一种基于PSO‑PD神经网络的四足机器人运动轨迹控制方法与流程
本发明涉及一种机器人运动轨迹控制方法,具体涉及一种基于PSO-PD神经网络的四足机器人运动轨迹控制方法。
背景技术:
随着科学技术的飞速发展,机器人技术也越来越多地应用于复杂环境之中。其中足式机器人相对于轮式或履带式机器人在非结构环境中运动具有一定的优越性。而四足机器人相比于其他多足步行机器人,具有结构简单,运动稳定等优势,因此具有较高的研究意义与应用价值。在复杂环境工作时,机器人沿着预先设定好的运动轨迹运行。能够以最快的速度,最低的能耗经过各个工作点,与此同时还能避开各种障碍等影响运行稳定的因素。因此研究四足机器人的运动轨迹控制对四足机器人的应用于研究具有重大的意义。
四足机器人是一个复杂的非线性系统,且躯干朝向与重心位置存在耦合关系,因此四足机器人运动轨迹控制是一个十分复杂非线性解耦控制问题。现有方法只能对四足机器人实现直线轨迹控制,或圆形轨迹控制;或在此基础上通过步态切换实现简单非线性轨迹的控制。但始终无法对机器人实现连续精准的非线性运动轨迹控制。
一般现有PD神经网络为四层前向神经网络,第一层为输入层,接收控制信号与反馈信号;第二层为比例微分计算层,通过作用函数对误差进行比例计算与微分计算;第三层为控制率输出层,通过对比例微分运算的结果进行线性运算得到控制率;第四层为控制对象。
技术实现要素:
针对现有技术的不足,本发明提供了一种基于PSO-PD神经网络的四足机器人运动轨迹控制方法。
本发明中设计了一种专门面向四足机器人运动轨迹控制的PD神经网络,但由于该PD神经网络经网络中存在状态反馈与不连续可导的作用函数无法通过BP学习算法实现神经网络的自适应学习,于是本发明使用改进PSO算法作为PD神经网络的学习算法。改进PSO算法收敛快、精度高且不宜陷入局部最优,能够精准地实现PD神经网络的自适应学习。总之,本发明能够快速精准地实现四足机器人运动轨迹控制,有望在机器人运动控制中得到广泛应用。
本发明的技术方案为:
一种基于PSO-PD神经网络的四足机器人运动轨迹控制方法,包括:
(1)根据四足机器人运动轨迹与预设步长,求取四足机器人重心在该运动轨迹上的目标落点,即四足机器人重心在该运动轨迹上的坐标;是相对于实际结果而言的。
(2)将步骤(1)求取的四足机器人重心在该运动轨迹上的目标落点、实时反馈的躯干重心位置(yx,yy)输入PD神经网络模型的输入层;线性变换后进入PD神经网络模型的第一隐含层,在第一隐含层进行比例运算与微分运算;再次线性变换后进入PD神经网络模型的第二隐含层,在第二隐含层得到x方向与y方向上的指导位移,所处坐标系为四足机器人运动所在的水平平面的坐标系,原点为四足机器人初始重心位置;进入PD神经网络模型的第三隐含层,在第三隐含层求得指导位移距离dr、指导转向角度dθ,指导位移距离dr是指四足机器人从当前这一步到下一步迈出的距离,指导转向角度是指四足机器人从当前这一步到下一步的躯干转向角度;进入PD神经网络模型的第五层,在第五层实现对四足机器人的足端轨迹控制、转向控制;进入PD神经网络模型的第六层,当四足机器人足端发生滑动时,调整四足机器人姿态,保证四足机器人运行稳定;但该过程会使机器人重心发生变化,可视为随机时刻发生的大小随机的扰动,此外还有诸多其他原因造成的扰动,在第六层加入扰动进行模拟,并将加入扰动后的步长作为实际步长反馈给第五层;进入PD神经网络模型的第七层,求取四足机器人的躯干朝向yθ、躯干重心位置(yx,yy),躯干朝向yθ是指当前迈步结束后,躯干的实际朝向,即躯干与X轴的夹角;躯干重心位置(yx,yy)是指四足机器人重心在所述坐标系中的坐标;四足机器人的躯干朝向yθ反馈给PD神经网络模型的第五层,躯干重心位置(yx,yy)反馈给PD神经网络模型的输入层。
