含意配对扩展装置、用于其的计算机程序以及提问应答系统的制作方法
本发明涉及自然语言处理,特别是,涉及高效地生成某个模式蕴含另一个模式那样的两个语言模式的配对的技术。
背景技术:
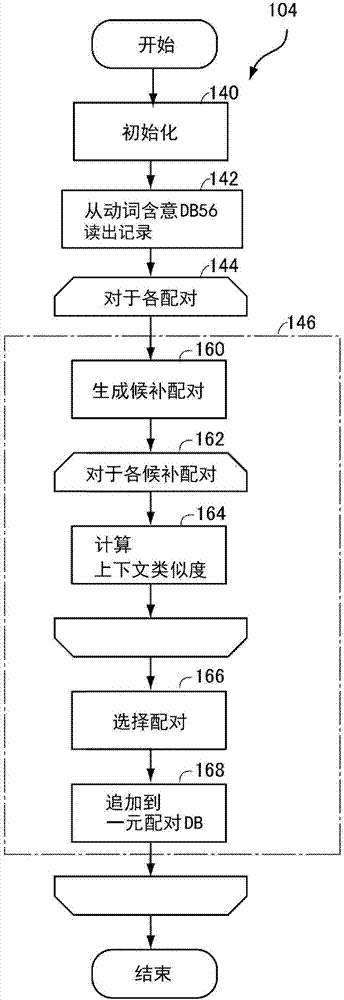
:在提问应答系统中,例如,对于“是什么引起肺癌?”这样的提问,典型地,作为回答可得到“公害引起肺癌”这样的句子。这是因为,这两个句子共同具有“引起(肺癌)”这样的表现。但是,适合作为回答的句子并不限于像这样与提问具有共同的表现的句子。例如,可以想到“吸烟导致肺癌”这样的表现也是适合作为回答的句子。为了得到这样的回答,需要能够将“a引起b”用“a导致b”来换个说法的知识。在此,a以及b是变量,能够置换为任意的单词。在本说明书中,将像这样在多个表现中共同地出现的类型称为语言模式或简称为模式。更详细地,在本说明书中,由谓语和n个(n为0以上的整数)项的组合构成的表现称为n项语言模式。“a引起b”是由“引起”这样的谓语、和变量项a以及b所构成的两个项的组合构成的2项语言模式。在两个语言模式(模式配对)处于含意关系的情况下,在本说明书中将它们的模式配对称为含意模式配对(简称为“含意配对”)。在提问应答系统中,期望高精度地收集许多含意配对。作为用于获得含意配对的现有技术,存在后述的非专利文献1。非专利文献1所记载的技术通过如下方式来收集处于含意关系的模式配对。通过预先以人工方式收集处于含意关系的模式配对,从而构筑学习数据。针对该学习数据,将n-gram、分布类似度等的分数作为特征量,进行在给出两个语言模式时判定一方是否蕴含另一方的判定器的机器学习。若判定器的学习结束,则从包括许多的句子的文集随机地生成大量的含意配对的候补。对这些候补的每一个进行基于判定器的判定。结果,通过收集被判断为处于含意关系的模式配对,从而能够收集学习数据中没有的新的含意配对。在先技术文献专利文献非专利文献1:julienkloetzer、鸟泽健太郎、stijndesaeger、佐野大树、桥本力、后藤淳、含意关系模式配对的大规模获得、2013年度信息处理学会关西支部支部大会(2013年)技术实现要素:发明要解决的课题通过现有技术,能够不经由人工地收集非常多的含意配对。但是,在使用基于机器学习的判定器的情况下,不能预测具体能够获得什么样的配对,也不能保证精度。因此,在开发提问应答系统时,存在必要的换言模式配对(含意配对)未被包罗的情况下的应对困难的问题。故此,本发明的目的在于,提供一种能够对现有的含意配对进行扩展并能够预测能够获得什么样的含意配对、并且还能够在某种程度上保证其精度那样的含意关系配对扩展装置。用于解决课题的技术方案本发明的第一方面涉及的含意配对扩展装置通过从m项的含意配对生成n项的含意配对,从而对含意配对进行扩展。其中,m以及n是0以上且满足m<n的整数。含意配对的每一个包含第一语言模式与第一语言模式蕴含的第二语言模式的配对。含意配对扩展装置包括用于存储用于从m项的含意配对生成n项的含意配对的生成规则的生成规则存储单元。该生成规则规定:为了应用该生成规则,m项的含意配对要满足的条件;以及包含在该条件得到满足时针对构成m项的含意配对的各个语言模式追加n-m个变量的语言模式的变形规则。含意配对扩展装置还包括:判定单元,其用于接受m项的含意配对,并针对该m项的含意配对,对存储在生成规则存储单元中的生成规则的每一个判定该生成规则的条件是否被m项的含意配对所满足;以及规则应用单元,其用于将由判定单元判定为条件得到满足的生成规则的变形规则应用于构成m项的含意配对的各语言模式,从而生成n项的含意配对。优选地,m为0,m项的含意配对分别是由谓语构成的谓语的含意配对。更优选地,n为1。含意配对扩展装置还可以包括:传递性应用单元,其用于通过对m项的含意配对应用传递性,从而对m项的含意配对进行扩展。优选为,含意配对扩展装置还包括:传递性应用单元,其用于通过对由规则应用单元生成的n项的含意配对应用传递性,从而对n项的含意配对进行扩展。本发明的第二方面涉及的计算机程序使计算机作为任一个含意配对扩展装置的全部单元而发挥功能。本发明的第三方面涉及的提问应答系统包括:含意配对存储单元,其用于对由上述的任一个含意配对扩展装置进行扩展得到的含意配对进行存储;文档存储单元,其存储有多个文档;模式提取单元,其用于接受提问,并通过对该提问进行句法分析,从而提取针对该提问的回答应具有的语言模式;模式扩展单元,其用于使用存储在含意配对存储单元中的含意配对对由模式提取单元提取出的语言模式的每一个进行扩展;检索单元,其用于从存储在文档存储单元中的文档检索与由模式扩展单元扩展得到的语言模式相匹配的表现,并计算出表示作为针对提问的回答的适合度的分数;以及选择单元,其用于在由检索单元检索的回答候补之中,优先在检索时相匹配的语言模式所包含的变量的数目最多的回答候补,使用分数来选择回答。附图说明图1是本发明的第一实施方式涉及的含意模式配对扩展装置的框图。图2是示出实现图1所示的一元配对生成部的程序的控制结构的流程图。图3是图1所示的一元配对扩展部的框图。图4是示出实现图3所示的一元配对扩展部中的传递性配对追加部的程序的控制结构的流程图。图5是示出实现图1所示的二元配对追加部的程序的控制结构的流程图。图6是示出图5所示的二元配对的生成处理的详情的流程图。图7是示出通过实验得到的一元配对全体的评价的曲线图。图8是示出通过实验得到的一元配对中的500个例子的评价的曲线图。图9是示出通过实验得到的二元含意配对中的500个例子的评价的曲线图。图10是示出本发明的第二实施方式涉及的提问应答系统的概略结构的功能框图。图11是实现本发明的第一实施方式涉及的含意模式扩展装置以及第二实施方式涉及的提问应答系统的计算机系统的外观图。图12是示出图11所示的计算机的内部结构的硬件框图。具体实施方式在以下的说明以及附图中,对于同一部件标注同一附图标记。因此,不再重复对他们的详细的说明。[用语的说明]在本说明书中,所谓“一元模式”,是指由一个变量和谓语构成的模式,在日语的情况下还包括连结它们的助词。上面举出的“引起a”、“导致a”等就是其例子。