工艺异因分析方法与工艺异因分析系统与流程
本公开涉及一种工艺异因分析方法与工艺异因分析系统。
背景技术:
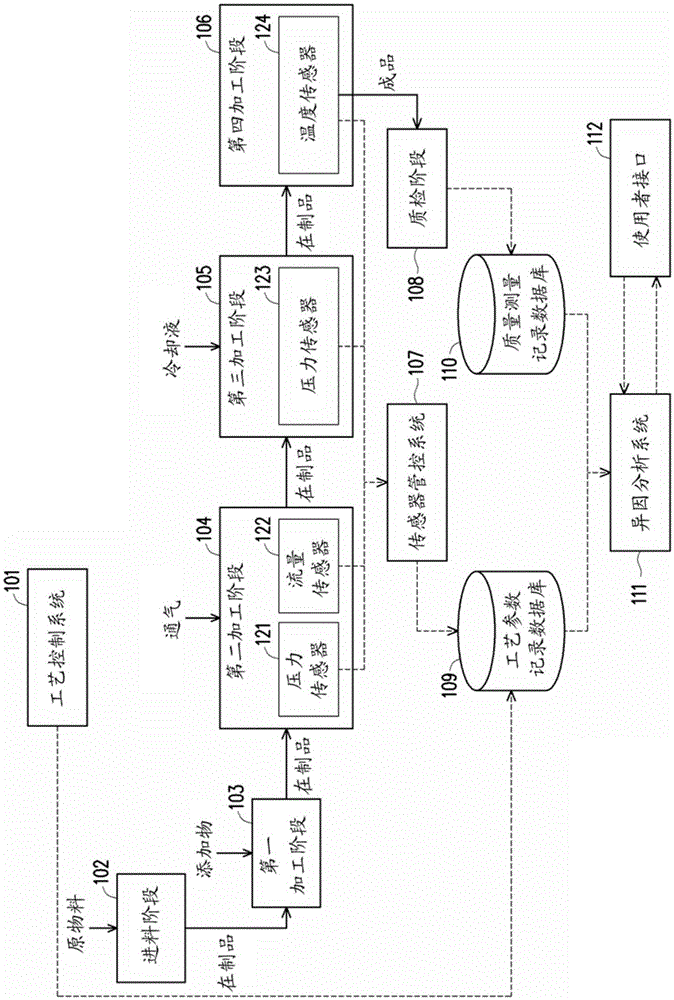
:制造业将原物料加工为产品的过程称为制造流程(或简称工艺)。随着科技日新月异,可被制造的产品越来越多样化、精细化,而相对地工艺也愈发复杂,可调控的工艺参数也越来越多。在制造现场环境中,亦存在着许多会使工艺条件产生变异因素,例如每日的气温、湿度等环境因子都有所不同。因此机械设备经过长时间的运作,其物理化学特性产生的偏移、原物料的来源、成分、操作人员的熟练度、经验等变动的因素提高了维持工艺条件稳定的难度。而当工艺条件不稳定、产生变异时,往往会造成产品的缺陷产生。长久以来,制造现场的工程人员面对产品缺陷,皆希望尽快找出缺陷的成因,以调整工艺,恢复正常生产。制造现场的缺陷成因分析在传统上通常是靠人工分析各种机械设备运转时留下的记录,例如各种工艺的控制参数、测量参数,或各种人为操作留下的记录,例如作业记录、操作记录等,来找出造成缺陷的重要工艺参数。这种方式高度仰赖资深人员经验,且面对日益复杂的工艺条件时,即使是资深人员,亦须花费许久的时间才能找出成因所在,而在此同时,便可能产出更多的不良品。因此,有许多工艺异因分析技术被发展出来,可对制造过程中留下的大量数据进行自动的分析,以期快速锁定造成缺陷的重要工艺参数,协助工程人员快速排除异常,回复正常的生产,减少缺陷造成的损失。目前的工艺异因分析技术,有些受限于可分析的数据类型,有些则无法分析各成因参数的贡献程度,更重要的是,在导入制造现场时,常因制造现场碍于人力、物力、成本考虑而无法提供完整的工艺参数信息,导致分析产生偏误,仍有改善空间。技术实现要素:本公开提供一种工艺异因分析方法及工艺异因分析系统,其可将非数值型数据进行数值编码,并利用分类器选出造成产品缺陷的关键工艺参数。本公开的一范例实施例提出一种工艺异因分析方法,包括获得多个产品的工艺数据,工艺数据包括对应上述产品的多个工艺参数及产品质量参数。上述方法还包括使用非概率类型分类器及概率类型分类器的至少其中之一对工艺数据作运算,以获得每一工艺参数的贡献度。上述方法还包括判断分类器正确率是否大于阈值。上述方法还包括若分类器正确率大于阈值时,对工艺参数进行一删除操作以删除具有最低的贡献度的工艺参数,并再次使用非概率类型分类器及概率类型分类器的至少其中之一对工艺数据运算,以获得每一工艺参数的该献度;以及若分类器正确率不大于阈值时,将工艺参数设定为关键工艺参数。本公开的一范例实施例提出一种工艺异因分析系统,包括收集模块、评估模块、判断模块及比较模块。收集模块用以获得多个产品的工艺数据,工艺数据包括对应上述产品的多个工艺参数及产品质量参数。评估模块用以使用非概率类型分类器及概率类型分类器的至少其中之一对工艺数据作运算,以获得每一工艺参数的贡献度。判断模块用以判断分类器正确率是否大于阈值。若分类器正确率大于阈值时,比较模块对工艺参数进行一删除操作以删除具有最低的贡献度的工艺参数,并再次使用非概率类型分类器及概率类型分类器的至少其中之一对工艺数据运算,以获得每一工艺参数的贡献度,其中若分类器正确率不大于阈值时,比较模块将此些工艺参数设定为关键工艺参数。基于上述,本公开的工艺异因分析方法及工艺异因分析系统会使用非概率类型及概率类型分类器对工艺数据作运算以获得工艺参数的贡献度,并在分类器正确率大于阈值时删除贡献度低的工艺参数,以获得关键工艺参数。