基于神经网络的工业炉炉温多步预测控制方法与流程
本发明涉及神经网络与预测控制领域,具体涉及一种基于神经网络的工业炉炉温多步预测控制方法。
背景技术:
工业炉炉温作为生产过程中最重要的参数之一,不仅影响到生产品质,还影响到能源节约、经济效益和生态环境,因此对工业炉的温度控制十分重要。传统的方法多数情况需要精确的数学模型,然而在实际工业过程中,对于强非线性工业炉进行精确的机理建模几乎是不可能的。因此,产生了一些新兴的控制方法如预测控制(predictivecontrol,pc),通过滚动优化的方式计算一定步长的控制量,进行工业炉炉温控制。目前常见的滚动优化实现方法有黄金分割法、pso、遗传算法(geneticalgorithm,ga)、n-r以及levenberg-marquardt算法等,其中黄金分割法是粗略的计算方法,控制精度低而且不能保证收敛,pso和ga属于全局寻优算法,能够得到不错的控制效果,但是耗时较长且精度不高,不适用于实时性要求较高的控制过程,n-r和levenberg-marquardt算法属于局部优化算法,该类算法计算速度快,控制精度高,但初值选取不当很容易容易陷入局部极值,导致系统不收敛。
技术实现要素:
本发明的目的在于提供一种基于神经网络的工业炉炉温多步预测控制方法。
实现本发明目的的技术解决方案为:一种基于神经网络的工业炉炉温多步预测控制方法,包括如下步骤:
步骤1:获取历史炉温与燃料量数据,分别计算当前时刻炉温与过去时刻燃料量、过去时刻炉温的相关系数,选择相关系数大于设定阈值的变量作为输入,构建训练集,训练bp神经网络模型;
步骤2:将训练好的bp神经网络模型级联,得到多步预测模型;
步骤3:对目标炉温进行柔化处理,将柔化后的炉温作为参考炉温;
步骤4:利用预测神经网络模型预测多步炉温,根据预测炉温与参考输炉温误差建立性能指标,基于融合pso+n-r方法最小化该性能指标,计算得到燃料量,据此控制炉温;
步骤5:将前一步长对应的燃料量作为下一步长pso寻优的初始状态,基于融合pso+n-r方法计算下一步长的燃料量,不断滚动优化,实现工业炉炉温的多步预测控制。
本发明与现有技术相比,其显著优点在于:1)利用神经网络对工业炉进行建模,不仅精度高,而且泛化能力强,摆脱了对精确数学模型的依赖,更适应工况复杂的工业炉的生产过程;2)结合局部寻优和全局寻优两者的优点,通过在步长内和步长间对pso和n-r进行融合实现炉温的多步预测控制,提高了炉温的控制精度和实时性。
附图说明
图1为多bp级联的多步预测模型图。
图2为融合算法流程图。
图3为设定温度的柔化效果图。
图4为基于n-r滚动优化的炉温控制效果图。
图5为在pso参数相同条件下,融合前后两种方法炉温控制效果对比图。
图6为在pso参数相同条件下,融合前后两种方法炉温误差对比图。
图7为在相似精度条件下,融合前后两种方法炉温控制效果图。
具体实施方式
下面结合附图和具体实施例,进一步说明本发明方案。
基于神经网络的工业炉炉温多步预测控制方法,基于融合pso和n-r算法实现对工业炉炉温的多步预测控制,具体步骤如下:
步骤1:获取历史炉温与燃料量数据,分别计算当前时刻炉温与过去时刻燃料量、过去时刻炉温的相关系数,确定bp神经网络的影响因子,从而确定神经网络的输入和输出,构建训练集,训练bp神经网络模型;
