基于GPU的地震数值模拟方法、装置和系统与流程
本公开涉及地震数值模拟领域,更具体地,涉及一种基于GPU的地震数值模拟方法、装置和系统。
背景技术:
在频率域,利用有限差分方法进行地震数值模拟的重要研究内容是求解稀疏线性方程组,此类问题一般可以归结为对以下方程的求解:
A(m,ω)P(ω)=-S(ω) (1)
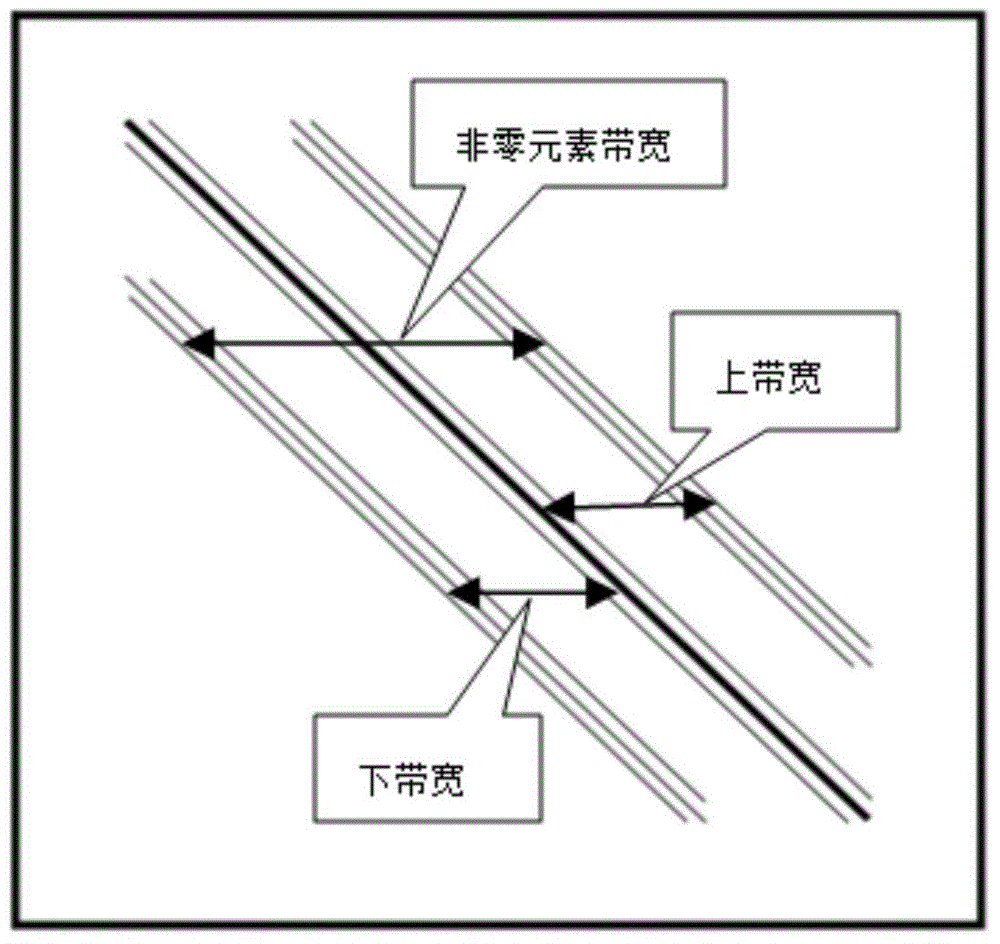
m表示与地下介质特征有关的参数(例如,地下物性参数,包括密度和速度等),ω是频率。假设波场空间的网格维数为(Nx,Nz),其中Nx和Nz是正整数,代表网格在x轴和z轴方向上的维数,方程(1)中的A(m,ω)是一个维数为(Nx×Nz)×(Nx×Nz)的有限差分算子矩阵(或称为系数矩阵);假设P(ω)为要求解的波场值,S(ω)代表的是震源项,P(ω)和S(ω)是(Nx×Nz)的一维向量。以9点差分格式为例,系数矩阵A中最多有9×Nx×Nz个元素是非零的,非零元素的带宽为2Nx+3,其上带宽和下带宽(即矩阵中心对角线上部和下部非零数据的宽度)均为Nx+2,其主要结构如图2所示,其中斜线表示非零元素在整个系数矩阵中呈带状分布的位置,即上下带宽内存在离散的非零数据,而带宽外离散数据值为零。
发明人意识到,如果用稠密矩阵的方式来求解以上稀疏线性方程组,存贮量和计算量都将十分巨大,既浪费内存也会造成不必要的计算开销。实际问题中,地震数值模拟过程中往往需要求解阶数为几十万直至几亿的稀疏线性方程组,因此提高地震数值模拟过程中求解大型稀疏线性方程组的计算效率是非常有必要的。
技术实现要素:
本公开介绍了一种基于GPU的地震数值模拟方法、装置和系统,其提出 利用图形处理单元GPU来进行地震数值模拟,提高了计算效率。
根据本公开的一方面,提出了一种基于图形处理单元GPU的地震数值模拟方法,该方法包括:确定以下方程中的有限差分算子矩阵A(m,ω)和震源项S(ω):
A(m,ω)P(ω)=-S(ω)
其中m表示与地下介质特征有关的参数,ω表示频率,P(ω)表示要求解的波场值;根据矩阵A(m,ω)的类型,选择与基于GPU的线性方程组迭代解法函数库相关的存储格式、预条件处理方法和迭代方法;以及基于所选择的存储格式、预条件处理方法和迭代方法,调用所述基于GPU的线性方程组迭代解法函数库中的相应函数以供GPU执行,从而求解上述方程中的波场值P(ω)。
根据本公开的另一方面,提出了一种基于图形处理单元GPU的地震数值模拟系统,该系统包括主处理单元以图形处理单元。其中主处理单元,包括:确定以下方程中的有限差分算子矩阵A(m,ω)和震源项S(ω):
A(m,ω)P(ω)=-S(ω)
其中m表示与地下介质特征有关的参数,ω表示频率,P(ω)表示要求解的波场值;选择模块,被配置为根据矩阵A(m,ω)的类型,选择与基于GPU的线性方程组迭代解法函数库相关的存储格式、预条件处理方法和迭代方法;和调用模块,被配置为基于所选择的存储格式、预条件处理方法和迭代方法,调用所述基于GPU的线性方程组迭代解法函数库中的相应函数。图形处理单元GPU被配置执行所调用的相应函数来求解上述方程中的波场值P(ω)。
根据本公开的又一方面,提出了一种基于图形处理单元GPU的地震数值模拟装置,该装置包括:用于确定以下方程中的有限差分算子矩阵A(m,ω)和震源项S(ω)的部件:
A(m,ω)P(ω)=-S(ω)