为让本公开的上述特征和优点能更明显易懂,下文特举实施例,并配合附图作详细说明如下。附图说明图1为根据本公开所绘示的金属加工工艺范例的流程图。图2为根据本公开一范例实施例所绘示的工艺异因分析系统的方块图。图3为根据本公开一范例实施例所绘示的最佳化标记法的流程图。图4为根据本公开一范例实施例所绘示的具有变量选择结构的分类器。图5为根据本公开一范例实施例所绘示的具有变量选择结构的分类器。图6为根据本公开一范例实施例所绘示的概率模型法的流程图。图7为根据本公开一范例实施例所绘示的工艺异因分析方法的流程图。【符号说明】101:工艺控制系统102:进料阶段103:第一加工阶段104:第二加工阶段105:第三加工阶段106:第四加工阶段107:传感器控管系统108:质检阶段109:工艺参数记录数据库110:质量测量记录数据库111:异因分析系统112:使用者接口121、123:压力传感器122:流量传感器124:温度传感器200:工艺异因分析系统210:收集模块220:评估模块230:判断模块240:比较模块250:编码模块260:存储模块S301、S303、S305、S307、S309、S311、S313、S315:最佳标记法的步骤S601、S603、S605、S607、S609、S611、S613:概率模型法的步骤S701、S703、S705、S707、S709、S711、S713、S715、S717、S719:工 艺异因分析方法的步骤具体实施方式在制造过程中,从原料进料到生产设备后,会按时间依序在不同工艺阶段(stage)进行各种处理,并留下在该工艺阶段被处理当下的感测信号值,以及工艺控制系统设定的控制值。当原料进料后,将逐渐被加工为成品,而在工艺阶段中的原料可被称为在制品(WorkInProcess,WIP)。在工艺阶段中,对在制品进行的每一种处理的参数可经由传感器感测其数值并记录下来成为工艺参数,例如温度、压力等等。值得注意的是,在一个产品(即,完成所有工艺阶段的成品)上,每一个区块都可对应到通过每个工艺阶段时的感测值记录,但在质检阶段中,大多仅会针对整块产品进行质量检测以判断整块产品是否有缺陷,并记录质量检测结果,以形成对应于该产品的质量测量数据。本公开的分析方法与系统会分析工艺参数及产品质量参数以找出造成产品缺陷的主要成因。图1为根据本公开所绘示的金属加工工艺范例的流程图。请参照图1,当原物料在进料阶段102之后,会经过四个加工阶段逐步被加工为成品,原物料在工艺中称为在制品。值得注意的是,在图1中的实线箭头代表原料流且虚线箭头代表数据流。当在制品进入第一加工阶段103中,工艺控制系统101会控制添加物的种类并将添加物的种类记录在工艺参数记录数据库109中。接着在制品进入第二加工阶段104中,工艺控制系统101会通气以维持工艺稳定,通气的压力与流量分别由压力传感器121及流量传感器122记录下来。接着在制品进入第三加工阶段105中,工艺控制系统101会导入冷却液并由压力传感器123记录冷却液压力。最后在制品进入第四加工阶段106加工至成品,并由温度传感器124感测成品温度并记录。压力传感器121、流量传感器122、压力传感器123及温度传感器124感测的数值会由传感器管控系统107收集并记录于工艺参数记录数据库109,形成对应于成品的工艺参数。