三维空间内多机器人编队的路径规划算法的制作方法
本发明属于智能算法优化领域,涉及一种基于市场拍卖法的多机器人系统编队任务分配算法和基于切线圆法的多机器人编队路径规划算法。
背景技术:
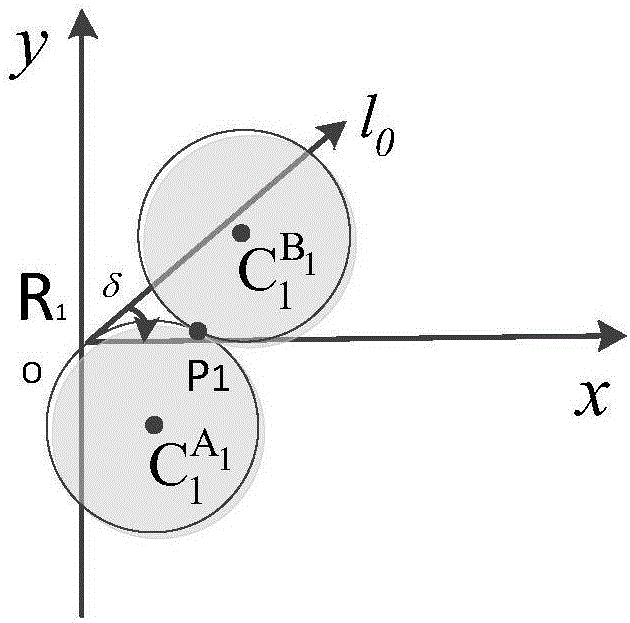
:编队控制方法是指多机器人系统在到达目标位置的过程中既保持某种队形又可以适应环境约束的控制方法。由于多机器人编队的作业任务和环境各不相同,科研人员提出了多种机器人编队的控制方法,其中最为常用的方法有基于领航者-跟随者的方法、虚拟结构法、基于行为的方法、基于图论的方法和强化学习的方法。领航者-跟随者方法的基本思想是在多机器人组成的编队系统中,可以存在一个或者多个领航机器人(Leader),其他非领航者机器人即为跟随机器人(Follower),跟随机器人以相对其领航机器人的位置(相对距离L、相对角度φ)作为输入控制量,使得跟随机器人与领航机器人的相对位置无限逼近目标值。领航跟随方法的控制结构比较简单,但是由于领航机器人和跟随机器人之间没有位置反馈,并且是领航者机器人单点控制,导致容易出现机器人掉队等情况,系统的鲁棒性较差。虚拟结构法的基本思想是将多机器人组成的系统看成一个假想的刚体结构,各个机器人在参考坐标系下的坐标不变,即机器人之间的相对位置不变。基于行为的方法的基本思想是将多机器人编队的各个环节看成由单个机器人的多个基本行为构成,只需要研究各个基本行为的控制方法即可通过基本行为的组合控制多机器人形成编队。基本行为一般包括目标跟踪、避免障碍、避免碰撞、编队生成和编队保持等。基于行为的方法由各个机器人相互感知控制,系统比较容易实现分布式控制,具有很好的鲁棒性。但是由于无法结合准确的数学模型分析,导致不能十分有效的保证系统的可靠性。基于图论的方法的基本思想是结合图论的知识,将各个机器人看成节点,然后节点之间按照一定的规则相互连通,控制指令在节点之间按照一定的方向“传递”,使得整个多机器人系统形成一种网状的拓扑结构。强化学习的方法是一种比较新兴的研究方法,基本思想是结合机器学习的理论,对机器人在学习阶段的行为进行评估,如果机器人的行为符合预期设定则奖励为正,那么机器人将在以后的动作行为中更加偏向使用该行为,反之这种行为的出现概率将会越来越低,甚至消失。通过有效的设定行为奖惩规则,可以使得各个机器人能够按照设定进行长时间的“训练”,最终可以实现编队效果。经过对现有多机器人编队控制方法的对比,可以看出国内外学者对多机器人的编队控制方法研究多应用于解决二维平面内的编队控制问题,或者只考虑编队形状而不考虑形成编队时各个机器人的姿态问题。目前,三维空间内的编队控制方法主要是简化为二维平面内的编队问题来处理,而且三维空间内的编队控制算法复杂度太高,很难实现对多机器人系统的准确编队控制。因此,现有的编队控制方法不能很好的适用于解决多机器人在三维空间内的编队控制问题。针对上述问题,提出一种基于市场拍卖法和切线圆法的新型路径规划算法,解决多机器人三维空间内的编队路径规划问题。技术实现要素:为解决上述问题,本专利提供一种基于市场拍卖法的多机器人系统编队的任务分配算法和基于切线圆法的多机器人编队路径规划算法。基于市场拍卖法的多机器人系统编队的任务分配算法包括,由目标状态矩阵ST可以通过市场拍卖法的方式将各坐标分配给各个机器人,并形成路径,使各个机器人跟踪参考路径向形成编队形状的各个目标位置运动。传统的市场拍卖法仅仅根据目标点与当前各个机器人的距离远近进行坐标分配,当多机器人系统中的机器人个数比较少时,传统的坐标分配方法可能产生比较小的误差,但是当机器人个数明显增加时,传统的方法很可能导致多机器人系统形成编队所需要的时间更长、耗能更多。本文提出一种改进的市场拍卖算法进行多机器人编队系统中各个坐标的分配计算,综合考虑所有机器人向形成编队的目标位置运动路程之和Sumdistance,机器人从接收到形成编队指令到形成编队所需要的时间Tcost(每个机器人的姿态调整时间Ta和机器人运动到指定位置时间Tb之和的最大值),分别使用Ka,Kb设置Sumdistance和Tcost的权值参数,在不同环境下可选择不同的权值参数。为了保证编队任务的连续性,需要在形成编队形状时各个机器人有相同的速度Vg和姿态角θg,因此需要计算各个机器人运动到指定坐标点所需要的时间Ti的最小值min{Ti},设机器人角速度为ω,Li为机器人Ri到形成编队形状需要运动的路程,则因此得Tcost=max{Ti},则每个机器人运动到指定目标点的平均速度:故需要根据目标速度Vg和运动时间Tcost,结合机器人的动力学公式,对机器人的速度进行运动学控制,使各个机器人都能在规定时间内以准确的速度和姿态到达指定位置。设编队形成过程效率指标为η,则:k表示第k种坐标分配方案,0≤ηk≤2。