其中m表示与地下介质特征有关的参数,ω表示频率,P(ω)表示要求解的波场值;用于根据矩阵A(m,ω)的类型,选择与基于GPU的线性方程组迭代解法函数库相关的存储格式、预条件处理方法和迭代方法的部件;以及用于基于所选择的存储格式、预条件处理方法和迭代方法,调用所述基于GPU的线性方程组迭代解法函数库中的相应函数以供GPU执行,从而求解上述方程中的波场值P(ω)的部件。
附图说明
通过结合附图对本公开示例性实施方式进行更详细的描述,本公开的上述以及其它目的、特征和优势将变得更加明显,其中,在本公开示例性实施方式中,相同的参考标号通常代表相同部件。
图1示出了适于用来实现本公开实施方式的示例性计算机系统/服务器12的框图。
图2示出了系数矩阵A(m,ω)的示例性结构的示意图。
图3是根据本公开的一个实施例的基于GPU的地震数值模拟方法的流程图。
图4示出了利用基于GPU的线性方程组迭代解法函数库中一些示例性迭代方法在英伟达NVIDIA C2070GPU上与在英特尔Xeon X5560CPU上实现的加速比对比图。
图5示出了根据本公开的一个实施例的基于GPU的地震数值模拟系统的示意性结构图。
图6示出了根据本公开的一个实施例的一种基于图形处理单元GPU的地震数值模拟装置的示意性结构图。
图7示出了层状模型的示意图。
图8示出了层状模型频率为1.172161Hz的正演波场值采样点。
图9示出了corner-edge模型的示意图。
图10示出了corner-edge模型频率为0.3937008Hz的正演波场值采样点。
图11示出了GPU与CPU的计算时间随着矩阵维数增长而增加的趋势的对比。
具体实施方式
下面将参照附图更详细地描述本公开的优选实施方式。虽然附图中显示了本公开的优选实施方式,然而应该理解,可以以各种形式实现本公开而不应被这里阐述的实施方式所限制。相反,提供这些实施方式是为了使本公开更加透彻和完整,并且能够将本公开的范围完整地传达给本领域的技术人员。
图1示出了适于用来实现本公开实施方式的示例性计算机系统/服务器 12的框图。图1显示的计算机系统/服务器12仅仅是一个示例,不应对本公开实施例的功能和使用范围带来任何限制。
如图1所示,计算机系统/服务器12以通用计算设备的形式表现。计算机系统/服务器12的组件可以包括但不限于:一个或者多个处理器或者处理单元16,系统存储器28,连接不同系统组件(包括系统存储器28和处理单元16)的总线18。
总线18表示几类总线结构中的一种或多种,包括存储器总线或者存储器控制器,外围总线,图形加速端口,处理器或者使用多种总线结构中的任意总线结构的局域总线。举例来说,这些体系结构包括但不限于工业标准体系结构(ISA)总线,微通道体系结构(MAC)总线,增强型ISA总线、视频电子标准协会(VESA)局域总线以及外围组件互连(PCI)总线。
计算机系统/服务器12典型地包括多种计算机系统可读介质。这些介质可以是任何能够被计算机系统/服务器12访问的可用介质,包括易失性和非易失性介质,可移动的和不可移动的介质。
系统存储器28可以包括易失性存储器形式的计算机系统可读介质,例如随机存取存储器(RAM)30和/或高速缓存存储器32。计算机系统/服务器12可以进一步包括其它可移动/不可移动的、易失性/非易失性计算机系统存储介质。仅作为举例,存储系统34可以用于读写不可移动的、非易失性磁介质(图1未显示,通常称为“硬盘驱动器”)。尽管图1中未示出,可以提供用于对可移动非易失性磁盘(例如“软盘”)读写的磁盘驱动器,以及对可移动非易失性光盘(例如CD-ROM,DVD-ROM或者其它光介质)读写的光盘驱动器。在这些情况下,每个驱动器可以通过一个或者多个数据介质接口与总线18相连。存储器28可以包括至少一个程序产品,该程序产品具有一组(例如至少一个)程序模块,这些程序模块被配置以执行本公开各实施例的功能。
