竖向文本广告过滤方法和装置与流程
本发明涉及到互联网技术领域,特别涉及到一种竖向文本广告过滤方法和装置。
背景技术:
互联网的快速发展给人们的生活带来了极大的便利,人们可以利用互联网浏览网页(如QQ浏览器的话题圈评论系统或一些论坛网站等)、或者通过聊天工具进行通信(如QQ、微信等)、或者通过安装一些应用软件获取一些信息(如天气预报应用、日历应用等)。
在互联网给人们带来便利的同时,一些广告发布者会利用互联网的便利发布各种广告,给用户带来了极大的烦恼。例如,广告发布者通常在QQ浏览器的话题圈评论系统上发布广告,或者在QQ群聊、微信群聊里发布广告,或者在一些应用软件中自动弹出一浮窗来发布广告。
为了自动过滤掉这些广告,现有技术中通常会对当前页面上显示的文本信息按照行进行语义识别,在识别结果为广告时则进行过滤处理。
然而,广告发布者为了利用现有广告过滤方法的漏洞,通常会发布一些竖向广告。如图1所示,图1为竖向广告的示意图,这种广告通常需要竖向阅读。例如,对于图1所示的竖向广告,其实际广告内容为“买时尚睡衣加微信357mai”。由于现有的广告过滤方法一般都是按照行进行广告识别,若采用现有技术进行识别,则按照行将上述竖向广告解析为“买加7时微m尚信a睡3i衣5”,此时解析出的内容的语义已经发生变化,采用现有的方法并不能识别出其为广告,因此现有技术对竖向广告的识别率比较低下,并不能过滤掉竖向广告。
技术实现要素:
本发明实施例提供一种竖向文本广告过滤方法和装置,旨在解决不能过 滤掉竖向广告的技术问题。
为实现上述目的,本发明实施例提出竖向文本广告过滤方法,所述竖向文本广告过滤方法包括步骤:
获取文本信息;
将所述文本信息按照行进行分组,依次生成若干第一文本序列;
按照顺序依次提取各个所述第一文本序列对应位置的字符,根据所述对应位置依次生成若干第二文本序列;
根据所述第二文本序列过滤广告。
为了实现上述目的,本发明实施例还进一步提出一种竖向文本广告过滤装置,所述竖向文本广告过滤装置包括:
获取模块,用于获取文本信息;
分组模块,用于将所述文本信息按照行进行分组,依次生成若干第一文本序列;
提取模块,按照顺序依次提取各个所述第一文本序列对应位置的字符,根据所述对应位置依次生成若干第二文本序列;
过滤模块,用于根据所述第二文本序列过滤广告。
本发明提出的竖向文本广告过滤方法和装置,通过获取文本信息,先将所述文本信息按照行进行分组,依次生成若干第一文本序列,然后再按照顺序依次提取各个所述第一文本序列对应位置的字符,根据所述对应位置依次生成若干第二文本序列,最后根据所述第二文本序列过滤广告。由于本发明通过依次提取第一文本序列对应位置的字符而生成第二文本序列,根据第二文本序列过滤广告,因此能够有效地识别竖向文本信息,从而达到过滤掉竖向广告的目的。
附图说明
图1为竖向文本广告的示意图;
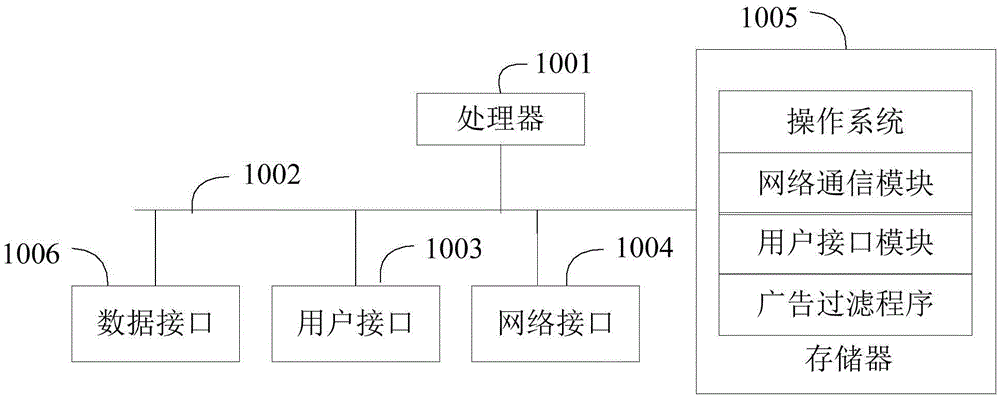
图2为本发明实施例竖向文本广告过滤装置所涉及的硬件架构示意图;
图3为本发明竖向文本广告过滤方法的流程示意图;
图4为页面中显示的文本信息的示意图;
图5为本发明竖向文本广告过滤方法中根据第二文本序列过滤广告步骤的第一细化流程示意图;
图6为本发明竖向文本广告过滤方法中根据文本重组序列过滤广告步骤的第一细化流程示意图;
图7为本发明竖向文本广告过滤方法中根据文本重组序列过滤广告步骤的第二细化流程示意图;
图8为本发明竖向文本广告过滤方法中根据文本重组序列过滤广告步骤的第三细化流程示意图;
图9为本发明竖向文本广告过滤方法中根据第二文本序列过滤广告步骤的第二细化流程示意图;
图10为本发明竖向文本广告过滤方法中根据第二文本序列过滤广告步骤的第三细化流程示意图;
图11为本发明竖向文本广告过滤装置的功能模块示意图;
图12为本发明竖向文本广告过滤装置中过滤模块的第一细化功能模块示意图;
图13为本发明竖向文本广告过滤装置中第一过滤单元的第一细化功能模块示意图;
图14为本发明竖向文本广告过滤装置中第一过滤单元的第二细化功能模块示意图;
图15为本发明竖向文本广告过滤装置中第一过滤单元的第三细化功能模块示意图;
图16为本发明竖向文本广告过滤装置中过滤模块的第二细化功能模块示意图;
图17为本发明竖向文本广告过滤装置中过滤模块的第三细化功能模块示意图。
本发明目的的实现、功能特点及优点将结合实施例,参照附图做进一步说明。
具体实施方式
应当理解,此处所描述的具体实施例仅仅用以解释本发明,并不用于限定本发明。
