基于Hadoop和MySQL的文件分层处理方法及处理系统与流程
本发明涉及数据处理领域,具体为一种基于Hadoop和MySQL的文件分层处理方法及处理系统。
背景技术:
在日志处理中,经常遇到要处理跨度几年甚至十几年的日志文件,文件总量经常达到T级甚至P级,处理过程中一般进行大颗粒度(以月为时间单位)的统计计算,如果需要进行小颗粒度统计(以小时为单位),无论是速度还是效率都会差很多。
如公开号为CN 101192227B的专利公开了一种基于分布式计算网络的日志文件分析方法和系统。所述方法包括:将用户标识与相应的日志信息存储在日志文件中;将所述日志文件划分为多个目标文件,所述目标文件中含有相同用户标识的日志信息;使用两个以上的节点分别对所述目标文件进行分析并得到分析结果;合并各节点的分析结果。这样,通过用户标识在不同的日志文件中建立关联,并可进一步分析用户访问网站不同内容之间的关系
如公开号为CN 100375047的专利公开了一种计算机日志的管理方法,至少包括如下步骤:在计算机上保存所形成的计算机日志文件;将不同计算机日志文件所包含的不同格式的日志记录解析成具有统一格式的日志记录;然后对统一格式的日志记录进行管理。其中可以进一步包括对具有统一格式的日志记录进行筛选和显示的步骤。该发明通过对日志文件所包含的具有不同格式的日志记录采取不同的解析方法解析成具有统一格式的日志记录,从而可以在一个管理主机上对所有被管理主机上的所有日志文件进行集中统一的管理。因此,该发明极大地提高了日志管理的方便性,降低了管理操作的难度,并提高了管理效率。
如上述两个公开的专利采用的文件处理的系统均是现有技术常采用的系统及方法,都存在相同的缺点,处理总量大的文件时计算速度慢、结果输出不方便、数据操作不灵活等问题。
技术实现要素:
本发明的目的是提供一种计算速度更快、结果输出更方便的基于Hadoop和MySQL的文件分层处理方法及处理系统。
本发明的上述技术目的是通过以下技术方案得以实现的:
基于Hadoop和MySQL的文件分层处理方法,包括如下步骤:
步骤1,收集并解析数据;
步骤2,对步骤1中解析后的数据通过MapReduce进行预处理计算;
步骤3,将步骤2中的预处理计算结果的数据存储在MySQL中。
作为对本发明的优选,步骤3之后还包括如下步骤:对存储在MySQL中的预处理计算结果的数据进行再次处理并存储在MySQL中。
作为对本发明的优选,步骤3之后还包括如下步骤:对存储在MySQL中的数据进行前端展示。
作为对本发明的优选,步骤1中收集的数据为日志文件数据。
作为对本发明的优选,步骤1-3定期执行一次。
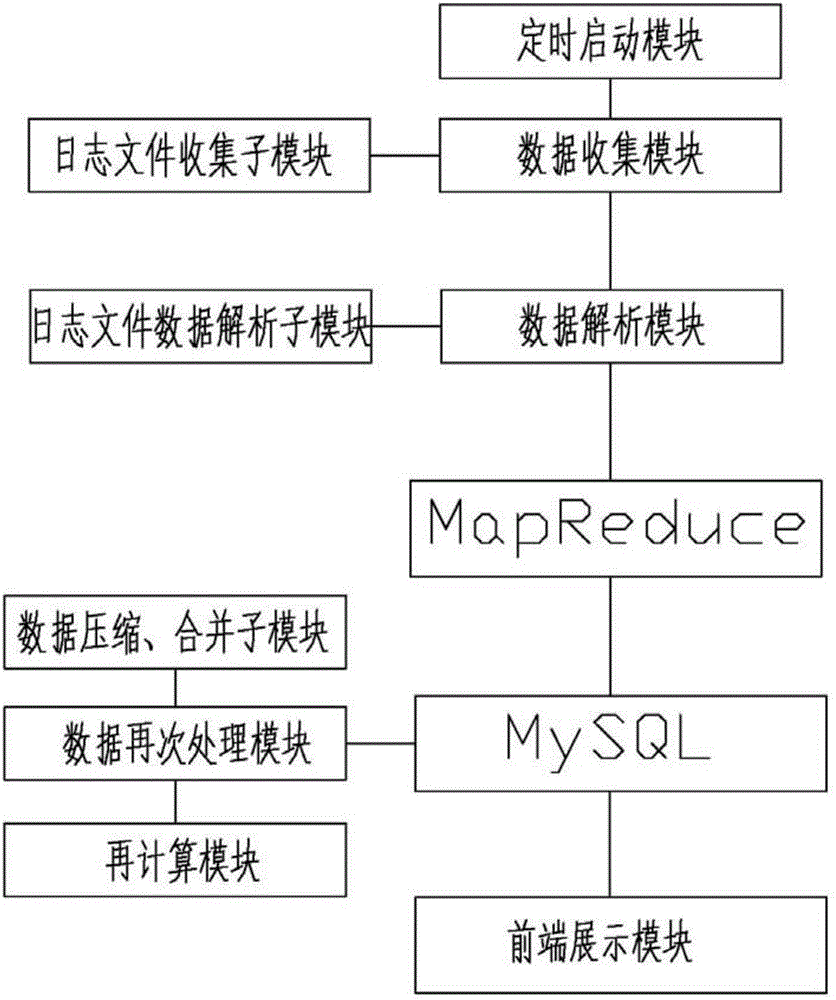
基于Hadoop和MySQL的文件分层处理系统,该系统具有Hadoop和MySQL,所述Hadoop具有HDFS和MapReduce,该系统还包括数据收集模块、数据解析模块,其中,
所述数据收集模块用于收集文件数据;
所述数据解析模块用于对所述数据收集模块收集的文件数据解析;
MapReduce用于对所述数据解析模块解析后的数据进行预处理计算;
MySQL用于存储数据。
作为对本发明的优选,所述数据收集模块包括日志文件收集子模块,所述数据解析模块包括日志文件数据解析子模块,其中,
所述日志文件收集子模块用于收集日志文件数据;
所述日志文件数据解析子模块用于对所述日志文件收集子模块手机的日志文件数据解析。
作为对本发明的优选,该系统还包括定时启动模块,所述定时启动模块用于所述数据收集模块定时启动收集文件数据。
作为对本发明的优选,该系统还包括数据再次处理模块,所述数据再次处理模块用于对MySQL中存储的MapReduce预处理计算结果的数据进行再次处理并存储在MySQL中。
