一种水文时间序列异常模式检测方法与流程
本发明属于数据处理领域,特别涉及一种水文时间序列异常模式检测方法。
背景技术:
水文是指自然界中水的变化、运动等的各种现象,对水文进行研究在水资源开发利用、工程建设管理、农业灌溉、城市用水、航运等方面发挥了重要作用。在对水文进行研究时可以通过发现站点监测的历年水位数据中的异常变化,从而发现水文过程变化规律。对于历年水位数据中的异常变化的检测主要是水文时间序列异常检测。
时间序列异常检测主要分成针对时间序列中异常点的检测和异常模式的检测。从一般意义上来说,时间序列中一个点的异常,是指在一条时间序列上与其它序列点存在显著差异的、具有异常特征的序列点;而模式异常是指在这条时间序列上与其它模式存在显著差异的、具有异常行为的模式。时间序列中的模式一般是指一段具有某种特殊变化过程的子序列。目前已有的各种时间序列异常检测的方法,包括生物学方法、基于频率的方法、机器学习方法、基于特征空间的方法等。生物学方法从生物的免疫系统的机制中获得灵感的将该思想映射到异常检测上来,这种基于生物学的时间序列异常模式检测方法的主要缺陷是,当正常的数据变得多种多样,那么可能产生的正常模式的数目也同样增加,这会导致产生不出任何用于负选择过程的异己,最终会使得选择过程失败,检测不出任何异常模式。基于频率的方法采用后缀树来编码时间序列中所有出现的模式,用马尔科夫模型(markovmodel)预测没有被观测到的模式期望发生的概率,然后根据用户给定的阈值来判断模式的奇异性,即检测出异常的模式,这样的方法检测出的结果不准确。机器学习的方法目前相关研究方法主要包括两大类:人工神经网络和支持向量机。基于特征空间的方法一般又分成两种:(1)一种方法是将时间序列分成等长的子序列,然后将子序列映射为n维空间中的点,然后采用普通数据集合中的异常点检测方法发现异常。这种方法的一个缺点是序列中的点一般较多,距离的计算和检测的时间消耗是相当可观的。(2)另一种方法是从时间序列中抽取特征,然后在特征空间中应用普通数据集合中的异常点检测方法来发现异常。
技术实现要素:
发明目的:为了克服现有技术中存在的不足,本发明提供了一种准确性高,检测速度快,运算量小的水文时间序列异常模式检测方法。
发明内容:为解决上述技术问题,本发明提出一种水文时间序列异常模式检测方法,包括以下步骤:
步骤1:采集历年的水位数据,根据时间的顺序,以年为单位组成每年的水位时间序列;
步骤2:对每年水位时间序列进行分割,产生水位子序列;
步骤3:水位子序列进行线性分段,形成维度低的水位子序列;主要通过提取主要特征,从而降低维度;
步骤4:对步骤3中获得的水位子序列进行分组,将同时间段的子序列划分为一组;
步骤5:在同一组子序列中结合平均变化距离和积累变化距离进行异常子序列的检测。
进一步,所述步骤2中采用滑动窗口机制对每年水位时间序列进行分割,产生水位子序列。这样划分出的子序列是等长的,更易于执行对应时期相同的子序列之间距离的比较计算。
进一步,所述步骤3中通过分析逐段聚集平均的方法对每年的水位时间序列进行线性分段;这样更加简单直观。
进一步,所述步骤5中对异常子序列检测的方法为,包括以下步骤:
步骤51:根据公式
步骤52:确定si邻近子序列的个数k,根据公式
步骤53:判断ac与mc的大小,若ac>mc,则当前子序列si可能为异常子序列,否则视为正常子序列。
进一步,所述子序列之间的距离度量函数采用动态时间序列弯曲距离函数。
进一步,还包括步骤6:将检测得到的异常子序列采用曲线方式进行图形展示并进行评估。这样得到的检测结果更加的准确并且直观。
进一步,近邻子序列的总数k的取值大于3,且小于子序列数量的一半n/2。这样检测出的结果更加的准确。
工作原理:本发明结合水文时间序列的特点,给出水文时间序列异常模式的定义,通过水文时间子序列累积变化距离和平均变化距离的检测出水文时间序列异常模式。
