语义信息生成方法和语义信息生成装置与流程
本公开涉及用于为了处理自然语言的文本信息的语义(意思)而生成针对单词的语义信息的装置及其方法。
背景技术:
存在为了处理自然语言的文本信息的语义而针对构成文本的单词生成语义信息的现有技术(非专利文献2、非专利文献3)。所述现有技术为,从大量的文本数据集(以下记述为文本语料库)学习要向文本语料库中所包含的各单词进行分配的多维度的向量,将单词和与该单词对应的多维度的向量(语义信息)的对应关系作为结果来输出。
由这样的现有技术所生成的语义信息能够在单词的语义是否相似的判定中加以使用。
现有技术文献
专利文献
专利文献1:日本特开2002-334077号公报
非专利文献
非专利文献1:柴田、黑桥“文脈に依存した述語の同義関係獲得”情報処理学会研究報告(“依赖于上下文的谓语的同义关系获得”信息处理学会研究报告),Vol.2010-NL-199No.13
非专利文献2:Tomas Mikolov,Kai Chen,Greg Corrado,and Jeffrey Dean.“Efficent Estimation of Word Representations in Vector Space.”ICLR 2013.
非专利文献3:Tomas Mikolov,Ilya Sutskever,Kai Chen,Greg Corrado,Jeffrey Dean,“Distributed Representations of Words and Phrases and their Compositionality.”NIPS 2013.
技术实现要素:
但是,根据现有技术,分配给某单词的语义信息、和分配给要与该单词区别语义的另一单词的语义信息成为相接近的信息,因此,为了在单词的语义是否相似的判定中使用,需要进一步的改善。
本公开的一技术方案的方法包括:
取得包含第一文本数据和第二文本数据的第一文本语料库,所述第一文本数据包含第一单词、且是用自然语言来记述的第一文章的文本数据,所述第二文本数据包含应与所述第一单词区别语义的第二单词、且是第二单词分布与第一单词分布相似的第二文章的文本数据,所述第二单词分布表示所述第二文章中在所述第二单词之前以及之后的预定范围内出现的单词的种类和出现个数,所述第一单词分布表示所述第一文章中在所述第一单词之前以及之后的所述预定范围内出现的的单词的种类和出现个数;
取得包含第三文本数据的第二文本语料库,所述第三文本数据包含作为与所述第一单词和所述第二单词中的至少一方相同的单词的第三单词、且是第三单词分布与所述第一单词分布不相似的第三文章的文本数据,所述第三单词分布表示所述第三文章中在所述第三单词之前以及之后的所述预定范围内出现的单词的种类和出现个数;
基于所述第一文本语料库和所述第二文本语料库中的单词串的排列,通过对所述第一单词分配在预定维度的向量空间中表示所述第一单词的语义的第一向量,并对所述第二单词分配在所述向量空间中表示所述第二单词的语义的第二向量,进行学习;
对所述第一向量以与所述第一单词相关联的方式进行存储,对在所述向量空间中与所述第一向量相距预定以上的距离的所述第二向量以与所述第二单词相关联的方式进行存储。
再者,这些总括或具体的方式可以由系统、装置、集成电路、计算机程序或计算机可读取的CD-ROM等的记录介质来实现,也可以由系统、装置、集成电路、计算机程序以及记录介质的任意组合来实现。
根据本公开,能够抑制分配给某单词的向量、和分配给应与该单词区别语义的另一单词的向量相接近,因此能够使用在单词的语义是否相似的判定中。
再者,本公开的进一步的效果和优点从本说明书以及附图的公开内容得以明确。上述进一步的效果和优点可以由本说明书以及附图所公开的各种实施方式以及特征单独地来提供,但不一定需要提供所有的效果以及优点。
附图说明
图1是表示本公开的一实施方式中的单词语义信息生成装置的结构的一例的框图。
图2是表示第二文本语料库所包含的单词为第一文本语料库所包含的单词的反义词的情况下的单词语义信息生成装置的结构的一例的框图。
图3是表示作为一般文本语料库而采用的文本语料库的一例的图。
图4是表示作为一般文本语料库而采用的文本语料库的包含存在反义词关系的单词的文本语料库的一例的图。
图5是表示存储在反义词文本语料库中的文本数据的一例的图。
图6是表示在出现概率的计算中使用的神经网络的结构的一例的图。
图7是表示在学习中使用的文本数据的一例的图。
图8是表示用1-of-K形式的向量表示的单词的一例的图。
图9是使用向量X、H、Y(-2)、Y(-1)、Y(+1)、Y(+2)来表现了图6的神经网络的情况的图。
图10是表示本公开的实施方式中的单词语义信息生成装置的学习处理的流程图。
图11是在本实施方式的比较例的语义向量表中用主成分分析法使分配给单词“アップ”和单词“ダウン”的语义向量退化(简并)为二维的曲线图。
图12是在本实施方式中的语义向量表中用主成分分析法使分配给单词“アップ”和单词“ダウン”的语义向量退化为二维的曲线图。
图13是构成语义信息表的利用形式的第一例的家电设备300的框图的一例。
图14是构成语义信息表的利用形式的第二例的家电系统的框图的一例。
标号说明
101:第一文本语料库
102:第二文本语料库
103:取得部
104:语义信息学习部
105:语义信息管理部
106:语料库生成部
107:语义信息表
108:操作部
110:存储部
120:处理部
130:存储部
201:一般文本语料库
201A、201B、201C、201D:文本语料库
202:反义词文本语料库
202A、202B:文本语料库
203:取得部
204:语义向量学习部
205:语义向量管理部
206:语料库生成部
207:语义向量表
具体实施方式
(成为本公开的基础的见解)
对前述的现有技术涉及的单词分配多维度的向量的方式是基于在自然语言处理技术领域中被称为分布假设的原理的方式。所谓分布假设是指具有相似的语义的单词被使用在相同的上下文中这一原理。换句话说,是指在具有相似的语义的单词的前后会出现同样的单词这一原理。例如,在非专利文献1中指出了:一般而言,具有反义词的关系的单词间往往上下文相似,即前后的单词串一致或者相似。
