一种基于超宽带与非单点模糊逻辑的土壤含水量测量方法与流程
涉及土壤含水量测量方法,使用超宽带雷达回波信号测量土壤含水量方法。
背景技术:
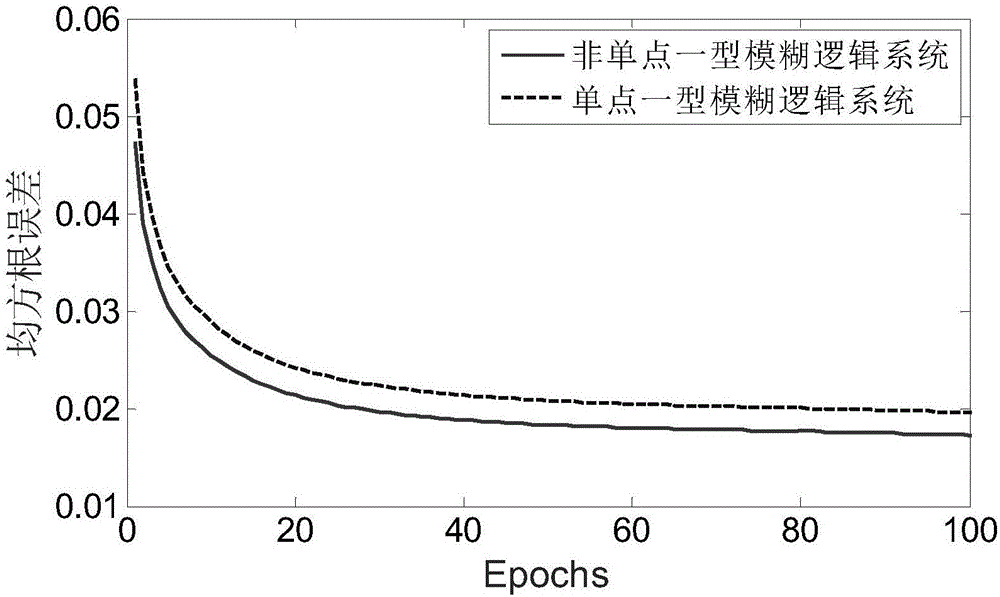
:近年来,微波遥感技术由于无破坏、实时性、穿透力强等优势,成为土壤含水量测量的研究热点。依据微波与土壤主要电介质(水)的关系,现今的主要研究方法是建立雷达回波、土壤结构的各种参数与土壤电介质之间的不同的数学模型,通过雷达回波反演出土壤电介质含量,再由经验公式推导出土壤含水量。主要使用土壤散射模型(后向散射系数与电介质含量关系)和土壤介电模板(电介质含量与含水量关系)如专利201410196776.5深层土壤湿度微波遥感探测方法与装置申请号201410340724.0一种基于超宽带雷达的土壤含水量测量方法采用一种超宽带雷达采集雷达数据,以估计土壤的超宽带多径信道;分析多径信道的参数(幅度、时延扩展),分析他们的统计特性;建立含水量与多径信道的统计特性之间的关系;根据对应关系,测量目标土壤的含水量。(同样使用超宽带信号监测)申请号201510536304.4一种针对超宽带雷达回波的土壤湿度反演方法利用了单点一型模糊逻辑系统对回波数据进行学习提取其隶属函数的特征参数;并通过对隶属函数进行模板匹配的方式反演土壤体积含水量。专利201410196776.5深层土壤湿度微波遥感探测方法与装置缺点:由于各参数间复杂的相互关系,数学模型往往存在一定的不确定性甚至某些条件下根本无法使用。同时,现有的技术(如探地雷达对土壤含水量测量)仅适用于对大面积含水量探测,受到含水量分布不均匀的影响而精度有限。由于设备笨重和功耗大等问题,很难做到对农田含水量的实时监测。另外,现有技术并未考虑成本问题,很难在常规农业生产中得到推广和实现。申请号201510536304.4一种针对超宽带雷达回波的土壤湿度反演方法由于使用单点一型模糊逻辑系统,对回波信号预测的精度没有本文中提出的非单点一型模糊逻辑系统高。另外使用提取特征参数的方法计算成本和时间成本均大于本文提出的使用模糊逻辑系统的输出信号序列作为回波模板进行比对的方法,且本方法最终土壤含水量识别正确率更高。技术实现要素:本发明的目的在于提供一种时间成本与计算成本小,且本方法最终土壤含水量识别正确率更高的土壤含水量测量方法。为了实现上述目的,本发明采用的技术方案为:一种基于超宽带信号与非单点一型模糊逻辑系统的土壤含水量测量方法,其特征在于,包括如下步骤:步骤一、采集不同土壤含水量的雷达回波信号;步骤二、截取雷达回波信号中噪声影响较小部分,将相同含水量的回波信号串联在一起组成一组回波信号序列,对多组回波信号序列求均值,作为信号预测中的真正的土壤回波信号序列;步骤三、使用非单点一型模糊逻辑系统对土壤回波信号序列进行预测,提取雷达回波模板;步骤四、将雷达回波模板与雷达收集的未知土壤含水量的回波信号进行比对,根据比对结果计算得到回波信号序列与回波模板的均方根误差(RMSE),最终将未知土壤含水量信号归类于最小均方根误差对应模板中,得到测试信号的土壤含水量。上述技术方案中,步骤1中,在无植被覆盖农田中使用超宽带雷达采集不同土壤含水量的雷达回波,每种土壤含水量土壤回波需测量800个以上,同时使用时域反射仪精确测量每种回波的真实土壤含水量,起到定标作用。上述技术方案中,步骤三具体包括以下步骤:3.2、构建非单点一型模糊逻辑系统;3.2、对回波信号进行预测,将回波信号序列数据点分为训练部分以及预测部分两类,没类信号序列的数据点分别编号,其中si表示训练部分第i个数据点,表示预测部分第k个数据点。