一种基于统计的核磁共振一维谱信噪比提高方法与流程
本发明涉及一种核磁共振信噪比提高方法,具体涉及一种基于统计的核磁共振一维谱信噪比提高方法,适用于核磁共振谱图信噪比的提高。
背景技术:
核磁共振(Nuclear Magnetic Resonance)现象自从二十世纪中期发现以来,已经在物理、化学、生物等自然科学研究以及医学诊断、油气探矿等领域,取得了广泛的应用。然而,灵敏度较低一直是制约核磁共振进一步发展的重要因素。
为提高核磁共振信号的灵敏度,科学工作者们分别从不同的方面进行了改进。动态核极化(Ardenkjaer-Larsen JH.Increase in signal-to-noise ratio of>10,000times in liquid-state NMR.PNAS 2003,100(18))、自旋交换光抽运、超量子干涉仪(Klaus Schlenga.High-Tc SQUIDs for Low-Field NMR and MRI of Room Temperature Samples.IEEE TRANSACTIONS ON APPLIED SUPERCONDUCTIVITY,1999,9(2))等超极化方法有效的提高了核磁共振的极化度,但是由于受到微波发热、仪器和使用成本过高等局限,并没有得到广泛的应用;现代核磁共振仪器大多采用提高磁场强度、降低探头检测温度等手段提高灵敏度,但是仪器的成本也随之不断提高;数据后处理的方法由于不受样品和硬件条件限制,具有很强的普适性,受到了核磁共振工作者们越来越多的关注。
为了提高核磁共振信号的信噪比,科技工作者们先后发展了一系列的数据处理方法。根据核磁共振时域FID(Free Induction Decay)信号指数衰减的线形特点,对FID信号进行加窗操作(如指数窗),使得FID对应谱图的信噪比得以提高,但是此方法在提高信噪比的同时,也降低了谱图分辨率;小波变换(Trbovic N,Dancea F,Using wavelet de-noised spectra in NMR screening.Journal of magnetic resonance2005,173(2))可将核磁共振信号分解为不同的频率成分,然后利用噪声的高频特性,将噪声从核磁信号中分离出来,使得谱图的信噪比得到提高,但是此方法仍然会损失一部分核磁信号的细节信息。
技术实现要素:
本发明为改善以上数据处理在提高信噪比时带来的相关问题,提出一种基于统计的核磁共振一维谱信噪比提高方法。其原理为:核磁共振一维谱在采集的过程中,谱数据的噪声区域和信号峰区域的变化特点不同,噪声数据由于为随机数据,相对偏差程度大,峰数据为有效核磁信号,相对偏差程度小。具体内容为:先分别保存每次扫描采集得到核磁共振FID信号,然后将各次扫描的FID信号傅立叶变换得到谱图数据,计算各谱图相同位置点强度的变异系数(又称标准差率),并将变异系数转化为加权数组,最后将加权数组应用到谱数据上,使得噪声信号得到有效抑制,核磁共振谱图的信噪比得到提高。
为解决现有技术存在的问题,本发明采用以下技术手段:
一种基于统计的核磁共振一维谱信噪比提高方法,包括以下步骤:
步骤1、核磁共振仪器载入设定的脉冲序列和采样参数,对核磁共振FID信号进行多次扫描采集;
步骤2、将步骤1中各次扫描采集到的核磁共振FID信号分别保存;
步骤3、将步骤2中各次扫描对应的核磁共振FID信号进行傅立叶变换,得到各次扫描对应的谱数据并组成二维数组Spec(n,m),其中n表示扫描总次数,m表示各次扫描对应的谱数据的点数;
步骤4、根据步骤3中二维数组Spec(n,m)计算各次扫描的谱数据的相同数据点索引位置的数据点的变异系数CVj,将所有变异系数CVj组成变异系数数组CV,其中j表示各次扫描对应的数据点索引位置,j∈[1,m];
