一种基于货车监控数据的装卸货地点识别方法与流程
本发明属于数据挖掘技术领域,具体涉及一种基于货车监控数据的装卸货地点识别方法。
背景技术:
国家要求道路营运车辆必须安装车辆监控系统,车辆运行的时候会产生大量的数据,挖掘车辆监控数据分析驾驶员偏好特征可以为他们提供更加个性化的地理信息服务。通过判断速度和gps点的有无,以及包络半径可以找出所有的停车点,但是很多停车点往往是红绿灯,司机的沿途休息、吃饭地点。又因为越来越多的货物运输采用甩挂运输形式,装卸货时间很短,不能仅仅依靠货车停车时间的长短判断车辆的装卸货地点,如何从货车监控数据中挖掘货车的装卸货地点,对有效识别在货车驾驶员的特定行为,分析驾驶员在各位置之间的关系以及预测货车驾驶员在这些位置之间的活动有重要意义。
技术实现要素:
有鉴于此,本发明的目的是提供一种基于货车监控数据的装卸货地点识别方法,可以识别出真正的装卸货地点。
本发明的一种基于货车监控数据的装卸货地点识别方法,包括如下步骤:
步骤1、货车监测数据的清洗与修复,具体为:
s11、轨迹数据分段:按照检测数据的时间戳顺次检查车辆历史数据,针对监控数据的时间戳tτ,若tτ-tτ-1>4小时,则时间戳tτ之前的监控数据构成一个新的轨迹段,针对该轨迹段,再进一步进行判断是否满足tτ-1-t1<1小时,如果不满足,保留该轨迹段;如果满足,则舍弃该轨迹段;剩余监控数据从时间戳tτ开始顺次进行判断;
s12、顺次检索车速数据,将车速小于0km/h或大于150km/h的点记为缺失数据,并对缺失数据进行修复;
s13、针对s12得到的监控数据,顺次检索车辆加速度数据,判断加速度是否满足车辆运动学规律,如果不满足,则记为缺失数据,并对缺失数据进行修复;
s14、对s13得到的监控数据进行数据平滑;
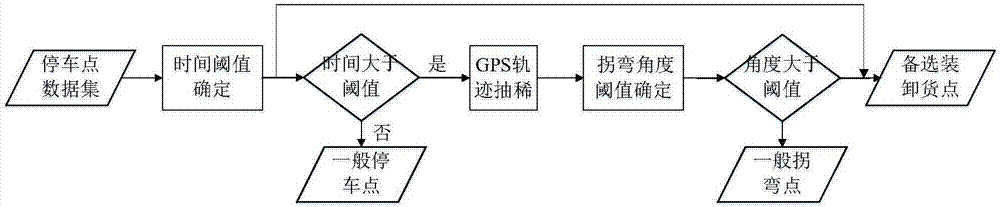
步骤2、对装卸货停车点进行判别,具体为:
s21、计算停留时间阈值th;
s22、找出车辆速度小于设定阈值vh的点,则初步判断为停车点;对停车点进行聚类,对每一类聚类点计算其停车时间,若停车时间大于停留时间阈值th,则认为是停车点,否则认为是一般停车点;
s23、轨迹抽稀
a、针对每一个轨迹段,确定轨迹段中的停车点后,相邻两个停车点之间轨迹作为车辆的一次出行轨迹;
b、针对每个出行轨迹,连接出行轨迹的首端点和末端点,记为线段l;若出行轨迹中某个轨迹点对线段l的垂足在线段l外,则将该出行轨迹以此轨迹点为界分割成两个子轨迹;
c、然后按照b的方法分别处理两个子轨迹,直到子轨迹没有轨迹点的垂足在线段之外,此时判断子轨迹首末端点的距离是否满足要求,如果满足:将子轨迹中除首、末端点之外的轨迹点删除;如果不满足,继续将子轨迹进行分割,直到子轨迹的首末端点的距离满足要求,并将子轨迹中除首、末端点之外的轨迹点删除;
d、按照b和c的方法处理每一次出行轨迹,完成每一个轨迹段的抽稀;
s24、折返点判定:针对抽稀后的各个轨迹段,根据设定的折返角阈值判断其中的每个轨迹点是否为折返点,如果是,则认为是折返点;如果否,认为是一般拐弯点;
步骤3、将s22判定的停车点以及s24认定的折返点作为备选装卸货停车点,针对备选装卸货停车点,根据车辆到达装卸备选点前和离开备选点后车的总质量判断备选装卸货停车点是否为真的装卸货停车点。
较佳的,s12中,当只有当前一个点为缺失数据时,称为孤立缺失数据,对孤立缺失数据的修复,采用缺失数据之前和之后的数据值加权平均方法进行修复。另一种为连续缺失数据;孤立缺失数据是指该数据前后的数据都存在,,连续缺失数据是指其前部或后部有连续三个点(包括当前点)缺失的数据。修复方法如式所示:
式中,vτ为使用加权平均方法的车速修复结果,wi为加权系数,w为所有加权系数之和,为修复数据所用相邻数据的最大间隔;vτ+i离缺失数据vτ越远,加权系数wi的值越小;
较佳的,s12中,当前缺失数据点之前和/或之后有连续三个数据点缺失的数据称为连续缺失数据;对于连续缺失数据的修复,采用指数平滑方法,如式所示:
vτ+r=aτ+bτ·r
式中,r=0,1,2,…,r-1;r为缺失数据累计序号,r为连续缺失数据个数,aτ,bτ为中间变量,分别由下式确定:
式中,α为平滑系数,α∈(0,1),