具有一组(至少一个)程序模块42的程序/实用工具40,可以存储在例如存储器28中,这样的程序模块42包括——但不限于——操作系统、一个或者多个应用程序、其它程序模块以及程序数据,这些示例中的每一个或某种组合中可能包括网络环境的实现。程序模块42通常执行本公开所描述的实施例中的功能和/或方法。
计算机系统/服务器12也可以与一个或多个外部设备14(例如键盘、指向设备、显示器24等)通信,还可与一个或者多个使得用户能与该计算机系 统/服务器12交互的设备通信,和/或与使得该计算机系统/服务器12能与一个或多个其它计算设备进行通信的任何设备(例如网卡,调制解调器等等)通信。这种通信可以通过输入/输出(I/O)接口22进行。并且,计算机系统/服务器12还可以通过网络适配器20与一个或者多个网络(例如局域网(LAN),广域网(WAN)和/或公共网络,例如因特网)通信。如图所示,网络适配器20通过总线18与计算机系统/服务器12的其它模块通信。应当明白,尽管图中未示出,可以结合计算机系统/服务器12使用其它硬件和/或软件模块,包括但不限于:微代码、设备驱动器、冗余处理单元、外部磁盘驱动阵列、RAID系统、磁带驱动器以及数据备份存储系统等。
实施例1
图3是根据本公开的一个实施例的基于GPU的地震数值模拟方法的流程图,在该实施例中,该方法可包括以下步骤:
步骤301,确定以下方程中的有限差分算子矩阵A(m,ω)和震源项S(ω):
A(m,ω)P(ω)=-S(ω)
其中m表示与地下介质特征有关的参数,ω表示频率,P(ω)表示要求解的波场值;
步骤302,根据矩阵A(m,ω)的类型,选择与基于GPU的线性方程组迭代解法函数库相关的存储格式、预条件处理方法和迭代方法;以及
步骤303,基于所选择的存储格式、预条件处理方法和迭代方法,调用所述基于GPU的线性方程组迭代解法函数库中的相应函数以供GPU执行,从而求解上述方程中的波场值P(ω)。
本公开所涉及的GPU(Graphics Processing Unit),即图形处理单元,是一种在计算设备(例如计算机、工作站、游戏机和一些移动设备(如平板电脑、智能手机等)等)上进行图像运算工作的微处理器。其典型用途是将计算机系统所需要的显示信息进行转换驱动,并向显示器提供行扫描信号,以控制显示器的正确显示。
本实施例利用图形处理单元GPU来进行地震数值模拟,提高了计算效率。
图4示出了根据本实施例,利用基于GPU的线性方程组迭代解法函数库 中一些示例性迭代方法在英伟达NVIDIA C2070GPU上与在英特尔XeonX5560CPU上实现的加速比对比图,其中矩阵维数为10000*10000。图4中横坐标表示函数库中的求解大型稀疏线性方程组的示例性迭代方法,包括:共轭梯度法CG、广义最小残量法GMRES、最小残量法MINRES、稳定双共轭梯度法BICGSTAB;纵坐标示出了GPU相对于CPU的约8至14倍的计算加速比。本领域技术人员应理解,图4的目的仅在于示例性地展示本实施例中利用GPU进行地震数值模拟提高计算效率的有益效果,而并非意在限制本发明。
