一种应用于JPEG2000的MQ编码器的制作方法
本发明属于图像压缩编码领域,涉及静态图像压缩标准jpeg2000。
背景技术:
图像是人类社会一个重要的信息渠道。原始图像的信息量往往十分巨大,对存储资源和传输带宽提出了很高的要求,然而这些原始信息当中包含了许多冗余信息。为了节约存储资源以及传输带宽,在不影响图像信息获取的前提下,应该对原始图像进行一定程度的压缩,去除冗余信息。因次,图像编码压缩技术一直以来都是图像处理的热门领域。
jpeg2000是国际标准化组织(iso)于2000年发布的新一代静态图像压缩标准。该标准在原有jpeg标准的基础上,采用了dwt(离散小波变换)和eboct(最优截断嵌入式块编码)两种新的技术,因此具有:(1)在低码率下保持着较高的压缩质量;(2)具有良好的容错纠错能力;(3)支持“感兴趣区域”(roi);(4)支持渐进传输等优点。jpeg2000的编码复杂程度较高,其中eboct部分的编码占据整体编码时间的80%以上,是当前jpeg2000算法结构优化的主要关注点。
eboct编码包括tier1编码以及tier2编码两部分,前者承担主要的编码工作。tier1编码由bpc编码器和mq编码器组成,前者产生上下文-判决对(cxd对),后者根据二进制编码原理对cxd对进行编码产生压缩码流。bpc编码器的优化目前已实现较大的突破,“skipscanningmethod”等改进方法的提出大大提高了bpc编码器的处理速度。
然而,mq编码器由于其本身严格串行的编码特点以及前后cxd对输入之间强烈的关联性,吞吐率一直难以提高。目前针对mq编码器的优化有两种思路:(1)提高编码器的吞吐率,设计出一个周期能处理多个cxd对的编码器;(2)对单cxd对处理的mq编码器进行优化,提高编码速度,缩短编码周期。对于前一种思路,有许多研究团队提出了相应的结构。但这些结构的通常具有以下问题:(1)编码器整体工作频率较低;(2)为了实现多对cxd对同时编码而采用较大面积的电路结构,存储需求也较大;(3)往往忽略了前后输入cxd对的相关性。当前后输入cxd对相同时,优化结构往往不能正常工作。第二种思路则得到了比较广泛的应用,本发明也是基于这一思路提出了优化的mq编码器结构。
mq编码器前后输入的cxd对之间具有强烈的相关性。每个cxd对进入mq编码器时会首先从ilt表格中找到一个对应index值。然而每次编码结束之后,这个对应的index有可能会被更新。因此,如果前后输入的cxd对的值相同,那么后一个cxd对就必须等待前一个cxd对的编码完成以获得正确的index。这样严格的关联性导致流水线结构无法应用到编码过程当中,使得编码速度较慢。
技术实现要素:
本发明的目的是克服现有技术的上述不足,提供一种编码速度快、能够减少存储占用量的应用于jpeg2000的mq编码器。技术方案如下:
一种应用于jpeg2000的mq编码器,包括索引预测模块以及主体编码模块两个部分,其特征在于,
(1)当前待编码的上下文判决对cxd进入第一部分索引预测模块以获得正确的索引值,该索引值有两种可能:a.根据上下文判决对cxd中的上下文值cx从索引查找表ilt中查询到的原始索引值;b.上一个上下文判决对cxd编码产生的更新索引值;选择索引值需要判断两个条件:a.判断当前上下文判决对cxd的上下文值cx值是否与前一个上下文判决对cxd的上下文值cx值相同;b.前一个上下文判决对cxd是否发生重归一化操作,如果两个条件都符合,那么就采用更新索引值作为当前上下文判决对cxd的索引值,否则采用原始索引值;获得的索引值将替换掉索引查找表ilt的原始索引值,另外,获得正确的索引值之后,当前的上下文判决对cxd还将根据自身将要进行的编码模式从概率估计值表pet中获取的nmps和nlps当中选择一个来选定本次编码的更新索引值,以提供给下一个上下文判决对cxd选择,编码模式由当前上下文判决对cxd的判决值d与其选定索引值的最低一位的比较来决定是codemps或者codelps,完成上述工作后,当前上下文判决对cxd开始后续的编码过程;
