尼罗罗非鱼Ly75基因克隆、原核表达与抗罗非鱼OnLy75多克隆抗体的制备方法与流程
本发明涉及基因工程技术领域,具体为尼罗罗非鱼(Oreochromis niloticus)生殖细胞表面标记基因淋巴细胞抗原75(OnLy75)的克隆、原核表达和抗罗非鱼OnLy75多克隆抗体制备的方法。
背景技术:
:
淋巴细胞抗原75基因(Lymphocyte Antigen 75,Ly75)也称为DEC205/CD205基因或gp200-MR6基因。该基因编码的I型跨膜表面蛋白属于C型凝集素超家族成员之一,该蛋白超家族还包括甘露糖受体(Mannose receptor,MR),M型磷脂酶A2受体(M-type phospholipase A2receptor,PLA2R)和尿激酶型纤维蛋白溶酶原激活剂相关蛋白(uPAR-associated protein,uPARAP/Endo180)。Ly75最先发现于鼠树突状细胞和胸腺上皮细胞表面,随后人的Ly75基因得到克隆,序列分析表明这种蛋白与MR、PLA2R在整体结构上相似,差别仅在于该蛋白包含10个CTLDs结构域。之后的研究发现Ly75分布广泛,不仅在树突状细胞中表达,还在胸腺上皮细胞、肺泡上皮细胞、肠上皮细胞等上皮细胞中,B淋巴细胞、T淋巴细胞等免疫细胞以及生殖细胞中表达。
哺乳动物Ly75的研究主要集中于该基因在免疫系统中发挥的作用;鱼类Ly75的研究虽然起步较晚,但已在虹鳟(Rainbow trout)、太平洋蓝鳍金枪鱼(Thunnus orientalis)、大西洋鲑(Atlantic salmon)和斑马鱼(Danio rerio)等鱼类中有相关研究报道,而罗非鱼中尚未见相关研究报道。虹鳟中的研究结果表明Ly75主要在精巢和鳃中表达,在头肾和脑表达较弱;在精巢中的原位杂交和免疫组化结果显示Ly75mRNA和蛋白质主要在A型精原细胞中特异表达。在太平洋蓝鳍金枪鱼、大西洋鲑和斑马鱼的研究中,原位杂交和免疫组化实验也得到了类似的结果,即Ly75的mRNA和蛋白质都在A型精原细胞中有特异表达。进一步的研究也证实了在硬骨鱼中Ly75的氨基酸序列具有高度的保守性。因此认为Ly75可作为某些鱼类原始生殖细胞A型精原细胞的标记基因来研究。
罗非鱼原产于非洲,1956年首次被引入我国,由于其生长快、食性杂、抗病力强,对水质要求较低,适合于各种养殖模式,因而规模化养殖发展极为迅猛,目前已成为世界性的主要养殖鱼类,也是我国最大宗的出口淡水养殖品种,产量和出口量分别占全球总量的40%和70%左右。
在生产养殖中,罗非鱼性成熟早、繁殖周期短、繁殖力强,雌、雄鱼混养易使成鱼规格不整齐,进而影响经济效益。且罗非鱼的生长过程中,雄鱼比雌鱼生长快40%~50%,在相同条件下,若能进行全雄养殖,则可极大地提高罗非鱼单位面积产量和商品鱼的规格。因而对于罗非鱼而言,研究其精原细胞标记基因,对于鱼类性别控制的研究具有重要作用。
技术实现要素:
:
本发明目的是提供一种尼罗罗非鱼淋巴细胞抗原75基因(OnLy75)克隆、原核表达和抗罗非鱼OnLy75多克隆抗体的制备方法。
在本发明中,申请人从尼罗罗非鱼在受精后8.5天的整个胚胎的cDNA中分离出一个尼罗罗非鱼淋巴细胞抗原75基因。
本发明提供的淋巴细胞抗原75基因,名称为OnLy75,尼罗罗非鱼淋巴细胞抗原75基因。OnLy75的cDNA序列为序列表中SEQ ID NO.1所示的核苷酸序列。共有6632个碱基组成,包含5199bp的开放阅读框,87bp的5’非翻译区和1346bp的3’非翻译区。开放阅读框起始于起始密码子ATG,终止于终止密码子TAA。
所述尼罗罗非鱼OnLy75基因的编码序列位于序列表SEQ ID NO.1的5’端第88~5286位脱氧核苷酸,编码1732个氨基酸。5’非翻译区位于序列表SEQ ID NO.1的5’端第1~87位脱氧核苷酸,3’非翻译区位于序列表SEQ ID NO.1的5’端第5287~6632位脱氧核苷酸。
本发明提供的淋巴细胞抗原75蛋白名称为OnLy75,尼罗罗非鱼淋巴细胞抗原75蛋白,其氨基酸序列为序列表中SEQ ID NO.2所示的氨基酸序列。
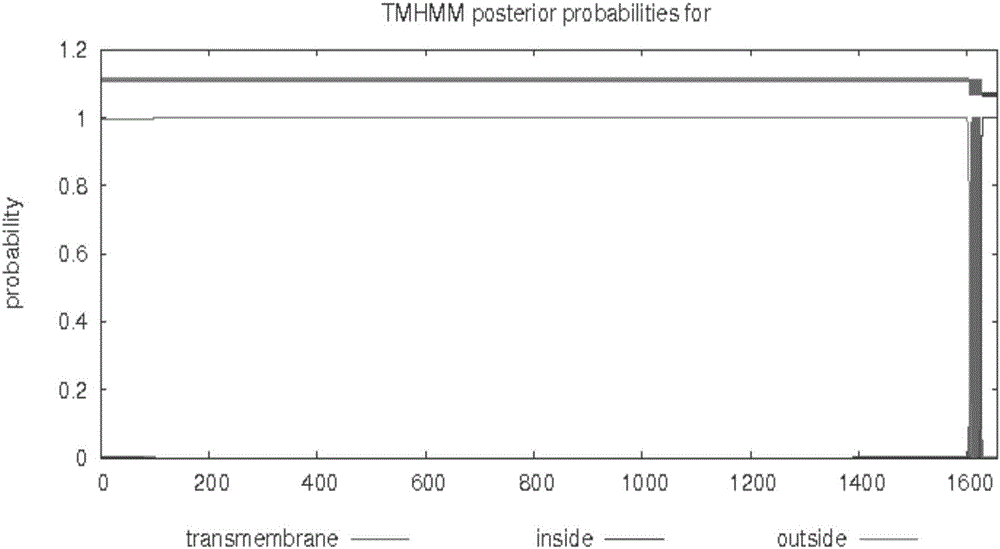
序列表中的SEQ ID NO.2所示的OnLy75蛋白共由1732个氨基酸残基所组成,使用ExPASy服务器上的工具ProtParam分析其的理化性质,结果显示OnLy75的分子量为196.5千道尔顿,理论等电点为6.41,总共包括27060个原子,推测其分子式为C8714H13253N2379O2606S108;在组成OnLy75蛋白的20种氨基酸中,丝氨酸所占的比例最高,达到8.3%,而蛋氨酸所占的比例最低,为2.5%;脂肪指数为67.22,半衰期是30h,不稳定指数是38.17,属于稳定蛋白;亲水性平均指数是-0.476,属于亲水性蛋白。用SignalP 4.1 Server在线分析,结果表明OnLy75蛋白为分泌蛋白,存在信号肽序列,具体序列为MLSLSRAPLCLCLLILLEAAVHWGTG,说明OnLy75蛋白可能在跨膜运输中起信号识别作用;剪切位点位于SEQ ID NO.2所示的氨基酸序列的第26和27位氨基酸之间,成熟肽始于第26位氨基酸之后。使用TMHMM2.0对OnLy75蛋白成熟肽链进行跨膜区分析,预测结果显示SEQ ID NO.2所示的氨基酸序列的第27~1630位氨基酸位于细胞膜表面,1631~1653位氨基酸之间形成一个典型的跨膜螺旋区,与该蛋白质的疏水性区域分析结果基本一致,表明OnLy75蛋白可能是一个与细胞信号传导有关的膜受体蛋白。使用SMART软件在线搜索OnLy75氨基酸的保守结构域,结果显示:OnLy75存在1个SP(The signal peptide),1个CysR(cysteine-rich),1个FNII(fibronectin II),10个CTLDs(C-typelectin-like)和1个TM(transmembrane)结构域。
本发明的第二目的是提供一种罗非鱼OnLy75蛋白原核表达的方法,包括下列步骤:
(1)提取尼罗罗非鱼受精后8.5天胚胎的总RNA;
(2)构建用于表达罗非鱼OnLy75蛋白的大肠杆菌重组表达载体;
(3)将重组表达载体导入大肠杆菌表达菌株BL21(DE3)中,构建携带重组表达载体的工程菌;