本发明实施例的主要解决方案是:获取文本信息;将所述文本信息按照行进行分组,依次生成若干第一文本序列;按照顺序依次提取各个所述第一文本序列对应位置的字符,根据所述对应位置依次生成若干第二文本序列;根据所述第二文本序列过滤广告。
由于现有的竖向文本广告过滤方法一般都是按照行进行广告识别,采用现有的方法并不能有效地识别出竖向广告。
本发明实施例架构一竖向文本广告过滤装置,该工具通过获取文本信息,先将所述文本信息按照行进行分组,依次生成若干第一文本序列,然后再按照顺序依次提取各个所述第一文本序列对应位置的字符,根据所述对应位置依次生成若干第二文本序列,最后根据所述第二文本序列过滤广告。由于本发明通过依次提取第一文本序列对应位置的字符而生成第二文本序列,根据第二文本序列过滤广告,因此能够有效地识别竖向文本信息,从而达到过滤掉竖向广告的目的。
其中,本实施例竖向文本广告过滤装置可以承载于服务器也可承载于终端,终端例如可以为计算机、手机或平板电脑等。本实施例以竖向文本广告过滤装置承载于终端为例说明。该竖向文本广告过滤装置所涉及的硬件架构可以如图2所示。
图2示出了本发明实施例竖向文本广告过滤装置所涉及的硬件架构。如图2所示,所述竖向文本广告过滤装置所涉及的硬件包括:处理器1001,例如CPU,通信总线1002,用户接口1003,网络接口1004,存储器1005,数据接口1006。其中,通信总线1002用于实现该服务器中各组成部件之间的连接通信。用户接口1003可以包括显示屏(Display)、键盘(Keyboard)、鼠标等组件,用于接收用户输入的信息,并将接收的信息发送至处理器1005进行处理。显示屏可以为LCD显示屏、LED显示屏,也可以为触摸屏。可选用户接口1003还可以包括标准的有线接口、无线接口。网络接口1004可选的可以包括标准的有线接口、无线接口(如WI-FI接口)。存储器1005可以是高速RAM存储器,也可以是稳定的存储器(non-volatile memory),例如磁盘存储器。存储器1005 可选的还可以是独立于前述处理器1001的存储装置。数据接口1006可以为USB接口或可接收外部数据的通信接口。如图2所示,作为一种计算机存储介质的存储器1005中可以包括操作系统、网络通信模块、用户接口模块以及广告过滤程序。
在图2所示的服务器所涉及的硬件中,网络接口1004主要用于连接其它应用服务器,与其它应用服务器进行数据通信;用户接口1003主要用于连接客户端,与客户端进行数据通信,接收客户端输入的信息和指令;而处理器1001可以用于调用存储器1005中存储的广告过滤程序,并执行以下操作:
获取文本信息;
将所述文本信息按照行进行分组,依次生成若干第一文本序列;
按照顺序依次提取各个所述第一文本序列对应位置的字符,根据所述对应位置依次生成若干第二文本序列;
根据所述第二文本序列过滤广告。
进一步地,在一个实施例中,处理器1001调用存储器1005中存储的广告过滤程序可以执行以下操作:
按照顺序依次将各个所述第二文本序列重组,生成文本重组序列;
根据所述文本重组序列过滤广告。
进一步地,在一个实施例中,处理器1001调用存储器1005中存储的广告过滤程序可以执行以下操作:
将预设广告库中的关键词与所述文本重组序列进行匹配;
在至少一所述关键词与所述文本重组序列匹配时,则确定所述文本信息包含广告,并将所述文本信息过滤。
进一步地,在一个实施例中,处理器1001调用存储器1005中存储的广告过滤程序可以执行以下操作:
提取所述文本重组序列中的字母和/或数字组合序列,并计算提取出的字母和/或数字组合序列的最大长度;
在所述最大长度大于预设阈值时,则确定所述文本信息包含广告,并将所述文本信息过滤。
进一步地,在一个实施例中,处理器1001调用存储器1005中存储的广告过滤程序可以执行以下操作:
将预设广告库中的关键词与所述第二文本序列进行匹配;
在至少一所述关键词与所述第二文本序列匹配时,则确定所述文本信息包含广告,并将所述文本信息过滤。
进一步地,在一个实施例中,处理器1001调用存储器1005中存储的广告过滤程序可以执行以下操作:
提取所述第二文本序列中的字母和/或数字组合序列,并计算提取出的字母和/或数字组合序列的最大长度;
在所述最大长度大于预设阈值时,则确定所述文本信息包含广告,并将所述文本信息过滤;
其中,在提取所述第二文本序列中的字母和/或数字组合序列时,按照所述第二文本序列的顺序,在相邻两第二文本序列中,若前一所述第二文本序列的尾端为字母和/或数字组合序列、且后一所述第二文本序列的首端为字母和/或数字组合序列,则将所述第二文本序列尾端的字母和/或数字组合序列和所述第二文本序列首端的字母和/或数字组合序列拼接形成一所述字母和/或数字组合序列。