所谓“一元含意模式配对”,是指如下的两个一元模式,即,处于一方蕴含另一方那样的意思关系的两个一元模式。“引起a”和“导致a”这样的配对就是一个例子。也简称为“一元配对”。所谓“二元模式”,是指由两个变量和谓语构成的模式,在日语的情况下还包括连结它们的助词。“a引起b”、“a导致b”等就是其例子。所谓“二元含意模式配对”,是指如下的两个二元模式,即,处于一方蕴含另一方那样的意思关系的两个二元模式。由“a导致b”和“a引起b”构成的配对就是一个例子。也简称为“二元配对”。所谓“n元模式”,一般是指由n项变量、谓语、以及连结它们的助词构成的模式。所谓n元含意模式配对(称为“n元配对”),是指如下的n元模式的配对,即,一方蕴含另一方那样的n元模式的配对。[第一实施方式]<基本思想>第一实施方式从记述了动词之间的含意关系的现有的动词含意数据库(db)生成一元配对。在这样得到的一元配对进一步追加从现有的一元模式db生成的一元配对。通过大致以下的方法对得到的多个一元配对进一步进行扩展。详情在后面进行叙述。(1)将谓语部变形为被动态(2)将谓语部变形为可能型能够对各配对中的仅一方、仅另一方、以及双方实施这些变形。进而,对于构成各配对的每个一元元素,将其自身和对其自身进行上述的变形而得到的一元元素进行组合而生成新的一元配对。接着,使用传递性对一元配对进行扩展。即,在存在两组一元配对p→q和q→r的情况下,从它们生成p→r。最后,对于扩展后的一元配对的每一个,针对双方的模式追加新的项,从而扩展为二元。作为追加新的项的方法,具有如下方法:追加新的项,使得原来的一元模式成为谓语部的方法;追加新的项,使得原来的一元模式成为定语从句的方法。作为前者的例子,存在如下变形,即,在“导致a”的前头添加“a”而成为“a导致b”。作为后者的例子,存在如下变形,即,将“导致a”作为定语从句并在末尾添加“a”而成为“导致b的a)”那样的例子。详情在后面进行叙述。<结构>在图1示出本发明的一个实施方式涉及的含意模式配对扩展装置50的框图。参照图1,含意模式配对扩展装置50用于使用第一一元db52、第二一元db54、动词含意db56、以及上下文类似度存储部58来输出扩展一元配对db60以及扩展二元配对db62。第一一元db52以及第二一元db54均为保存有现有的一元配对的数据库。它们可以是以任何方式得到的。既可以是通过手工作业制作的,也可以是通过某种处理以机器方式生成的。另外,在该实施方式中,作为一元db而使用了第一一元db52以及第二一元db54,但是它们的数目并没有限制。也可以是一个,还可以是三个以上。假设使用动词含意db56来生成一元配对的情况下,也可以完全不使用一元db。动词含意db56记录有多个预先准备的处于含意关系的动词的配对。动词含意配对的一个例子是“导致→引起”这样的动词含意配对。作为该数据,在本实施方式中,使用了申请人以人工方式构筑的动词含意数据(https://alaginrc.nict.go.jp/)。该动词含意db56收录有52689对的动词含意配对。记录在上下文类似度存储部58中的数据用于算出两个单词的上下文类似度。所谓上下文类似度(contextsimilarity),简单来说,是示出两个单词出现的文章上的位置类似到何种程度的尺度。上下文类似度使用两个单词共现程度来算出,并通过以下的顺序得到。求出单词vi与其各上下文单词vj之间的共现程度fij。所谓单词vi的上下文单词,是指出现在单词vi的出现位置的上下文内的全部单词。上下文的范围可以任意地决定,例如,可以想到该单词出现的句子内、以该句子为中心的前后给定数目的句子内、同段落内的句子等。将通过该处理得到的共现程度fij按照上下文单词vj的顺序进行排列,从而得到向量。该向量能够认为是针对单词vi的上下文向量。将该单词vi的上下文向量记为向量fi*。向量fi*是由共现程度fij中的单词vi和与其上下文单词对应的值的全部构成的向量。对于全部单词的集合v内的单词vi与单词vj的全部组合,计算该向量fi*以及fj*的余弦类似度,将该值作为上下文类似度ωij。在上下文类似度存储部58预先存储有按照上述的顺序算出的任意两个单词间的上下文类似度。含意模式配对扩展装置50包括:对于保存在第一一元db52以及第二一元db54的一元配对,变形为在含意模式配对扩展装置50中处理的格式,并且作为表示各一元配对的数据源的值附加各一元db的标识符并进行输出的一元配对追加部100;保存一元配对追加部100输出的一元配对的一元配对db102;以及根据保存在动词含意db56的各个动词含意配对,使用存储在上下文类似度存储部58中的上下文类似度来生成一元配对,并追加输出到一元配对db102的一元配对生成部104。含意模式配对扩展装置50还包括:以机器可读的形式保存单词的汉字及其读音的汉字词典106;用于对保存在一元配对db102中的各个一元配对一边参照汉字词典106一边进行扩展处理,输出多个一元配对的一元配对扩展部108;存储有用于从一元配对生成二元配对的生成规则的二元配对生成规则存储部110;以及用于对记录在扩展一元配对db60中的各个一元配对应用存储在二元配对生成规则存储部110中的生成规则,从而生成二元配对,并输出到扩展二元配对db62的二元配对追加部112。参照图2,图1所示的一元配对生成部104能够通过计算机程序来实现。该程序包括:与程序开始同时进行存储区域的确保以及初始化等的步骤140;从动词含意db56将动词含意配对全部读出的步骤142;以及对动词含意配对的每一个执行处理146的步骤144。处理146包括:对构成处理对象的动词含意配对的动词的每一个分别赋予“aが(a接主格助词)”、“aに(a接受格助词)”、“aを(a接宾格助词)”、以及“aで(a接补格助词)”,从而生成多个一元含意模式的候补配对的步骤160;针对这样得到的各个候补配对,在构成该候补配对的配对彼此之间进行上下文类似度计算处理164的步骤162;选择配对彼此之间的上下文类似度最高的配对的步骤166;以及将选择的配对作为新的一元配对而追加到一元配对db102的步骤168。