(4)工程菌扩大培养至OD600达到0.4~0.6时,通过IPTG诱导OnLy75重组蛋白表达;
(5)抽提诱导表达后的工程菌总蛋白,通过SDS-PAGE电泳鉴定OnLy75重组蛋白的表达;
(6)过柱纯化OnLy75重组蛋白。
进一步的,步骤(2)中,构建重组表达载体时,克隆尼罗罗非鱼OnLy75基因所用的引物见表1。
进一步的,步骤(2)中,构建重组表达载体所涉及的核苷酸序列为序列表中SEQ ID NO.3所示的核苷酸序列。该序列位于序列表SEQ ID NO.1的5’端第3928~5120位。
PCR扩增条件为:95℃预变性5min,95℃变性30s,57℃退火30s,72℃延伸1min,进行35个循环,最后72℃延伸10min。
进一步的,步骤(4)所用IPTG的浓度为0.5mmol/L,诱导时间为4小时。
进一步的,步骤(5)中抽提诱导表达后的工程菌总蛋白所用方法为超声破碎法,其中超声破碎仪设置的参数为:功率260W,破碎时间2s,间隔5s,破碎30min。
本发明提供的罗非鱼OnLy75重组蛋白的氨基酸序列为序列表中SEQ ID NO.4所示的氨基酸序列。该序列处于SEQ ID NO.2所示的氨基酸序列的第1281~1677位。
本发明的第三目的是提供一种抗罗非鱼OnLy75多克隆抗体的制备方法,将OnLy75重组蛋白的工程菌接种到5mL含有浓度为100μg/mL氨苄青霉素的LB液体培养基中,37℃、250rpm振荡培养过夜活化。取1mL活化的工程菌接种于50mL含有浓度为100μg/mL氨苄青霉素的LB液体培养基中37℃、250rpm振荡培养,待菌液的OD600到达0.4~0.6时加入诱导剂IPTG,终浓度为0.5mmol/L,37℃诱导4小时。4℃离心收集菌体后经超声破碎抽提工程菌总蛋白,总蛋白经镍柱亲和层析法纯化。将纯化后的OnLy75重组蛋白作为抗原免疫哺乳动物,免疫前采血2mL,收集血清作为阴性血清。首次免疫时,取1mL重组蛋白溶液(400μg/mL)与1mL完全佐剂充分混合形成稳定的乳剂制备获得免疫复合物,然后进行免疫。加强免疫时,等量蛋白与同体积不完全佐剂混匀形成乳剂获得免疫复合物后再注射。共免疫4次,免疫周期为2周。免疫完毕后,颈动脉采血,收集抗血清。用纯化的OnLy75重组蛋白对抗血清进行亲和纯化,获得OnLy75纯化后的多克隆抗体。
附图说明
图1 SignalP软件在线分析尼罗罗非鱼OnLy75的信号肽及剪切位点;
图2 TMHMM预测的尼罗罗非鱼OnLy75的蛋白类型;
图3 SMART软件预测的尼罗罗非鱼OnLy75蛋白的结构域;
图4不同物种Ly75蛋白和甘露糖受体家族成员的NJ分子进化树;
图中:nile tilapia-尼罗罗非鱼;human-人;cattle-牛;bluefin tuna-蓝鳍金枪鱼;fugu-河鲀;rainbow trou-虹鳟;Salmo salar-大西洋鲑;zebrafish-斑马鱼;chicken-鸡;rat-大鼠;mouse-小鼠;hamster-仓鼠;Monkey-猴;dog-狗;HMRC1-人甘露糖受体C1;MMRC1-小鼠甘露糖受体C1;MMRC2-小鼠甘露糖受C2;HMRC2-人甘露糖受C2;MPLA2R1-小鼠M型磷脂酶A2受体;HPLA2R1-人M型磷脂酶A2受体
图5尼罗罗非鱼OnLy75重组蛋白工程菌诱导表达的鉴定;
图6兔抗罗非鱼OnLy75多克隆抗体与重组蛋白反应性的检测;
图7兔抗罗非鱼OnLy75多克隆抗体在尼罗罗非鱼体内的Western Blot检测。
具体实施方式
实施例一:OnLy75基因的克隆与序列分析
1.cDNA的制备
根据北京全式金总RNA提取试剂盒的操作说明,提取尼罗罗非鱼受精后8.5天胚胎的总RNA,1%琼脂糖凝胶电泳检测总RNA的提取效果,并用核酸蛋白定量仪(Bio-Rad Smartspic plus)检测RNA纯度和完整性。按照TransScript All-in-One First-Stand cDNA合成试剂盒(全式金)说明书进行扩增尼罗罗非鱼OnLy75基因中间片段的模板cDNA的制备;按照SMARTerTM RACE cDNA Amplification Kit(Clotech)说明书制备RACE-Ready cDNA。
2.OnLy75基因的克隆
根据NCBI上罗非鱼基因组序列中Ly75基因的预测序列,用Primer 5.0软件设计引物Ly75-f1、Ly75-r1和Ly75-f2、Ly75-r2,以8.5天的尼罗罗非鱼总cDNA为模板扩增OnLy75的中间片段。PCR反应体系为:2×Taq MasterMix(全式金)12.5ul,上游引物0.5ul,下游引物0.5ul,cDNA 0.5ul,ddH2O 11ul,Total 25ul。扩增条件为:95℃3min;95℃30sec,57℃30sec,72℃1min,35个循环;72℃10min。PCR结束之后,其反应产物用1%琼脂糖凝胶电泳检测。使用全式金胶回收试剂盒纯化目的片段,把纯化的目的片段与载体pEASY-T3(全式金)连接,连接产物转入E.coli DH5α感受态细胞中,均匀涂布于含氨苄青霉素(100μg/mL)的LB平板上,37℃条件下过夜培养,挑取阳性克隆,然后测序。
根据已获得的中间片段,设计5’RACE引物Ly75-5’RACE-T、Ly75-5’RACE-N和3’RACE引物Ly75-3’RACE-T、Ly75-3’RACE-N,与Smart试剂盒中自带的通用引物UPM和NUPM,巢式PCR扩增OnLy75基因的3’端和5’端。反应条件:PCR扩增程序1:95℃30sec,72℃30min,5cycles;95℃30sec,70℃30sec,72℃30min,5cycles;95℃30sec,68℃30sec,72℃30min,25cycles;72℃10min。PCR扩增程序2:95℃3min;94℃30sec,68℃30sec,72℃3min,25cycles;72℃min。结束之后,其产物用1%琼脂糖凝胶电泳检测。PCR扩增产物的纯化、连接、阳性克隆检测和测序与中间片段克隆的步骤相同。
3.OnLy75基因的序列分析