进一步地,在一个实施例中,处理器1001调用存储器1005中存储的广告过滤程序可以执行以下操作:
在根据所述文本重组序列过滤广告之前,先剔除所述文本重组序列中的预设字符。
本实施例根据上述方案,通过获取文本信息,先将所述文本信息按照行进行分组,依次生成若干第一文本序列,然后再按照顺序依次提取各个所述第一文本序列对应位置的字符,根据所述对应位置依次生成若干第二文本序列,最后根据所述第二文本序列过滤广告。由于本发明通过依次提取第一文本序列对应位置的字符而生成第二文本序列,根据第二文本序列过滤广告,因此能够有效地识别竖向文本信息,从而达到过滤掉竖向广告的目的。
基于上述硬件架构,提出本发明竖向文本广告过滤方法实施例。
如图3所示,提出本发明一种竖向文本广告过滤方法的第一实施例,所述竖向文本广告过滤方法包括:
步骤S10,获取文本信息;
在本实施例中,可以获取当前浏览的网页中的文本信息,例如一些论坛网站(如QQ浏览器的话题圈评论系统、天涯论坛、百度贴吧等);或者当前开启的软件所显示的文本信息(如QQ群聊、微信群聊);或者当前开启的应用软件中自动弹出的浮窗中的信息(如游戏软件中的浮窗等)。
可选的,可以只获取预设页面中的文本信息。即用户可以对需要进行广告过滤的页面进行预设。
预设页面可以包括基于浏览器浏览的页面、预设应用软件显示的界面和/或预设应用软件对应的预设界面。
可选的,可以预设网址,在浏览器当前浏览的页面地址为预设网址时,则获取当前页面中的文本信息。即,只对预设网址对应的网页进行广告过滤。
上述预设应用软件对应的预设界面例如可以为QQ软件对应的群聊界面,或者微信软件对应的群聊界面。
可选的,在获取文本信息时,可以根据空行获取文本信息。可以预设空行的数量,可以为一行、两行或多行,在文本信息之间的空行数量大于或等于预设数量时,则以空行为分界将文本信息划分为两段文本信息。如图4所示,图4为页面中显示的文本信息的示意图,位于上方的文本信息与位于下方的文本信息之间具有三个空行,若预设空行数量为一行,则系统将以空行为分界将图4所述的文本信息划分为两段文本信息,因此在获取文本信息时,将会获取两段相互独立的文本信息,第一段文本信息为“岭南文化是悠久灿烂的中华文化的有机组成部分。岭南先民遗址的出土材料证明,岭南文化为原生性文化。”;第二段文本信息为“买加7时微m尚信a睡3i衣5”。在本实施例后续的处理步骤中,每段文本信息将会分别单独处理。
步骤S20,将所述文本信息按照行进行分组,依次生成若干第一文本序列;
在本实施例中,可以按照换行符“\n”对文本信息进行分组。可以由上至下依次按照行生成第一文本序列,也可以由下至上依次按照行生成第一文本序列。本实施例中以由上至下依次生成第一文本序列为例进行说明。
如图4所示的文本信息中,对于第一段文本信息,可分为5组第一文本序列,第一组为“岭南文化是悠久灿烂的”,第二组为“中华文化的有机组成部”,第三组为“分。岭南先民遗址的出”,第四组为“土材料证明,岭南文 化”,第五组为“为原生性文化。”。对于第二段文本信息,可分为5组第一文本序列,第一组为“买加7”,第二组为“时微m”,第三组为“尚信a”,第四组为“睡3i”,第五组为“衣5”。
步骤S30,按照顺序依次提取各个所述第一文本序列对应位置的字符,根据所述对应位置依次生成若干第二文本序列;
在本实施例中,每一对应位置生成一第二文本序列。在提取各个第一文本序列的某一对应位置的字符时,可以按照文本行由上至下的顺序依次提取,也可以按照文本行由下至上的顺序依次提取。本实施例以按照文本行由上至下的顺序依次提取为例进行说明,例如,若对应位置为第一文本序列的第一个位置,则可以依次提取第一组第一文本序列、第二组第一文本序列、第三组第一文本序列、第四组第一文本序列和第五组第一文本序列的第一个字符。以上述第二段文本信息为例,则提取出的第一个位置的第二文本序列为“买时尚睡衣”。同理,提取出的第二个位置的第二文本序列为“加微信35”,提取出的第三个位置的第二文本序列为“7mai”。
对于每一第二文本序列来说,在从第一文本序列中提取字符时,各个第一文本序列的对应位置可以为相同位置,即同一第二文本序列中的字符在各个文本行中的位置相同,例如,对于上述第二文本序列“买时尚睡衣”来说,该第二文本序列中的各个字符在各个第一文本序列中的位置均为第一个字符,对于上述第二文本序列“加微信35”来说,该第二文本序列中的各个字符在各个第一文本序列中的位置均为第二个字符,对于上述第二文本序列“7mai”来说,该第二文本序列中的各个字符在各个第一文本序列中的位置均为第三个字符。