对于这样得到的模式配对,优选通过人工方式检查作为该含意配对的妥当性,删除不合适的模式配对。此时,为了从在后面的处理中得到的模式配对中删除不合适的模式配对,更优选将像这样应删除的模式配对作为反例而进行保存。另外,虽然在后述的各处理中没有特别叙述,但是在登记新的一元配对或二元配对时,与像这样预先保存的或预先准备的反例进行对照,使得从登记中除去反例。参照图3,图1所示的一元配对扩展部108能够通过计算机程序来实现。该程序使计算机作为以下各部发挥功能:记录读出部180,其从一元配对db102读出一元配对的记录(record);被动态/可能型追加部182,其对于由记录读出部180读出的各个一元配对,对构成配对的模式的每一个进行向被动态的变形以及向可能型的变形,将由它们的组合得到的新的一元配对与原来的一元配对一同追加到扩展一元配对db60;以及传递性配对追加部184,其在被动态/可能型追加部182对扩展一元配对db60的一元配对的追加完成之后,对存储在扩展一元配对db60中的、第一一元配对的后半部与第二一元配对的前半部一致的一元配对进行检索,并针对它们的组合的每一个,将第一一元配对的前半部和第二一元配对的后半部进行组合而生成新的一元配对,并追加到扩展一元配对db60。另外,在本实施方式中,在被动态/可能型追加部182的处理之前,通过将谓语的拼写变体(spellingvariations)以及语尾的变形应用于各一元配对,从而进一步对一元配对进行扩展。作为对于拼写变体的应对,参照汉字词典106,制作将用汉字书写的谓语变换为假名的模式,并追加具有新的模式的一元配对。在此,还同时生成像“aが起きる→aがおきる”以及“aがおきゐ→aが起きゐ”这样的“汉字→假名”以及“假名→汉字”这样的一元配对,并追加到扩展一元配对db60。这样的配对严格来说不能说处于“蕴含(entailment)”关系。但是,可以想到,在提问应答中的“换句话说”这样的上下文中,存在这样的配对是更有利的。传递性配对追加部184可通过计算机程序来实现。在图4中以流程图形式示出这样的计算机程序的控制结构。该程序包括从扩展一元配对db60将一元配对全部读出的步骤220和对读出的各一元配对执行处理224的步骤222。处理224包括:将具有与处理对象的一元配对的后半部一致的前半部的一元配对全部从扩展一元配对db60读出的步骤250;以及对在步骤250中读出的每个一元配对执行处理254的步骤252。以下,为了进行说明,将在步骤222中作为处理对象而选择的配对称为第一一元配对,将在步骤252中作为处理对象而选择的配对称为第二一元配对。处理254包括:步骤280,判定是否第一一元配对的谓语部为「汉字→假名」的组合而第二一元配对的谓语部为「假名→汉字」的组合,如果判定结果为肯定,则结束处理,并将处理转移到下一个第二一元配对;步骤282,在步骤280的判定结果为否定时,判定第一一元配对的前半部是否与第二一元配对的后半部一致;步骤284,在步骤282的判定为“否”时,将由第一一元配对的前半部和第二一元配对的后半部构成的配对作为新的一元配对追加到扩展一元配对db60中;以及步骤286,在步骤282的判定为肯定时,针对第一一元配对以及第二一元配对的每一个,将相当于其对偶的配对追加到扩展一元配对db60中。步骤284的处理的结果是,从p→q这样的配对和q→r这样的配对通过所谓的传递性(transitivity)生成p→r这样的配对,并追加到扩展一元配对db60中。步骤286的处理并不是基于传递性的处理。步骤286的处理是在如下的情况下进行:第一一元配对的后半部与第二一元配对的前半部相等,并且第一一元配对的前半部与第二一元配对的后半部相等。即,是第一一元配对与第二一元配对彼此相反的情形。即,存在p→q和q→p这两者。这两个一元配对同时存在的情况可以认为在这两个一元配对之间与所谓的“同值”同样的关系成立。因此,在本实施方式中,对于这两个一元配对的双方,生成相当于在逻辑学中所说的“对偶”的一元配对,并追加到扩展一元配对db60中。即,对p→q追加这样的一元配对(表示否定),对q→p这样的一元配对追加这样的一元配对。另外,一般来说,如果某个命题为真,其对偶也为真,因此如果是p→q这样的一元配对,可以认为可以无条件地追加其对偶的这样的一元配对。但是,在本实施方式中处理的是自然语言,假定存在某个一元配对,其对偶实际上也不一定正确。因此,在此,只有在两个一元配对彼此为同值时追加它们的对偶。参照图5,在本实施方式中,图1所示的二元配对追加部112也可通过计算机程序来实现。该程序包括:步骤320,从扩展一元配对db60读出全部的一元配对;以及步骤322,针对所读出的各个一元配对,执行从该一元配对生成二元配对的处理324。参照图6,实现图5的处理324的程序包括:步骤350,从图1所示的二元配对生成规则存储部110将二元配对的生成规则全部读出;以及步骤352,针对处理对象的一元配对,执行应用在步骤350中读出的各生成规则来生成二元配对并追加到扩展二元配对db62的处理354。在此,各二元生成规则由为了将该二元规则应用于一元配对而需要一元配对满足的条件、和记述了在条件成立时如何对构成一元配对的模式配对进行变形来生成二元配对的命令部构成。命令部实际上记述了句子的变形规则。处理354包括:步骤380,判定要应用处理对象的二元配对生成规则的条件是否为处理中的一元配对所满足,如果不满足,则结束规则的应用;步骤382,在步骤380的判定为肯定时,针对在图5的步骤322中选择的一元配对应用在图6的步骤352中选择的二元配对生成规则,从而生成二元配对;以及步骤384,将在步骤382中生成的二元配对追加到扩展二元配对db62,并结束该二元配对生成规则的应用。另外,存储在二元配对生成规则存储部110中的二元配对生成规则在本实施方式中以“如果-则(if-then)”形式进行记载。一个二元配对生成规则记载为,通过应用于一个一元配对,从而生成一个二元配对。在本实施方式中,二元配对生成规则的主要规则如下。(1)假使在一元配对的助词不是“が”的情况下,在一元配对的双方附加“aが”。