低密度奇偶校验解码器、包括其的存储设备和方法与流程
对相关申请的交叉引用
根据35u.s.c.§119,本美国非临时专利申请要求于2016年7月19日提交的韩国专利申请no.10-2016-0091536的优先权,特此通过引用将其整体并入本文。
本发明的原理和构思一般地涉及纠错技术,并且更具体地讲,涉及低密度奇偶校验(ldpc)解码器以及包括该ldpc解码器的存储设备。
背景技术:
由于存储设备通过精密的工艺被制造并且由于存储设备并入多级单元(mlc)用于增加存储设备的集成密度,因而降低了存储设备的可靠性。所述精密工艺致使电路线宽缩短,其导致单元易受单元与单元间的干扰。mlc的使用造成级间的间隔减小,这增大了相邻级之间的重叠区域,从而会降低可靠性。在存储设备本身的错误增多的情况下,应该使用纠错码(ecc)技术以确保并入了一个或多个存储设备的数据存储设备的高水平可靠度。最近几年,已对ldpc解码器进行了诸多研究,以增强nand闪存设备的读取性能的ecc功能。出于这一目的,当前在闪存设备中使用了这样的ldpc解码器。
技术实现要素:
本公开涉及ldpc解码器、包括该ldpc解码器的存储设备、以及用于在包括该ldpc解码器的存储设备中执行读取操作的方法。
ldpc解码器包含:可变节点处理单元(vnu),被配置为接收信道信息和校验节点信息,并且计算可变节点信息;校验节点处理单元(cnu),被配置为接收可变节点信息,并且计算校验节点信息;以及存储器,被配置为暂时地存储在vnu的操作和cnu的操作期间生成的数据。cnu包括存储相应校验节点值的多个存储器元件。存储器元件通过两个或更多个路径互连,每个路径包括存储器元件的全部或部分循环排列以发送校验节点值。
存储设备包含:至少一个非易失性存储器(nvm)设备,被配置为存储包括信息和对应于该信息的奇偶性的码字;以及存储器控制器,包括ldpc解码器,所述ldpc解码器被配置为从nvm设备中读取码字并且纠正所读取的码字的错误。ldpc解码器包含:vnu,被配置为接收信道信息和对应于码字的校验节点信息并且更新可变节点信息;以及cnu,被配置为接收可变节点信息并且更新校验节点信息。在ldpc解码器的时钟的每个时钟周期,cnu通过第一存储器元件的第一互连改变存储在cnu的相应的第一存储器元件中的校验节点信息的顺序或位置,或者通过cnu的第二存储器元件的第二互连改变存储在cnu的相应的第二存储器元件中的校验节点信息的顺序或位置。
所述方法包含下列步骤:
在存储设备中执行硬判决存储器感测;
将所读取的数据从存储设备的非易失性存储器(nvm)设备发送到存储设备的存储器控制器的纠错电路;
在纠错电路的低密度奇偶校验(ldpc)解码器中,使用ldpc解码对所读取的数据做出硬判决;
在ldpc解码器中,确定是否成功地做出了硬判决;
如果确定未成功地做出硬判决,则对所读取的数据执行软判决存储器感测;
将所读取的数据从nvm设备发送到存储器控制器的纠错电路;
在纠错电路的ldpc解码器中,使用ldpc解码对所读取的数据执行软判决;以及
在ldpc解码器中,确定是否成功地做出了软判决。ldpc解码器具有vnu和cnu。cnu包括通过两个或更多个路径互连的多个存储器元件,每个路径包括存储器元件的全部或部分循环排列,以在执行ldpc解码做出硬判决和软判决时发送校验节点值。
从以下描述、附图和权利要求中,本发明的原理和构思的这些和其它特征与益处将变得显见。
附图说明
在以下描述中,具体化发明原理和构思的代表性实施例将参照附图描述,在所有不同的图中,相同的附图标记指代相同的元件、特征或组件。附图不一定按比例,而将重点放在示出发明原理和构思上。在所述附图中:
图1示出了根据代表性实施例的ldpc解码器;
图2示出了根据代表性实施例的第一排列(τ),其包括用于支持h矩阵的图1中所示ldpc解码器的cnu的存储设备的互连;