训练部分回波信号分组输入非单点模糊逻辑系统中,信号分组方法为x(i)={si+1,si+2,...,si+p}(1)其中x(i)为非单点一型模糊逻辑系统的第i个输入向量,向量包含p个元素;si+1为训练部分回波信号序列的第i+1个数据点,非单点一型模糊逻辑系统输出为回波信号序列第i+p+1个数据点的预测值,第i+p+1个数据点即为模糊逻辑系统输出预测数值对应的真实值;将x(i)(i=0,1,2,...,i为整数)依顺序输入模糊逻辑系统中,进行预测得到预测值,预测值有序排列最终构成预测信号;将训练部分数据点分组输入非单点一型模糊逻辑系统中,比较输出值与真实数据点的误差,使用后向反馈方法训练非单点一型模糊逻辑系统参数和mFkl(i+1)=mFkl(i)-αm[fs(x(i))-y(i)][y‾l(i)-fs(x(i))][xk(i)-mFkl(i)]σFkl2(i)φl(x(i))---(2)]]>σFkl(i+1)=σFkl(i)-ασ[fs(x(i))-y(i)][y‾l(i)-fs(x(i))][xk(i)-mFkl(i)]σFkl3(i)φl(x(i))---(3)]]>y‾l(i+1)=y‾l(i)-αy‾[fs(x(i))-y(i)]φl(x(i))---(4)]]>σxk(i+1)=σxk(i)-ασx[fs(x(i))-y(i)][y‾l(i)-fs(x(i))]σxk(i)[xk(i)-mFkl(i)σxk2(i)+σFk2(i)]φl(x(i))---(5)]]>和表示第i次训练第l个规则中输入向量的第k个元素的前件隶属度函数的期望和方差,fs(x(i))表示第i次训练后非单点一型模糊逻辑系统输出的预测值,y(i)表示第i次训练后输出对应的真实值,表示第i次训练后的第l个规则的后件隶属度函数的高度值,φl(x(i))表示第i次训练后,非单点一型模糊逻辑系统的模糊基函数,表示第i次训练后输入向量第k个元素的高斯模糊函数方差,表示xi中第k个元素,αmασ分别代表各个参数调整的灵敏度,其影响每次参数调整的大小。3.3、将预测部分数据点分组输入非单点一型模糊逻辑系统,分组方法如(6)xf(i)={sfi+1,sfi+2,...,sfi+p}---(6)]]>其中xf(i)为预测部分非单点一型模糊逻辑的输入向量,共包含p个元素,为预测部分第i+p个数据点,(i=0,1,2,...,i为整数)。计算模糊逻辑系统输出的预测信号与对应回波信号序列的均方根误差(RMSE);RMSE=1N+1Σk=ii+N[y(i)-fs(x(i))]2---(7)]]>其中N+1为非单点一型模糊逻辑系统预测的数据点总数,fs(x(i))表示第i个输入向量输入后非单点一型模糊逻辑系统输出的预测值,y(i)表示第i次预测后输出对应的真实值;反复训练非单点一型模糊逻辑系统参数和在预测部分中找出最小回波信号序列的均方根误差的预测信号,作为该土壤含水量的土壤回波模板。上述技术方案中,步骤3.1中非单点一型模糊逻辑系统包括:模糊器:由前件隶属度函数函数组成,每个输入xi向量使用非单点一型模糊逻辑预测时输入向量如公式x(i)={si+1,si+2,...,si+p}。