履历信息,并判定是否存在第1比较对象话题。
控制部210(发言控制部215)为,在判定为存在第1比较对象话题时,从多个话题的候选中除去与第1比较对象话题一致或者相关联的话题,并最终地决定话题。
另一方面,在决定出多个话题的候选的情况下,在未存储任何的机器人100b的发言履历信息时、或者在判定为在发言履历信息中不存在第1比较对象话题时,将从决定出的多个话题的候选中随机地选择出的一个话题决定为最终的话题。
机器人100a经由通信部170a接收文本数据,并发送到声音合成部116a。声音合成部116a访问服务器200的存储部220的声音信息db222,使用声音信息db222中所保存的音响模型等,根据所接收到的文本数据来生成声音数据。声音合成部116a对声音输出部150a进行控制,对所生成的声音数据进行声音输出。
接着,执行反应判定处理(参照图7到图9),该反应判定处理判定对象用户针对机器人100a的发言的反应。
控制部210(反应判定部217的声音判定部217a)执行声音判定处理(参照图7)。声音判定部217a基于在机器人100a发言后对象用户发出的声音,来判定对象用户针对机器人100a的发言的反应。当对象用户发言时,机器人100a的声音识别部114a访问服务器200的存储部220的声音信息db222,使用声音信息db222中所保存的音响模型等,根据声音数据来生成文本数据。文本数据被发送到服务器200。声音判定部217a基于通过通信部270接收到的文本数据,判定对象用户针对机器人100a以及机器人100b的发言的反应。
在执行了声音判定处理之后,控制部210(反应判定部217的表情判定部217b)执行表情判定处理(参照图8)。表情判定部217b基于机器人100a发言后的对象用户的表情,判定对象用户针对机器人100a的发言的反应。当机器人100a的用户信息取得部113a取得用户的摄像图像时,用户信息取得部113a经由通信部170a将摄像图像发送到服务器200。表情判定部217b从经由通信部270取得的摄像图像中检测对象用户的面部的特征量,参照存储部220的反应判定信息db224中所存储的笑脸度信息,基于所检测到的特征量来计算对象用户的笑脸度。表情判定部217b根据计算出的笑脸度来判定对象用户针对机器人100a的发言的反应。
在执行了表情判定处理之后,控制部210执行行动判定处理(参照图9)。行动判定部217c基于机器人100a发言之后的对象用户的行动,来判定对象用户针对机器人100a的发言的反应。行动判定部217c基于从经由通信部270取得的摄像图像中检测出的对象用户的行动,来判定对象用户针对机器人100a的发言的反应。
在执行了行动判定处理之后,控制部210(嗜好判定部218a)执行嗜好判定处理(参照图10)。嗜好判定部218确定对象用户与机器人100a之间的对话的话题,并基于反应判定部217的各判定结果,来判定表示对象用户针对话题的嗜好的高度的嗜好度。
在执行了嗜好判定处理之后,控制部210将嗜好判定结果反映到嗜好度信息中。控制部210为,作为嗜好判定处理的嗜好判定结果,将使对象用户与机器人100a之间的对话的话题和嗜好度建立了对应的信息,追加到用户信息db221中所存储的用户信息的嗜好度信息中,而对嗜好度信息进行更新。由此,嗜好信息按照每个用户usr被更新。
对于机器人100b也进行同样的控制处理。在第1实施方式中,机器人100a将对象用户与机器人100a之间的对话的嗜好度信息进行更新,并且发送给机器人100b,接受到该信息的机器人100b同样地将用户信息db121b中所存储的嗜好度信息进行更新。由此,机器人100a与机器人100b能够共享各自的嗜好判定结果。与此相对,在本实施方式中,在服务器200的用户信息db221中按照每个用户usr存储有机器人100a以及机器人100b的嗜好度信息,因此不需要对相互的嗜好度信息进行更新。