有限差分算子矩阵A(m,ω)和震源项S(ω)的确定
在一个示例中,有限差分算子矩阵A(m,ω)和震源项S(ω)可以根据本领域技术人员已知的任何手段来确定。例如,如本领域技术人员所知,在频率域,利用有限差分方法求取有限差分算子矩阵可以基于波动方程的微分推导,利用差分算子来替代微分算子,从而得到有限差分算子矩阵。而震源项可以是给定的子波(一般采用最小相位雷克子波)做傅里叶变换后的结果。
存储格式、预条件处理方法和迭代方法的选择
本实施例所涉及的基于GPU的线性方程组迭代解法函数库,可以是包含能够由GPU执行以实现线性方程组迭代解法的函数的任何函数库,例如本领域技术人员已知的CULA sparse函数库等。基于GPU的线性方程组迭代解法函数库通常包括涉及以下三方面的函数:
(1)迭代方法,包括共轭梯度、双共轭梯度、最小残差法等迭代方法;
(2)预条件处理,包括块状雅克比、不完全LU分解等预条件处理方法;
(3)稀疏系数矩阵的存储格式,包括行压缩存储、列压缩存储、坐标存储等格式。
这些储格式、预条件处理方法和迭代方法在本公开中被称为与基于GPU的线性方程组迭代解法函数库相关的存储格式、预条件处理方法和迭代方法。
可以根据矩阵A(m,ω)的类型来选择迭代方法。例如,在针对频率域进行地震数值模拟的一个示例中,A(m,ω)可以是非对称的,因此可以选用适于非对称矩阵的迭代方法,例如双共轭梯度方法(诸如稳定双共轭梯度迭代方法 (BI-CGSTAB)等)等。
可以根据矩阵A(m,ω)的类型来选择存储格式。例如,在一个示例中,由于边界条件的原因,矩阵A可以是高度稀疏、非对称、非正定的,而且分布很有规律的,为了节省存储空间,可以仅存储矩阵中的非零元素,即将矩阵压缩成(9,Nx×Nz)的大小,因此可选择坐标存储格式。
此外,本实施例还利用了预条件处理技术,以降低矩阵的条件数,改善矩阵病态特征,加快收敛速度。可以根据矩阵A(m,ω)的类型来选择预条件处理技术,例如,在一个示例中,由于在频率域中数值模拟的矩阵A(m,ω)可以是高度稀疏、非对称和非正定矩阵,因此可以选择不完全LU分解预条件处理方法。
以上以示例了将存储格式、预条件处理方法和迭代方法分别选择为坐标存储格式、不完全LU分解预条件处理方法和双共轭梯度方法,这种示例性的选择方式是根据频率域进行地震数值模拟中矩阵A(m,ω)的示例性类型(或特性)给出的示例性选择。例如,在矩阵A(m,ω)的类型是高度稀疏、非对称和非正定矩阵的情况下,以上选择可以提高计算效率。然而本领域技术人员应理解,针对其他地震数值模拟应用场景下确定的不同类型的矩阵A(m,ω),可以根据计算精度和/或计算效率的需要选择其他的存储格式、预条件处理方法和迭代方法。
在一个示例中,以上选择可以基于用户输入的选择指示来进行,也可以基于预先设置的矩阵A(m,ω)的类型与存储格式、预条件处理方法和迭代方法的对应关系来根据矩阵A(m,ω)的类型自动选择。
相应函数的调用
在一个示例中,调用与选择的存储格式、预条件处理方法和迭代方法相对应的相应函数的过程,可以通过根据所选择的存储格式、预条件处理方法和迭代方法编写函数调用接口来实现。GPU的线性方程组迭代解法函数库可提供例如C,C++和FORTRAN等不同编程语言的函数,因此可以相应地编写不同语言的函数接口进行调用,以Fortran语言调用为例,其调用方式的一个示例如以下代码所示:
status=CULA_ITERATIVE_CONFIG_INIT(config)