结果,例如,从“aを使う(使用a)→aを用いる(采用a)”这样的一元配对生成“aがbを使う(a使用b)→aがbを用いる(a采用b)”这样的二元配对。另外,在此将规则应用之前记载为“a”的变量记载为“b”,这是为了使二元配对的形式容易理解,并非由b表示的变量变为其它的变量。这在以下的记载中也是同样的。(2)假使在一元配对的助词不是“が”的情况下,在一元配对中的前半部的模式追加“aが”,在后半部的模式的前头附加“aが”并删除“bを”,在末尾附加“b”。对于与(1)相同的例子,可生成“aがbを使う(a使用b)→aが用いるb(a所采用的b)”这样的二元配对。(3)假使在一元配对的助词不是“が”的情况下,在前半部的前头附加“aが”,在后半部的末尾附加“a”。以上面的例子来说,生成“aがbを使う(a使用b)→bを用いるa(采用b的a)”这样的二元配对。(4)假使在一元配对的助词不是“が”的情况下,在前半部的前头附加“aが”,并删除“bを”而在末尾附加“b”。在后半部的前头附加“aが”。以上面的例子来说,可得到“aが使うb(a所使用的b)→aがbを用いゐ(a采用b)”。将同样的变换规则应用于一元配对的前半部或后半部或这两者,从而生成新的二元配对。关于成为应用的条件的助词,在代替“が”而将“で”设为条件的情况下,也能够使用同样的生成规则来生成二元配对。在此,还制作将相同的一元模式组合而成的一元配对,并进行与上面同样的操作来制作二元配对。例如,从“aを使う(使用a)”这样的模式生成“aがbを使う(a使用b)→bを使うa(使用b的a)”这样的二元配对,并保存在扩展二元配对db62。另外,在本实施方式中,在程序的外部作为数据而具有二元配对生成规则,但是本发明并不限定于那样的实施方式。也可以将生成规则以程序的形式进行记载,并在程序执行时动态地载入。或者,也可以将生成规则以命令形式依次记载于程序的主体。在从外部读入生成规则的情况下,也可以预先将每个规则准备为独立的文件,还可以将全部规则汇总在一个文件中。不管怎样,各规则只要预先准备为条件部与该条件部被一元配对所满足时要应用于各模式的变形规则的组,并以某种形式准备即可。如前所述,作为规则的形式,可以是数据形式,也可以是程序形式。此外,也可以将规则以算法形式嵌入到程序主体中,还可以以程序形式保存为外部文件使得在执行时从外部以引用的形式读入。<动作>参照图1,上述的含意模式配对扩展装置50如下执行动作。另外,在含意模式配对扩展装置50执行以下的处理之前,需要预先对第一一元db52、第二一元db54、动词含意db56、上下文类似度存储部58、汉字词典106以及二元配对生成规则存储部110准备其内容。一元配对追加部100从第一一元db52以及第二一元db54中依次读出一元配对,对于各一元配对,变形为在含意模式配对扩展装置50中处理的格式,并且作为表示各一元配对的数据源的值而附加各一元db的标识符并输出到一元配对db102。一元配对生成部104使用存储在上下文类似度存储部58中的上下文类似度按如下方式生成一元配对,并追加输出到一元配对db102。参照图2,一元配对生成部104与处理的开始同时进行存储区域的确保以及初始化等(步骤140)。一元配对生成部104从动词含意db56将动词含意配对全部读出(步骤142)。一元配对生成部104对所读出的各个动词含意配对执行处理146(步骤144)。在处理146中,一元配对生成部104针对构成处理对象的动词含意配对的各个动词分别附加“aが”、“aに”、“aを”、以及“aで”,从而生成多个一元含意模式的候补配对(步骤160)。一元配对生成部104针对这样得到的各个候补配对,在构成该候补配对的一元配对彼此之间进行上下文类似度计算处理164(步骤162)。一元配对生成部104基于所计算的上下文类似度,选择构成一元配对的模式彼此之间的上下文类似度最高的一元配对(步骤166)作为新的一元配对追加到一元配对db102(步骤168)。此时,作为新的一元配对的数据源,对新的一元配对赋予动词含意db56的标识符,进而还赋予成为基础的动词含意配对的标识符。一元配对生成部104对从动词含意db56读出的全部的动词含意配对进行这样的处理。若一元配对追加部100以及一元配对生成部104对一元配对db102的一元配对的追加完成,则一元配对扩展部108根据保存在一元配对db102中的各个一元配对来生成多个一元配对并输出到扩展一元配对db60。即,参照图3,一元配对扩展部108的记录读出部180从一元配对db102读出一元配对的记录。被动态/可能型追加部182针对由记录读出部180读出的一元配对的每一个,对构成一元配对的各一元模式进行向被动态的变形、以及向可能型的变形,并将通过它们的组合得到的多个新的一元配对与原来的一元配对一同追加到扩展一元配对db60。此时,对新的一元配对赋予成为新的一元配对的基础的一元配对的标识符和确定所应用的变形的标志。在被动态/可能型追加部182对扩展一元配对db60的一元配对的追加完成之后,传递性配对追加部184将谓语的拼写变体以及语尾的变形应用于各一元配对,从而进一步对一元配对进行扩展。即,传递性配对追加部184对于以汉字书写的谓语,通过参照汉字词典106来制作变换为假名的一元模式,并追加具有新的模式的一元配对。进而,传递性配对追加部184还同时生成“汉字→假名”、以及“假名→汉字”这样的一元配对,并追加到扩展一元配对db60。此后,传递性配对追加部184检索存储在扩展一元配对db60并且第一一元配对的后半部与第二一元配对的前半部一致的一元配对的组合。对于检索到的各个一元配对的组合,传递性配对追加部184将第一一元配对的前半部和第二一元配对的后半部进行组合而生成新的一元配对,并追加到扩展一元配对db60。参照图4,更具体地,传递性配对追加部184从扩展一元配对db60将一元配对全部读出(步骤220),并针对所读出的各一元配对执行处理224(步骤222)。即,在步骤222中,传递性配对追加部184将读出的一元配对以给定的顺序依次选择为处理对象,并对选择的一元配对(第一一元配对)像以下那样执行处理224。在处理224中,传递性配对追加部184将具有与处理对象的一元配对的后半部一致的前半部的全部一元配对从扩展一元配对db60读出(步骤250)。