一种基于卷积神经网络的业务流程推荐方法与流程
本发明属于业务流程建模及推荐技术领域,具体设计一种基于卷积神经网络的业务流程推荐方法。
背景技术:
业务流程管理是现代企业信息化发展的重要组成部分,高效而精准的业务流程建模是现代企业在应对频繁变化的市场需求时的必然要求。由于人工建模复杂性较高并且需要投入大量的人力物力,所以业界对于辅助流程建模技术的需求日益迫切,业务流程推荐是目前国内外最有效的辅助流程建模技术之一。
虽然推荐系统已经被广泛运用于学术和工业领域,但是对于业务流程的推荐工作仍然是一个比较新的研究领域。基于流程管理的不同目的,目前国内外主要有两种类型的业务流程推荐系统:第一种是对已有的完整流程进行重用,即推荐结果是完整的业务流程;第二种是对于流程子图或节点进行重用,推荐的是流程子图或节点。
传统的业务流程推荐算法主要是基于相似度匹配的思想,其基本思想都是通过计算当前构建的流程子图与模式表中流程模型之间的距离,选择距离最小的候选节点推荐给建模人员。其中最有代表性的是基于图编辑距离(grapheditdistance,ged)的推荐算法和基于字符串编辑距离(stringeditdistance,sed)的推荐算法。ged推荐算法采用图的编辑距离作为相似性度量方法进行推荐,该方法通过计算待推荐流程子图与流程模式表中所有流程模式的图编辑距离,将距离最小的流程模式对应的后续节点作为推荐结果;这种方法能够支持流程图中的并行模型,但由于ged的计算存在np-hard问题,算法时间会随着图的节点个数的增加呈指数增长,推荐效率较低。sed推荐算法使用字符串编辑距离作为图相似性度量指标,该方法将流程图的最小dfs编码作为唯一标识,计算此标识的字符串编辑距离并基于此进行流程子图的匹配;这种方法虽然能够在一定程度上降低算法时间复杂度,但是不适用于对包含循环结构的流程进行匹配和推荐。
综合来讲,上述基于流程相似度匹配的推荐思路主要面临以下两大挑战:
(1)由于每次推荐需要与模式表中的所有流程模式进行比对计算距离,并对距离进行排序后作出推荐,因而导致推荐的时间复杂度很高,推荐实时性难以得到保证。
(2)由于基于距离”计算对图的结构有一定要求,对于图中包含复杂结构(如循环结构)的情况距离的数值意义不能很好的体现流程图间的相似性,从而导致推荐的平均准确率偏低。
技术实现要素:
鉴于上述,本发明提供了一种基于卷积神经网络的业务流程推荐方法,能够适用于任何复杂结构的业务流程推荐问题,从而提高了平均推荐准确率;与此同时,该方法的推荐过程具有极小的时间复杂度,从而显著的增强了推荐的实时性。
一种基于卷积神经网络的业务流程推荐方法,包括如下步骤:
(1)获取一定数量的流程文件并对这些文件进行预处理,得到大量流程子图组成训练集;所述流程子图包括末节点以及由其余节点所组成的上游子图,所述上游子图用于特征训练,所述末节点的类型作为分类标签;
(2)对训练集中的上游子图进行数据标准化,得到对应初始特征矩阵;
(3)对初始特征矩阵进行基于矩阵变换的特征提取得到初始特征图;
(4)对初始特征图进行多层卷积核操作以挖掘初始特征图中的隐含特性,得到最终特征图;
(5)对最终特征图中每一行进行子采样并将采样结果组成训练样本,基于大量训练样本作为全连接神经网络的输入层,采用随机梯度下降算法对该神经网络进行训练从而得到分类模型,通过调用所述分类模型为实际业务流程子图推荐后续流程节点。
所述步骤(1)中对流程文件进行预处理的具体过程为:首先对流程文件中的节点进行语义分类标记,同时隐藏掉节点中的具体文字内容,将流程文件抽象成有向图;然后采用gspan频繁子图挖掘算法对流程文件进行子图挖掘,得到大量流程子图。
