一种基于二级结构空间距离约束的蛋白质构象搜索方法与流程
本发明涉及一种生物学信息学、人工智能优化、计算机应用领域,尤其涉及的是一种基于二级结构空间距离约束的蛋白质构象搜索方法。
背景技术:
蛋白质是由氨基酸脱水缩合形成的生物大分子,对人类的健康起着决定性作用,准确掌握蛋白质的结构和功能对疾病研究、生物制药等方面都有重要意义。目前蛋白质结构预测的方法主要有两种:实验方法和理论预测。实验方法包括x射线晶体学、核磁共振光谱、和电子显微镜等;虽然这些方法能够准确地测定某些蛋白质的三维结构,但是通过实验的方法来测定结构是耗时且昂贵的,同时有些蛋白质的结构通过实验方法根本无法获得。所以,利用计算的方法来预测蛋白质结构已成为生物信息学研究中的热点。理论预测方法主要利用计算机技术和智能优化算法从氨基酸一级序列来预测蛋白质三维结构,从而有效的节约了预测成本,减少了预测时间,因此这类方法相比于实验方法更能得到广泛应用。但由于蛋白质结构本身的复杂性,到目前为止蛋白质三维结构的预测问题仍是一个有待解决的难题。
在从头预测蛋白质结构的方法中,进化算法是研究蛋白质分子构象优化的重要方法,例如遗传算法、差分进化等算法,这些算法拥有收敛速度快、结构简单以及鲁棒性强等优点。然而,当蛋白质序列比较长时,因构象空间太大,如果按照特定的能量函数来搜索,由于能量函数的不精确性,并不能保证所找到的能量最小的构象最接近天然态结构,因此往往不能形成正确的折叠。
因此,现有的构象空间搜索方法在预测精度和采样效率方面存在着缺陷,需要改进。
技术实现要素:
为了克服现有的蛋白质结构预测构象空间搜索方法存在采样效率较低、预测精度较低的不足,本发明提出一种采样效率较高、预测精度较高的基于二级结构空间距离约束的蛋白质构象搜索方法。
本发明解决其技术问题所采用的技术方案是:
一种基于二级结构空间距离约束的蛋白质构象搜索方法,所述方法包括以下步骤:
1)给定输入序列信息;
2)参数初始化:设置种群规模np,最大遗传代数gmax,确定交叉概率pc,初始种群迭代次数iteration,交叉片段长度frag_length,组装计数器reject_number,最大组装次数reject_max,先验知识中二级结构的空间长度以及相邻两个二级结构中心残基间的空间距离构成的特征向量d={d1,…,dm,d1,2,…,dk,k+1},其中dm是目标蛋白的第m个二级结构块的长度,dk,k+1是第k个二级结构块和第k+1个二级结构中心残基的空间距离,最大距离约束范围δ,选择概率ps;
3)初始化种群:启动np条montecarlo轨迹,每条轨迹搜索iteration次,即生成np个初始个体;
4)对每个目标个体xi和随机选取的个体xj进行如下操作,i,j∈(1,...,np)且j≠i:
4.1)按概率pc对个体xi和xj进行交叉操作,过程如下:
4.1.1)在允许范围[1,total_residue-frag_length]内随机选择交叉起始点begin_position,同时计算出交叉终止点end_position=begin_position+frag_length,其中total_residue为残基总数;
4.1.2)在每个交叉位点position∈[begin_position,end_position]处进行扭转角度交换,生成新个体x′i,x′j,即交叉个体x′i,x′j;
4.2)对交叉个体x′i,x′j进行如下变异操作,过程如下:
4.2.1)利用片段组装技术对交叉个体x′i进行空间构象搜索,计算出交叉个体x′i片段组装后的二级结构的长度以及相邻两个二级结构中心残基间的空间距离,并构成距离向量
4.2.2)根据公式
4.2.3)计数器reject_number开始计数,如果reject_number≤reject_max则依次执行步骤4.2.1)和4.2.2)生成新个体x″i,直到满足similarity_mutation_1≤δ停止;否则执行步骤4.2.1)生成新个体x″i;
4.2.4)与步骤4.2.1)和4.2.2)同理对个体x′j进行片段组装并计算相应的manhattan距离值similarity_mutation_2,最后得到新个体x″j;
4.2.5)根据公式
5)根据目标个体xi和变异个体x″i、x″j的能量和距离相似度进行选择,选出优势个体并更新种群,过程如下:
5.1)根据rosettascore3函数e(xi)分别计算目标个体xi和变异个体x″i、x″j的能量e(xi)、e(x″i)和e(x″j);
5.2)在目标个体xi和变异个体x″i、x″j中,若某一个体x,x∈{xi,x″i,x″j}的能量值小于其他两个个体的能量值,同时对应的manhattan距离值也比其他两个个体对应的manhattan距离值小,则该个体为优势个体;若某一个体x′,x′∈{xi,x″i,x″j}只有能量值比其他两个个体的能量值小,则按选择概率ps将该个体设为优势个体;同理,若某一个体x″,x″∈{xi,x″i,x″j}只有对应的manhattan距离值比其他两个个体对应的manhattan距离值小,则按选择概率ps将该个体设为优势个体;最后,优势个体替代目标个体,更新种群;
6)判断是否达到最大遗传代数gmax,若满足终止条件,则输出结果,否则转至步骤4)。
本发明的技术构思为:在遗传算法的基本框架下,利用目标蛋白中每个二级结构的空间长度以及相邻两个二级结构中心残基间的空间距离信息构成特征向量作为空间限制条件,使得在给定能量函数的条件下,在一个较小的构象空间中搜索解空间,同时在选择算子中加入了空间距离信息,弥补了能量函数的不精确性,进而有效提高了结构建模的精确度。
本发明的有益效果表现在:一方面通过二级结构的空间长度以及相邻两个二级结构中心残基间的空间距离构成特征向量作为空间限制条件,降低了构象搜索空间,同时降低了能量函数不精确带来的误差,进而大大提高了预测精度;另一方面,在遗传算法的框架下,通过个体间的信息交互、父代个体的变异选择操作,加快了收敛速度、增加了种群的多样性。
附图说明
图1是基于二级结构空间距离约束的蛋白质构象搜索方法的基本流程图。
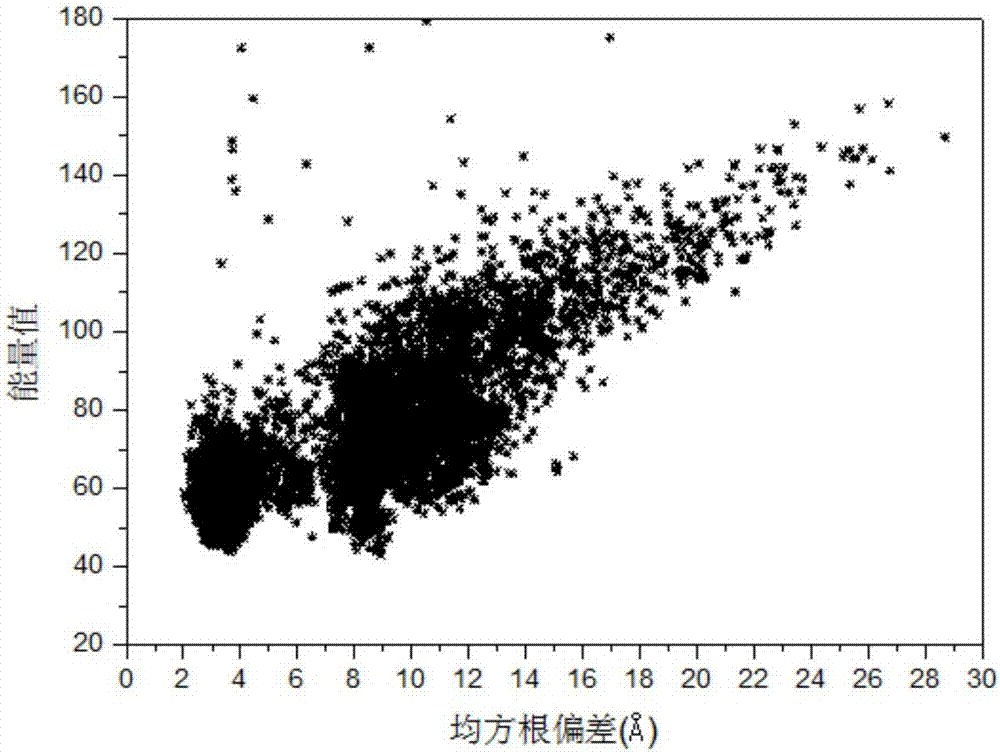
图2是基于二级结构空间距离约束的蛋白质构象搜索方法对蛋白质1ail进行结构预测时的构象更新示意图。
图3是基于二级结构空间距离约束的蛋白质构象搜索方法对蛋白质1ail进行结构预测得到的三维结构图。
具体实施方式
下面结合附图对本发明作进一步描述。
参照图1~图3,一种基于二级结构空间距离约束的蛋白质构象搜索方法,所述方法包括以下步骤:
1)给定输入序列信息;
2)参数初始化:设置种群规模np,最大遗传代数gmax,确定交叉概率pc,初始种群迭代次数iteration,交叉片段长度frag_length,组装计数器reject_number,最大组装次数reject_max,先验知识中二级结构的空间长度以及相邻两个二级结构中心残基间的空间距离构成的特征向量d={d1,…,dm,d1,2,…,dk,k+1},其中dm是目标蛋白的第m个二级结构块的长度,dk,k+1是第k个二级结构块和第k+1个二级结构中心残基的空间距离,最大距离约束范围δ,选择概率ps;