例如,日语中所谓的“上がる”(提高)这一单词和“アップする”(提高)这一单词,分别在构成如“ボーナス/が/上がる/と/うれしい”(奖金提高的话会很高兴)、“ボーナス/が/アップする/と/うれしい”(奖金提高的话会很高兴)这样的句子时使用,“ボーナス/が”(奖金)、“と/うれしい”(高兴)这样的前后的单词串是共同的。在基于分布假设的现有技术中,对单词分配多维度的向量时,在文本语料库中前后的上下文相似的单词彼此被分配了值接近的向量。其结果是,基于分布假设的现有技术能够将单词转换为多维度的向量,用所得到的多维度的向量是否相似来判定单词的语义是否相似。
但是,基于分布假设的现有技术存在对于具有互相相反的语义的反义词也会分配了值接近的向量这一问题。例如,“上涨”、“下跌”这样的单词会出现在“股价/会/上涨/吧”、“股价/会/下跌/吧”这样的句子中,因此,如“股价/会”、“吧”这样,前后的上下文是共同的。因此,当按照分布假设的“具有相似语义的单词被使用在相同的上下文中”这一原理时,会导致“上涨”、“下跌”这样的反义词也被判断为具有相似语义的单词。
另一方面,存在公开了用于区别反义词的语义的方法的现有技术(专利文献1)。该现有技术的前提是构成了如下的概念基础,即预先用多个属性值的组合来表现单词的语义。对于在该概念基础中存在反义词关系的单词,通过预先设定属性值以使得在某属性值的情况下其值不同,从而存在反义词关系的单词彼此被区别开来。例如,对于“上游”、“下游”这样的反义词,通过使之具有“高度”这样的属性值,对于“上游”,对“高度”的属性值分配正的数值,对于“下游”,对“高度”的属性值分配负的数值,由此表现出“上游”和“下游”为反义词关系。
但是,专利文献1仅停留在如下记载:要设定属性值以使得反义词彼此的值不同,需通过人工的操作记述属性值,或者通过适当的学习方式从文本语料库等语言资源数据进行学习。因此,专利文献1并没有公开设定属性值以使得对于反义词来说其属性值不同的具体学习方式。
另外,非专利文献1仅停留在指出了会出现反义词的上下文是相似的,但完全没有明示用于解决基于分布假设的现有技术的上述问题的具体方法。
这样,根据现有技术,存在通过从文本语料库的学习无法对反义词分配能适当地区别语义的语义信息这一问题。
为了解决这种问题,本公开涉及的方法包括:取得包含第一文本数据和第二文本数据的第一文本语料库,所述第一文本数据包含第一单词、且是用自然语言来记述的第一文章的文本数据,所述第二文本数据包含应与所述第一单词区别语义的第二单词、且是第二单词分布与第一单词分布相似的第二文章的文本数据,所述第二单词分布表示所述第二文章中在所述第二单词之前以及之后的预定范围内出现的单词的种类和出现个数,所述第一单词分布表示所述第一文章中在所述第一单词之前以及之后的所述预定范围内出现的单词的种类和出现个数;
取得包含第三文本数据的第二文本语料库,所述第三文本数据包含作为与所述第一单词和所述第二单词中的至少一方相同的单词的第三单词、且是第三单词分布与所述第一单词分布不相似的第三文章的文本数据,所述第三单词分布表示所述第三文章中在所述第三单词之前以及之后的所述预定范围内出现的单词的种类和出现个数;
基于所述第一文本语料库和所述第二文本语料库中的单词串的排列,通过对所述第一单词分配在预定维度的向量空间中表示所述第一单词的语义的第一向量,并对所述第二单词分配在所述向量空间中表示所述第二单词的语义的第二向量,进行学习;
对所述第一向量以与所述第一单词相关联的方式进行存储,对在所述向量空间中与所述第一向量相距预定以上的距离的所述第二向量以与所述第二单词相关联的方式进行存储。
由此,通过从文本语料库的学习,能够实现能将某单词和应与该单词区别语义的另一单词加以区别的语义信息的分配。
更具体而言,能取得反映了实际的单词的使用方法的第一文本语料库、和以应区别语义的单词的周围的单词串不相似的方式所作成的第二文本语料库。并且,从两个文本语料库生成作为单词的语义信息的向量,因此在不同的上下文中使用应区别语义的单词这一信息被反映到单词的语义信息的学习中。其结果是,能够解决应区别语义的单词的语义相似这一现有技术的问题。
另外,对第一单词分配了用预定维数的向量表现的语义信息,因此例如能够使用向量间的距离适当地判断第一单词彼此的相似度。
另外,也可以为,所述第二文本语料库包含所述第三单词和第四单词,所述第四单词是在自然语言的文本数据中不出现的人为创造的单词,在所述第三文本数据中,所述第三单词之前以及之后的所述预定范围内所包含的单词是所述第四单词。
由此,成为在第二文本语料库中包含人工的单词,能够排除对文本语料库中的自然语言的单词分配语义信息时的不良影响。当用自然语言的某一个单词替换第三单词周围的单词时,有可能对于该一个单词的语义信息会受到第二文本语料库中的上下文的影响,会分配了与原本应分配的语义信息不同的语义信息。因此,在本技术方案中,通过将第三单词周围的单词替换为第四单词,能够解决上述的问题。
也可以为,所述第一文本数据和所述第二文本数据由第一语言的单词构成,在所述第三文本数据中,所述第三单词是所述第一语言的单词,所述第三单词之前以及之后的所述预定范围内所包含的单词是与所述第一语言不同的第二语言的单词。
另外,也可以为,所述第二单词是与所述第一单词相对的反义词。
由此,能够适当地区别例如“提高”、“降低”这样的反义词。
另外,也可以为,所述第二单词是具有与所述第一单词相同的语义、且程度与该第一单词不同的单词。
由此,能够适当地区别例如“good”“better”、“best”这样的语义相同且程度不同的单词。
另外,也可以为,所述第二单词是属于与所述第一单词相同的概念、且属性与该第一单词不同的单词。
由此,能够适当地区别例如属于“颜色”这一相同概念的“红”、“蓝”、“绿”这样的属性不同的单词。
另外,也可以为,所述学习使用神经网络来进行。
由此,通过使用神经网络使第一文本语料库和第二文本语料库进行学习,以适当地区别第一单词和第二单词的方式进行语义信息的分配。
另外,也可以为,所述学习使用潜在语义索引来进行。