较佳的,s13中,判别轨迹点的加速度是否满足车辆运动学规律的方法为:车辆加速度小于0.9g,则正常数据;若加速度大于或等于0.9g,轨迹数据记为缺失数据;缺失的轨迹点数据直接用插值法对数据进行修。
较佳的,s14中,采用移动平均方法对数据进行平滑处理。
较佳的,s21中,计算停留时间阈值th的方法为:
选取n个(这里n取100)停车点作为样本,按照停留时间t从1分钟到60分钟间隔为1分钟顺序递增,计算不同停留时间下样本的综合评价指标ef,选取ef最大时的t作为停留时间阈值th;综合评价指标ef的计算公式如下:
式中ep为准确率,er为召回率,准确率和召回率的计算公式如下式所示:
式中np是检索到的真正装卸货点数量,nw是检索到的错误的装卸货点数量,nreal是n个停车点中实际的装卸货点总数。
较佳的,s22中,用基于密度聚类方法dbscan对停车点进行聚类。
较佳的,s22中,其停车时间的计算方法为,每一个停车点聚类中,停车时间最大值与最小值的差值即为该聚类的停车时间。
较佳的,s23的步骤c中,删除首末端点之外的轨迹点的方法为:如果所有点的垂足都在线段上,则求所有点与线段的距离,并找出最大距离值dmax,用dmax与垂直距离阈值dh相比,dh取值如下式所示:
式中dl是线段l的长度;若dmax<dh,这条曲线上的中间点全部舍去,若dmax≥dh,保留dmax对应的坐标点,并以该点为界,把曲线分为两部分。
进一步的,针对s22中确定的停车点,输入停车点的地理坐标信息,利用百度地图api获得该坐标的地址信息,在停车点中删除非装卸货停车点,得到的停车点用于下一步的处理。
较佳的,折返角度阈值为150°。
较佳的,步骤3的具体方法为:计算发动机瞬时功率p,再根据
本发明具有如下有益效果:1.从海量数据中挖掘货物场站位置,实现数据的自动采集,可有效构建场站数据库;2.分析驾驶员行为,为驾驶员推送配货信息,实现智能化配货。
附图说明
图1为本发明的识别方法中货车监测数据的清洗与修复流程图;
图2为本发明的识别方法中停车点的判别流程图;
图3为本发明的整体方法流程图;
图4为本发明的车辆载重变化判别流程图。
具体实施方式
下面结合附图并举实施例,对本发明进行详细描述。
步骤1、货车监测数据的清洗与修复
1)轨迹数据分段。货车历史监控数据按时间存储,监控数据dτ={pτ,vτ,qτ,tτ},τ=1,2,…,n,其中pτ为位置信息,pτ={xτ,yτ,zτ},xτ,yτ,zτ分别为车辆的经度纬度和高程信息;vτ为车辆速度,单位为km/h,qτ为车辆扭矩值,单位为n.m;tτ为监控数据的时间戳。按照检测数据的时间戳顺次检查车辆历史数据,若tτ-tτ-1>4小时,则{d1,d2,…,dτ-1,dτ}构成一个新的轨迹段,再进一步进行判断:若tτ-1-t1<1小时,则舍弃该轨迹段,剩余监控数据从dτ开始顺次处理。
2)车速数据清洗与修复。顺次检索车速数据,车速小于0km/h或大于150km/h的点,以-1替代,记为缺失数据。缺失数据分为两种:一种为孤立缺失数据,另一种为连续缺失数据;孤立缺失数据是指该数据前后的数据都存在,只有当前一个点缺失的数据,连续缺失数据是指其前部或后部有连续三个点(包括当前点)缺失的数据。对孤立缺失数据的修复,采用加权平均方法修复,修复方法如式所示:
式中,vτ为使用加权平均方法的车速修复结果,wi为加权系数,w为所有加权系数之和,为修复数据所用相邻数据的最大间隔;vτ+i离缺失数据vτ越远,加权系数wi的值越小;对于连续缺失数据的修复,采用指数平滑方法,如式所示:
vτ+r=aτ+bτ·r
式中,r=0,1,2,…,r-1;vτ+r为使用了指数平滑法的车速修复结果,r为缺失数据累计序号,r为连续缺失数据个数,aτ,bτ为中间变量,分别由下式确定:
式中,α为平滑系数,α∈(0,1),
3)轨迹数据的清洗与修复
考虑gps的定位精度和信号强度问题,车辆在行驶过程中记录的轨迹可能包含一些异常情况,出现gps信号的漂移或轨迹点的粗大误差,大误差点的判别准则是当前点的加速度是否满足车辆运动学规律。计算车辆的加速度
缺失的轨迹点数据直接用插值法对数据进行修复,公式如下。