或者同一第二文本序列中的字符在各个第一文本序列中的位置呈规则变化。例如,可以依次提取第一组第一文本序列中的第一个位置的字符、第二组第一文本序列中的第二个位置的字符、第三组第一文本序列中的第三个位置的字符、第四组第一文本序列中的第四个位置的字符和第五组第一文本序列中的第五个位置的字符,并将提取出的这五个字符作为第一个第二文本序列。同理,可以依次提取第一组第一文本序列中的第二个位置的字符、第二组第一文本序列中的第三个位置的字符、第三组第一文本序列中的第四个位置的字符、第四组第一文本序列中的第五个位置的字符和第五组第一文本序 列中的第六个位置的字符,并将提取出的这五个字符作为第二个第二文本序列。对于上述第一段文本信息来说,第一个第二文本序列为“岭华岭证文”,第二个第二文本序列为“南文南明化”。
由于某些竖向广告可能包含若干特殊字符,比如空格等,从而使得广告并不是完全竖向显示,而且斜竖向显示,为了使得广告明显,通常广告文本前会增加一些特殊字符。可选的,在生成第二文本序列之前,先剔除各个所述第一文本序列中的预设字符。预设字符可以为空格、“*”、“-”以及其他字符等,在此不作限定。
步骤S40,根据所述第二文本序列过滤广告。
在本实施例中,可以设置一包含若干关键词的预设广告库,然后查找第二文本序列中是否有关键词,含有预设广告库中的关键词时则认为其含有广告,则将获取的文本信息过滤。还可以确定第二文本序列中的字母和/或数字组合序列的长度,在确定的长度达到预设长度阈值时,则认为包含广告,则将获取的文本信息过滤。
本发明提供的竖向文本广告过滤方法,通过获取文本信息,先将所述文本信息按照行进行分组,依次生成若干第一文本序列,然后再按照顺序依次提取各个所述第一文本序列对应位置的字符,根据所述对应位置依次生成若干第二文本序列,最后根据所述第二文本序列过滤广告。由于本发明通过依次提取第一文本序列对应位置的字符而生成第二文本序列,根据第二文本序列过滤广告,因此能够有效地识别竖向文本信息,从而达到过滤掉竖向广告的目的。
以下提出几种根据所述第二文本序列过滤广告的实施方式:
方式一,如图5所示,步骤S40包括:
步骤S41,按照顺序依次将各个所述第二文本序列重组,生成文本重组序列;
对于上述第二段文本信息来说,第一个第二文本序列为“买时尚睡衣”,第二个第二文本序列为“加微信35”,第三个第二文本序列为“7mai”。因此,按照第二文本序列的顺序,生成的文本重组序列为“买时尚睡衣加微信357mai”。
步骤S42,根据所述文本重组序列过滤广告。
在本实施例中,可以对文本重组序列进行语义分析,以辨别其是否为广告。或者还可以将文本重组序列与预设的广告库进行匹配,在匹配时,则认为该文本重组序列对应的文本信息为广告。在确定文本重组序列包含广告时,则将该文本重组序列对应的文本信息过滤。过滤的方式可以为屏蔽、模糊、或乱码的形式等,具体可以根据实际需要进行设置。
例如,上述生成的文本重组序列为“买时尚睡衣加微信357mai”,根据语义分析结果确定其为广告,或者通过判定确定其与预设的广告库匹配,从而确定其为广告。因此将上述第一段文本信息过滤。
以下提出几种根据文本重组序列过滤广告的方案。
方案一,如图6所示,步骤S42包括:
步骤S421,将预设广告库中的关键词与所述文本重组序列进行匹配;
步骤S422,在至少一所述关键词与所述文本重组序列匹配时,则确定所述文本信息包含广告,并将所述文本信息过滤。
在本实施例中,若预设广告库中的某一关键词与文本重组序列中的部分连续字符或所有连续字符一致,则认为预设广告库中的关键词与文本重组序列匹配。本实施例提供的竖向文本广告过滤方法,能够准确的识别出竖向广告。
方案二,为了进一步提高竖向广告过滤的准确性,如图7所示,步骤S421包括:
步骤S423,将预设广告库中的关键词与所述文本重组序列进行匹配;
步骤S424,提取所述文本重组序列中的字母和/或数字组合序列,并计算提取出的字母和/或数字组合序列的最大长度;
在本实施例中,上述步骤S423和步骤S424可以同时执行,也可以不同时执行,执行顺序不分先后。
上述字母和/或数字组合序列可以只包含字母,也可以只包含数字,也可以同时包含字母和数字。在提取字母和/或数字组合序列时,该字母和/或数字组合序列中的各个字母和/或数字在上述文本重组序列中为连续的。每一文本重组序列可能包含多个字母和/或数字组合序列,只需在各个字母和/或数字组合序列中确定最大长度的序列即可。