所述步骤(2)中对上游子图进行数据标准化的具体过程为:首先对有向图形式表示的上游子图中的节点重新进行标记,即从0开始以自然数序列为顺序进行标记,并记录每个节点的原始类型;然后把重新标记后的有向图转化为邻接矩阵的形式,即得到对应初始特征矩阵,矩阵中值为1的位置表示对应的两个节点之间存在有向边相关联。
所述步骤(3)中对初始特征矩阵进行基于矩阵变换特征提取的具体过程为:首先基于同构原理从初始特征矩阵中任取两列进行交换即第i列与第j列交换,再取对应的两行进行交换即第i行与第j行交换,i和j均为自然数且1≤i≤n,1≤j≤n,i≠j,n为初始特征矩阵的维度,通过执行多次这样的交换,得到新矩阵的有向图与初始特征矩阵的有向图互为同构,即含有相同的结构信息;然后设定一个n×n大小的窗口沿着新矩阵对角线由左上角至右下角滑动扫描,从而得到一张由n-n+1个n×n大小的小方阵依次平铺组成的初始特征图,n为大于1的自然数。
所述步骤(4)中对初始特征图进行多层卷积核操作的具体过程为:
首先,使初始特征图作为level-0feature与第一层卷积核cl-1直接相连,cl-1中每一片卷积核的大小为h1×w1,卷积核总片数为f1;进而使cl-1与level-0feature进行卷积操作得到第一级特征图level-1feature,即将cl-1中的每一片卷积核分别与level-0feature中每一个n×n大小的小方阵进行卷积操作,并将得到的结果对应至level-1feature中相应的行和列中,其中h1=w1=n且cl-1在level-0feature中的移动步长为n,则得到level-1feature的大小为f1×(n-n+1);
然后,使level-1feature与第二层卷积核cl-2直接相连,cl-2中每一片卷积核的大小为h2×w2,卷积核总片数为f2;进而使cl-2与level-1feature进行卷积操作得到第二级特征图level-2feature,即将cl-2中的每一片卷积核分别与level-1feature中每一个h2×w2大小的子矩阵进行卷积操作,并将得到的结果对应至level-2feature中相应的行和列中,其中h2=f1且cl-2在level-1feature中的移动步长为1,则得到level-2feature的大小为f2×((n-n+1)-w2+1);
依据上述使每一层卷积核与上一级特征图做卷积操作,则得到的最后一级特征图即为最终特征图。
所述步骤(5)中采用maxpooling对最终特征图中每一行进行子采样。
所述步骤(5)中根据以下损失函数l采用随机梯度下降算法对全连接神经网络进行训练,即通过对卷积核及神经网络迭代调参以确立最优的模型参数,从而得到分类模型;
其中:num为训练样本总数,k为节点的类别总数,c(p)为第p个训练样本所对应分类标签的类别序号,yk(p)和yc(p)(p)分别为第p个训练样本对应输出的类别概率向量中第k个元素值和第c(p)个元素值。
对卷积核及神经网络迭代调参的具体表达如下:
其中:ω和ω'分别为迭代更新前后的模型参数,cl1~clm分别为第1层至第m层卷积核的参数,m为卷积核的总层数,wh和bh分别为神经网络中输入层与隐藏层之间的权重系数和偏置系数,ws和bs分别为神经网络中隐藏层与输出层之间的权重系数和偏置系数,
本发明的有益技术效果如下:
(1)本发明中模型训练阶段和实际测试阶段是分开进行的,虽然线下训练模型耗时较长,但是用于推荐过程的实际测试阶段的耗时极少,一旦通过随机梯度下降迭代计算确定了卷积神经网络各层的参数,那么单次流程分类(推荐)的平均时间复杂度将接近于o(1);所以相比于ged和sed推荐方法,本发明在业务流程推荐场景的耗时将大大减小,从而具备更强的推荐实时性。
(2)本发明对流程图的结构没有局限,不论原始的业务流程图中是否包含复杂结构(如循环结构),都可以用有向图的形式进行统一表达,再进一步处理成矩阵等数据结构供算法程序使用,从而很好的规避了ged和sed推荐方法面临的对于复杂结构的局限性;所以整体上讲,在数据允许的条件下,本发明的平均准确率优于其他两种算法。
附图说明
图1为业务流程推荐系统的典型架构示意图。
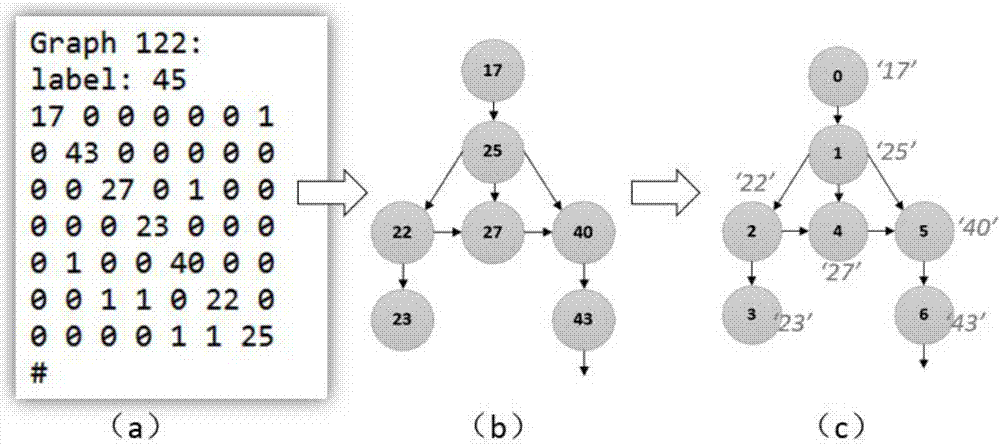
图2(a)为流程子图对应的矩阵示例图。
图2(b)为流程子图对应的有向图。
图2(c)为流程子图对应重新标记后的有向图。
图3为流程数据转化为邻接矩阵的示意图。
图4为基于矩阵变换的特征提取示意图。
图5为基于滑动窗口得到新特征矩阵的过程示意图。
图6为多卷积核操作的设计流程示意图。
图7为子采样层和分类器的设计流程示意图。
具体实施方式
为了更为具体地描述本发明,下面结合附图及具体实施方式对本发明的技术方案进行详细说明。
图1展示了业务流程推荐系统的典型架构,主要包括用户界面、线下挖掘、流程仓库、线上推荐四个模块。用户界面中的流程文件是基于真实的企业流程(如行政许可、方案审批等),并对其业务节点进行语义分类标记(如申请、受理、审核等,相关文献中一般分为52类),再隐藏掉流程的具体文字内容,将专业流程图抽象成基本有向图。在线下挖掘模块中,先采用gspan频繁子图挖掘算法对流程文件进行子图挖掘,得到大量流程子图;然后根据子图中结束节点的位置把子图分解为上游子图us(非结束节点形成的局部图)和候选节点集cns(结束节点集);最后通过计算所有二元组(us,cns)之间的置信度conf(cns,us)形成流程模式三元组(us,cns,conf(cns,us));进一步地提取出置信度高于一定阈值的组合,将其中的上游子图作为“特征值”,将候选节点集作为“标签”,得到业务流程推荐问题的数据集,并持久化存储在流程仓库中。线上推荐模块即是采用相关推荐算法,对用户给出的待推荐流程子图推荐匹配度高的流程节点。
本发明方法处于线上推荐模块,其求解的问题可以用表1所示:
表1
本发明的核心处理框架包括数据标准化、特征提取、多层卷积核操作、子采样和分类;除此之外,本发明还包括采用随机梯度下降算法进行的对模型的迭代调参过程,具体包括以下步骤:
(1)数据标准化。
图2和图3展示了对业务流程图进行数据标准化的过程,业务流程图的数据集由两部分组成——由流程子图表征的特征值以及由候选流程节点表征的分类标签,数据标准化指的是对流程子图的标准化。
图2展示流程子图的重新标记的过程,图2(a)是该子图的矩阵表示,图2(b)是该子图的有向图表示,在保留图结构的情况下对该图的节点进行重新编号(用从0开始的自然数序列顺序标记),同时记录节点原始类别信息,得到图2(c)。
图3展示把有向图转化为邻接矩阵,矩阵中数值为1的位置表示对应的两个节点之间连有一条有向边,所得到的邻接矩阵即为初始输入特征图。
(2)基于矩阵变换的特征提取。
典型的卷积神经网络并不需要对输入特征图进行特征提取,但是会使得参数的数目急剧扩增并导致巨大的计算量和内存消耗。本发明对卷积神经网络的结果进行了适当的改进,提出了一种基于矩阵变换的特征提取方法,在对该方法进行具体说明之前先给出其所依赖的一个矩阵变换推论。
