呼吸气体诊断系统的领域自适应方法及装置与流程
本发明涉及气体检测训练技术领域,尤其涉及一种呼吸气体诊断系统的领域自适应方法及装置。
背景技术:
传统的疾病诊断和监测手段包括血检、尿检、CT等,其结果较准确,但操作较复杂,有些也是有创检测,会带来疼痛。不少患者因此忽视日常检查,错过了最佳的治疗时间。因此,社迫切需要一种无创和操作简便的常见疾病监测方法。
呼吸气体诊断系统能够通过对患者的呼吸气体进行检测,从而诊断出患者的疾病,具体通过在主设备上采集一系列有配备的标准气体作为标签样本,用于训练预测模型,然后将训练的模型应用到其他所有从设备上,以供从设备的测试样本进行学习,从而获得测试样本的诊断数据。
传统的机器在学习时,假定预测训练域与测试域独立同分布,即不存在个体差异,直接将训练数据集得到的模型直接应用于测试集。但在实际应用中,这种假设很多时候并不成立,例如由于使用不同的设备、在不同时间采集到的气体样本间会存在设备差异和时间漂移,即训练域与测试域分布存在差异,导致传统机器学习的性能较低,导致系统诊断的准确率较低。
技术实现要素:
本发明的主要目的在于提供一种呼吸气体诊断系统的领域自适应方法及装置,旨在缩小训练样本与测试样本由于设备差异和时间漂移导致分布存在的差异,提高系统的学习性能和诊断的准确率。
为实现上述目的,本发明提供的一种呼吸气体诊断系统的领域自适应方法包括以下步骤:
根据第一设备的响应获取对已知病患者及健康者呼吸气体进行采样的数据,按照预定规则从所述数据中提取目标数据作为训练样本;
根据第二设备的响应获取对待测病患者呼吸气体进行采样的数据,按照预定规则从所述数据中提取目标数据作为测试样本;所述训练样本和测试样本共同构成样本空间;所述训练样本的背景特征及测试样本的背景特征构成背景特征空间;
根据kernel trick核戏法、背景特征空间、HSIC独立准则、MIDA最大独立领域适配算法获得第一投影矩阵;
经所述第一投影矩阵将所述样本空间投影到一个高维特征空间,以使所述训练样本及测试样本按照同一特征呈线性分布。
优选地,所述样本空间由多个原始特征向量构成;所述根据kernel trick核戏法、背景特征空间、HSIC独立准则、MIDA最大独立领域适配算法获得第一投影矩阵包括:
用非线性映射函数把所述原始特征向量映射到所述高维特征空间;
定义第二投影矩阵将高维特征空间投影到所述第一投影矩阵,投影后的样本构成子空间;
根据kernel trick核戏法获得非线性映射函数内积的核函数,获得所述子空间中样本与非线性映射函数内积的核函数及所述第一投影矩阵的关系式,进而获得所述子空间中样本内积的核函数;
从所述子空间和背景特征空间中分别抽取独立样本,通过HSIC独立准则使得从所述子空间中样本与背景特征空间中抽取的独立样本之间的独立性最大;并使得所述子空间中样本的方差最大,获得所述第一投影矩阵。
优选地,所述从所述子空间和背景特征空间中分别抽取独立样本,通过HSIC独立准则使得从所述子空间中样本与背景特征空间中抽取的独立样本之间的独立性最大;并使得所述子空间中样本的方差最大,获得所述第一投影矩阵包括:
由所述子空间中样本内积的核函数Kz、所述背景特征空间中样本内积的核函数Kd及HSIC独立准则的经验估计公式获得决定HSIC值的关键因子:
tr(Kz×H×Kd×H)=tr(Kx×W×WT×Kx×H×Kd×H);
由所述子空间中样本Z与非线性映射函数内积的核函数Kx及所述第一投影矩阵W的关系式:Z=Kx×W,计算子空间样本的协方差矩阵:
cov(Z)=WT×Kx×H×Kx×W;
根据HSIC值的关键因子和子空间样本的协方差矩阵,获得MIDA最大独立领域适配算法目标函数:
Y=-tr(WT×Kx×H×Kd×H×Kx×W)+μ×tr(WT×Kx×H×Kx×W)
其中:μ为权重系数,μ>0,Kx为非线性映射函数内积的核函数,W为所述第一投影矩阵,且满足:WT×W=I,H满足:I是单位矩阵,n为样本空间中样本的数量;
在所述MIDA最大独立领域适配算法目标函数的函数值Y最大时,获取与所述函数值Y对应的变量,即获得所述第一投影矩阵W。
优选地,在所述求解所述MIDA最大独立领域适配算法目标函数的函数值Y最大时,获取与所述函数值Y对应的变量,即获得所述第一投影矩阵W包括:
利用拉格朗日乘子法构造中间函数:
tr(WT×Kx×(-H×Kd×H+μ×H)×Kx×W)-tr((WT×W-I)×Λ)
其中Λ为拉格朗日乘子矩阵;
所述中间函数对W的导数为:
Y'=Kx×(-H×Kd×H+μ×H)×Kx×W-W×Λ
在所述中间函数对W的导数值Y’为零时,可得所述第一投影矩阵W是矩阵Kx×(-H×Kd×H+μ×H)×Kx的最大特征值对应的特征向量;
其中所述非线性映射函数内积的核函数Kx为以下线性核函数(k(x,y)=xTy)、多项式(k(x,y)=(σxTy+1)d)或高斯径向基函数中的一个;其中所述σ为核参数,d为核矩阵维度;
所述背景特征空间中样本内积的核函数Kd满足:Kd=DDT,其中,D为背景特征矩阵,若样本i和样本j来自不同设备,则(Kd)ij=0;若来自相同设备,则(Kd)ij=1或1+titj,t为样本的采样时间;
由所述非线性映射函数内积的核函数Kx及所述背景特征空间中样本内积的核函数Kd获得所述第一投影矩阵W。
优选地,当所述训练样本中包含有标签样本时,根据第一设备的响应获取对标准成分及标准含量的气体进行采样的数据,按照预定规则从所述数据中提取目标数据作为所述标签样本;
定义所述训练样本的标签矩阵,获得标签矩阵的核函数Ky:
根据所述HSIC值的关键因子、子空间样本的协方差矩阵、标签矩阵的核函数获得SMIDA半监督最大独立领域适配目标函数:
P=-tr(WT×Kx×(-H×Kd×H+μ×H+γ×H×Ky×H)×Kx×H)
其中:γ为权重系数,γ>0;
在所述SMIDA半监督最大独立领域适配目标函数的函数值P最大时,获取与所述函数值P对应的变量,即所述第一投影矩阵W为矩阵Kx×(-H×Kd×H+μ×H+γ×H×Ky×H)×Kx的最大特征值对应的特征向量;
其中所述非线性映射函数内积的核函数Kx为以下线性核函数(k(x,y)=xTy)、多项式(k(x,y)=(σxTy+1)d)或高斯径向基函数中的一个;其中所述σ为核参数,d为核矩阵维度;