前件隶属度函数类型选择高斯隶属度函数,则第l个规则中,第k个前件隶属度函数为μFkl(xk(i))=exp(-(xk(i)-mFkl)22σFkl2)---(8)]]>其中xi表示第i次输入非单点一型模糊逻辑系统的一个输入向量,表示xi中第k个元素,和分别表示该高斯隶属度函数的期望和方差,需通过个人经验设置参数;模糊逻辑规则:均由相同结构描述为Rl:Ifx1isF1land...xkisFkland...xpisFpl]]>ThenyisGll=1,...,M(9)xk表示非单点一型模糊逻辑系统输入向量的第k个元素,表示第l个规则中输入第k个元素的语言描述,Gl表示第l个规则中输出的语言描述;模糊推理机制:由于非单点一型模糊逻辑系统中前件隶属度函数输出值存在不确定性,需要使用模糊函数进行描述,表示输入向量第p个元素的隶属度函数输出的模糊函数,模糊函数使用高斯隶属度函数,μXp(xp(i))=exp(-(xp(i)-mXp)22σXp2)---(10)]]>其中为输入向量x(i)的第p个元素,为模糊函数的期望,为模糊函数的方差推理机制表达式可化简为μBl(y)=μGl*{μF1l(xk,maxl)*...*μFpl(xk,maxl)},y∈Yxk,maxl=σxk2mFkl+σFk2mxklσxk2+σFk2---(11)]]>其中*表示模糊逻辑中t-norm运算(最小值运算或乘法运算),为第l个规则的输出模糊集,为非单点一型模糊逻辑中输入向量第k个元素在第l个规则中隶属度函数输出的最大值对应的横坐标,与分别代表输入向量的第k个元素的前件隶属度函数输出的模糊函数的期望与方差,且非单点一型模糊逻辑系统中默认与输入向量x(i)的第k个元素相等;表示第l个规则对应的后件隶属度函数,需通过经验构建;表示第l个规则中输入向量第1个元素对应的前件隶属度函数;表示第l个规则中输入向量第p个输入元素对应的前件隶属度函数;解模糊器:对不同规则的推理机制结果使用高度解模糊化方法,且所有规则对应的后件隶属度函数为高斯隶属度函数,确定的最大值对应的横坐标为计算过程中数值大小简化为1,得出最终输出y(x)=f(x)=Σl=1My‾lφl(x)=Σi=1My‾lμBl(y‾l)Σi=1MμBl(y‾l)=Σi=1My‾lΠk=1pexp(-(xk,maxl-mFkl)22σFkl2)Σi=1MΠk=1pexp(-(xk,maxl-mFkl)22σFkl2)---(12)]]>其中x表示非单点一型模糊逻辑的一个输入向量,含有p个元素;为第l个规则对应的后件隶属度函数高度值;φl(x)为非单点一型模糊逻辑系统的模糊基函数;为第l个规则的输出模糊集;为非单点一型模糊逻辑中输入向量的第k个元素在第l个规则中隶属度函数输出的最大值对应的横坐标,表达式见公式(11);由于非单点一型模糊逻辑系统默认数值与相等,(12)中可以看出,非单点一型模糊逻辑系统中影响输出y的参数分别为和综上所述,由于采用了上述技术方案,本发明的有益效果是:一、本发明具有超宽带雷达体积小、功耗低、抗干扰能力强、成本可控的特点,同时兼顾非单点一型模糊逻辑系统优势,运算时间短且精度高,可以达到实时的土壤含水量监测效果。二、对回波信号预测的精度本文中提出的非单点一型模糊逻辑系统更高。本文提出的使用模糊逻辑系统的输出信号序列作为回波模板进行比对的方法时间成本与计算成本小,且本方法最终土壤含水量识别正确率更高。附图说明图1土壤体积含水量13.7%雷达回波去耦合噪声后的回波信号图2土壤体积含水量13.7%非单点一型模糊逻辑系统输出信号与真实信号间均方根误差随训练次数变化曲线图3土壤体积含水量40.9%非单点一型模糊逻辑系统输出回波模板(0-10ns)图4土壤体积含水量40.9%非单点一型模糊逻辑系统输出回波模板(10-20ns)图5土壤体积含水量40.9%单点和非单点一型模糊逻辑系统不同性噪比下正确识别概率对比图。具体实施方式下面结合附图,对本发明作详细的说明。2.1雷达回波采集本实验选择10*10m无植被的农田内采集数据。首先,将PulsON410悬挂至距地面80cm的空中,雷达天线垂直指向地面。