由此,通过使用潜在语义索引使第一文本语料库和第二文本语料库进行学习,能够以适当地区别第一单词和第二单词的方式进行语义信息的分配。
另外,也可以为,所述学习使用概率语义索引来进行。
由此,通过使用概率语义索引使第一文本语料库和第二文本语料库进行学习,能够以适当地区别第一单词和第二单词的方式进行语义信息的分配。
另外,也可以为,所述预定维度的向量空间将在所述第一文本语料库和所述第二文本语料库中出现的不同词的数量作为维数。
根据该构成,语义信息用具有在第一文本语料库和第二文本语料库中出现的不同词数的维度的向量来表示,因此种类不同的各单词能够用例如1-of-K形式的向量来表现,能用适于学习的符号串来表示。
另外,也可以为,所述第一文本语料库包含在操作设备的指示中使用的自然语言的文本数据,所述第三单词是与所述设备的操作内容有关的单词。
由此,能够适当地区别对例如“请提高温度”和“请降低温度”、“请打开卧室空调”和“请打开起居室空调”这样的单词串相似而语义不同的设备的指示,能够防止设备的错误操作。
另外,也可以为,所述第一文本语料库包含医疗诊断中在患者症状说明中使用的自然语言的文本数据,所述第三单词是与身体的状态有关的单词。
由此,能够适当地区别例如“从三天前开始头痛”、“从三天前开始头晕”这样单词串相似而语义完全不同的症状的说明,能够防止进行错误的诊断。
另外,也可以为,所述第一文本语料库包含医疗诊断中在症状说明或对该症状的处置中使用的自然语言的文本数据,所述第三单词是与身体的部位有关的单词。
由此,能够适当地区别例如“从三天前开始右手痛”和“从三天前开始肚子痛”、或者“请对头部进行冷敷”和“请对左脚进行冷敷”这样单词串相似、而语义完全不同的症状说明或处置说明,能够防止错误的诊断或者提示错误的处置。
另外,也可以为,所述第一文本语料库包含医疗诊断中在对症状的处置的说明中使用的自然语言的文本数据,所述第三单词是与处置内容有关的单词。
由此,能够适当地区别例如“请对患部进行温敷”和“请对患部进行冷敷”这样单词串相似、而语义完全不同的处置说明,能够防止提示错误的处置。
另外,本公开不仅可以作为执行如以上这样的特征性处理的单词语义信息生成方法来实现,还可以作为具备用于执行单词语义信息生成方法所包含的特征性步骤的处理部的单词语义信息生成装置等来实现。另外,也能够作为使计算机执行这样的单词语义信息生成方法所包含的特征性的各步骤的计算机程序来实现。并且,当然能够使这种计算机程序通过CD-ROM等的计算机可读取的非暂时性的记录介质或者互联网等通信网络来流通。
以下,参照附图对本公开的实施方式进行说明。
再有,以下说明的实施方式均表示本公开的一具体例。以下的实施方式中示出的数值、形状、构成要素、步骤、步骤的顺序等为一例,并不是意在限定本公开。另外,对于以下的实施方式中的构成要素之中表示最上位概念的独立权利要求中未记载的构成要素,作为任意的构成要素来说明。另外,也可以在所有的实施方式中组合各个内容。
(实施方式)
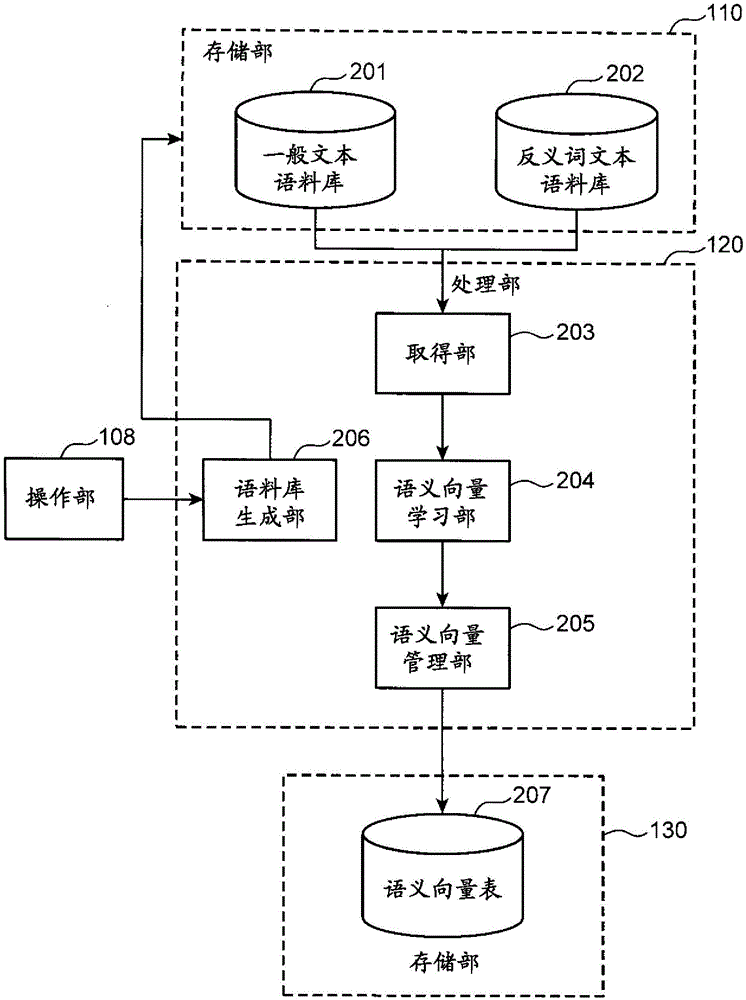
图1是表示本公开的一实施方式中的单词语义信息生成装置的结构的一例的框图。单词语义信息生成装置例如由计算机构成,具备存储部110、处理部120、存储部130以及操作部108。存储部110、130由例如硬盘驱动器、固态硬盘等可改写的非易失性的存储器构成。存储部110具备第一文本语料库101和第二文本语料库102。存储部130具备语义信息表107。
处理部120由例如CPU、ASIC(专用集成电路)、FPGA(现场可编程门阵列)等处理器构成,具备取得部103、语义信息学习部104、语义信息管理部105以及语料库生成部106。操作部108例如由键盘以及鼠标等输入装置和显示信息的显示装置构成。
再者,存储部110、处理部120以及存储部130具备的各块可通过CPU执行使计算机作为单词语义信息生成装置发挥作用的程序来实现。
第一文本语料库101是积累了多个包含作为语义信息的生成对象的单词的预定单位的文本数据(例如,将一个句子作为一个单位的文本数据)的文本语料库。各文本数据在以单词为单位分割的状态下被记录到第一文本语料库101中。在此,所谓一个句子,例如是指由句号(例如,如果是英语,则为“句点(period)”,如果是日语,则为“○”)划分而得到的单词串。
第一文本语料库101是积累了多个出现具有预定语义的单词(以下记述为“第一单词”)的一个以上的文本数据、和出现相对于第一单词要区别语义的单词(以下记述为“第二单词”)的一个以上的文本数据的文本语料库。
第二文本语料库102是积累了多个出现与第一单词和第二单词中的至少一方相同的单词(以下记述为“第三单词”)的一个以上的文本数据的文本语料库。
在第二文本语料库102中,出现第三单词的文本数据既可以是自然语言的文本数据,也可以是包含在自然语言中不出现的人为创造的单词(以下记述为“第四单词”)的文本数据。在使用第四单词的情况下,包含第三单词的文本数据构成为第三单词周围(周边)的单词串的分布与在第一文本语料库101所包含的文本数据中出现的第一单词或第二单词周围的单词串的分布不同即可。在此,“单词周围的单词串的分布”是指在对象单词的前后的预定范围内出现的单词的种类以及出现个数。例如,在作为日语的“音量を上げて下さい”(请提高音量)这样的语句中,对象单词“上げ”的前后两个单词量的单词串的分布为:“音量”为1个、“を”为1个、“て”为1个、“下さい”为1个。再者,对象单词的前后的预定范围,既可以设定为如包含1篇文章的全部数量,也可以设定为包含文章的一部分的预定数量(例如3个单词)。另外,作为“单词串的分布”,除了所出现的单词的种类以及出现个数之外,还可以考虑单词的出现顺序。这样地通过在文本数据中包含第四单词,能够排除对文本语料库中的自然语言的单词分配语义信息时的不良影响。
例如,当用自然语言的某一个单词替换了第三单词周围的单词时,有可能对于该一个单词的语义信息会受到第二文本语料库102中的上下文的影响,会对该一个单词分配与原本应分配的语义信息不同的语义信息。因此,在本公开中,将第三单词周围的单词替换为第四单词。