图3示出了根据代表性实施例的第二排列(σ),其包括用于支持h矩阵的图1中所示ldpc解码器的cnu的存储设备的互连;
图4示出了根据代表性实施例的将校验节点存储器元件的状态恢复为原始状态所需的排列组合模式的周期(period)和循环(cycle);
图5示出了根据代表性实施例的生成图1中所示ldpc解码器的0循环和130循环中双对角线型h矩阵的过程;
图6示出了根据代表性实施例的生成图1中所示ldpc解码器的131循环处的双对角线型h矩阵的过程;
图7示出了根据代表性实施例的生成图1中所示ldpc解码器的132循环中的双对角线型h矩阵的过程;
图8示出了根据代表性实施例的支持多开销实现的图1中所示ldpc解码器的cnu的存储器元件的附加路径;
图9示出了依赖于图8中附加路径的第一附加排列(τ');
图10示出了依赖于图8中附加路径的第二附加排列(σ');
图11示出了根据代表性实施例的支持图1中所示ldpc解码器的多开销实现的h矩阵的排列组合;
图12示出了根据代表性实施例的并入了图1中所示ldpc解码器的存储设备;
图13示出了表示由图12中所示存储设备执行的读取操作的流程图;以及
图14示出了根据代表性实施例的包括使用对象存储装置的服务器的电子系统的框图。
具体实施方式
提供了根据本发明原理和构思的示范性或代表性实施例的低密度奇偶校验(ldpc)解码器,其包括与校验节点处理单元和/或可变节点处理单元的相对应的存储器元件的互连(所述互连还被称为“可变互连”)。可变互连包括至少两条路径,以简化校验节点处理单元和可变节点处理单元之间的互连(该互连也被称为“固定互连”),并且支持各种h矩阵(或解码矩阵)。
在以下详细描述中,出于解释而非限制的目的,阐述了公开具体细节的示范性或代表性实施例,以便提供对本发明可被具体化的方式的示例的全面理解。但是,对受益于本公开的本领域普通技术人员将显见的是,脱离本文公开的具体细节的根据本教导的其它实施例仍处于所附权利要求的范围内。而且,可以省略对公知的装置与方法的描述,以便不模糊示例实施例的描述。这样的方法和装置明确地在本教导的范围内。
如此处所使用的,术语“一”、“一个”和“该”包括单数和复数提及,除非上下文明确地另有所指。因此,例如,“一设备”包括一个设备和多个设备。相对的术语可被用来描述各种元件的相互关系,如附图中所示。这些相对的术语意图包含除附图中描绘的方向外设备和/或元件的不同方向。
应当理解,当元件被称为“连接到”或“耦接到”或“电耦接到”另一元件时,其可直接连接或耦接,或可以存在介入其间的元件。
术语“存储器”或“存储设备”,当这些术语在本文使用时,意图表示能够存储用于由一个或多个处理器运行的计算机指令或计算机代码的计算机可读存储介质。术语“计算机代码”,当该术语在本文使用时,意图表示针对由处理器或处理核的运行所设计的软件和/或固件。本文对“存储器”或者“存储设备”的提及应被解释为一个或多个存储器或存储设备。例如,存储器可以是相同计算机系统内的多个存储器。存储器还可以是分布在多个计算机系统或计算设备之中的多个存储器。
“处理器”、“处理核”或“处理逻辑”,当这些术语在本文使用时,包含能够运行计算机程序或可执行的计算机指令的电子组件。本文对包含“处理器”的计算机的提及应被解释为具有一个或多个处理器或处理核的计算机。例如,处理器可以是多核处理器。处理器还可以指代单个计算机系统内或分布在多个计算机系统之中的处理器集合。术语“计算机”也应当被解释为或许指代计算机或计算设备的集合或网,每个计算机或计算设备包含一个或多个处理器。计算机程序的指令可由多个处理器执行,所述多个处理器可在相同计算机内或可以分布在多个计算机上。
图1示出了根据代表性实施例的ldpc解码器100。如所示,与该实施例一致,ldpc解码器100包括可变节点处理单元(vnu)120、校验节点处理单元(cnu)140和存储器160。
在某些实施例中,vnu120包括多个可变节点。在某些实施例中,vnu120包括与每个可变节点对应的第一存储器元件。