所述背景特征空间中样本内积的核函数Kd满足:Kd=DDT,其中,D为背景特征矩阵,若样本i和样本j来自不同设备,则(Kd)ij=0;若来自相同设备,则(Kd)ij=1或1+titj,t为样本的采样时间;
所述标签矩阵的核函数Ky满足:
Ky=Y×YT
对于c类分类问题使用哑变量编码方式,即标签矩阵Y∈Rn×c,若xi为有标签样本且属于第j类,则Yij=1;否则Yij=0;对于回归问题,首先将标签的均值设置为0、标签的方差设置为1,然后定义标签矩阵Y∈Rn,若xi为有标签样本,则Yi等于该标签值;否则Yi=0;c为正整数;
由所述非线性映射函数内积的核函数Kx、所述背景特征空间中样本内积的核函数Kd及标签矩阵的核函数Ky获得所述第一投影矩阵W。
此外,为实现上述目的,本发明还提供一种呼吸气体诊断系统的领域自适应装置包括:
第一获取模块,用于根据第一设备的响应获取对已知病患者呼吸气体进行采样的数据,按照预定规则从所述数据中提取目标数据作为训练样本;
第二获取模块,用于根据第二设备的响应获取对待测病患者呼吸气体进行采样的数据,按照预定规则从所述数据中提取目标数据作为测试样本;所述训练样本和测试样本共同构成样本空间;所述训练样本的背景特征及测试样本的背景特征构成背景特征空间;
计算模块,用于根据kernel trick核戏法、背景特征空间、HSIC独立准则、MIDA最大独立领域适配算法获得第一投影矩阵;
迁移模块,用于经所述第一投影矩阵将所述样本空间投影到一个高维特征空间,以使所述训练样本及测试样本按照同一特征呈线性分布。
优选地,在所述样本空间由多个原始特征向量构成时,所述计算模块包括:
映射模块,用于用非线性映射函数把所述原始特征向量映射到所述高维特征空间;
投影模块,用于定义第二投影矩阵将高维特征空间投影到所述第一投影矩阵,投影后的样本构成子空间;
核戏法模块,用于根据kernel trick核戏法获得非线性映射函数内积的核函数,获得所述子空间中样本与非线性映射函数内积的核函数及所述第一投影矩阵的关系式,进而获得所述子空间中样本内积的核函数;
适配模块,用于从所述子空间和背景特征空间中分别抽取独立样本,通过HSIC独立准则使得从所述子空间中样本与背景特征空间中抽取的独立样本之间的独立性最大;并使得所述子空间中样本的方差最大,获得所述第一投影矩阵。
优选地,所述适配模块包括:
HSIC模块,用于由所述子空间中样本内积的核函数Kz、所述背景特征空间中样本内积的核函数Kd及HSIC独立准则的经验估计公式获得决定HSIC值的关键因子:
tr(Kz×H×Kd×H)=tr(Kx×W×WT×Kx×H×Kd×H);
方差模块,用于由所述子空间中样本Z与非线性映射函数内积的核函数Kx及所述第一投影矩阵W的关系式:Z=Kx×W,计算子空间样本的协方差矩阵:
cov(Z)=WT×Kx×H×Kx×W;
MIDA模块,根据HSIC值的关键因子和子空间样本的协方差矩阵的迹,获得MIDA最大独立领域适配算法目标函数:
Y=-tr(WT×Kx×H×Kd×H×Kx×W)+μ×tr(WT×Kx×H×Kx×W)
其中:μ为权重系数,μ>0,Kx为非线性映射函数内积的核函数,,W为所述第一投影矩阵,且满足:WT×W=I,H满足:I是单位矩阵,n为样本空间中样本的数量;
解析模块,用于在所述MIDA最大独立领域适配算法目标函数的函数值Y最大时,获取与所述函数值Y对应的变量,即获得所述第一投影矩阵W。
优选地,所述解析模块包括:
函数构造模块,用于利用拉格朗日乘子法构造中间函数:
tr(WT×Kx×(-H×Kd×H+μ×H)×Kx×W)-tr((WT×W-I)×Λ)
其中Λ为拉格朗日乘子矩阵;
算子模块,用于令所述中间函数对W的导数为:
Y'=Kx×(-H×Kd×H+μ×H)×Kx×W-W×Λ
在所述中间函数对W的导数值Y’为零时,可得所述第一投影矩阵W是矩阵Kx×(-H×Kd×H+μ×H)×Kx的最大特征值对应的特征向量;
其中所述非线性映射函数内积的核函数Kx为以下线性核函数(k(x,y)=xTy)、多项式(k(x,y)=(σxTy+1)d)或高斯径向基函数中的一个;其中所述σ为核参数,d为核矩阵维度;
所述背景特征空间中样本内积的核函数Kd满足:Kd=DDT,其中,D为背景特征矩阵,若样本i和样本j来自不同设备,则(Kd)ij=0;若来自相同设备,则(Kd)ij=1或1+titj,t为样本的采样时间;
由所述非线性映射函数内积的核函数Kx及所述背景特征空间中样本内积的核函数Kd获得所述第一投影矩阵W。
优选地,当所述训练样本中包含有标签样本时;
所述第一模块,还用于根据第一设备的响应获取对标准成分及标准含量的气体进行采样的数据,按照预定规则从所述数据中提取目标数据作为所述标签样本;
自定义模块;用于定义所述训练样本的标签矩阵,获得标签矩阵的核函数Ky:
SMIDA模块,用于根据所述HSIC值的关键因子、子空间样本的协方差矩阵的迹、标签矩阵的核函数获得SMIDA半监督最大独立领域适配目标函数:
P=-tr(WT×Kx×(-H×Kd×H+μ×H+γ×H×Ky×H)×Kx×H)
其中γ为权重系数,γ>0;
所述解析模块,还用于在所述SMIDA半监督最大独立领域适配目标函数的函数值P最大时,获取与所述函数值P对应的变量,即获得所述第一投影矩阵W为矩阵Kx×(-H×Kd×H+μ×H+γ×H×Ky×H)×Kx的最大特征值对应的特征向量;
其中所述非线性映射函数内积的核函数Kx为以下线性核函数(k(x,y)=xTy)、多项式(k(x,y)=(σxTy+1)d)或高斯径向基函数中的一个;其中所述σ为核参数,d为核矩阵维度;
所述背景特征空间中样本内积的核函数Kd满足:Kd=DDT,其中,D为背景特征矩阵,若样本i和样本j来自不同设备,则(Kd)ij=0;若来自相同设备,则(Kd)ij=1或1+titj,t为样本的采样时间;
所述标签矩阵的核函数Ky满足:
Ky=Y×YT