步骤S425,在至少一所述关键词与所述文本重组序列匹配,且所述最大长度大于预设阈值时,则确定所述文本信息包含广告,并将所述文本信息过滤。
由于一般在做广告宣传时,尤其对于一些不良广告内容,通常会留有QQ号码、电话号码、微信号等,因此通过对字母和数字进行检测,可以快速有效地过滤掉广告。预设阈值可以根据实际需要进行设置,在本实施例中,预设阈值可以取6。
本实施例中提供的竖向文本广告过滤方法,通过将语义分析与字母数字组合相结合的方式进行广告的判断与过滤,准确性较高。
方案三,为了进一步提高竖向广告过滤的准确性,如图8所示,步骤S42包括:
步骤S426,提取所述文本重组序列中的字母和/或数字组合序列,并计算提取出的字母和/或数字组合序列的最大长度;
在本实施例中,字母和/或数字组合序列可以只包含字母,也可以只包含数字,也可以同时包含字母和数字。在提取字母和/或数字组合序列时,该字母和/或数字组合序列中的各个字母和/或数字在上述文本重组序列中为连续的。每一文本重组序列可能包含多个字母和/或数字组合序列,只需在各个字母和/或数字组合序列中确定最大长度的序列即可。
步骤S427,在所述最大长度大于预设阈值时,则确定所述文本信息包含广告,并将所述文本信息过滤。
由于一般在做广告宣传时,尤其对于一些不良广告内容,通常会留有QQ号码、电话号码、微信号等,因此通过对字母和数字进行检测,可以快速有效地过滤掉广告。预设阈值可以根据实际需要进行设置,在本实施例中,预设阈值可以取6。
本实施例中提供的竖向文本广告过滤方法,仅通过字母数字组合的方式进行广告的判断与过滤,使得竖向文本广告过滤方法更加高效率。
此外,上述根据所述文本重组序列过滤广告的实施方式还可以为,提取所述文本重组序列中的字母和/或数字组合序列,并计算提取出的字母和/或数字组合序列的最大长度;在所述最大长度大于预设阈值时,则确定所述文本信息包含广告,并将所述文本信息过滤;在所述最大长度小于或等于预设阈 值时,则将预设广告库中的关键词与所述文本重组序列进行匹配;在至少一所述关键词与所述文本重组序列匹配时,则确定所述文本信息包含广告,并将所述文本信息过滤。
此外,基于上述竖向文本广告过滤方法的任一实施例,上述根据所述文本重组序列过滤广告的实施方式还可以与现有技术中的横向竖向文本广告过滤方法相结合。
方式二,如图9所示,步骤S40包括:
步骤S43,将预设广告库中的关键词与所述第二文本序列进行匹配;
步骤S44,在至少一所述关键词与所述第二文本序列匹配时,则确定所述文本信息包含广告,并将所述文本信息过滤。
在本实施例中,若预设广告库中的某一关键词与第二文本序列中的部分连续字符或所有连续字符一致,则认为预设广告库中的关键词与第二文本序列匹配。本实施例提供的竖向文本广告过滤方法,能够准确的识别出竖向广告。
方式三,如图10所示,步骤S40包括:
步骤S45,提取所述第二文本序列中的字母和/或数字组合序列,并计算提取出的字母和/或数字组合序列的最大长度;
步骤S46,在所述最大长度大于预设阈值时,则确定所述文本信息包含广告,并将所述文本信息过滤;
其中,在提取所述第二文本序列中的字母和/或数字组合序列时,按照所述第二文本序列的顺序,在相邻两第二文本序列中,若前一所述第二文本序列的尾端为字母和/或数字组合序列、且后一所述第二文本序列的首端为字母和/或数字组合序列,则将所述第二文本序列尾端的字母和/或数字组合序列和所述第二文本序列首端的字母和/或数字组合序列拼接形成一所述字母和/或数字组合序列。
在本实施例中,字母和/或数字组合序列可以只包含字母,也可以只包含数字,也可以同时包含字母和数字。
以上述生成的第二文本序列为例,按照提取位置的顺序,第二文本序列 依次为“买时尚睡衣”、“加微信35”、“7mai”。对于第二个第二文本序列,其字母和/或数字组合序列为“35”,且位于其尾端;对于第三个第二文本序列来说,其与第二个第二文本序列相邻,且位于其后面,且其字母和/或数字组合序列为“7mai”,且位于其首端,因此拼接形成一个字母和/或数字组合序列“357mai”,其长度为6。
本实施例中提供的竖向文本广告过滤方法,仅通过字母数字组合的方式进行广告的判断与过滤,使得竖向文本广告过滤方法更加高效率。
对应地,提出本发明竖向文本广告过滤装置的较佳实施例。参考图11,所述竖向文本广告过滤装置包括:获取模块10、分组模块20、提取模块30、过滤模块40,其中,
获取模块10,用于获取文本信息;