使用NCBI网站的BLAST(http://blast.ncbi.nlm.nih.gov/Blast.cgi)软件对测序后所得序列进行同源性检索,用DNAMAN软件进行序列拼接,得到OnLy75的全长cDNA序列(序列表SEQ ID NO.1)。利用ORF Finder(http://www.ncbi.nlm.nih.gov/projects/gorf/)在线确定开放阅读框。结果表明OnLy75序列全长6632bp,其中开放阅读框长5199bp,可编码1732个氨基酸。5’非翻译区长87bp,3’非翻译区长1346bp。
TMHMM软件(http://www.cbs.dtu.dk/services/TMHMM-2.0/)对蛋白进行跨膜区域预测;SignalP 4.1Server(http://www.cbs.dtu.dk/services/SignalP/)在线分析蛋白的信号肽;SMART软件(http://smart.embl-heidelberg.de/)在线分析蛋白结构;ExPASy网站分析蛋白质的分子量、等电点;利用TargetP(http://www.cbs.dtu.dk/services/TargetP/)和PSORT(http://psort.hgc.jp/)进行蛋白亚细胞定位。使用ProtParam分析OnLy75基因前体蛋白的理化性质,推测其分子分子量为196.5千道尔顿,理论等电点为6.41,总共包括27060个原子,推测其分子式为C8714H13253N2379O2606S108;在组成OnLy75蛋白的20种氨基酸中,丝氨酸所占的比例最高,达到8.3%,而蛋氨酸所占的比例最低,为2.5%;脂肪指数为67.22,半衰期是30h,不稳定指数是38.17,属于稳定蛋白;亲水性平均指数是-0.476,属于亲水性蛋白。
经SignalP 4.1 Server在线分析,结果显示S=0.978>0.5,表明OnLy75蛋白为分泌蛋白,存在信号肽序列,具体序列为MLSLSRAPLCLCLLILLEAAVHWGTG,说明OnLy75蛋白可能在跨膜运输中起信号识别作用;剪切位点位于SEQ ID NO.2所示的氨基酸序列的第26和27位氨基酸之间,成熟肽始于第26位氨基酸之后。使用TMHMM2.0对OnLy75蛋白成熟肽链进行跨膜区分析,预测结果显示SEQ ID NO.2所示的氨基酸序列的第27~1630位氨基酸位于细胞膜表面,1631~1653位氨基酸之间形成一个典型的跨膜螺旋区,与该蛋白质的疏水性区域分析结果基本一致,表明ly75蛋白可能是一个与细胞信号传导有关的膜受体蛋白。使用SMART软件在线搜索Ly75氨基酸的保守结构域,结果显示:Ly75存在1个SP(The signal peptide),1个CysR(cysteine-rich),1个FNII(fibronectin II),10个CTLDs(C-typelectin-like)和1个TM(transmembrane)结构域。
使用软件clustalX进行氨基酸的多序列比较,DNAstar中的MegAlign比较不同物种同源基因的相似性。结果显示尼罗罗非鱼的OnLy75与蓝鳍金枪鱼(Thunnus orientalis,基因序列号GQ468310)、河鲀(Takifugu rubripes,AB438982)、虹鳟(Oncorhynchus mykiss,GQ468309)、大西洋鲑(Salmo salar,JN712913)、斑马鱼(Danio rerio,XM_690165)等鱼类Ly75的序列相似性为46.96~65.36%,相似性较高。而与鸡(Gallus gallus,AJ574899)、大鼠(Rattus norvegicus,XM_001068965)、小鼠(Mus musculus,U19271)、仓鼠(Mesocricetus auratus,AB059273)、猴(Macaca mulatta,XM_001093552)、人(Homo sapiens,AF011333)、牛(Bos taurus,AY264845)、狗(Canis lupus familiaris,XM_545488)等高等脊椎动物的Ly75的序列相似性在34.13~36.48%。
利用MEGA 5.1软件对尼罗罗非鱼OnLy75氨基酸序列与其他物种的OnLy75氨基酸序列进行邻接(neighbor-joining)聚类分析。在系统进化树中,尼罗罗非鱼首先与蓝鳍金枪鱼、河鲀聚类,然后与虹鳟、大西洋鲑、斑马鱼等聚为一簇。人和哺乳动物聚为一支,而鸟类的鸡单独为一支,位于前面两大分支的中间。
实施例二:OnLy75原核表达载体构建和重组蛋白诱导表达
对根据已克隆得到的OnLy75cDNA序列推测得到的氨基酸序列进行抗原表位预测,得到OnLy75蛋白抗原性比较好的多肽序列,即序列表中SEQ ID NO.4所示的氨基酸序列。根据该多肽对应的核苷酸序列(序列表SEQ ID NO.3所示核苷酸序列,该序列位于序列表SEQ ID NO.1的5’端第3928~5120位。)设计构建原核表达载体所用的引物Ly75-Ef、Ly75Er(引物序列见表1),以8.5天的尼罗罗非鱼总cDNA为模板扩增构建OnLy75原核表达载体的片段。PCR反应体系为:2×Taq MasterMix(全式金)12.5ul,上游引物0.5ul,下游引物0.5ul,cDNA 0.5ul,ddH2O 11ul,Total 25ul。扩增条件为:95℃3min;95℃30sec,57℃30sec,72℃1min,35个循环;72℃10min。PCR结束之后,其反应产物用1%琼脂糖凝胶电泳检测。使用全式金胶回收试剂盒纯化目的片段,把纯化的目的片段插入全式金pEASY-E2表达载体中,连接产物转入E.coli DH5α感受态细胞中,均匀涂布于含氨苄青霉素(100μg/mL)的LB平板上,37℃条件下过夜培养,挑取阳性克隆测序。
将测序正确的克隆扩大培养后,使用全式金质粒小提试剂盒提取重组表达载体pEASY-E2-OnLy75。将该重组表达载体转化大肠杆菌BL21(DE3)感受态细胞,在含氨苄青霉素(100μg/mL)的LB平板上筛选到的克隆即为含有重组表达载体pEASY-E2-OnLy75的工程菌。OnLy75重组蛋白原核表达工程菌单克隆经LB液体培养基培养后使用甘油保存菌种。