在某些实施例中,cnu140包括多个校验节点。在某些实施例中,cnu140包括与每个校验节点对应的第二存储器元件。
在某些实施例中,vnu120和cnu140之间的互连被固定在特定形式中。例如,在某些实施例中,仅将cnu140的多个校验节点中的某些(即,少于全部)与vnu120的可变节点互连。
在某些实施例中,cnu140包括经由两条路径互连的存储器元件170(图1中所示的正方形)。
在某些实施例中,每个存储器元件170可被用来从自vnu120接收的可变-至-校验(v2c)消息中计算校验-至-可变(c2v)消息。每个存储器元件170可以存储用来计算相应校验节点的c2v消息的信息。
例如,每个存储器元件170可被实现为存储设备,诸如寄存器或触发器。例如,如果最小和算法(msa)被用于ldpc解码,则cnu140的存储器元件170可以存储用来计算c2v消息的第一最小值(min1)、第二最小值(min2)、以及最小位置信息(minposition)。
在某些实施例中,在每一时钟周期,cnu140的每个存储器元件170的值在实线箭头所指示的方向中移位,下文将其称为“循环移位”。因而,在每个时钟周期,cnu140的存储器元件170可以存储与不同校验节点对应的值(例如,在使用msa的解码器的情况下,所存储的值被称为每个校验节点的min1、min2、minposition或“校验节点信息”)。
在某些实施例中,在每个时钟周期,可以使用cnu140的每个存储器元件170的值与从vnu120接收的v2c消息一起计算c2v消息值。因而,可以在每个时钟周期在cnu140中计算c2v消息,并且可以将计算的c2v消息发送到vnu120。
在某些实施例中,vnu120对从cnu140接收的c2v消息进行处理,以计算v2c消息。可以将计算的v2c消息重新发送(retransmit)到cnu140。
在某些实施例中,cnu140将从vnu120发送的v2c消息与存储在cnu140的存储器元件170中的值组合,以更新存储器元件170的值。例如,当使用msa执行解码时,从vnu120发送的v2c消息可被用来更新校验节点的第一最小值(min1)、第二最小值(min2)、以及第一最小位置信息(min1position)。当发送的v2c消息小于存储器元件170中存储的min1时,可以将min1改变为发送的v2c消息、可以将min2改变为更新前的min1、并且可以将min1position调整为正被处理的可变节点位置。
存储器160可用来暂时地存储执行vnu120和/或cnu140的操作所需的数据。例如,存储器160可以存储执行ldpc解码的码字、v2c消息、c2v消息、中间值、最终值等。
如图1所示,cnu140通常包括多个存储器元件170,但可以包括单个存储器元件170,或者可以并不包括存储器元件,在这一情况下,存储器元件可以在cnu140的外部。例如,存储器元件可以提供在存储器160的内部。
在ldpc解码器100中,vnu120和cnu140之间的互连被固定。因而,ldpc解码器100不需要诸如在一般的ldpc解码器中所要求的复杂互连电路。
在ldpc解码器100中,除了简单的循环移位之外,仅在与vnu120互连的cnu140的存储器元件170处执行存储器元件170的更新。因此,与一般的ldpc解码器相比,执行更新操作所需的逻辑可以显著减少。即,可以仅在与vnu120互连的cnu140的存储器元件170处使用更新操作逻辑。
即使当从cnu140向vnu120发送c2v消息时,ldpc解码器100优选地仅在与vnu120互连的cnu140的存储器元件170处计算c2v消息。因而,与一般的ldpc解码器相比,与c2v消息的计算相关联的cnu140中的逻辑可以显著减少。即,可以仅在与vnu120互连的cnu140的存储器元件170处使用与c2v消息的计算相关联的逻辑。