在本实施例中,可以获取当前浏览的网页中的文本信息,例如一些论坛网站(如QQ浏览器的话题圈评论系统、天涯论坛、百度贴吧等);或者当前开启的软件所显示的文本信息(如QQ群聊、微信群聊);或者当前开启的应用软件中自动弹出的浮窗中的信息(如游戏软件中的浮窗等)。
可选的,可以只获取预设页面中的文本信息。即用户可以对需要进行广告过滤的页面进行预设。
预设页面可以包括基于浏览器浏览的页面、预设应用软件显示的界面和/或预设应用软件对应的预设界面。
可选的,可以预设网址,在浏览器当前浏览的页面地址为预设网址时,则获取文本信息。即,只对预设网址对应的网页进行广告过滤。
上述预设应用软件对应的预设界面例如可以为QQ软件对应的群聊界面,或者微信软件对应的群聊界面。
可选的,在获取文本信息时,可以根据空行获取文本信息。可以预设空行的数量,可以为一行、两行或多行,在文本信息之间的空行数量大于或等于预设数量时,则以空行为分界将文本信息划分为两段文本信息。如图4所示,图4为页面中显示的文本信息的示意图,位于上方的文本信息与位于下方的文本信息之间具有三个空行,若预设空行数量为一行,则系统将以空行为分界将图4所述的文本信息划分为两段文本信息,因此在获取文本信息时, 将会获取两段相互独立的文本信息,第一段文本信息为“岭南文化是悠久灿烂的中华文化的有机组成部分。岭南先民遗址的出土材料证明,岭南文化为原生性文化。”;第二段文本信息为“买加7时微m尚信a睡3i衣5”。在本实施例后续的处理步骤中,每段文本信息将会分别单独处理。
分组模块20,用于将所述文本信息按照行进行分组,依次生成若干第一文本序列;
在本实施例中,可以按照换行符“\n”对文本信息进行分组。可以由上至下依次按照行生成第一文本序列,也可以由下至上依次按照行生成第一文本序列。本实施例中以由上至下依次生成第一文本序列为例进行说明。
如图4所示的文本信息中,对于第一段文本信息,可分为5组第一文本序列,第一组为“岭南文化是悠久灿烂的”,第二组为“中华文化的有机组成部”,第三组为“分。岭南先民遗址的出”,第四组为“土材料证明,岭南文化”,第五组为“为原生性文化。”。对于第二段文本信息,可分为5组第一文本序列,第一组为“买加7”,第二组为“时微m”,第三组为“尚信a”,第四组为“睡3i”,第五组为“衣5”。
提取模块30,按照顺序依次提取各个所述第一文本序列对应位置的字符,依次生成若干第二文本序列;
在本实施例中,每一对应位置生成一第二文本序列。在提取各个第一文本序列的某一对应位置的字符时,可以按照文本行由上至下的顺序依次提取,也可以按照文本行由下至上的顺序依次提取。本实施例以按照文本行由上至下的顺序依次提取为例进行说明,例如,若对应位置为第一文本序列的第一个位置,则可以依次提取第一组第一文本序列、第二组第一文本序列、第三组第一文本序列、第四组第一文本序列和第五组第一文本序列的第一个字符。以上述第二段文本信息为例,则提取出的第一个位置的第二文本序列为“买时尚睡衣”。同理,提取出的第二个位置的第二文本序列为“加微信35”,提取出的第三个位置的第二文本序列为“7mai”。
对于每一第二文本序列来说,在从第一文本序列中提取字符时,各个第一文本序列的对应位置可以为相同位置,即同一第二文本序列中的字符在各个文本行中的位置相同,例如,对于上述第二文本序列“买时尚睡衣”来说,该第二文本序列中的各个字符在各个第一文本序列中的位置均为第一个字 符,对于上述第二文本序列“加微信35”来说,该第二文本序列中的各个字符在各个第一文本序列中的位置均为第二个字符,对于上述第二文本序列“7mai”来说,该第二文本序列中的各个字符在各个第一文本序列中的位置均为第三个字符。
或者同一第二文本序列中的字符在各个第一文本序列中的位置呈规则变化。例如,可以依次提取第一组第一文本序列中的第一个位置的字符、第二组第一文本序列中的第二个位置的字符、第三组第一文本序列中的第三个位置的字符、第四组第一文本序列中的第四个位置的字符和第五组第一文本序列中的第五个位置的字符,并将提取出的这五个字符作为第一个第二文本序列。同理,可以依次提取第一组第一文本序列中的第二个位置的字符、第二组第一文本序列中的第三个位置的字符、第三组第一文本序列中的第四个位置的字符、第四组第一文本序列中的第五个位置的字符和第五组第一文本序列中的第六个位置的字符,并将提取出的这五个字符作为第二个第二文本序列。对于上述第一段文本信息来说,第一个第二文本序列为“岭华岭证文”,第二个第二文本序列为“南文南明化”。