将保存的OnLy75重组蛋白原核表达工程菌按照1:500接种到5mL LB液体培养基中37℃培养过夜活化,将活化的工程菌按照1:100的比例接种于50mL LB液体培养基(含氨苄青霉素100μg/mL)中,37℃、250rpm振荡培养至OD600为0.4~0.6时加入IPTG,使其终浓度为0.5mmol/l,诱导培养4小时后离心获取沉淀,PBS重悬菌体后超声破碎,参数为:功率260W,破碎时间2s,间隔5s,破碎30min,分离上清和包涵体沉淀,分别变性处理后进行SDS-PAGE电泳,经考马斯亮蓝染色、脱色后经凝胶成像系统分析。结果表明OnLy75重组蛋白主要以包涵体形式表达。
实施例三:OnLy75重组蛋白纯化
将活化的工程菌接种于50mL LB液体培养基(含氨苄青霉素100μg/mL),37℃,250rpm振荡培养至OD600为0.4~0.6时加入IPTG,使其终浓度为0.5mmol/L,37℃诱导4小时后6000rpm离心10分钟取沉淀,向沉淀中加入3mL的盐酸胍裂解液(100mM磷酸二氢
钠,300mM氯化钠,6M盐酸胍,pH8.0)裂解1h至溶液澄清;12000rpm离心20分钟,收集上清,上清经0.45μm滤膜过滤。10倍柱体积的Ni-Denature-urea(100mM磷酸二氢钠,300mM氯化钠,8M尿素,pH8.0)缓冲液平衡柱子,流速为1mL/min;经滤膜过滤后的1mL上清样经过纯化柱,流速0.5-1mL/min;10倍柱体积的Ni-Denature-urea缓冲液冲洗柱子,流速为1mL/min;5倍柱体积的Ni-Denature-250(100mM磷酸二氢钠,300mM氯化钠,250mM咪唑,PH8.0)缓冲液收集洗脱液得纯化蛋白,流速为1mL/min,收集洗脱缓冲液得纯化的OnLy75重组蛋白,-80℃保存。
本发明提供的罗非鱼OnLy75重组蛋白的氨基酸序列为序列表中SEQ ID NO.4所示的氨基酸序列。该序列处于SEQ ID NO.2所示的氨基酸序列的第1281~1677位。
实施例四:兔抗罗非鱼OnLy75多克隆抗体制备
经实施例三步骤后,参照BCA蛋白浓度测定试剂盒说明,测定纯化后OnLy75重组蛋白的浓度。将纯化后的OnLy75重组蛋白作为抗原免疫新西兰大白兔,免疫前耳静脉采血2mL,收集血清作为阴性血清。首次免疫时,取1mL OnLy75重组蛋白溶液(400μg/mL)与1mL完全佐剂充分混合形成稳定的乳剂(即免疫复合物)后免疫兔子。加强免疫时,制备等量蛋白与同体积不完全佐剂混匀形成乳剂的免疫复合物后再注射。共免疫4次,免疫周期为2周。免疫完毕后,颈动脉采血,收集抗血清。用纯化的OnLy75蛋白对抗血清进行亲和纯化,获得OnLy75纯化后的多克隆抗体。总共4次免疫,最后一次加免7天后,采血,收集抗血清;阴性血清作为阴性对照,ELISA法测定抗体效价,Western blot测定抗体特异性。
抗体效价定义为稀释后的抗血清在490nm吸光度大于免疫前(阴性对照)血清2.1倍时的最高稀释倍数。实验结果表明,经ELISA法测定制备的多克隆抗体抗血清效价大于1:64000;经Western blot分析抗体特异性得出抗体特异性良好。
以上所述仅为本发明的较佳实施例而已,并不用以限制本发明,凡在本发明的精神和原则之内,所作的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。
本发明所涉及的引物见下表
表1尼罗罗非鱼OnLy75基因克隆和原核表达载体构建所用的引物
[0001]
SEQ ID NO.1的序列
(i)序列特征:(A)长度:6632bp;(B)类型:核苷酸(C)链性:单链;(D)1-87:5’非翻译区;(E)88-5286:开放阅读框;(F)5287-6632:3’非翻译区。
(ii)分子类型:核苷酸
(iii)序列描述:SEQ ID NO.1
1 ACATGGGGAG TTATCAACCG GCCTAAACTA AGTGCGCCAC GCTCAGAGGA GGCTTTATGA
61 TTGTCACAAA AAGACTCAGT CGTGACCATG CTGAGTCTAT CCAGAGCGCC TCTTTGCCTT
121 TGTTTGTTGA TATTGTTGGA GGCAGCTGTT CACTGGGGAA CTGGTTCACC GGCTGCAGGT
181 TTAGATGAGG ATGCTTTCAC CATTCAGCAC CAGAGCACAG GGAAATGCCT GAGTGCAAGG
241 GGTCCAGCAA ACCTGAGCCT CGCCACCTGC AACTCAGCCA GCAAGTCCCA ACAGTGGAAG
301 TGGGGTTCAG GTCACCGGCT CTTCCATGTG GGGACATCGC TCTGCATGGC GCTGGACGTC
361 AGTTCCAAGA TGTTGACTAT GTTCGACTGT GGCTCCAACA TCCTGTTATG GTGGCGCTGT
421 TTGGACGGAG CTGTTTACAC TGTTTATCAG ATGGGCCTGG CGGTCAACAA AGGCAAAGTA
481 GCGCTCAGTC GGGAAACTAA TGACACTTGG GTAAGAGGAG AATCCCAAGA CAACATCTGC
541 CAGAGGCCAT ACCGCGTCAT CCATACCATG GATGGGAACT CTGCCGGCAG CCCCTGTGAG
601 TTCCCCTTCA AGTTCAATAA CAGCTGGTAT CATGGATGCC TCCCCGATGC AGAATTCCCT
661 GGAATGTCCT GGTGTGCCAC CTCCTCAGAC TATGACCAAG ACAAGAAGAT GGGATACTGT
721 CTGAAACCTG AGGAGGGCTG CCACACTCTG TTCACCGGTC CAGACGGCGA TTCCTGCTAT
781 GAGTTTGTCA TCAATAGTGC GGTGACCTGG CACGAAGCTC TGGATTCGTG TCGCAGTCAG
841 GGAGCCGATC TGCTTAGTTT CTCTGGCCCT GATGAGCTCA ATTCTACAAT CTTGTTGAAC
901 GGCCTTCGCA GAATGCCTGA GAAGATGTGG ATCGGCCTTC ACCAGTTAGA TACTTCTCAA
961 GGATGGCAGT GGTCTGATGG CTCCCCCCTC TCCATGTTAC GCTGGGAAAA AGGAATGCCC