在此,作为第四单词,例如可采用如“#”、“!”、“””、“$”、“&”这样的自然语言中不会出现的符号或组合了这些符号的符号串。当作为第四单词而一律采用相同的符号串时,有可能会在第三单词彼此之间分配相似的语义信息。因此,作为第四单词,例如,可以按构成第二文本语料库102的每个文本数据而采用不同的符号或者符号串,也可以按作为替换对象的每个单词而采用不同的符号或者符号串,还可以在对象单词相似的单词彼此之间采用相同的符号或者符号串。
另外,在第二文本语料库102中,第二文本语料库102所包含的文本数据也可以包括第三单词周围的单词串与第一单词周围的单词串不同的自然语言的文本数据。例如,假设“エアコンを入れると涼しい”(打开空调的话会凉快)这样的文本数据包含在第一文本语料库101中。在该情况下,相对于“入れる”(打开)的反义词即“切る”(关闭),如“エアコンを切ると暑い”(关闭空调的话会热)那样,第二文本语料库102包括在“切る”(关闭)的周围具有“涼しい”(凉快)的反义词即“暑い”(热)的上下文的文本数据即可。
另外,例如,在第一文本语料库101、第二文本语料库102包括预定的第一语言(例如日语)的情况下,第三单词周围的单词串也可以由与第一语言不同的第二语言(例如英语)构成。例如,当“エアコンを入れると涼しい”(打开空调的话会凉快)这样的文本语料库包含在第一文本语料库101中时,第二文本语料库102可以包括用“APPLE/APPLE”替换了“エアコン/を”、用“APPLE/APPLE”替换了“と/涼しい”的文本数据“APPLE/APPLE/入れる/APPLE/APPLE”。
另外,作为第一文本语料库101所包含的第二单词和第二文本语料库102所包含的第三单词的例子,可列举出(1)第一文本语料库101所包含的第一单词的反义词、(2)具有与第一文本语料库101所包含的第一单词相同的语义且程度不同的单词、(3)属于与第一文本语料库101所包含的第一单词相同的概念且属性不同的单词等。
在为反义词的情况下,能够区别为例如“提高”、“降低”这样的反义词。另外,在为具有相同的语义且程度不同的单词的情况下,能够区别为例如“good”(好)、“better”(更好)、“best”(最好)这样的相同的语义、且程度不同的单词。另外,在为属于相同的概念且属性不同的单词的情况下,能够区别为例如属于“颜色”这一相同概念的“红”、“蓝”、“绿”这样的属性不同的单词。
取得部103取得第一文本语料库101和第二文本语料库102。在此,如果存储部110由本地的存储装置构成,则取得部103从存储部110读出第一文本语料库101、第二文本语料库102即可。另外,如果存储部110由经由通信网络而连接的外部的存储装置构成,则取得部103经由通信网络对存储部110进行访问来取得第一文本语料库101、第二文本语料库102即可。
语义信息学习部104进行如下学习:将在第一文本语料库101和第二文本语料库102所包含的文本数据中出现的单词作为对象单词,对在该对象单词的前后的预定范围内出现的单词串的分布相似的单词,以语义接近的方式分配语义信息。
在此,分配给对象单词的语义信息表现为能够通过预定维数的语义向量来区别即可。由此,例如,可以使用语义向量间的距离来适当地判断单词彼此的相似度。
对于该语义向量,例如将在第一文本语料库101、第二文本语料库102中出现的不同词数作为维数即可。由此,种类不同的各单词例如能够用1-of-K形式的向量来表现,用适于学习的符号串来表示。
再者,语义信息也可以不是预定维度的向量空间中的向量,而作为与向量的终点相当的点的坐标信息来表现。
另外,语义信息也可以用能够计算表示单词彼此的语义相似到哪种程度的相似度的预定形式来表现。作为能够计算相似度的预定形式,例如,既可以采用上述的语义向量,也可以采用从向量空间内的某基准点(例如原点)到各语义向量的顶端为止的距离。在采用该距离的情况下,从基准点起位于同一距离的单词彼此间不能区别,但距基准点的距离不同的单词彼此间能够区别。另外,在该情况下,相似度用标量表示,因此能减轻计算单词彼此间的相似度时的处理负担。
另外,对于语义信息学习部104,作为学习,采用神经网络、潜在语义索引(latent semantic analysis indexing)或者概率语义索引等即可。
语义信息管理部105管理语义信息表107,该语义信息表107表示由语义信息学习部104进行的学习的结果、即对对象单词的语义信息的分配状态。再者,“对象单词”是指成为语义信息的分配对象的单词,包含第一单词和第三单词。另外,第四单词既可以设为对象单词,也可以不设为对象单词。
语义信息表107是用表形式存储各单词与分配给各单词的语义信息的对应关系的数据。
语料库生成部106使用第一文本语料库101生成第二文本语料库102。在此,第二文本语料库102既可以人工地生成,也可以自动地生成。在人工地生成的情况下,语料库生成部106基于操作部108受理的操作员的操作来生成第二文本语料库102即可。在该情况下,操作员通过输入例如一句一句地编辑第一文本语料库的操作,使语料库生成部106生成第二文本语料库102即可。
另外,在自动地生成的情况下,语料库生成部106在构成第一文本语料库101的文本数据中将语义存在预定关系的单词对作为第一单词、第三单词来抽取。然后,语料库生成部106用预定的单词替换在抽取出的第一单词的前后的预定范围内出现的单词串,并且,用预定的单词替换在第三单词的前后的预定范围内出现的单词串,并存储在第二文本语料库102中。在此,作为预定的单词,可采用上述的第四单词或者第二语言的单词。此时,语料库生成部106针对包含第一单词的文本数据、和包含与该第一单词成对的第三单词的文本数据,使用不同的预定的单词进行所述替换即可。另外,在抽取语义具有预定关系的第一单词、第三单词时,语料库生成部106使用事先登记了单词彼此的对应关系的对应表即可。对于该对应表,例如作为第三单词,如果采用反义词,则事先登记如“暑い”(热)-“涼しい”(凉)这样的反义词的对应关系即可。另外,语料库生成部106也可以对于包含第一单词的文本数据不进行单词的替换。