步骤5、将步骤3得到二维数组Spec(n,m)对应各次扫描对应的谱数据的相同数据点索引位置的数据值进行累加,得到累加后的各次扫描对应的谱数据的相同数据点索引位置的数据值AddedSpecj,各AddedSpecj组成累加谱数据组AddedSpec;
步骤6、计算步骤4中得到的变异系数数组CV的噪声水平ε,
步骤7、根据步骤4中得到的变异系数数组CV和步骤6得到的噪声水平ε通过以下公式获得权重数组w:
其中,α、β、γ均为预设的系数,α表示累加谱数据组AddedSpec的噪声系数,β表示抑制噪声的程度,CVi为步骤4得到的变异系数数组CV的第i个数值,ε为步骤6得到的噪声水平,γ表示噪声与峰进行区分的系数,wi为权重数组w的第i个数值,
步骤8、将步骤7中得到的权重数组w,与步骤5中得到的累加谱数据组AddedSpec逐点相乘,得到新的谱数据weightedSpec。
如上所述的步骤4包括以下步骤:
步骤4.1、取得各次扫描对应的谱数据的第j个点的数据值,组成一维数组Sj,
步骤4.2、计算步骤4.1中各次扫描对应的谱数据的第j个点组成的一维数组Sj的标准差,记为δj,并计算各次扫描对应的谱数据的第j个点组成的一维数组Sj的算术平均值,记为μj,
步骤4.3、根据以下公式计算各次扫描对应的谱数据的第j个点对应的变异系数CVj:
步骤4.4、遍历j,j∈[1,m],将各次扫描对应的谱数据的第j个点对应的变异系数CVj组成变异系数数组CV。
如上所述的步骤6包括以下步骤:
步骤6.1、将步骤4中得到的变异系数数组CV中每个数值取倒数,组成新的数组CV’,将数组CV’平均分为若干段子数组,各段子数组记为seg1,seg2......segp,1~p为段编号;
步骤6.2、对步骤6.1中数组CV’分出来的各段子数组seg1,seg2......segp分别计算标准差,记为std1,std2......stdp;
步骤6.3、取步骤6.2中计算得到各段子数组的标准差std1,std2......stdp的最小值,标准差std1,std2......stdp的最小值的段编号记为q,并取步骤6.1中CV’第q段segq的最大值,记为segmax;
步骤6.4、取步骤6.3中segmax的倒数,即为变异系数数组CV的噪声水平值ε。
本发明相对于现有技术具有以下有益效果:
1、在不增加仪器成本的情况下,采用数据处理的方法使得谱图的信噪比得到提高。
2、通过对各次扫描采集得到FID数据对应的谱数据进行统计学分析,形成加权数组,应用到谱数据上后,谱图信噪比得到提高的同时,有效避免了指数加窗方法的谱线增宽效应。
附图说明
图1为本发明方法的总流程图。
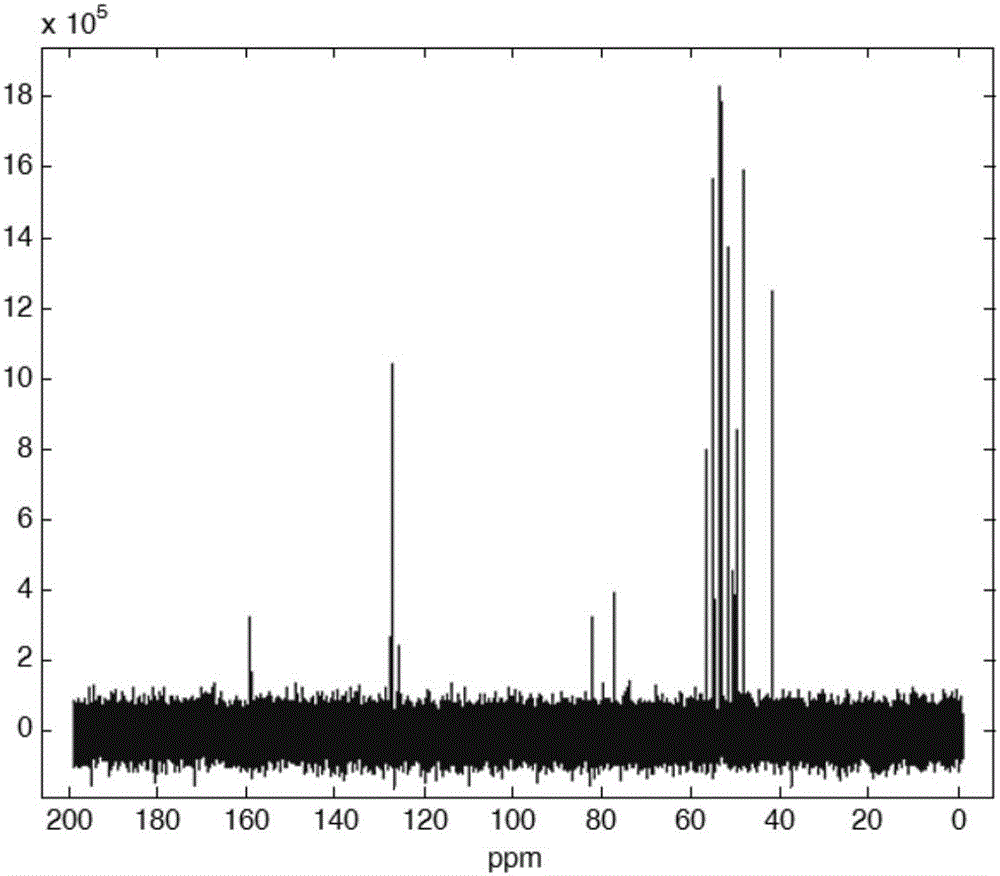
图2为单次扫描对应的谱数据。
图3为各次扫描对应的谱数据累加后的累加谱数据组AddedSpec。
图4为根据各次扫描对应的谱数据各数据点索引位置处对应的加权数组。
图5为经过加权后的谱数据weightedSpec。
具体实施方式
下面通过实施例,结合附图,对本发明的技术方案作进一步的详细描述。
实施实例1:
一种基于统计的核磁共振一维谱信噪比提高方法,总体流程图如图1所示,该方法总体包括以下步骤:
步骤1、核磁共振仪器载入设定的脉冲序列和采样参数,对核磁共振FID信号进行多次扫描采集;(在本实施例中:脉冲序列为单脉冲,采样参数主要包括观测核=13C,谱宽sw=30kHz,采样时间acqutime=1s,采样点数=30k)
步骤2、将步骤1中各次扫描采集到的核磁共振FID信号分别保存;
步骤3、将步骤2中各次扫描对应的核磁共振FID信号进行傅立叶变换,得到各次扫描对应的谱数据并组成二维数组Spec(n,m),其中n表示扫描总次数,m表示各次扫描对应的谱数据的点数。(本实施例中:n=128,m=65536,单次扫描对应的谱数据如图2所示)。