由于工业炉在实际生产中具有强非线性、强耦合性以及大时滞性,很难进行精确建模,因此本发明对工业炉输入输出历史数据进行相关性分析。因为spearman相关系数对数据没有特定的分布要求和容量要求,仅需要数据是整齐成对,因此选取选取spearman相关系数计算输入输出的相关性。通过spearman相关系数的计算,从而得到影响工业炉炉温的影响因子,将这些影响因子作为神经网络的输入,结合温度输出值,构建训练数据集,训练bp神经网络模型。以当前时刻k为例,计算相关系数和构建数据集的步骤如下:
步骤1.1:当前炉温为y(k),因为系统一般不超过4阶,因此分别计算过去时刻的炉温y(k-1)、y(k-2)、y(k-3)、y(k-4)与y(k)的spearman相关系数。
步骤1.2:计算过去时刻的燃料量u(k-1)、u(k-2)、u(k-3)、u(k-4)与y(k)的spearman相关系数。
步骤1.3:设定一个影响因子选取阈值a,在以上的相关系数中将大于a的的变量作为神经网络的输入,结合炉温y(k)构建数据集,训练神经网络模型。
步骤2:根据设定的预测步长,将训练好的神经网络模型级联,级联的方式见图1,得到多步预测模型,实现炉温的多步预测。前一个神经网络的输出作为后一个神经网络的一个输入,读取各神经网络的输出,得到一个预测的温度序列。多步预测模型中神经网络模型的数量与设置的步长相关,假设一个预测步长包括d个采样时刻,则将d个神经网络模型级联,用以预测一个步长即d个时刻的炉温。
步骤3:初始化滚动优化的参数,在炉温预测控制开始之前需要对pso和n-r的基本参数进行初始化,包括pso的粒子数、迭代次数或者迭代精度、个体和群体的学习率,n-r的迭代次数和迭代精度等。
步骤4:对目标炉温进行柔化处理,将柔化后的炉温作为参考炉温;
考虑工业炉的动态特性,当参考温度发生剧烈变化时,则燃料量也要发生相应的大幅度变化,如此可能会导致系统不稳定,因此对设定的目标炉温进行柔化处理,使参考输入平缓过渡到设定值,柔化过程采用如下公式:
式中,r为目标温度,α为柔化系数,取值范围是(0,1),yr(k)表示k时刻经柔化后的参考温度值,y(k)为k时刻炉温,其中y(0)等于环境温度或者工业炉初始炉温。
步骤5:利用预测神经网络模型预测多步炉温,根据预测炉温与参考输炉温误差建立性能指标,基于融合pso+n-r方法最小化该性能指标,计算得到燃料量,控制炉温;
步骤5.1:选取二次性能指标函数构建性能指标,表达式如下:
式中,λ为权重因子且大于等于0,指标函数j是未来d个采样时刻预测控制量的函数,可以通过寻优算法求解得到d个采样时刻的燃料量。yr是目标温度r经过柔化处理后的参考温度,yp是预测模型的预测温度,u表示燃料量。
步骤5.2:基于融合pso+n-r方法最小化性能指标得到一个步长的燃料量。融合pso+n-r算法是本发明的核心部分,发生在一个预测步长内,首先利用pso算法进行初步寻优,并将初步寻优得到的d个采样时刻的燃料量传递给n-r算法作为初始燃料量,然后利用n-r算法求解一个步长内的燃料量,以此作为基础进行炉温控制。
以两步预测控制,即d=2为例,融合pso+n-r方法介绍如下:
(1)以燃料量作为粒子,采用pso算法进行初步寻优;
按如下公式更新粒子速度和位置:
v(k)i+1=ω·v(k)i+c1·rand1·(pbest(k)i-u(k)i)+c2·rand2·(gbest(k)j-u(k)i)
v(k+1)i+1=ω·v(k+1)i+c1·rand1·(pbest(k+1)i-u(k+1)i)+c2·rand2·(gbest(k+1)j-u(k+1)i)
u(k)i+1=u(k)i+v(k)i+1