以下,以第二文本语料库102所包含的单词为第一文本语料库101所包含的单词的反义词的情况为例进行说明。
图2是表示第二文本语料库102所包含的单词为第一文本语料库101所包含的单词的反义词的情况下的单词语义信息生成装置的结构的一例的框图。再有,在图2中,对于与图1相同的结构标记同一标号,并省略说明。
在图2中,一般文本语料库201是积累了多个包含作为语义信息的生成对象的单词的预定单位的文本数据(例如,将一个句子作为一个单位的文本数据)的文本语料库。各文本数据在以单词为单位分割了的状态进行记录。
图3是表示作为一般文本语料库201而采用的文本语料库201A、201B的例子的图。在图3中,文本语料库201A是日语的一般文本语料库201的例子。日语大体上是用没有划分单词的文字串来记述的情况,但可通过词素分析软件(例如MeCab)从没有划分单词的文字串数据得到以单词为单位分割的单词串数据。在图3的例子中,文本语料库201A所包含的文本数据的单位被设为以一句为单位。文本语料库201A中的多个文本数据分别根据识别码(图3的ID)来识别。另外,文本语料库201A按出现顺序存储构成各文本数据的单词。文本数据中的各单词根据索引(index)信息(图3的W1~W6···)来识别。
在图3中,文本语料库201B是英语的一般文本语料库201的例子。英语大体上是用由空格符明示了单词的划分的文字串来记述的情况,因此以空格符为边界分割文字串,可得到单词串数据。文本语料库201B与文本语料库201A同样地,文本数据的单位设为以一句为单位,用识别信息(图3的ID)识别文本数据。另外,文本语料库201B与文本语料库201A同样地,文本数据中的各单词根据索引信息(图3的W1~W5···)来识别。
图4是表示作为一般文本语料库201而采用的包含存在反义词关系的单词的文本语料库201C、201D的例子的图。文本语料库201C为日语的文本语料库的例子,包含有出现“上げ”(提高)的文本数据、和出现作为“上げ”的反义词的“下げ”(降低)的文本数据。另外,在文本语料库201C中包含有出现“アップ”(提高)的文本数据、和出现作为“アップ”的反义词的“ダウン”(降低)的文本数据。
在该例中,“上げ”、“下げ”这些单词的前后出现的单词串共同为“音量/を”、“て/下さい”,“アップ”、“ダウン”这些单词的前后出现的单词串共同为“温度/を”、“し/て/欲しい”。如在非专利文献1中所指出的那样,一般而言,关于反义词,往往反义词出现的上下文相似,即前后的单词串一致或者相似。
文本语料库201D为英语的文本语料库的例子,包含有出现“increase”的文本数据、和出现作为“increase”的反义词的“decrease”的文本数据。另外,文本语料库201D包含有出现“raise”的文本数据、和出现作为“raise”的反义词的“lower”的文本数据。在该例中,“increase”、“decrease”这些单词的前后出现的单词串共同为“Please”、“the/volume”,“Please”、“raise”、“lower”这写单词的前后出现的单词串共同为“Please”、“the/temperature”。
这样,出现反义词的上下文相似这一现象是在日语以外的英语或其他语言中也能共同地看到的现象。
在图2中,反义词文本语料库202是积累了包含一般文本语料库201所包含的存在反义词关系的单词的至少一方的预定单位的文本数据(例如,将一句作为一个单位的文本数据)的文本语料库。反义词文本语料库202与一般文本语料库201是同样的,各文本数据以单词为单位来分割记录。
图5是表示存储在反义词文本语料库202中的文本数据的例子的图。在图5中,文本语料库202A是日语的反义词文本语料库202的例子。在文本语料库202A中包含有出现“上げ”的文本数据、和出现作为“上げ”的反义词的“下げ”的文本数据。在出现“上げ”的文本数据中,在“上げ”的前后出现的单词串是“#U1#/#U1#”、“#U1#/#U1#”。即,在图4中,记述为“音量/を/上げ/て/下さい”(请提高音量)的文本数据被替换为“#U1#/#U1#/上げ/#U1#/#U1#”。
另一方面,在“下げ”的前后出现的单词串是“#D1#/#D1#”、“#D1#/#D1#”。即,在图4中,记述为“音量/を/下げ/て/下さい”(请降低音量)的文本数据被替换为“#D1#/#D1#/下げ/#D1#/#D1#”。
在此,“#U1#”、“#D1#”这些单词(符号)是上述的第四单词的一例,是在通常的自然语言的文本中不出现的人为创造的单词。即,“#U1#”、“#D1#”这些单词(符号)是在一般文本语料库201的文本数据中不出现的单词。
使用这种第四单词“#U1#”、“#D1#”,以存在反义词关系的“上げ”和“下げ”的前后的单词串不同的方式作成了文本语料库202A。对于存在反义词关系的“アップ”、“ダウン”,也同样地使用第四单词“#U2#”、“#D2#”,以“アップ”和“ダウン”的前后出现的单词串不同的方式作成了文本语料库202A。因此,当使用文本语料库201A、202A进行学习时,能够以明确地区别反义词的方式分配语义信息。
在图5中,文本语料库202B是在英语的情况下的反义词文本语料库202的例子。在文本语料库202B中包含有出现“increase”的文本数据、和出现作为“increase”的反义词的“decrease”的文本数据。在两个文本数据中,“increase”的前后出现的单词串是“#INC#”、“#INC#/#INC#”。即,在图4中,记述为“Please/increase/the/volume”的文本数据被替换为“#INC#/increase/#INC#/#INC#”。
另一方面,“decrease”的前后出现的单词串是“#DEC#”、“#DEC#/#DEC#”。即,在图4中,记述为“Please/decrease/the/volume”的文本数据被替换为“#DEC#/decrease/#DEC#/#DEC#”。
在此,与文本语料库202A同样地,“#INC#”、“#DEC#”这些单词(符号)是上述的第四单词的一例,是在通常的自然语言的文本中不出现的人为创造的单词。