在一块成品(例如数米)上,每一小段(例如10厘米)都可以对应到通过每一加工阶段时的感测值记录,但在质检阶段108,仅会针对整块成品作质检,并将质量检测结果记录于质量测量记录数据库110中,形成对应于成品的质量测量数据。最后,异因分析系统111就能根据工 艺参数记录数据库109及质量测量记录数据库110来分析工艺参数数据及质量测量数据,找出造成产品缺陷的主要成因并显示于使用者接口(又称之为“用户界面”)112上。须说明的是,本公开的工艺异因分析系统及方法并不仅适用于图1所示的金属加工工艺范例。[第一范例实施例]图2为根据本公开一范例实施例所绘示的工艺异因分析系统的方块图。请参照图2,工艺异因分析系统200包括收集模块210、评估模块220、判断模块230、比较模块240及编码模块250。收集模块210用以获得多个产品的工艺数据。在此,每一产品包括多个区块,工艺数据例如包括对应每一区块的多个工艺参数及对应每一产品的产品质量参数。以下为工艺数据的格式及其说明:…在上述的工艺数据中,xi,1(1),…,xi,1(p)称为一组工艺参数,代表第i个产品的第1个区块在生产过程中被记录的p个工艺参数,以下记为xi,1。每个产品包含的区块个数不一定相同,第i个产品包含的区块个数记为mi。产品在质量检测时,仅整个产品的质量检测结果被记录下来。在本范例实施例中,产品个数为n。以第i个产品为例,产品质量检测结果记为Zi,称为产品质量参数。此产品中任一区块j在生产过程中被记录的一组工艺参数记为xi,j。由于每个工艺参数之间是彼此独立,因此工艺参数也 可称为独立变量。另外,区块j所对应的质量记为yi,j,称为区块质量参数。但由于此区块质量参数受限于制造环境而未被记录下来,因此区块质量参数为隐藏变量。当一个产品产出后可能并不会立即做质量检测,而是将产品先切割(或区分)成多个区块之后,再对切割后的区块进行质量检测。然而,在此过程中只能得知切割后的区块有缺陷,。但无法确切得知这些有缺陷的区块在产品中的位置,故无法将这些有缺陷的区块的工艺参数对应出来。若在第i个产品制出的多块切割后的产品中,任一个有缺陷,代表在产品时即存在缺陷,故产品i被记为有缺陷,即Zi=缺陷。也就是说,当产品i的产品质量参数为无缺陷时,产品i的多个区块的区块质量参数为皆为无缺陷。反之,当产品i的产品质量参数为有缺陷时,产品i的多个区块中的至少一区块的区块质量参数为有缺陷。在不同工艺阶段进行各种处理的过程中,产品的每个区块会被记录一组工艺参数,因此一个产品会被记录到多组工艺参数。例如,产品i共被记录了mi组工艺参数。如此一来,可将产品i视为包含了mi个区块,每个区块有对应的工艺参数xi,1,…,xi,ml。但每个区块对应的区块质量,即区块质量参数yi,1,…,yi,ml,并无法得知。仅可知最后整块产品i是否有缺陷,即产品质量参数Zi=缺陷或Zi=正常。在下表中以产品个数为3,且每个产品都包括4个区块的例子说明,即n=3,m1=4,m2=4,m3=4。表一请参照表一,PID代表了产品ID,PID(1,1)代表了产品1的第1个区块,PID(1,2)代表了产品1的第2个区块,以此类推。X1~X5为工艺参数,Y为区块质量参数,Z为产品质量参数。工艺参数X1为非数值型参数,其具有三个种类A、B、C。请再参照图1,评估模块220用以使用非概率类型分类器及概率类型分类器的至少其中之一对工艺数据作运算,以获得每一工艺参数的贡献度。