3)初始化种群:启动np条montecarlo轨迹,每条轨迹搜索iteration次,即生成np个初始个体;
4)对每个目标个体xi和随机选取的个体xj进行如下操作,i,j∈(1,...,np)且j≠i:
4.1)按概率pc对个体xi和xj进行交叉操作,过程如下:
4.1.1)在允许范围[1,total_residue-frag_length]内随机选择交叉起始点begin_position,同时计算出交叉终止点end_position=begin_position+frag_length,其中total_residue为残基总数;
4.1.2)在每个交叉位点position∈[begin_position,end_position]处进行扭转角度交换,生成新个体x′i,x′j,即交叉个体x′i,x′j;
4.2)对交叉个体x′i,x′j进行如下变异操作,过程如下:
4.2.1)利用片段组装技术对交叉个体x′i进行空间构象搜索,计算出交叉个体x′i片段组装后的二级结构的长度以及相邻两个二级结构中心残基间的空间距离,并构成距离向量
4.2.2)根据公式
4.2.3)计数器reject_number开始计数,如果reject_number≤reject_max则依次执行步骤4.2.1)和4.2.2)生成新个体x″i,直到满足similarity_mutation_1≤δ停止;否则执行步骤4.2.1)生成新个体x″i;
4.2.4)与步骤4.2.1)和4.2.2)同理对个体x′j进行片段组装并计算相应的manhattan距离值similarity_mutation_2,最后得到新个体x″j;
4.2.5)根据公式
5)根据目标个体xi和变异个体x″i、x″j的能量和距离相似度进行选择,选出优势个体并更新种群,过程如下:
5.1)根据rosettascore3函数e(xi)分别计算目标个体xi和变异个体x″i、x″j的能量e(xi)、e(x″i)和e(x″j);
5.2)在目标个体xi和变异个体x″i、x″j中,若某一个体x,x∈{xi,x″i,x″j}的能量值小于其他两个个体的能量值,同时对应的manhattan距离值也比其他两个个体对应的manhattan距离值小,则该个体为优势个体;若某一个体x′,x′∈{xi,x″i,x″j}只有能量值比其他两个个体的能量值小,则按选择概率ps将该个体设为优势个体;同理,若某一个体x″,x″∈{xi,x″i,x″j}只有对应的manhattan距离值比其他两个个体对应的manhattan距离值小,则按选择概率ps将该个体设为优势个体;最后,优势个体替代目标个体,更新种群;
6)判断是否达到最大遗传代数gmax,若满足终止条件,则输出结果,否则转至步骤4)。
本实施例序列长度为73的α折叠蛋白质1ail为实施例,一种基于二级结构空间距离约束的蛋白质构象搜索方法,其中包含以下步骤:
1)给定输入序列信息;