CALL CULA_CHECK_STATUS(status)
config%indexing=1
config%tolerance=1e-6
config%maxIterations=50000
status=CULA_BICGSTAB_OPTIONS_INIT(solverOpts)
CALL CULA_CHECK_STATUS(status)
status=CULA_EMPTY_OPTIONS_INIT(precondOpts)
CALL CULA_CHECK_STATUS(status)
call cpu_time(start)
status=CULA_ZCOO_BICGSTAB(config,solverOpts,precondOpts,N,NZ,A,JCN,IRN,xi,bi,result)
CALL CULA_CHECK_STATUS(status)
status=CULA_ITERATIVE_RESULT_STRING(result,bufi,bufsizei)
CALL CULA_CHECK_STATUS(status)
WRITE(*,′(a)′)bufi
call cpu_time(finish)
WRITE(*,*)″Time to solve system for forward:″,finish-start,″seconds″
在一个可能的示例中,本实施例的方法还可以包括以下步骤:设置迭代精度和最大迭代次数,其中,在达到所设置的迭代精度和最大迭代次数其中之一时,GPU停止执行所选择的迭代方法,并以停止时所得到的结果作为波场值P(ω)的数值解。
众所周知,目前求解线性方程组的方法包括直接法和迭代解法。从理论上来说,直接法经过有限次四则运算,假设每一步运算过程中都没有舍入误差,那么最后得到的方程组的解就是精确解,但是直接法对计算机有很高的要求,一般只能应用于中等规模的线性方程组(例如方程组维数n<200)。
本实施例中,发明人认识到矩阵A(m,ω)通常是大型稀疏非对称矩阵,因此,选择了迭代法来求解,以适应于这种大型稀疏非对称矩阵,且易于利用GPU实现优化。迭代法是本领域熟知并且经常用到的数值求解方法,其方法是按照某种规则构造一个收敛的向量序列,该序列收敛于所求解的方程组的准确解。换言之,迭代法是将方程组的解看作某种极限过程的向量极限值,在迭代方法中不将极限过程算到底,只将迭代进行有限次,直到得到满足一定精度的方程组的近似解。
迭代精度是指当某次迭代的求解结果达到该精度时,则认为所求解结果满足误差范围要求,因此可以停止迭代过程。最大迭代次数是指当迭代到该次数时,即使求解结果还没有满足迭代精度的要求也强制停止迭代过程。
本示例采用了设置迭代精度和迭代次数两者的方式来加快收敛速度,只 要迭代精度和最大迭代次数中的一个满足条件,迭代就停止,由此避免了陷入无限迭代。其中最大迭代次数的设置可以防止迭代不收敛而过多浪费计算资源。可以根据需要给定一个可以接受的最大迭代次数,超过这个次数后就停止迭代。
实施例2
图5示出了根据本公开的一个实施例的基于GPU的地震数值模拟系统的示意性结构图,在该实施例中,该系统可包括:
主处理单元501,其可包括:
确定模块5011,被配置为确定以下方程中的有限差分算子矩阵A(m,ω)和震源项S(ω):
A(m,ω)P(ω)=-S(ω)
其中m表示与地下介质特征有关的参数,ω表示频率,P(ω)表示要求解的波场值;