对于c类分类问题使用哑变量编码方式,即标签矩阵Y∈Rn×c,若xi为有标签样本且属于第j类,则Yij=1;否则Yij=0;对于回归问题,首先将标签的均值设置为0、标签的方差设置为1,然后定义标签矩阵Y∈Rn,若xi为有标签样本,则Yi等于该标签值;否则Yi=0;c为正整数;
由所述非线性映射函数内积的核函数Kx、所述背景特征空间中样本内积的核函数Kd及标签矩阵的核函数Ky获得所述第一投影矩阵W。
本发明的方案,由于训练样本与测试样本是根据不同设备的相应获取的采用数据,由于存在设备漂移和时变漂移,样本的分布呈非线性,本方案通过非线性函数将由训练样本和测试样本共同构成的样本空间的原始向量特征映射到一个高维特征空间,在这个高维特征空间中样本按照统一特征呈线性分布,本方案通过将高维特征空间投影到第一投影矩阵,通过kernel trick核戏法、HSIC独立准则、MIDA最大独立领域适配算法获得第一投影矩阵;经第一投影矩阵将所述样本空间投影到高维特征空间或者说按照第一投影矩阵将样本空间迁移到高维特征空间中,在高维空特征间中,迁移后的训练样本及测试样本按照同一特征呈线性分布,即降低训练样本与测试样本分布存在的差异,尽可能相似;并且关于样本数据的重要结构信息能够被保留在迁移后的样本信息中,由于保留了样本数据的重要结构信息,用迁移到高维特征空间后的训练样本结合疾病标签训练学习疾病分类模型;用所述疾病分类模型对迁移后的测试样本进行疾病分类预测,并输出诊断结果;相对于现有技术,本方案缩小了使不同设备、不同时间采集到气体样本间的设备差异和时变漂移,提高了系统的学习性能和诊断的准确率。
附图说明
图1为本发明呼吸气体诊断系统的领域自适应方法第一实施例的流程示意图;
图2为本发明呼吸气体诊断系统的领域自适应方法第二实施例获得第一投影矩阵步骤的细化流程示意图;
图3为本发明呼吸气体诊断系统的领域自适应方法第三实施例中的流程示意图;
图4为本发明呼吸气体诊断系统的领域自适应方法第四实施例的细化流程示意图;
图5为本发明呼吸气体诊断系统的领域自适应方法第五实施例的细化流程示意图;
图6为本发明呼吸气体诊断系统的领域自适应装置第一实施例的功能模块示意图;
图7为本发明呼吸气体诊断系统的领域自适应装置第二实施例的细化功能模块示意图;
图8为本发明呼吸气体诊断系统的领域自适应装置第三实施例的细化功能模块示意图;
图9为本发明呼吸气体诊断系统的领域自适应装置第四实施例的细化功能模块示意图;
图10本发明呼吸气体诊断系统的领域自适应装置第五实施例的细化功能模块示意图。
本发明目的的实现、功能特点及优点将结合实施例,参照附图做进一步说明。
具体实施方式
应当理解,此处所描述的具体实施例仅仅用以解释本发明,并不用于限定本发明。
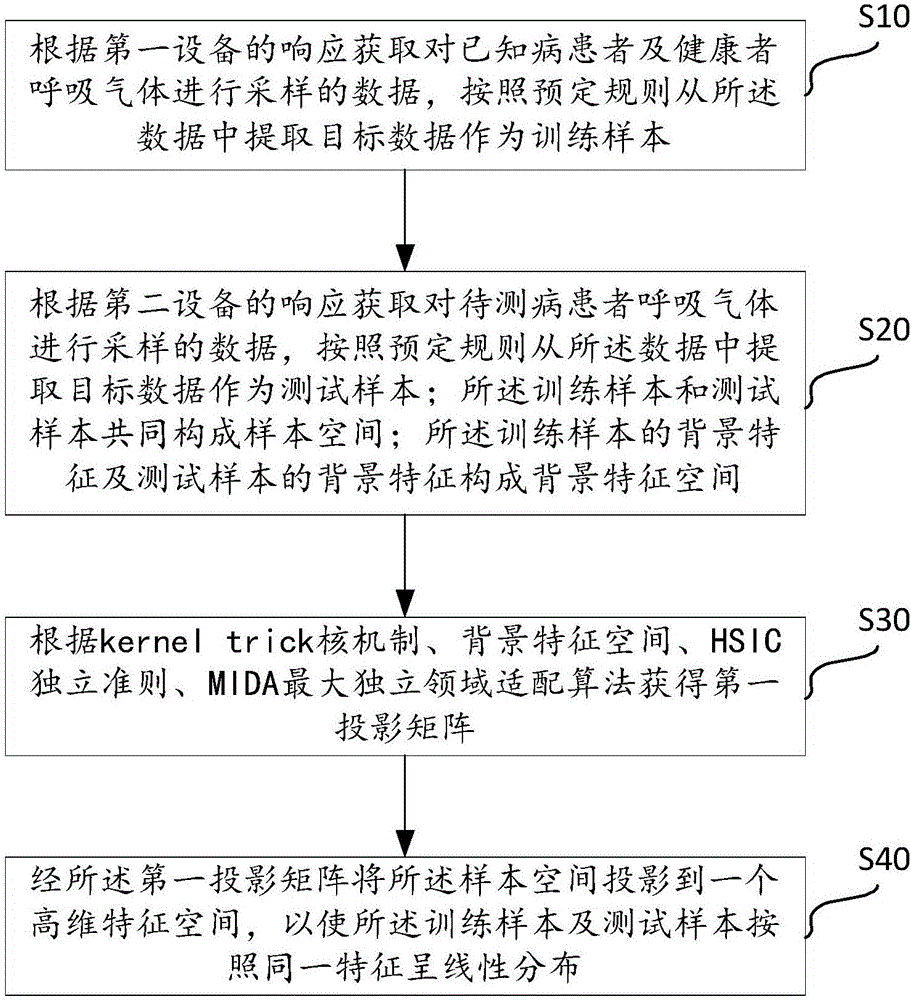
本发明提供一种呼吸气体诊断系统的领域自适应方法,参照图1,在一实施例中,该方法包括以下步骤:
步骤S10,根据第一设备的响应获取对已知病患者及健康者呼吸气体进行采样的数据,按照预定规则从所述数据中提取目标数据作为训练样本;
利用电子鼻实地采集了健康人和各种病人的呼气样本,样本的详细情况如表1.1所示。所有样本都由医院提供了诊断标签。目前数据库数据量超过10000条,涵盖了包括糖尿病、高血压、心脏病、肺病、肾病、乳腺疾病等四十余种常见、非常见疾病,为挖掘呼气和疾病间的对应关系提供了足够的数据支持。
表1.1呼气大数据样本疾病分布表
在采集病人呼气样本的同时,还记录了病人的实时血糖、血脂等生化指标,以便后续对全面的身体状况检测进行实验,如表1.2所示。
表1.2呼气大数据样本生化指标分布表
这里的第一设备为电子鼻,根据电子鼻的响应采集的数据很多是没有用的,按照预定规则从采集的这些数据中提取有价值的目标数据作为训练样本,这里的目标数据实际上是对采集的数据中一部分含有有用信息的数据的一个命名,可以是原有的数据,也可以是对原有数据的一个分析或变形,训练样本的集合可理解为源领域或源数据集,在机器的学习领域,根据源数据集建立一个预测模型,预测根据从设备的响应获取的目标数据集的响应变量值。这里的第一设备也可理解为主设备,具体使用过程中,会将训练样本拷贝到第二设备、第三设备等从设备中。
步骤S20,根据第二设备的响应获取对待测病患者呼吸气体进行采样的数据,按照预定规则从所述数据中提取目标数据作为测试样本;所述训练样本和测试样本共同构成样本空间;所述训练样本的背景特征及测试样本的背景特征构成背景特征空间;
这里的第二设备也是电子鼻,但是与步骤S10中提到的第一设备不是同一台电子鼻,第二设备可理解为从设备,上述根据源数据集建立的预测模型希望能用在若干从设备上;测量样本构成的空间可理解为目标数据集,在实际运算过程中,获取的所有样本包括练样本和测试样本共同构成样本空间,
设X∈Rn×m为样本空间,即包含原始特征向量的样本矩阵,原始特征维度为m,样本数为n,其中既包含训练也包含测试样本。与DCAE类似,这里我们不需要指明每个样本x属于哪个领域(源领域或目标领域),相关信息蕴含在这些样本的背景特征中。这里的背景特征可以是来自同一设备、来自不同设备、来自同一时间、或不同时间等,具体可定义一个背景特征矩阵来表达。传统的机器学习假定训练域(源领域)与测试域(目标领域)独立同分布,将由训练数据集得到的模型直接应用于测试集。但在实际应用中,这种假设并不一定成立,若训练域与测试域分布存在差异,则传统机器学习的性能将会大大降低,而实际应用中,源领域与目标领域之间存在较大的差距。
步骤S30,根据kernel trick核戏法、背景特征空间、HSIC独立准则、MIDA最大独立领域适配算法获得第一投影矩阵;
核戏法(kernel trick)是核方法(kernel methods简称KMs)一个运算规则,其中KMs是一类模式识别的算法。其目的是找出并学习一组数据中的相互的关系。用途较广的核方法有支持向量机、高斯过程等。
核方法是解决非线性模式分析问题的一种有效途径,其核心思想是:首先,通过某种非线性映射将原始数据嵌入到合适的高维特征空间;然后,利用通用的线性学习器在这个新的空间中分析和处理模式。相对于使用通用非线性学习器直接在原始数据上进行分析的范式,核方法有明显的优势:
首先,通用非线性学习器不便反应具体应用问题的特性,而核方法的非线性映射由于面向具体应用问题设计而便于集成问题相关的先验知识。