在本公开的一范例实施例中,若评估模块220使用非概率类型分类器对工艺数据作运算时,评估模块220会反复更新区块质量参数并求解具有变量选择结构的分类器,直到将全部有缺陷的区块利用分类器检验后都符合数据特性时,即可获得每个工艺参数的贡献度。上述方法又称为最佳化标记法。在本公开的另一范例实施例中,若评估模块220使用概率类型分类器对工艺数据作运算时,评估模块220会分别建立产品质量参数及区块质量参数的概率模型分类器,并加入变量选择结构。接着以最大期望算法求解,而获得每个工艺参数的贡献度。上述方法又称为概率模型法。最佳化标记法及概率模型法都会在下文中有更详细的描述。值得一提的是,在本范例实施例中,评估模块220例如可依据使用者的输入信号以外部数据计算出的该分类器正确率来选择使用概率类型分类器及非概率类型分类器的至少其中之一对工艺数据作运算。判断模块230用以判断分类器正确率是否大于阈值。例如,在一范例实施例中,分类器正确率的阈值可设定为90%,然而本公开并不以此为限。在另一范例实施例中分类器正确率的阈值也可根据各种状况而设定为其他的值。若分类器正确率大于阈值时,比较模块240会从工艺参数中删除具有最低的贡献度的工艺参数,并再次使用分类器对工艺数据运算,以获得每一工艺参数的贡献度,上述步骤会重复进行,直到分类器正确率不大于阈值时,比较模块240会将还没被删除的工艺参数加上最后一次被删除的工艺参数设定为关键工艺参数。最后,比较模块240会将利用关键工艺参数而建立的分类器(又称为缩减模型,ReducedModel)与利用原始所有工艺参数而建立的分类器(又称为完整模型,FullModel)进行效能比较,检查缩减模型是否相对于完整模型有相近的分类结果,例如分类正确率、误放率(即,将有缺陷的产品误认为正常)或误判率(即,将正常的产品误判为有缺陷),进而判断缩减模型 中的工艺参数可能为产生缺陷的重要成因。另外,编码模块250会在获得该工艺数据之后,对工艺参数中的非数值型变量进行数值编码。在本范例实施例中,编码模块250可利用虚拟变量(DummyVariable)法或最适规模(OptimalScale)法对非数值型变量进行数值编码。最适规模法为一种通过数值方法的编码方式,首先在初始时随机给定非数值型变量一个编码数值,例如上述的表一中,工艺参数X1有A、B、C三种取值,初始时将A编码为数值1,B编码为数值2,C编码为数值3,接着可利用所获得的工艺数据以最适规模(OptimalScaling)算法计算出A的最适编码数值,例如为-0.074,B的最适编码数值为-0.1964,C的最适编码数值为0.2344。在虚拟变量法中,若非数值型变量原本有n种取值(或称为n个level时),编码模块250可利用n-1个变量来进行编码。例如在上述的表一中,工艺参数X1有A、B、C三种取值,则可利用第一新参数代表原始参数是否为A,若原始参数为A,第一新参数为1,否则为0。接着以第二新参数代表原始参数是否为B,若原始参数为B,第二新参数为1,否则为0。当原始参数为C时,则第一新参数与第二新参数皆为0。在编码模块150对工艺数据中的非数值型变量进行数值编码之后,工艺数据可以下列表二来表示。表二在表二中,以第一新参数X1及第二新参数X2的数值数据取代了表一中 原本工艺参数X1中的非数值数据。如此一来,就可将工艺数据使用分类器作运算。