在上述实施方式中,服务器200执行了机器人100a以及机器人100b各自的发言的控制、用户的反应的判定、以及用户的嗜好的判定等各种处理。但是,并不限于此,服务器200能够选择地执行机器人100a以及机器人100b的任意处理。例如,也可以为,服务器200的控制部210仅具有发言控制部215,并仅执行机器人100a以及机器人100b的发言控制的处理,其他处理由机器人100a以及机器人100b执行。另外,也可以为,机器人100a以及机器人100b的用户检测、用户确定、用户信息取得、声音识别、声音合成、发言控制、反应判定、嗜好判定的处理全部由服务器执行。另外,在本实施方式中,服务器200的存储部220具备用户信息db221、声音信息db222、发言信息db223、以及反应判定信息db224。但是,并不限于此,服务器200能够具备任意的数据库。例如,在本实施方式中也可以为,不是服务器200具备声音信息db222,而是机器人100a以及机器人100b分别具备声音信息db222。另外,关于用户信息db221的确定用户的面部信息,也可以是不仅服务器200具备,而且机器人100a以及机器人100b也分别具备。由此,在声音识别、声音合成、用户确定时,机器人100a以及机器人100b不需要访问服务器200。
如以上说明的那样,根据第1实施方式,对话系统1具备机器人100a以及机器人100b,并基于对对象用户针对机器人100a的发言的反应进行了判定的结果(即对象用户的嗜好信息)以及对对象用户针对机器人100b的发言的反应进行了判定的结果(即对象用户的嗜好信息),控制机器人100a以及机器人100b各自的发言。
根据第2实施方式,对话系统1具备机器人100a、机器人100b以及服务器200,服务器200基于对对象用户针对机器人100a的发言的反应进行了判定的结果(即对象用户的嗜好信息)以及对对象用户针对机器人100b的发言的反应进行了判定的结果(即对象用户的嗜好信息),控制机器人100a以及机器人100b各自的发言。通过以上,根据第1以及第2实施方式,能够高精度且有效地掌握对象用户的喜好,并进行与对象用户的喜好相符合的对话。
此外,本发明不限定于上述实施方式,能够进行各种变形和应用。上述实施方式也可以如以下那样变形。
在上述实施方式中,机器人100a与机器人100b被设置在相互的发言未被对象用户识别的场所。与此相对,对机器人100a与机器人100b被设置在相互的发言被对象用户识别的场所的情况下的变形例进行说明。在该情况下,机器人100a和机器人100b能够同时与对象用户进行对话。但是,当机器人100a和机器人100b的发言时刻重复或者连续时,有可能无法适当地判断对象用户是对哪个发言进行了反应。于是,无法适当地取得对象用户的嗜好信息,另外,无法适当地应答。因此,发言控制部115a(115b)为,为了防止机器人100a以及机器人100b的发言时刻相互重复、或者相互连续,而与机器人100b的发言控制部115b(机器人100a的发言控制部115a)协作地决定机器人100a(100b)的发言开始时期。发言控制部115a(115b)将机器人100a(100b)的发言开始时期决定为,机器人100a以及机器人100b彼此的发言间隔例如成为足够判断对象用户的反应的时间等规定时间以上。另外,机器人100b的发言控制部115b(机器人100a的发言控制部115a)将机器人100b(100a)的发言开始时期决定为,机器人100b(100a)不会在机器人100a(100b)的发言中以及发言结束紧后连续地发言。机器人100a和机器人100b的发言开始时期,除了由发言控制部115a、115b分别决定以外,也可以由某一方决定。在服务器200对机器人100a以及机器人100b的发言进行控制的情况下,发言控制部215决定二者的发言开始时期。由此,机器人100a以及机器人100b的发言不会相互连续地进行,而是在相互相差规定时间以上的定时进行。由此,能够高精度地掌握对象用户的嗜好,并进行与对象用户的嗜好相符合的对话。
并且,在上述变形例中也可以为,发言控制部115a与机器人100b的发言控制部115b协作,将机器人100a以及机器人100b发言的话题决定为相互不同的话题。在该情况下,也可以与第1实施方式的情况同样,当在机器人100a以及100b中的一个机器人发言后、在上述规定经过时间以内另一个机器人发言的情况下,将另一个机器人发言的话题决定为与在另一个机器人的发言前的规定经过时间以内一个机器人进行了发言的话题不同的话题,在除此以外的情况下,相互不协作且相互无关(相互独立)地决定机器人100a以及100b发言的话题。或者,在该情况下,也可以为,在用户信息db121a(db121b)中所存储的对象用户的嗜好信息的数量小于规定的阈值的情况下,将机器人100a以及100b发言的话题决定为相互不同的话题,在为规定的阈值以上的情况下,相互无关地决定机器人100a以及100b发言的话题。或者,也可以与上述那样的规定条件无关,总是相互不协作且相互无关地决定机器人100a以及100b发言的话题(发言内容)。