由于某些竖向广告可能包含若干特殊字符,比如空格等,从而使得广告并不是完全竖向显示,而且斜竖向显示,为了使得广告明显,通常广告文本前会增加一些特殊字符。可选的,所述提取模块还用于在生成第二文本序列之前,先剔除各个所述第一文本序列中的预设字符。预设字符可以为空格、“*”、“-”以及其他字符等,在此不作限定。
过滤模块40,用于根据所述第二文本序列过滤广告。
在本实施例中,可以设置一包含若干关键词的预设广告库,然后查找第二文本序列中是否有关键词,含有预设广告库中的关键词时则认为其含有广告,则将获取的文本信息过滤。还可以确定第二文本序列中的字母和/或数字组合序列的长度,在确定的长度达到预设长度阈值时,则认为包含广告,则将获取的文本信息过滤。
本发明提供的竖向文本广告过滤装置,通过获取文本信息,先将所述文本信息按照行进行分组,依次生成若干第一文本序列,然后再按照顺序依次提取各个所述第一文本序列对应位置的字符,依次生成若干第二文本序列,并按照顺序依次将各个所述第二文本序列重组,生成文本重组序列,最后根 据所述文本重组序列过滤广告。由于本发明通过依次提取第一文本序列对应位置的字符而生成第二文本序列,并对第二文本序列按照顺序进行重组,因此能够有效地识别竖向文本信息,从而达到过滤掉竖向广告的目的。
以下提出几种过滤模块40的实施方式:
方式一,如图12所示,过滤模块40包括:
重组单元41,用于按照顺序依次将各个所述第二文本序列重组,生成文本重组序列;
对于上述第二段文本信息来说,第一个第二文本序列为“买时尚睡衣”,第二个第二文本序列为“加微信35”,第三个第二文本序列为“7mai”。因此,按照第二文本序列的顺序,生成的文本重组序列为“买时尚睡衣加微信357mai”。
第一过滤单元42,用于根据所述文本重组序列过滤广告。
在本实施例中,可以对文本重组序列进行语义分析,以辨别其是否为广告。或者还可以将文本重组序列与预设的广告库进行匹配,在匹配时,则认为该文本重组序列对应的文本信息为广告。在确定文本重组序列包含广告时,则将该文本重组序列对应的文本信息过滤。过滤的方式可以为屏蔽、模糊、或乱码的形式等,具体可以根据实际需要进行设置。
例如,上述生成的文本重组序列为“买时尚睡衣加微信357mai”,根据语义分析结果确定其为广告,或者通过判定确定其与预设的广告库匹配,从而确定其为广告。因此将上述第一段文本信息过滤。
以下提出几种第一过滤单元42的方案。
方案一,如图13所示,第一过滤单元42包括:
匹配子单元421,用于将预设广告库中的关键词与所述文本重组序列进行匹配;
第一过滤子单元422,用于在至少一所述关键词与所述文本重组序列匹配时,则确定所述文本信息包含广告,并将所述文本信息过滤。
在本实施例中,若预设广告库中的某一关键词与文本重组序列中的部分连续字符或所有连续字符一致,则认为预设广告库中的关键词与文本重组序列匹配。本实施例提供的竖向文本广告过滤方法,能够准确的识别出竖向广 告。
方案二,为了进一步提高竖向广告过滤的准确性,如图14所示,第一过滤单元42包括:
匹配子单元421,用于将预设广告库中的关键词与所述文本重组序列进行匹配;
计算子单元423,用于提取所述文本重组序列中的字母和/或数字组合序列,并计算提取出的字母和/或数字组合序列的最大长度;
上述字母和/或数字组合序列可以只包含字母,也可以只包含数字,也可以同时包含字母和数字。在提取字母和/或数字组合序列时,该字母和/或数字组合序列中的各个字母和/或数字在上述文本重组序列中为连续的。每一文本重组序列可能包含多个字母和/或数字组合序列,只需在各个字母和/或数字组合序列中确定最大长度的序列即可。
第二过滤子单元424,用于在至少一所述关键词与所述文本重组序列匹配,且所述最大长度大于预设阈值时,则确定所述文本信息包含广告,并将所述文本信息过滤。
由于一般在做广告宣传时,尤其对于一些不良广告内容,通常会留有QQ号码、电话号码、微信号等,因此通过对字母和数字进行检测,可以快速有效地过滤掉广告。预设阈值可以根据实际需要进行设置,在本实施例中,预设阈值可以取6。
本实施例中提供的竖向文本广告过滤装置,通过将语义分析与字母数字组合相结合的方式进行广告的判断与过滤,准确性较高。
方案三,为了进一步提高竖向广告过滤的准确性,如图15所示,第一过滤单元42包括:
计算子单元423,用于提取所述文本重组序列中的字母和/或数字组合序列,并计算提取出的字母和/或数字组合序列的最大长度;