有益效果:与现有技术相比,本发明提供的方法计算量小,有效缩短了检测的时间;本发明中的异常阈值根据已有序列来确定,能够获得的结果的准确性更高,有效的避免了检测失败的可能。在水文领域,不同流域受地理位置和环境影响,其异常的阈值是不同的,本发明的阈值根据采集的数据自身确定,能够满足不同流域的异常模式检测,因此,采用本发明提供方法能够更好的对水文进行研究和观察。
附图说明
图1为水位时间序列异常子序列检测总体流程图;
图2为检测一组内的异常水位时间子序列流程图。
具体实施方式
下面结合附图对本发明的技术方案作进一步解释。
如图1所示,本发明提供了一种水文时间序列异常模式检测方法,主要包括以下步骤:
步骤11:水位时间序列。首先以年为单位,读取原始水位数据,构造水位时间序列。将采集的1年水位数据按照时间等间隔(如,天,小时等)排列,构成水位时间序列。
步骤12:构造水位时间序列的子序列。对逐年的水位时间序列使用长度为w的滑动窗口,构造子序列,其中,每年的水位时间序列的长度为l。这样形成的子序列是等长的。使用滑动窗口时,每次向前移动一个单位,因此,各个相邻子序列间大部分是重叠的,这样长度为l的时间序列,会产生l-w+1个子序列。分析人员根据需要研究的模式长度,来确定子序列的长度,如需要研究一个汛期的异常变动,可以选择w为60,或者如需要研究太湖水位7月份的波动情况,可选择w为31。
步骤13:线性分段。对步骤12中的子序列进行线性分段,实现降维。采用paa(piecewiseaggregateapproximation,通过分析逐段聚集平均,简称paa)进行线性分段,长度为w的水位子序列q转换成长度为m的子序列s,每个点的值为原始序列中连续的p个点均值,s[j]=(q[(j-1)*p+1]+…+q[j*p])/p,j=1,2,…,w/p,s[j]为子序列s的第j个点的值,q[j]为子序列q的第j个点的值。使用paa方法分段的原因是简单直观,且划分出的子序列是等长的,这样易于执行对应时期相同的子序列之间距离的比较计算。p取值由分析人员确定,一般w为p的整数倍。这样可以提高计算速度,同时保留了原始序列的主要信息。
步骤14:对步骤13产生的所有年份时间序列的子序列进行分组。构造好子序列后,对子序列进行分组,将对应时间相同的,即起始时间相同的子序列分在一组中。如,2015年7月10日-7月20日的子序列和2016年7月10日-7月20日的子序列等分在一组中。
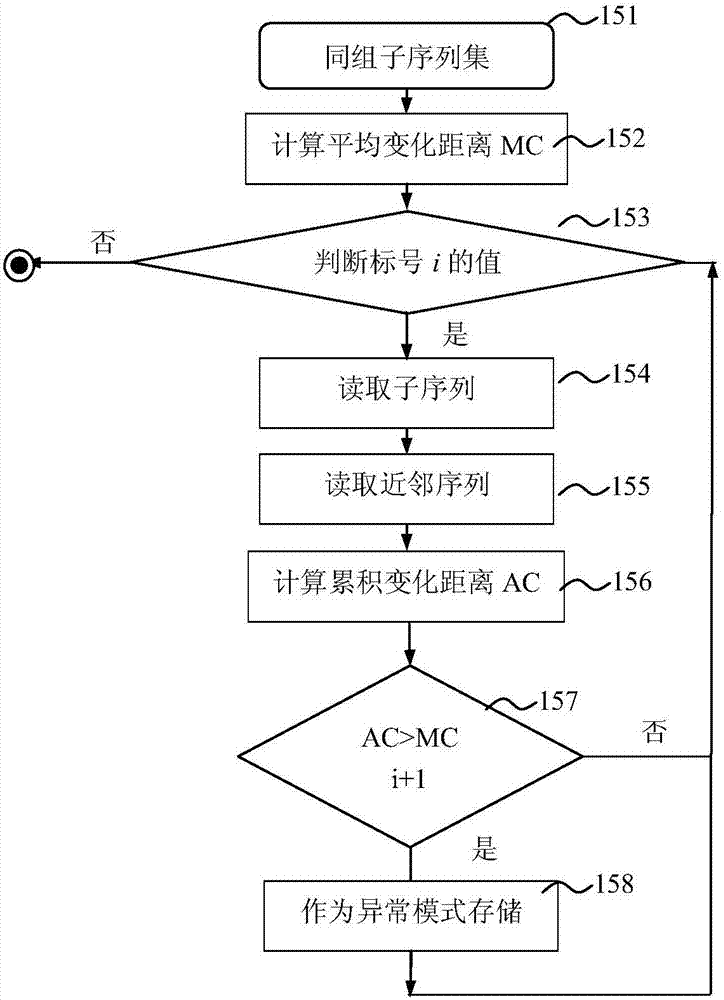
步骤15:检测同一组内的异常子序列。计算组内子序列之间的平均变化距离,以此作为异常阈值,针对每个子序列,计算其与邻近子序列之间的累积变化距离,如果超过平均变化距离,则为异常子序列。如图2所示,具体包括如下步骤:
步骤151:读取同组中所有子序列的相关参数,进入步骤152;
步骤152:根据公式
步骤153;判断标号i的值;如果i大于该组内子序列的总数则结束本组的处理;如果i不小于该组内子序列的总数则结束本组的处理;则进行步骤154。
步骤154:读取子序列si的信息。
步骤155:读取子序列si的邻近子序列。设置邻近子序列的个数k,一般取k为偶数。读取si-k/2,…,si-1,si+1,…,si+k/2作为邻近子序列。水文规律变化一般相对较缓,因此k取值可以大于3,但是小于子序列数量的一半,即n/2,取值太大距离值将被太多的邻近子序列平滑,不能体现出异常。
步骤156:根据公式
步骤157:ac>mc。判断累积变化距离ac是否大于平均变化距离mc,如果大于,则si识别为异常子序列,直接进行步骤157;否则si为正常子序列,先将i的值加1后重复步骤153~步骤157。
步骤158:将异常子序列进行保存,重复步骤153~步骤157。
步骤16:将检测得到的异常子序列采用曲线方式进行图形展示。
步骤17:对检测得到的异常子序列进行评估,通过专家的人工经验,核查其是否为真正的异常子序列。
以上所述仅是本发明的优选实施方式,应当指出:对于本技术领域的普通技术人员来说,在不脱离本发明原理的前提下,还可以做出若干改进和润饰,这些改进和润饰也应视为本发明的保护范围。
- 还没有人留言评论。精彩留言会获得点赞!