4)数据平滑。异常数据清洗修复后,数据中仍然存在一些噪声数据,影响数据的鲁棒性,导致后续的计算产生偏差,为减少噪声数据的影响,这里采用移动平均方法对数据进行处理,轨迹数据
2.停车点判别
1)计算停留时间阈值th。选取n个(这里n取100)停车点作为样本,按照停留时间t从1分钟到60分钟间隔为1分钟顺序递增,计算不同停留时间下样本的综合评价指标ef,选取ef最大时的t作为停留时间阈值th。综合评价指标ef的计算公式如下:
式中ep为准确率,er为召回率,准确率和召回率的计算公式如下式所示。
式中np是检索到的真正装卸货点数量,nw是检索到的错误的装卸货点数量,nreal是n个停车点中实际的装卸货点总数。
2)以速度判断车辆的停车点,找出车辆速度小于阈值vh的点,并针对找到的点用基于密度聚类方法dbscan(density-basedspatialclusteringofapplicationswithnoise)对停车点进行聚类,对每一类聚类点计算其停车时间,若停车时间大于停留时间阈值th,则认为是停车点,否则认为是一般停车点。其中,停车时间的计算方法为,每一个停车点聚类中,停车时间最大值与最小值的差值即为该聚类的停车时间。
3)轨迹抽稀
a、针对每一个轨迹段,确定轨迹段中的停车点后,相邻两个停车点之间轨迹作为车辆的一次出行轨迹;
b、针对每个出行轨迹,连接出行轨迹的首端点和末端点,记为线段l;若出行轨迹中某个轨迹点对线段l的垂足在线段l外,则说明末端点不是离首端点最远点,则将该出行轨迹以此轨迹点为界分割成两个子轨迹;
c、然后按照b的方法分别处理两个子轨迹,直到子轨迹没有轨迹点的垂足在线段之外,此时判断子轨迹首末端点的距离是否满足要求,如果满足:将子轨迹中除首、末端点之外的轨迹点删除;如果不满足,继续将子轨迹进行分割,直到子轨迹的首末端点的距离满足要求,并将子轨迹中除首、末端点之外的轨迹点删除;
d、按照b和c的方法处理每一次出行轨迹,完成轨迹的抽稀;
其中,在步骤c中,如果所有点的垂足都在线段上,则求所有点与线段的距离,并找出最大距离值dmax,用dmax与垂直距离阈值dh相比,dh取值如式所示。
式中dl是线段l的长度,单位km,若dmax<dh,这条曲线上的中间点全部舍去,若dmax≥dh,保留dmax对应的坐标点,并以该点为界,把曲线分为两部分,对这两部分重复使用该方法。
4)折返角度阈值确定
针对抽稀后的轨迹找转折点就好,找转折点的方法就是判断夹角大小,正常沿直线行走,夹角应该接近于0°,如果达到了接近180°的时候说明这是一个折返点。本发明中定义折返角度为150°。对每一个抽稀后的点计算其折返角度,若折返角度大于150°,则认为是折返点,否则认为是一般拐弯点。
其中,针对认定的停车点,采用以下方法剔除非装卸货停车点,具体为:计算逆地理编码,删除干扰停车点;逆地理编码是指输入地理坐标信息,获得该坐标的地址信息。用百度地图api,输入经纬度坐标,得到经纬度点的位置信息,删除含有“加油站”、“服务区”等关键词的位置点。
将判定的停车点以及认定的折返点作为备选装卸货停车点。
3.车辆载重变化判别
备选的装卸车地点获得后,如果车辆的载重发生变化,才认为该点为车辆装卸货地点。具体流程如下:
(1)车辆载重计算
发动机瞬时功率的计算如下式所示:
p=rmp×torque×2π/60
式中,p为发动机瞬时功率,单位:瓦特;rpm为转速,单位:r/min;torque为扭矩,单位:n.m;又已知
f=ma
式中m为车辆和货物的总质量,a为车辆运行加速度。综合上式,可得车辆和货物的总质量m
在具体计算中,需选取某段时间内匀加速行驶行为,才能较好的符合牛顿第二定律的使用条件。本研究选取每辆卡车连续匀加速10秒钟及以上的点,作为研究个案数据。
(2)车辆载重变化判别
计算货车到达装卸备选点前和离开备选点后车的总质量,比较两种情况下车辆质量是不是有明显差别,若差别明显,认为该点是装卸货点,否则认为该点为一般停车点。差别明显的判断标准看前后车重相差是否超过10%。
综上所述,以上仅为本发明的较佳实施例而已,并非用于限定本发明的保护范围。凡在本发明的精神和原则之内,所作的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!