人机交互方法及智能机器人与流程
本发明涉及智能机器人技术领域,具体而言,涉及一种人机交互方法及智能机器人。
背景技术:
随着科学技术的不断发展,信息技术、计算机技术以及人工智能技术的引入,机器人的研究已经逐步走出工业领域,逐渐扩展到了医疗、保健、家庭、娱乐以及服务行业等领域。而人们对于机器人的要求也从简单重复的机械动作,提升为具有高度智能、自主性、能与其他智能体交互的智能机器人。对于智能机器人来说,其不仅需要具有完成指定工作的能力,还需要能够在许多场合与人进行交互,这就要求智能机器人能够与人进行有效的信息交流。
目前,在商场、公园、饭店等公共场所中,越来越多的设置有为公众提供接待、介绍、推销等服务的机器人。现有的机器人只是通过语音识别,判断一些简单的问话和命令,进行回答、动作等回应。但是,在接受服务的公众中,每个人的需求都不同,而现有的机器人在面对任何人时,都是按照既定的程序进行交互服务,因此现有的机器人存在提供的交互服务较为单一的问题。
技术实现要素:
有鉴于此,本发明的目的在于提供一种人机交互方法及智能机器人,已解决现有的机器人提供的交互服务较为单一的问题。
第一方面,本发明提供了一种人机交互方法,包括:
识别步骤,对目标进行面部识别,并分辨出目标的人群类别;
交互步骤,根据目标的人群类别,采用相应的方式与目标进行交互。
结合第一方面,本发明提供了第一方面的第一种可能的实施方式,其中,所述人群类别包括特定人群和非特定人群。
结合第一方面,本发明提供了第一方面的第二种可能的实施方式,其中,所述交互步骤具体为:
当目标为特定人群时,向目标播放音频;
当目标为非特定人群时,不向目标播放音频。
结合第一方面,本发明提供了第一方面的第三种可能的实施方式,其中,向目标播放音频后,如果目标有所回应,则通过语音识别的方式,与目标进行语音交互。
结合第一方面,本发明提供了第一方面的第四种可能的实施方式,其中,所述交互步骤具体为:
对属于不同人群类别的目标,分别播放不同内容的音频。
结合第一方面,本发明提供了第一方面的第五种可能的实施方式,其中,在识别步骤之前,还包括:
训练步骤,训练出用于分辨出目标的人群类别的支持向量机分类器。
结合第一方面,本发明提供了第一方面的第六种可能的实施方式,其中,所述训练步骤具体为:
获取各个人群类别的面部图像样本;
提取各个图像样本的方向梯度直方图特征,并基于libsvm,训练出支持向量机分类器。
第二方面,本发明还提供一种智能机器人,包括处理器、摄像头、扩音器和话筒;
所述摄像头用于检测目标,所述处理器用于对目标进行面部识别,分辨出目标的人群类别,并根据目标的人群类别,采用相应的方式,通过所述扩音器和所述话筒与目标进行交互。
结合第二方面,本发明提供了第二方面的第一种可能的实施方式,其中,所述处理器中设置有语音识别模块,用于通过语音识别的方式,与目标进行语音交互。
结合第二方面,本发明提供了第二方面的第二种可能的实施方式,其中,所述处理器中设置有支持向量机分类器,用于通过面部识别,分辨出目标的人群类别。
本发明带来了以下有益效果:本发明提供的人机交互方法中,首先通过面部识别的方式,分辨出目标的人群类别,再根据目标的人群类别,采用与该人群类别相应的方式与目标进行交互。比如,以不同的年龄段来区分人群类别,那么智能机器人面对不同年龄段的目标时,就会以不同的方式与目标进行交互,从而实现了具有针对性的、多元化的交互服务,因此解决了现有的机器人提供的交互服务较为单一的问题。
为使本发明的上述目的、特征和优点能更明显易懂,下文特举较佳实施例,并配合所附附图,作详细说明如下。
附图说明
为了更清楚地说明本发明实施例的技术方案,下面将对实施例中所需要使用的附图作简单地介绍,应当理解,以下附图仅示出了本发明的某些实施例,因此不应被看作是对范围的限定,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他相关的附图。