使用这种第四单词“#INC#”、“#DEC#”,以存在反义词关系的“increase”、“decrease”的前后的单词串不同的方式作成了文本语料库202B。关于存在反义词关系的“raise”、“lower”,也同样地使用第四单词“#UP#”、“#DW#”,以“raise”、“lower的前后出现的单词不同的方式生成了文本语料库202B。因此,当使用文本语料库201B、202B进行学习时,能够以明确地区别反义词的方式分配语义信息。
再者,在图5中,用第四单词替换了相对于对象单词在之前以及之后出现的一个或两个单词,但本公开并不限定于此,也可以用第四单词替换在紧挨着对象单词的之前以及之后出现的三个以上的单词。另外,用第四单词替换的紧挨着的之前之后的单词数也可以与一般文本语料库201中的对象单词的紧挨着的之前之后的单词数不一致。例如,在文本语料库202B中,记载了紧挨着“increase”、“decrease”之前的单词仅被替换一个的例子,但也可以用两个以上或者一个以下的第四单词来替换。
另外,在文本语料库202B中,紧挨着“increase”、“decrease”之前的单词仅被替换一个的原因是在原来的文本数据中紧挨着“increase”、“decrease”之前只有一个单词。如果在紧挨着“increase”、“decrease”之前有两个以上的单词,则用第四单词替换紧挨着的之前的两个单词。
另外,在图5的例子中,在一个文本数据中使用了相同的第四单词,但其为一例,也可以按成为替换对象的每个单词而使用不同的第四单词。
在图2中,取得部203取得一般文本语料库201和反义词文本语料库202。
在图2中,语义向量学习部204(语义信息学习部的一例)使用一般文本语料库201所包含的文本数据和反义词文本语料库202所包含的文本数据来进行以下学习:将在文本语料库中出现的单词作为对象单词,对在对象单词的前后的预定范围内出现的单词串的分布相似的单词,以语义接近的方式分配语义向量(语义信息的一例)。语义向量是用一维以上的数值信息表现了单词的语义的向量。
语义向量管理部205(语义信息管理部的一例)管理由语义向量学习部204进行的学习的结果、即表示对对象单词的语义信息的分配状态的语义向量表207(语义信息的一例)。
语料库生成部206与语料库生成部106同样地,从一般文本语料库201生成反义词文本语料库202。
语义向量表207是用表形式存储各单词与相对于各单词的语义向量的对应关系的数据。
对于单词的语义向量的分配采用如下原理:对于具有相似的上下文的单词、即对于出现前后相似的单词串的单词分配值相似的语义向量。基于这种原理进行语义向量的学习的方式能够使用非专利文献2、3所公开的方式来实现。
在本实施方式中,设为使用非专利文献3的方式向单词分配语义向量。在此,对非专利文献3的方式的概要进行说明。首先,语义向量学习部204如式(1)所示,将成为学习数据的各文本数据表达式化为包括单词数T(T为1以上的整数)的单词串W。具体而言,语义向量学习部204抽取在构成一般文本语料库201的所有文本数据以及反义词文本语料库202所包含的所有文本数据中出现的所有单词,将各单词替换为后述的1-of―K形式的向量表现后,将各文本数据表达式化为作为1-of-K的串的单词串W。
W=ω1,ω2,ω3,…,ωT (1)
学习的目的在于使由式(2)定义的值最大化。
式(2)表示针对单词串W的所有单词将在位于单词串W的第t个的单词wt的前后出现的c(c为1以上的整数)个单词w(t+j)的附条件出现概率的对数和进行平均。j是用于确定在单词wt的前后出现的c个单词的索引,用-c以上、c以下、且0以外的整数来表示。使式(2)最大化意味着:在输入了单词wt时所输出的单词w(t+j)在学习数据中成为相对于单词wt在前后出现的单词的概率高。
在非专利文献3中,式(2)的附条件出现概率的计算使用三层的神经网络进行了模型化。图6是表示在出现概率的计算中使用的神经网络的结构的一例的图。
图6所示的神经网络表示了在式(2)中设为c=2的情况的例子。也就是说,该神经网络是学习以与在单词wt的前后各出现两个的四个单词w(t-2)、w(t-1)、w(t+1)、w(t+2)有关的附条件出现概率被最大化的方式构成神经网络的各层彼此的结合状态。
在图6中,输入层601是输入单词wt的层。例如,假设图7所示的文本数据“今日/の/天気/は/良く/なる/予報/が/出て/いる”中的单词“良く”为单词wt,则与“良く”对应的向量被输入到输入层601。
在此,与单词wt对应的向量采用被称为1-of-K形式的表现形式。所谓的1-of-K形式为如下表现形式:当将学习数据的文本语料库中出现的不同词数设为K个时,在排列了K个单词时,对第t(t为K以下的整数)个单词,仅K维向量的第t个维度分配“1”,其他维度分配“0”。
通常,大规模(size)的文本语料库被设为学习数据,因此不同词数成为数万~数十万,单词wt用数万~数十万维度的向量来表示。例如,在为日语的报刊报道的情况下,不同词数约不足20万,因此在报刊报道被设为学习数据的情况下,单词wt用约20万维度的向量来表示。再者,假如单词wt用K维度的向量来表示,则输入层601由K个节点构成。
图8是表示用1-of-K形式的向量来表示的单词wt的一例的图。在图8的例子中,单词“天気”、“は”、“良く”、“なる”、“予報”用1-of-K形式的向量来表示。例如,假如单词“天気”是作为学习数据的K个单词之中排列在第t个的单词,仅对第t个维度分配“1”,对其他维度分配“0”。另外,单词“は”是排列在单词“天気”的后面的单词,因此仅对第t+1个维度分配“1”,对其他维度分配“0”。其他单词也同样地用1-of-K形式的向量来表示。这样地,各单词以“1”的出现位置不同的方式分配了向量,因此语义向量学习部204能够根据“1”出现的位置来区别单词。再者,K个单词的排列方法并不特别地限定,既可以是文本语料库中的单词的出现顺序,也可以是随机顺序。
在图6中,隐藏层602是对被输入到输入层601的向量的各要素进行加权线性组合、将所得到的标量值用激活函数(activation function)进行了转换而得到的向量的层。