传递性配对追加部184对在步骤250中读出的各一元配对(第二一元配对)执行以下的处理254(步骤252)。在处理254中,如果第一一元配对的谓语部为“汉字→假名”的组合、并且第二一元配对的谓语部为“假名→汉字”的组合,则传递性配对追加部184结束处理,并将处理转移到下一个第二一元配对(在步骤280中为肯定)。在步骤280的判定为否定时,传递性配对追加部184判定第一一元配对的前半部模式是否与第二一元配对的后半部模式一致(步骤282)。在判定为“否”时,传递性配对追加部184将由第一一元配对的前半部模式和第二一元配对的后半部模式构成的一元配对作为新的一元配对追加到扩展一元配对db60(步骤284)。在步骤282的判定为肯定时,传递性配对追加部184针对第一一元配对以及第二一元配对的每一个将相当于其对偶的一元配对追加到扩展一元配对db60(步骤286)。步骤284的处理的结果是,从p→q这样的配对和q→r这样的配对通过所谓的传递性而生成p→r这样的配对,并追加到扩展一元配对db60。在步骤286的处理中,针对p→q追加这样的配对,针对q→p这样的配对追加这样的配对。若基于传递性配对追加部184的传递性配对的登记完成,则在扩展一元配对db60中,积累了从存储在第一一元db52、第二一元db54、以及动词含意db56中的一元配对以及动词含意配对扩展得到的一元配对,并能够进行利用。另外,对通过传递性而生成的一元配对赋予成为基础的两组一元配对的标识符和表示是通过传递性追加的标志,对通过同值而追加的一元配对赋予成为基础的两组一元配对的标识符和表示是通过同值追加的标志。返回到图1,若向扩展一元配对db60的一元配对的积累完成,则二元配对追加部112对保存在扩展一元配对db60中的各一元配对像以下那样生成多个二元配对,并保存在扩展二元配对db62。具体地,参照图5,二元配对追加部112从扩展一元配对db60读出全部的一元配对(步骤320)。二元配对追加部112依次选择所读出的一元配对(步骤322),并针对其每一个执行从该一元配对生成二元配对的处理324。参照图6,二元配对追加部112在图5的处理324中,从图1所示的二元配对生成规则存储部110中将二元配对的生成规则全部读出(步骤350)。进而,二元配对追加部112针对所选择的处理对象的一元配对依次选择在步骤350中读出的各生成规则(步骤352),并执行处理354。在处理354中,二元配对追加部112判定处理中的一元配对是否满足要应用处理对象的二元配对生成规则的条件(步骤380)。如果不满足条件,则结束该规则的应用,使处理前进到下一个生成规则的应用(步骤380的判定为“否”)。在步骤380的判定为肯定时,二元配对追加部112针对处理对象的一元配对应用处理中的二元配对生成规则,从而生成二元配对(步骤382)。二元配对追加部112将这样生成的二元配对追加到扩展二元配对db62,并结束该二元配对生成规则的应用(步骤384)。在本实施方式中,从“aを使う(使用a)→aを用いる(采用a)”这样的一元配对可生成如下的二元配对。[表格1]二元配对追加部112针对存储在扩展一元配对db60中的全部一元配对,应用存储在二元配对生成规则存储部110中的生成规则,并将所生成的全部的二元配对(反例除外)追加到扩展二元配对db62,从而在扩展二元配对db62中积累从第一一元db52、第二一元db54以及动词含意db56扩展得到的二元配对,并能够利用。此时,对各二元配对作为信息而附加成为该二元配对的基础的一元配对的标识符和所应用的生成规则的标识符。通常,在提问应答系统中,一元配对作为对提问的回答容易命中。但是,一元配对只具有一个项。因此,若想要仅从一元配对得到回答,则不能过度地期待回答精度。为此,在检索回答时,最初使用二元配对,在二元配对中未找到回答的情况下使用一元配对。通过这样的回答检索的方法,能够在维持较高的回答精度的同时提高命中率。在该情况下,按照上述实施方式的方法来充实二元配对,能够进一步提高回答的精度。另外,通过上述方法生成的一元配对也能够以如下的方法利用于提问应答系统。首先,预先计算构成配对的各模式的、文集中的出现频度。在后述的实验中,在从网页收集的许多文档中,在回答检索中命中各模式的情况下,根据一元模式的数据的来源以及性质,按照如下的优先顺序优先地利用一元配对作为换言模式。(1)同值关系(p→q和q→p同时成立的情况)(2)读音或形态(可能型/被动态)不同的相同谓语(3)上述以外的情况下从第一一元db52以及第二一元db54扩展得到的一元配对而且,与数据的来源无关,从上述网页收集的文档中的频度小于某常数的模式的优先顺序设定为最低。在后述的评价实验中,从网页上收集的文档的数目为6亿,用于将优先顺序设定得最低的阈值设为10。<评价>对基于在以上说明了结构的第一实施方式的含意配对(一元配对以及二元配对)的评价实验进行叙述。在该实验中,代替第一一元db52以及第二一元db54,而使用了3个一元配对的集合。其中的第一集合是以人工方式从现有的一元配对检查构成配对的模式间的上下文类似度为上位的一元配对而构筑的,由83706例的一元配对构成。第二集合是从现有的谓语对中选择助词为“を”、“に”、“で”的谓语并设为一元配对的集合。此时,意思含糊的以人工方式进行检查,进而只选择判断为正例的一元配对来进行构筑,由7334例的一元配对构成。第三集合是由基于申请人到目前为止构筑的若干数据得到的27369例的正例构成的。作为动词含意db56,如上所述,使用了申请人以人工方式构筑的动词含意数据(https://alaginrc.nict.go.jp/)。该动词含意db56收录有52689对的动词含意配对。对此进行一元配对生成部104的处理,以人工方式进对所得到的一元配对进行检查,从而积累了正例。结果得到的一元配对为51589对。根据以上,作为处理的种子而使用的一元配对的数目为83706+7334+27369+51589=169998。使用基于上述实施方式的方法来生成这样的一元配对以及二元配对,结果得到了如下数目的配对。首先,应用传递性之前的一元配对的数目为901232。