再者,线性学习器相对于非线性学习器有更好的过拟合控制从而可以更好地保证泛化性能。
还有,很重要的一点是核方法还是实现高效计算的途径,它能利用核函数将非线性映射隐含在线性学习器中进行同步计算,使得计算复杂度与高维特征空间的维数无关。
本文对核方法进行简要的介绍。
核方法的主要思想是基于这样一个假设:“在低维空间中不能线性分割的点集,通过转化为高维空间中的点集时,很有可能变为线性可分的”,例如有两类数据,一类为x<aUx>b;另一部分为a<x<b。要想在一维空间上线性分开是不可能的。然而我们可以通过F(x)=(x-a)(x-b)把一维空间上的点转化到二维空间上,这样就可以划分两类数据F(x)>0,F(x)<0;从而实现线性分割。
然而,如果直接把低维度的数据转化到高维度的空间中,然后再去寻找线性分割平面,会遇到两个大问题,一是由于是在高维度空间中计算,导致维度祸根(curse of dimension)问题;二是非常的麻烦,每一个点都必须先转换到高维度空间,然后求取分割平面的参数等等;怎么解决这些问题?答案是通过核戏法(kernel trick)。
Kernel Trick:定义一个核函数K(x1,x2)=<\phi(x1),\phi(x2)>,其中x1和x2是低维度空间中点(在这里可以是标量,也可以是向量),\phi(xi)是低维度空间的点xi转化为高维度空间中的点的表示,<,>表示向量的内积。这里核函数K(x1,x2)的表达方式一般都不会显式地写为内积的形式,即我们不关心高维度空间的形式。
核函数巧妙地解决了上述的问题,在高维度中向量的内积通过低维度的点的核函数就可以计算了。这种技巧被称为Kernel trick。
这里还有一个问题:“为什么我们要关心向量的内积?”,一般地,我们可以把分类(或者回归)的问题分为两类:参数学习的形式和基于实例的学习形式。参数学习的形式就是通过一堆训练数据,把相应模型的参数给学习出来,然后训练数据就没有用了,对于新的数据,用学习出来的参数即可以得到相应的结论;而基于实例的学习(又叫基于内存的学习)则是在预测的时候也会使用训练数据,如KNN算法。而基于实例的学习一般就需要判定两个点之间的相似程度,一般就通过向量的内积来表达。从这里可以看出,核方法不是万能的,它一般只针对基于实例的学习。
紧接着,我们还需要解决一个问题,即核函数的存在性判断和如何构造?既然我们不关心高维度空间的表达形式,那么怎么才能判断一个函数是否是核函数呢?
Mercer定理:任何半正定的函数都可以作为核函数。所谓半正定的函数f(xi,xj),是指拥有训练数据集合(x1,x2,...xn),我们定义一个矩阵的元素aij=f(xi,xj),这个矩阵式n×n的,如果这个矩阵是半正定的,那么f(xi,xj)就称为半正定的函数。这个mercer定理不是核函数必要条件,只是一个充分条件,即还有不满足mercer定理的函数也可以是核函数。
常见的核函数有高斯核,多项式核等等,在这些常见核的基础上,通过核函数的性质(如对称性等)可以进一步构造出新的核函数。SVM是目前核方法应用的经典模型。
Hilbert-Schmidt独立性准则(Hilbert-Schmidt Independence Criterion,HSIC)是一种用来度量两个随机变量的独立性的准则。
最大独立领域适配(Maximum Independence Domain Adaptation,MIDA)可以被视为一种特征抽取(feature extraction)算法,目标在于学习一个领域不变子空间,利用Hilbert-Schmidt独立性准则来最大化子空间中的特征与背景特征之间的独立性。直观来讲,子空间中的特征与背景特征独立意味着我们不能通过一个样本在子空间中的位置来推断它的背景,也就是说不同背景的样本不存在分布差异。根据Ben-David等人的理论,为了取得较好的领域适配效果,需要使得不同领域的样本变得难以区分。通过这种方式,我们不仅可以对两个离散领域进行适配,还可以处理多个离散领域和连续分布变化的情况。
要去解决上述这个问题并跨不同目标领域构建预测模型。为此,本文提出了一种基于核分布嵌入和Hilbert-Schmidt独立准则的方法。该方法将源数据和目标数据嵌入在一个新的特征空间中。新的特征空间具有两个属性:1)源数据集和目标数据集的分布尽可能相似;2)关于数据的重要结构信息被保存下来。嵌入数据在一个较低维度的空间中并同时保留了之前的两个属性。因此,该方法也能被看作是一种降维方法。该方法具有闭合形式解并且实验表明其能够有效处理实际数据。
步骤S40,经所述第一投影矩阵将所述样本空间投影到一个高维特征空间,以使所述训练样本及测试样本按照同一特征呈线性分布。
可理解为以第一投影矩阵为迁移规则,将上述的样本空间迁移到高维特征空间,在这个高维特征空间中,训练样本与测试样本的分布的差异很小,或者说训练样本的分布与测试样本的分布之间彼此独立,相互依赖性很低或不存在,所述训练样本及测试样本按照同一特征呈线性分布,并且关于样本数据的重要结构信息能够被保留在迁移后的样本信息中,由于保留了样本数据的重要结构信息,用迁移到高维特征空间后的训练样本结合疾病标签训练学习疾病分类模型;用所述疾病分类模型对迁移后的测试样本进行疾病分类预测,并输出诊断结果;相对于现有技术,本方案缩小了使不同设备、不同时间采集到气体样本间的设备差异和时变漂移,提高了系统的学习性能和诊断的准确率。
实施例二
进一步地,参见图2,在实施例一的基础上,对其中的步骤S30进一步细化,包括:
步骤S31,用非线性映射函数把所述原始特征向量映射到所述高维特征空间;
这里的非线性映射函数用Φ(X)表示,基于核戏法(kernel trick),非线性映射函数的具体形式Φ并不需要给出,只需要将Φ(X)的内积用一个核矩阵代替Kx=Φ(X)Φ(X)T。
步骤S32,定义第二投影矩阵将高维特征空间中的样本投影到所述第一投影矩阵,投影后的样本构成子空间;
第一投影矩阵用W表示,第二投影矩阵用表示,假设子空间的维度为h,高维特征空间中的样本用Φ(X)表示,步骤S32可理解为定义第二投影矩阵用将Φ(X)投影到第一投影矩阵W中,投影后的样本满足:
步骤S33,根据kernel trick核戏法获得非线性映射函数内积的核函数,获得所述子空间中样本与非线性映射函数内积的核函数及所述第一投影矩阵的关系式,进而获得所述子空间中样本内积的核函数;
基于核技巧(kernel trick),非线性映射函数的具体形式Φ并不需要给出,只需要将Φ(X)的内积用一个核矩阵或核函数Kx=Φ(X)Φ(X)T代替。
核子空间学习中,可以用高维空间中的样本的线性组合来表达第二投影矩阵,即第一投影矩阵W∈Rn×h才是真正需要学习的投影矩阵。这时,子空间中的样本可表达为:
Z=Φ(X)Φ(X)TW=KxW
其核矩阵为:
Kz=KxWWTKx
步骤S34,从所述子空间和背景特征空间中分别抽取独立样本,通过HSIC独立准则使得从所述子空间中样本与背景特征空间中抽取的独立样本之间的独立性最大;并使得所述子空间中样本的方差最大,获得所述第一投影矩阵。
HSIC独立准则(Hilbert-Schmidt Independence Criterion,HSIC)是一种用来度量两个随机变量的独立性的准则。设两个随机变量的联合分布是pxy,它们的核函数分别是kx和ky,对应着两个RKHS:F和G。HSIC定义为互协方差运算符Cxy的Hilbert-Schmidt范数的平方:
这里Exx′yy′是对从pxy中抽取的独立样本组合(x,y)和(x′,y′)求取的期望。可以证明,对于典型核函数(characteristic kernels)kx和ky,HSIC(pxy,F,G)为0当且仅当两个随机变量独立。HSIC越大,两个随机变量的依赖性越强(在所选核函数意义下)。
HSIC有一个有偏经验估计。设X和Y是从pxy中抽取的两组观测样本,Z=X×Y={(x1,y1),…,(xn,yn)},Kx,Ky∈Rn×n分别是X和Y的核矩阵,则:
HSIC(Z,F,G)=(n-1)-2tr(KxHKyH)
其中为中心化矩阵。由于上式有效且应用方便,HSIC已被应用在特征抽取和特征选择等领域。通常的方法是最大化抽取或选择的特征与标签之间的依赖,即最小化独立性。然而,在领域适配问题中用HSIC来最大化子空间中特征与背景特征之间的独立性。
子空间中样本的方差最大的目的在于使得样本中保留有用的信息或重要结构信息;
在上述两个条件下,根据线性函数关系能够获得第一投影矩阵W。
实施例三
更进一步地,参见图3,上述实施例二中的步骤S34包括:
步骤S34a,由所述子空间中样本内积的核函数Kz、所述背景特征空间中样本内积的核函数Kd及HSIC独立准则的经验估计公式:HSIC(Z,F,G)=(n-1)-2tr(KxHKyH)获得决定HSIC值的关键因子:
tr(Kz×H×Kd×H)=tr(Kx×W×WT×Kx×H×Kd×H);
相当于在子空间和背景特征空间中抽取独立样本,HSIC值最小时,两者之间的独立性越大,因此在下面的步骤中,使得HSIC值的关键因子最小;
步骤S34b,由所述子空间中样本Z与非线性映射函数内积的核函数Kx及所述第一投影矩阵W的关系式:Z=Kx×W,计算子空间样本的协方差矩阵:
cov(Z)=WT×Kx×H×Kx×W;
通过子空间样本的协方差矩阵的迹最大来获得方差的最大值;以此实现子空间中的样本保留重要结构信息;
步骤S34c,根据HSIC值的关键因子和子空间样本的协方差矩阵,获得MIDA最大独立领域适配算法目标函数:
Y=-tr(WT×Kx×H×Kd×H×Kx×W)+μ×tr(WT×Kx×H×Kx×W)
其中:μ为权重系数,μ>0,Kx为非线性映射函数内积的核函数,W为所述第一投影矩阵,且满足:WT×W=I,H满足:I是单位矩阵,n为样本空间中样本的数量;
首先需要根据子空间样本的协方差矩阵获得子空间样本的协方差矩阵的轨迹:
tr(WT×Kx×H×Kx×W)
然后根据MIDA最大独立领域适配算法的核心思想,HSIC值的关键因子取最小值,保证抽取的来自两个领域的独立样本之间的独立性最大;子空间样本的方差最大保证每个抽取的独立样本保留最多的重要结构信息,这里通过使得子空间样本的协方差矩的迹最大来实现子空间样本的方差最大,因此MIDA最大独立领域适配算法目标函数:
Y=-tr(WT×Kx×H×Kd×H×Kx×W)+μ×tr(WT×Kx×H×Kx×W)
HSIC值的关键因子数值越小,目标函数的前半部分的值越大,子空间样本的协方差矩的迹越大,目标函数的后半部分的值越大;因子后面只要在目标函数值Y最大时,获取变量的值能够满足需要的结果:抽取的来自两个领域的独立样本之间的独立性最大;每个抽取的独立样本保留最多的重要结构信息。
步骤S34d,在所述MIDA最大独立领域适配算法目标函数的函数值Y最大时,获取与所述函数值Y对应的变量,即获得所述第一投影矩阵W。这里的变量就是第一投影矩阵W。
实施例四
再进一步地,作为实施例四,参见图4,在实施例三的基础上,步骤S34d包括:
步骤d1,利用拉格朗日乘子法构造中间函数:
tr(WT×Kx×(-H×Kd×H+μ×H)×Kx×W)-tr((WT×W-I)×Λ)
其中Λ为拉格朗日乘子矩阵;
所述中间函数对W的导数为:
Y'=Kx×(-H×Kd×H+μ×H)×Kx×W-W×Λ
步骤d2,在所述中间函数对W的导数值Y’为零时,可得所述第一投影矩阵W是矩阵Kx×(-H×Kd×H+μ×H)×Kx的最大特征值对应的特征向量;
其中所述非线性映射函数内积的核函数Kx为以下线性核函数(k(x,y)=xTy)、多项式(k(x,y)=(σxTy+1)d)或高斯径向基函数中的一个;其中所述σ为核参数,d为核矩阵维度;
所述背景特征空间中样本内积的核函数Kd满足:Kd=DDT,其中,D为背景特征矩阵,若样本i和样本j来自不同设备,则(Kd)ij=0;若来自相同设备,则(Kd)ij=1或1+titj,t为样本的采样时间;
步骤d3,由所述非线性映射函数内积的核函数Kx及所述背景特征空间中样本内积的核函数Kd获得所述第一投影矩阵W。
上述的实施例一至实施例四,训练样本中没有包括根据第一设备的响应获取对标定气体采样的数据,适用与无监督领域适配算法。