如上所述,ldpc解码器100可以仅使用和与vnu120互连的cnu140的存储器元件170的数目一样多的与c2v消息和校验节点信息(例如,在msa情况下的min1、min2、min1position)相关联的逻辑。与要求与所有校验节点的存储器元件相关联的逻辑的一般的ldpc解码器相比,这显著地减小了ldpc解码器100消耗的区域的量。
继续参照图1,当cnu140的存储器元件170的校验节点值在每个时钟周期沿实线移动时,经互连而连接到vnu120的校验节点的顺序可以保持不变。另一方面,存储在cnu140的存储器元件170中的校验节点的顺序可以通过如虚线所示在cnu140的存储器元件170之间添加互连而改变。因而,ldpc解码器100可以改变用于ldpc解码的h矩阵的模式。
如图1所示,cnu140的存储器元件170之间存在互连。由虚线指示的互连是特意被添加以改变校验节点的顺序的路径。在图1中,从下一个时钟周期中标记为1的一个存储器元件170移动的路径可以是到标记为2或4的存储器元件170的任一者。同时,从下一个时钟周期中标记为3的一个存储器元件170移动的路径可以是到标记为2或4的存储器元件170的任一者。在按1→2→3→4的顺序选择路径的情况下,该情况与不存在附加互连的情况相同。另一方面,在按1→4→3→2的顺序选择路径的情况下,校验节点值可以沿不同于现有路径的路径向cnu140的存储器元件170移动。
如上所述,可以非常简单地实现ldpc解码器100的cnu140的附加互连。因此,与ldpc解码器不具有附加互连的情况相比,可以极大地增加实现h矩阵的自由度。其原因在于,ldpc解码器100的cnu140/vnu120中处理的校验节点顺序可以通过在每个时钟周期在存储器元件之间不同地设置两种类型的路径模式而改变。因而,ldpc解码器100可被配置为支持不具有码率、纠正能力和解码收敛速度的限制而仅有复杂度的最小增加的h矩阵。
例如,为了在无附加互连的情况下实现15×145的h矩阵(作为一般的ldpc解码器的情况),列数可以是行数的倍数。因此,在无附加互连的情况下很难实现15×145的h矩阵。其原因在于,存储在ldpc解码器的cnu的存储器元件中的校验节点值应当在对应于一次迭代的时钟周期之后,返回到原始顺序,并且该周期等于校验节点的数目。因而,在其中不存在附加互连的一般ldpc解码器的情况下,可以消耗150个时钟周期,以便支持15×145的h矩阵。
但是,根据ldpc解码器100和由此执行的解码方法,存储在cnu140的存储器元件170中的校验节点信息的顺序可以在每个时钟周期改变,以生成具有更大周期的校验节点顺序模式。因此,ldpc解码器100可以支持各种列数的h矩阵。例如,如果存在将存储在cnu140的存储器元件170中的校验节点的顺序恢复成原始顺序的模式,则ldpc解码器100可以支持具有与相应时钟周期一样多的列的h矩阵。
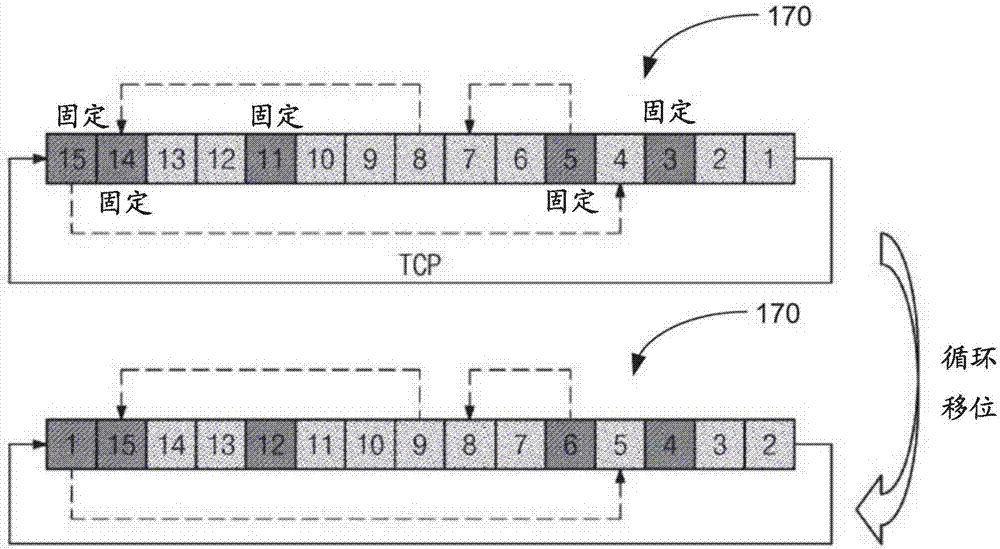
图2示出了根据代表性实施例的包括用于支持h矩阵的cnu140的存储器元件170的互连的第一排列(τ)。出于示范的目的,将假设cnu140具有15个存储器元件170。但是,要理解,存储器元件170的数目不限于15。
在以下的讨论中,各个存储器元件170被标记有数字1至15,为了概念性地说明发送存储在存储器元件中的值的过程。
每个存储器元件170在每个时钟周期从左向右发送值。标记为15、14、11、5和3的每个存储器元件170是与vnu120互连的cnu140的存储器元件(见图1)。在路径处定义的校验节点的值的移动可被视为在集合{1,2,...,14,15}上定义的排列。例如,图2中所示的第一排列(τ)对应于(15,14,13,12,11,10,9,8,7,6,5,4,3,2,1)。第一排列(τ)可以是由标记为15至1的所有存储器元件170形成的全部循环排列(totalcyclicpermutation,tcp)。