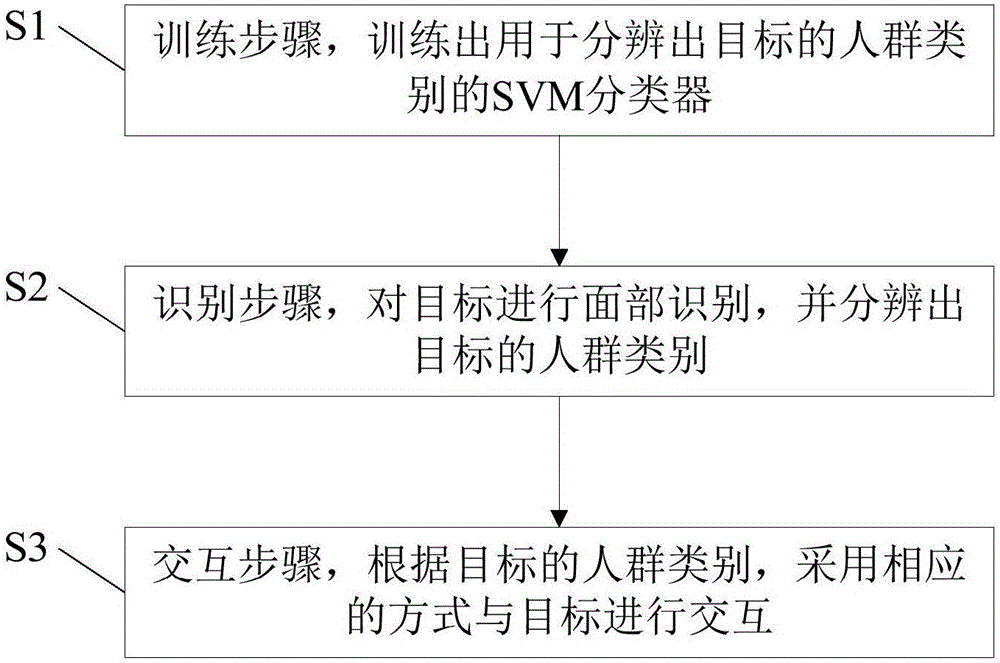
图1示出了本发明实施例一所提供的人机交互方法的流程图;
图2示出了本发明实施例中SVM分类器的示意图。
具体实施方式
为使本发明实施例的目的、技术方案和优点更加清楚,下面将结合本发明实施例中附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。因此,以下对在附图中提供的本发明的实施例的详细描述并非旨在限制要求保护的本发明的范围,而是仅仅表示本发明的选定实施例。基于本发明的实施例,本领域技术人员在没有做出创造性劳动的前提下所获得的所有其他实施例,都属于本发明保护的范围。
实施例一:
本发实施例明提供了一种人机交互方法,可应用于智能机器人的交互服务中。
如图1所示,该人机交互方法包括:
S1:训练步骤,训练出用于分辨出目标的人群类别的支持向量机(Support Vector Machine,简称SVM)分类器。
具体的,可以在智能机器人投入使用之前,对该智能机器人进行特定的训练。而在大多数情况下,可以在智能机器人之外,事先通用地训练出SVM分类器,再将训练出的SVM分类器植入到智能机器人中,这样便于将SVM分类器进行批量植入。
该训练步骤的具体过程将在本实施例末尾进行详细描述。
S2:识别步骤,对目标进行面部识别,并分辨出目标的人群类别。
本实施例中,人群类别包括特定人群和非特定人群。例如,智能机器人在超市推销老年早餐饮品的场景中,老年人即为特定人群,其他的低年龄段的人则都属于非特定人群。
本实施例中,还可以将特定人群进一步分为多个类别。例如,可以将老年人按性别再分为两个人群类别,或者结合其他条件分为更多个人群类别,而这些人群类别都属于特定人群。对于非特定人群,通常不需要进一步分类。
在实际的应用场景中,智能机器人先利用摄像头扫描面前一定视野范围内通过的人群。利用SVM分类器对视野范围内的每个人进行面部识别,从而分辨出其中的老年人,即分辨出特定人群。
对于本实施例的场景,还可以根据性别将老年人进一步分为老年男性和老年女性两个子类别。
S3:交互步骤,根据目标的人群类别,采用相应的内容与目标进行交互。
当目标为特定人群时,向目标播放音频,与目标进行语音交互。同时,智能机器人还可以做出一些动作,以动作交互的方式作为辅助。
当目标为非特定人群时,不向目标播放音频。也就是说,在本实施例中,智能机器人只与特定人群进行主动交互,不会主动与非特定人群进行交互。
因为本实施例中的特定人群还进一步分为老年男性和老年女性,所以对于这两个子类别,也可以以不同的方式进行交互。
例如,智能机器人将一位老年女性作为交互目标时,智能机器人可以由扩音器播放音频,向其推荐相关的产品和服务;同时,智能机器人的头部转向该交互目标,跟随她的运动。
之后,如果目标有所回应,则结合语音识别技术,与目标进行语音交互,进而向交互目标播放更多的音频,进行更细致的交互。
交互结束,交互目标离开时,智能机器人可以说:“谢谢,再见。欢迎再次光临。”并可以保存该交互目标的面部特征。在该交互目标下一次光顾时,智能机器人能够识别。智能机器人可以根据该交互目标的消费历史记录,分析消费偏好与倾向,向其推荐相应的产品与服务。
以下详细描述本实施例中的S1训练步骤:
首先获取各个人群类别的面部图像样本。样本可通过搜索引擎获取,或在实际应用场景中拍摄获得。
所获得的样本可能并不都是面部特写,需要进行面部图像分割。可利用图像编辑软件,进行手动图像切割,保留脖子以上的面部图像及头发。
提取各个图像样本的方向梯度直方图特征(Histogram of Oriented Gradient,简称HOG),并基于libsvm,训练SVM分类器。