选择模块5012,被配置为根据矩阵A(m,ω)的类型,选择与基于GPU的线性方程组迭代解法函数库相关的存储格式、预条件处理方法和迭代方法;和
调用模块5013,被配置为基于所选择的存储格式、预条件处理方法和迭代方法,调用所述基于GPU的线性方程组迭代解法函数库中的相应函数;以及
图形处理单元GPU502,被配置执行所调用的相应函数来求解上述方程中的波场值P(ω)。
本实施例利用图形处理单元GPU来进行地震数值模拟,提高了计算效率。
在一个示例中,主处理单元501可以是图1所示实施例中的处理单元16。
在一个示例中,主处理单元501还可包括设置模块,被配置为设置迭代精度和最大迭代次数,其中,在达到所设置的迭代精度和最大迭代次数其中之一时,GPU停止执行所选择的迭代方法,并以停止时所得到的结果作为波场值P(ω)的数值解。本示例采用了设置迭代精度和迭代次数两者的方式来加快收敛速度,只要迭代精度和最大迭代次数中的一个满足条件,迭代就停止, 由此避免了陷入无限迭代。其中最大迭代次数的设置可以防止迭代不收敛而过多浪费计算资源。可以根据需要给定一个可以接受的最大迭代次数,超过这个次数后就停止迭代。
参考关于实施例1的讨论,在一个示例中,所选择的存储格式可以为坐标存储格式;在一个示例中,所选择的迭代方法可以为双共轭梯度方法;在一个示例中,所选择的预条件处理方法可以为不完全LU分解预条件处理方法。
实施例3
图6示出了根据本公开的一个实施例的一种基于图形处理单元GPU的地震数值模拟装置的示意性结构图,该装置包括:
用于确定以下方程中的有限差分算子矩阵A(m,ω)和震源项S(ω)的第一部件601:
A(m,ω)P(ω)=-S(ω)
其中m表示与地下介质特征有关的参数,ω表示频率,P(ω)表示要求解的波场值;
用于根据矩阵A(m,ω)的类型,选择与基于GPU的线性方程组迭代解法函数库相关的存储格式、预条件处理方法和迭代方法的第二部件602;
用于基于所选择的存储格式、预条件处理方法和迭代方法,调用所述基于GPU的线性方程组迭代解法函数库中的相应函数以供GPU执行,从而求解上述方程中的波场值P(ω)的第三部件603。
本实施例利用图形处理单元GPU来进行地震数值模拟,提高了计算效率。
在一个示例中,该装置还可包括:用于设置迭代精度和最大迭代次数的第四部件,其中,在达到所设置的迭代精度和最大迭代次数其中之一时,GPU停止执行所选择的迭代方法,并以停止时所得到的结果作为波场值P(ω)的数值解。本示例采用了设置迭代精度和迭代次数两者的方式来加快收敛速度,只要迭代精度和最大迭代次数中的一个满足条件,迭代就停止,由此避免了陷入无限迭代。其中最大迭代次数的设置可以防止迭代不收敛而过多浪费计算资源。可以根据需要给定一个可以接受的最大迭代次数,超过这个次数后就停止迭代。
参考关于实施例1的讨论,在一个示例中,所选择的存储格式可以为坐标存储格式;在一个示例中,所选择的迭代方法可以为双共轭梯度方法;在一个示例中,所选择的预条件处理方法可以为不完全LU分解预条件处理方法。
应用示例及效果
以下通过两个地震理论模型的正演数值模拟过程的应用示例,来说明发明实施例在保证计算精度的同时,提高计算效率的有益效果。本领域技术人员应理解,以下示例的目的仅为了示例性地说明本发明实施例的有益效果,并不意在将本发明实施例限制于所给出的任何示例。