最大独立领域适配(Maximum Independence Domain Adaptation,MIDA)可以被视为一种特征抽取(feature extraction)算法,目标在于学习一个领域不变子空间,利用Hilbert-Schmidt独立性准则来最大化子空间中的特征与背景特征之间的独立性。直观来讲,子空间中的特征与背景特征独立意味着我们不能通过一个样本在子空间中的位置来推断它的背景,也就是说不同背景的样本不存在分布差异。根据Ben-David等人的理论,为了取得较好的领域适配效果,需要使得不同领域的样本变得难以区分,这与我们的思路是一致的。通过这种方式,我们不仅可以对两个离散领域进行适配,还可以处理多个离散领域和连续分布变化的情况。
实施例五,
在实施例三的基础上,步骤S34d还包括:
步骤d4,当所述训练样本中包含有标签样本时,根据第一设备的响应获取对标准成分及标准含量的气体进行采样的数据,按照预定规则从所述数据中提取目标数据作为所述标签样本,并定义所述训练样本的标签矩阵,获得标签矩阵的核函数Ky:
所述背景特征空间中样本内积的核函数Kd满足:Kd=DDT,其中,D为背景特征矩阵,若样本i和样本j来自不同设备,则(Kd)ij=0;若来自相同设备,则(Kd)ij=1或1+titj,t为样本的采样时间;
所述标签矩阵的核函数Ky满足:
Ky=Y×YT
对于c类分类问题使用哑变量编码方式,即标签矩阵Y∈Rn×c,若xi为有标签样本且属于第j类,则Yij=1;否则Yij=0;对于回归问题,首先将标签的均值设置为0、标签的方差设置为1,然后定义标签矩阵Y∈Rn,若xi为有标签样本,则Yi等于该标签值;否则Yi=0;其中,对于分类问题,如果所有可能出现的类型数为c类,就叫c类分类,例如:按性别分类问题,一般只有两种可能的类型,可以叫二类分类,这里统一定义类型为c类,便于后面的标签矩阵的关系式表达。
步骤d5,根据所述HSIC值的关键因子、子空间样本的协方差矩阵、标签矩阵的核函数获得SMIDA半监督最大独立领域适配目标函数:
P=-tr(WT×Kx×(-H×Kd×H+μ×H+γ×H×Ky×H)×Kx×H)
其中:γ为权重系数,γ>0;
步骤d6,在所述SMIDA半监督最大独立领域适配目标函数的函数值P最大时,获取与所述函数值P对应的变量,即所述第一投影矩阵W为矩阵Kx×(-H×Kd×H+μ×H+γ×H×Ky×H)×Kx的最大特征值对应的特征向量;
其中所述非线性映射函数内积的核函数Kx为以下线性核函数(k(x,y)=xTy)、多项式(k(x,y)=(σxTy+1)d)或高斯径向基函数中的一个;其中所述σ为核参数,d为核矩阵维度;
步骤d7,由所述非线性映射函数内积的核函数Kx、所述背景特征空间中样本内积的核函数Kd及标签矩阵的核函数Ky获得所述第一投影矩阵W。
MIDA在缩小不同背景样本的分布差异时没有考虑样本的标签。如果部分样本标签已知,将其结合到学习过程中有利于提高子空间中特征的鉴别能力。提高特征的鉴别能力也可以降低领域适配误差上界。因此,我们将无监督情况下的MIDA拓展到半监督情况,并命名为SMIDA(Semi-supervised MIDA)。在SMIDA中,无标签和有标签样本都可以来自任何领域。SMIDA利用HSIC最大化子空间中有标签样本的特征与标签的依赖性。用这种方式利用样本标签的好处在于,不管是分类问题中的离散标签还是回归问题中的连续标签,都可以被统一地集成到算法中。
数据集中,选取了对应五种疾病的呼气样本,分别是糖尿病、慢性肾病、心脏病、肺癌、乳腺癌。这些疾病已被证明与特定呼气标志物相关。我们对健康样本和每种疾病样本进行二分类,比较无迁移、基于PCA的成分校正(CC-PCA)方法以及本研究提出的几种方法的识别率,如表1.3。
表1.3漂移补偿方法识别率比较
表1.4总结比较了不同漂移补偿方法的特点
表1.4 TMTL、DCAE和MIDA的算法差异
本发明通过采用大数据支持下的漂移补偿方法,缩小了使不同设备、不同时间采集到气体样本间的设备差异和时变漂移。
本发明还提供一种呼吸气体诊断系统的领域自适应装置,参照图6,在一实施例中,本发明提供的呼吸气体诊断系统的领域自适应装置包括:
第一获取模块10,用于根据第一设备的响应获取对已知病患者呼吸气体进行采样的数据,按照预定规则从所述数据中提取目标数据作为训练样本;
利用电子鼻实地采集了健康人和各种病人的呼气样本,样本的详细情况如表1.1所示。所有样本都由医院提供了诊断标签。目前数据库数据量超过10000条,涵盖了包括糖尿病、高血压、心脏病、肺病、肾病、乳腺疾病等四十余种常见、非常见疾病,为挖掘呼气和疾病间的对应关系提供了足够的数据支持。
表1.1呼气大数据样本疾病分布表
在采集病人呼气样本的同时,还记录了病人的实时血糖、血脂等生化指标,以便后续对全面的身体状况检测进行实验,如表1.2所示。
表1.2呼气大数据样本生化指标分布表
这里的第一设备为电子鼻,根据电子鼻的响应采集的数据很多是没有用的,这里按照预定规则从采集的这些数据中提取有价值的目标数据作为训练样本,这里的目标数据实际上是对采集的数据中一部分还有有用信息的数据的一个命名,训练样本的集合可理解为源领域或源数据集,在机器的学习领域,根据源数据集建立一个预测模型,预测根据从设备的响应获取的目标数据集的响应变量值。这里的第一设备也可理解为主设备,具体使用过程中,会将训练样本拷贝到第二设备、第三设备等从设备中。
第二获取模块20,用于根据第二设备的响应获取对待测病患者呼吸气体进行采样的数据,按照预定规则从所述数据中提取目标数据作为测试样本;所述训练样本和测试样本共同构成样本空间;所述训练样本的背景特征及测试样本的背景特征构成背景特征空间;
这里的第二设备也是电子鼻,但是与第一获取模块10中提到的第一设备不是同一台电子鼻,第二设备可理解为从设备,上述根据源数据集建立的预测模型希望能用在若干从设备上;测量样本构成的空间可理解为目标数据集,在实际运算过程中,获取的所有样本包括练样本和测试样本共同构成样本空间,
