一种新的GNSS时间序列中异常值精确识别方法与流程
本发明涉及测绘变形监测的预警领域,具体是一种新的gnss时间序列中异常值精确识别方法。
背景技术:
构筑物和建筑物作为人类生活和经济发展的主要场所,在世界中占据非常重要的地位。随着全球经济的不断发展,高层建筑,高速铁路,地铁等重大土木水利工程日益增多,且结构越来越复杂。这些构筑物和建筑物在支撑着我们生活,同时也伴随着地表塌陷、公路和铁路变形、建筑物损坏等灾害发生,对人民生命财产安全构成了巨大威胁,有必要研究如何准确识别变形数据和异常值,用于指导灾害控制和防治。目前常用于监测变形的方法为控制图理论,如何准确的进行识别是成为提高精度的关键。
现有的控制图理论方法大体分为传统的休哈特控制图和cusum控制图算法。一类是传统的算法,利用的是3倍标准差的原理,虽然大偏移变形数据可以识别,但存在对小偏移变形的数据却不能适用、大偏移数据识别精度较低等问题;一类是基于累积和的算法,虽然可以解决传统算法在小偏移变形方面存在的问题,但是对于大偏移变形数据的误报率较高。因此,建立一种能够有效地识别变形数据且结果稳定的方法具有极其重要的意义。
技术实现要素:
针对现有技术存在的问题,本发明所要解决的是提供一种新的gnss时间序列中异常值精确识别方法。本发明首次将cu-bfast算法应用于对gnss时间序列的异常值识别中,能够全面的分析数据和识别异常值,具有较好地异常值检验能力和误报率较低的优点。
本发明实现发明目的采用如下技术方案:
本发明提供一种新的gnss时间序列中异常值精确识别方法,步骤如下:
步骤1,采集对构筑物或建筑物进行形变监测的gnss时间序列,统计其均值和标准差;
步骤2,将步骤1中的数据进行正态性检验,对不服从正态性分布的数据通过q统计量的方法转换;
步骤3,将步骤1或步骤2的数据通过cusum的统计量计算公式,构建cusum偏移统计量;
步骤4,将步骤3中的cusum统计量作为检验数据,使用bfast算法,得出趋势项中的断点列表。
作为优选,根据权利要求1所述的一种新的gnss时间序列中异常值精确识别方法,其特征在于步骤1中,采集对构筑物或建筑物进行形变监测的gnss时间序列,统计其均值μ和标准差σ。
作为优选,根据权利要求1所述的一种新的gnss时间序列中异常值精确识别方法,其特征在于步骤2中,对于判别监测数据的正态性所构建的公式如下(1)和(2):
a=(mtv-1v-1m)-1/2mtv-1(2)
式(1)和(2)中:
式(3)中,k(x)为核函数,l为一个平滑参数,kl(x)为缩放核函数。再通过标准正态分布的逆函数将通过核密度估计得到的概率密度函数fi转换为qi,转换后的qi近似的服从正态分布。
作为优选,根据权利要求1所述的一种新的gnss时间序列中异常值精确识别方法,其特征在于步骤3中,求解的cusum统计量的参数有6个,gnss监测序列的均值μ,标准差σ,偏移值δ,参数k,cusum上偏移量初始值
作为优选,根据权利要求1所述的一种新的gnss时间序列中异常值精确识别方法,其特征在于步骤3中,根据服从正态分布的gnss时间序列或转换后的数据,构建cusum偏移统计量,其具体思路为:
步骤3.1:给定偏移值δ,设置参数k,计算均值μ,标准差σ,cusum上、下偏移统计量初始值
步骤3.2:计算累计偏移统计量,上、下偏移统计量分别如公式(4)和(5)所示:
作为优选,根据权利要求1所述的一种新的gnss时间序列中异常值精确识别方法,其特征在于步骤4中,根据步骤3中构建的cusum偏移统计量,使用bfast算法得到断点列表,具体步骤如下:
步骤4.1:将cusum偏移统计量作为检测序列,转换为时间类型序列,给定频率设置;
步骤4.2:设定检验步长h,季节性参数season,最大迭代次数max.iter,使用方法类型是普通最小二乘的移动平均求和(ols-mosum)。
与现有技术相比,本发明的有益效果是:本发明首次将cu-bfast算法应用于对gnss时间序列的异常值识别中,能够全面的分析数据和识别异常值,具有较好地异常值检验能力和误报率较低的优点。