(2)当前上下文判决对cxd获得的索引值将进入第二部分主体编码模块进行mq编码器的主要编码过程,该模块是一个四级流水线结构,第一级流水线根据输入的索引值从概率估计值表pet中得到对应的qe值以及lz值,lz值是用来指明移位的次数,用在寄存器a的更新当中,此外,当前上下文判决对cxd的判决值d也将和其索引值的最低一位进行比较得到当前上下文判决对cxd的编码模式是codemps或者codelps;
(3)qe值以及lz值进入第二级流水线,主要完成寄存器a的更新:首先,根据编码模式,寄存器a的原始值将和qe值进行加法器计算以获得新的编码区间宽度,然后将该宽度与规定的0x800进行比较;如果小于0x800,那么就需要进行重归一化操作,编码区间宽度值左移倍增;在codelps编码模式下,从概率估计值表pet表中获取的lz值可以指示需要左移的次数,从而实现一次性完成重归一化操作;重归一化操作完成之后,编码器a完成更新,总共移位的次数将被送到下一级流水线完成寄存器c的更新;
(4)qe值以及寄存器a的移位次数进入第三级流水线,主要完成寄存器c低16位c16的更新:与前一级流水线类似,首先从c16的原始值将根据编码模式与q进行加法器计算得到更新的值,然后根据寄存器a的移位次数完成c16的移位进而完成寄存器c低16位的更新;产生的进位位将送入第四级流水线;
(5)第四级流水线主要完成寄存器c高12位的更新,并且根据寄存器c的移位情况进行比特输出操作,最终输出压缩字节。
在原始的mq编码器结构当中,当前cxd对为了得到正确的index值,必须等待前一个cxd对的编码完成,这样的机制导致mq编码器难以使用流水线结构。本发明提供的mq编码器主要由两部分组成——indexdetector以及codingpart,indexdetector的作用是为进入mq编码的cxd对预测对应的index值从而提前开始编码,使其不必等待前一个cxd对的编码结束。这样就可以在后续编码过程中采用流水线结构。codingpart承担主要的编码工作。这是一个四级流水线结构,主要的改进点有:
(1)对pet表格进行优化,减小存储占用量;
(2)对寄存器a的更新进行了优化,缩短关键路径;
(3)将寄存器c分为低16位和高12位两个寄存器,由两级流水线分别更新。避免使用28位的加法器;
附图说明
图1本发明的高性能mq编码器结构
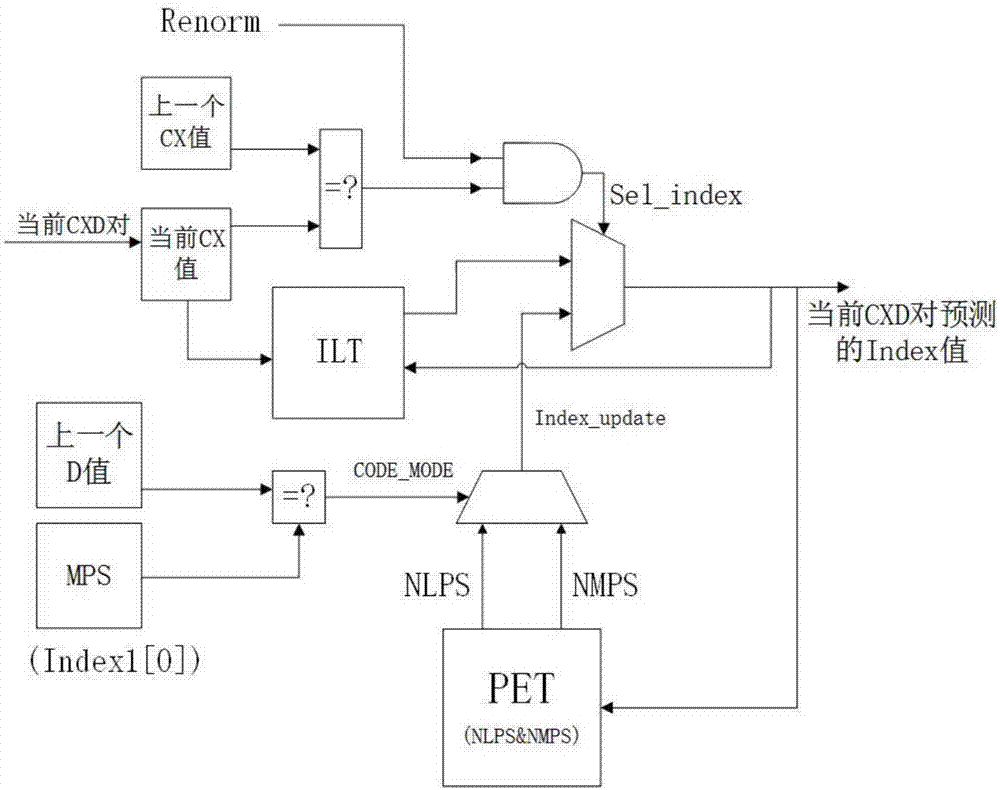
图2indexdetector的结构图
图3四级流水线结构codingpart
图4简化后的更新寄存器a电路结构
具体实施方式
本发明提出的高性能mq编码器结构图如图1所示。该编码器由indexdetector(索引预测模块)以及codingpart(主体编码模块)两部分组成。一个时钟周期可以处理一个cxd对。
1.indexdetector
设计indexdetector的目的是为了让当前进入mq编码器的cxd对提前获取正确的index值,从
而开始编码,不必再等待前一个cxd对编码结束,其结构如图2所示。
在传统的结构当中,每个cxd对在编码过程如果发生重归一化(renormalizaton)操作,那么就会生成一个新的index值替换掉原先在ilt表中对应的index,并在编码结束之后更新ilt表。因此下一个cxd对必须等待前者结束以获取更新后的ilt表。
在indexdetector当中,当前cxd对在前一个cxd尚未编码结束时,其对应index有两种可能性:(1)从未更新的ilt表中得到的index值、(2)前一个cxd对更新后的index值(index_update)。如果当前cxd对的cx值不等于前一个cxd对的cx值,或者两者相等但前一个cxd对没有发生重归一化操作(renorm),那么就按照ilt表中的原始数据选定index值。如果两者相等且前一个cxd对发生了重归一化操作,就采用前一个cxd对的更新值index_update来作为当前cxd对的index。
index_update同样有两种可能:nlps以及nmps。两者可以根据前一个cxd对的index值从pet表得到。index_update的选定要根据前一个cxd对的编码模式(code_mode)来判断。