图7是一个层状模型的示意图,其横纵坐标分别表示速度模型在水平方向和垂直方向的网格数,在图7所示的示例中,水平和垂直方向上的网格数均为200,网格间距h=25m,震源坐标为(1000m,2500m),介质速度为V1=4000m/s和V2=6000m/s,震源为雷克子波激发。分别运用常规LU分解直接法和CULA sparse函数库中稳定双共轭梯度迭代法来求解正演过程中的方程组,对这两种方法求出来的波场值进行采样对比。图8是层状模型频率为1.172161Hz的正演波场值采样点,其中横坐标表示方程组解的个数,纵坐标表示方程组解的值的范围。
图9为相对于图7更复杂的corner-edge模型的示意图,其横纵坐标分别表示速度模型在水平方向和垂直方向的网格数。在图9所示的示例中,水平和垂直方向上的网格数均为800,网格间距h=40m,震源坐标为(11000m,5000m),介质速度分别为V1=4000m/s和V2=6000m/s,震源为雷克子波激发。图10是corner-edge模型频率为0.3937008Hz的正演波场值采样点,其横坐标表示方程组解的个数,纵坐标表示方程组解的值的范围。
从图8和图10可以看到,采用直接法和基于GPU的迭代方法,其求解出来的数值精度吻合得比较好,说明本发明实施例的基于GPU进行地震数值模拟的计算精度是有保障的。
图11更加直观地表达了GPU与CPU的计算时间随着矩阵维数增长而增加的趋势的对比。其中图11中横坐标表示矩阵维数,纵坐标表示求解方程组的计算时间,单位为秒。当矩阵维数小于20万时,GPU的计算效率有较低幅度的提高,这主要是由于计算数据量不大时,计算时间很短,受到带宽限 制,将数据从内存拷贝到显存的时间占整个耗时的比例比较重;一旦数据量增加到一定程度后,计算时间大量增加,数据拷贝时间所占比例减小,此时GPU的加速效果就体现地越来越充分,加速比不断得到提高,从而提高了地震数据模拟过程中的计算效率。
本公开可以是系统、方法和/或计算机程序产品。计算机程序产品可以包括计算机可读存储介质,其上载有用于使处理器实现本公开的各个方面的计算机可读程序指令。
计算机可读存储介质可以是可以保持和存储由指令执行设备使用的指令的有形设备。计算机可读存储介质例如可以是――但不限于――电存储设备、磁存储设备、光存储设备、电磁存储设备、半导体存储设备或者上述的任意合适的组合。计算机可读存储介质的更具体的例子(非穷举的列表)包括:便携式计算机盘、硬盘、随机存取存储器(RAM)、只读存储器(ROM)、可擦式可编程只读存储器(EPROM或闪存)、静态随机存取存储器(SRAM)、便携式压缩盘只读存储器(CD-ROM)、数字多功能盘(DVD)、记忆棒、软盘、机械编码设备、例如其上存储有指令的打孔卡或凹槽内凸起结构、以及上述的任意合适的组合。这里所使用的计算机可读存储介质不被解释为瞬时信号本身,诸如无线电波或者其他自由传播的电磁波、通过波导或其他传输媒介传播的电磁波(例如,通过光纤电缆的光脉冲)、或者通过电线传输的电信号。
这里所描述的计算机可读程序指令可以从计算机可读存储介质下载到各个计算/处理设备,或者通过网络、例如因特网、局域网、广域网和/或无线网下载到外部计算机或外部存储设备。网络可以包括铜传输电缆、光纤传输、无线传输、路由器、防火墙、交换机、网关计算机和/或边缘服务器。每个计算/处理设备中的网络适配卡或者网络接口从网络接收计算机可读程序指令,并转发该计算机可读程序指令,以供存储在各个计算/处理设备中的计算机可读存储介质中。