与该代表性实施例一致,标记为15、14、11、5和3的每个存储器元件170固定地与vnu120互连。
图3示出了根据另一代表性实施例的包括用于支持h矩阵的cnu140的存储器元件170的互连的第二排列(σ)。第二排列(σ)对应于(15,4,3,2,1)、(7,6,5)、以及(14,13,12,11,10,9,8)。第二排列(σ)可以包括由标记为15、4、3、2和1的5个存储器元件170形成的第一循环排列pcp1、由标记为7、6和5的3个存储器元件170形成的第二循环排列pcp2、以及由标记为14、13、12、11、10、9和8的7个存储器元件170形成的第三循环排列pcp3。第一、第二、和第三循环排列pcp1、pcp2、和pcp3的每个包括存储器元件170的子集(即,少于全部)。以下,该循环排列将被称为“部分循环排列”。
总结图2和图3,图2中所示的第一排列(τ)包括包含cnu140的所有存储器元件170的全部循环排列(tcp),并且图3中所示的第二排列(σ)包括包含cnu140的存储器元件170的相应子集的至少两个部分循环排列(pcp)。
根据代表性实施例的ldpc解码所需的h矩阵可被用来通过将对应于图2所示第一路径的第一排列(τ)与对应于图3所示第二路径的第二排列(σ)组合来调整cnu140的存储器元件的周期。例如,用来在对应于图2的第一路径状态下运行循环m次和用来在对应于图3的第二路径状态下运行循环n次的模式可被表示为σnτm。
图4示出了根据代表性实施例的将校验节点存储器元件的状态恢复为原始状态所需的排列组合模式的周期和循环。
由于在该示例中,第一排列(τ)的周期为15,所以60(σ3τ)+15(τ)+55(σ4τ)+15(τ)=145。在145个循环之后,校验节点的存储器元件的状态被恢复为原始状态。当在15×145的h矩阵解码中使用了混洗(shuffled)解码时,最小循环为145。因而,如果使用了根据代表性实施例的排列组合模式,则可以使用该最小循环执行一次迭代。
在某些情况下,为了实现ldpc编码效率,h矩阵的奇偶块部分可以呈双对角线形式。例如,当以60(σ3τ)+15(τ)+55(σ4τ)+15(τ)=145这样的方式形成15×145的h矩阵时,分别在60、15、55和15个循环之后恢复存储器元件的原始状态。
图5示出了根据代表性实施例的生成ldpc解码器100的循环0和130中双对角线型h矩阵的过程。参照图5,如果存储器元件170被配置为在130个循环之后恢复原始顺序,当存储器元件的顺序在循环0中为1,15,14,13,…,4,3,2时,则存储器元件的原始顺序为1,15,14,12,…,4,3,2。可以使用60+15+55=130的排列获得130个循环的周期。在15个循环期间使用第一排列(τ)移动校验节点值,并且在130个循环处使用cnu140的标记为1、2和11的存储器元件170。
图6示出了根据代表性实施例的生成ldpc解码器100的131个循环处的双对角线型h矩阵的过程。参照图6,连接到可变节点的校验节点的数目为2,这不同于图5所示校验节点的数目。即,在131个循环处,标记为2和1的cnu140的两个存储器元件170连接到相应的校验节点。
图7示出了根据代表性实施例的生成ldpc解码器100的132个循环处的双对角线型h矩阵的过程。参照图7,在132个循环处,标记为3和2的cnu140的两个存储器元件170连接到相应的校验节点。
总结图6和图7中描述的过程,从131个循环到144个循环,可以仅使用cnu140的两个存储器元件170实现双对角线型的h矩阵。
根据代表性实施例的ldpc解码器100的cnu140具有附加路径,以便实现多开销配置,现将参照图8至图11对此进行描述。
图8示出了根据代表性实施例的用于实现多开销配置的cnu140的存储器元件170的附加路径。参照图8,存储器元件170包括由从标记为2的一个存储器元件170指向标记为15的另一存储器元件170的实线箭头所指示的附加路径。因而,支持了15×145的h矩阵和14×145的h矩阵两者。