作为对本发明的优选,所述数据再次处理模块还包括数据压缩、合并子模块和再计算子模块,其中,
所述数据压缩、合并子模块用于对MySQL中存储的MapReduce预处理计算结果的非活跃数据进行压缩、合并并存储在MySQL中;
所述再计算子模块用于对MySQL中存储的数据进行再次计算并存储在MySQL中。
本发明采用分段计算方式,首先利用MapReduce计算,分段处理大批量的原始数据,把计算结果存储在关系型数据库(MySQL)中,在后阶段的计算就只要针对前次结果进行再计算,这个设计可以把原来一次大规模的计算工作分到多次的中小规模的计算中,使计算速度更快,结果输出更方便。
附图说明
图1是本发明实施例1的流程图;
图2是本发明实施例2的系统模块图。
具体实施方式
以下具体实施例仅仅是对本发明的解释,其并不是对本发明的限制,本领域技术人员在阅读完本说明书后可以根据需要对本实施例做出没有创造性贡献的修改,但只要在本发明的权利要求范围内都受到专利法的保护。
实施例1,基于Hadoop和MySQL的文件分层处理方法,包括如下步骤,
步骤1,收集并解析数据;
步骤2,对步骤1中解析后的数据通过MapReduce进行预处理计算;
步骤3,将步骤2中的预处理计算结果的数据存储在MySQL中。
Hadoop是一个开源的分布式系统基础架构,Hadoop的框架最核心的设计就是:HDFS和MapReduce,HDFS为海量的数据提供了存储,则MapReduce为海量的数据提供了计算,这两个核心在日志处理中经常会用到,在平常的处理过程中,中间结果是不保存的,每次只输出最终结果,而本申请中,则会利用到MySQL(关系型数据库),用于数据的存储,在文件处理中,经常遇到要处理跨度几年甚至十几年的文件,文件总量经常达到T级甚至P级,在这种情况下,通常采用MapReduce模型来处理,处理过程中一般进行大颗粒度(以月为时间单位)的统计计算,如果需要进行小颗粒度统计(以小时为单位),无论是速度还是效率都会差很多,那么配合MySQL(关系型数据库),就可以很好地解决这些问题,通过MapReduce模型分次多进行预处理数据,把预处理数据结果保存到MySQL(关系型数据库)中;把一次、大批量计算分解为多次、小批量计算,最后直接在MySQL(关系型数据库)中生成报表,当然这些需要第一步骤的对需要进行处理的文件的数据进行收集并解析。
对上述方案进一步的优化,步骤3之后还包括如下步骤:对存储在MySQL(关系型数据库)中的预处理计算结果的数据进行再次处理并存储在MySQL(关系型数据库)中。也即对MySQL(关系型数据库)中的预处理计算结果的数据进行再次的处理,再次处理包括两方面,一方面是对MySQL(关系型数据库)存储的预处理计算结果的数据中的非活跃数据,采用压缩、合并的方式,对数据进行再处理,减少存储空间,并将处理后的数据继续存储在MySQL(关系型数据库)中;另一方面,是对MySQL(关系型数据库)存储的包括压缩、合并后的再次处理的数据及MySQL(关系型数据库)中的预处理计算结果的数据根据需求再次进行计算,并存储在MySQL(关系型数据库)中。
更进一步,步骤3之后还包括如下步骤:对存储在MySQL中的数据进行前端展示。主要是将MySQL中的数据更加实际需求进行前端展示。该步骤和上述的再处理计算的步骤结合使用,使得前端展示更多的有用数据,也更加快捷方便。
对上述方案的进一步细化,步骤1中收集的数据为日志文件数据。这个设置是为了更好地对日志文件进行处理,在日志处理中,更加容易遇到要处理跨度几年甚至十几年的日志文件,文件总量经常达到T级甚至P级,通常采用MapReduce模型来处理,处理过程中一般进行大颗粒度(以月为时间单位)的统计计算,如果需要进行小颗粒度统计(以小时为单位),无论是速度还是效率都会差很多,此时,通过本申请的方案就能有效处理这些日志文件。