2)参数初始化:设置种群规模np=200,最大遗传代数gmax=2000,确定交叉概率pc=0.1,初始种群迭代次数iteration=2000,交叉片段长度frag_length=9,组装计数器reject_number=0,最大组装次数reject_max=100,先验知识中二级结构的空间长度以及相邻两个二级结构中心残基间的空间距离构成的特征向量d={3.81085,33.8066,8.38603,30.3193,6.69076,22.1852,19.6409,17.2739,15.4455,14.6372,15.5907,12.43},最大距离约束范围δ=15,选择概率ps=0.3;
3)初始化种群:启动np条montecarlo轨迹,每条轨迹搜索iteration次,即生成np个初始个体;
4)对每个目标个体xi和随机选取的个体xj进行如下操作,i,j∈(1,...,np)且j≠i:
4.1)按概率pc对个体xi和xj进行交叉操作,过程如下:
4.1.1)在允许范围[1,total_residue-frag_length]内随机选择交叉起始点begin_position,同时计算出交叉终止点end_position=begin_position+frag_length,其中total_residue为残基总数;
4.1.2)在每个交叉位点position∈[begin_position,end_position]处进行扭转角度交换,生成新个体x′i,x′j,即交叉个体x′i,x′j;
4.2)对交叉个体x′i,x′j进行如下变异操作,过程如下:
4.2.1)利用片段组装技术对交叉个体x′i进行空间构象搜索,计算出交叉个体x′i片段组装后的二级结构的长度以及相邻两个二级结构中心残基间的空间距离,并构成距离向量
4.2.2)根据公式
4.2.3)计数器reject_number开始计数,如果reject_number≤reject_max则依次执行步骤4.2.1)和4.2.2)生成新个体x″i,直到满足similarity_mutation_1≤δ停止;否则执行步骤4.2.1)生成新个体x″i;
4.2.4)与步骤4.2.1)和4.2.2)同理对个体x′j进行片段组装并计算相应的manhattan距离值similarity_mutation_2,最后得到新个体x″j;
4.2.5)根据公式
5)根据目标个体xi和变异个体x″i、x″j的能量和距离相似度进行选择,选出优势个体并更新种群,过程如下:
5.1)根据rosettascore3函数e(xi)分别计算目标个体xi和变异个体x″i、x″j的能量e(xi)、e(x″i)和e(x″j);
5.2)在目标个体xi和变异个体x″i、x″j中,若某一个体x,x∈{xi,x″i,x″j}的能量值小于其他两个个体的能量值,同时对应的manhattan距离值也比其他两个个体对应的manhattan距离值小,则该个体为优势个体;若某一个体x′,x′∈{xi,x″i,x″j}只有能量值比其他两个个体的能量值小,则按选择概率ps将该个体设为优势个体;同理,若某一个体x″,x″∈{xi,x″i,x″j}只有对应的manhattan距离值比其他两个个体对应的manhattan距离值小,则按选择概率ps将该个体设为优势个体;最后,优势个体替代目标个体,更新种群;
6)判断是否达到最大遗传代数gmax,若满足终止条件,则输出结果,否则转至步骤4)。
以序列长度为73的α折叠蛋白质1ail为实施例,运用以上方法得到了该蛋白质的近天然态构象,最小均方根偏差为
以上说明是本发明以1ail蛋白质为实例所得出的优化效果,并非限定本发明的实施范围,在不偏离本发明基本内容所涉及范围的前提下对其做各种变形和改进,不应排除在本发明的保护范围之外。
- 还没有人留言评论。精彩留言会获得点赞!