在本实施例中,字母和/或数字组合序列可以只包含字母,也可以只包含数字,也可以同时包含字母和数字。在提取字母和/或数字组合序列时,该字母和/或数字组合序列中的各个字母和/或数字在上述文本重组序列中为连续的。每一文本重组序列可能包含多个字母和/或数字组合序列,只需在各个字母和/或数字组合序列中确定最大长度的序列即可。
第三过滤子单元425,用于在所述最大长度大于预设阈值时,则确定所述文本信息包含广告,并将所述文本信息过滤。
由于一般在做广告宣传时,尤其对于一些不良广告内容,通常会留有QQ号码、电话号码、微信号等,因此通过对字母和数字进行检测,可以快速有效地过滤掉广告。预设阈值可以根据实际需要进行设置,在本实施例中,预设阈值可以取6。
本实施例中提供的竖向文本广告过滤装置,仅通过字母数字组合的方式进行广告的判断与过滤,使得竖向文本广告过滤方法更加高效率。
此外,上述第一过滤单元42的实施方式还可以为,第一过滤单元42还用于提取所述文本重组序列中的字母和/或数字组合序列,并计算提取出的字母和/或数字组合序列的最大长度;在所述最大长度大于预设阈值时,则确定所述文本信息包含广告,并将所述文本信息过滤;在所述最大长度小于或等于预设阈值时,则将预设广告库中的关键词与所述文本重组序列进行匹配;在至少一所述关键词与所述文本重组序列匹配时,则确定所述文本信息包含广告,并将所述文本信息过滤。
此外,基于上述竖向文本广告过滤装置的任一实施例,上述第一过滤单元42的实施方式还可以与现有技术中的横向竖向文本广告过滤方法相结合,即上述第一过滤单元42还可以同时用于进行横向广告过滤。
方式二,如图16所示,过滤模块40包括:
匹配单元43,用于将预设广告库中的关键词与所述第二文本序列进行匹配;
第二过滤单元44,用于在至少一所述关键词与所述第二文本序列匹配时,则确定所述文本信息包含广告,并将所述文本信息过滤。
在本实施例中,若预设广告库中的某一关键词与第二文本序列中的部分连续字符或所有连续字符一致,则认为预设广告库中的关键词与第二文本序列匹配。本实施例提供的竖向文本广告过滤方法,能够准确的识别出竖向广告。
方式三,如图17所示,过滤模块40包括:
计算单元45,用于提取所述第二文本序列中的字母和/或数字组合序列,并计算提取出的字母和/或数字组合序列的最大长度;
第三过滤单元46,用于在所述最大长度大于预设阈值时,则确定所述文本信息包含广告,并将所述文本信息过滤;
其中,在提取所述第二文本序列中的字母和/或数字组合序列时,按照所述第二文本序列的顺序,在相邻两第二文本序列中,若前一所述第二文本序列的尾端为字母和/或数字组合序列、且后一所述第二文本序列的首端为字母和/或数字组合序列,则将所述第二文本序列尾端的字母和/或数字组合序列和所述第二文本序列首端的字母和/或数字组合序列拼接形成一所述字母和/或数字组合序列。
在本实施例中,字母和/或数字组合序列可以只包含字母,也可以只包含数字,也可以同时包含字母和数字。
以上述生成的第二文本序列为例,按照提取位置的顺序,第二文本序列依次为“买时尚睡衣”、“加微信35”、“7mai”。对于第二个第二文本序列,其字母和/或数字组合序列为“35”,且位于其尾端;对于第三个第二文本序列来说,其与第二个第二文本序列相邻,且位于其后面,且其字母和/或数字组合序列为“7mai”,且位于其首端,因此拼接形成一个字母和/或数字组合序列“357mai”,其长度为6。
本实施例中提供的竖向文本广告过滤方法,仅通过字母数字组合的方式进行广告的判断与过滤,使得竖向文本广告过滤方法更加高效率。
需要说明的是,在本文中,术语“包括”、“包含”或者其任何其他变体意在涵盖非排他性的包含,从而使得包括一系列要素的过程、方法、物品或者装置不仅包括那些要素,而且还包括没有明确列出的其他要素,或者是还包括为这种过程、方法、物品或者装置所固有的要素。在没有更多限制的情况下,由语句“包括一个……”限定的要素,并不排除在包括该要素的过程、方法、物品或者装置中还存在另外的相同要素。
上述本发明实施例序号仅仅为了描述,不代表实施例的优劣。
通过以上的实施方式的描述,本领域的技术人员可以清楚地了解到上述实施例方法可借助软件加必需的通用硬件平台的方式来实现,当然也可以通 过硬件,但很多情况下前者是更佳的实施方式。基于这样的理解,本发明的技术方案本质上或者说对现有技术做出贡献的部分可以以软件产品的形式体现出来,该计算机软件产品存储在一个存储介质(如ROM/RAM、磁碟、光盘)中,包括若干指令用以使得一台终端设备(可以是手机,计算机,服务器,或者网络设备等)执行本发明各个实施例所述的方法。
- 还没有人留言评论。精彩留言会获得点赞!