附图说明
图1是本发明一种新的gnss时间序列中异常值精确识别方法的一较佳实施例的流程图;
图2是本发明的案例中的原始数据及加入不同变形的数据图;
图3是本发明的转换后的数据图;
图4是本发明的不同偏移变形的bfast检验图;
图5是本发明的不同偏移变形的趋势项断点列表图。
具体实施方式
下面结合附图对本发明的较佳实施例进行详细阐述,以使本发明的优点和特征能更易于被本领域技术人员理解,从而对本发明的保护范围做出更为清楚明确的界定。
请参阅图1,本发明实施例包括:
一种新的gnss时间序列中异常值精确识别方法,包括以下步骤:
步骤1,采集对构筑物或建筑物进行形变监测的gnss时间序列,统计其均值和标准差;
步骤2,将步骤1中的数据进行正态性检验,对不服从正态性分布的数据通过q统计量的方法转换;
步骤3,将步骤1或步骤2的数据通过cusum的统计量计算公式,构建cusum偏移统计量;
步骤4,将步骤3中的cusum统计量作为检验数据,使用bfast算法,得出趋势项中的断点列表。
以某段建筑物的gnss监测时间序列为例,具体实施步骤如下:
第一步,本文取实测数据加入变形数据进行验证,取1000个数据。原始监测序列如图2(a)所示,为了充分验证该算法对异常值识别的能力,在原始监测序列的500~600位置处加入1~3倍的标准差作为变形信息,详见图2(b)~(d)。均值和标准差分别为:0.00514和0.00155。
第二步,将第一步中的数据进行正态性检验,对不服从正态性分布的数据通过q统计量的方法转换。对于判别监测数据的正态性所构建的公式如下(6)和(7):
a=(mtv-1v-1m)-1/2mtv-1(7)
式(6)和(7)中:
式(8)中,k(x)为核函数,l为一个平滑参数,kl(x)为缩放核函数。再通过标准正态分布的逆函数将通过核密度估计得到的概率密度函数fi转换为qi,转换后的qi近似的服从正态分布。
转换后的数据如图3所示。
第三步,将第二步中的数据通过cusum的统计量计算公式,构建cusum偏移统计量;给定偏移值δ=1,设置参数k=0.5,根据第一步中计算的均值和标准差,cusum上、下偏移统计量初始值
累计偏移统计量,上、下偏移统计量的计算公式见(9)和(10):
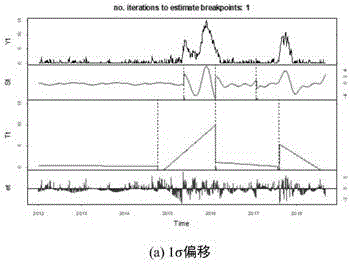
所得的统计量详见图4中yt。
第四步,根据第三步中构建的cusum偏移统计量,使用bfast算法得到断点列表,具体步骤如下:
4.1,将cusum偏移统计量作为检测序列,转换为时间类型序列,频率设置为150;
4.2,设定检验步长h=0.06,季节性参数season为harmonic,最大迭代次数max.iter=2,使用方法类型是普通最小二乘的移动平均求和(ols-mosum)。
详细结果见图4,趋势项断点列表见图5。
在图5(a)~(c)中,本文所提出的一种新的gnss时间序列中异常值精确识别方法,对异常值的识别效果较好。图5中,对时间序列中1倍标准差变形的检验结果分别为415、617、839;对于2倍标准差变形的识别结果为495、604、715;对于3倍标准差变形的识别结果为495、609、763。本算法能够较为准确的对异常值进行识别,随着变形的增大,对断点起始位置的检测越来越靠近变形数据的起始位置。
由本发明所要解决的是提供一种新的gnss时间序列中异常值精确识别方法。本发明首次将cu-bfast算法应用于对gnss时间序列的异常值识别中,能够全面的分析数据和识别异常值,具有较好地异常值检验能力和误报率较低的优点。
以上仅为本发明的较佳实施例而已,并非用于限定本发明的保护范围,因此,对于本技术领域的普通技术人员来说,凡在本发明的精神和原则之内所作的任何修改、等同替换、润饰、改进等,均应包含在本发明的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!