在示例实施例中,可以互连存储器元件,以将校验节点值发送到附加排列,并且附加排列可以包括由其数目小于存储器元件170的总数目的存储器元件170的子集形成的全部循环排列。
图9示出了依据图8中附加路径的第一附加排列(τ')。参照图9,第一附加排列(τ')可以包括包含标记为15、14、13、12、11、10、9、8、7、6、5、4、3和2的14个存储器元件的全部循环排列tcpa。
图10示出了依据图8中附加路径的第二附加排列(σ')。参照图10,第二附加排列(σ')可以包括包含标记为15、4、3和2的4个存储器元件的第一部分循环排列pcp1a、包含标记为7、6和5的3个存储器元件170的第二部分循环排列pcp2a、以及包含标记为14、13、12、11、10、9和8的7个存储器元件的第三部分循环排列pcp3a。
如上所述,为了在经一次迭代实现145个循环的同时形成双对角线型的14×145的h矩阵,使用切换模式在131个循环之后恢复校验节点的存储器元件的状态。这可以通过应用第一排列(τ)、图9中的第一附加排列(τ')和图10中的第二附加排列(σ')实现。
图11示出了根据代表性实施例的支持ldpc解码器100的多开销配置的h矩阵的排列组合。参照图11,用来在131循环期间恢复原始状态的模式可以通过组合图2、图9和图10中的排列(τ、τ'和σ')形成。
例如,通过组合36(σ'2τ')+15(τ)+44(σ'3τ')+36(σ'2τ')+14(τ')=145,可以在保持双对角线状态的同时形成14×145的h矩阵。
根据代表性实施例的ldpc解码器100被用作存储设备的纠错码,现将参照图12对此进行描述。
图12示出了根据代表性实施例的存储设备200。如所示,存储设备200包括至少一个非易失性存储器(nvm)210和控制该非易失性存储器210的存储器控制器220。
非易失性存储器210可被实现为存储信息和对应于该信息的奇偶性。奇偶性可以包括纠错码(ecc)。
在某些实施例中,(多个)nvm210包括nand快闪存储器、垂直nand(vnand)快闪存储器、nor快闪存储器、电阻式随机存取存储器(rram)、相变存储器(pram)、磁阻式随机存取存储器(mram)、铁电随机存取存储器(fram)、自旋转移力矩随机存取存储器(stt-ram)、晶闸管随机存取存储器(tram)等。
在某些实施例中,使用三维(3d)存储器阵列实现(多个)nvm210。3d存储器阵列整体地形成在存储器单元的阵列的一个或多个物理级中,存储器单元具有布置在硅基底之上的有源区域以及与所述存储器单元的操作相关联的电路,无论所述相关联的电路是在该基底上还是在该基底内。术语“整体”,当在本文使用该术语时,意指将阵列的每级的层直接放置在阵列的每个基础级的层上。
与代表性实施例一致,3d存储器阵列包括垂直nand串,其是垂直导向的,使得一个或多个存储器单元位于一个或多个其它存储器单元之上。所述存储器单元中的至少一个可以包含电荷俘获层。每个垂直nand串可以包括位于一个或多个存储器单元之上的至少一个选择晶体管,所述选择晶体管具有与存储器单元相同的结构并且与其整体地形成在一起。
以下专利和已公开的专利申请(特此通过引用将其整体地并入本文)描述了配置为多个级的3d存储器阵列的适当的配置,其中,级之间共享字线和/或比特线:美国专利no.7,679,133、8,553,466、8,654,587、8,559,235;以及美国专利公开no.2011/0233648。根据本文公开的代表性实施例的nvm不仅可应用于其中由导电浮动栅极形成电荷存储层的快闪存储器设备,也可应用于其中由绝缘层形成电荷存储层的电荷俘获快闪(ctf)存储器设备。