这是原来的一元配对的个数的8倍以上。通过基于传递性的扩展,新得到了2864415个一元配对。该配对数是应用传递性之前的大约3倍。进而,通过从相同的一元表现来扩展二元配对,从而最终生成了42096327个二元配对。与成为基础的一元配对的个数相比较,是大约280倍。通过上述处理而生成的配对,通过启发法(heuristics)像以下那样赋予分数。[数学式1]score=α-(α-β)/(f/1000+1)在此,f表示成为生成某个配对的基础的两个一元模式在网页6亿文档中出现的频度的合计。α、β的值根据成为基础的一元模式如下这样给出。·处于同值关系的模式:α=2、β=-0.2·由传递性扩展的模式:α=-0.2、β=-0.8·上述以外的模式:α=0.1、β=-0.3图7是示出一元配对的全体的评价的曲线图。该曲线图是对如下这样在扩展一元配对db60中得到的一元配对全体(3765647个)进行评价的曲线图。(1)选择构成一元配对的两个模式在网页6亿文档中的出现频度均为10以上的一元配对。(2)从(1)所选择出的一元配对中通过随机采样选择500对,由3名注解者来评价各一元配对是否为正。该注解者都不是本申请发明的发明人。最终评价由基于3名注解者的评价的多数来决定。此时的一致率为kappa:0.46,是中等程度的一致率。(3)将500个样本根据构成各样本的模式的出现频度之积进行排序并进行了绘制。根据该图可知,几乎没有看到各模式的出现频度所引起的差异。此外,针对通过传递性进行扩展得到的一元配对和除此以外进行扩展得到的配对分开进行正例的评价,得到了以下的结果。[表格2]表1正例(精度)合计通过传递性而生成的配对249(0.64)386通过传递性以外而生成的配对94(0.82)114全部配对343(0.68)500在图8中,对500对的一元配对进行随机采样并进行评价,按照其优先顺序(分数)从高到低的顺序进行排序,绘制了上位n位的精度。作为全体,成为0.68左右的精度。但是,如表1所示,对于通过传递性以外生成的一元配对,得到了超过0.8的精度。同样地,从所生成的二元配对(42096327个)中随机采样500对进行评价,并按其分数顺序进行排序来进行绘制,结果在图9中示出。如图9的曲线图所示,作为全体的精度成为0.66,成为与一元配对相同程度的精度。从提问应答系统中的换言的利用的观点来说,在大约4200万的二元配对中,关于上位30%的大约1200万配对得到了0.8左右的精度,在大约380万的一元配对中,关于上位20%的大约75万配对得到了0.8左右的精度。若是该数量并且该精度,则能够评价为得到了充分实用的数据。在这些配对中进一步包括通过机器学习获得的配对,将总共为大约1亿的含意配对作为换言用的资源,装入申请人制作的提问应答系统,并输入了“大数据用于何处”这样的提问。结果,除了“商务”、“营销”这样的能够预料到的回答以外,还得到了“有助于输送计划”、“广泛地报道了大数据的运用如何有助于正确的政治性预测”这样的回答。要得到这些,均要使用“有助于a→使用于a”这样的基于传递性得到的配对。进而,对于“信长谋取的是什么”这样的提问,不仅得到了“天下统一”这样的常识性的回答,还得到了“以绝对王政为目标”、“以自由经济为目标”这样的回答。关于这些,在换言中使用了“a以b为目标→a谋取b”、“以b为目标的a→a谋取b”这样的基于传递性得到的配对。因此,通过使用上述的实施方式的方法对含意配对进行扩展来使用于提问应答系统的换言,从而提取出多种多样的回答的情况得到了确认。<变形例>在本实施方式中,将传递性的应用限于两个阶段。这是因为,若成为3个阶段以上,则处理需要时间。原理上,无论是几个阶段,都能够应用该传递性。只要以嵌套形式应用图4所示的处理224即可。不过,若传递性的应用阶段的数目增多,则可以预测到精度的下降。就实际使用而言,可以认为限度是3阶段或4阶段程度。但是,根据处理的方法,即使在这以上的数目的含意配对之间应用传递性,能够防止精度的下降也说不定。关于这些,需要今后的验证。进而,在上述实施方式中,在一元配对的扩展后进行传递性的应用。但是,原理上,传递性的应用,不仅在一元配对的扩展后,也可考虑在动词含意配对的阶段或一元配对的扩展前进行。不过,例如在动词含意配对的情况下,由于动词本身的多义性,也可以想到通过传递性的应用而得到的新的动词含意配对成为不合适的动词含意配对的情况。因此,需要通过应用传递性后的检查来除去不合适的配对。虽然在针对扩展前的一元配对的传递性的应用时,这样的危险性低,但是可以想到通过传递性的应用而得到的新的一元配对的数目比在扩展后应用传递性的情况少。因此,在获得换言表现这样的意义上,与上述实施方式相比,有可能变得不利。但是,即使这样,也不同于现有技术,仍然可以得到能够以能够预测的形式对一元配对进行扩展这样的效果。因此,也完全可以考虑这样的实施方式。进而,在上述实施方式中,进行从一元配对向二元配对的扩展。但是,本发明不限定于这样的实施方式。通过在二元配对中进一步追加项,从而还能够进行向三项配对(称为“三元配对”)的扩展。作为三元配对的例子,有“a向b传送c”。作为其方法,能够直接使用基于与从一元配对向二元配对的扩展时相同的生成规则的方法。但是,在生成三元模式时,可以想到如下情况:能够应用规则的条件的指定变得比二元配对的情况更加复杂、所得到的三元配对的多样性与二元配对的情况相比增多、以及因此处理所需的时间变长。基于同样的考虑,对于4以上的自然数n,也能够设m=n-1对m元模式进行扩展而得到n元模式。实装上的制约不过是规则决定的作业量和处理时间的问题。进而,也能够从一元配对直接扩展为三元配对。在该情况下,制作在条件得到满足时对一元配对追加两项那样的规则即可。通过将从一元配对制作二元配对的规则和从一元配对制作三元配对的规则进行混合并应用于一元配对,从而还能够同时生成二元配对和三元配对。如上所述,根据本发明,能够通过应用简单的规则而从单纯的动词的含意配对生成项为一个以上的复杂的语言模式间的含意配对。在该方法中,只要准备必要的动词的含意配对,就可自动地生成由与此关联的各种各样的模式构成的含意配对。