用于执行本公开操作的计算机程序指令可以是汇编指令、指令集架构(ISA)指令、机器指令、机器相关指令、微代码、固件指令、状态设置数据、或者以一种或多种编程语言的任意组合编写的源代码或目标代码,所述编程语言包括面向对象的编程语言—诸如Smalltalk、C++等,以及常规的过程式编程语言—诸如“C”语言或类似的编程语言。计算机可读程序指令可以完全 地在用户计算机上执行、部分地在用户计算机上执行、作为一个独立的软件包执行、部分在用户计算机上部分在远程计算机上执行、或者完全在远程计算机或服务器上执行。在涉及远程计算机的情形中,远程计算机可以通过任意种类的网络—包括局域网(LAN)或广域网(WAN)—连接到用户计算机,或者,可以连接到外部计算机(例如利用因特网服务提供商来通过因特网连接)。在一些实施例中,通过利用计算机可读程序指令的状态信息来个性化定制电子电路,例如可编程逻辑电路、现场可编程门阵列(FPGA)或可编程逻辑阵列(PLA),该电子电路可以执行计算机可读程序指令,从而实现本公开的各个方面。
这里参照根据本公开实施例的方法、装置(系统)和计算机程序产品的流程图和/或框图描述了本公开的各个方面。应当理解,流程图和/或框图的每个方框以及流程图和/或框图中各方框的组合,都可以由计算机可读程序指令实现。
这些计算机可读程序指令可以提供给通用计算机、专用计算机或其它可编程数据处理装置的处理器,从而生产出一种机器,使得这些指令在通过计算机或其它可编程数据处理装置的处理器执行时,产生了实现流程图和/或框图中的一个或多个方框中规定的功能/动作的装置。也可以把这些计算机可读程序指令存储在计算机可读存储介质中,这些指令使得计算机、可编程数据处理装置和/或其他设备以特定方式工作,从而,存储有指令的计算机可读介质则包括一个制造品,其包括实现流程图和/或框图中的一个或多个方框中规定的功能/动作的各个方面的指令。
也可以把计算机可读程序指令加载到计算机、其它可编程数据处理装置、或其它设备上,使得在计算机、其它可编程数据处理装置或其它设备上执行一系列操作步骤,以产生计算机实现的过程,从而使得在计算机、其它可编程数据处理装置、或其它设备上执行的指令实现流程图和/或框图中的一个或多个方框中规定的功能/动作。
附图中的流程图和框图显示了根据本公开的多个实施例的系统、方法和计算机程序产品的可能实现的体系架构、功能和操作。在这点上,流程图或框图中的每个方框可以代表一个模块、程序段或指令的一部分,所述模块、程序段或指令的一部分包含一个或多个用于实现规定的逻辑功能的可执行指 令。在有些作为替换的实现中,方框中所标注的功能也可以以不同于附图中所标注的顺序发生。例如,两个连续的方框实际上可以基本并行地执行,它们有时也可以按相反的顺序执行,这依所涉及的功能而定。也要注意的是,框图和/或流程图中的每个方框、以及框图和/或流程图中的方框的组合,可以用执行规定的功能或动作的专用的基于硬件的系统来实现,或者可以用专用硬件与计算机指令的组合来实现。
以上已经描述了本公开的各实施例,上述说明是示例性的,并非穷尽性的,并且也不限于所披露的各实施例。在不偏离所说明的各实施例的范围和精神的情况下,对于本技术领域的普通技术人员来说许多修改和变更都是显而易见的。本文中所用术语的选择,旨在最好地解释各实施例的原理、实际应用或对市场中的技术的技术改进,或者使本技术领域的其它普通技术人员能理解本文披露的各实施例。
- 还没有人留言评论。精彩留言会获得点赞!