值得注意的是,当工艺异因分析系统200的使用者欲进行工艺缺陷成因分析时,可利用使用者接口(未绘示于图中)选定欲分析的数据。在一范例实施例中,使用者接口可为一计算机程序,运行于一个人计算机、工业计算机或工作站上,使用者可直接输入分析命令、取得并呈现分析结果。在另一范例实施例中,使用者接口也可为一网页服务,运行于一个人计算机、工业计算机或工作站上,使用者可通过具有输入输出接口的终端,例如个人计算机、平板计算机、智能手机等,输入分析命令、取得并呈现分析结果。存储模块260可以是例如硬盘(HardDiskDrive,HDD)、固态硬盘(SolidStateDrive,SSD)等的非易失性存储器。在一范例实施例中,存储模块260至少可包括工艺参数数据库、质量测量数据库、工艺参数贡献度数据库及分类效能数据库,其中工艺参数数据库用以记录传感器的感测数值,以及工艺参数的设定的控制值,质量测量数据库用以记录产品质量检测结果,工艺参数贡献度数据库用以记录经由分类器求得的工艺参数贡献度,分类效能数据库用以记录缩减模型及完整模型的分类效能。虽然以上说明了将各种工艺参数、产品质量与效能检测结果的相关数据存储于不同数据库,但本公开并不以此为限。在另一范例实施例中,也可将各种工艺参数、产品质量与效能检测结果的相关数据全部存储于存储模块260的服务器数据库中。在一范例实施例中,收集模块210例如是可测量各种数值(例如温度、压力、气体或液体流量等)的传感器,并用以将其感测结果回传到存储模块260中。在一范例实施例中,评估模块220、判断模块230、比较模块240及编码模块250,皆可使用硬件描述语言(如Verilog或VHDL)来进行电路设计,经过整合与布局后,可烧录至现场可编程逻辑门阵列(FieldProgrammableGateArray,FPGA)上。藉由硬件描述语言所完成的电路设计,例如可交由专业的集成电路生产商以特殊应用集成电路(Application-SpecificIntegratedCircuit,ASIC)或称专用集成电路来实现,但本公开并不以此为限。在另一范例实施例中,评估模块220、判断模块230、比较模块240及编码模块250也可利用软件或固件的方式来实作,并以处理器来执行以实现其功能。图3为根据本公开一范例实施例所绘示的最佳化标记法的流程图,图4为根据本公开一范例实施例所绘示的具有变量选择结构的分类器,并且图5 为根据本公开一范例实施例所绘示的具有变量选择结构的分类器。请参照图3,在步骤S301中,初始化区块质量参数,详细内容将请参照下表3说明。表3请参照表3,在本范例实施例中,关于产品质量参数Z的赋值,设定为产品质量正常时赋值为-1,而产品质量有缺陷时赋值为1。然而,本公开并不以此为限。在另一范例实施例中,产品质量参数Z可再依据缺陷严重程度赋值,例如,轻微缺陷赋值为1,严重缺陷赋值为2。在本范例实施例中,为了方便说明,产品质量参数Z的赋值只有1及-1两种。当产品质量参数Z的值给定以了以后,区块质量参数Y会初始地设定为与当产品质量参数Z相同的值。请再参照图3,在步骤S303中,求解具有变量选择结构的非概率类型分类器,并在步骤S305中,将产品质量参数有缺陷的产品以非概率类型分类器检验是否符合数据特性。在此,请同时参照图4。具体来说,对于所有Z=1的产品,会逐一将工艺参数X输入图4的分类器,并检验分类结果是否符合数据特性。