另外,例如,也可以具备根据发言控制部115a对发言的控制来对移动部160a进行控制的移动控制单元。移动控制单元例如可以将移动部160a控制为,与机器人100a的发言开始相配合地使机器人100a接近对象用户。
例如,也可以为,构成对话系统1的多个机器人100采用主设备/从设备方式,例如,作为主设备发挥功能的机器人100,将作为从设备发挥功能的机器人100的发言内容包含在内而一并决定,并对作为从设备发挥功能的机器人100指示基于所决定的发言内容进行发言。在该情况下,作为主设备发挥功能的机器人100和作为从设备发挥功能的机器人100的决定方法是任意的,例如,可以使最先检测以及确定了周围的用户usr的机器人作为主设备发挥功能,使其他机器人100作为从设备发挥功能。另外,例如,可以使最先被用户usr接通电源的机器人100作为主设备发挥功能,使接着被接通电源的机器人100作为从设备发挥功能,也可以构成为,用户usr能够使用物理的开关等设定作为主设备发挥功能的机器人100和作为从设备发挥功能的机器人100。
另外,可以预先决定作为主设备发挥功能的机器人100和作为从设备发挥功能的机器人100。在该情况下,也可以省略一部分作为从设备发挥功能的机器人100能够执行的功能。例如,在按照作为主设备发挥功能的机器人100的指示来进行发言的情况下,作为从设备发挥功能的机器人100也可以不具备与发言控制部115a等相当的功能。
另外,在上述实施方式中,对机器人100a和机器人100b与对象用户进行对话的例子进行了说明,但是也可以构成为,通过1台机器人100来实施与对象用户的对话。在该情况下,例如,1台机器人100为,与上述的作为主设备发挥功能的情况同样,一并决定自身的发言内容以及其他机器人的发言内容,并改变声色地将所决定的发言内容依次进行声音输出,由此表现为如1台机器人100对其他机器人的发言进行代言即可。
在上述实施方式中,以对话系统1是具备多个机器人100的机器人系统的情况为例进行了说明,但是对话系统1也可以由具备机器人100所具备的构成的全部或者一部分的多个对话装置构成。
在上述实施方式中,控制部110a、110b的cpu执行的控制程序预先存储在rom等中。但是,本发明并不限定于此,也可以将用于执行上述各种处理的控制程序安装到现存的通用计算机、架构、工作站等电子设备,由此使其作为与上述实施方式所涉及的机器人100a、100b相当的装置发挥功能。例如,作为与机器人100a、100b相当的发言装置,包含具有声音辅助功能的便携终端、数字标牌等。所谓数字标牌是指在显示器等电子显示设备上显示影像、信息的系统。此外,发言并不限于通过扬声器进行声音输出,也包含在显示设备上作为文字进行显示。因此,将发言用文字显示的便携终端、数字标牌等也被包含作为与机器人100a、100b相当的发言装置。
这样的程序的提供方法是任意,例如,可以保存于计算机能够读取的记录介质(软盘、cd(compactdisc:紧凑型盘)-rom、dvd(digitalversatiledisc:数字多功能光盘)-rom)等而分发,也可以预先将程序保存在互联网等网络上的存储器中,通过对其进行下载来提供。
另外,在通过os(operatingsystem:操作系统)与应用程序的分担、或者os与应用程序的协作来执行上述处理的情况下,也可以仅将应用程序保存到记录介质、存储器中。另外,也能够在载波上重叠程序而经由网络发布。例如,可以在网络上的公告板(bulletinboardsystem(bbs):电子公告板系统)中公告上述程序,并经由网络发布程序。而且,也可以构成为,启动所发布的程序,在os的控制下,与其他应用程序同样地执行,由此能够执行上述处理。
本发明在不脱离本发明的广义的精神和范围内,能够成为各种实施方式以及变形。另外,上述实施方式是用于说明本发明的,并不限定本发明的范围。即,本发明的范围不由实施方式、而由专利请求的范围表示。并且,在专利请求的范围内以及与专利请求的范围同等的发明的意义的范围内实施的各种变形被视为在本发明的范围内。
- 还没有人留言评论。精彩留言会获得点赞!