u(k+1)i+1=u(k+1)i+v(k+1)i+1
式中,ω表示惯性因子,具有非负性,越大全局寻优能力越强,局部寻优能力越弱;c1、c2表示个体和群体学习因子,取2;rand1、rand2表示介于0到1之间的随机数;pbest(k)i表示k时刻第i个粒子的个体最佳位置;gbest(k)j表示k时刻经过j迭代之后群体最佳位置。
计算适应度值fitnessvalue:
式中,y(k)表示k时刻工业炉炉温的实际值,ym(k)为k时刻预测模型预测炉温,h为误差修正因子,u(k)表示第k采样时刻的燃料量。
重复粒子速度和位置更新,直至fitnessvalue达到设置的精度,输出初步寻优得到的燃料量u(k)和u(k+1)。
(2)将初步寻优得到的燃料量u(k)和u(k+1)作为初始状态,采用n-r算法进行局部寻优,得到最终的燃料量u(k)和u(k+1),n-r计算过程如下:
uj+1=uj-(hj)-1fj
式中,j为性能指标函数,hj表示第j次hessian矩阵,fj为第j次迭代的jacobian矩阵,uj、uj+1表示第j和第j+1次迭代的控制向量。
jacobian矩阵展开式为:
hessian矩阵展开式为:
由于hessian矩阵为对称矩阵,因此可以得到:
推导计算得到:
通过以上的计算得到最终的燃料量u(k)和u(k+1),将燃料量传递给工业炉实现炉温控制,可以得到工业炉炉温。
步骤6:将前一步长对应的燃料量作为下一步长pso寻优的初始状态,基于融合pso+n-r方法计算下一步长的燃料量,据此进行炉温控制。
实现pso和n-r的第二阶段融合,考虑到炉温是一个连续变化的量,两个步长之间的燃料量相差不大,结合pso寻优的原理,故将前一步得到的燃料量作为下一步pso寻优的初始状态,大大缩小pso寻优时间。即将前一步计算得到的燃料量u(k+1)作为下一步pso的参考最佳位置的初值,以两步预测为例,如以下公式所示:
gbest(k+2)=gbest(k+3)u(k+1)
步骤7:重复步骤6,不断地计算步长内的燃料量,实现工业炉炉温的多步预测控制。
实施例
为了验证本发明方案的有效性,采用某石油炼化厂的实际数据进行仿真实验,实现工业炉炉温的多步预测控制。基于硬件平台是联想t420s,操作系统windows7,仿真软件为matlab2016a。具体步骤如下:
步骤1:将历史数据进行整编,考虑到四阶系统几乎可以精确描述一个模型,因此选择当前时刻k与k-1、k-2、k-3、k-4四个过去时刻计算spearman相关系数。计算结果请参阅表1和表2,其中u(k)表示k时刻的燃料量,y(k)表示k时刻的炉温,数值越大相关性越强。
表1k+1时刻炉温和历史燃料量的相关性分析结果
表2k+1时刻炉温和历史炉温的相关性分析结果
设定阈值为0.5,大于0.5的作为神经网络的输入,为了更精确的刻画工业炉模型,可以选取更多作为输入,但是模型就会变得复杂,训练的速度响应下降。根据选取好的影响因子,构建神经网络训练集,采用bp算法进行训练,对模型进行测试并保存。
步骤2:将多个bp神经网络级联,可以一次预测多个步长的炉温,请参阅图1。本次仿真采用步长为2,级联的bp神经网络的个数为两个,即d等于2。
步骤3:对pso各个参数进行初始化,设置粒子数为20,迭代次数为30,精度为20,初值最佳位置随机产生,个体和群体的学习率均设置为2。对n-r进行初始化,迭代次数为50,迭代精度为1。