推论:设a是n阶矩阵,先交换a的第i列与第j列,再交换第i行与第j行,得到的矩阵记为b,则有:
1.|a|=|b|
2.r(a)=r(b)
4.a~b
5.a[*]b
证明:交换a的第i列与第j列,再交换第i行与第j行,相当于右乘、左乘相同的互换初等阵eij,即b=eijaeij,其中:
①因为|eij|=-1≠0是可逆阵,|eij|2=1,故1,2,3成立;
②eij-1=eij,则eijaeij=eij-1aeij=b,即a~b,所以4成立;
③eijt=eij,则eijaeij=eijtaeij=b,即
基于上述理论,对一个有向图的方阵先交换a的第i列与第j列再交换第i行与第j行得到的新矩阵表达的有向图与原图互为同构图,即含有相同的结构信息。基于此,本发明将初始输入特征图中的有用信息(即业务流程图中有向边的连接信息,在矩阵中指值为1的矩阵位置)集中到邻接矩阵的对角线附近,然后选取一个大小为n×n的滑动窗口沿着矩阵对角线由左上角至右下角滑动,得到新的特征图;其中实验参数n可能远小于数据集中单图最大节点数,从而使得最终得到的输入特征图的维度被显著地缩小,同时也保留了原图的有用信息。
图4展示了此步骤的过程。由图4可以看出,当选用滑动窗口的大小n=3时,对于初始输入特征图的邻接矩阵,有的边信息会位于滑动窗口之外,如图4中所示的位于矩阵右上区域的椭圆深色元素;而在经过矩阵变换之后,矩阵中所有的1都位于滑动窗口扫过的阴影区域,即原始的业务流程图的所有边信息都被集中到了相对较小的范围内;另一方面,可以从图4下方对应的有向图看到,新的特征图所表达的有向图与初始特征图所表达有向图互为同构图,即经过变换后100%的保留了原图的结构信息。
在基于矩阵变换后得到的特征图上,把滑动窗口滑过的区间在水平方向上连在一起,即构成了新的输入特征图,如图5所示。图5中n表示训练集中单图最大节点数,n表示选取的滑动窗口的大小,则原始输入特征图的大小为n×n,新的输入特征图的大小为n×(n-n+1)n。对于真实数据集而言,由于业务流程的场景不一样,业务流程图的节点数可能相差较大;现假设n=100,n=10,则经计算可以得到新的输入特征图可以减少近10%的输入特征数量,在多层卷积神经网络中,这样可以有效减少算法对内存的占用以及模型训练时间。
(3)多层卷积核操作。
本步骤对上一步所提取的输入特征图进行多层卷积核操作,以挖掘输入特征图的隐含特性,卷积层的结构如图6所示。把经矩阵变换得到的输入特征图称为level-0feature,可以看到level-0feature是由n-n+1个n×n的方阵拼接而成,每个小方阵对应滑动窗口的滑过的某一帧。
第一层卷积核cl-1(convolutionlayer-1)与level-0feature直接相连,其每一片卷积核的大小为h1×w1,卷积核总片数为f1。cl-1与level-0feature进行卷积操作,得到level-1feature,具体过程为:将cl-1中的每一片卷积核分别与level-0feature中的每一个n×n的小方阵进行卷积操作,结果对应到level-1feature中的相应行和列中。由图6所示,cl-1中,h1=w1=n,且cl-1在level-0feature中的移动步长为n,得到level-1feature的大小为f1×(n-n+1),其相应位置的计算公式为:
第二层卷积核cl-2(convolutionlayer-1)与level-1feature直接相连,其中每一片卷积核的大小为h2×w2,卷积核总片数为f2。同样,将cl-2与level-1feature进行卷积核操作,得到level-2feature,具体地:将cl-2中的每一片卷积核分别与level-1中的大小为h2×w2的矩阵子区间进行卷积操作,结果对应到level-2feature中对应的相应行和列中。在实际算法实现中,一般令cl-2每一片卷积核的高度与level-1feature的高度一致,即cl-2中h2=f1;另外,为了保证level-1feature中的特征具有平移不变性,cl-2的每一片卷积核在level-1feature中的移动步长为1,得到level-2feature的大小为发f2×((n-n+1)-w2+1),其相应位置的计算公式为:
值得注意的是,在每一个卷积层与上一级特征图做卷积操作得到新一级特征图的过程中,都需要对卷积后的结果做一次非线性激活;本实施方式采用的激活函数是relu激活函数,即:
(4)子采样和分类。
本步骤采用的子采样层和分类层结构如图7所示,子采样层是指采用maxpooling对level-2feature中的每一行进行子采样,采样结果写到finalfeature中;如果用ym向量表示level-mfeature,yf向量表示finalfeature,则有如下公式:
yf(i)=max(ym(i,:))
得到finalfeature后,经过一个两层的全连接神经网络分类器对其进行分类,得到最终的output。
特别的,在这个全连接神经网络的第一层中,本实施方式采用典型的dropout方式随机使部分权重参数失效,避免因训练样本不足导致过拟合问题,dropout的比率本实施方式中采用经验值20%。如果用yh向量表示hiddenlayer,yo向量表示output,wh,bh向量和ws,bs向量分别表示第一层和第二层的全连接权重参数,那么有:
yh(i)=σ(yf(j)·w1(j,i)+b1(i))
y0(i)=σ(yh(j)·w2(j,i)+b2(i))
另外,本实施方式在每一层全连接之后,使用sigmoid激活函数来激活和保存yh和yo向量的特征,如下式所示:
最后得到的yo向量即反应了该样本被分在不同类别的概率。如果用pr(class=i)表示该样本被分在第i类(i从0开始编号)的概率,则有如下公式,并且使得pr(class=i)最大的i值即是该次训练得到分类类别。
(5)模型迭代调参.
定义num表示训练样本总数,k表示总的分类类别数,c(j)表示第j个样本的真实分类,yk(j)表示训练第j个样本时所得到的output中的第k个值(表征计算中该样本被分为第k类的概率),cli表示第i层卷积核的参数;那么得到卷积神经网络的代价函数为:
需要训练的参数为:
ω=(cl1,cl2,···,clm,wh,bh,ws,bs)
基于上述代价函数和训练参数,本实施方式采用随机梯度下降算法(stochasticgradientdescent)对卷积神经网络进行训练,通过公式推导,可以得出如下所示的参数更新规则。
定义好损失函数和参数更新规则之后,将采用随机梯度下降算法对模型进行训练,通过反向传播算法确定各层结构的模型参数。
上述对实施例的描述是为便于本技术领域的普通技术人员能理解和应用本发明。熟悉本领域技术的人员显然可以容易地对上述实施例做出各种修改,并把在此说明的一般原理应用到其他实施例中而不必经过创造性的劳动。因此,本发明不限于上述实施例,本领域技术人员根据本发明的揭示,对于本发明做出的改进和修改都应该在本发明的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!