还有一个优选方式,步骤1-3定期执行一次。也就是进行按照需求定时进行步骤1-3,具体来说,如果以一天为定期的期限,那么,如果采用本发明中的处理方法,可以设定每天定时通过MapReduce模型处理当天的数据,把预处理结果保存到MySQL(关系型数据库)中;把一次、大批量计算分解为多次、小批量计算,最后直接在MySQL(关系型数据库)中生成报表,同时,对存储在MySQL(关系型数据库)中的预处理计算结果的数据进行再次处理,在本发明中,MySQL(关系型数据库)中的数据进行操作也远比NoSQL数据库中方便、灵活。
如图1所示的流程图,就形成一个比较完整的对日志文件基于Hadoop和MySQL的分层处理流程,首先,每天进行一次日志文件收集并解析数据;通过MapReduce模型处理当天的数据,把预处理结果保存到MySQL(关系型数据库)中;把一次、大批量计算分解为多次、小批量计算,最后直接在MySQL(关系型数据库)中生成报表;然后,对MySQL(关系型数据库)中预处理计算结果进行再次处理,再次处理包括两方面,一方面是对MySQL(关系型数据库)存储的预处理计算结果的数据中的非活跃数据,采用压缩、合并的方式,对数据进行再处理,减少存储空间,并将处理后的数据继续存储在MySQL(关系型数据库)中;另一方面,是对MySQL(关系型数据库)存储的包括压缩、合并后的再次处理的数据及MySQL(关系型数据库)中的预处理计算结果的数据根据需求再次进行计算,并存储在MySQL(关系型数据库)中,当然,再次处理是根据使用的不同需求,选择必要的时间进行此操作,另外,再次处理中的计算也可以通过MapReduce来进行计算,或者采用别的现有模型进行计算,后者两者结合使用;前端展示放在可放在最后,展示出最终所需的数据。这样就形成了一个完整的处理流程。
基于上述的流程模型,下面举一个公司实际运用的例子:
现在要分析某公司近5年来各应用系统(WEB应用)的使用情况,包括访问数排名,使用时间段人数排名,总时间排名等,假设每天的日志量为10G,5年的日志总量就有将近20T,如果直接使用MapReduce来统计,需要大量的时间多次进行MapReduce的计算。
如果在每天运行分析统计,例如,在白天分析前一天的日志或者在零点分析当天的日志,每次花费的时间要远小于全量日志,而把每天的每小时(甚至每分钟),各系统、甚至各用户的访问情况都记录到MySQL(关系型数据库)中,每天的数据量会减少1000倍以上,最后需要统计任意时间段的数据都可以从MySQL(关系型数据库)中计算出来,即便处理跨度几年甚至十几年的日志文件,都会非常方便,
综上,本发明体现了如下几个优点:
1、减少单次计算时间;
2、展示结果方便灵活;
3、如果不需要保留历史数据,还可以大大减少存储空间。
实施例2,基于Hadoop和MySQL的文件分层处理系统,该系统具有Hadoop和MySQL,所述Hadoop具有HDFS和MapReduce,该系统还包括数据收集模块、数据解析模块,其中,
所述数据收集模块用于收集文件数据;
所述数据解析模块用于对所述数据收集模块收集的文件数据解析;
MapReduce用于对所述数据解析模块解析后的数据进行预处理计算;
MySQL用于存储数据。
上述系统,可适用于实施例1的件分层处理方法。