根据本发明优选的,采用改进的粒子群优化算法调整PD神经网络模型中多层神经元之间的连接权值,实现面向机器人运动轨迹控制的PD神经网络的自适应学习,包括:
a、将多层神经元之间的连接权值的选取问题转化为最优化问题,最优化问题的目标函数即输出向量与导师信号向量的L2范数,如式(Ⅰ)所示,导师信号即目标落点坐标,输出向量即四足机器人实际重心位置;
式(Ⅰ)中,Error为最优化问题的目标函数,xd(k)、yd(k)分别为四足机器人第k步的重心目标落点的横坐标、纵坐标,yx(k)、yy(k)为四足机器人第k步的重心目标落点的实际横坐标、纵坐标;
b、利用先前经验确定每个连接权值的取值范围,即确定寻优范围;
c、在寻优范围内随机初始化一群粒子,即粒子群,包括初始化粒子的初始位置与初始速度,用位置、速度和适应度这三个指标表示粒子特征,位置表示PD神经网络模型中所有的连接权值取值,速度表示每个粒子演化的方向,适应度值由适应度函数求得,即每个粒子对应的目标函数;而每个粒子都代表上述最优化问题的一个潜在最优解;
粒子的速度依据粒子的当前位置、当前速度、粒子的历史最佳位置Pbest与粒子群中最优粒子的位置Gbest更新,粒子的速度的更新公式如式(Ⅱ)所示:
式(Ⅱ)中,id为粒子群中粒子的编号,为第i代粒子的速度,为第i代粒子在第i代之前的历史最佳位置,为第i代粒子群中最优粒子的位置;ω(i)为第i代粒子的惯性权重,其大小决定速度在多大程度上继承上一代粒子的运动速度;%1、%2为加速度因子,取值为非负常数;r1、r2为0到1之间的随机数;是第i代粒子的位置;初始化时ω的取值ωstart为0.9,迭代结束时ω的取值ω34d为0.01,在迭代过程中惯性权重ω加速衰减,初期优先寻优速度,后期着重寻优精度,惯性权重ω的更新公式如式(Ⅲ)所示:
式(Ⅲ)中,maxg;n为最大迭代次数;
本发明加入了非线性递减惯性权重ω(i),惯性权重ω(i)决定速度在多大程度上继承上一代的运动速度,在迭代过程中ω(i)越大寻优速度越快,但精度越低;反之则精度越高,速度越低。为达到速度与精度的平衡,惯性权重ω(i)在迭代初期较大,随着迭代进行惯性权重逐步减小。
得到更新后的粒子的速度后,更新该粒子的位置,粒子的位置的更新公式如式(Ⅳ)所示:
若式(Ⅳ)求取的对应的目标函数小于对应的适应度函数,则反之,同时,更新种群中最优粒子的位置,得到
如此,进行多次迭代即得到近似最优解,即使PD神经网络模型控制误差最小的近似最优权值。
加入遗传算法中的自适应变异的思想,即粒子位置更新之后,有一定概率发生在取值范围内的变异。自适应变异拓展了在迭代中不断缩小的粒子群搜索空间,使其能够在更大的空间展开搜索,使其跳出局部最优,增加得到全局最优的可能性。每个粒子在位置更新后,会生成一个随机数,如果大于0.9则在寻优范围内重新随机初始化该粒子。如果小于等于0.9则什么都不做。
改进的粒子群优化算法在不易陷入局部最优的同时兼顾收敛速度与寻优精度。用其替代传统PSO粒子群算法实现PSO-PD神经网络的自适应学习。改进的粒子群优化算法,学习时间更短,控制精度更高,因此可以更好的满足四足机器人运动轨迹控制的控制需求。
根据本发明优选的,所述步骤(1),根据四足机器人运动轨迹,求取四足机器人在该运动轨迹上的目标落点,设定四足机器人的运动轨迹为正弦曲线,沿正弦曲线运动时,机器人的转弯半径,转弯角度都在不断发生变化,因此可用来证明该控制策略是否广泛适用于绝大多数非线性运动轨迹。设置预设步长L的取值范围为0.38-0.42m,当没有外界扰动时,机器人的重心不会发生变化;求取四足机器人在该运动轨迹上的目标落点的公式如式(Ⅴ)所示:
式(Ⅴ)中,x_1、y_1分别为前一步四足机器人重心的横坐标与纵坐标,x、y分别为当前一步四足机器人重心的横坐标与纵坐标;
x_1、y_1的初始值均为0,求取x、y后,再赋值给x_1、y_1,反复迭代二百次后,得到四足机器人在该运动轨迹上的目标落点。
进一步优选的,L的取值为0.4m。
根据本发明优选的,在第三隐含层求得指导位移距离dr、指导躯干朝向dθ,包括:
通过式(Ⅵ)求取指导位移距离dr,式(Ⅵ)如下所示:
式(Ⅵ)中,dΔx,dΔy为第二隐含层所求得的指导x增量与指导y增量,即x方向与y方向上的指导位移;
通过式(Ⅶ)求取指导躯干朝向dθ,式(Ⅶ)如下所示:
根据本发明优选的,实现对四足机器人的足端轨迹控制,四足机器人包括躯干以及与所述躯干连接的四条腿,在四足机器人的一个迈步周期中,在同一对角线上的两条腿以相同运动方式摆动,支撑躯干并推动躯干前进的两条腿称为支撑相,而按照事先设定轨迹进行摆动的另一对角线上的两条腿称为摆动相,包括步骤如下:
A、通过分析四足机器人腿部结构,构建四足机器人腿部运动数学模型,包括四足机器人足端位置模型:
每条腿包括大腿、小腿;四足机器人的一个迈步周期包括一个支撑相、一个摆动相,躯干坐标系中,x轴表示足端在水平方向上的位移,y轴代表足端高度,原点o为腿髋关节在地面上的投影点,躯干坐标系下足端位置模型如式(Ⅷ)所示:
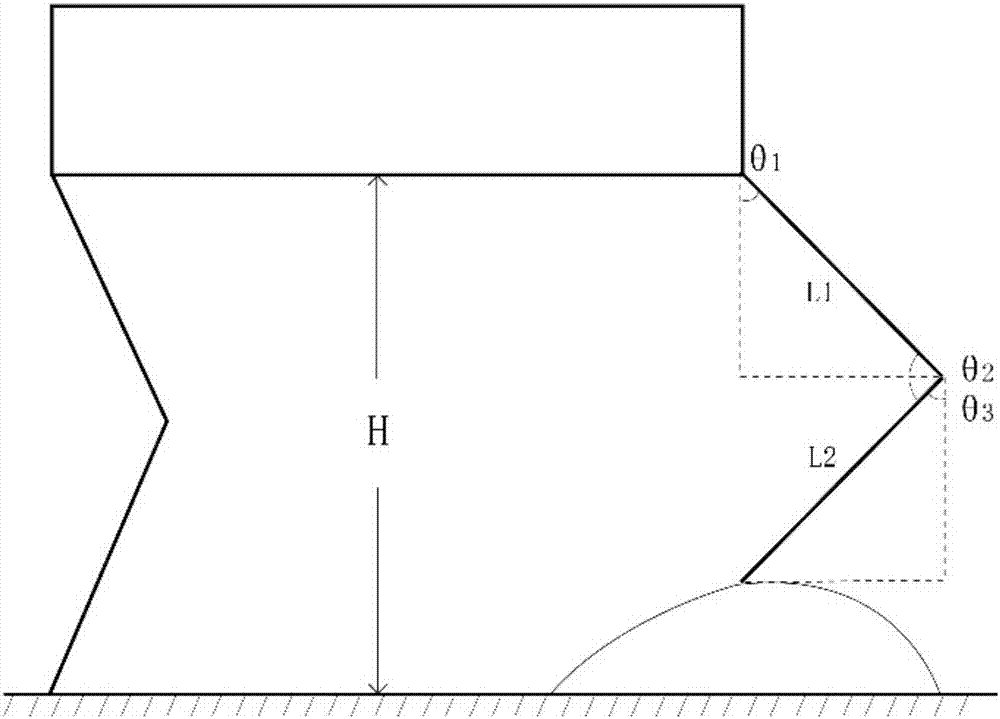
式(Ⅷ)中,px(θ1,θ2)为足端水平位移与θ1、θ2的函数,pz(θ1,θ2)为足端高度与θ1、θ2的函数,L1为机器人大腿的长度,L2为机器人小腿的长度,θ1为机器人髋关节纵向开合角度,取值范围为0°-180°;θ2为膝关节开合角度,取值范围为0°-180°;H为机器人躯干底端到地面的距离;
B、采用一种新型正弦对角步态,求取支撑相足端在躯干坐标系下的运动轨迹、摆动相足端在躯干坐标系下的运动轨迹,所述新型正弦对角步态是指:四足机器人的四条腿以对角分为两组,前左腿和右后腿为一组,前右腿和后左腿为一组,两组交替作为支撑相与摆动相;支撑相推动躯干前行,摆动相向前迈步跨越障碍,这些过程均可通过足端轨迹进行解释。尤其是摆动相足端轨迹,直接决定了摆动相以何种方式进行迈步。因此,足端轨迹的选择对机器人运动控制有着十分重要的意义。
支撑相足端在躯干坐标系下的运动轨迹如式(Ⅸ)所示:
式(Ⅸ)中,p1x(t)为支撑相足端水平位移关于时间t的函数,p1z(t)支撑相足端高度关于时间t的函数,S为当前迈步周期步长,S_1为上一迈步周期实际步长,t为迈步周期内的时刻,T为迈步周期;
支撑相支撑躯干并推动其前行,因此,为使机器人平稳运行,支撑相足端在躯干坐标系下运动应尽量保持匀速,且在z轴方向上保持不变。在x0y平面上,支撑相足端进行匀速运动运动距离为d=0.5*(S+S_1)。
摆动相足端在躯干坐标系下的运动轨迹如式(Ⅹ)所示:
式(Ⅹ)中,p2x(t)为摆动相足端水平位移关于时间t的函数,p2z(t)摆动相足端高度关于时间t的函数,h为步高,为摆动相上升过程中达到的最高点;
C、控制率的求解
设定步长的取值范围是0.38m~0.42m,精度为1mm,则摆动相足端在躯干坐标系下的运动轨迹有41*41=1681种可能性;
将1681种可能性对应的S_1、S带入公式(Ⅹ),求得摆动相足端不同时刻的位置p2x(t)、p2z(t);
将求得摆动相足端不同时刻的位置p2x(t)、p2z(t)代入公式(Ⅷ)中的px(θ1,θ2)、pz(θ1,θ2),得到一非线性方程组,通过MATLAB求解该非线性方程组,并依据关节约束条件筛选得到符合关节约束条件的髋关节纵向开合角度与膝关节开合角度,作为控制摆动相运动的控制率;