使用PulsON410雷达收集雷达回波,需重复采集雷达回波800次以上。将测量区域分为3*3的小区域,每块区域面积30*30cm。使用TDR300测量每块小区域内土壤体积水量,注意TDR300探针需垂直插入土壤3.5公分深。将9个测量结果求平均,作为该区域土壤体积含水量。不断向测量区域内加水灌溉,20分钟等待后,继续收集雷达回波并测量土壤体积含水量。以此方法共收集5种不同土壤体积含水量的雷达回波数据,分别为体积含水量13.7%、21.7%、28.3%、35.0%、40.9%。2.2雷达回波处理采集的雷达回波,考虑前端耦合噪声以及PulsON410渗透深度,截取图中91-490点数据作为回波信号如图1,用于生成回波模板。提取800个拥有相同土壤体积含水量的回波信号,每20个级联为一组,共分为40组数据,并求40组回波数据均值作为一个回波信号序列。2.3建立回波模型(a)确立一型模糊逻辑逻辑系统该实验使用非单点一型模糊逻辑系统,并与单点一型模糊逻辑系统结果进行对比,模糊器选择高斯隶属度函数,模糊逻辑运算t-norm使用乘法运算,解模糊器使用高度解模糊化方法。非单点一型模糊逻辑系统由模糊器、规则、模糊推理机制和解模糊器构成。模糊器选择高斯隶属度函数,第l个规则中,第k个输入的隶属度函数为μFkl(xk(i))=exp(-(xk(i)-mFkl)22σFkl2)---(1)]]>其中xi表示第i次输入非单点一型模糊逻辑系统的一个输入向量,表示xi中第k个元素,和分别表示该高斯隶属度函数的期望和方差,需通过个人经验设置参数;模糊逻辑规则均由相同结构描述为Rl:Ifx1isF1land...xkisFkland...xpisFpl]]>ThenyisGll=1,...,M(2)xk表示非单点一型模糊逻辑系统输入向量的第k个元素,表示第l个规则中输入第k个元素的语言描述,Gl表示第l个规则中输出的语言描述;对于非单点模糊逻辑系统,模糊推理机制为μBl(y)=μGl*{μF1l(xk,maxl)*...*μFpl(xk,maxl)},y∈Yxk,maxl=σxk2mFkl+σFk2mxklσxk2+σFk2---(3)]]>其中*表示模糊逻辑中t-norm运算(最小值运算或乘法运算),为第l个规则的输出模糊集,为非单点一型模糊逻辑中输入向量第k个元素在第l个规则中隶属度函数输出的最大值对应的横坐标,与分别代表输入向量的第k个元素的前件隶属度函数输出的模糊函数的期望与方差,且非单点一型模糊逻辑系统中默认与输入向量x(i)的第k个元素相等;表示第l个规则对应的后件隶属度函数,需通过经验构建;表示第l个规则中输入向量第1个元素对应的前件隶属度函数;表示第l个规则中输入向量第p个输入元素对应的前件隶属度函数。不同规则的推理机制结果由解模糊器使用高度解模糊化方法进行整合,得出最终输出。y(x)=f(x)=Σl=1My‾lφl(x)=Σi=1My‾lμBl(y‾l)Σi=1MμBl(y‾l)=Σi=1My‾lΠk=1pexp(-(xk,maxl-mFkl)22σFkl2)Σi=1MΠk=1pexp(-(xk,maxl-mFkl)22σFkl2)---(4)]]>其中x表示非单点一型模糊逻辑的一个输入向量,含有p个元素;为第l个规则对应的后件隶属度函数高度值;φl(x)为非单点一型模糊逻辑系统的模糊基函数;为第l个规则的输出模糊集;为非单点一型模糊逻辑中输入向量的第k个元素在第l个规则中隶属度函数输出的最大值对应的横坐标,表达式见公式(11);(b)生成回波模板计算2.2中土壤回波信号序列所有数据点的期望m和方差σ,设置模糊逻辑系统参数初值:为m-2σ和m+2σ,为2σ。