Hadoop是一个由Apache基金会所开发的分布式系统基础架构。MySQL是一个关系型数据库管理系统,由瑞典MySQL AB公司开发,目前属于Oracle旗下产品。MySQL最流行的关系型数据库管理系统,在WEB应用方面MySQL是最好的RDBMS(Relational Database Management System,关系数据库管理系统)应用软件之一。MySQL是一种关联数据库管理系统,关联数据库将数据保存在不同的表中,而不是将所有数据放在一个大仓库内,这样就增加了速度并提高了灵活性。MySQL所使用的SQL语言是用于访问数据库的最常用标准化语言。MySQL软件采用了双授权政策,它分为社区版和商业版,由于其体积小、速度快、总体拥有成本低,尤其是开放源码这一特点,一般中小型网站的开发都选择MySQL作为网站数据库。
MySQL(关系型数据库)不仅可以存储来自于MapReduce进行预处理计算后的结果数据,也能存储各种其他的数据。
为了使得上述的系统能够满足日志文件的处理,则进一步进行如下的系统优化:
所述数据收集模块包括日志文件收集子模块,所述数据解析模块包括日志文件数据解析子模块,其中,
所述日志文件收集子模块用于收集日志文件数据;
所述日志文件数据解析子模块用于对所述日志文件收集子模块手机的日志文件数据解析。
该系统还包括定时启动模块,所述定时启动模块用于所述数据收集模块定时启动收集文件数据。所述定时启动模块主要是一个定期进行数据的开端,例如以天作为时间间隔,每天白天进行收集前一天的日志文件数据或者每天零点收集当天的日志文件数据,然后通过日志文件数据解析子模块进行解析,接着通过MapReduce对所述日志文件数据解析子模块解析后的数据进行预处理计算,并将MapReduce预处理计算的结果数据存储在MySQL(关系型数据库)中,这些预处理的数据分次进行的方式,可以简化后面处理时间久、文件总量大的日志文件,这些数据存储起来,相当于把中间结果保存在MySQL(关系型数据库),最后需要统计任意时间段的数据都可以从MySQL(关系型数据库)中计算出来,并进行展示。
进一步地该系统还包括数据再次处理模块,所述数据再次处理模块用于对MySQL中存储的MapReduce预处理计算结果的数据进行再次处理并存储在MySQL中。
所述数据再次处理模块还包括数据压缩、合并子模块和再计算子模块,其中,
所述数据压缩、合并子模块用于对MySQL(关系型数据库)中存储的MapReduce预处理计算结果的非活跃数据进行压缩、合并并存储在MySQL(关系型数据库)中;
所述再计算子模块用于对MySQL(关系型数据库)中存储的数据进行再次计算并存储在MySQL中。
所述再计算子模块仍然可以包含MapReduce这个模型,当然可以加入其它各种根据不同需求而设置的计算模型,实现各种不同的计算,可以统计各种跨年度大的、数据总量大的信息。
当然,整个系统还需要配置用于前端展示数据的前端展示模块。展示MySQL(关系型数据库)中的各种数据。
整个系统可以采用如下的一种流程运行:
结合MySQL(关系型数据库)的Hadoop模型日志处理流程:收集、解析数据/预处理(每天)——>结果保存在MySQL(关系型数据库)中——>根据具体需求在数据库中进行再次处理——>前端展示。
利用本发明系统就可以采用分段计算方式,首先利用MapReduce计算,分段处理大批量的原始数据,把计算结果存储在MySQL(关系型数据库)中,在后阶段的计算就只要针对前次结果进行再计算,这个设计可以把原来一次大规模的计算工作分到多次的中小规模的计算中,使计算速度更快,结果输出更方便。
本文中所描述的具体实施例仅仅是对本发明精神作举例说明。本发明所属技术领域的技术人员可以对所描述的具体实施例做各种的修改或补充或采用类似的方式替代,但并不会偏离本发明的精神或者超越所附权利要求书所定义的范围。
- 还没有人留言评论。精彩留言会获得点赞!