设X∈Rn×m为样本空间,即包含原始特征向量的样本矩阵,原始特征维度为m,样本数为n,其中既包含训练也包含测试样本。与DCAE类似,这里我们不需要指明每个样本x属于哪个领域(源领域或目标领域),相关信息蕴含在这些样本的背景特征中。这里的背景特征可以是来自同一设备、来自不同设备、来自同一时间、或不同时间等,具体可定义一个背景特征矩阵来表达。传统的机器学习假定训练域(源领域)与测试域(目标领域)独立同分布,将由训练数据集得到的模型直接应用于测试集。但在实际应用中,这种假设并不一定成立,若训练域与测试域分布存在差异,则传统机器学习的性能将会大大降低,而实际应用中,源领域与目标领域之间存在较大的差距。
计算模块30,用于根据kernel trick核戏法、背景特征空间、HSIC独立准则、MIDA最大独立领域适配算法获得第一投影矩阵;
要去解决上述这个问题并跨不同目标领域构建预测模型。为此,本文提出了一种基于核分布嵌入和Hilbert-Schmidt独立准则的方法。该方法将源数据和目标数据嵌入在一个新的特征空间中。新的特征空间具有两个属性:1)源数据集和目标数据集的分布尽可能相似;2)关于数据的重要结构信息被保存下来。嵌入数据在一个较低维度的空间中并同时保留了之前的两个属性。因此,该方法也能被看作是一种降维方法。该方法具有闭合形式解并且实验表明其能够有效处理实际数据。
迁移模块40,用于经所述第一投影矩阵将所述样本空间投影到一个高维特征空间,以使所述训练样本及测试样本按照同一特征呈线性分布。
可理解为以第一投影矩阵为迁移规则,将上述的样本空间迁移到高维特征空间,在这个高维特征空间中,训练样本与测试样本的分布的差异很小,或者说训练样本的分布与测试样本的分布之间彼此独立,相互依赖性很低或不存在,所述训练样本及测试样本按照同一特征呈线性分布,并且关于样本数据的重要结构信息能够被保留在迁移后的样本信息中,由于保留了样本数据的重要结构信息,用迁移到高维特征空间后的训练样本结合疾病标签训练学习疾病分类模型;用所述疾病分类模型对迁移后的测试样本进行疾病分类预测,并输出诊断结果;相对于现有技术,本方案缩小了使不同设备、不同时间采集到气体样本间的设备差异和时变漂移,提高了系统的学习性能和诊断的准确率。
实施例二
进一步地,参见图7,在所述样本空间由多个原始特征向量构成时,其中所述计算模块30包括:
映射模块31,用于用非线性映射函数把所述原始特征向量映射到所述高维特征空间;
这里的非线性映射函数用Φ(X)表示,基于核技巧(kernel trick),非线性映射函数的具体形式Φ并不需要给出,只需要将Φ(X)的内积用一个核矩阵代替Kx=Φ(X)Φ(X)T。
投影模块32,用于定义第二投影矩阵将高维特征空间投影到所述第一投影矩阵,投影后的样本构成子空间;
第一投影矩阵用W表示,第二投影矩阵用表示,假设子空间的维度为h,高维特征空间中的样本用Φ(X)表示,步骤S32可理解为定义第二投影矩阵用将Φ(X)投影到第一投影矩阵W中,投影后的样本满足:
核戏法模块33,用于根据kernel trick核戏法获得非线性映射函数内积的核函数,获得所述子空间中样本与非线性映射函数内积的核函数及所述第一投影矩阵的关系式,进而获得所述子空间中样本内积的核函数;
基于核戏法(kernel trick),非线性映射函数的具体形式Φ并不需要给出,只需要将Φ(X)的内积用一个核矩阵或核函数Kx=Φ(X)Φ(X)T代替。
核子空间学习中,可以用高维空间中的样本的线性组合来表达第二投影矩阵,即第一投影矩阵W∈Rn×h才是真正需要学习的投影矩阵。这时,子空间中的样本可表达为:
Z=Φ(X)Φ(X)TW=KxW
其核矩阵为:
Kz=KxWWTKx
适配模块34,用于从所述子空间和背景特征空间中分别抽取独立样本,通过HSIC独立准则使得从所述子空间中样本与背景特征空间中抽取的独立样本之间的独立性最大;并使得所述子空间中样本的方差最大,获得所述第一投影矩阵。
HSIC独立准则(Hilbert-Schmidt Independence Criterion,HSIC)是一种用来度量两个随机变量的独立性的准则。设两个随机变量的联合分布是pxy,它们的核函数分别是kx和ky,对应着两个RKHS:F和G。HSIC定义为互协方差运算符Cxy的Hilbert-Schmidt范数的平方:
这里Exx′yy′是对从pxy中抽取的独立样本组合(x,y)和(x′,y′)求取的期望。可以证明,对于典型核函数(characteristic kernels)kx和ky,HSIC(pxy,F,G)为0当且仅当两个随机变量独立。HSIC越大,两个随机变量的依赖性越强(在所选核函数意义下)。
HSIC有一个有偏经验估计。设X和Y是从pxy中抽取的两组观测样本,Z=X×Y={(x1,y1),…,(xn,yn)},Kx,Ky∈Rn×n分别是X和Y的核矩阵,则:
HSIC(Z,F,G)=(n-1)-2tr(KxHKyH)
其中为中心化矩阵。由于上式有效且应用方便,HSIC已被应用在特征抽取和特征选择等领域。通常的方法是最大化抽取或选择的特征与标签之间的依赖,即最小化独立性。然而,在领域适配问题中用HSIC来最大化子空间中特征与背景特征之间的独立性。
子空间中样本的方差最大的目的在于使得样本中保留有用的信息或重要结构信息;
在上述两个条件下,根据线性关系能够获得第一投影矩阵W。
实施例三
更进一步地,参见图8,所述适配模块34包括:
HSIC模块34a,用于由所述子空间中样本内积的核函数Kz、所述背景特征空间中样本内积的核函数Kd及HSIC独立准则的经验估计公式获得决定HSIC值的关键因子:
tr(Kz×H×Kd×H)=tr(Kx×W×WT×Kx×H×Kd×H);
相当于在子空间和背景特征空间中抽取独立样本,HSIC值最小时,两者之间的独立性越大,因此在下面的步骤中,使得HSIC值的关键因子最小;
方差模块34b,用于由所述子空间中样本Z与非线性映射函数内积的核函数Kx及所述第一投影矩阵W的关系式:Z=Kx×W,计算子空间样本的协方差矩阵:
cov(Z)=WT×Kx×H×Kx×W;
通过子空间样本的协方差矩阵的迹最大来获得方差的最大值;以此实现子空间中的样本保留重要结构信息;
MIDA模块34c,根据HSIC值的关键因子和子空间样本的协方差矩阵的迹,获得MIDA最大独立领域适配算法目标函数:
Y=-tr(WT×Kx×H×Kd×H×Kx×W)+μ×tr(WT×Kx×H×Kx×W)
其中:μ为权重系数,μ>0,Kx为非线性映射函数内积的核函数,,W为所述第一投影矩阵,且满足:WT×W=I,H满足:I是单位矩阵,n为样本空间中样本的数量;
解析模块34d,用于在所述MIDA最大独立领域适配算法目标函数的函数值Y最大时,获取与所述函数值Y对应的变量,即获得所述第一投影矩阵W。
这里的变量就是第一投影矩阵W。
实施例四
再进一步地,参见图9,所述解析模块到34d包括:
函数构造模块d1,用于利用拉格朗日乘子法构造中间函数:
tr(WT×Kx×(-H×Kd×H+μ×H)×Kx×W)-tr((WT×W-I)×Λ)
其中Λ为拉格朗日乘子矩阵;
算子模块d2,用于令所述中间函数对W的导数为:
Y'=Kx×(-H×Kd×H+μ×H)×Kx×W-W×Λ
在所述中间函数对W的导数值Y’为零时,可得所述第一投影矩阵W是矩阵Kx×(-H×Kd×H+μ×H)×Kx的最大特征值对应的特征向量;
其中所述非线性映射函数内积的核函数Kx为以下线性核函数(k(x,y)=xTy)、多项式(k(x,y)=(σxTy+1)d)或高斯径向基函数中的一个;其中所述σ为核参数,d为核矩阵维度;
所述背景特征空间中样本内积的核函数Kd满足:Kd=DDT,其中,D为背景特征矩阵,若样本i和样本j来自不同设备,则(Kd)ij=0;若来自相同设备,则(Kd)ij=1或1+titj,t为样本的采样时间;
由所述非线性映射函数内积的核函数Kx及所述背景特征空间中样本内积的核函数Kd获得所述第一投影矩阵W。
上述的实施例一至实施例四,训练样本中没有包括根据第一设备的响应获取对标定气体采样的数据,适用与无监督领域适配算法。
最大独立领域适配(Maximum Independence Domain Adaptation,MIDA)可以被视为一种特征抽取(feature extraction)算法,目标在于学习一个领域不变子空间,利用Hilbert-Schmidt独立性准则来最大化子空间中的特征与背景特征之间的独立性。直观来讲,子空间中的特征与背景特征独立意味着我们不能通过一个样本在子空间中的位置来推断它的背景,也就是说不同背景的样本不存在分布差异。根据Ben-David等人的理论,为了取得较好的领域适配效果,需要使得不同领域的样本变得难以区分,这与我们的思路是一致的。通过这种方式,我们不仅可以对两个离散领域进行适配,还可以处理多个离散领域和连续分布变化的情况。
作为实施例五,参见图10,在实施例三的基础上:
当所述训练样本中包含有标签样本时;
所述第一模块10,还用于根据第一设备的响应获取对标准成分及标准含量的气体进行采样的数据,按照预定规则从所述数据中提取目标数据作为所述标签样本;
适配模块34包括:
自定义模块34e;用于定义所述训练样本的标签矩阵,获得标签矩阵的核函数Ky:
SMIDA模块34f,用于根据所述HSIC值的关键因子、子空间样本的协方差矩阵的迹、标签矩阵的核函数获得SMIDA半监督最大独立领域适配目标函数:
P=-tr(WT×Kx×(-H×Kd×H+μ×H+γ×H×Ky×H)×Kx×H)
其中γ为权重系数,γ>0;
所述解析模块34d,还用于在所述SMIDA半监督最大独立领域适配目标函数的函数值P最大时,获取与所述函数值P对应的变量,即获得所述第一投影矩阵W为矩阵Kx×(-H×Kd×H+μ×H+γ×H×Ky×H)×Kx的最大特征值对应的特征向量;
其中所述非线性映射函数内积的核函数Kx为以下线性核函数(k(x,y)=xTy)、多项式(k(x,y)=(σxTy+1)d)或高斯径向基函数中的一个;其中所述σ为核参数,d为核矩阵维度;
所述背景特征空间中样本内积的核函数Kd满足:Kd=DDT,其中,D为背景特征矩阵,若样本i和样本j来自不同设备,则(Kd)ij=0;若来自相同设备,则(Kd)ij=1或1+titj,t为样本的采样时间;
所述标签矩阵的核函数Ky满足:
Ky=Y×YT
对于c类分类问题使用哑变量编码方式,即标签矩阵Y∈Rn×c,若xi为有标签样本且属于第j类,则Yij=1;否则Yij=0;对于回归问题,首先将标签的均值设置为0、标签的方差设置为1,然后定义标签矩阵Y∈Rn,若xi为有标签样本,则Yi等于该标签值;否则Yi=0;其中,对于分类问题,如果所有可能出现的类型数为c类,就叫c类分类,例如:按性别分类问题,一般只有两种可能的类型,可以叫二类分类,这里统一定义类型为c类,便于后面的标签矩阵的关系式表达。
由所述非线性映射函数内积的核函数Kx、所述背景特征空间中样本内积的核函数Kd及标签矩阵的核函数Ky获得所述第一投影矩阵W。
MIDA在缩小不同背景样本的分布差异时没有考虑样本的标签。如果部分样本标签已知,将其结合到学习过程中有利于提高子空间中特征的鉴别能力。提高特征的鉴别能力也可以降低领域适配误差上界。因此,我们将无监督情况下的MIDA拓展到半监督情况,并命名为SMIDA(Semi-supervised MIDA)。在SMIDA中,无标签和有标签样本都可以来自任何领域。SMIDA利用HSIC最大化子空间中有标签样本的特征与标签的依赖性。用这种方式利用样本标签的好处在于,不管是分类问题中的离散标签还是回归问题中的连续标签,都可以被统一地集成到算法中。
数据集中,选取了对应五种疾病的呼气样本,分别是糖尿病、慢性肾病、心脏病、肺癌、乳腺癌。这些疾病已被证明与特定呼气标志物相关。我们对健康样本和每种疾病样本进行二分类,比较无迁移、基于PCA的成分校正(CC-PCA)方法以及本研究提出的几种方法的识别率,如表1.3。
表1.3漂移补偿方法识别率比较
表1.4总结比较了不同漂移补偿方法的特点
表1.4 TMTL、DCAE和MIDA的算法差异
本发明通过采用大数据支持下的漂移补偿方法,缩小了使不同设备、不同时间采集到气体样本间的设备差异和时变漂移。
以上仅为本发明的优选实施例,并非因此限制本发明的专利范围,凡是利用本发明说明书及附图内容所作的等效结构或等效流程变换,或直接或间接运用在其他相关的技术领域,均同理包括在本发明的专利保护范围内。
- 还没有人留言评论。精彩留言会获得点赞!