将1681种可能性对应的S_1、S带入公式(Ⅹ),求得支撑相足端不同时刻的位置p1x(t)、p1z(t);
将求得的支撑相足端不同时刻的位置p1x(t)、p1z(t)代入公式(Ⅷ)中的px(θ1,θ2)、pz(θ1,θ2),得到一非线性方程组,通过MATLAB求解该非线性方程组,并依据关节约束条件筛选得到符合关节约束条件的髋关节纵向开合角度与膝关节开合角度,作为控制支撑相运动的控制率;
D、根据求取的摆动相运动的控制率、支撑相运动的控制率,建立数据库
数据库采用二维地址指针,第一维为S_1,第二维为S,每个地址存有2个2*200的控制矩阵,分别为支撑相关节控制率与摆动相关节控制率;
E、通过快速查表法,实现对四足机器人的足端轨迹控制
a、求取S与S_1;
b、根据S_1与S,进行快速查表,从数据库中得到存有支撑相关节控制率的支撑相控制矩阵与存有摆动相关节控制率的摆动相控制矩阵;
c、将支撑相控制矩阵传递给支撑相,将摆动相控制矩阵传递给摆动相,依照相应的控制率运动。
根据本发明优选的,实现对四足机器人的转向控制,包括步骤如下:
F、获取四足机器人前一迈步周期结束时刻的躯干朝向yθ_1、理想情况下迈步周期结束时躯干的朝向θ;
G、通过式(Ⅺ)求得躯干的转向角度Δθ,式(Ⅺ)如下所示:
yθ=yθ_1+Δθ(Ⅺ)
H、在机器人运动过程中,躯干的转向是由支撑相在躯干坐标系下向相反的方向转动相同的角度而实现的。因此,在已知目标转向角度的前提下,就可得到支撑相髋关节横向开合角的控制率,通过式(Ⅻ)求得支撑相髋关节横向开合角的控制率θ14:
I、摆动相的胯关节横向开合角要回正,准备状态时,y_θ_1=y_θ_2=0,对式(XIII)进行迭代运算求得摆动相的回正角度为Δθ_1,大小为当前躯干朝向y_θ_1与前一周期初始时刻躯干朝向y_θ_2的差:
Δθ_1=yθ_1-yθ_2(XIII)
J、通过式(XIV)求得摆动相髋关节横向开合角的控制率θ24:
K、通过控制率分配,将信号传递给相应的腿组,令其依照控制率变化,实现四足机器人的转向控制。
相较于足端轨迹控制,转向控制较为简单,控制率可直接通过方程求得,仅需将控制率分配给相应的腿组即可精确地实现转向控制与摆动相的回正控制。
根据本发明优选的,当四足机器人发生扰动时,调整四足机器人姿态,保证四足机器人运行稳定,包括步骤如下:
当机器人在复杂地面运动时,在迈步结束时,摆动相足端与地面可能会随机发生相对滑动。这会影响机器人运动的稳定性。在迈步周期结束后T/10内,足端轨迹控制单元与转向控制单元协同工作调整机器人姿态,假设随机发生的扰动大小为(Δpx,Δpy),(Δpx,Δpy)是指相较于目标落点的偏差量,包括:
作为摆动相的腿贴着地面向前挪动,在调整姿态的同时,把能耗降到最低,步长为Δr,通过式(XV)求取:
与此同时,支撑相将机器人躯干向前推进同时髋关节横向开合角改变Δθ2,通过式(XVI)求取:
经过上述调整,虽然机器人躯干的朝向与重心位置都可能发生变化。但左右腿髋关节连线得以保持在支撑相足端落点与摆动相足端落点的正中间,且同一腿组内的腿姿态相同。这样可使运动过程拥有极高的稳定性。
根据本发明优选的,求取四足机器人的躯干朝向yθ、躯干重心位置(yx,yy),求取公式如式(XVII)所示:
式(XVII)中,Uθ是指实际躯干转向角度,Ur是指实际四足机器人重心位移距离。
本发明的有益效果为:
1、本发明采用PD神经网络进行机器人运动轨迹控制。相较于传统控制方法,PSO-PD神经网络具有更好的非线性解耦控制能力,控制精确,稳定性强,并且具有较好的抗干扰能力。