1021 TTCACCTCCA TCATCATTCA GTCAGACTGT GGAGTCCTGA ACTCTAAGAA CAACTATGAA
1081 ACAATGGCGT GTAACAGGCG GCTGCCATAC GTCTGCAAGA AGAGAGTCAA TGCCAGTGAG
1141 ACAACAACAA CAGATTCTTT TGTCTATAAG GAAACGTTGT GTAAGGATGA CTGGGTGCCA
1201 TGGAATGGAC TTTGTTACAA GTTGATGGAG CAGCCAAAGA ACTTCAGCGC TGCCCAGGAA
1261 CAGTGTAAAG CTGCGAACGG AGTTTTAGCC AGCTTCCACA CGATTGACAG CAAAGAGATG
1321 ATCAGCACTA ATCTCCACGG AGATGGCAAA AATTTAGACG TGTGGATCGG TCTGGTTGGT
1381 GTCGGCGCGA ACCCCACCGT CTTCAACTGG ACGGACGGAG CACCCATCAC TTTCACTTAC
1441 TGGGCTCCAT CACAACCGGT CCAGCCCACT TCGGATACCA GCTGTGTCTC CTACACTGGA
1501 GAGTTTCATA GTTGGCGGGT TGAGGATTGC ACACAGATGC TGCCCTTCAT GTGCCAGAGG
1561 AAAGGAGAGG TCAATGAATC AGCAGCACAG GTCGGATGTA GCTCGAAAGA TGGTTGGAAG
1621 AGACATGGAA ACTCCTGTTA TAAAGTGAAC ACAACGCAAG TGTCCTTCAA GGACCATTGC
1681 AGCATCACCA TAAGAAACAG GTTTGAGCAG GCCTTTATTA ACAGTCTGCT TCAAGAGACG
1741 ACAGGCAAGG AAACTCAGTA TTTTTGGATA GGGTTGCAGG ACATCAACAG CACCAGGGAG
1801 TACAAGTGGG TGAGGGCAGA TGGGTCAATG GATGTGGCGA CATACACCAA CTGGGGCTGG
1861 TTTGAACCAG ATCGGCAAGG AGGGTGTGTT GCAGTTTCCA CTGCAAAGCC TTTGGGTAAG
1921 TGGGAGGTGA AGAACTGCAC TCTCTTCAGG GCCGGCACCA TCTGTAGAAA AGACCTCATT
1981 ATACCTCCTG CCCCAGAACC AGAACCAAAC CTTAATGCAT CGTGTCCTAA TGGCTGGGTG
2041 TCCAGGCCAA ACATCAAATA CTGCTACAAG GTGTTTCATG AAGAAAGGTT GAGCAGGAAG
2101 CGCTCCTGGG AGGAGGCCAT GAGGTTCTGT CAGGCTCTAG GAGCCAATCT TCCCAGTTTC
2161 ACAAACTTGG ATGAAATGAG AGCCCTACAT TTCATTATGA GAGAGACTAT CAGTAATAAT
2221 CGGTACTTCT GGGTCGGCCT GAACAGGAGA AACCCCGCAG ATCGCTCGTG GCAGTGGAGT
2281 GACGGCCGGC CTGTATCTCT AGATATTTCA TACAGAAATT TCTACGAGGA AGATGCGTAC
2341 GATCGGGACT GCACTGCATT CAAGACAATG AAGAACAGCT TGAAACACGT GTTTTACTAT
2401 CTGCTGCACG ACTTGTCTCC CACACCTTTC TACCCCAGAC CCTTTCATTG TGACGCGCAG
2461 CTGGAATGGG TCTGCCAAAT ACCTCGAGGG GTGACACCGA AAACGCCAGA GTGGTACAAT
2521 CCCGATGGGC ATCGTGACAC GTCCACCTTT GTGGATGGAG CAGAGTTTTG GTTTGTTAAT
2581 AAGTCACCGC TCAGTTTTCA GGAGGCGAGG CTCTTTTGCA ATTCTGAAAA CGGTACACTG
2641 GCGGCTCCAA CCAACGCCGA TGCTGCTAAG AAAATCCAAA AGGAGATACA TAAAATATCA
2701 GGTCAGAACC AAAGCTGGTG GATTGATATG ACACAGCCTG GACGCATATT CCCTATGACG
2761 TACAACTCTA TGTACTATAA CCATTTATTT CCCCTGGGTA ACTGCACCTA CATCACTTCT
2821 GAAAGTGTCT TTCCCGACTC TGACCAGTGC TCACGGAGGT TACCGTTTGT GTGTGAAGGA
2881 GTGAACACCA CATTAGTGGA GAAAAACCCC CTGGAGCCTC AGCCTGGAGG ACTGCCCTGT
2941 GGAAAGGAAT CTGTCCCCTT CAGAAATAAA TGCTACACGC TGATGAAGAA TTCAAAACCT
3001 TTTAACTTCA AGGGTGCCGA CGAGGAATGC CAGACGGTAA AGGGAACCTT GGTCACCATC
3061 TCTGATCAGG TGGAGCAAGA TTTCATCAAC ACCCTCCTGA TGGACACAAA AGACATGAAC
3121 AAAACATGGA TTGGTATGAA AATCCAGAAC AGCGAAGCTT CATGGATTGA CAAGTCCAAA
3181 GTGAACTACT TAAATTTTAA CCCTCTGCTC CTGGGCATGC ACAAGGTTGT GGCTATACAT
3241 CCATGGGATC TGGAGAGTTT GGATTTGTGC GTGTTCATGC TCCATAACCC CAAGTCTGAC