能够大量地获得仅由以往那样通过机器学习而获得的配对无法包罗的含意配对。结果,通过将该含意配对应用于提问应答系统中的换言,从而能够得到所得到的回答大幅增加这样的效果。至于通过该扩展而得到的含意配对是什么样的含意配对,能够根据成为基础的动词的含意配对进行预测。而且,如上所述,能够保证最终采用的数据的精度成为某种程度的值。因此,与现有技术相比较,能够高效地收集能够利用于提问应答系统等利用了自然语言的系统的、高精度的含意配对的集合。[第二实施方式]通过上述第一实施方式涉及的含意模式配对扩展装置50,能够像扩展一元配对db60以及扩展二元配对db62那样得到多个db。第二实施方式涉及使用这样的多个db从网页存档(webarchive)中检索针对提问的回答的提问应答系统。另外,关于该第二实施方式涉及的提问应答系统,作为一般的例子,设为使用对扩展至包括n项的变量的模式的含意配对进行存储的db,即,扩展n元db。以下将扩展一元配对、扩展二元配对、以及一般的扩展n元配对统称为扩展配对,并将分别对它们进行存储的db(扩展一元配对db60、扩展二元配对db62等)统称为扩展配对db。参照图10,该第二实施方式涉及的提问应答系统500接受基于声音的提问502,并通过声音输出对提问的回答504。提问502可以通过设置于该提问应答系统500的麦克风以及声音处理部来接受,也可以通过网络从其它终端接受。对于提问502,声音识别部520进行声音识别,并输出由附有句法信息的文本构成的提问句。句法分析部522通过对该提问句应用预先准备的句法变换规则,从而得到肯定句,进而进行承接分析以及句法分析,输出表示单词间的意思上的承接关系的曲线图形式的承接信息。模式提取部526对该承接信息进行扫描,从存在于曲线图上的连结单词的路线提取模式。此时,将该模式包含的变量的项数的上限设为n。该项数的最大值存储在最大项数存储部524中,模式提取部526读出该值,并根据承接信息提取包括最大n项的变量的模式。在变量为一个时以及两个时,如前所述,称为一元以及二元。一般来说,将变量为n个的模式称为n元模式。因此,模式提取部526提取的模式为一元模式、二元模式、…、n元模式。更具体地,模式提取部526通过在曲线图上连结名词和谓语的路线上将名词置换为变量,从而提取一元模式。同样地,模式提取部526通过在曲线图上连结两个名词和谓语的路线上将两个名词分别置换为变量,从而提取二元模式。以下相同。另外,在此,模式提取部526在将名词置换为变量时,对变量赋予与该名词的意思种类对应的制约。例如,如果名词是地名,则对变量赋予“地名”,如果是食物,则对变量赋予“食物”等的制约。通过这样,从而在检索回答时,能够排除虽然句法形式很相似但是意思上没有关系的候补。为此,提问应答系统500除了前述的扩展一元配对db60以及扩展二元配对db62以外还包括直到保存有n元配对的扩展n元db530为止的扩展配对db。当然,可以是n=2,在该情况下,提问应答系统500作为含意配对仅包含扩展一元配对db60和扩展二元配对db62。模式提取部526所提取出的模式,由模式扩展部528利用扩展一元配对db60、扩展二元配对db62、…、扩展n元配对db530来进行扩展。如果扩展对象的模式为一元模式,则模式扩展部528利用扩展一元配对db60进行模式的扩展。同样地,如果扩展对象的模式为二元模式,则模式扩展部528利用扩展二元配对db62进行模式的扩展。以下相同。在此,模式扩展部528依次利用扩展一元配对db60、扩展二元配对db62、…、扩展n元配对db530来进行含意配对的扩展。因此,提问应答系统500包括选择器532,选择器532由模式扩展部528控制,将扩展一元配对db60、扩展二元配对db62、…、扩展n元配对db530中的、由模式扩展部528指定的扩展配对db选择性地与模式扩展部528连接。像这样,关于由模式提取部526提取而得到的一元配对、二元配对、…、n元配对,分别使用保存在扩展一元配对db60、扩展二元配对db62、…、扩展n元配对db530中的含意配对,均大幅地扩展。结果,从模式扩展部528输出对变量赋予了制约的大量的模式。提问应答系统500包括存储了网页上的大量的数据的网页存档534。回答候补检索部536从网页存档534检索具有与从模式扩展部528输出的大量的模式匹配的表现的句子,并分别按照是否与存储在哪个扩展配对db中的配对匹配来进行分类并输出。回答候补检索部536输出的回答候补分别分类存储在一元回答候补存储部538、二元回答候补存储部540、…、n元回答候补存储部542中。另外,回答候补检索部536包括预先完成了基于学习用数据的机器学习的判别器。该判别器包括模式所包含的单词的意思分类、检索该回答候补时使用的模式、该模式与原来的提问句的意思上的类似度、回答候补与提取该回答候补时使用的模式的关联度等各种各样的要因来进行回答候补的检索,分别对各回答候补赋予表示作为对提问502的回答的适合度(aptness)的分数。提问应答系统500还包括:对为了从存储于一元回答候补存储部538、二元回答候补存储部540、…、n元回答候补存储部542的回答候补之中选择回答而预先准备的阈值进行存储的阈值存储部546;以及从存储于一元回答候补存储部538、二元回答候补存储部540、…、n元回答候补存储部542的回答候补之中只选择一个具有存储在阈值存储部546中的阈值以上的分数的回答的回答选择部548。关于回答选择部548,在该选择时,如果最初在回答候补之中存在使用变量最多的模式而检索到的回答候补,则在其中选择分数最高且分数为阈值以上的回答候补作为回答。如果没有这样的回答候补,则回答选择部548尝试从使用变量的数目少一个的模式而检索到的回答候补中选择回答。以下,直到变量的值成为1为止,进行同样的处理。回答选择部548像这样优先使用变量多的模式而检索到的回答候补来选择回答。因此,提问应答系统500还包括选择器544,选择器544按照回答选择部548的控制,选择n元回答候补存储部542、…、二元回答候补存储部540、一元回答候补存储部538中的任一个与回答选择部548的输入进行结合。