步骤4:考虑工业炉的动态特性,当参考温度发生剧烈变化时,则燃料量也要发生相应的大幅度变化,如此可能会导致系统不稳定,因此对设定的目标炉温进行柔化处理,使参考输入平缓过渡到设定值,柔化过程采用如下公式:
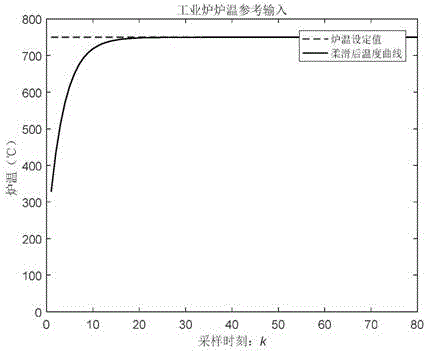
假设设定温度r等于750℃,柔化系数α取值范围是(0,1),取0.75,可根据系统的特性进行调整,yr是柔化后的温度曲线,效果见图3。
步骤5:基于两种优化算法进行多步预测控制,融合原理请参阅图2,具体步骤如下:
步骤5.1:先进行pso初步寻优,达到迭代次数或者精度终止计算,得到燃料量u(k)和u(k+1)。pso的迭代计算公式如下:
v(k)i+1=ω·v(k)i+c1·rand1·(pbest(k)i-u(k)i)+c2·rand2·(gbest(k)j-u(k)i)
v(k+1)i+1=ω·v(k+1)i+c1·rand1·(pbest(k+1)i-u(k+1)i)+c2·rand2·(gbest(k+1)j-u(k+1)i)
u(k)i+1=u(k)i+v(k)i+1
u(k+1)i+1=u(k+1)i+v(k+1)i+1
式中:
h表示校正系数,取0.1;
ω表示惯性因子,本次仿真取1;
c1、c2表示个体和群体学习因子,取2;
rand1、rand2表示介于0到1之间的随机数;
pbest(k)i表示第k步时第i个粒子的个体最佳位置;
gbest(k)j表示第k步时经过j迭代之后群体最佳位置。
步骤5.2:将pso算法寻优结果作为n-r寻优的初值,通过满足精度或者满足迭代次数结束寻优过程,得到燃料量。n-r方法迭代计算过程如下:
uj+1=uj-(hj)-1fj
式中j为性能指标函数,hj表示第j次hessian矩阵,fj为第j次迭代的jacobian矩阵,uj、uj+1表示第j和第j+1次迭代的控制向量。首先对jacobian矩阵进行展开,可以得到:
进一步求解hessian矩阵,对其展开推导得到:
在hessian矩阵中根据对称性,可以得到:
步骤6:将前一步的燃料量作为下一步滚动优化pso的全局最佳位置初值,进行寻优,即:
gbest(k+2)=gbest(k+3)=u(k+1)
步骤7:循环步骤6,实现炉温多步预测控制。
n-r方法收敛速度快精度高,但是非常依赖初值的选取,如果指标函数非线性很强,存在多个极值点,那么很容易陷入局部极值。随机选取初值,进行n-r控制,结果请参阅图4,可以看出控制的炉温不收敛。
单纯使用n-r实现滚动优化很难保证收敛,因此不做比较,对比pso算法与融合pso+n-r算法的多步预测控制效果,请参阅图5中,可以看出,在设置pso参数相同的情况下,本发明的融合算法控制精度更高。因为pso参数相同,所以在pso部分的平均滚动优化时间是相同的,而n-r方法迭代计算速度很快,相对pso寻优时间可以忽略不计,因此,pso方法同融合pso+n-r算法的时间成本基本一致,后者精度更高。pso算法与融合pso+n-r算法的控制炉温误差图,请参阅图6,可以看出,融合后的方法误差更小。
通过调整pso的参数,增加迭代次数和粒子数,也能够提高炉温的控制精度,请参阅图7,调整后的pso与融合pso+n-r方法的精度相差较小,此时两者的温度控制效果大致相同。进行时间成本比较,参阅表3,从表中可以看出,虽然控制效果相差不大,但是平均滚动优化的时间存在着很大的差异,融合后的算法,平均滚动优化时间更小,实时性更好。
表3pso方法与pso+n-r方法优化时间比较(单位:s)
- 还没有人留言评论。精彩留言会获得点赞!