2、本发明利用改进PSO粒子群优化算法替代传统BP学习算法,由于本发明提出的面向四足机器人运动轨迹控制的PD神经网络中存在状态反馈与不连续可导的作用函数,因此BP学习算法不能实现神经网络的自适应学习,因此采用改进PSO粒子群优化算法作为神经网络的自适应学习算法。该算法收敛速度快,精度高,且不易陷入局部最优,能够较好的实现该PD神经网络的自适应学习,综上所述,本发明提出的基于改进PSO-PD神经网络的四足机器人运动轨迹控制方法高速、精确、稳定。
附图说明
图1为四足机器人的运动轨迹以及目标落点示意图;
图2是四足机器人的躯干与腿部结构示意图;
图3是摆动相足端轨迹示意图;
图4是足端轨迹控制的流程示意框图;
图5是转向控制的流程示意框图;
图6是PD神经网络的网络结构示意图;
图7是PD神经网络的控制效果图;
图8是存在随机扰动时的控制效果图。
具体实施方式
下面结合说明书附图和实施例对本发明作进一步限定,但不限于此。
实施例
一种基于PSO-PD神经网络的四足机器人运动轨迹控制方法,包括:
(1)根据四足机器人运动轨迹与预设步长,求取四足机器人重心在该运动轨迹上的目标落点,即四足机器人重心在该运动轨迹上的坐标;是相对于实际结果而言的。
(2)将步骤(1)求取的四足机器人重心在该运动轨迹上的目标落点、实时反馈的躯干重心位置(yx,yy)输入PD神经网络模型的输入层;线性变换后进入PD神经网络模型的第一隐含层,在第一隐含层进行比例运算与微分运算;再次线性变换后进入PD神经网络模型的第二隐含层,在第二隐含层得到x方向与y方向上的指导位移,所处坐标系为四足机器人运动所在的水平平面的坐标系,原点为四足机器人初始重心位置;进入PD神经网络模型的第三隐含层,在第三隐含层求得指导位移距离dr、指导转向角度dθ,指导位移距离dr是指四足机器人从当前这一步到下一步迈出的距离,指导转向角度是指四足机器人从当前这一步到下一步的躯干转向角度;进入PD神经网络模型的第五层,第五层分别为足端轨迹控制单元与转向控制单元。足端轨迹控制单元接收指导距离与上一周期的实际位移距离,实现四足机器人的足端轨迹控制;转向控制单元接收指导躯干朝向与当前躯干朝向,实现四足机器人的转向控制,在第五层实现对四足机器人的足端轨迹控制、转向控制;进入PD神经网络模型的第六层,当四足机器人足端发生滑动时,调整四足机器人姿态,保证四足机器人运行稳定;但该过程会使机器人重心发生变化,可视为随机时刻发生的大小随机的扰动,此外还有诸多其他原因造成的扰动,在第六层加入扰动进行模拟并将加入扰动后的步长作为实际步长反馈给第五层;进入PD神经网络模型的第七层,求取四足机器人的躯干朝向yθ、躯干重心位置(yx,yy),躯干朝向yθ是指当前迈步结束后,躯干的实际朝向,即躯干与X轴的夹角;躯干重心位置(yx,yy)是指四足机器人重心在所述坐标系中的坐标;四足机器人的躯干朝向yθ反馈给PD神经网络模型的第五层,躯干重心位置(yx,yy)反馈给PD神经网络模型的输入层。该PD神经网络模型的结构如图6所示;
采用改进的粒子群优化算法调整PD神经网络模型中多层神经元之间的连接权值,实现面向机器人运动轨迹控制的PD神经网络的自适应学习,包括:
a、将多层神经元之间的连接权值的选取问题转化为最优化问题,最优化问题的目标函数即输出向量与导师信号向量的L2范数,如式(Ⅰ)所示,导师信号即目标落点坐标,输出向量即四足机器人实际重心位置;
式(Ⅰ)中,Error为最优化问题的目标函数,xd(k)、yd(k)分别为四足机器人第k步的重心目标落点的横坐标、纵坐标,yx(k)、yy(k)为四足机器人第k步的重心目标落点的实际横坐标、纵坐标;