SVM是一种分类算法,通过寻求结构化风险最小来提高学习机泛化能力,实现经验风险和置信范围的最小化,从而达到在统计样本量较少的情况下,亦能获得良好统计规律的目的。通俗来讲,它是一种二类分类模型,其基本模型定义为特征空间上的间隔最大的线性分类器,即支持向量机的学习策略便是间隔最大化,最终可转化为一个凸二次规划问题的求解。SVM的原理是在n维空间中找到一个分类超平面,将空间上的点分类。图2所示出的是二维空间中SVM分类器的示意图,可以看出中间的实线将两类点分开了,这条实线就是该二维空间中的分类超平面,一般而言,一个点距离超平面的远近可以表示为分类预测的确信或准确程度。SVM就是要最大化这个间隔值,即最大化两条虚线的间距,而在虚线上的点即为支持向量(Supprot Verctor)。人群类别通常默认分为两个类别,如果像本实施例这样需要识别多个人群类别,可由若干次两类识别的组合、嵌套实现。
图2中的w、b为分类器参数,在本实施例中可以是面部的鼻子、眼睛、额头、下巴等部位的HOG特征,所使用的参数越多,该n维空间的维度也就越高,运算也越复杂;x则是每张照片中相应的HOG特征。
在训练过程中所使用的libsvm,是台湾大学林智仁(Lin Chih-Jen)教授等开发设计的一个简单、易于使用和快速有效的SVM模式识别与回归的软件包,他不但提供了编译好的可在Windows系列系统的执行文件,还提供了源代码,方便改进、修改以及在其它操作系统上应用。该软件对SVM所涉及的参数调节相对比较少,提供了很多的默认参数,利用这些默认参数可以解决很多问题,并提供了交互检验(Cross Validation)的功能。
SVM分类器在实际应用时,首先需要对目标进行人脸检测。具体可以基于opencv的Haar检测器实现,调用cvHaarDetectObjects函数,加载配置文件“haarcascade_frontalface_default.xml”,检测出若干备选窗口,选取最大的窗口,作为检测到关注目标的人脸。
OpenCV(Open Source Computer Vision Library)是一个基于BSD许可(开源)发行的跨平台计算机视觉库,可以运行在Linux、Windows和MacOS操作系统上。它轻量级而且高效,由一系列C函数和少量C++类构成,同时提供了Python、Ruby、MATLAB等语言的接口,实现了图像处理和计算机视觉方面的很多通用算法。
在人脸检测过程中,使用的cvHaarDetectObjects函数以及加载配置文件“haarcascade_frontalface_default.xml”等都是公知的视觉处理工具,在此不作过多赘述。
在检测到的人脸窗口中,从图像提取HOG特征。根据HOG特征,结合预先训练得到的SVM分类器,识别人脸所属的人群类别。识别默认分为两个类别,如果像本实施例这样需要识别多个人群类别,可由若干次两类识别的组合、嵌套实现。
关注目标可被识别为类别一或类别二,亦可识别为属于类别一或类别二的程度。SVM分类器得到一个线性分类面,在分类面一侧的人脸图像到线性分类面的距离,可以刻画该人脸图像属于这一侧所属分类的程度。此种设计可基于libsvm完成。
本发明实施例提供的人机交互方法中,首先通过面部识别的方式,分辨出目标的人群类别,再根据目标的人群类别,采用与该人群类别选择是否与目标进行交互。那么智能机器人面对不同年龄段的目标时,就会只与特定类别的目标进行交互,从而实现了具有个性化的交互服务,因此提供了交互的有效性,也解决了现有的机器人提供的交互服务较为单一的问题。
实施例二:
本实施例提供一种人机交互方法,其与实施例一基本相同,其不同点在于,本实施例中的S3交互步骤为:
对属于不同人群类别的目标,分别播放不同内容的音频。
本实施例的应用场景是在银行的服务大厅,智能机器人为不同的人群类别的客户提供引导服务。
例如,智能机器人当前的交互目标是一个青年人时,智能机器人可以由扩音器播放音频,向他打招呼:“您好,请问需要哪方面的服务。”同时,智能机器人的头部俯仰并转向该交互目标,跟随他的运动。
