一种基于无监督自动编码器的面部重建方法与流程
本发明涉及面部重建领域,尤其是涉及了一种基于无监督自动编码器的面部重建方法。
背景技术:
人体最重要的生物特征之一就是人脸,脸部重建是计算机视觉领域热门的领域之一。人脸重建具有广阔的实际应用,在人脸识别系统、医学、电影广告、计算机动画、游戏、视频会议以及可视电话、人机交互等领域具有广阔的应用前景。在公共安全领域,人脸重建和识别对公安刑侦、预防犯罪等方面有着越来越大且难以忽视的作用。近年来,恐怖活动、暴力事件、暴力犯罪等严重威胁公共安全的时间频繁出现,人脸识别能够方便地对重点区域的进出人员进行控制、对各个场合进行隐蔽监控等,这些都能有效保护公共安全。然而,面部姿态、形状、表情、肤色和场景照明等都会给重建带来影响,提高重建的难度。
本发明提出了一种基于无监督自动编码器的面部重建方法,以语义码矢量的形式给出场景描述,参数解码器生成对应面部的合成图像,通过标准反向传播反转图像形成,实现无人监督的端到端训练,包括图像形成模型、照明模型、图像形成和反向传播,由三个项定义损失函数,包括密集的光度校准、稀疏地标对齐、统计正则化和反向传播。本发明可以编码面部的细节,如姿态、形状、表情、肤色和场景照明等,而且更加精细,无须监督,并且允许端到端学习;与合成人脸数据训练的网络相比,此网络能更好地推广到现实数据中。
技术实现要素:
针对面部姿态、形状、表情、肤色和场景照明等会产生影响的问题,本发明的目的在于提供一种基于无监督自动编码器的面部重建方法,以语义码矢量的形式给出场景描述,参数解码器生成对应面部的合成图像,通过标准反向传播反转图像形成,实现无人监督的端到端训练,包括图像形成模型、照明模型、图像形成和反向传播,由三个项定义损失函数,包括密集的光度校准、稀疏地标对齐、统计正则化和反向传播。
为解决上述问题,本发明提供一种基于无监督自动编码器的面部重建方法,其主要内容包括:
(一)语义码矢量;
(二)基于参数模型的解码器;
(三)损失层。
其中,所述的语义码矢量,语义码矢量
x=(α,δ,β,t,t,γ)(1)
由上式以统一的方式显示;
脸部表示为具有n=24k顶点
其中,平均脸部形状as基于200个(100个男性,100个女性)高质量面部扫描计算;线性主成分分析基础
除面部几何外,根据仿射参数模型对每个顶点肤色
这里计算了平均肤色ar,并且正交主成分分析基础
其中,所述的基于参数模型的解码器,以语义码矢量x的形式给出场景描述,参数解码器生成对应面部的逼真合成图像;图像形成模型是完全分析和可微分的,通过标准反向传播反转图像形成,这使网络可以实现无人监督的端到端训练;其包括图像形成模型、照明模型、图像形成和反向传播。
进一步地,所述的图像形成模型,透视相机在全视角投影下,使用针孔相机模型渲染逼真的面部图像π:
进一步地,所述的照明模型,使用球形谐波(sh)代表场景照明;因此,用正常表面ni和肤色ri评估顶点vi处的辐射度如下:
hb:
进一步地,所述的图像形成和反向传播,使用呈现的相机和照明模型渲染场景的逼真图像;为此,在正向通过
tni将空间法线转换为相机空间,并在相机空间中将γ模型照射;
训练实现了反转图像形成的反向传递:
这需要相对于面部和场景参数计算图像形成模型的梯度;为了在训练过程中实现高效率,以数据并行方式评估梯度。
其中,所述的损失层,损失函数结合了三个项:
eloss(x)=wlandeland(x)+wphotoephoto(x)+wregereg(x)(7)
其中,eland为执行稀疏的地标对齐,ephoto为密集的光度对齐,freg为统计似然性的模型面孔;二进制权重wland∈{0,1}切换此约束;恒权重wphoto=1.92,wreg=2.9×10-5;
损失层包括密集的光度校准、稀疏地标对齐、统计正则化和反向传播。
进一步地,所述的密集的光度校准,编码器的目标是预测导致与所提供的单目输入图像匹配的合成人脸图像的模型参数;为此,使用密集光度对齐,在每顶点水平上使用鲁棒的l2,1范数:
其中,
进一步地,所述的稀疏地标对齐,除了密集的测光对齐,提出了基于检测到的面部特征点的可选替代丢失;使用46个地标的一个子集(66个地图);给定了检测到的2d地标
这种替代损失是可选的,网络可以完全无人训练,而不提供这些稀疏约束;训练后,不需要地标。