步骤4、根据步骤3中二维数组Spec(n,m)计算各次扫描的谱数据的相同数据点索引位置的数据点的变异系数CVj,将所有变异系数CVj组成变异系数数组CV,其中j表示各次扫描对应的数据点索引位置,j∈[1,m]。具体步骤如下:
步骤4.1、取得各次扫描对应的谱数据的第j个点的数据值,组成一维数组Sj,其中j表示各次扫描对应的数据点索引位置,j∈[1,m]。
步骤4.2、计算步骤4.1中各次扫描对应的谱数据的第j个点组成的一维数组Sj的标准差,记为δj,并计算各次扫描对应的谱数据的第j个点组成的一维数组Sj的算术平均值,记为μj。
步骤4.3、根据步骤4.2中得到各次扫描对应的谱数据的第j个点组成的一维数组Sj的标准差δj,各次扫描对应的谱数据的第j个点组成的一维数组Sj的算术平均值μj,计算各次扫描对应的谱数据的第j个点对应的变异系数CVj。计算方法如下:
步骤4.4、遍历j,j∈[1,m],将各次扫描对应的谱数据的第j个点对应的变异系数CVj组成变异系数数组CV。
步骤5、将步骤3得到二维数组Spec(n,m)对应各次扫描对应的谱数据的相同数据点索引位置的数据值进行累加,得到累加后的各次扫描对应的谱数据的相同数据点索引位置的数据值AddedSpecj。计算方法如下:
其中,各AddedSpecj组成累加谱数据组AddedSpec。
(本实施例中:累加谱数据组AddedSpec如图3所示。)
步骤6、计算步骤4中得到的变异系数数组CV的噪声水平ε。具体步骤如下:
步骤6.1、将步骤4中得到的变异系数数组CV中每个数值取倒数,组成新的数组CV’,将数组CV’平均分为若干段子数组,各段子数组记为seg1,seg2......segp,1~p为段编号;
(本实施例中:p=64。)
步骤6.2、对步骤6.1中数组CV’分出来的各段子数组seg1,seg2......segp分别计算标准差,记为std1,std2......stdp;
步骤6.3、取步骤6.2中计算得到各段子数组的标准差std1,std2......stdp的最小值,标准差std1,std2......stdp的最小值的段编号记为q,并取步骤6.1中CV’第q段子数组segq数据值的最大值,记为segmax;
步骤6.4、取步骤6.3中segmax的倒数,即为变异系数数组CV的噪声水平值ε;计算步骤如下:
ε=1/segmax
(本实施例中:ε=2*10-6。)
步骤7、根据步骤4中得到的变异系数数组CV和步骤6得到的噪声水平ε形成权重数组w。
具体计算方法如下,:
其中,α、β、γ均为预设的系数,α表示累加谱数据组AddedSpec的噪声系数(0<α<0.2),β表示抑制噪声的程度(1<β<10),CVi为步骤4得到的变异系数数组CV的第i个数值,ε为步骤6得到的噪声水平,γ表示噪声与峰进行区分的系数(1<γ<5),wi为权重数组w的第i个数值。
(本实施例中:α=0.1,β=2,ε=2*10-6,γ=2,计算得到的加权数组w如图4所示。)
步骤8、将步骤7中得到的权重数组w,与步骤5中得到的累加谱数据组AddedSpec逐点相乘,得到新的谱数据weightedSpec,新的谱数据weightedSpec即为经过噪声抑制后的谱数据。具体计算方法如下:
weightedSpecj=AddedSpecj*wj
其中,weightedSpecj表示谱数据weightedSpec第j个点的数值。
(本实施例中:加权后的谱数据weightedSpec如图5所示。)
本方法与传统的一维13C谱效果对比:
传统的一维13C谱指采用多次采集、直接累加的方法。如图3和图5所示,相同采样谱宽、采样时间、采样点数、累加次数等实验条件下,传统的一维13C谱的信噪比为365.5(图3),而采用本方法得到的信噪比为2721.3(图5),采用本方法得到的谱图的信噪比提高为传统方法的7.45倍。
- 还没有人留言评论。精彩留言会获得点赞!