3301 ATGCTGGGTA CCTGGGACTA CACCAGCTGC ACAAAGATGC TAAATGTGGC TGTTTGCCAA
3361 CACTATGCAG ATAAGCTAGA GGAGCCACGG GTCCCCACGA AGCCTTTCGT TGTCAATAAC
3421 CACACCGTGC TGCTGCTTGT CAAAAATCTC ACCTGGTCTG AGGCGTCAGA GGAGTGCAAA
3481 AAAAACGACA TGGAACTGGC AAGCGTGGCT GATACCTACA TGCAATCCGT CCTCACCGTG
3541 CACGTGAGCC GTGCAAAAAC ACCCATGTGG ATTGGACTCT TTAGCGAAGA TGACGGGAAC
3601 CACTACCACT GGACTGACCA AAGTCACACT GTGTTCAGTC GCTGGTCTTC TGATGTCACT
3661 AGTGGCCAAT GCGTTTACCT GGACACTGAT GGCTTCTGGA AAGCCACTGA GTGTGAGGAC
3721 ACTCTAGGAG GTGCTATCTG CCACAAACCA AGCAAGCACA AAATCCCTAC ACATAAGGAT
3781 GATTCAATGA AGTGCCCCCA TAAAAAAAAT GGTCCAAACT GGATCCCCTG GAAGAATAAT
3841 TGCTACTCAT TTCAGCTGGT TGGCTCCAGA TGGGAGTCGT ATAACCGAGG ACGTATTGAG
3901 AATATCTGCA AAAAACTTGA TGCAGGTGCA GACATCCTGA CTATCCGAAA TGCACAAGAG
3961 AACGAGTTTA TAAAGAGCCA GCTGCTGCCC TTTGAGTCAT TGGTTCAGTT TGTATGGCTG
4021 GGACTGTTCA AGGATAACAA TGATAACCAG ACAAGGTGGT ATGATGGCAC AAATGTGCAA
4081 TATTCCAACT GGGCGAAAGG CCGACCAAAT TTAGAAAGCC CATTCTTAGC CGGTCTCACG
4141 ACTGATGGCA CGTGGATTCT CGTCGCAAAC AAAGAGCTAC ATCCCATATT CAAGCAGAGG
4201 ACGATTGTGA GCTGCAAGCT GGATAATGAA TCCAAGAAAG AATACAACCA GTCAGCCAAG
4261 GATTTTCAGC AGTATGGTAA CTTAACATAT AGGGTTGTTA CCCGAAAGTT GAATTGGTCT
4321 CAGGCTCTAG GCGAATGTGA TAAGCTTGGA GGCCACCTGG CAAGCATCCA TGACGTGGAG
4381 CACAACGCAC ACCTGAGGCT CATTTCCAAG ATGGATGGCT TCCCACTCTG GATTGGCCTG
4441 TCAAACTATG CTGTCAGTGG CTCACCCTAT GAATGGTCTG ATGGAACAAA ATTTGACTAC
4501 CGTCCCACCA TCTCTAACTC CCAAGACACA CCGAAAACCA ACTGTGTTTA TATAAACCCT
4561 GCTGGAGACT GGAAAAGGAC CAGCTGCGAT GCTATGATCG ATGGCGCCAT CTGTTACACC
4621 ACCAATATTA CCTCTTCTTA CCAAAGAGCC AAACTACAAG ATGGCCCAGA AACTAATCAT
4681 TGCCCTCAGG TTGATGGTAA GTCCAAGTGG GTTCAGCACA AGGATCACTG TTACGCTTTT
4741 GACATGGGCT TCTACAACTA CAGACTCCAC AGCATGGAAC AGGCCAAGGC TCTCTGCCAG
4801 GAGATGGATT CCCATCTACT AACCGTCGAA ACCAAAGACG AAAATGATTT TCTGGCCAAC
4861 TACATCACTG AGCACCCTCT CATCACCAGT CAAGTGTGGC TCGGCATAGA TCTTGATACT
4921 CTTGATACTC AAGGTAAGCC TGTATCCTGG CAGGATGGCT CCCATCTGAA TTTCTCTAAC
4981 TGGTCATCTA CAGCCTTCAC CGGGAAGAAG TCCAGGTCCC AGTGTGCCGT CATGGCGACA
5041 GGCAATGGTG GAAACTGGAA TCTGGTCCCC TGCGAGAGTA GCTACAGCCG TGTTGTTTGC
5101 AAAACGAAAG CAAAGTCTGC AGGCTCCCCG GCGGCACTGG GCTTCTTCAT CGTGGCCCTC
5161 ATCGCTCTCA TTTTAGCCCT CAGCTTTGTC ATCTACAAGA AAAACCGAGC CCGGTTCCAT
5221 TCTTCCGTCC GCTACGAGAG GACCTTTAAC GATATGGACA CCACCAGTAT AATTGATGCA
5281 GACTGAGCCT GCTTCAAGTT TTCAGCCTCA GGAAGTATTG ATATGCCTGC CTCAAGTTAT
5341 TTTTTTTTAA CGTAATCTCC CCCCTCCTCT TTTTAAATTA TTTATTTATC TTTCTCAAAG
5401 CCAAATTTTT TTCTGTGTGA AACTGTAAAT ATAGTTTGAG ATTTGTGAAT ATTTCCCAAT
5461 CAGTTTCTTA ATTTGGGTTC AGATTGTGTT TAATAAGAGC AGCACTGTAT ACTTAATTTT
5521 AATGCGTGGG CTTATTCTTC TTGGTCTTTT TTTTTTTTTA TTTCAATGAT AAAAATGGGA