若Z代表的缺陷有分等级,可设定有缺陷的区块数量,例如当Z为严重缺陷时则该产品的至少50%的区块Y=1,而当Z为轻微缺陷时,则该产品的至少10%的区块Y=1。在本范例实施例中,为了方便说明,设定为若 一产品的Z=1,则此产品的至少一区块的Y=1。在将PID2的四个区块全部输入图4的分类器时,所产生的Y值全部为-1,如表4所示。表4由于Z=1代表则至少一区块的Y=1,因此此分类器不符合数据特性,表示此分类器有偏误,则在步骤S307中,依照比例将分类信心度低的区块的区块质量参数设定为有缺陷。由于在本范例实施例中假设缺陷严重程度为轻微缺陷,其对应的数据特性是若一产品的Z=1,则此产品的至少一区块的Y=1。因此在本范例实施例中,会将分类信心度最低的区块的区块质量参数设定为有缺陷,例如将PID(2,3)的Y设定为1。然而,在另一范例实施例中,若缺陷的严重程度为严重缺陷,并假设其对应的数据特性是若一产品的Z=1,则此产品的至少一半的区块的Y=1。在这种情况下,会将缺陷产品中的区块依照信心度排序,并依序将信心度低的区块的Y设定为1,直至满足一半的区块有缺陷,以满足数据特性。接着回到步骤S303,重新求解具变量选择结构的非概率类型分类器,如图5所示。若产品质量参数有缺陷的全部区块以非概率类型分类器检验皆符合数据特性时,则在步骤S309中,获得每一工艺参数的贡献度,如表5所示。表5X1X2X3X4X5X6贡献度563602429接着在步骤S311中,判断分类器正确率是否大于阈值。若分类器正确率大于阈值,则在步骤S313中,删除贡献度最低的工艺参数,例如删除表5中贡献度为0的工艺参数X4,再回到步骤S303重新求解分类器。直到分类正确率不大于阈值时,则在步骤S315中,将最后一次判断分类器正确率是否大于阈值之前留下的工艺参数设定为关键工艺参数,如表6所示,工艺参数X3、X5、X6会被设定为关键工艺参数。表6X3X5X6贡献度362429值得一提的是,例如,在一范例实施例中,工艺数据中的一部分(例如,70%的工艺数据)可用来作为分类器的训练数据,而工艺数据的其他部分(例如,30%的工艺数据)则可用来作为测试数据,以测试分类器的正确率。在一范例实施例中,在步骤S303中求解具有变量选择结构的非概率类型分类器可使用支持向量机(SupportVectorMachine,SVM)分类器,其目标函数如下:其中n为产品数量。mi为第i个产品的区块数量。yi,j为-1或1,为第i个产品的第j个区块的区块质量参数。xi,j为第i个产品的第j个区块的工艺参数。β0为常数。p为工艺参数个数,β为p×1的系数向量。λ大于等于0,其为正则化(regularization)参数。而在加入变量选择结构后,目标函数变为:其中λ1、λ2大于等于0,其为正则化参数。SVM分类器的解β0及β可藉由求解方程式(1)来求出。解出的SVM分类器可由输入的区块对应的工艺参数X来估计对应的Y。另外,解出的分类器具变量选择结构,因此可更进一步估计各个工艺参数的贡献度(或重要程度)。举例来说,在本范例实施例中使用的SVM分类器可用OOB(Out-Of-Bag)的方法将每个工艺参数的贡献度量化。具体来说,假设工艺参数有p个{v1,v2…,vp},以这些工艺参数建立一个SVM分类器并由SVM损失函数计算出此SVM分类器的损失值lossa。接着每删除一个工艺参数vi并以剩余的p-1个工艺参数重新建立SVM分类器,再由SVM损失函数计算出此SVM分类器的损失值lossi,i=1到p。