存储器控制器220被配置为控制(多个)nvm210。存储器控制器220可以包括纠错电路(ecc)222,ecc222可以包括用来生成对应于信息的ecc的ldpc编码器222-1和用来接收码字(信息+奇偶性)并且执行ecc纠正的ldpc解码器222-2。ldpc解码器222-2可被实现为以上参照图1至图11描述的ldpc解码器100。码字可被输入到vnu120的可变节点(见图1)。
与代表性实施例一致,ldpc解码器222-2包括至少一个处理器,其被配置为使用如上所述的可变节点更新操作和校验节点更新操作执行解码。
ldpc222-2包括被配置为根据信道信息和校验节点消息(c2v消息)执行可变节点更新操作的vnu120(见图1)、被配置为根据可变节点消息(v2c)执行校验节点更新操作的cnu140(见图1)、存储器元件170、输入/输出(i/o)设备等。
根据代表性实施例,第一存储器元件存储用于执行校验节点更新的校验节点信息。根据代表性实施例,第一存储器元件之间存在互连,并且,存储在第一存储器元件中的校验节点信息的顺序和/或位置可以在每个时钟周期改变。根据代表性实施例,第一存储器元件之间的互连可以包括两个或更多个类型的路径。根据代表性实施例,移位校验节点信息的顺序和/或位置的方法在每个时钟周期改变。
根据代表性实施例,vnu120(见图1)和cnu140具有用于消息传输的固定互连。
根据代表性实施例,第二存储器元件存储用于执行可变节点更新的可变节点信息。根据代表性实施例,第二存储器元件之间存在互连,并且,存储在第二存储器元件中的可变节点信息的顺序和/或位置可以在每个时钟周期改变。根据代表性实施例,第二存储器元件之间的互连包括两个或更多个类型的路径。根据代表性实施例,改变可变节点信息的顺序和/或位置的方法在每个时钟周期改变。
在某些实施例中,信道信息包括信道对数似然比(llr)。
在某些实施例中,校验节点消息包括从校验节点向可变节点发送的校验-至-可变(c2v)消息。在某些实施例中,可变节点消息包括从可变节点向校验节点发送的可变-至-校验(v2c)消息。
在某些实施例中,校验节点信息包括第一最小值(min1)、第二最小值(min2)、用来发送第一最小值消息的可变节点索引、以及发送到相应校验节点的v2c消息中的v2c消息的乘号(signmultiplication)。
在某些实施例中,第一存储器元件的每个包括寄存器。在某些实施例中,第一存储器元件彼此连接,以通过它们移位循环移位的值。在某些实施例中,第一存储器元件被划分为多个组或子集,并且每个组的存储器元件彼此连接,以通过它们以循环移位的形式移位值。
在某些实施例中,ldpc解码器222-2还包括控制逻辑,其被配置为在每个时钟周期选择存储校验节点信息的第一存储器元件之间的互连。
在某些实施例中,校验节点消息包括从校验节点向可变节点发送的c2v消息。在某些实施例中,可变节点消息包括从可变节点向校验节点发送的v2c消息。在某些实施例中,可变节点信息包括相应可变节点的后验概率(app)或者log-app。
在某些实施例中,第二存储器元件中的每个包括存储校验节点信息的寄存器。在某些实施例中,存储校验节点信息的存储器元件之间的互连中的一个可以以循环移位的形式实现,以将值移位到相邻存储器元件。在某些实施例中,存储校验节点信息的存储器元件之间的互连中的一个被划分为多个组,并且每个组的存储器元件互相连接,从而以循环移位的形式移位值。
在某些实施例中,ldpc解码器222-2还包括控制逻辑,其被配置为在每个时钟周期选择存储校验节点信息的存储器元件之间的互连。
图13示出了表示由图12中所示存储设备200执行的读取操作的流程图。参照图12和图13,可以执行存储设备200的读取操作如下。
通常,硬判决信息仅包括关于存储在存储器单元中的比特的读取值是0还是1的信息。同时,软判决信息包括关于存储在存储器单元中的比特的量化的读取信息。例如,针对比特的软判决信息的值可以包括0、1、以及0和1之间的值。仅包括关于比特是0还是1的信息的硬判决信息缺乏可靠性信息,而关于比特的软判决信息包括较多的可靠性信息并且因此可以在纠错方面是有益的。