当前cxd对获得index之后会同步更新ilt表。
2.codingpart
本发明提出的mq编码器第二部分为codingpart,该部分为一个四级流水线结构,如图3所示。
这里介绍优化pet表以及rega的简化更新。
(1)优化pet表
首先,在pet表中加入了一个新的参数lz(leadingzero)。该数值指示了rega的数值需要被移位的次数,可以被用在codelps当中的重归一化操作,达到一次性完成移位的目的。其次,本发明将pet表中47个qe值用二进制表示之后,发现47个qe值可以分成三组,每一组当中的qe有8位数值是相同的,如表1所示。因为qe是一个位宽为15的数据,因此每个qe实际所需要存储的只有7位数据。
表1简化qe存储方式
(2)寄存器a更新的简化
本发明增加了一个信号——space_judge来简化寄存器a的更新。该信号按根据下面的公式
来更新:
space_judge=(d==mps)?(a<2qe):(a>2qe)
如果space_judge=1,那么a=a_lps,否则a=a_mps。当a=a_lps的时候,重归一化操作一定会发生。此时pet表给出的lz就可以用来指示a需要移动几位,从而一次完成a的移位。如果a=mps,那么只有当a–qe<0x8000的时候会发生重归一化操作。此时移位的次数有三种可能:移动0次、移动1次、移动2次。可以根据(a–qe)的最高三位来决定需要移位的次数。简化后的更新电路结构如图4所示。
本发明提出的高性能mq编码器的工作流程如下所示:
(1)待编码的cxd对首先进入indexdetector当中预测所对应的index值。预测结束之后,indexdetector会根据更新后的index值来更新ilt表,为下一个cxd对预测index值。
(2)待编码cxd对与对应的index值进入codingpart开始进行编码。codingpart是一个四级流水线结构。第一级流水线主要根据index值来查询pet表,得到对应的qe值以及leadingzero值(lz)。这两个值将被送到后续流水线完成寄存器a以及寄存器c的更新。本发明对pet表进行了优化,减小了存储占用。
(3)第二级流水线主要的工作是更新寄存器a的值。与传统mq编码器结构当中需要多次移位完成寄存器a的更新不同,本发明实现了一次性移位即完成寄存器a的更新,大大缩短了关键路径。
(4)第三级流水线完成寄存器c的低16位的更新。由于寄存器c是一个宽度为28位的数据,为了避免使用28位的加法器增加关键路径,本发明将寄存器c划分为低16位和高12位,分两级流水线更新。
(5)第四级流水线完成寄存器c的高12位更新,同时完成byte-out输出压缩字节,完成该cxd对的编码工作。
3.比较
为了说明编码器性能,本发明提出的mq编码器与其他研究小组提出的几种mq编码器在fpga
平台上进行了比较,比较结果如表2所示。为了确保比较的结果的准确性,比较双方都采用了同样的fpga。比较结果说明,本发明提出的mq编码器具有较高的性能。
表2比较结果
[1]k.liu,y.zhou,y.s.li,andj.f.ma,“ahighperformancemqencoderarchitectureinjpeg2000,”integration,thevlsijournal,vol.43,pp.305-317,jan.2010.
[2]k.sarawadekarands.banerjee,“areaefficient,highspeedebcotarchitecturefordigitalcinema,”isrnsignalprocessing,vol.2012,p.9,jan.2012.
[3]z.di,y.hao,j.shi,andp.ma,“ahigh-throughputvlsiarchi-tecturedesignofarithmeticencoderinjpeg2000,”journalofsignalprocessingsystems,vol.81,pp.227-247,sep.2015.
- 还没有人留言评论。精彩留言会获得点赞!