隐藏层602的向量的维数可以设定为任意的维数,但通常设定为比输入层601的向量的维数(K维)小的维数。在非专利文献3中,作为隐藏层602的向量的维数,设定200维度作为默认的维数。
在图6中,输出层603A、603B、603C、603D分别是对隐藏层602的向量的各要素进行加权线性组合、将所得到的标量值用Softmax函数进行转换而得到的向量的层。在此,输出层603A、603B、603C、603D分别表示单词w(t-2)、w(t-1)、w(t+1)、w(t+2)的出现概率分布。在文本语料库所包含的不同词数为K个的情况下,输出层603A、603B、603C、603D的向量分别为K维,第k个维度的值表示第k个单词wk的出现概率。
将输入层601的向量设为X,将隐藏层602的向量设为H,将输出层603A、603B、603C、603D的向量设为Y(-2)、Y(-1)、Y(+1)、Y(+2)。从向量X得到向量H的式子由式(3)表示,从向量H得到向量Y(-2)、Y(-1)、Y(+1)、Y(+2)的第i个要素的式子由式(4)表示。
H=WXH·X (3)
式(3)的WXH是表示对向量X的各要素进行加权线性组合时的权重的矩阵。式(4)的向量Ii、Ik分别是仅对第i个、第k个维度分配了“1”、对其他维度分配了“0”的K维的向量。
式(4)的权重矩阵W(j)HY是表示对向量H进行加权线性组合时的权重的矩阵。式(4)的分子表示将用权重矩阵W(j)HY的第i行的向量对向量H进行了线性组合而得到的值作为自变量的指数函数值。式(4)的分母是将用权重矩阵W(j)HY的第1行到第K行的各向量对向量H分别进行了线性组合而得到的值作为自变量的指数函数值的和。
图9是使用向量X、H、Y(-2)、Y(-1)、Y(+1)、Y(+2)表现了图6的神经网络的情况的图。使用这样被表达式化的神经网络,语义向量学习部204将在文本语料库所包含的文本数据中出现的单词wt作为输入教师信号(教授信号),将单词w(t+j)(-c≤j≤c,j≠0)作为输出教师信号,通过误差反向传播学习来决定表示权重的矩阵的值。
在采用非专利文献3的方法构成了语义向量学习部204的情况下,采用权重矩阵WXH作为语义向量表207。当用1-of-K形式的向量表示各单词时,由式(3)所示的权重矩阵WXH用S行×K列的矩阵来表示。再者,S是隐藏层602的向量的维数。
权重矩阵WXH的第j列是用1-of-K形式表现的向量,表示第j维度为1的单词的语义向量。因此,除了权重矩阵WXH之外,语义向量表207也可以包含表示分配给权重矩阵WXH的各列的单词的对应关系的表。
再者,在使用了误差反向传播学习的学习阶段中,权重矩阵W(-2)HY、W(-1)HY、W(+1)HY、W(+1)HY是必需的,但如果学习阶段结束,则不需要这些权重矩阵。因而,在利用语义向量表207的利用阶段中仅使用权重矩阵WXH。
图10是表示本公开的实施方式中的单词语义信息生成装置的学习处理的流程图。
首先,语义向量学习部204使用随机值将神经网络的权重矩阵WXH、WHY进行初始化(步骤S101)。接着,语义向量学习部204判定由误差反向传播学习得到的权重矩阵WXH、WHY的值的变化是否低于预定的阈值时、学习是否已收敛(步骤S102)。在判定为学习已收敛的情况下(在S102中为“是”),语义向量学习部204结束学习处理。如果权重矩阵WXH、WHY未低于预定的阈值,则语义向量学习部204判定为学习没有收敛(在步骤S102中为“否”),使处理进入步骤S103。
接着,取得部203从学习对象的文本语料库取出一个文本数据(步骤S103)。在此,学习对象的文本语料库是一般文本语料库201和反义词文本语料库202。因此,取得部203从两个文本语料库之中取出任一个文本数据即可。
接着,语义向量学习部204将所取出的一个文本数据所包含的某一个单词wt作为输入教师信号,将单词wt前后的j个单词w(t+j)(-c≤j≤c,j≠0)作为输出教师信号,使用误差反向传播学习使权重矩阵WXH、WHY的值变化(步骤S104),使处理返回到步骤S102。
也就是说,语义向量学习部204从学习对象的文本语料库中逐一地取出文本数据,直到权重矩阵WXH、WHY的值的变化低于阈值为止。再者,如果将学习对象的文本语料库所包含的文本数据全部取出,学习也没有收敛,则取得部203再次从第一个文本数据依次地取出文本数据即可。也就是说,在学习处理中,从学习对象的文本语料库之中循环地取出文本数据,使权重矩阵WXH、WHY的值收敛。
按照以上的说明,语义向量学习部204将文本语料库中的文本数据作为教师信号,将某单词作为输入,修正神经网络的权重矩阵以使得该单词的前后的单词的出现概率变高,学习对单词分配的语义向量。由此,必然地在文本语料库所包含的多个单词中,前后的单词串相似的单词彼此间的所学习的语义向量也相似。其原因是,具有相同语义的单词进行基于在相似的上下文中出现这一分布假设的学习。
但是,在现实的自然语言的文本中,往往反义词也伴随如相似的上下文而出现。如图4所示的文本语料库201C、201D的例子中可以看到的那样,存在反义词的关系的单词彼此的上下文往往是前后的单词串一致或者相似。因而,当将通常收集到的文本语料库作为学习数据进行基于分布假设的学习时,分配给存在反义词的关系的单词彼此的语义向量将会相似,难以明确地区别两者。
图11是在本实施方式的比较例的语义向量表中使用主成分分析法使分配给单词“アップ”(上升)和单词“ダウン”(下降)的语义向量退化为二维的坐标图。该比较例的语义向量表是通过以下方法获得的:针对将日语版的Wikipedia(维基百科)进行词素分析而生成的文本语料库,实施基于分布假设的学习。如图11所示可知,单词“アップ”和单词“ダウン”配置在靠近的位置,分配了非常接近的语义向量。
图12是在本实施方式中的语义向量表207中使用主成分分析法使分配给单词“アップ”和单词“ダウン”的语义向量退化为二维的曲线图。在图12中,使用从日语版的Wikipedia生成的文本语料库来作为一般文本语料库201。另外,对于包含单词“アップ”和单词“ダウン”的反义词,使用以如图5的202A所示那样的反义词的上下文不同的方式生成的文本语料库来作为反义词文本语料库202。并且,对两个文本语料库实施基于分布假设的学习,生成了语义向量表207。