最后计算Di=|lossa-lossi|,当Di越大代表删除工艺参数vi后损失越大,也就是说vi的贡献度越高。因此p个工艺参数的贡献度可用Di来表示,i=1到p。以下为根据一范例实施例以SVM分类器为例的完整算法:图6为根据本公开一范例实施例所绘示的概率模型法的流程图。请参照图6,在步骤S601中,分别建立产品质量参数及区块质量参数的概率模型,以描述产品中的区块质量有缺陷的概率及产品的质量检测结果有缺陷的概率。在本范例实施例中,可使用逻辑回归(LogisticRegression,LR)建立概率模型。区块质量参数的概率模型如下:其中Pri,j为第i个产品的第j个区块有缺陷的概率。xi,j为第i个产品的第j个区块的工艺参数。p为工艺参数个数。β为p×1的系数向量。β0为常数。产品质量参数的概率模型如下:其中πi为第i个产品有缺陷的概率。mi为第i个产品的区块数量。由于1-Pri,j为第i个产品第j个区块无缺陷的概率,因此将第i个产品所有区块无缺陷的概率相乘就是第i个产品无缺陷的概率,而πi就会是第i个产品有缺陷的概率。在步骤S603中,根据产品质量参数及区块质量参数定义似然函数(LikelyhoodFunction)。似然函数如下:其中n为产品的数量。mi为第i个产品的区块数量。Zi为0或1,其为第i个产品的二进位产品质量参数。yi,j为0或1,其为第i个产品的第j的区块的二进位区块质量参数。对于无缺陷的产品i而言,所有区块的yi,j皆为0,因此1-Zi=1,可得Zi=0。对于有缺陷的产品i而言,至少一区块的yi,j为1,因此1-Zi=0,可得Zi=1。在步骤S605中,加入惩罚值以定义概率模型的损失函数。逻辑回归的损失函数如下:其中λ大于等于0,其为正则化参数,而p为工艺参数个数。在定义完损失函数之后,接着会对产品质量参数赋值。在本范例实施例中,当产品质量正常时,Z的值为0,当产品质量有缺陷时,Z的值为1。如下表7所示。表7在步骤S607中,利用最大期望(Maximum-Estimation,EM)算法求出每一这些工艺参数所对应的该贡献度。具体来说,会先将表2中的工艺数据代入方程式(2),并以最大期望算法求解方程式(2)以获得逻辑回归分类器的解β0及β。解出逻辑回归分类器之后就可藉由输入一区块对应的工艺参数X来估算对应的Y=1的概率。此外,系数β的绝对值即可代表每个工艺参数X的重要程度。假设解出的系数β如下表8所示。表8X1X2X3X4X5X6β0.250.3-3.202.62.8在步骤S609中,判断分类器正确率是否大于阈值。若分类器正确率大于阈值,则在步骤S611中,删除贡献度最低的工艺参数,例如删除表8中β值为0的工艺参数X4,再回到步骤S605中。直到分类正确率不大于阈值时,则在步骤S613中,将最后一次执行步骤S611前留下的工艺参数设定为关键工艺参数,如表9所示,工艺参数X3、X5、X6会被设定为关键工艺参数。表9X3X5X6贡献度3.12.52.7以下根据一范例实施例以逻辑回归为例的概率模型法的完整算法:虽然在上述范例实施例中,是基于一个产品有多个区块来说明本公开的工艺异因分析方法,也就是工艺参数对应到产品的区块且产品质量参数对应到每个产品,但本公开并不以此为限。[第二范例实施例]在本范例实施例中,可将所有产品分为多个群组,其中这些群组中的每一产品有对应的工艺参数,且每一群组有对应的产品质量参数。