如果交互目标停下并与智能机器人对话,则智能机器人可以利用语音识别系统,为交互目标提供更加细致的语音交互服务,而且会多介绍一些青年人感兴趣的投资、信用卡等服务内容。
又如,智能机器人当前的交互目标是一个老年人时,智能机器人可以由扩音器播放另一段音频:“您好,请问您需要帮助吗?”在之后的语音交互服务中,智能机器人会多介绍一些老年人感兴趣的与医疗、保健等相关的服务内容。
本发明实施例提供的人机交互方法中,首先通过面部识别的方式,分辨出目标的人群类别,再根据目标的人群类别,采用与该人群类别相应的方式与目标进行交互。本实施例以不同的年龄段来区分人群类别,那么智能机器人面对不同年龄段的目标时,就会以不同的方式与目标进行交互,从而实现了具有针对性的、多元化的交互服务,因此解决了现有的机器人提供的交互服务较为单一的问题。
实施例三:
本发明实施例提供一种智能机器人,主要包括处理器、摄像头、扩音器和话筒。其中,摄像头用于检测目标,处理器用于对目标进行面部识别,分辨出目标的人群类别,并根据目标的人群类别,采用相应的方式,通过扩音器和话筒与目标进行交互。
此外,智能机器人还可以根据实际需求设置面部表情灯光、各部位的运动机构等部件。
进一步的是,该智能机器人的处理器中设置有语音识别模块,用于通过语音识别的方式,与目标进行语音交互。
例如,在银行的服务大厅,智能机器人为不同的人群类别的客户提供引导服务。
当智能机器人当前的交互目标是一个青年人时,智能机器人可以由扩音器播放音频,向他打招呼:“您好,请问需要哪方面的服务。”同时,智能机器人的头部俯仰并转向该交互目标,使摄像头跟随他的运动。
如果交互目标停下并与智能机器人对话,则智能机器人可以利用语音识别系统,通过扩音器和话筒为交互目标提供更加细致的语音交互服务,而且会多介绍一些青年人感兴趣的投资、信用卡等服务内容。
当智能机器人当前的交互目标是一个老年人时,智能机器人可以由扩音器播放另一段音频:“您好,请问您需要帮助吗?”在之后的语音交互服务中,智能机器人会多介绍一些老年人感兴趣的与医疗、保健等相关的服务内容。
本实施例中,处理器中还设置有SVM分类器,该SVM分类器用于在上述应用场景中,分辨出目标的人群类别。SVM分类器的具体训练方法与实施例一中的描述相同,此处不再赘述。
本发明实施例提供的智能机器人,利用摄像头通过面部识别的方式,分辨出目标的人群类别,再由处理器根据目标的人群类别,采用与该人群类别相应的方式与目标进行交互。本实施例以不同的年龄段来区分人群类别,那么智能机器人面对不同年龄段的目标时,就会以不同的方式与目标进行交互,从而实现了具有针对性的、多元化的交互服务,因此解决了现有的机器人提供的交互服务较为单一的问题。
应当说明的是,本发明提供的上述三个实施例中,并不对智能机器人的外形进行限定,智能机器人的外形可根据实际的应用场景自由设置。另外,智能机器人的其他常规参数,也可以根据实际情况自由设定,既可以预先设定,也可以通过网络进行实时更新。
本发明上述实施例中实现的功能,如果以软件功能单元的形式实现并作为独立的产品销售或使用时,可以存储在一个计算机可读取存储介质中。基于这样的理解,本发明的技术方案本质上或者说对现有技术做出贡献的部分或者该技术方案的部分可以以软件产品的形式体现出来,该计算机软件产品存储在一个存储介质中,包括若干指令用以使得一台计算机设备(可以是个人计算机,服务器,或者网络设备等)执行本发明各个实施例所述方法的全部或部分步骤。而前述的存储介质包括:U盘、移动硬盘、只读存储器(ROM,Read-Only Memory)、随机存取存储器(RAM,Random Access Memory)、磁碟或者光盘等各种可以存储程序代码的介质。
以上所述,仅为本发明的具体实施方式,但本发明的保护范围并不局限于此,任何熟悉本技术领域的技术人员在本发明揭露的技术范围内,可轻易想到变化或替换,都应涵盖在本发明的保护范围之内。因此,本发明的保护范围应所述以权利要求的保护范围为准。
- 还没有人留言评论。精彩留言会获得点赞!