b、利用先前经验确定每个连接权值的取值范围,即确定寻优范围;
c、在寻优范围内随机初始化一群粒子,即粒子群,包括初始化粒子的初始位置与初始速度,用位置、速度和适应度这三个指标表示粒子特征,位置表示PD神经网络模型中所有的连接权值取值,速度表示每个粒子演化的方向,适应度值由适应度函数求得,即每个粒子对应的目标函数;而每个粒子都代表上述最优化问题的一个潜在最优解;
粒子的速度依据粒子的当前位置、当前速度、粒子的历史最佳位置Pbest与粒子群中最优粒子的位置Gbest更新,粒子的速度的更新公式如式(Ⅱ)所示:
式(Ⅱ)中,id为粒子群中粒子的编号,为第i代粒子的速度,为第i代粒子在第i代之前的历史最佳位置,为第i代粒子群中最优粒子的位置;ω(i)为第i代粒子的惯性权重,其大小决定速度在多大程度上继承上一代粒子的运动速度;%1、%2为加速度因子,取值为非负常数;r1、r2为0到1之间的随机数;是第i代粒子的位置;初始化时ω的取值ωstart为0.9,迭代结束时ω的取值ω34d为0.01,在迭代过程中惯性权重ω加速衰减,初期优先寻优速度,后期着重寻优精度,惯性权重ω的更新公式如式(Ⅲ)所示:
式(Ⅲ)中,maxg;n为最大迭代次数;
本发明加入了非线性递减惯性权重ω(i),惯性权重ω(i)决定速度在多大程度上继承上一代的运动速度,在迭代过程中ω(i)越大寻优速度越快,但精度越低;反之则精度越高,速度越低。为达到速度与精度的平衡,惯性权重ω(i)在迭代初期较大,随着迭代进行惯性权重逐步减小。
得到更新后的粒子的速度后,更新该粒子的位置,粒子的位置的更新公式如式(Ⅳ)所示:
若式(Ⅳ)求取的对应的目标函数小于对应的适应度函数,则反之,同时,更新种群中最优粒子的位置,得到
如此,进行多次迭代即得到近似最优解,即使PD神经网络模型控制误差最小的近似最优权值。
加入遗传算法中的自适应变异的思想,即粒子位置更新之后,有一定概率发生在取值范围内的变异。自适应变异拓展了在迭代中不断缩小的粒子群搜索空间,使其能够在更大的空间展开搜索,使其跳出局部最优,增加得到全局最优的可能性。每个粒子在位置更新后,会生成一个随机数,如果大于0.9则在寻优范围内重新随机初始化该粒子。如果小于等于0.9则什么都不做。
改进的粒子群优化算法在不易陷入局部最优的同时兼顾收敛速度与寻优精度。用其替代传统PSO粒子群算法实现PSO-PD神经网络的自适应学习。改进的粒子群优化算法,学习时间更短,控制精度更高,因此可以更好的满足四足机器人运动轨迹控制的控制需求。
步骤(1),根据四足机器人运动轨迹,求取四足机器人在该运动轨迹上的目标落点,本实施例中四足机器人的运动轨迹为正弦曲线,沿正弦曲线运动时,机器人的转弯半径,转弯角度都在不断发生变化,因此可用来证明该控制策略是否广泛适用于绝大多数非线性运动轨迹。设置预设步长L为0.4m,当没有外界扰动时,机器人的重心不会发生变化,机器人的前进距离即为步长;求取四足机器人在该运动轨迹上的目标落点的公式如式(Ⅴ)所示:
式(Ⅴ)中,x_1、y_1分别为前一步四足机器人重心的横坐标与纵坐标,x、y分别为当前一步四足机器人重心的横坐标与纵坐标;
x_1、y_1的初始值均为0,求取x、y后,再赋值给x_1、y_1,反复迭代二百次后,构成一个200*2的矩阵,得到四足机器人在该运动轨迹上的目标落点。如图1所示。
在第三隐含层求得指导位移距离dr、指导躯干朝向dθ,包括:
通过式(Ⅵ)求取指导位移距离dr,式(Ⅵ)如下所示:
式(Ⅵ)中,dΔx,dΔy为第二隐含层所求得的指导x增量与指导y增量,即x方向与y方向上的指导位移;
通过式(Ⅶ)求取指导躯干朝向dθ,式(Ⅶ)如下所示:
实现对四足机器人的足端轨迹控制,四足机器人包括躯干以及与所述躯干连接的四条腿,在四足机器人的一个迈步周期中,在同一对角线上的两条腿以相同运动方式摆动,支撑躯干并推动躯干前进的两条腿称为支撑相,而按照事先设定轨迹进行摆动的另一对角线上的两条腿称为摆动相,包括步骤如下:
A、通过分析四足机器人腿部结构,构建四足机器人腿部运动数学模型,包括四足机器人足端位置模型:
每条腿包括大腿、小腿;四足机器人的一个迈步周期包括一个支撑相、一个摆动相,躯干坐标系中,x轴表示足端在水平方向上的位移,y轴代表足端高度,原点o为腿髋关节在地面上的投影点,躯干坐标系下足端位置模型如式(Ⅷ)所示:
式(Ⅷ)中,px(θ1,θ2)为足端水平位移与θ1、θ2的函数,pz(θ1,θ2)为足端高度与θ1、θ2的函数,四足机器人的躯干与腿部结构示意图如图2所示,L1为机器人大腿的长度,L1=300mm,L2为机器人小腿的长度,L2=300mm,θ1为机器人髋关节纵向开合角度,取值范围为0°-180°;θ2为膝关节开合角度,取值范围为0°-180°;H为机器人躯干底端到地面的距离;
B、采用一种新型正弦对角步态,求取支撑相足端在躯干坐标系下的运动轨迹、摆动相足端在躯干坐标系下的运动轨迹,所述新型正弦对角步态是指:四足机器人的四条腿以对角分为两组,前左腿和右后腿为一组,前右腿和后左腿为一组,两组交替作为支撑相与摆动相;支撑相推动躯干前行,摆动相向前迈步跨越障碍,这些过程均可通过足端轨迹进行解释。尤其是摆动相足端轨迹,直接决定了摆动相以何种方式进行迈步。因此,足端轨迹的选择对机器人运动控制有着十分重要的意义。
支撑相足端在躯干坐标系下的运动轨迹如式(Ⅸ)所示:
式(Ⅸ)中,p1x(t)为支撑相足端水平位移关于时间t的函数,p1z(t)支撑相足端高度关于时间t的函数,S为当前迈步周期步长,S_1为上一迈步周期实际步长,t为迈步周期内的时刻,T为迈步周期;
支撑相支撑躯干并推动其前行,因此,为使机器人平稳运行,支撑相足端在躯干坐标系下运动应尽量保持匀速,且在z轴方向上保持不变。在x0y平面上,支撑相足端进行匀速运动运动距离为d=0.5*(S+S_1)。
摆动相足端在躯干坐标系下的运动轨迹如式(Ⅹ)所示:
式(Ⅹ)中,p2x(t)为摆动相足端水平位移关于时间t的函数,p2z(t)摆动相足端高度关于时间t的函数,h为步高,为摆动相上升过程中达到的最高点;摆动相足端轨迹示意图如图3所示。
C、控制率的求解
设定步长的取值范围是0.38m~0.42m,精度为1mm,则摆动相足端在躯干坐标系下的运动轨迹有41*41=1681种可能性;
将1681种可能性对应的S_1、S带入公式(Ⅹ),求得摆动相足端不同时刻的位置p2x(t)、p2z(t);
将求得摆动相足端不同时刻的位置p2x(V)、p2z(t)代入公式(Ⅷ)中的px(θ1,θ2)、pz(θ1,θ2),得到一非线性方程组,通过MATLAB求解该非线性方程组,并依据关节约束条件筛选得到符合关节约束条件的髋关节纵向开合角度与膝关节开合角度,作为控制摆动相运动的控制率;
将1681种可能性对应的S_1、S带入公式(Ⅹ),求得支撑相足端不同时刻的位置p1x(t)、p1z(t);
将求得的支撑相足端不同时刻的位置p1x(t)、p1z(t)代入公式(Ⅷ)中的px(θ1,θ2)、pz(θ1,θ2),得到一非线性方程组,通过MATLAB求解该非线性方程组,并依据关节约束条件筛选得到符合关节约束条件的髋关节纵向开合角度与膝关节开合角度,作为控制支撑相运动的控制率;
D、根据求取的摆动相运动的控制率、支撑相运动的控制率,建立数据库
数据库采用二维地址指针,第一维为S_1,第二维为S,每个地址存有2个2*200的控制矩阵,分别为支撑相关节控制率与摆动相关节控制率;