为0至1间随机数。将2.2中土壤回波信号序列(共8000数据点)平均分为训练部分和预测部分。在训练部分,每四个信号分为1组,输入模糊逻辑系统x(i)=[xi,xi+1,xi+2,xi+3]i=1,2...,3996(5)如(5)为一组数据,每个输入设置两个隶属度函数,四个输入共组成16种规则。输出结果与xi+4进行比对。设置模糊逻辑系统参数初值:为m-2σ和m+2σ,为2σ,为0至1间随机数。将训练部分每组数据点输入模糊逻辑系统,比较输出值与真实数据点的误差,使用后向反馈方法训练模糊逻辑系统参数mFkl(i+1)=mFkl(i)-αm[fs(x(i))-y(i)][y‾l(i)-fs(x(i))][xk(i)-mFkl(i)]σFkl2(i)φl(x(i))---(6)]]>σFkl(i+1)=σFkl(i)-ασ[fs(x(i))-y(i)][y‾l(i)-fs(x(i))][xk(i)-mFkl(i)]σFkl3(i)φl(x(i))---(7)]]>y‾l(i+1)=y‾l(i)-αy‾[fs(x(i))-y(i)]φl(x(i))---(8)]]>σxk(i+1)=σxk(i)-ασx[fs(x(i))-y(i)][y‾l(i)-fs(x(i))]σxk(i)[xk(i)-mFkl(i)σxk2(i)+σFk2(i)]φl(x(i))---(9)]]>和表示第i次训练第l个规则中输入向量的第k个元素的前件隶属度函数的期望和方差,fs(x(i))表示第i次训练后非单点一型模糊逻辑系统输出的预测值,y(i)表示第i次训练后输出对应的真实值,表示第i次训练后的第l个规则的后件隶属度函数的高度值,φl(x(i))表示第i次训练后,非单点一型模糊逻辑系统的模糊基函数,表示第i次训练后输入向量第k个元素的高斯模糊函数方差,表示xi中第k个元素,αmασ分别代表各个参数调整的灵敏度,其影响每次参数调整的大小。3996组数据点均带入模糊逻辑系统完成训练成为一个epoch。每个epoch将预测部分数据输入模糊逻辑系统,对比输出数据与真实数据并计算均方根误差。RMSE=1N+1Σk=ii+N[y(i)-fs(x(i))]2---(10)]]>其中N+1为非单点一型模糊逻辑系统预测的数据点总数,fs(x(i))表示第i个输入向量输入后非单点一型模糊逻辑系统输出的预测值,y(i)表示第i次预测后输出对应的真实值。反复训练非单点一型模糊逻辑系统参数和在预测部分中找出最小回波信号序列的均方根误差的预测信号,作为该土壤含水量的土壤回波模板。调节(6)-(9)中α值(所有α取同一数值)和(9)中σx初值,寻找均方根误差最小结果,保存模糊逻辑系统输出的预测信号作为超宽带雷达回波模板。如图3与图4分别为40.9%土壤体积含水量0-10ns与10-20ns的回波模板。以上述方法分别制作5种不同土壤体积含水量的回波模板。使用PulsON410雷达以2.1中描述方法采集未知土壤含水量的雷达回波进行回波处理,得到的回波信号作为测试信号,与5种模板比较,并将未知信号划入均方根误差最小的回波模板中,以此判断回波信号对应的土壤含水量。测试信号添加高斯白噪声,调节噪声大小,得到性噪比与识别率曲线。如图5为土壤体积含水量40.9%的回波信号识别率,可得结论,在高斯白噪声影响下,依然保持较高识别率。同时对比单点一型模糊逻辑系统,非单点一型模糊逻辑系统同性噪比下识别率更高。当前第1页1 2 3
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1