举例来说,可将一百个产品分为十个群组,并且在每个群组中只抽出一个产品进行质量检测并以此质量检测结果代表此群组的产品质量参数。在本范例实施例中,由于无法获得每一个产品的产品质量参数,而仅能得知一个群组的产品质量参数,因此本范例实施例中的每一个产品的产品质量参数及每一个群组的产品质量参数可对应于第一范例实施例的区块质量参数及产品质量参数,并适用于本公开的工艺异因分析方法。[第三范例实施例]在本范例实施例中,一个产品的制造过程可分为多个制造时间区段。每一产品的多个制造时间区段有对应的工艺参数,且每一产品有对应的产品质量参数。举例来说,若制造一个产品时会每十秒取样一次工艺参数,假设制造此产品费时两分钟,则此产品会有对应于不同制造时间区段的12组工艺参数。在本范例实施例中,由于无法获得此产品在每一个制造时间区段的产品质量参数,而仅能得知此产品制造完成时的产品质量参数,因此本范例实施例中的每一个制造时间区段的产品质量参数及制造完成时的产品质量参数可对应于第一范例实施例的区块质量参数及产品质量参数,并适用于本公开的工艺异因分析方法。图7为根据本公开一范例实施例所绘示的工艺异因分析方法的流程图。请参照图7,在步骤S701中,获得产品的工艺数据,其中工艺数据包括对应产品的工艺参数及产品质量参数,且工艺参数的取样数量大于产品质量参数的取样数量。在步骤S703中,对非数值型的工艺参数进行数值编码。在步骤S705中,选择分类器并判断分类器是否为概率类型。在此,可依据使用者的输入信号以外部数据计算出的分类器正确率来选择使用概率类型分类器或非概率类型分类器。若分类器不是概率类型时,在步骤S707中,求解具变量选择结构的分类器,直到解出的分类器符合数据特性,并获得各个工艺参数的贡献度。接着在步骤S709中,判断分类器正确率是否大于阈值。若分类器正确率大于阈值时,在步骤S711中,删除贡献度最低的工艺参数,再回到步骤S707重新求解分类器。若分类器正确率不大于阈值时,在步骤S719中,将最后一次删除工艺参数前所解出的分类器与使用所有工艺参数解出的分类器比较效能,验证用来建构前者分类器的工艺参数为关键工艺参数。若分类器为概率类型时,在步骤S713中,建立概率模型,并加入变量选择结构,以最大期望算法求解,并获得各个工艺参数的贡献度。接着在步骤S715中,判断分类器正确率是否大于阈值。若分类器正确率大于阈值时,在步骤S717中,删除贡献度最低的工艺参数,再回到步骤S713重新求解分类器。若分类器正确率不大于阈值时,在步骤S719中,将最后一次删除工艺参数前所解出的分类器与使用所有工艺参数解出的分类器比较效能,验证用来建构前者分类器的工艺参数为关键工艺参数。综上所述,本公开会获得产品的工艺数据,对工艺数据中的非数值变量进行数值编码,并利用最佳化标记法或概率模型法求解分类器以获得工艺参数的贡献度。若分类器正确率大于阈值时则删除贡献度低的工艺参数,以获得关键工艺参数。最后再比较以关键工艺参数解出的分类器与以全部工艺参数解出的分类器的效能,用来验证关键工艺参数为造成缺陷的重要成因。虽然本公开已以实施例公开如上,然其并非用以限定本公开,本领域技术人员在不脱离本公开的精神和范围内,当可作些许的更动与润饰,故本公开的保护范围当视所附权利要求书界定范围为准。当前第1页1 2 3
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1