E、通过快速查表法,实现对四足机器人的足端轨迹控制,如图4所示:
a、求取S与S_1;
b、根据S_1与S,进行快速查表,从数据库中得到存有支撑相关节控制率的支撑相控制矩阵与存有摆动相关节控制率的摆动相控制矩阵;
c、将支撑相控制矩阵传递给支撑相,将摆动相控制矩阵传递给摆动相,依照相应的控制率运动。
实现对四足机器人的转向控制,如图5所示,包括步骤如下:
F、获取四足机器人前一迈步周期结束时刻的躯干朝向yθ_1、理想情况下迈步周期结束时躯干的朝向θ;
G、通过式(Ⅺ)求得躯干的转向角度Δθ,式(Ⅺ)如下所示:
yθ=yθ_1+Δθ(Ⅺ)
H、在机器人运动过程中,躯干的转向是由支撑相在躯干坐标系下向相反的方向转动相同的角度而实现的。因此,在已知目标转向角度的前提下,就可得到支撑相髋关节横向开合角的控制率,通过式(Ⅻ)求得支撑相髋关节横向开合角的控制率θ14:
I、摆动相的胯关节横向开合角要回正,准备状态时,y_θ_1=y_θ_2=0,对式(XIII)进行迭代运算求得摆动相的回正角度为Δθ_1,大小为当前躯干朝向y_θ_1与前一周期初始时刻躯干朝向y_θ_2的差:
Δθ_1=yθ_1-yθ_2(XIII)
J、通过式(XIV)求得摆动相髋关节横向开合角的控制率θ24:
K、通过控制率分配,将信号传递给相应的腿组,令其依照控制率变化,实现四足机器人的转向控制。
相较于足端轨迹控制,转向控制较为简单,控制率可直接通过方程求得,仅需将控制率分配给相应的腿组即可精确地实现转向控制与摆动相的回正控制。
当四足机器人发生扰动时,调整四足机器人姿态,保证四足机器人运行稳定,包括步骤如下:
当机器人在复杂地面运动时,在迈步结束时,摆动相足端与地面可能会随机发生相对滑动。这会影响机器人运动的稳定性。在迈步周期结束后T/10内,足端轨迹控制单元与转向控制单元协同工作调整机器人姿态,假设随机发生的扰动大小为(Δpx,Δpy),(Δpx,Δpy)是指相较于目标落点的偏差量,包括:
作为摆动相的腿贴着地面向前挪动,在调整姿态的同时,把能耗降到最低,步长为Δr,通过式(XV)求取:
与此同时,支撑相将机器人躯干向前推进同时髋关节横向开合角改变Δθ2,通过式(XVI)求取:
经过上述调整,虽然机器人躯干的朝向与重心位置都可能发生变化。但左右腿髋关节连线得以保持在支撑相足端落点与摆动相足端落点的正中间,且同一腿组内的腿姿态相同。这样可使运动过程拥有极高的稳定性。
求取四足机器人的躯干朝向yθ、躯干重心位置(yx,yy),求取公式如式(XVII)所示:
式(XVII)中,Uθ是指实际躯干转向角度,Ur是指实际四足机器人重心位移距离。
PD神经网络在足端不发生偏差且没有其他扰动的情况下(即仿真过程中不加入扰动的情况下)的控制效果图如图7所示,运行程序后200步的累积误差为0.1360m,实际重心落点与目标重心落点基本重合,控制效果快速精准。
摆动相足端在接触到非结构性地面后会发生大小随机的滑动,由于步长的限定最大步长为0.42m,最小步长为0.38m,因此,在x轴、y轴上的最大滑动距离均为0.04m,对机器人重心在x轴、y轴上的最大扰动均为0.02m,考虑到其他原因引起的扰动,将机器人重心在x轴、y轴上的最大扰动均设为0.08m,且扰动随机发生,发生的概率为10%,以测试系统的抗干扰能力。经过程序验证,200步的累积扰动为1.5544m,而控制系统的累积误差为1.8694m,如图8所示,在扰动发生后,控制系统会立即减小或消除误差。可见基于PSO-PD神经网络的四足机器人控制精准,抗干扰能力强,具有极高的实用价值。
- 还没有人留言评论。精彩留言会获得点赞!