也就是说,在语义向量表207中,表示第一单词的语义的第一向量和第一单词被相关联地存储,并且,在向量空间中与第一向量相距预定以上的距离的第二向量和第二单词被相关联地存储。
如图12所示可知,单词“アップ”和单词“ダウン”与图11相比大幅度分离地配置,分配了明显不同的语义向量。
这样,在本实施方式的单词语义信息生成装置中,除了通常的一般文本语料库201之外,还使用了以具有反义词的关系的单词彼此的上下文不同的方式生成的反义词文本语料库202。并且,对两个文本语料库实施了基于分布假设的学习,因此能够以具有反义词的关系的单词彼此被适当地区别的方式对各单词分配语义向量。
以上,使用区别某单词及其反义词的例子来说明了本公开。本公开此外还可以应用于如以下所述的具体事例。
(1)例如,第一文本语料库101可以构成为包含在操作设备的指示中使用的自然语言的文本数据,第二文本语料库102可以构成为包含与设备的操作内容有关的单词来作为第三单词。通过这样,能够适当地区别例如“请提高温度”和“请降低温度”、“请打开卧室的空调”和“请打开起居室的空调”这样的单词串相似而语义不同的指示,能够防止设备的错误操作。
(2)另外,第一文本语料库101可以构成为包含医疗诊断中在患者症状说明中使用的自然语言的文本数据,第二文本语料库102可以构成为包含与身体的状态有关的单词来作为第三单词。通过这样,能够适当地区别例如“从三天前开始头痛”、“从三天前开始头晕”这样的单词串相似而语义完全不同的症状的说明,能够防止进行错误的诊断。
(3)另外,第一文本语料库101可以构成为包含医疗诊断中在症状的说明或对该症状的处置中使用的自然语言的文本数据,第二文本语料库102可以构成为包含与身体的部位有关的单词来作为第三单词。通过这样,能适当地区别例如“从三天前开始右手痛”和“从三天前开始肚子痛”、或者“请对头部进行冷敷”和“请对左脚进行冷敷”这样的单词串相似、而语义完全不同的症状的说明或处置的说明,能够防止错误的诊断或者提示错误的处置。
(4)另外,第一文本语料库101可以构成为包含医疗诊断中在对症状的处置的说明中使用的自然语言的文本数据,第二文本语料库102可以构成为包含与处置内容有关的单词来作为第三单词。通过这样,能够适当地区别例如“请对患部进行温敷”和“请对患部进行冷敷”这样的单词串相似、而语义完全不同的处置的说明,能够防止提示错误的处置。
接着,对在上述的学习中所作成的语义信息表的利用方式进行说明。图13是构成语义信息表的利用方式的第一例的家电设备300的框图的一例。
家电设备300包括电视机、录音机、音响装置、洗衣机、空调机、冰箱、照明装置这样的各种家电设备。
家电设备300具备语义信息表301、麦克风302、语音处理部303、解析部304、指令生成部305以及指令执行部306。语义信息表301是通过对图1所示的第一文本语料库101、第二文本语料库102实施上述的学习而作成的表,相当于图1的语义信息表107。
麦克风302是将语音转换为电语音信号的装置,用于对用户的语音进行收音。语音处理部303解析从麦克风302输出的语音信号,生成表示用户发出的语音的文本数据。解析部304使用语义信息表301解析由语音处理部303所生成的文本数据。在此,解析部304通过参照语义信息表301来决定构成所输入的文本数据的各单词的语义信息。然后,解析部304根据所决定出的各单词的语义信息来判定用户的发声内容是否为与对家电设备300的操作有关的内容。然后,如果用户的发声内容为与对家电设备300的操作有关的内容,则解析部304将表示该操作的操作信息输出到指令生成部305。
指令生成部305生成用于执行所输入的操作信息表示的操作的指令,并向指令执行部306输出。指令执行部306执行所输入的指令。由此,家电设备300能够使用语义信息表301适当地识别用户说出的操作内容。
图14是构成语义信息表的利用方式的第二例的家电系统的框图的一例。该家电系统是使存在于云上的服务器500担负语音识别的功能、通过语音操作家电设备400的系统。
家电设备400和服务器500经由例如互联网等公共通信网络相连接。
家电设备400与用图13说明的家电设备300相同。但是,在第二例中,家电设备400不进行语音识别,因此语义信息表501、语音处理部502、解析部503以及指令生成部504设置在服务器500中。
麦克风401与图13的麦克风302相同。信号处理部402判定从麦克风401输入的语音信号是否为噪声,在不是噪声的情况下,将该语音信号向通信部404输出。通信部404将所输入的语音信号转换为具有可通信的格式的通信信号,并向服务器500发送。
服务器500的通信部505接收来自家电设备400的通信信号,取出语音信号,并输出到语音处理部502。语音处理部502与图13所示的语音处理部303同样地解析所输入的语音信号,生成表示用户发出的语音的文本数据。解析部503与图13所示的解析部304同样地使用语义信息表501来解析由语音处理部502所生成的文本数据,将操作信息输出到指令生成部504。
指令生成部504生成用于执行所输入的操作信息表示的操作的指令,并输出到通信部505。通信部505将所输入的指令转换为具有可通信的格式的通信信号,并向家电设备400发送。
家电设备400的通信部404接收通信信号,从接收到的通信信号中除去报头(header)等,并输出到信号处理部402。信号处理部402在除去了报头的通信信号为家电设备400的指令的情况下,将该指令输出到指令执行部403。指令执行部403执行所输入的指令。
这样,在图14的家电系统中,服务器500能够使用通过上述的学习而生成的语义信息表501来适当地识别用户说出的操作内容,并向家电设备400发送指令。
产业上的可利用性
本公开涉及的单词语义信息生成装置能有效地应用于处理自然语言文本的语义的应用。例如,能够应用于语义相似的句子的检索、说法转换处理、对话系统中的发达文的语义分类等。
- 还没有人留言评论。精彩留言会获得点赞!