5581 TTTTCAGATG CTTTACAAAC TTATGCAACC TGCAGCCTTA ACAGCTAAAA TTGCACTGAT
5641 GCATGAGTGA CTTCAAACAT TCACAAACGT GCTTTTAACC AATAATCCAC TGTCTGATTT
5701 ACGTGGCGGG GGGATCAATA TATGAATAGG ATTTTTTTAA AAGCACAGGT CATCTGAAAA
5761 TACAGTAACA ACCTGTTTTC TTTAAAGTGT TTATATATCT AGATTGTATT TCAGGTAACA
5821 CTGCGACATG CCCTGACTTT TGTCTTCAAG CAAAACAGGG AAACTAAAGG CCGTGGCTCT
5881 TAAATCATTT TTCTTTGGTT TGTTGTATGC CGACTGCAAC TCAGCTGTAC TGAAAGCTGG
5941 TTTGACAAAC TAACACTGTG GCCTAAGAAA ATACATGTGT ATTTTAGTTT GACTGCACTT
6001 TAAAGTAACA TTTTTTTAGC TTTGTTTTTT TTTTTTTTAC TTTAAAGCGC AAACATTATC
6061 TAGTTTAATT TTAAATGTAC TTAAAAGATT GTTATAGACA TGTATTCATG TCTAACAATG
6121 GTTTTATTAG TGTGAGGGCA AAAAGGAATT TAAAAAAACA ACTTAATCCT ACTGATAAGC
6181 TTTGAAGGGT CCTCTCCTAG CTTAAGATAC CATATTTAAT GATATGGCTC TGGCTTTACT
6241 ATGTACTTGA CTACTGACCA AGAACGCACT TTAATACCTT GTGGAGAAGC AGTTCCCAAA
6301 TTCAAGCACA GTGAGTTTTG GAAAGTGTTG TTTTTTTGTC ATGTTTGCTA TTGAGATTGC
6361 ACTGCTGTTT CCTGTAAATG CTCTGTAAAT AAGTGATGTT TATTACTGAG AATGAACCAA
6421 AGACGCTCTG ACTCATTTTG AATGGTAAAA GCCAGAGGAA CTGCTTCTGT GTGGCTTGTT
6481 AACCTGTCTT TATATCAAAC TGCAGACCAA ATGGTTGTTT TGCTTGGTTT ACTTTCACGT
6541 CATTGCTGCT CAAACTTATC AGCTCAAATC AGGTGCCGTA TGCTTCCAAT AAAATGCATG
6601 GTTTTCAAAA AAAAAAAAAA AAAAAAAAAA AA
[0002]
SEQ ID NO.2的序列
(i)序列特征:(A)长度:1732个氨基酸;(B)类型:氨基酸(C)链性:单链。
(ii)分子类型:多肽
(iii)序列描述:SEQ ID NO.2
1 MLSLSRAPLC LCLLILLEAA VHWGTGSPAA GLDEDAFTIQ HQSTGKCLSA RGPANLSLAT
61 CNSASKSQQW KWGSGHRLFH VGTSLCMALD VSSKMLTMFD CGSNILLWWR CLDGAVYTVY
121 QMGLAVNKGK VALSRETNDT WVRGESQDNI CQRPYRVIHT MDGNSAGSPC EFPFKFNNSW
181 YHGCLPDAEF PGMSWCATSS DYDQDKKMGY CLKPEEGCHT LFTGPDGDSC YEFVINSAVT
241 WHEALDSCRS QGADLLSFSG PDELNSTILL NGLRRMPEKM WIGLHQLDTS QGWQWSDGSP
301 LSMLRWEKGM PFTSIIIQSD CGVLNSKNNY ETMACNRRLP YVCKKRVNAS ETTTTDSFVY
361 KETLCKDDWV PWNGLCYKLM EQPKNFSAAQ EQCKAANGVL ASFHTIDSKE MISTNLHGDG
421 KNLDVWIGLV GVGANPTVFN WTDGAPITFT YWAPSQPVQP TSDTSCVSYT GEFHSWRVED
481 CTQMLPFMCQ RKGEVNESAA QVGCSSKDGW KRHGNSCYKV NTTQVSFKDH CSITIRNRFE
541 QAFINSLLQE TTGKETQYFW IGLQDINSTR EYKWVRADGS MDVATYTNWG WFEPDRQGGC
601 VAVSTAKPLG KWEVKNCTLF RAGTICRKDL IIPPAPEPEP NLNASCPNGW VSRPNIKYCY
661 KVFHEERLSR KRSWEEAMRF CQALGANLPS FTNLDEMRAL HFIMRETISN NRYFWVGLNR
721 RNPADRSWQW SDGRPVSLDI SYRNFYEEDA YDRDCTAFKT MKNSLKHVFY YLLHDLSPTP
781 FYPRPFHCDA QLEWVCQIPR GVTPKTPEWY NPDGHRDTST FVDGAEFWFV NKSPLSFQEA
841 RLFCNSENGT LAAPTNADAA KKIQKEIHKI SGQNQSWWID MTQPGRIFPM TYNSMYYNHL
901 FPLGNCTYIT SESVFPDSDQ CSRRLPFVCE GVNTTLVEKN PLEPQPGGLP CGKESVPFRN
961 KCYTLMKNSK PFNFKGADEE CQTVKGTLVT ISDQVEQDFI NTLLMDTKDM NKTWIGMKIQ
1021 NSEASWIDKS KVNYLNFNPL LLGMHKVVAI HPWDLESLDL CVFMLHNPKS DMLGTWDYTS
1081 CTKMLNVAVC QHYADKLEEP RVPTKPFVVN NHTVLLLVKN LTWSEASEEC KKNDMELASV
1141 ADTYMQSVLT VHVSRAKTPM WIGLFSEDDG NHYHWTDQSH TVFSRWSSDV TSGQCVYLDT