执行硬判决存储器感测,如框s110所示。将所读取的数据从nvm210发送到存储器控制器220的纠错电路222,如框s120所示。纠错电路222的ldpc解码器222-2使用ldpc解码对所读取的数据进行硬判决,如框s130所示。对是否成功地做出硬判决进行确定,如框s140所示。如果成功地做出了硬判决,则完成读取操作。如果没有成功地做出硬判决,则流程前进至框s150。
在框s150处执行软判决存储器感测。将所读取的数据从nvm210发送到存储器控制器220的纠错电路222,如框s160所示。纠错电路222的ldpc解码器222-2使用ldpc解码对所读取的数据执行软判决,如框s170所示。在某些实施例中,在用于做出软判决而执行ldpc解码时使用的h矩阵与在用于做出硬判决而执行ldpc解码时使用的h矩阵相同。替换地,在用于做出软判决而执行ldpc解码时使用的h矩阵与在用于做出硬判决而执行ldpc解码时使用的h矩阵不同。如上所述,可以通过全部循环排列和部分循环排列的组合可变地确定或选择h矩阵。
对是否成功地做出软判决进行确定,如框s180所示。如果成功地做出了软判决,则读取操作完成。如果没有成功地做出软判决,则可以认为读取操作失败,在这一情况下,可以执行附加的读取/重写操作。
图14示出了根据代表性实施例的包括使用对象存储装置的服务器的电子系统1000的框图。如所示,电子系统1000包括主机1100和存储服务器1200。
主机1100根据包括在主机1100中的各种电子电路/芯片/设备的操作向主机1100的用户提供服务。例如,主机1100可以执行各种操作以处理从主机1100的用户接收的命令,并且可以将操作结果提供给主机1100的用户。为了实现这一点,例如,主机1100可以包括包含专用逻辑电路(例如,现场可编程门阵列(fpga)、特定用途集成电路(asic)等)的操作处理器(例如,中央处理单元(cpu)、图形处理单元(gpu)、应用处理器(ap)等)。
根据该代表性实施例,存储服务器1200包括处理器1210、基于非易失性存储器的存储装置1230、以及基于易失性存储器的存储装置1250。存储服务器1200执行以上参照图1至图12描述的ldpc解码或ecc功能。例如,基于非易失性存储器的存储装置1230和基于易失性存储器的存储装置1250中的至少一个可被实现以执行上述ldpc解码方法。
在某些实施例中,基于非易失性存储器的存储装置1230和基于易失性存储器的存储装置1250中的至少一个包括对象存储装置。与块存储装置或文件存储装置不同,对象存储装置基于对象的唯一标识符管理数据。例如,对象存储装置可以从主机1100接收具体数据和对应于该具体数据的“密钥”。密钥唯一地标识所述具体数据。当由于对象存储装置的特性而使诸如音频数据或视频数据的非典型数据的量大时,对象存储装置可以比块存储装置或文件存储装置更有效地管理数据。
如上所述,ldpc解码器100和222-2以及包括ldpc解码器100和222-2的存储设备在每个时钟周期选择包括可变节点/校验节点信息的存储器元件170的互连,以实现各种可支持的解码矩阵。
应当注意的是,已经参照几个代表性实施例描述了本发明的原理和构思,并且本发明的原理和构思不限于这些实施例。代表性实施例被视为说明性的,而非限制性的,并且所附权利要求意图覆盖落入发明原理和构思的精神和范围内的所有这样的修改、增强、和其它特征。因此,为了最大程度被法律允许,要由以下权利要求及其等同物的最宽的允许的解释确定发明原理和构思的范围,并且发明原理和构思的范围不受以上具体描述的约束或限制。尽管已具体地示出和描述了某些代表性实施例,但本领域普通技术人员将理解,鉴于本文提供的描述,在不脱离权利要求的精神和范围的情况下,可以对这些实施例做出形式和细节上的改变。
- 还没有人留言评论。精彩留言会获得点赞!