通过设置合适的权值参数Ka、Kb可以选择不同的编队分配方案作为任务要求下的最优解。基于切线圆法的多机器人编队路径规划算法应用于解决三维空间内的多机器人编队的路径规划和位姿控制,三维空间内的切线圆法原理图如图1所示。步骤1:通过程序算法计算机器人Ri到达指定目标位置所需要的时间ti;步骤2:用表示机器人Ri的目标点,在图1中绘出的位置,并结合目标位置的姿态角方向向量ri和机器人Ri的初始位置坐标可以构建一个平面H;在平面H内,以为切点可以做目标点运动轨迹直线的两个外切圆外切圆半径为机器人Ri的预设转弯半径ri;步骤3:在平面H内,由机器人初始位置向作切线,易知有四种解法路径直线l1、l2、l3、l4,满足机器人运动学要求的是直线l2、l3,计算易知直线l2路径最优;步骤4:由机器人初始位置Ri的初始姿态角,及直线l2可得一个平面,记为平面P,则需要在平面P内找到一条路径使得机器人Ri可以沿此路径进入到l2;步骤5:在P平面内,过点,在直线l2侧做外切圆外切圆半径为ri;在直线l2上下两侧分别作出圆与圆直线l2相切,如图1所示,仅有圆满足要求,故可构建路径如图1虚线所示。以为例计算路径曲线。过x轴、点和ri可做平面则由空间平面方程求解。平面法向量:则平面的方程为:设ri与nx的夹角为δ,则:在XOY平面作出以δ为方向角的直线l0,如图2所示,并作相切圆则圆的方程可写成:r为转弯半径。则圆的圆心(a,b)由下式定义:则圆的方程可写成:则切点P1坐标定义如下:设平面与平面XOY的夹角为γ,则:则由坐标旋转公式,绕x轴旋转后新坐标满足:故可得在平面中圆的方程为:圆的方程为:附图说明图1为三维空间内的切线圆法原理图图2为平面XOY上几何关系图图3为编队任务分配仿真图图4为空间四面体编队模型图图5为四面体编队仿真图具体实施方式定义机器人的坐标和姿态用矩阵表示,x,y,z表示机器人在笛卡尔直角坐标系下的位置,θ,表示机器人在笛卡尔直角坐标系下的姿态方向。以四个机器人形成一个四面体形的多机器人编队形状为例。初始坐标为:目标编队形状各顶点坐标为:四机器人编队系统中的所有任务分配方法如表1所示。表1四机器人编队系统中的所有任务分配方法kSumdistance(m)Tcost(s)η144.976220.59210.8845246.067621.43160.9133352.519021.54330.9783451.661424.67551.0382550.677224.67551.0286652.626221.54330.9793746.067620.59210.8950847.159021.43160.9239951.661420.59210.94931053.185124.79521.05561152.200924.79521.04601251.768621.43160.96861350.677220.59210.93971452.200924.79521.04601552.626221.54330.97931651.768624.67551.03921756.378224.67551.08391858.759424.79521.10961950.226824.79521.02692049.794621.43160.94952157.769624.79521.10002255.388424.67551.07432349.794624.67551.02012451.743521.54330.9708由表中数据可得,当I=0.8845时,系统有最优解,此时花费时间20.5921s,总运动路程44.9762m。通过MATLAB仿真可得任务分配如图3所示,实心圆点为各个机器人的初始位置,空心圆点为目标点位置。此种解法为给定初始状态和目标位置的最优解,证明了多机器人编队过程的任务分配算法的有效性。以四面体编队为例,最终形成的四面体编队形状如图4中所示四面体G0G1G2G3,并沿x轴正向向目标点Gt运动。目标状态矩阵:编队形成过程的问题即转化为使用算法使得ST=S,为了保证目标矩阵的单一性,便于计算,做如下规定依次由的大小确定目标矩阵ST的行向量,列坐标小的行向量在前。运用基于改进市场拍卖法的多机器人编队坐标分配方法,将形成编队形状的G1、G2、G3坐标分配给R1、R2、R3机器人。运用基于切线圆法的三维平面内路径规划算法和位姿控制方法,计算各个机器人的编队路径。最终得到仿真图如图5所示。从图5可以看出,各个机器人在初始各自不同的姿态方向运动情况下,可以使用切线圆法规划出运动路线和调整运动姿态,并最终和其他机器人以相同的运动姿态形成四面体编队形状,验证了多机器人编队过程的路径规划和位姿控制算法的有效性。当前第1页1 2 3
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1