在直到使用一元配对而检索到的回答候补为止调查了全部回答候补也未能找到满足条件的回答候补的情况下,选择根据预先决定的基准而选定的回答候补。另外,选择回答候补时的阈值可以与检索该回答候补时使用的模式所包含的变量的数目无关而是恒定的,也可以随着变量的数目增大而使阈值减小。在找到的回答候补均不满足条件时,例如,可以将找到的回答候补中的分数最高的回答候补作为回答,也可以选择在检索时使用的模式的变量的项数最多的回答候补之中的分数最高的回答候补。回答选择部548选择的回答传递至回答输出部550。回答输出部550将该回答以与输入形式对应的形式作为回答504而输出到与提问502的输入路径相应的路径。例如,在提问502经由提问应答系统500具备的麦克风等进行输入的情况下,回答输出部550将回答504变换为声音,并用扬声器输出声音。在提问502经由网络作为声音传送过来时,回答输出部550对将提问502发送过来的地址发送进行加工使得作为声音输出的数据。如上所述,该第二实施方式涉及的提问应答系统500使用由第一实施方式所涉及的含意模式配对扩展装置50扩展的扩展一元配对db60、扩展二元配对db62、…、扩展n元配对db530,对从提问502得到的模式进行扩展。这些扩展配对的数目非常多,从提问502得到的模式的数目也非常多。像这样,使用大量的模式从网页存档534检索回答候补。因此,能够检索到即使是作为句法的形式与提问502大不相同也适合作为回答的回答候补的可能性提高。进而,因为使用传递性对模式配对进行扩展,所以得到与从提问502得到的模式不同的意外的模式的回答的可能性也提高。进而,优选选择在检索回答时使用的模式包含的变量的数目多的回答候补。结果,具有对于提问502能够得到更具体且更合适的回答的可能性提高这样的效果。[基于计算机的实现]上述第一实施方式涉及的含意模式配对扩展装置50、第二实施方式涉及的提问应答系统500以及其它变形例能够由计算机硬件和在该计算机硬件上执行的计算机程序来实现。图11示出该计算机系统930的外观,图12示出计算机系统930的内部结构。参照图11,该计算机系统930包含具有存储器端口952以及dvd(digitalversatiledisc:数字通用盘)驱动器950的计算机940、键盘946、鼠标948、以及监视器942。参照图12,计算机940除了存储器端口952以及dvd驱动器950以外,还包括cpu(中央处理装置)956、与cpu956、存储器端口952以及dvd驱动器950连接的总线966、存储引导程序等的读出专用存储器(rom)958、与总线966连接并对程序命令、系统程序以及作业数据等进行存储的随机存取存储器(ram)960、以及硬盘954。计算机系统930还包括使得与其它终端的通信成为可能的提供对网络968的连接的网络接口(i/f)944。能够与ram960、硬盘954、以及存储器端口952进行拆装的插拔式存储器964作为图1所示的第一一元db52、第二一元db54、动词含意db56、上下文类似度存储部58、扩展一元配对db60、扩展二元配对db62、汉字词典106、二元配对生成规则存储部110、扩展n元db530、网页存档534、回答候补存储部538、540、542、最大项数存储部524以及阈值存储部546那样的存储装置而发挥功能。不需要信息的改写的数据,例如,像汉字词典106那样的数据保存在cd-rom或dvd962,也可以安装在dvd驱动器950并读出。用于使计算机系统930作为上述的实施方式涉及的含意模式配对扩展装置50或提问应答系统500的各功能部发挥功能的计算机程序存储在安装于dvd驱动器950或存储器端口952的dvd962或插拔式存储器964,并进一步转发到硬盘954。或者,程序也可以通过网络968发送到计算机940并存储到硬盘954。程序在执行时载入到ram960。也可以从dvd962、插拔式存储器964或者经由网络968直接将程序载入到ram960。该程序包含由用于使计算机940作为上述实施方式涉及的含意模式配对扩展装置50或提问应答系统500的各功能部而发挥功能的多个命令构成的命令列。使计算机940进行该动作所需的基本功能中的若干个由在计算机940上动作的操作系统或第三方的程序或安装在计算机940的可进行动态链接的各种程序工具包或程序库提供,并在执行程序时动态地链接而被执行。因此,该程序本身未必一定要包含用于实现为了实现该实施方式的系统以及方法所需的功能的结果代码或脚本的全部。该程序只要只包括命令中的如下的命令即可,该命令以控制为可得到所希望的结果的做法在执行合适的功能或程序工具包或程序库内的合适的程序时动态地调出,从而实现作为上述的系统的功能。当然,也可以使得仅通过程序来提供所需的全部功能。此外,也可以将含意模式配对扩展装置50或提问应答系统500的各功能部分散在独立的计算机进行处理,或者经由网络通过分别存在于不同的地域的独立的计算机进行分散并进行处理。此次公开的实施方式仅是例示,本发明并不仅限制于上述的实施方式。本发明的范围在参考发明的详细的说明的记载的基础上由权利要求书的各权利要求示出,包括与其中记载的语句等同的意思以及范围内的全部的变更。产业上的可利用性本发明能够利用于提问应答系统、引导系统、基于机器人的对话系统等需要使用自然语言并使用多种多样的语言表现统一地、有效地进行自然语言处理的系统。附图标记说明50:含意模式配对扩展装置;52:第一一元db;54:第二一元db;56:动词含意db;58:上下文类似度存储部;60:扩展一元配对db;62:扩展二元配对db;100:一元配对追加部;102:一元配对db;104:一元配对生成部;106:汉字词典;108:一元配对扩展部;110:二元配对生成规则存储部;112:二元配对追加部;164:上下文类似度计算处理;180:记录读出部;182:被动态/可能型追加部;184:传递性配对追加部;500:提问应答系统;522:句法分析部;526:模式提取部;528:模式扩展部;534:网页存档;536:回答候补检索部;548:回答选择部。当前第1页12
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1