进一步地,所述的统计正则化和反向传播,在训练过程中,使用统计正则化进一步约束优化问题对模型参数的影响:
该约束通过优选接近于平均值的值来限制面部形状α、表情δ和肤色β;参数wβ=1.7×10-3和wδ=0.8平衡项;为了实现基于随机梯度下降的训练,在反向传播过程中,鲁棒损耗的梯度向后传递到基于模型的解码器,并使用链规则与
附图说明
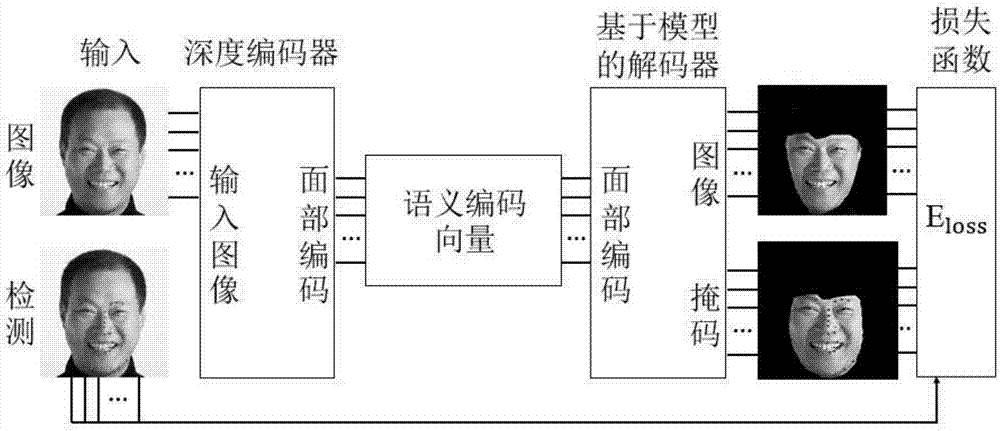
图1是本发明一种基于无监督自动编码器的面部重建方法的系统框架图。
图2是本发明一种基于无监督自动编码器的面部重建方法的流程示意图。
具体实施方式
需要说明的是,在不冲突的情况下,本申请中的实施例及实施例中的特征可以相互结合,下面结合附图和具体实施例对本发明作进一步详细说明。
图1是本发明一种基于无监督自动编码器的面部重建方法的系统框架图。主要包括语义码矢量,基于参数模型的解码器和损失层。
语义码矢量,语义码矢量
x=(α,δ,β,t,t,γ)(1)
由上式以统一的方式显示;
脸部表示为具有n=24k顶点
其中,平均脸部形状as基于200个(100个男性,100个女性)高质量面部扫描计算;线性主成分分析基础
除面部几何外,根据仿射参数模型对每个顶点肤色
这里计算了平均肤色ar,并且正交主成分分析基础
基于参数模型的解码器,以语义码矢量x的形式给出场景描述,参数解码器生成对应面部的逼真合成图像;图像形成模型是完全分析和可微分的,通过标准反向传播反转图像形成,这使网络可以实现无人监督的端到端训练;其包括图像形成模型、照明模型、图像形成和反向传播。
图像形成模型,透视相机在全视角投影下,使用针孔相机模型渲染逼真的面部图像π:
照明模型,使用球形谐波(sh)代表场景照明;因此,用正常表面ni和肤色ri评估顶点vi处的辐射度如下:
hb:
图像形成和反向传播,使用呈现的相机和照明模型渲染场景的逼真图像;为此,在正向通过
tni将空间法线转换为相机空间,并在相机空间中将γ模型照射;
训练实现了反转图像形成的反向传递:
这需要相对于面部和场景参数计算图像形成模型的梯度;为了在训练过程中实现高效率,以数据并行方式评估梯度。
损失层,损失函数结合了三个项:
eloss(x)=wlandeland(x)+wphotoephoto(x)+wregereg(x)(7)
其中,eland为执行稀疏的地标对齐,ephoto为密集的光度对齐,ereg为统计似然性的模型面孔;二进制权重wland∈{0,1}切换此约束;恒权重wphoto=1.92,wreg=2.9×10-5;
损失层包括密集的光度校准、稀疏地标对齐、统计正则化和反向传播。
密集的光度校准,编码器的目标是预测导致与所提供的单目输入图像匹配的合成人脸图像的模型参数;为此,使用密集光度对齐,在每顶点水平上使用鲁棒的l2,1范数:
其中,
稀疏地标对齐,除了密集的测光对齐,提出了基于检测到的面部特征点的可选替代丢失;使用46个地标的一个子集(66个地图);给定了检测到的2d地标
这种替代损失是可选的,网络可以完全无人训练,而不提供这些稀疏约束;训练后,不需要地标。
统计正则化和反向传播,在训练过程中,使用统计正则化进一步约束优化问题对模型参数的影响:
该约束通过优选接近于平均值的值来限制面部形状α、表情δ和肤色β;参数wβ=1.7×10-3和wδ=0.8平衡项;为了实现基于随机梯度下降的训练,在反向传播过程中,鲁棒损耗的梯度向后传递到基于模型的解码器,并使用链规则与
图2是本发明一种基于无监督自动编码器的面部重建方法的流程示意图。以语义码矢量的形式给出场景描述,参数解码器生成对应面部的合成图像,通过标准反向传播反转图像形成,实现无人监督的端到端训练,包括图像形成模型、照明模型、图像形成和反向传播,由三个项定义损失函数,包括密集的光度校准、稀疏地标对齐、统计正则化和反向传播。
对于本领域技术人员,本发明不限制于上述实施例的细节,在不背离本发明的精神和范围的情况下,能够以其他具体形式实现本发明。此外,本领域的技术人员可以对本发明进行各种改动和变型而不脱离本发明的精神和范围,这些改进和变型也应视为本发明的保护范围。因此,所附权利要求意欲解释为包括优选实施例以及落入本发明范围的所有变更和修改。
- 还没有人留言评论。精彩留言会获得点赞!