1201 DGFWKATECE DTLGGAICHK PSKHKIPTHK DDSMKCPHKK NGPNWIPWKN NCYSFQLVGS
1261 RWESYNRGRI ENICKKLDAG ADILTIRNAQ ENEFIKSQLL PFESLVQFVW LGLFKDNNDN
1321 QTRWYDGTNV QYSNWAKGRP NLESPFLAGL TTDGTWILVA NKELHPIFKQ RTIVSCKLDN
1381 ESKKEYNQSA KDFQQYGNLT YRVVTRKLNW SQALGECDKL GGHLASIHDV EHNAHLRLIS
1441 KMDGFPLWIG LSNYAVSGSP YEWSDGTKFD YRPTISNSQD TPKTNCVYIN PAGDWKRTSC
1501 DAMIDGAICY TTNITSSYQR AKLQDGPETN HCPQVDGKSK WVQHKDHCYA FDMGFYNYRL
1561 HSMEQAKALC QEMDSHLLTV ETKDENDFLA NYITEHPLIT SQVWLGIDLD TLDTQGKPVS
1621 WQDGSHLNFS NWSSTAFTGK KSRSQCAVMA TGNGGNWNLV PCESSYSRVV CKTKAKSAGS
1681 PAALGFFIVA LIALILALSF VIYKKNRARF HSSVRYERTF NDMDTTSIID AD
[0003]
SEQ ID NO.3的序列
(i)序列特征:(A)长度:1193bp;(B)类型:核苷酸(C)链性:单链;
(ii)分子类型:核苷酸人工序列
(iii)序列描述:SEQ ID NO.3
1 GCAGACATCC TGACTATCCG AAATGCACAA GAGAACGAGT TTATAAAGAG CCAGCTGCTG
61 CCCTTTGAGT CATTGGTTCA GTTTGTATGG CTGGGACTGT TCAAGGATAA CAATGATAAC
121 CAGACAAGGT GGTATGATGG CACAAATGTG CAATATTCCA ACTGGGCGAA AGGCCGACCA
181 AATTTAGAAA ACCCATTCTT AGCCGGTCTC ACGACTGATG GCACGTGGAT TCTCGTCGCA
241 AACAAAGAGC TACACCCCAT ATTCAAGCAG AGGACGATTG TGAGCTGCAA GCTGGATAAT
301 GAATCCAAGA AAGAATACAA CCAGTCAGCC AAGGATTTTC AGCAGTATGG TAACTTAACA
361 TATAGGGTTG TTACCCGAAA GTTGAATTGG TCTCAGGCTC TAGTCGAATG TGATAAGCTT
421 GGAGGCCACC TGGCAAGCAT CCATGACGTG GAGCACAACG CACACCTGAG GCTCATTTCC
481 AAGATGGATG GCTTCCCACT CTGGATTGGC CTGTCAAACT ATGCTGTCAG TGGCTCACCC
541 TATGAATGGT CTGATGGAAC AAAATTTGAC TACCGTCCCA CCATCTCTAA CTCCCAAGAC
601 ACACCGAAAA CCAACTGTGT TTATATAAAC CCTGCTGGAG ACTGGAAAAG GACCAGCTGC
661 GATGCTATGA TCGATGGCGC CATCTGTTAC ACCACCAATA TTACCTCTTC TTACCAAAGA
721 GCCAAACTAC AAGATGGCCC AGAAACTAAT CATTGCCCTC AGGTTGATGG TAAGTCCAAG
781 TGGGTTCAGC ACAAGGATCA CTGTTACGCT TTTGACATGA GCTTCTACAA CTACAGACTC
841 CACAGCATGG AACAGGCCAA GGCTCTCTGC CAGGAGATGG ATTCTCATCT ACTAACCATC
901 GAAACCAAAG ACGAAAATGA TTTTCTGGCC AACTACATCA CTGAACACCC TCTCATCACC
961 AGTCAAGTGT GGCTCGGCAT AGATCTTGAT ACTCTTGATA CTCAAGGTAA GCCTGTATCC
1021 TGGCAGGATG GCTCCCATCT GAATTTCTCT AACTGGTCAT CTACAGCCTT CACCGGGAAG
1081 AAGTCCAGGT CCCAGTGTGC CGTCATGGCG ACAGGCAATG GTGGAAACTG GAATCTGGTC
1141 CCCTGCGAGA GTAGCTACAG CCGTGTTGTT TGCAAAACGA AAGCAAAGTC TGC
[0004]
SEQ ID NO.4的序列
(i)序列特征:(A)长度:1732个氨基酸;(B)类型:氨基酸(C)链性:单链。
(ii)分子类型:多肽人工序列
(iii)序列描述:SEQ ID NO.4
1 ADILTIRNAQ ENEFIKSQLL PFESLVQFVW LGLFKDNNDN QTRWYDGTNV QYSNWAKGRP
61 NLENPFLAGL TTDGTWILVA NKELHPIFKQ RTIVSCKLDN ESKKEYNQSA KDFQQYGNLT
121 YRVVTRKLNW SQALVECDKL GGHLASIHDV EHNAHLRLIS KMDGFPLWIG LSNYAVSGSP
181 YEWSDGTKFD YRPTISNSQD TPKTNCVYIN PAGDWKRTSC DAMIDGAICY TTNITSSYQR
241 AKLQDGPETN HCPQVDGKSK WVQHKDHCYA FDMSFYNYRL HSMEQAKALC QEMDSHLLTI
301 ETKDENDFLA NYITEHPLIT SQVWLGIDLD TLDTQGKPVS WQDGSHLNFS NWSSTAFTGK
361 KSRSQCAVMA TGNGGNWNLV PCESSYSRVV CKTKAKS
- 还没有人留言评论。精彩留言会获得点赞!